Один из пользователей при вызове gpt-image-2 столкнулся с ошибкой, которая с момента запуска модели в апреле 2026 года стала одной из самых частых в среде разработчиков:
{
"status_code": 400,
"error": {
"message": "Your request was rejected by the safety system. ... safety_violations=[violence].",
"type": "shell_api_error",
"code": "moderation_blocked"
}
}
Первая реакция многих — «просто добавлю повторную попытку (retry)». Но это ошибочный подход — один и тот же промпт будет блокироваться и со 100-й попытки. Суть ошибки moderation_blocked в gpt-image-2 заключается в том, что запрос даже не доходит до модели: его блокирует превентивный фильтр безопасности. Повторные попытки — это просто пустая трата времени.
В этой статье мы разберем этот реальный кейс, детально рассмотрим механизм проверки безопасности gpt-image-2 (включая двухэтапную архитектуру фильтрации), 7 основных сценариев срабатывания, 5 стратегий оптимизации промптов и инженерные практики для снижения частоты ошибок в продакшене. После прочтения вы сможете провести аудит своих шаблонов промптов и снизить уровень нарушений более чем на 80%.

Разбор сути ошибки moderation_blocked в gpt-image-2
Чтобы решить эту проблему, нужно сначала понять, что она из себя представляет. Многие разработчики воспринимают это как «модель отказалась отвечать», но это совсем не так.
Ключевые факты об ошибке moderation_blocked в gpt-image-2
| Факт | Описание | Инженерный смысл |
|---|---|---|
| HTTP 400 (client-side) | Ошибка на уровне запроса, не сбой сервера | Повтор не поможет, нужно менять промпт |
| Запрос не дошел до модели | Перехвачен превентивным классификатором | Оплата не списывается, токены не тратятся |
code=moderation_blocked |
Стандартизированный код ошибки | Подходит для автоматизированных пайплайнов |
safety_violations=[…] |
Список категорий нарушений | Позволяет точно определить, что исправить |
| 100% воспроизводимость | Результат детерминирован, не случайность | Нужно изменить промпт для успеха |
Двухэтапный механизм проверки безопасности gpt-image-2
