Recentemente, recebi uma consulta muito comum: um usuário quer "destilar" centenas de milhares de palavras de um escritor experiente para servir como base de estilo para um Modelo de Linguagem Grande, mas não sabe qual é a forma mais econômica de inserir esse corpus em Markdown. As três abordagens mais comuns são: enviar os arquivos um a um para ferramentas de chat como o Cherry Studio, usar MCP para que o modelo acesse diretamente os arquivos no disco rígido ou colocar tudo em uma base de conhecimento para RAG. À primeira vista, todas parecem funcionar, mas quando o volume de dados ultrapassa 300 mil palavras, a conta de tokens e a latência divergem rapidamente, e escolher a estratégia errada pode facilmente custar dez vezes mais caro.
Este artigo vai dissecar quatro soluções principais para economizar tokens ao alimentar um Modelo de Linguagem Grande com corpus em Markdown: consumo real de tokens, custo por tarefa, latência do primeiro token, controlabilidade e a melhor escolha para diferentes escalas de dados. Por fim, apresentarei um caminho de decisão faseado — o que usar na exploração inicial e o que adotar após a escala. Se você está trabalhando com destilação de estilo, perguntas e respostas em bases de conhecimento ou limpeza de dados antes do ajuste fino (fine-tuning), após a leitura, você poderá tomar uma decisão prática e imediata.
I. O problema central da economia de tokens com corpus Markdown em Modelos de Linguagem Grande
Antes de decompor as soluções, vamos esclarecer onde reside o custo real. Alimentar centenas de milhares de palavras em Markdown para um Modelo de Linguagem Grande envolve, essencialmente, equilibrar quatro tipos de custos: tokens de entrada, tokens de saída, custos de recuperação/indexação e custos de depuração humana.
Os tokens de entrada são o item mais subestimado. Se um blog técnico estiver em formato HTML original, convertê-lo para Markdown geralmente economiza de 70% a 80% dos tokens, pois tags, estilos e scripts embutidos são removidos. É por isso que o primeiro passo de qualquer pipeline que processa grandes volumes de dados é padronizar o conteúdo para Markdown ou txt. Ao fazer isso bem, a linha de base de custo de qualquer método de entrada subsequente cairá um degrau.
Os tokens de saída parecem irrelevantes, mas em tarefas de "destilação", eles são, na verdade, um gargalo oculto. O Claude Sonnet e o Opus já tornaram a janela de contexto de 1 milhão de tokens um padrão de precificação (Sonnet a US$ 3/M, Opus a US$ 5/M de entrada). Teoricamente, você pode inserir centenas de milhares de palavras de uma vez, mas a saída máxima de uma única resposta ainda é de apenas algumas dezenas de milhares de tokens, o que significa que você não pode concluir uma reescrita completa com uma única invocação. A tarefa deve ser fatiada, o que também determina diretamente que scripts de processamento em lote são geralmente mais adequados para cenários de escala do que o chat interativo.
🎯 Sugestão de preparação antes da seleção: Antes de escolher uma solução, faça um tratamento de dessensibilização e normalização de formato em todos os arquivos Markdown. Recomendamos usar a plataforma APIYI (apiyi.com) para testar amostras em pequenos lotes, confirmar o consumo real de tokens por mil palavras e, só então, decidir entre usar ferramentas de chat ou scripts de processamento em lote, evitando que os custos fiquem fora de controle posteriormente.
2. As principais diferenças e limites de aplicação das 4 abordagens
Cada uma das quatro abordagens possui limites de capacidade bem definidos. Entender essas diferenças é muito mais importante do que decorar parâmetros técnicos.
