Интересное наблюдение: в последнее время многие разработчики, тестируя модель M2.7 от MiniMax, выпущенную в марте 2026 года, столкнулись с контринтуитивной проблемой. Эта флагманская модель, которую называют «королем кода и агентных рабочих процессов», внезапно оказалась лишена поддержки ввода изображений. Согласитесь, в эпоху, когда мультимодальность стала стандартом для Claude 4, GPT-5 и Gemini 3, отсутствие функции распознавания изображений у флагмана с 230 млрд параметров выглядит как минимум неожиданно. В этой статье, опираясь на официальную документацию MiniMax, карты моделей NVIDIA NIM и открытые спецификации OpenRouter, а также на опыт внедрения через APIYI (apiyi.com), мы глубоко разберем логику продукта, стоящую за «чисто текстовым» позиционированием M2.7.
I. Правда ли, что MiniMax M2.7 не поддерживает ввод изображений?
Ответим сразу: да, это правда. Согласно официальной платформе MiniMax и спецификациям модели NVIDIA NIM, M2.7 (включая версию M2.7-highspeed) на данный момент поддерживает только текстовый ввод и не может напрямую обрабатывать изображения, аудио или видео. Это соответствует чисто текстовому позиционированию предыдущего поколения M2.5, но резко контрастирует с мейнстримом «нативной мультимодальности», представленным в то же время моделями Claude 4 Opus, GPT-5 и серией Gemini 3.
1.1 Краткий обзор основных характеристик MiniMax M2.7
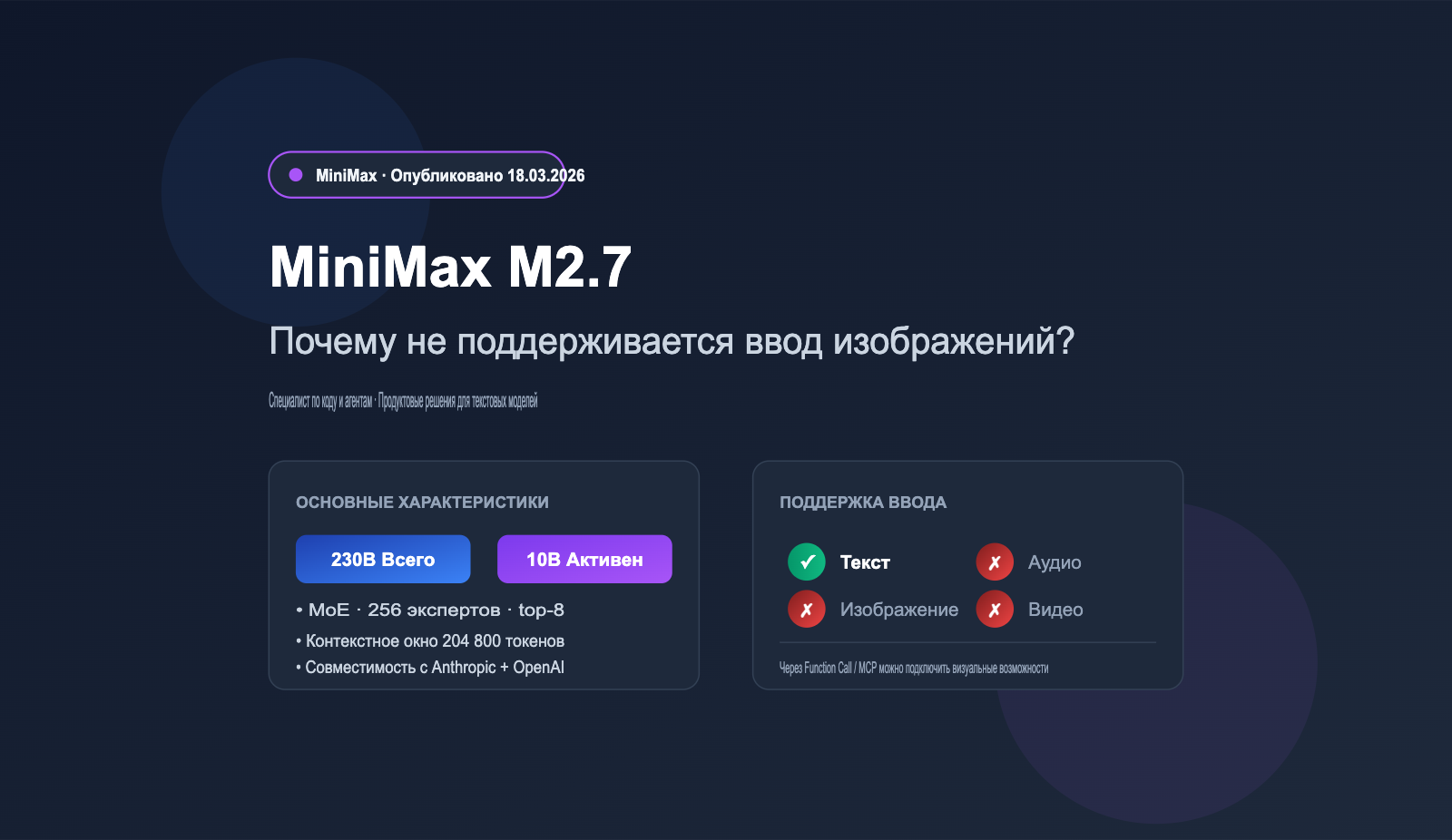
Модель M2.7 была официально открыта для доступа 18 марта 2026 года. Она использует архитектуру MoE (смесь экспертов) с общим количеством параметров 230 млрд и 10 млрд активных параметров, делая ставку на «высокую производительность и низкую стоимость».
| Характеристика | Параметр |
|---|---|
| Дата выпуска | 18.03.2026 |
| Тип архитектуры | MoE Transformer (256 экспертов, 8 активных на токен) |
| Общие / Активные параметры | 230B / 10B |
| Контекстное окно | 204 800 токенов |