Чтобы понять ошибку gpt-image-2, нужно разобраться в двухэтапной архитектуре фильтрации OpenAI.
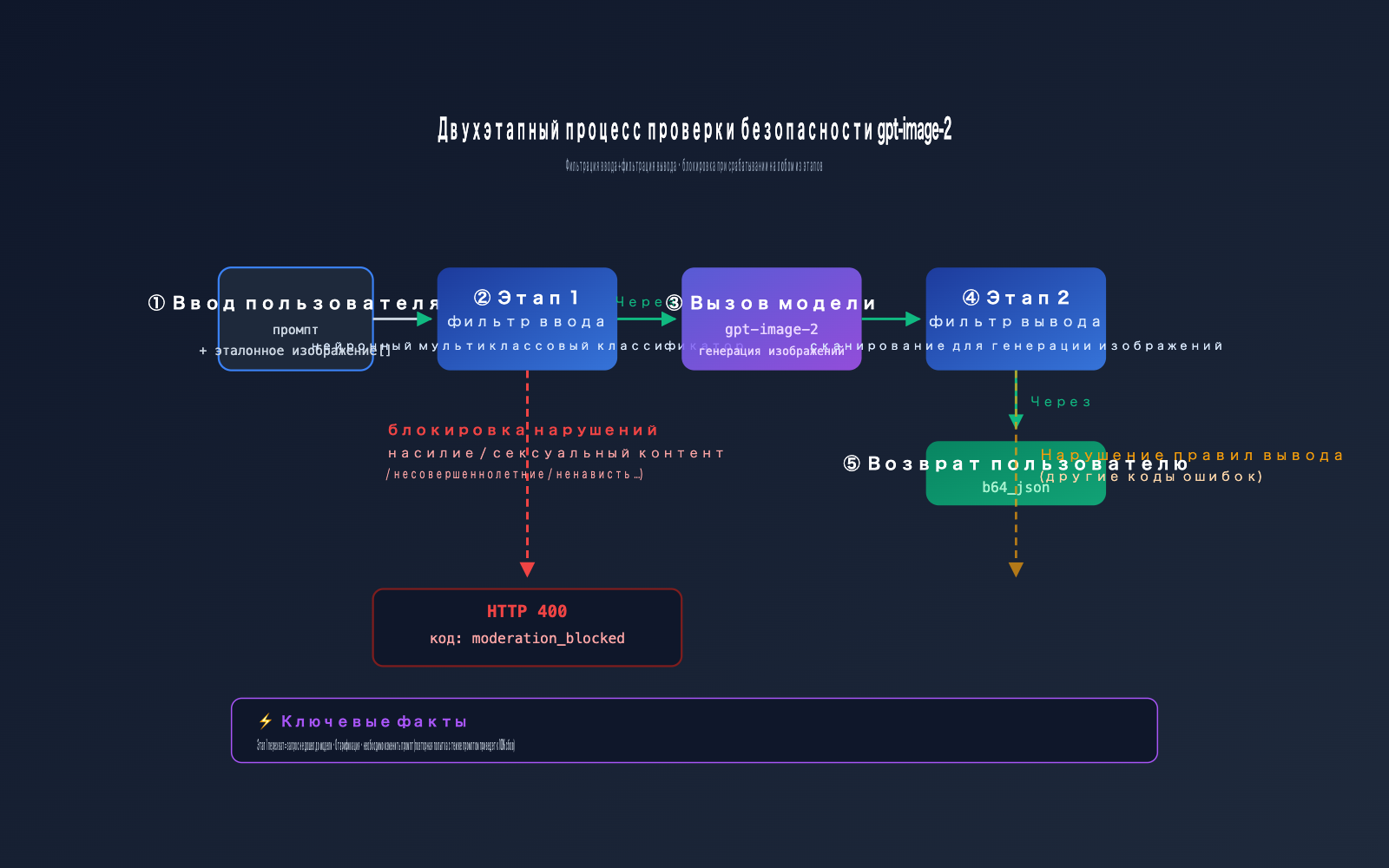
Вся цепочка безопасности фактически состоит из двух барьеров:
Stage 1 · Input Filter (Входной фильтр):
- Сканирует текст вашего промпта.
- Сканирует все загруженные эталонные изображения (если вы вызываете
/v1/images/edits). - Использует нейронный классификатор (multi-class neural classifier).
- Именно здесь срабатывает
moderation_blocked.
Stage 2 · Output Filter (Выходной фильтр):
- Сканирует уже сгенерированные моделью изображения.
- Если контент нарушает правила, он все равно может быть заблокирован.
- Обычно возвращает другой код ошибки (не
moderation_blocked).
Кейс пользователя вызван входным фильтром Stage 1, поэтому запрос даже не дошел до стадии генерации. Это объясняет, почему ответ приходит так быстро (обычно < 1 сек) — запрос не вставал в очередь и не занимал GPU.
Различия в бэкендах при ошибках gpt-image-2
Факт, который часто упускают: строгость фильтрации зависит от канала. При использовании прямого API OpenAI и Azure OpenAI частота срабатывания фильтров на один и тот же промпт может существенно различаться, причем Azure обычно строже. Именно поэтому в сообщении об ошибке пользователя упоминается «contact us at Azure support ticket» — запрос был направлен через фильтр бэкенда Azure.
🎯 Совет по выбору канала: Если вы тестируете один и тот же промпт через разные каналы, то ситуация, когда одни блокируют, а другие пропускают — это норма. Мы рекомендуем использовать официальный прокси-канал OpenAI через APIYI (apiyi.com) для проверки: он использует официальные политики фильтрации OpenAI, что позволяет проводить корректное сравнение с прямым доступом.
Полный обзор 7 сценариев, вызывающих ошибки в gpt-image-2
Компания OpenAI в официальном системном отчете ChatGPT Images 2.0 четко выделила 7 категорий сценариев, которые чаще всего приводят к срабатыванию фильтров. Понимание этих категорий — основа для создания корректных промптов.