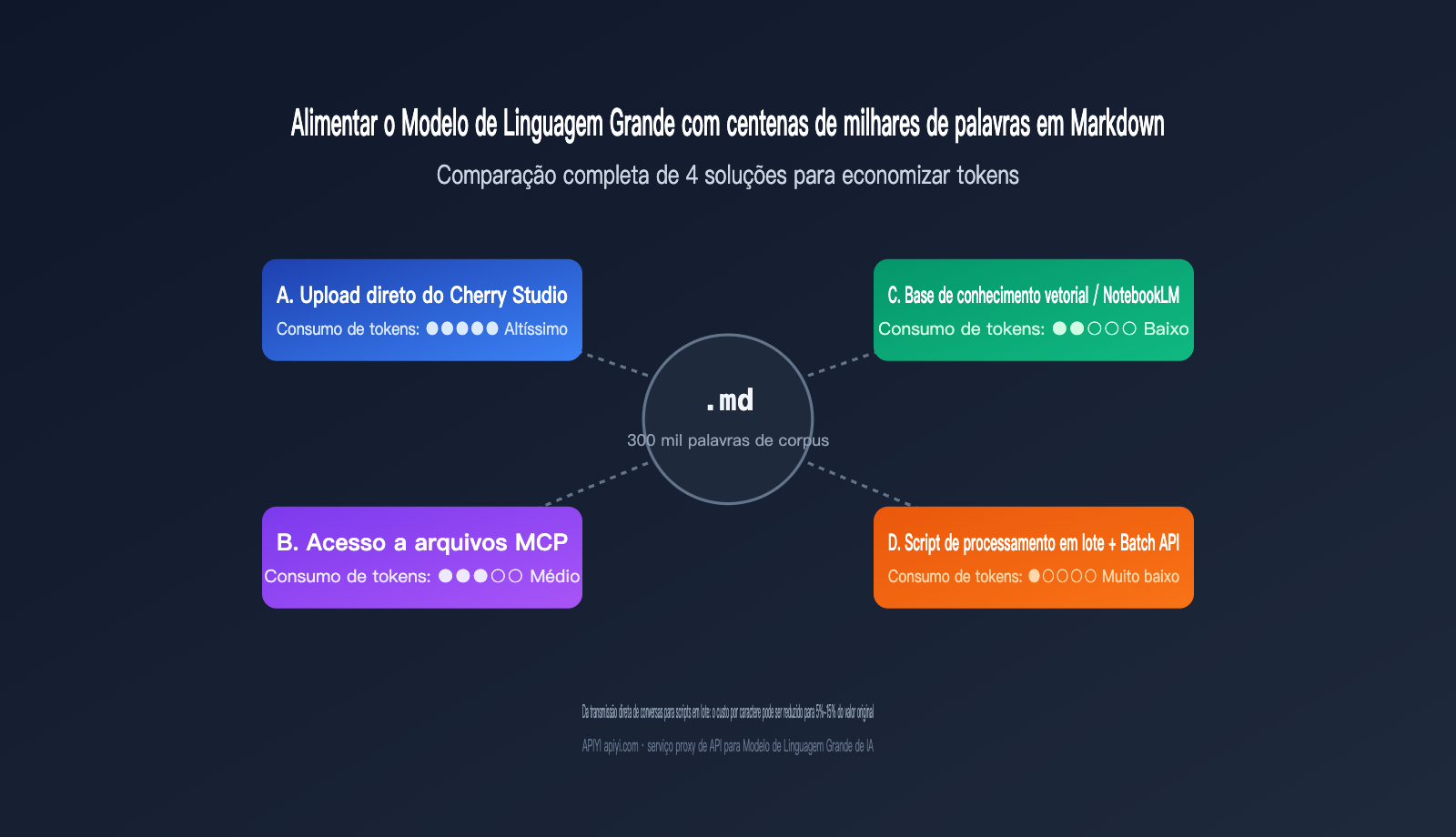
2.1 Abordagem A: Upload direto em ferramentas de chat como o Cherry Studio
Esta é a forma com a barreira de entrada mais baixa. Ferramentas como Cherry Studio, Claude Desktop e ChatGPT permitem que você arraste vários arquivos Markdown diretamente para a caixa de diálogo, e o modelo combina todo o conteúdo em um longo comando para processamento. A vantagem é a engenharia zero e o resultado imediato; a desvantagem é que, a cada nova sessão, é preciso "alimentar" o modelo novamente, o que gera um consumo repetitivo de tokens. Além disso, a quantidade de arquivos que podem ser inseridos de uma só vez é limitada pela janela de contexto.
Para tarefas com pequenos volumes de até 50 mil caracteres, essa abordagem é, na verdade, a mais eficiente, pois você pode ajustar e verificar os resultados usando linguagem natural. No entanto, assim que o corpus ultrapassa 200 mil caracteres, você encontrará frequentemente cortes no contexto, latência no processamento de longo contexto (o primeiro token pode levar de 20 a 30 segundos para aparecer) e cobranças repetidas.