| Максимальный вывод | 131 072 токена |
| Цена за вход | $0.279 / млн токенов |
| Цена за выход | $1.20 / млн токенов |
| Поддержка мультимодальности | ❌ Только текст |
| API-совместимость | Anthropic API + OpenAI API |
1.2 В каких сценариях вы можете «споткнуться»
Если ваше приложение включает в себя ответы на вопросы по скриншотам, анализ PDF-документов через изображения, понимание изображений товаров, визуальный контроль UI-автоматизации или поиск по изображениям в мультимодальном RAG, прямой вызов M2.7 приведет к ошибке или бессмысленному выводу. Рекомендуем на уровне маршрутизации (например, через LiteLLM, One API или единый шлюз APIYI apiyi.com) настроить проверку типа модели и перенаправлять запросы с изображениями на модели серий Claude, GPT-5 или Gemini 3.
二、为什么 MiniMax M2.7 选择"纯文本"路线
M2.7 ориентируется на работу с чистым текстом не из-за нехватки технических возможностей, а в результате четкого продуктового решения. Ранее MiniMax уже выпускала серию моделей abab с мультимодальными функциями, поэтому компания вполне могла добавить визуальный модуль и в серию M. Однако они решили направить все вычислительные мощности обучения M2.7 на два направления — «код + агентные системы», чтобы добиться в них максимальной производительности.
2.1 Код и агенты — ключевое поле битвы для M2.7
Согласно официальному README и техническому блогу NVIDIA, модель M2.7 специально оптимизирована для «редактирования нескольких файлов, циклов написания-запуска-исправления кода, тестирования, а также вызова длинных цепочек инструментов, включая работу с оболочкой (Shell), браузером, поиском и исполнителями кода». В реальных задачах программирования, таких как SWE-bench, Aider Polyglot и Terminal Bench, результаты M2.7 близки к Claude 4 Sonnet, но при этом модель имеет всего 10 млрд активных параметров, а стоимость вывода составляет около 1/8 от стоимости конкурента.
