Кэширование промптов (Prompt Caching) — это тема, которую в 2026 году не обойдет стороной ни один пользователь API больших языковых моделей. Если вы запускаете RAG-приложение с системным промптом на 8 тысяч токенов, разница в ежемесячном счете с включенным кэшированием и без него может превышать 10 раз. Однако многие разработчики, переключаясь между OpenAI и Anthropic, спотыкаются о скрытую деталь: модели тарификации кэширования у этих компаний кардинально различаются.

Самое важное различие заключается в одной фразе: запись в кэш серии GPT тарифицируется по базовой цене 1x без наценок, в то время как запись в кэш серии Claude облагается наценкой 1.25x (на 5 минут) или 2x (на 1 час). Эта разница кажется незначительной, но при реальных объемах трафика она существенно влияет на точку безубыточности. В этой статье мы подробно разберем правила тарификации, условия активации, скидки на чтение, стратегии TTL и расчет окупаемости, чтобы помочь вам точнее спрогнозировать расходы.
5 ключевых различий кэширования промптов GPT и Claude
Перейдем сразу к выводам. Таблица ниже — это то, что стоит сохранить в закладки. В ней собраны 5 критических аспектов кэширования, которые чаще всего упускают из виду.
| Параметр | OpenAI GPT | Anthropic Claude |
|---|---|---|
| Тарификация записи | 1x базовая цена, без наценки | 5 мин: 1.25x; 1 час: 2x |
| Тарификация чтения | ~0.1x (скидка до 90%) | 0.1x (цена после 10% скидки) |
| Метод активации | Автоматически, без правок кода | Явный opt-in, нужен cache_control |
| Мин. порог токенов | Единый 1024 токена | 1024 / 2048 / 4096 (зависит от модели) |
| TTL кэша | 5–10 мин простоя, макс. 1 час; расширенный режим 24 часа | По умолчанию 5 мин, опционально 1 час (2x запись) |
Суть таблицы кроется в строке «Тарификация записи». Логика OpenAI такова: кэширование для вас бесплатно, первая запись оплачивается по базовой цене, а последующие попадания (hits) дают скидку. Поэтому как только происходит хотя бы одно попадание, вы сразу выходите в зону чистой прибыли. Логика Claude: за запись нужно сначала заплатить наценку, которая компенсируется скидками при попаданиях, поэтому требуется «достаточное количество попаданий», чтобы окупить эту наценку.
🎯 Совет по настройке: Если ваш бизнес-трафик непредсказуем, а коэффициент попаданий нестабилен, рекомендую отдать предпочтение автоматическому кэшированию GPT для снижения рисков. Если же коэффициент попаданий очень стабилен (например, в поддержке, агентах или анализе длинных документов), явное управление кэшем в Claude позволит получить более высокую скидку. Обе модели доступны в APIYI (apiyi.com), где вы можете провести сравнительное тестирование в рамках одного ключа, не создавая лишних аккаунтов.
Подробный разбор механизма тарификации кэширования промптов в OpenAI GPT
Официальная документация OpenAI описывает функцию Prompt Caching максимально просто: «Кэширование происходит автоматически, никаких явных действий или дополнительных затрат для использования этой функции не требуется». Переводя на человеческий: автоматическое включение, нулевая доплата и ни строчки кода в изменениях.
Тарификация записи и чтения кэша GPT
GPT не взимает никакой наценки за запись в кэш. Когда вы впервые отправляете системный промпт объемом 8K токенов, с вас списывают стандартную стоимость ввода — точно так же, как если бы кэширование было отключено. Начиная со второго раза, если система распознает, что этот префикс уже закэширован, она тарифицирует попавшую в кэш часть со скидкой около 90% от базовой цены.
| Пункт | Метод тарификации | Соотношение к базовой цене |
|---|---|---|
| Первая запись в кэш | По базовой цене ввода | 1x (без наценки) |
| Чтение из кэша | Скидка за попадание | около 0.1x |
| Стоимость активации | Полностью бесплатно | 0 |
| Изменения в коде | Нулевые | Не требуются |
Официально заявленный размер скидки составляет «до 90%», что может незначительно варьироваться в зависимости от модели и тарифной сетки. Например, базовая цена ввода для GPT-5.4 составляет $2/1M токенов, а цена при попадании в кэш — $0.20/1M, что ровно в 10 раз меньше. Модели GPT-4.1, GPT-4o и другие поддерживаемые версии в основном придерживаются этой пропорции.