2.2 Abordagem B: Conexão direta via MCP com arquivos locais
O MCP (Model Context Protocol) permite que o modelo leia arquivos no seu disco rígido como se estivesse usando uma ferramenta. Parece elegante: o modelo faz a chamada conforme a necessidade, sem precisar carregar tudo. Mas, na prática, o consumo de tokens do MCP é frequentemente subestimado — mesmo que uma chamada de ferramenta retorne um JSON onde você só precisa de 3 campos, a estrutura completa entra no contexto. O modo de correspondência de palavras-chave consome cerca de 3 vezes mais tokens do que a busca vetorial.
O verdadeiro ponto forte do MCP são as fontes de dados que mudam dinamicamente, como logs em tempo real, dados privados do usuário ou dados financeiros que devem permanecer localmente. Para o cenário típico de "centenas de milhares de caracteres em Markdown estático", o MCP é como usar um canhão para matar uma mosca, além de ser fácil esgotar a janela de contexto precocemente em chamadas de múltiplas etapas.
2.3 Abordagem C: Base de conhecimento vetorial / NotebookLM
Dividir todos os arquivos em partes (chunks), realizar o embedding e armazená-los, para então chamar apenas os fragmentos relevantes via busca semântica — essa é a rota RAG. Um pipeline RAG bem projetado recupera apenas 5 a 20 chunks por consulta, totalizando geralmente de 2.000 a 10.000 tokens, o que economiza de 50 a 200 vezes os tokens de entrada em comparação com o carregamento total.
O NotebookLM é um produto RAG pronto para uso oferecido pelo Google, que lida automaticamente com embedding, busca e citações, sendo ideal para tarefas de leitura, como análise de estilo de escrita, revisão de literatura e perguntas e respostas sobre notas. Sua limitação é que as respostas baseiam-se apenas nos arquivos de origem e não associam proativamente dados de treinamento, além de ter personalização limitada. Se você precisar de estratégias de busca complexas ou raciocínio em várias etapas, construir sua própria base de conhecimento vetorial será mais flexível.
🎯 Dica para a Abordagem C: A qualidade da busca na base de conhecimento vetorial determina diretamente a qualidade da saída. O corte de chunks, o modelo de embedding e o top-k da busca devem ser ajustados de acordo com o corpus. Recomendamos que você faça um pequeno teste no APIYI (apiyi.com) usando o Claude ou GPT para comparar a precisão das respostas com diferentes parâmetros de busca antes de decidir entre o NotebookLM ou uma solução própria.
2.4 Abordagem D: Scripts de processamento em lote criados por IA (a melhor solução para escala)
Esta é a abordagem mais enfatizada na resposta original: peça à IA para escrever um script de processamento em lote. Primeiro, use o Modelo de Linguagem Grande para processar de 5 a 10 amostras de dados, identifique manualmente ou automaticamente padrões reutilizáveis (como modelos de frases, estruturas de parágrafos, distribuição de palavras-chave) e, em seguida, incorpore essas regras no código para que ele processe os centenas de milhares de caracteres restantes, deixando o Modelo de Linguagem Grande atuar apenas em pontos críticos.
Essencialmente, isso é "incorporar regras": o Modelo de Linguagem Grande é usado para descobrir padrões, e o código é responsável pela execução em lote. Com a Batch API do Claude/GPT (desconto de 50%), o custo total geralmente é de apenas 5% a 15% da Abordagem A. A desvantagem é que exige 1 a 2 dias de esforço de engenharia inicial, não sendo ideal para tarefas únicas.