2.2 Баланс между чисто текстовым и мультимодальным подходом
Концентрация ресурсов обучения на одном направлении приносит как гарантированные выгоды, так и потери. В таблице ниже приведены ключевые аспекты сравнения этих двух подходов:
| Параметр | Чисто текстовый подход (M2.7 / DeepSeek-R1) | Мультимодальный подход (Claude/GPT/Gemini) |
|---|---|---|
| Стоимость обучения | Концентрированная, высокая эффективность | Распределенная, высокая стоимость данных |
| Цена за 1 млн токенов | Ниже ($0.28–2) | Выше ($3–15) |
| Глубина рассуждений (текст/код) | Обычно сильнее | Чуть слабее, но достаточна |
| Понимание изображений/видео | Не поддерживается | Поддерживается нативно |
| Широта применения | Узкоспециализированная | Более универсальная |
| Сложность инженерной интеграции | Низкая | Низкая–средняя |
2.3 «Дополнение» мультимодальных возможностей через вызов инструментов
Хотя сама по себе M2.7 не распознает изображения, она нативно поддерживает MCP (Model Context Protocol) и вызов функций (Function Calling). Это означает, что разработчики могут «аутсорсить» задачи по пониманию изображений специализированным визуальным моделям (например, Claude 4 Opus или Gemini 3 Vision), оставляя за M2.7 только планирование и финальные рассуждения. Такая архитектура «главный контроллер + визуальный помощник» очень распространена в агентных системах.
三、Являются ли мультимодальные API в 2026 году отраслевым стандартом?
На первый взгляд кажется, что «мультимодальность = стандарт» — это уже общепринятый факт 2026 года. Но если присмотреться к лагерю ведущих моделей, становится понятно, что этот вопрос требует более глубокого анализа.
3.1 Ведущие закрытые флагманы почти все поддерживают мультимодальность
Серия Claude 4 от Anthropic, GPT-5 от OpenAI и Gemini 3 Pro/Ultra от Google уже сделали работу с изображениями базовой функцией. В тесте ScreenSpot-Pro модель Gemini 3 совершила рывок с 11,4% до 72,7%, научившись напрямую «понимать» скриншоты и взаимодействовать с интерфейсом; Claude 4 также усилила возможности распознавания графиков и анализа PDF-файлов.
3.2 Раскол в лагере Open Source и бюджетных моделей
В лагере моделей с открытым исходным кодом наблюдается явное разделение: с одной стороны, это «полностековые мультимодальные» модели, такие как Llama 3.2 Vision, Qwen3-VL и InternVL; с другой — модели, сфокусированные на тексте и рассуждениях, такие как DeepSeek-R1 и MiniMax M2.7, которые выигрывают за счет специализации и соотношения цены и качества. Это не просто «лучше или хуже», а дифференцированный выбор для разных типов задач.
3.3 Сравнение мультимодальных возможностей ведущих моделей
В таблице ниже собраны данные о мультимодальных возможностях основных больших языковых моделей на май 2026 года, что позволяет быстро понять позиционирование M2.7:
| Модель | Ввод изображений | Ввод видео | Ввод аудио | Основное позиционирование |
|---|---|---|---|---|
| MiniMax M2.7 | ❌ | ❌ | ❌ | Код / Агентные рассуждения |
| Claude 4 Opus | ✅ | ❌ | ❌ | Универсальность + длинные тексты + код |
| GPT-5 | ✅ | ✅ | ✅ | Универсальная мультимодальность |
| Gemini 3 Pro | ✅ | ✅ | ✅ | Мультимодальность + понимание UI |
| DeepSeek-R1 | ❌ | ❌ | ❌ | Математические рассуждения |
| Qwen3-VL | ✅ | ✅ | ❌ | Open Source мультимодальность |
Как видите, «стандартная мультимодальность» в основном сосредоточена среди закрытых флагманских моделей. В сегменте Open Source и бюджетных решений специализация на тексте остается эффективным способом дифференциации.

IV. Как заставить MiniMax M2.7 работать с изображениями, если у него нет встроенного зрения
Хотя сама по себе модель M2.7 не умеет «читать» изображения, вы можете легко построить гибридную архитектуру «M2.7 как основной контроллер + визуальная модель». Это позволит вам пользоваться низкой стоимостью M2.7, не жертвуя при этом мультимодальными возможностями.