🎯 Проверка цен: Поскольку модели OpenAI обновляются часто, актуальные цены при попадании в кэш смотрите в официальном прайс-листе. Рекомендую проверять текущие тарифы прямо в панели управления APIYI (apiyi.com) — платформа синхронизируется с официальными изменениями и не взимает дополнительных комиссий за сервис-прокси API, разработчики платят только за фактическое использование токенов.
Условия попадания в кэш GPT
Чтобы сработало кэширование, должны одновременно выполняться два условия:
- Длина промпта ≥ 1024 токенов (тексты короче не попадают в кэш).
- Префикс промпта должен полностью совпадать с предыдущим запросом; попадание рассчитывается с шагом в 128 токенов.
Минимальный размер блока кэширования OpenAI установлен на уровне 128 токенов. Это означает, что для стабильного префикса в 1500 токенов, при условии совпадения первых 1024 токенов, остальная часть будет постепенно попадать в кэш с шагом в 128 токенов. Минус такого автоматизированного подхода — низкая гибкость: разработчик не может явно указать, «какую именно часть нужно кэшировать», поэтому весь стабильный контент необходимо размещать в начале промпта.
Поведение TTL (времени жизни) кэша GPT
OpenAI дает ключевое описание TTL: кэшированные префиксы обычно удаляются после 5–10 минут простоя, а максимальный срок хранения составляет 1 час. Более новые модели, такие как GPT-5 и GPT-4.1, также поддерживают «расширенное хранение» (extended retention), которое может достигать 24 часов.
🎯 Совет по использованию: При работе с GPT через APIYI (apiyi.com) автоматическая стратегия кэширования OpenAI остается прозрачной для нашего сервиса-прокси API, а частота попаданий совпадает с прямым подключением к официальным эндпоинтам. Это значит, что вы можете управлять счетами и токенами OpenAI и Claude в едином окне APIYI без каких-либо дополнительных затрат.
Подробный разбор механизма тарификации кэширования промптов в Anthropic Claude
Философия дизайна Claude прямо противоположна OpenAI — здесь кэширование рассматривается как «активно настраиваемая возможность оптимизации». Разработчик должен явно объявить, что именно и на какой срок кэшировать. Цена за это — наценка при записи, награда — высочайшая точность управления.
Наценка за запись и скидка за чтение в кэше Claude
| Пункт | Коэффициент тарификации | Примечание |
|---|---|---|
| Запись на 5 минут | 1.25x базовой цены ввода | TTL по умолчанию, подходит для большинства задач |
| Запись на 1 час | 2x базовой цены ввода | Подходит для длинных сессий, агентов и т.д. |
| Чтение из кэша | 0.1x базовой цены ввода | Скидка 90% |
| Стоимость активации | 0 | Нет доп. сборов |
| Изменения в конфигурации | Обязательное добавление cache_control |
Явное согласие (opt-in) |
Наглядный пример: базовая цена ввода Claude Opus 4.7 составляет $5/1M токенов. Запись на 5 минут обойдется в $6.25/1M, на 1 час — в $10/1M, а чтение из кэша — всего в $0.50/1M. Эта таблица цен зафиксирована в документации Anthropic и остается стабильной уже несколько кварталов.
Минимальный порог токенов для кэша Claude
Минимальное количество токенов для кэширования в Claude зависит от модели, и это первая ловушка, в которую попадают многие пользователи.
| Модель | Мин. кэшируемых токенов |
|---|---|
| Claude Opus 4.7 / 4.6 / 4.5 | 4096 |
| Claude Haiku 4.5 | 4096 |
| Claude Sonnet 4.6 | 2048 |
| Claude Sonnet 4.5 / Opus 4.1 / Sonnet 4 | 1024 |
Если ваш стабильный префикс короче минимального порога модели, он не попадет в кэш, даже если вы добавите cache_control. Запрос будет молча обработан как обычный — ошибок не будет, но кэширование фактически не сработает. Это особенно важно для Opus 4.7: порог в 4096 токенов довольно высок, и в коротких диалогах кэширование практически бесполезно.