三、Comparativo de consumo de Tokens e custos entre 4 abordagens
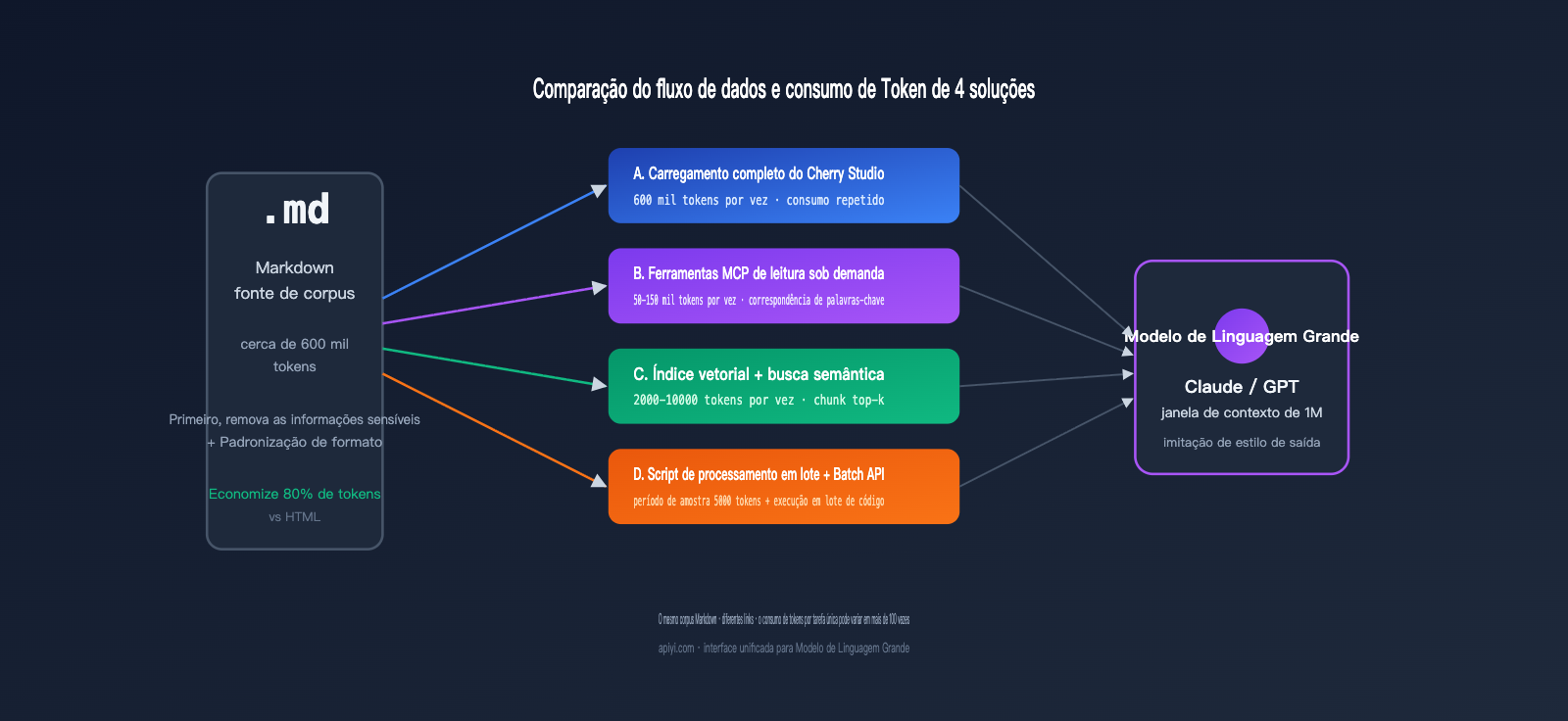
Para entender as diferenças reais, precisamos colocar os números na ponta do lápis. A tabela abaixo compara um cenário específico: um usuário que deseja destilar 300 mil palavras de material em Markdown (aprox. 600 mil Tokens) e gerar 100 artigos estilizados (aprox. 2 mil palavras cada).
| Abordagem | Tokens de entrada (por vez) | Total de Tokens de entrada | Total de Tokens de saída | Custo estimado (Sonnet) | Latência do primeiro Token |
|---|---|---|---|---|---|
| A. Chat direto | 600 mil | 60 milhões (100 vezes) | 6 milhões | ≈ $270 | 20-30 seg |
| B. Acesso a arquivos via MCP | 50-150 mil (dividido) | 15 milhões | 6 milhões | ≈ $135 | 8-15 seg |
| C. Base de conhecimento vetorial | 5-10 mil | 1 milhão | 6 milhões | ≈ $93 | 1-2 seg |
| D. Script de processamento + Batch API | 5000 (amostra) + processamento | 1 milhão | 6 milhões | ≈ $46 | Assíncrono |
Como você pode ver, a abordagem D custa apenas cerca de 17% da abordagem A, além de oferecer uma latência muito mais estável. Se somarmos o desconto de 50% da Batch API, o custo real da abordagem D cai pela metade. Embora o contexto de 1M do Claude tenha padronizado os preços para contextos longos, o desperdício de reprocessar o mesmo material repetidamente continua sendo um problema — essa é uma limitação inerente aos fluxos de trabalho baseados em chat.