4.1 Рекомендуемая архитектура гибридного вызова
Самый простой подход — использовать единый шлюз (например, сервис-прокси API от APIYI, apiyi.com) для распределения запросов по типам контента. Текстовые запросы и код направляются в M2.7, а запросы с изображениями — в Claude 4 или Gemini 3. Затем текстовый ответ от визуальной модели передается обратно в M2.7 для финального анализа и принятия решения. Такая архитектура прозрачна для фронтенда и не требует изменения SDK на стороне вашего приложения.
4.2 Использование визуальных моделей через Function Calling
Если ваше приложение использует Function Calling, вы можете зарегистрировать для M2.7 инструмент analyze_image. Внутри него будет вызываться визуальный интерфейс Claude/GPT/Gemini, а результат распознавания будет возвращаться в формате JSON. M2.7 будет автоматически определять, когда нужно вызвать этот инструмент, основываясь на запросе пользователя, без необходимости прописывать это явно в промпте. Этот паттерн отлично подходит для агентских фреймворков (например, LangGraph, CrewAI или OpenAI Agents SDK).
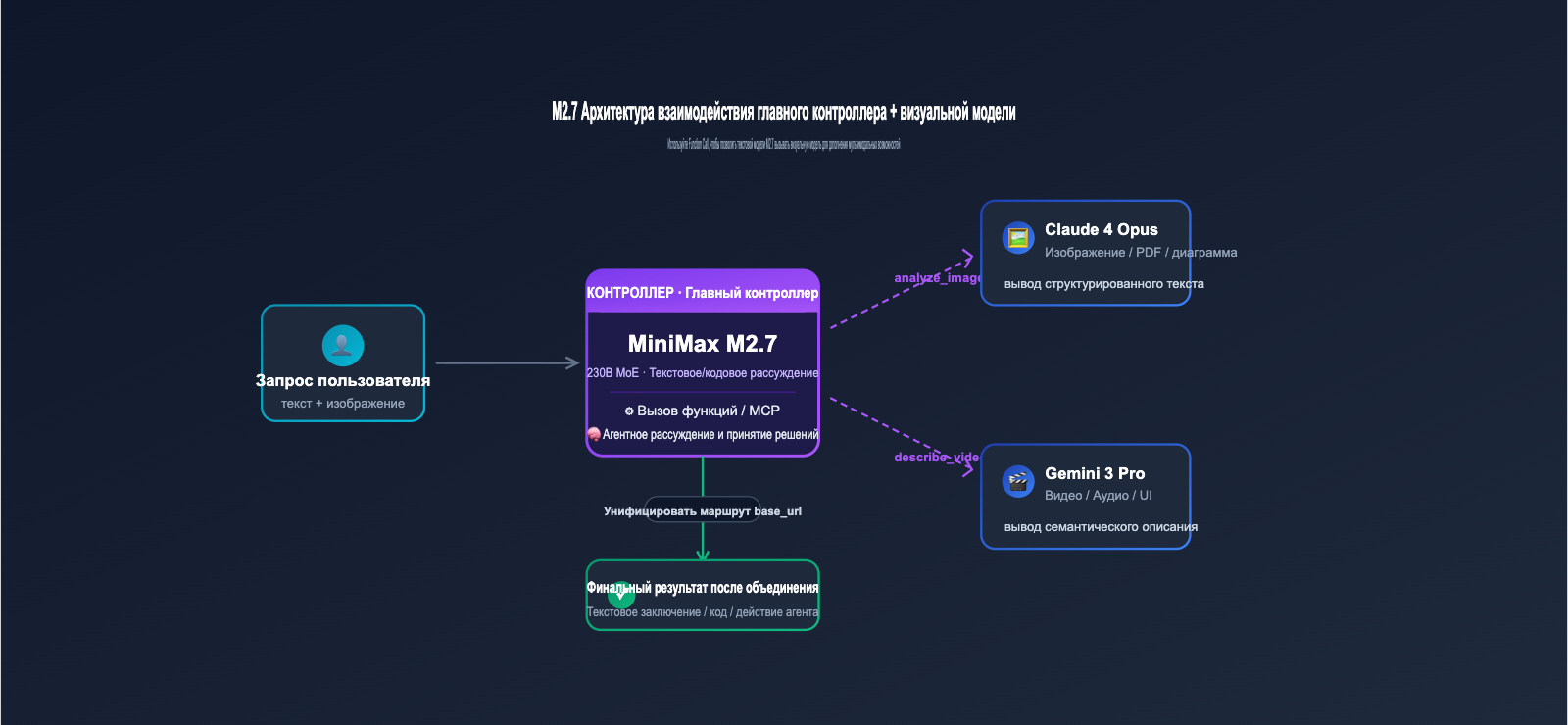
🎯 Совет по интеграции: Мы рекомендуем использовать APIYI (apiyi.com) с единым
base_urlдля доступа как к M2.7, так и к мультимодальным моделям (таким как Claude 4 Opus или Gemini 3 Pro). Это избавит вас от необходимости поддерживать отдельные SDK и API-ключи для каждого провайдера, значительно упростит инженерную часть и позволит централизованно отслеживать потребление токенов и расходы.
4.3 Рекомендуемые параметры вывода
Для MiniMax M2.7 официально рекомендуются относительно высокие параметры выборки: temperature=1.0, top_p=0.95, top_k=40. Это отличается от рекомендаций для многих других моделей, где советуют низкую температуру. Практика показывает, что в задачах программирования и агентских сценариях эти параметры позволяют получить более качественный и креативный код. Если в ваших шаблонах промптов по умолчанию стоит temperature=0, на M2.7 вы можете получить «зажатые» или повторяющиеся ответы, поэтому параметры стоит перенастроить.
V. Выбор между MiniMax M2.7 и мультимодальными моделями