🎯 Совет по выбору модели: Если длина контекста в вашем проекте нестабильна, рекомендую выбирать Claude Sonnet 4.5 или 4.6 — у них ниже порог и проще добиться попадания в кэш. Через APIYI (apiyi.com) можно переключаться между Sonnet и Opus в один клик, избегая ситуации, когда кэширование не работает из-за ограничений модели.
Точки прерывания (breakpoint) и ограничения параллелизма в Claude
Claude позволяет установить до 4 точек прерывания кэширования (cache breakpoint) в одном запросе, причем для каждой можно задать свой TTL. Это мощная функция, отличающая Claude от GPT: вы можете закэшировать «системный промпт» на 1 час, «фрагменты базы знаний» на 5 минут, а «контекст пользователя» не кэшировать вовсе. Все три части тарифицируются и истекают независимо.
Важный нюанс при параллельных запросах: запись в кэш Claude становится доступной для других запросов только после того, как первый запрос начнет возвращать ответ. Если вы отправите N параллельных запросов с одинаковым префиксом, только первый запишет данные в кэш, а остальные N-1 будут тарифицироваться по базовой цене без скидки. Поэтому при массовых вызовах сначала отправьте один запрос для «прогрева» кэша, а затем запускайте остальные параллельно.
🎯 Совет по пакетным вызовам: При работе с Claude через APIYI (apiyi.com) перед запуском параллельной пачки запросов отправьте один «прогревочный» запрос, чтобы инициировать запись в кэш. Как только начнется ответ, можно запускать остальные — это позволит избежать лишних наценок за запись и существенно сэкономить бюджет.
Влияние наценки за запись на реальные счета: расчет точки безубыточности
В этом разделе мы переведем абстрактные коэффициенты в конкретные суммы. Допустим, у нас есть стабильный системный промпт объемом 10 000 токенов, к которому обращаются N раз в течение часа, а объем вывода составляет 500 токенов. Посмотрим на общие затраты для обоих провайдеров при разном N.