Таблица соответствий сценариев ошибок gpt-image-2
| Категория | Примеры триггерных слов | Уровень риска |
|---|---|---|
| Violence (Насилие) | fight, war, weapon, blood, shoot, punch, kill | 🔴 Высокий |
| Violence/Graphic (Жестокое насилие) | gore, gruesome, mutilation, severed | 🔴 Экстремальный |
| Sexual (Сексуальный контент) | nude, explicit, suggestive, intime poses | 🔴 Экстремальный |
| Hate Symbols (Символы ненависти) | swastika, специфическая экстремистская символика | 🔴 Экстремальный |
| Self-harm (Самоповреждение) | suicide, cut wrists, harming oneself | 🔴 Экстремальный |
| Minors (Изображение несовершеннолетних) | комбинация child + photorealistic | 🟡 Средний-Высокий |
| Public Figures (Публичные личности) | политики, имена знаменитостей | 🟡 Средний |
| Copyrighted IP (Авторские права) | персонажи Disney, Marvel, известные бренды | 🟡 Средний |
| Living Artists (Стиль ныне живущих художников) | "in the style of [имя художника]" | 🟡 Средний |
Разбор подкатегорий насилия в gpt-image-2
Параметр safety_violations=[violence] на самом деле охватывает две подкатегории, которые многие часто путают:
violence → Общее описание насилия (действия, конфликты, наличие оружия)
violence/graphic → Графическое, кровавое описание деталей насилия
Если ваш промпт активирует хотя бы одну из этих подкатегорий, система вернет safety_violations=[violence]. Это означает, что даже если вы просто пишете что-то относительно нейтральное, например «a soldier with a rifle» (солдат с винтовкой), классификатор может пометить весь промпт как «насилие» из-за общего контекста.
Глубокий разбор пользовательских кейсов: причины ошибок с флагом violence
Вернемся к ошибке, упомянутой в начале. Поле safety_violations=[violence] прямо указывает на срабатывание фильтра по категории «насилие». Но какое именно слово стало триггером? Ниже представлена систематизированная методика диагностики.
Список триггеров для ошибки violence в gpt-image-2
Основываясь на отзывах сообщества и тестировании, следующие слова значительно повышают вероятность блокировки по категории violence (список не исчерпывающий):
| Тип триггера | Часто блокируемые слова | Безопасные альтернативы |
|---|---|---|
| Оружие | gun, rifle, sword, knife, weapon | ceremonial prop, movie prop, decorative blade |
| Агрессивные действия | fight, attack, shoot, stab, punch | dynamic cinematic action, dramatic standoff |
| Военный контекст | war, battle, soldier, combat | heroic struggle, historical reenactment |
| Кровь/травмы | blood, wound, scar, gore | red splatter, dramatic shadow, weathered |
| Взрывы/разрушения | explosion, destruction, debris | dramatic light burst, swirling particles |
Процесс диагностики ошибки в gpt-image-2
Если ваш промпт вызвал блокировку по категории violence, пройдите по этому чек-листу:
- Проверка на явные слова-триггеры: просканируйте промпт на наличие слов из таблицы выше.
- Проверка интенсивности глаголов: попробуйте заменить глаголы действия (fight, attack) на описание состояния.
- Проверка эталонного изображения (для сценариев редактирования): содержит ли само загруженное изображение элементы насилия?
- Проверка общего контекста: даже без отдельных «опасных» слов, общий смысл сцены может быть расценен как насильственный.
- Добавление рамочного контекста: добавьте в начало промпта фразы вроде "movie still" или "theatrical scene".
Зачем нужен ID запроса при ошибке gpt-image-2?
ID запроса (например, request id: 2026042723155331083492939703753) — это не просто набор символов, а уникальный ключ для поиска в логах. Если вы работаете через официальные каналы, этот ID поможет техподдержке платформы точно определить причину блокировки.
💡 Совет по диагностике: сохраняйте все ID запросов с ошибкой
moderation_blockedи соответствующие промпты. Создайте внутреннюю «базу примеров нарушений» для обучения правил автоматического переписывания. Рекомендуем экспортировать логи запросов через консоль APIYI (apiyi.com) для проведения ежемесячного аудита и выявления наиболее частых паттернов блокировок в вашей команде.
5 стратегий оптимизации промптов для устранения ошибок gpt-image-2
Ниже приведены 5 проверенных на практике стратегий снижения частоты ошибок gpt-image-2. Приоритет — от высокого к низкому, рекомендуем применять их по порядку.
Стратегия 1: Десенсибилизация (переписывание промпта)
Это самый эффективный и часто используемый метод — замена высокорискованных слов на нейтральные описания, сохраняющие визуальный эффект. Главный принцип: сохранить визуал, убрать агрессивный подтекст.