🎯 Dica de validação de custos: Os custos acima são baseados em preços públicos. Os valores reais podem variar de 30% a 50% dependendo do design do comando, da taxa de acerto do cache e do uso de prompt caching. Recomendamos ativar o monitoramento de uso no painel da APIYI (apiyi.com), conferir os gastos diariamente nos primeiros 3 dias e transformar seu orçamento abstrato em curvas visuais antes de decidir migrar tarefas para a Batch API.
A tabela abaixo inclui a complexidade de engenharia das quatro abordagens para facilitar a comparação:
| Dimensão | A. Chat direto | B. MCP | C. Base vetorial | D. Script de lote |
|---|---|---|---|---|
| Esforço de engenharia | Quase zero | Médio | Médio-alto | Alto (inicial) |
| Tempo de aprendizado | 5 minutos | 1-2 horas | 0,5 a 1 dia | 1-2 dias |
| Reprodutibilidade | Fraca (histórico fácil de perder) | Média | Forte | Muito forte |
| Escala de dados ideal | < 50 mil palavras | 50-300 mil (dados dinâmicos) | 100 mil – 10 mi (estáticos) | > 300 mil palavras |
| Controle de saída | Limitado pelo contexto | Limitado por chamadas de ferramenta | Limitado pela qualidade da busca | Totalmente controlável |
IV. Recomendações por escala de dados
Aplicar essas abordagens a cenários reais torna tudo mais claro. Abaixo, apresentamos caminhos recomendados para três escalas diferentes.
4.1 Pequena escala (< 50 mil palavras): Fase de exploração
Nesta fase, o objetivo principal é validar ideias rapidamente, não otimizar custos. A abordagem A (chat direto) é a escolha mais lógica: arraste todos os arquivos para o Cherry Studio ou Claude Desktop e converse diretamente com o modelo para ajustar o comando. Foque em: o modelo consegue capturar as características de estilo do autor? Quais dimensões são quantificáveis (tamanho da frase, vocabulário, estrutura)? Quais são subjetivas (tom, ritmo)? O custo aqui é baixíssimo; com poucos dólares você resolve tudo.
4.2 Média escala (50-300 mil palavras): Fase de pesquisa e análise
Neste intervalo, o custo de entrada repetida da abordagem A cresce rapidamente. A melhor prática é mudar para a abordagem C (base de conhecimento vetorial) ou NotebookLM, salvando as amostras em um banco vetorial e consultando conforme necessário. Se você faz apenas análise de conteúdo, resumo de estilo ou exploração via perguntas, o NotebookLM funciona quase sem esforço de engenharia. Para raciocínios complexos de várias etapas, monte seu próprio sistema de RAG baseado em Claude ou GPT.
🎯 Dica para média escala: O NotebookLM é ótimo para leitura e análise, mas não suporta estratégias de busca personalizadas ou fluxos complexos. Recomendamos conectar o Claude Sonnet ou Opus com contexto de 1M na plataforma APIYI (apiyi.com) para rodar seu RAG. Assim, você aproveita o preço padrão e controla com flexibilidade o número de chunks e o peso da busca, ideal para bases de dados de longo prazo.
4.3 Grande escala (> 300 mil palavras): Fase de produção
Para volumes de centenas de milhares ou milhões de palavras, a abordagem D (script de processamento em lote) é praticamente a única opção sustentável. Divida o fluxo em três partes: "descoberta de padrões nas amostras" → "processamento em lote via código" → "uso do Modelo de Linguagem Grande apenas nos pontos críticos". Combinado com a Batch API de forma assíncrona, você pode reduzir o custo por palavra para 5%-15% do original. Nesta fase, o que você precisa não é de um comando mais inteligente, mas de um pipeline de engenharia mais robusto.