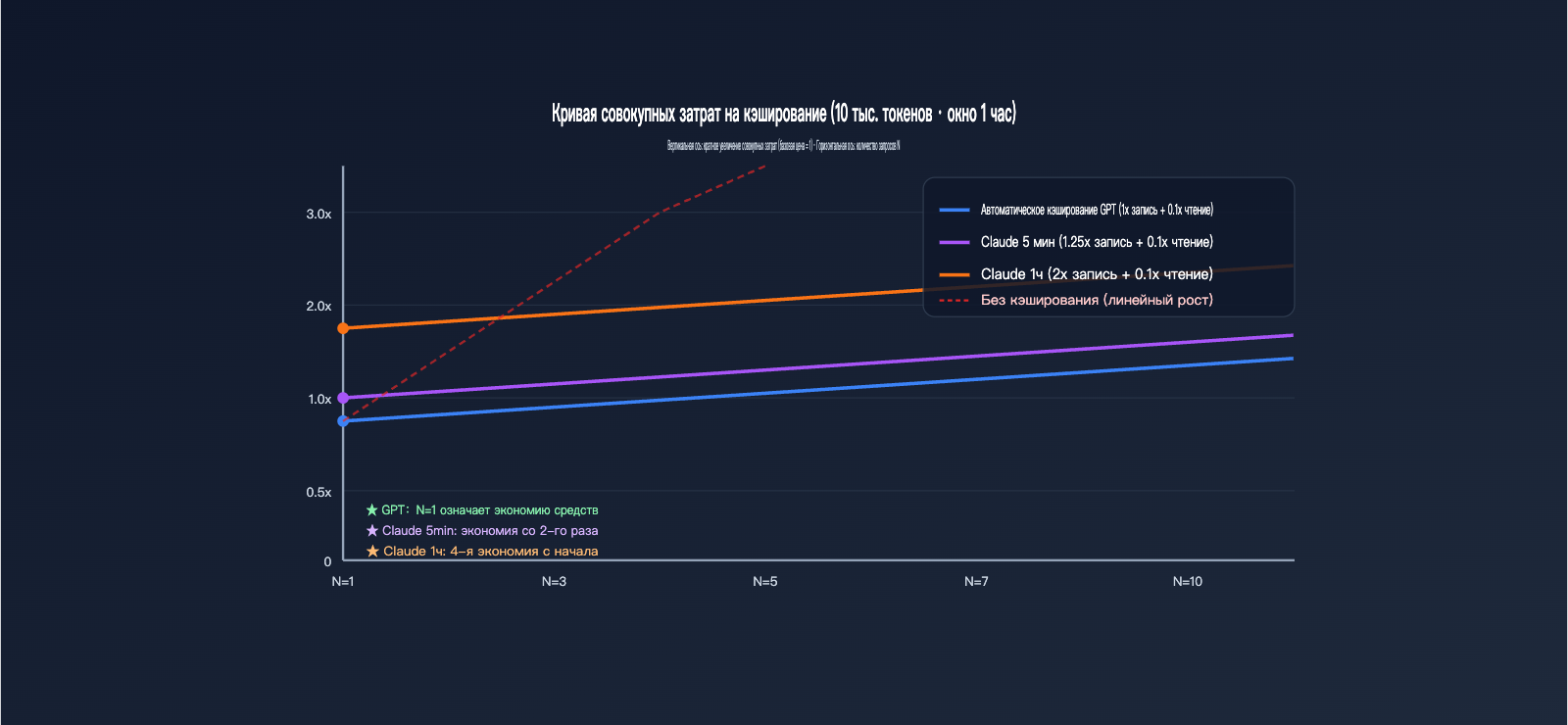
Для удобства сравнения предположим, что базовая цена ввода нормализована до $X/1M токенов. Базовая стоимость 10 000 токенов за один запрос = 10 × $X / 1000 = $0.01X. Ниже мы рассматриваем только часть с кэшированием ввода, игнорируя вывод (вывод считается по стандартным тарифам).
| Количество запросов N | GPT (авто-кэш) | Claude (кэш 5 мин) | Claude (кэш 1 ч) |
|---|---|---|---|
| N=1 (первая запись) | $0.01X | $0.0125X | $0.02X |
| N=2 | $0.011X | $0.0135X | $0.021X |
| N=5 | $0.014X | $0.0165X | $0.024X |
| N=10 | $0.019X | $0.0215X | $0.029X |
| Без кэша (справка) | $0.01X × N | $0.01X × N | $0.01X × N |
| Запросов для окупаемости | 0 (экономия сразу) | 1 (со 2-го раза) | 3 (с 4-го раза) |
Ключевой вывод: кэширование GPT выгодно уже при N=1 — поскольку запись идет по ставке 1x, а при попадании в кэш предоставляется скидка, вы всегда в плюсе. Кэширование Claude на 5 минут требует как минимум одного попадания, чтобы окупить наценку за запись (0.25x), а кэширование на 1 час — трех попаданий. Если ваш стабильный префикс используется всего один раз в день, использование кэша Claude на 1 час обойдется дороже, чем работа без него.
Как выбрать TTL в реальных бизнес-задачах
Наши расчеты дают четкие рекомендации:
- Низкая или нерегулярная частота: используйте авто-кэширование GPT, это самый простой способ сэкономить.
- Высокая частота, много попаданий в течение 5 минут (например, чат-боты поддержки, веб-приложения): кэширование Claude на 5 минут дает максимальную выгоду — небольшая наценка за запись и существенная скидка на чтение.
- Длительные задачи, повторное использование в течение часа (например, Coding Agent, диалоги по длинным документам): кэширование Claude на 1 час оправдано, но только если вы гарантируете минимум 3 попадания.
- Неопределенный коэффициент попаданий: всегда начинайте с 5-минутного TTL, и только после проверки эффективности переходите на 1 час.
