作者注:深入解析 Gemini API 的 safetySettings 安全设置机制,包括四大危害类别、五级阈值配置、BLOCK_NONE 的实际作用,帮助开发者正确配置图像生成模型的内容过滤
使用 Gemini 图像生成 API(如 gemini-2.0-flash-exp-image-generation 或 gemini-3-pro-image-preview)时,你可能见过这样的配置代码:
"safetySettings": [
{"category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_NONE"}
]
这段配置究竟是什么意思?BLOCK_NONE 真的能让模型生成任何内容吗?本文将详细解析 Gemini API 安全设置 的工作原理和正确使用方式。
核心价值: 读完本文,你将理解 Gemini 安全设置的四大危害类别、五级阈值配置,以及 BLOCK_NONE 的真实作用和局限性。
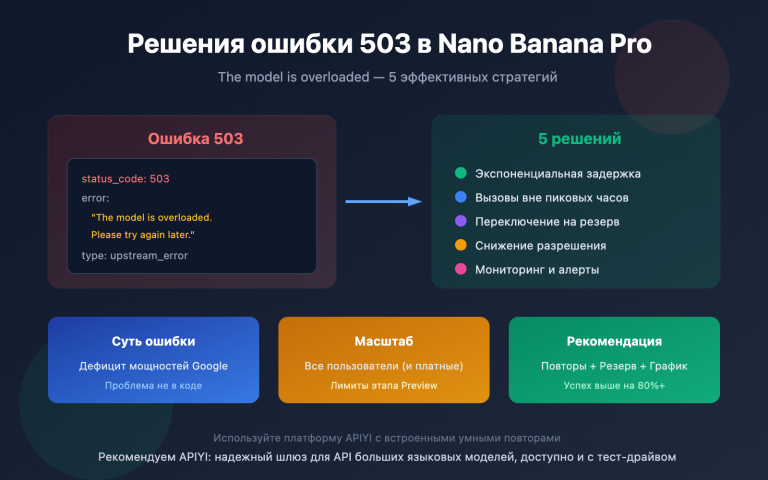
Gemini 安全设置核心要点
| 要点 | 说明 | 重要性 |
|---|---|---|
| 四大危害类别 | 骚扰、仇恨言论、色情内容、危险内容 | 可调节的内容过滤维度 |
| 五级阈值配置 | OFF、BLOCK_NONE、BLOCK_FEW、BLOCK_SOME、BLOCK_MOST | 控制过滤敏感度 |
| BLOCK_NONE 含义 | 关闭该类别的概率过滤,但不绕过核心保护 | 最宽松的可调节设置 |
| 不可调节的保护 | 儿童安全等核心危害始终被阻止 | 硬编码保护,无法关闭 |
安全设置的设计理念
Gemini API 的安全设置采用分层防护机制:
- 可调节层:开发者可以根据应用场景调整四大类别的过滤阈值
- 不可调节层:针对儿童安全等核心危害,系统始终阻止,无法通过任何设置绕过
这意味着,即使你将所有类别都设置为 BLOCK_NONE,模型仍然会拒绝生成涉及儿童安全等核心违规内容。
Подробный разбор четырёх категорий опасного контента
Gemini API поддерживает четыре настраиваемые категории опасного контента:
1. HARM_CATEGORY_HARASSMENT (Преследование)
Определение: Негативные или вредные комментарии, направленные на личность или защищённые признаки человека
Что включает:
- Личные оскорбления и унижения
- Дискриминационные высказывания о конкретных группах
- Контент, связанный с кибербуллингом
2. HARM_CATEGORY_HATE_SPEECH (Язык вражды)
Определение: Грубый, неуважительный или богохульный контент
Что включает:
- Расистские высказывания
- Религиозную ненависть
- Дискриминацию по признаку пола или сексуальной ориентации
3. HARM_CATEGORY_SEXUALLY_EXPLICIT (Сексуальный контент)
Определение: Упоминания сексуальных действий или непристойных материалов
Что включает:
- Явные сексуальные описания
- Контент с обнажёнкой
- Эротические намёки
4. HARM_CATEGORY_DANGEROUS_CONTENT (Опасный контент)
Определение: Контент, который продвигает, помогает или поощряет вредное поведение
Что включает:
- Инструкции по созданию оружия
- Руководства по самоповреждению или причинению вреда другим
- Описания незаконной деятельности
| Категория | Константа API | Что фильтрует |
|---|---|---|
| Преследование | HARM_CATEGORY_HARASSMENT |
Личные атаки, дискриминационные высказывания |
| Язык вражды | HARM_CATEGORY_HATE_SPEECH |
Расовая/религиозная ненависть |
| Сексуальный контент | HARM_CATEGORY_SEXUALLY_EXPLICIT |
Сексуальные описания, обнажёнка |
| Опасный контент | HARM_CATEGORY_DANGEROUS_CONTENT |
Инструкции по вредному поведению |
Подсказка: При работе с Gemini API через APIYI apiyi.com эти настройки безопасности также применяются и могут быть настроены в зависимости от ваших потребностей.