V. Sugestões de decisão para economia de tokens por etapas
Condensamos a análise acima em uma tabela de roteiro prático, que você pode seguir diretamente:
| Condição de disparo | Solução recomendada | Ação principal |
|---|---|---|
| Corpus < 50 mil palavras / Exploração única | Solução A: Chat direto | Arraste o arquivo, ajuste o comando e registre os comandos eficazes |
| 50-300 mil palavras / Corpus estático / Análise de leitura | Solução C: Base de conhecimento vetorial | Escolha o NotebookLM ou crie seu RAG, priorizando o ajuste de chunk e top-k |
| > 300 mil palavras / Tarefas repetitivas / Produção em massa | Solução D: Script de processamento em lote + Batch API | Peça ao IA para escrever o script, valide os padrões manualmente na fase de amostragem |
| Dados dinâmicos / Necessidade de processamento local | Solução B: MCP | Limite as chamadas de ferramentas, use a busca por palavras-chave com cautela |
A combinação mais comum em projetos reais é "iniciar com a Solução A, passar para a Solução C e finalizar com a Solução D". Isso ocorre porque a compreensão da tarefa é progressiva: diálogos com pequenas amostras ajudam a entender o que deve ser feito e quais são os critérios de sucesso; amostras médias ajudam a verificar a qualidade da recuperação e a capacidade de generalização; a fase de larga escala serve para consolidar processos já maduros em código.
Pular etapas e ir direto para scripts de processamento em lote é um erro comum — você descobrirá que o script está perfeito, mas os resultados não atendem às expectativas porque o comando inicial não foi otimizado. Por outro lado, ficar preso na fase de chat desperdiça tokens; contas de centenas de dólares podem resultar em apenas algumas dezenas de amostras eficazes.
🎯 Sinais para mudança de fase: Quando você perceber que usou comandos semelhantes para processar arquivos parecidos em 5 conversas seguidas, é hora de migrar para a base de conhecimento vetorial; quando você tiver que repetir a mesma lógica de busca em cada tarefa, é hora de escrever um script. Recomendamos ativar o cache de comandos e o monitoramento de uso na plataforma APIYI (apiyi.com) para que a decisão de mudança seja baseada em dados, não em intuição.
VI. Exemplo mínimo funcional de script de processamento em lote
Para tornar a Solução D mais concreta, aqui está uma estrutura de script de processamento em lote minimalista que demonstra o fluxo central de "descoberta de amostras → consolidação de regras → execução em lote":
import os, json
from anthropic import Anthropic
# O base_url aponta para o serviço proxy de API da APIYI
client = Anthropic(base_url="https://vip.apiyi.com")
def extract_style_features(markdown_text: str) -> dict:
"""Usa o Modelo de Linguagem Grande para extrair características de estilo quantificáveis de um artigo."""
resp = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1500,
messages=[{"role": "user", "content": f"""
Por favor, extraia as características do estilo de escrita do artigo Markdown abaixo e gere um JSON contendo:
- avg_sentence_length: comprimento médio da frase
- paragraph_structure: padrão de estrutura de parágrafo
- key_phrases: 10 frases de alta frequência
- tone: etiqueta de tom (ex: rigoroso/informal/incisivo)
Conteúdo do artigo:
{markdown_text}
"""}],
)
return json.loads(resp.content[0].text)
# Fase de amostragem: use 10 artigos para descobrir padrões
samples = [open(f, encoding="utf-8").read() for f in os.listdir("samples")[:10]]
features = [extract_style_features(s) for s in samples]
# Consolidação de regras: salve as características de alta frequência em um arquivo de configuração para uso posterior pelo código
with open("style_profile.json", "w", encoding="utf-8") as f:
json.dump(features, f, ensure_ascii=False, indent=2)
Após a fase de amostragem, a etapa real de reescrita em lote pode aplicar as regras do style_profile.json diretamente via código. O Modelo de Linguagem Grande intervém apenas na "revisão final", reduzindo o consumo de tokens de centenas de milhares para apenas alguns milhares.
🎯 Dica de integração de API para processamento em lote: O
base_urlacima aponta para o endpoint do serviço proxy de API da APIYI, permitindo reutilizar o SDK oficial da Anthropic sem alterar o código. Recomendamos adicionar lógica de retry (tentativa) e rastreamento de custos no script. Parar automaticamente ao exceder o orçamento em tarefas longas é a melhor forma de evitar surpresas em processamentos em lote de grande escala.