🎯 Совет по анализу: В личном кабинете APIYI (apiyi.com) доступна статистика по полю
cached_tokensдля каждого запроса — вы сразу увидите реальный коэффициент попаданий. Рекомендуем прогнать продакшн-трафик в течение недели, прежде чем переходить на агрессивный 1-часовой TTL.
Рекомендации по стратегии кэширования для разных сценариев
Понимая разницу в тарифах, можно эффективно применять кэширование в бизнесе. Ниже приведены рекомендации по стратегиям для типичных сценариев.
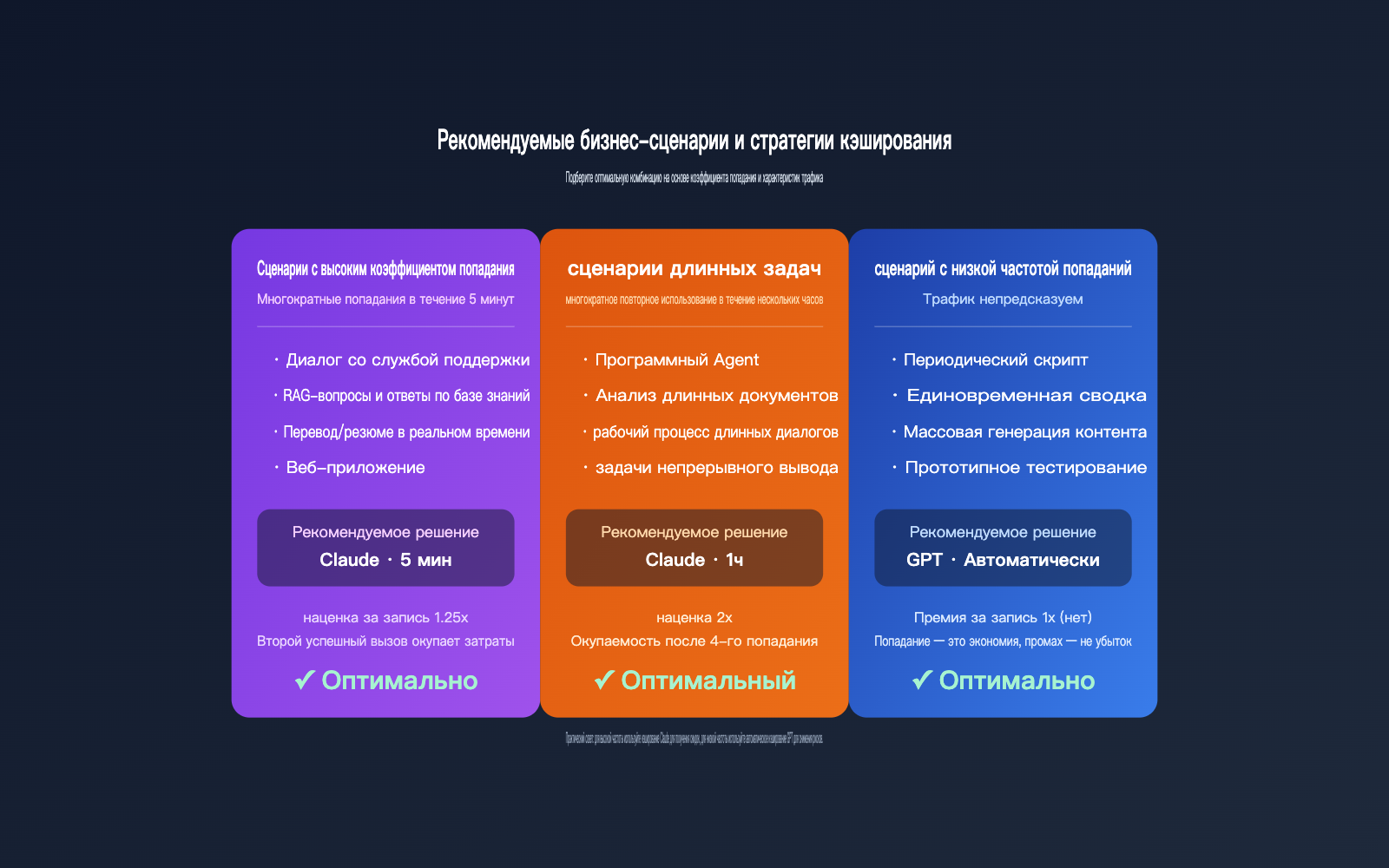
Сценарий 1: Высокочастотный RAG и корпоративные базы знаний
В таких сценариях стабильный префикс обычно содержит системный промпт и фрагменты базы знаний. В рамках одной сессии происходит многократное обращение, и количество запросов за 5 минут легко превышает 10. Кэширование Claude на 5 минут позволяет снизить затраты на ввод более чем на 80%. Для часовых сессий можно рассмотреть 1-часовой кэш.