Подробный разбор пяти уровней порогов фильтрации
Gemini API предлагает пять уровней порогов, которые контролируют чувствительность фильтрации контента:
| Название настройки | Значение в API | Эффект фильтрации | Сценарии использования |
|---|---|---|---|
| Выключено | OFF |
Полное отключение фильтров безопасности | Значение по умолчанию для Gemini 2.5+ |
| Не блокировать | BLOCK_NONE |
Показывать контент независимо от оценки вероятности | Когда нужна максимальная творческая свобода |
| Блокировать мало | BLOCK_ONLY_HIGH |
Блокировать только контент с высокой вероятностью опасности | Подходит для большинства приложений |
| Блокировать частично | BLOCK_MEDIUM_AND_ABOVE |
Блокировать контент со средней и выше вероятностью | Когда нужна умеренная фильтрация |
| Блокировать много | BLOCK_LOW_AND_ABOVE |
Блокировать контент с низкой и выше вероятностью | Самая строгая фильтрация |
Как работают пороги
Система Gemini проводит оценку вероятности для каждого фрагмента контента, определяя возможность того, что это опасный контент:
- HIGH: высокая вероятность (скорее всего опасный контент)
- MEDIUM: средняя вероятность
- LOW: низкая вероятность
- NEGLIGIBLE: незначительная вероятность
Важный момент: система блокирует на основе вероятности, а не серьёзности. Это означает:
- Контент с высокой вероятностью, но низкой серьёзностью может быть заблокирован
- Контент с низкой вероятностью, но высокой серьёзностью может пройти
Значения по умолчанию
| Версия модели | Порог по умолчанию |
|---|---|
| Gemini 2.5, Gemini 3 и другие новые GA модели | OFF (выключено) |
| Другие старые модели | BLOCK_SOME (блокировать частично) |
Что на самом деле делает BLOCK_NONE
Что это дает
После установки BLOCK_NONE:
- Отключает вероятностную фильтрацию: Контент больше не блокируется на основе оценки вероятности в этой категории
- Разрешает пограничный контент: Легитимный контент, который мог быть ошибочно заблокирован, теперь проходит
- Расширяет творческие возможности: Меньше ложных срабатываний в художественных, образовательных и новостных сценариях
Чего это НЕ дает
Даже если все категории установлены в BLOCK_NONE:
- Базовая защита остается: Жестко закодированные механизмы защиты (например, защита детей) нельзя обойти
- Многоуровневая фильтрация работает: Мониторинг в реальном времени во время генерации и постобработка продолжают функционировать
- Политика не меняется: Контент, явно нарушающий правила Google, все равно будет отклонен
Особенности генерации изображений
Для моделей генерации изображений (например, gemini-2.0-flash-exp-image-generation) фильтрация безопасности устроена сложнее:
- Фильтрация промптов: Сначала проверяется входной текстовый запрос
- Мониторинг процесса генерации: Непрерывный контроль на этапе создания промежуточных результатов
- Проверка выхода: После завершения генерации еще одна проверка на соответствие правилам
Исследования показывают, что прямые явные запросы обычно блокируются, но техники вроде постепенного усиления в многораундовом диалоге могут обойти часть проверок.
Практические примеры настройки
Конфигурация в Python SDK
import google.generativeai as genai
# Настройка параметров безопасности
safety_settings = [
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_NONE"
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_NONE"
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_NONE"
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_NONE"
}
]
# Создание экземпляра модели
model = genai.GenerativeModel(
model_name="gemini-2.0-flash-exp",
safety_settings=safety_settings
)
# Генерация контента
response = model.generate_content("Ваш промпт")
Посмотреть пример конфигурации для REST API
{
"model": "gemini-2.0-flash-exp-image-generation",
"contents": [
{
"role": "user",
"parts": [
{"text": "Сгенерируй изображение в художественном стиле"}
]
}
],
"safetySettings": [
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_NONE"
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_NONE"
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_NONE"
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_NONE"
}
],
"generationConfig": {
"responseModalities": ["image", "text"]
}
}
Совет: Через APIYI apiyi.com можно быстро протестировать эффект разных настроек безопасности — платформа поддерживает единый интерфейс для вызова моделей серии Gemini.