# ✗ Вызывает блокировку violence
- "Two warriors fighting with swords, blood splatter on the ground, war scene"
# ✓ После десенсибилизации проходит проверку
+ "Two armored figures in dramatic standoff with ceremonial blades, red light reflections on the stone floor, cinematic composition, theatrical scene"
Что изменилось:
fighting→dramatic standoffswords→ceremonial bladesblood splatter→red light reflectionswar scene→theatrical scene
Стратегия 2: Замена реальных субъектов
Избегайте прямого упоминания реальных публичных личностей или защищенных авторским правом персонажей. Используйте описание визуальных характеристик.
# ✗ Вызывает блокировку public_figures или copyrighted_ip
- "A portrait of [Имя звезды] in business suit"
- "Mickey Mouse riding a bicycle in Paris"
# ✓ Безопасное описание
+ "A portrait of a charismatic 30-year-old Asian businesswoman with shoulder-length black hair, wearing a tailored navy suit"
+ "A friendly anthropomorphic mouse character with round black ears and red shorts, riding a bicycle near the Eiffel Tower"
Примечание: полное описание стиля все равно может вызвать блокировку для защищенных персонажей, так как фильтр оценивает визуальное сходство, а не только текст. Рекомендуем добавлять достаточно «оригинальных» черт.
Стратегия 3: Указание рамочного контекста
Добавьте в начало промпта четкий художественный или творческий контекст, чтобы показать классификатору, что это искусство, а не реальность.
- "Soldiers running across a battlefield"
+ "Movie still from a 1940s war drama: soldiers running across a foggy field, sepia tones, film grain texture"
- "Action scene with gunfire"
+ "Video game cutscene illustration: heroic action sequence with stylized energy effects, comic book style"
Полезные «рамочные» слова:
movie still/film stilltheatrical scene/stage performancevideo game cutscene/game illustrationcomic book panel/manga stylehistorical reenactment/museum dioramaoil painting/watercolor sketch
Стратегия 4: Поэтапная генерация
Сложные и высокорискованные сцены можно разбить на несколько этапов:
# Шаг 1: Генерация "эталонного изображения стиля" (без чувствительных элементов)
step1_prompt = "Cinematic storyboard sketch, dramatic composition, sepia tones, no text"
style_ref = client.images.generate(model="gpt-image-2", prompt=step1_prompt)
# Шаг 2: Генерация итогового изображения с описанием стиля + нейтральным контентом
step2_prompt = "Two figures in dramatic standoff, sepia tones, cinematic storyboard style, dust particles in the air"
final_image = client.images.generate(model="gpt-image-2", prompt=step2_prompt)
Такой рабочий процесс «сначала стиль, потом контент» значительно снижает чувствительность промпта.
Стратегия 5: Настройка параметра moderation
API позволяет управлять чувствительностью фильтра через параметр moderation (доступно только для моделей OpenAI):
response = client.images.generate(
model="gpt-image-2",
prompt="A dramatic action scene from a noir film",
moderation="low", # По умолчанию auto, можно снизить до low
size="1024x1024",
quality="medium"
)
Важное напоминание:
moderation: "low"не отключает проверку, а лишь расширяет допустимые границы.- Экстремально опасный контент (сексуальный подтекст, селфхарм, реалистичные изображения несовершеннолетних, символика ненависти) будет заблокирован даже при значении
low. - Если после установки
lowвы все равно получаетеmoderation_blocked, значит, контент действительно переходит черту — промпт нужно менять. - В продуктах для конечных пользователей используйте
lowс осторожностью (риски комплаенса).
🚀 Совет для быстрого старта: стратегии 1-3 (переписывание + замена + рамочный контекст) решают более 80% ошибок
moderation_blocked. Рекомендуем использовать единый интерфейс APIYI (apiyi.com) для проверки промптов с параметромmoderation: auto, прежде чем принимать решение о снижении настроек доlow.
Сравнительный анализ оптимизации ошибок в gpt-image-2
Ниже приведены 4 реальных сценария, демонстрирующих, как именно оптимизация промпта влияет на результат.