Сценарий 2: Программирование и Agent-воркфлоу
Для кодинг-агентов (например, Claude Code, OpenCode) задача может длиться от получаса до нескольких часов, в течение которых агент постоянно считывает структуру проекта, файлы типа CLAUDE.md и результаты предыдущих вызовов инструментов. Здесь кэш Claude на 1 час — оптимальный выбор, так как количество попаданий значительно превышает порог окупаемости в 3 запроса.
Сценарий 3: Низкочастотные или непредсказуемые запросы
Например, периодические скрипты, пакетная генерация SEO-статей или разовое резюмирование длинных документов. Интервалы между запросами могут быть намного больше 5 минут. Рекомендуем использовать модели GPT с авто-кэшированием: попадание дает экономию, а отсутствие попадания не несет лишних затрат, что делает этот подход более гибким, чем явное кэширование Claude.
Сценарий 4: Сжатие ввода для экономии
Если ваша цель — максимально снизить стоимость промптов объемом 10K+ токенов, используйте Claude Sonnet 4.6 с 5-минутным кэшем: наценка за запись всего 25%, а для окупаемости достаточно одного попадания. Стоимость чтения снижается до $0.075/1M токенов (базовая $3 × 0.025).
| Бизнес-сценарий | Рекомендуемое семейство моделей | Рекомендуемый TTL | Причина |
|---|---|---|---|
| Поддержка/RAG/Чат | Claude Sonnet | 5 минут | Частые попадания, быстрая окупаемость |
| Программирование/Агенты | Claude Sonnet/Opus | 1 час | Более 3 попаданий в течение часа |
| Скрипты/Пакетная обработка | GPT-4.1 / GPT-5.x | Авто | Нестабильные попадания, нет наценки за запись |
| Разовый анализ документов | GPT-5.x | Авто | Разовая задача, низкий шанс попадания |
| Максимальная экономия | Claude Sonnet 4.6 | 5 минут | Минимальная эффективная цена кэша |
🎯 Совет по архитектуре: В продакшене не обязательно выбирать что-то одно. Используйте единый шлюз APIYI (apiyi.com) для доступа к обеим моделям и динамически маршрутизируйте трафик: высокочастотные запросы — на кэширование Claude, низкочастотные — на авто-кэширование GPT. Это позволит сократить общие расходы более чем на 40%.
Часто задаваемые вопросы (FAQ)
Q1: GPT действительно не берет наценку за запись в кэш? Она не спрятана в других расходах?
Да, в официальной документации OpenAI прямо сказано: «No. Caching happens automatically, with no explicit action needed or extra cost paid to use the caching feature.» Запись в кэш тарифицируется по базовой цене ввода, никаких скрытых наценок нет. Вы платите по сниженной цене только за ту часть, которая попала в кэш (hit), а за непопавшую часть — по базовой цене. По сути, функция кэширования идет «в подарок».
Q2: Наценка Claude 1.25x и 2x за запись считается для всего промпта или только для кэшируемой части?
Только для той части, которая помечена cache_control для кэширования. Например, если из 10К токенов промпта в кэш помечено только 8К, то наценка 1.25x применяется только к этим 8К, а оставшиеся 2К оплачиваются по базовой цене 1x. Поэтому рекомендуем точно настраивать точки останова (breakpoint), чтобы не переплачивать за лишний контент.