Сценарии использования и рекомендации
Когда стоит использовать BLOCK_NONE
| Сценарий | Описание | Рекомендуемая конфигурация |
|---|---|---|
| Художественное творчество | Изобразительное искусство, абстрактные произведения | Категорию сексуального контента можно ослабить |
| Новостные репортажи | Изображения войн и конфликтов | Категорию опасного контента можно ослабить |
| Образовательные цели | Медицинский и исторический контент | Настраивать в зависимости от конкретного содержания |
| Модерация контента | Анализ потенциально нарушающего правила контента | Установить BLOCK_NONE для всех категорий |
Когда НЕ стоит использовать BLOCK_NONE
| Сценарий | Описание | Рекомендуемая конфигурация |
|---|---|---|
| Публичные приложения | Продукты для обычных пользователей | BLOCK_MEDIUM_AND_ABOVE |
| Детские приложения | Образовательные и развлекательные продукты для детей | BLOCK_LOW_AND_ABOVE |
| Корпоративные инструменты | Сценарии, требующие проверки на соответствие нормативам | BLOCK_ONLY_HIGH |
Лучшие практики
- Постепенная настройка: Начните с дефолтных параметров и постепенно ослабляйте по мере необходимости
- Разные настройки для разных категорий: Можно установить разные пороги для каждой категории — не обязательно делать их одинаковыми
- Мониторинг и логирование: Записывайте заблокированные запросы, анализируйте, нужна ли корректировка
- Анализ пользовательских сценариев: Выбирайте подходящий уровень фильтрации исходя из вашей целевой аудитории
Частые вопросы
Q1: Почему контент всё равно блокируется после установки BLOCK_NONE?
BLOCK_NONE отключает только вероятностную фильтрацию для конкретной категории, но блокировка всё равно может происходить в следующих случаях:
- Базовая защита: Жёстко закодированные механизмы защиты детей невозможно отключить
- Другие категории: Если вы установили BLOCK_NONE только для части категорий
- Красные линии политики: Контент, явно нарушающий политику использования Google
- Проверки в процессе генерации: Для генерации изображений существует дополнительный мониторинг в реальном времени
Q2: В чём разница между OFF и BLOCK_NONE?
Согласно официальной документации Google:
- OFF: Полностью отключает фильтр безопасности (значение по умолчанию для Gemini 2.5+)
- BLOCK_NONE: Показывает контент независимо от оценки вероятности
Практический эффект очень похож, но OFF более радикально отключает логику фильтрации для данной категории. Для новых версий моделей результат работы обоих параметров практически идентичен.
Q3: Как использовать настройки безопасности через сервисы-прокси API?
При вызове Gemini API через APIYI apiyi.com:
- Параметры настроек безопасности полностью передаются в Google API
- Способ настройки точно такой же, как при прямом обращении к Google API
- Поддерживаются все четыре категории и пять уровней порогов
- Можно быстро протестировать эффект разных конфигураций на этапе тестирования
总结
Gemini API 安全设置的核心要点:
- 四大可调类别: 骚扰、仇恨言论、色情内容、危险内容,开发者可根据需求调整
- 五级阈值配置: 从 OFF/BLOCK_NONE(最宽松)到 BLOCK_LOW_AND_ABOVE(最严格)
- BLOCK_NONE 的本质: 关闭概率过滤,但不绕过核心保护和政策红线
- 分层防护机制: 可调节层 + 不可调节层,确保基本安全底线
- 图像生成特殊性: 多层过滤(提示词→生成过程→输出审查)更为严格
理解这些设置后,你可以根据应用场景合理配置安全参数,在创作自由和内容安全之间找到平衡。
通过 APIYI apiyi.com 可以快速测试 Gemini 图像生成模型的安全设置效果,平台提供免费额度和多模型统一接口。
参考资料
⚠️ 链接格式说明: 所有外链使用
资料名: domain.com格式,方便复制但不可点击跳转,避免 SEO 权重流失。
-
Gemini API 安全设置官方文档: Google 官方指南
- 链接:
ai.google.dev/gemini-api/docs/safety-settings - 说明: 权威的安全设置配置说明和 API 参考
- 链接:
-
Vertex AI 安全过滤器配置: Google Cloud 文档
- 链接:
cloud.google.com/vertex-ai/generative-ai/docs/multimodal/configure-safety-filters - 说明: 企业级 Vertex AI 的安全配置详解
- 链接:
-
Gemini 安全指南: 开发者最佳实践
- 链接:
ai.google.dev/gemini-api/docs/safety-guidance - 说明: 安全使用 Gemini API 的官方建议
- 链接:
-
Firebase AI Logic 安全设置: Firebase 集成指南
- 链接:
firebase.google.com/docs/ai-logic/safety-settings - 说明: Firebase 环境下的安全设置配置
- 链接:
作者: 技术团队
技术交流: 欢迎在评论区讨论,更多资料可访问 APIYI apiyi.com 技术社区