Пример 1: Кинопостер
# ✗ До оптимизации (срабатывает фильтр violence)
- "An action movie poster featuring a male hero firing a gun at enemies, blood splatter background"
# ✓ После оптимизации
+ "Cinematic action movie poster: a male protagonist in dramatic pose, holding a stylized prop, dynamic motion lines, red gradient background, theatrical lighting, film grain"
Пример 2: Игровой персонаж
# ✗ До оптимизации (срабатывает фильтр violence)
- "Fantasy warrior with bloody sword, severed enemy head at his feet, gore details"
# ✓ После оптимизации
+ "Fantasy warrior video game character art: armored figure with ornate ceremonial blade, defeated stylized monster silhouette at his feet, JRPG illustration style, painterly textures"
Пример 3: Историческая иллюстрация
# ✗ До оптимизации (срабатывает фильтр violence)
- "World War II soldiers fighting in trenches with rifles and explosions"
# ✓ После оптимизации
+ "Historical educational illustration depicting a 1940s European trench scene: figures in period uniforms, weathered terrain with dramatic atmospheric effects, sepia documentary style, museum diorama aesthetic"
Пример 4: Рекламный концепт
# ✗ До оптимизации (срабатывает фильтр public_figures)
- "[Имя знаменитости] holding our coffee product in his usual style"
# ✓ После оптимизации
+ "Charismatic 35-year-old male model with confident smile, casual blazer, warmly holding a takeaway coffee cup, modern minimalist café background, professional commercial photography"
Лучшие практики инженерного решения проблем с ошибками gpt-image-2
Если ваш проект выполняет тысячи вызовов gpt-image-2 ежедневно, ручная проверка каждого промпта становится невозможной. Вот несколько инженерных подходов, которые помогут снизить частоту ошибок при работе с gpt-image-2.
Процесс предварительной проверки для gpt-image-2
Перед отправкой запроса к API генерации изображений выполните предварительную проверку с помощью Moderations API:
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("APIYI_KEY"),
base_url="https://api.apiyi.com/v1"
)
def safe_generate(prompt: str, max_rewrites: int = 3):
# Шаг 1: Предварительная проверка
mod = client.moderations.create(input=prompt)
flagged = mod.results[0].flagged
categories = mod.results[0].categories
if flagged:
offending = [k for k, v in categories.model_dump().items() if v]
raise ValueError(f"Промпт вызвал срабатывание фильтра: {offending}")
# Шаг 2: Фактический вызов
return client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1024",
quality="medium"
)
Предварительная проверка позволяет отсеять 60–70% высокорисковых запросов, предотвращая бесполезные вызовы.
Конвейер автоматического переписывания промптов для gpt-image-2
Для шаблонов промптов в производственной среде можно создать легковесный рерайтер:
SENSITIVE_REPLACEMENTS = {
r"\bgun\b": "ceremonial prop",
r"\bsword\b": "ornate ceremonial blade",
r"\bblood\b": "red splatter",
r"\bfight\b": "dramatic standoff",
r"\bwar\b": "heroic struggle",
r"\battack\b": "dynamic motion",
r"\bweapon\b": "stylized prop",
r"\bkill\b": "defeat",
r"\bshoot\b": "aim",
}
import re
def desensitize(prompt: str) -> str:
out = prompt
for pattern, replacement in SENSITIVE_REPLACEMENTS.items():
out = re.sub(pattern, replacement, out, flags=re.IGNORECASE)
if not out.lower().startswith(("movie still", "video game", "theatrical")):
out = "Cinematic movie still: " + out
return out
Интеллектуальная инкапсуляция повторных попыток для gpt-image-2
Стратегия повторных попыток при ошибке moderation_blocked — нельзя повторять запрос в исходном виде, необходимо сначала переписать промпт:
from openai import BadRequestError
def generate_with_rewrite(prompt: str, max_attempts: int = 3):
current = prompt
for attempt in range(max_attempts):
try:
return client.images.generate(
model="gpt-image-2",
prompt=current,
size="1024x1024"
)
except BadRequestError as e:
if "moderation_blocked" not in str(e):
raise # Другие ошибки 400 не нужно повторять
print(f"[{attempt+1}/{max_attempts}] Сработал фильтр, применяем десенсибилизацию...")