Q3: Передает ли сервис-прокси APIYI данные о кэшировании обеих компаний без изменений?
APIYI (apiyi.com) полностью передает данные о кэшировании для GPT и Claude в исходном виде. Скидки за попадание в автоматический кэш GPT, наценка 1.25x/2x за запись и скидка 0.1x за чтение в Claude — всё в счетах полностью соответствует официальным данным. Поле cache_control также поддерживается, поэтому разработчики могут использовать оригинальный код SDK.
Q4: В каких случаях кэширование Claude на 1 час может быть менее выгодным, чем его отсутствие?
Если количество реальных попаданий в кэш в течение часа меньше 3 раз, то наценка за запись (2x) не окупается. Например, если определенный промпт отправляется только при входе пользователя и при выходе (всего 2 раза в день), то использование кэша на 1 час обойдется дороже, чем работа без него, из-за наценки 1x за запись. В таких сценариях лучше либо использовать кэш на 5 минут, либо вовсе его отключить.
Q5: Может ли автоматическое кэширование GPT привести к утечке данных моих промптов?
Документация OpenAI четко указывает, что кэширование изолировано на уровне организации и не является общим для разных аккаунтов. С 5 февраля 2026 года Claude еще больше ужесточил изоляцию до уровня рабочего пространства (workspace-level). Обе компании придерживаются схожих стандартов безопасности данных, поэтому корпоративные пользователи могут быть спокойны. При подключении через APIYI (apiyi.com) изоляция на уровне токенов дополнительно усиливает эту защиту.
Q6: Как отслеживать коэффициент попаданий в кэш? Есть ли у обеих компаний соответствующие поля?
OpenAI возвращает поле cached_tokens в объекте usage, а Claude — поля cache_creation_input_tokens и cache_read_input_tokens. Первое показывает объем записи в кэш, второе — объем попаданий. Рекомендуем записывать эти поля в бизнес-логи, чтобы построить дашборд эффективности и на основе этого корректировать стратегию TTL.
Q7: Если проект использует и GPT, и Claude, как лучше настроить токены?
Рекомендуем использовать единую систему токенов от APIYI (apiyi.com): один ключ sk-xxx для доступа и к GPT, и к Claude. В личном кабинете можно просматривать расходы по каждой модели отдельно, что избавляет от необходимости заводить разные аккаунты, управлять балансами и сводить счета в разных местах. Такое унифицированное подключение также упрощает A/B-тестирование для сравнения реальной стоимости работы обеих моделей в рамках одной задачи.
Итог: понимание наценки за запись — первый шаг к оптимизации кэша
Возвращаясь к главному тезису статьи: фундаментальное различие в тарификации кэша GPT и Claude заключается в модели наценки на запись. GPT выбрал путь «нулевого трения и автоматического включения без наценки за запись», а Claude — путь «явного контроля и обмена наценки за запись на более гибкие условия скидок». У обеих моделей нет явного преимущества, главное — соответствие характеристикам вашего трафика.
Если ваше приложение работает с высокой частотой попаданий, стабильным трафиком и требует точного контроля, наценка Claude (1.25x / 2x) легко окупается за счет высокой доли попаданий, а двойной TTL (5 мин / 1 час) дает гибкость, которой нет у GPT. Если же ваше приложение характеризуется редкими попаданиями, скачкообразным трафиком и требует простоты «из коробки», модель автоматического кэширования GPT без наценок — самый надежный выбор.
🎯 Финальный совет: лучшая практика оптимизации затрат — не выбирать что-то одно. Рекомендуем подключать обе модели через APIYI (apiyi.com) и маршрутизировать запросы в зависимости от сценария: высокочастотные — через кэш Claude для получения скидок, низкочастотные — через автоматический кэш GPT для минимизации рисков. Один ключ, один счет, удобное сравнение — это самый эффективный подход к управлению затратами для технических команд в 2026 году.
— Техническая команда APIYI | Мы продолжаем следить за изменениями в тарификации больших языковых моделей. Больше глубоких сравнений — в центре помощи APIYI (apiyi.com).