VII. Perguntas Frequentes (FAQ)
Q1: Claude Sonnet e Opus já possuem uma janela de contexto de 1 milhão de tokens, não é possível simplesmente inserir tudo de uma vez?
Tecnicamente é possível, mas existem dois custos ocultos. Primeiro, a latência do primeiro token pode chegar a 20-30 segundos, o que prejudica a experiência interativa; segundo, o mesmo corpus precisa ser reenviado a cada sessão, o que pode custar de 50 a 200 vezes mais caro do que usar RAG após algumas interações. O contexto de 1M é ideal para raciocínio global pontual (como "encontrar contradições entre documentos"), mas não é adequado para consultas repetidas ao mesmo material. Recomendamos usar o Sonnet 1M na APIYI (apiyi.com) para tarefas de raciocínio global e o Haiku para tarefas de processamento em lote, combinando-os para obter o melhor custo-benefício.
Q2: Como escolher entre o NotebookLM e construir minha própria base de vetores?
Se você é um indivíduo ou uma pequena equipe fazendo análise de corpus estático, pesquisa de estilo ou consultas de perguntas e respostas, o NotebookLM é o mais rápido para começar — basta arrastar os arquivos. Se você precisa personalizar estratégias de chunking, controlar pesos de busca, integrar sistemas de negócios ou usar modelos de outros fornecedores para geração, construir sua própria base de vetores oferece muito mais flexibilidade.
Q3: O MCP é realmente inútil?
De forma alguma. O ponto forte do MCP reside em cenários onde os "dados mudam frequentemente" ou "não podem sair do ambiente local", como ler logs em tempo real, consultar bancos de dados privados ou chamar APIs internas. Para corpus estáticos em Markdown, o RAG é superior em quase todas as dimensões; essa é a conclusão.
Q4: A Batch API realmente economiza 50%? A resposta é lenta?
A Batch API é assíncrona, geralmente retornando resultados em até 24 horas, com um preço de 50% em relação à API padrão. É muito adequada para tarefas que não exigem tempo real, como "destilar estilos de escrita para gerar 100 artigos imitados". Combinando isso com o preço padrão do contexto de 1M, o custo total pode ser reduzido para 30%-40% do original. Recomendamos validar o fluxo na plataforma APIYI (apiyi.com) usando a API síncrona e, em seguida, migrar para o modo Batch para produção em massa.
Q5: O que fazer se o corpus contiver imagens, tabelas e blocos de código?
O Markdown já preserva bem essas estruturas, mas atenção: grandes blocos de código consomem muitos tokens. Se o objetivo for apenas analisar o estilo do texto, você pode usar um script para remover o código antes. Se as tabelas forem muito complexas, recomendamos convertê-las para CSV e armazená-las separadamente, enviando apenas o resumo para o Modelo de Linguagem Grande, o que pode economizar mais de 30% de tokens.
VIII. Conclusão
Voltando à pergunta inicial: qual método usar para alimentar um Modelo de Linguagem Grande com centenas de milhares de palavras em Markdown? A resposta não é uma escolha única, mas uma combinação dividida por etapas. No período de exploração com pequenas amostras, o envio direto via chat é mais rápido; no período de pesquisa de escala média, uma base de conhecimento vetorial ou o NotebookLM são mais estáveis; no período de produção em escala, é essencial migrar para scripts de processamento em lote combinados com a Batch API. O papel do Modelo de Linguagem Grande deve ser reduzido de "executor" para "descobridor de padrões", deixando o código como o verdadeiro responsável pelo processamento de volume.
Ao entender esse caminho, a tarefa de economizar tokens em corpus Markdown para Modelos de Linguagem Grande deixa de ser sobre "qual ferramenta escolher" e passa a ser sobre "qual combinação usar em cada estágio". Se você está travado em alguma etapa e não tem certeza se deve mudar, pode realizar uma avaliação em pequena escala na plataforma APIYI (apiyi.com). Compare os dados de custo por mil palavras, precisão de busca e latência do primeiro token; a decisão ficará muito mais clara. Esperamos que esta comparação ajude você a evitar erros e a investir seu orçamento onde ele realmente gera valor.
— Equipe APIYI (api.apiyi.com)