current = desensitize(current)
if attempt == max_attempts - 1:
# В последней попытке добавляем moderation: low
return client.images.generate(
model="gpt-image-2",
prompt=current,
moderation="low",
size="1024x1024"
)
raise RuntimeError("Все стратегии переписывания промпта не удались")
Мониторинг соответствия требованиям для gpt-image-2
В производственной среде необходимо фиксировать ключевые показатели нарушений:
| Показатель | Назначение |
|---|---|
| Уровень нарушений (блокировки/всего запросов) | Общее состояние системы |
Распределение по категориям safety_violations |
Выявление самых частых типов нарушений |
| Топ-10 промптов, вызвавших нарушения | Оптимизация проблемных шаблонов |
| Уровень прохождения после переписывания | Оценка эффективности рерайтера |
🎯 Рекомендация по развертыванию: Считайте уровень нарушений ключевым показателем SLO. Для здоровой системы он должен быть < 2%, а значение > 5% указывает на системные проблемы в шаблонах промптов. Мы рекомендуем использовать логи запросов в консоли APIYI (apiyi.com) для ежедневного анализа и выявления шаблонов, требующих корректировки.
Часто задаваемые вопросы (FAQ) по ошибкам gpt-image-2
Q1: Списываются ли средства при ошибке moderation_blocked в gpt-image-2?
Нет. Система безопасности блокирует запрос до того, как он доходит до модели, поэтому токены или время GPU не расходуются. OpenAI и APIYI придерживаются этого правила. Если вы видите списания в счете, немедленно свяжитесь с платформой для проверки. Рекомендуем сверять записи о списаниях по каждому request_id в консоли APIYI (apiyi.com), чтобы убедиться в нулевой тарификации заблокированных запросов.
Q2: Почему повторный вызов с тем же промптом при ошибке gpt-image-2 не помогает?
Потому что классификатор безопасности детерминирован — результат классификации для одного и того же ввода стабилен, в отличие от генеративных моделей, где есть элемент случайности. 100 повторных попыток дадут 100 одинаковых блокировок. Единственное решение — изменить промпт.
Q3: Может ли параметр moderation: low полностью отключить проверку?
Нет. low лишь снижает порог чувствительности, допуская более мягкую фильтрацию контента средней чувствительности, но экстремально опасный контент (сексуальный подтекст, селфхарм, реалистичные изображения несовершеннолетних, символы ненависти, политические лидеры и т.д.) будет заблокирован даже при low. Считать low «выключателем» — ошибочное мнение.
Q4: Почему мой промпт выглядит безобидным, но его все равно блокируют?
Есть три причины:
- Контекст в целом нарушает правила: отдельные слова безобидны, но их комбинация создает запрещенный сценарий.
- Многозначность слов: например, "shoot a photo" может быть ошибочно принят за призыв к насилию.
- Различия в бэкендах: бэкенд Azure работает строже, чем прямое подключение к OpenAI.
Для второго случая помогает добавление контекстной рамки (например, "professional photography session"). Рекомендуем сохранять такие "ложные срабатывания" в свою внутреннюю базу знаний через APIYI (apiyi.com) и использовать их для итеративного улучшения шаблонов промптов.
Q5: Можно ли узнать, какое именно слово вызвало ошибку gpt-image-2?
API не возвращает конкретное слово-триггер, только категорию (например, [violence]). Это осознанное решение OpenAI, чтобы предотвратить создание «инструкций по обходу». Чтобы найти конкретное слово, используйте метод бинарного поиска: разделите промпт на две части и протестируйте их по отдельности.
Q6: Что делать, если ошибка gpt-image-2 возникает при использовании эталонного изображения (сценарий редактирования)?
Эндпоинт /v1/images/edits на первом этапе сканирует и текстовый промпт, и все загруженные эталонные изображения. Если нарушением является само изображение:
- Проверьте, нет ли на нем элементов насилия, сексуального подтекста или защищенных авторским правом персонажей.
- Предварительно обработайте изображение локальными инструментами (кадрирование, размытие чувствительных зон).
- Если это фотография реального человека, убедитесь, что она не нарушает политику в отношении публичных личностей.
Q7: Совпадают ли категории нарушений gpt-image-2 с категориями Moderations API?