Вопрос о том, когда выбирать M2.7, а когда — флагманскую мультимодальную модель, сводится не к сравнению количества параметров, а к тому, что является приоритетом в вашем приложении: текст/код или мультимодальные задачи.
5.1 Выбор M2.7 для задач, ориентированных на текст и код
Если более 90% запросов вашего продукта связаны с текстом (генерация кода, ответы на вопросы по документам, оркестрация агентов, суммаризация длинных текстов), то M2.7 — один из самых выгодных вариантов на сегодняшний день. Общее количество параметров в 230 млрд обеспечивает возможности, близкие к Claude 4 Sonnet, при этом стоимость за токен составляет лишь малую часть от цены конкурента, что особенно удобно для SaaS-бэкендов с высокой нагрузкой.
5.2 Выбор Claude / Gemini для частого использования мультимодальности
Если ваш основной сценарий — это понимание изображений (OCR, автоматизация UI, распознавание товаров, помощь в анализе медицинских снимков), видеоанализ или обработка аудио, лучше сразу выбрать Claude 4 Opus, GPT-5 или Gemini 3 Pro. Это будет проще и надежнее, чем использовать гибридную архитектуру «M2.7 + визуальная модель», так как позволит снизить задержки и вероятность сбоев при вызове нескольких моделей.
5.3 Рекомендации по выбору для различных сценариев
| Сценарий применения | Приоритетная модель | Альтернатива |
|---|---|---|
| Генерация / рефакторинг кода | MiniMax M2.7 | Claude 4 Sonnet |
| Вызов инструментов агентами | MiniMax M2.7 | GPT-5 |
| Ответы по длинным документам (до 200К) | MiniMax M2.7 | Claude 4 Opus |
| OCR изображений / ответы по скриншотам | Gemini 3 Pro | Claude 4 Opus |
| Видеоанализ | Gemini 3 Pro | GPT-5 |
| Мультимодальный RAG | Claude 4 Opus | Gemini 3 Pro |
| Смешанные задачи (текст + немного изображений) | Комбинация M2.7 + визуальная модель | Claude 4 Opus (одна модель) |
🎯 Совет по выбору: Суть выбора модели не в том, «кто сильнее», а в том, «кто лучше соответствует распределению ваших запросов». Рекомендуем провести A/B-тестирование на реальном трафике через платформу APIYI apiyi.com, чтобы сравнить стоимость и качество выполнения задач разными моделями, прежде чем определиться с основным стеком.