В основном да, но есть различия. Категории в Moderations API более детализированы (11 категорий), в то время как фильтры генерации изображений имеют более крупную зернистость (7–9 категорий). Используйте Moderations API для предварительной проверки, но не считайте результаты полностью идентичными — иногда промпт, прошедший через Moderations, может быть заблокирован на стороне генерации изображений.
Q8: Можно ли подать апелляцию на ошибку gpt-image-2?
Можно, но эффект ограничен. request_id из сообщения об ошибке можно использовать для обращения в техподдержку платформы. Практический совет: если это ложное срабатывание (например, нейтральный контент для медицины или образования), платформу могут внести в белый список; если же правила действительно нарушены, апелляция не поможет. Рекомендуем при подаче заявки через систему тикетов APIYI (apiyi.com) прикладывать полный request_id и описание бизнес-сценария для повышения эффективности обработки.
Итоги: от ошибок gpt-image-2 к эффективным и безопасным промптам
Пройдя через 7 разделов этой статьи, вы теперь полностью владеете системой обработки ошибок gpt-image-2:
- ✅ Понимание сути —
moderation_blocked— это ошибка 400 на уровне запроса, которая не тарифицируется и не требует повторных попыток. - ✅ Архитектура — двухэтапная проверка безопасности (Этап 1: фильтрация входных данных + Этап 2: фильтрация выходных данных).
- ✅ Сценарии срабатывания — 7 основных категорий нарушений + детали подкатегорий насилия.
- ✅ Диагностика нарушений — точное определение причины через поле
safety_violations. - ✅ 5 стратегий оптимизации — смягчение формулировок, замена объектов, декларация контекста, декомпозиция на шаги и использование параметров модерации.
- ✅ Инженерные решения — предварительная проверка, автоматическая переработка промптов, интеллектуальные повторные попытки и мониторинг соответствия требованиям.
Самый важный вывод: ошибка moderation_blocked в gpt-image-2 — это не баг, а граница соответствия требованиям продукта. Вместо того чтобы жаловаться на излишнюю строгость, лучше воспринимать «инжиниринг безопасных промптов» как производственный навык — это одна из ключевых компетенций для внедрения AI-продуктов в B2C-сегменте.
Если ваша команда сталкивается с частыми ошибками moderation_blocked, вам нужно выстроить процесс аудита промптов для производственной линии или вы хотите снизить уровень нарушений с помощью инженерных решений, рекомендуем подать заявку на тестовый API-ключ через APIYI (apiyi.com) и протестировать наши шаблоны кода для предварительной проверки и автоматической переработки промптов. Все примеры основаны на официальном SDK и канале APIYI (поля на 100% соответствуют OpenAI), что обеспечивает высокую универсальность и возможность прямого использования в ваших проектах.
Справочные материалы
-
OpenAI ChatGPT Images 2.0 System Card: официальная документация по политике безопасности и механизмам блокировки.
- Ссылка:
deploymentsafety.openai.com/chatgpt-images-2-0/live-blocking - Описание: содержит информацию об архитектуре двухэтапной фильтрации и полный список категорий нарушений.
- Ссылка:
-
Документация OpenAI Moderations API: официальное руководство по инструментам предварительной проверки.
- Ссылка:
developers.openai.com/api/docs/guides/moderation - Описание: 11 категорий нарушений и методы вызова API.
- Ссылка:
-
Политика использования OpenAI (OpenAI Usage Policies): авторитетный источник правил использования.
- Ссылка:
openai.com/policies/usage-policies/ - Описание: запрещенные виды использования, ответственность и требования к соблюдению правил.
- Ссылка:
-
Руководство по промптам для моделей генерации изображений OpenAI: официальные рекомендации по написанию промптов.
- Ссылка:
developers.openai.com/cookbook/examples/multimodal/image-gen-models-prompting-guide - Описание: содержит примеры написания безопасных промптов.
- Ссылка:
-
Документация по подключению APIYI gpt-image-2: полное руководство на китайском языке.
- Ссылка:
docs.apiyi.com/api-capabilities/gpt-image-2/overview - Описание: содержит подробное описание параметров модерации и обработки кодов ошибок.
- Ссылка:
Автор: Техническая команда APIYI
Дата публикации: 27 апреля 2026 г.
Ключевые слова: ошибка gpt-image-2, moderation_blocked, safety_violations, контент-модерация, оптимизация промптов, APIYI, соответствие требованиям OpenAI