VI. Часто задаваемые вопросы о MiniMax M2.7
6.1 Действительно ли M2.7 совсем не умеет работать с изображениями?
Да, если вы отправите файл изображения (base64 или URL) в messages, интерфейс отклонит запрос или вернет ошибку. Единственный рабочий вариант — сначала использовать другую визуальную модель для преобразования изображения в текстовое описание, а затем передать это описание в M2.7 для дальнейшего рассуждения.
6.2 В чем разница между M2.7 и M2.7-highspeed?
Результаты генерации у них идентичны, разница только в скорости ответа. M2.7-highspeed подходит для сценариев, чувствительных к задержкам (например, автодополнение в IDE), а стандартная версия M2.7 — для массовых асинхронных задач. Переключаться между версиями можно в консоли APIYI apiyi.com по названию модели, параметры интерфейса полностью совместимы.
6.3 Является ли M2.7 моделью с открытым исходным кодом, можно ли развернуть её локально?
Да, M2.7 — это модель с открытыми весами, её можно скачать на HuggingFace и разместить на своих мощностях. Однако для полноценной работы с контекстным окном 200К потребуется как минимум 8 карт A100 / H100. Стоимость локального развертывания значительно выше, чем использование API, поэтому, если у вас нет строгих требований по комплаенсу данных, создавать собственную инфраструктуру не рекомендуется.
6.4 Совместима ли M2.7 с официальными SDK Anthropic / OpenAI?
Полностью совместима. Вы можете напрямую использовать официальные SDK anthropic или openai, просто указав base_url на сервис-прокси API (например, единую точку доступа APIYI apiyi.com) и изменив название модели. Переписывать бизнес-логику не нужно. Это самый простой способ внедрения гибридной архитектуры.
6.5 Стоит ли командам с большим количеством мультимодальных задач отказываться от M2.7?
Не обязательно. Даже в мультимодальных приложениях текстовые рассуждения и оркестрация составляют значительную часть запросов. Рекомендуем оставить мультимодальные задачи для Claude/Gemini, а текстовую логику и принятие решений доверить M2.7 — это позволит существенно снизить общие расходы на вызов моделей. Если вам нужно разработать индивидуальное гибридное решение, свяжитесь с командой APIYI apiyi.com для получения архитектурных рекомендаций.
VII. Итоги: мультимодальность — это тренд, но «узкая специализация» остается эффективным путем
Отсутствие поддержки ввода изображений в MiniMax M2.7 — это не только факт, но и осознанная продуктовая стратегия. В 2026 году, когда мультимодальность стала стандартом для флагманских закрытых моделей, MiniMax решила сосредоточить все ресурсы на обучении в двух наиболее перспективных нишах: написании кода и разработке агентов. Это позволило достичь уровня Claude 4 Sonnet в задачах программирования при значительно более низкой стоимости инференса.
Для разработчиков это означает, что выбор модели теперь сводится не к простому сравнению «кто более универсален», а к вопросу «кто лучше соответствует распределению ваших запросов». В сценариях, где доминируют текст и код, M2.7 остается одним из самых выгодных решений по соотношению цена-качество. В то же время для задач с высокой частотой мультимодальных запросов стоит выбирать специализированные модели, такие как Claude 4 Opus, GPT-5 или Gemini 3. Комбинированное использование этих инструментов через единый шлюз часто позволяет добиться оптимального баланса между затратами и результатом.
Если вам нужно интегрировать M2.7 и флагманские мультимодальные модели через один base_url, посетите официальную документацию APIYI на сайте apiyi.com, где вы найдете полный список моделей и примеры подключения.
Автор: Команда APIYI — мы предоставляем стабильные и эффективные сервисы-прокси API и маршрутизацию для мультимодальных моделей для AI-разработчиков по всему миру. Подробности на сайте apiyi.com