Ao utilizar a API do Claude para chamadas com contexto longo, muitos desenvolvedores se deparam com a mesma confusão: embora tenham declarado o cache no campo cache_control, os valores de cache_creation_input_tokens e cache_read_input_tokens na resposta continuam sendo 0, e não há desconto de cache na fatura. Este artigo detalha sistematicamente as 5 principais razões para a falha de cache no Claude prompt caching, focando no "limite mínimo de tokens para cache" e no mecanismo de "falha silenciosa", que são os pontos mais negligenciados.
Valor central: Ao terminar de ler este artigo, você entenderá os limites mínimos de cache para cada modelo da Anthropic, saberá por que comandos curtos com cache_control não geram erro, mas também não são armazenados em cache, e aprenderá a verificar se o cache foi atingido com apenas 4 linhas de código.
Pontos principais do Claude prompt caching
O Claude prompt caching é o mecanismo de cache de comandos fornecido pela Anthropic: ele armazena comandos de sistema, documentos longos e definições de ferramentas repetitivas em um cache temporário. Na próxima vez que for atingido, a cobrança é feita pelo preço de leitura, que é cerca de 90% mais barato que o preço de entrada normal. Suas características principais são "correspondência de prefixo + declaração explícita + falha silenciosa", e esses três pontos determinam a maioria das suas direções de solução de problemas.
| Ponto | Descrição | Valor para diagnóstico |
|---|---|---|
| Declaração explícita | Deve inserir o bloco cache_control dentro de system, messages ou tools |
Esquecer ou colocar no lugar errado impedirá o cache |
| Correspondência de prefixo | Exige consistência byte a byte de todo o conteúdo antes do bloco de cache | Até um espaço extra causará falha |
| Falha silenciosa | Requisições que não atendem aos critérios retornam normalmente, sem erro ou cache | É necessário validar ativamente o campo usage |
| Limite de TTL | Padrão de 5 minutos, máximo de 1 hora | Chamadas com intervalos longos expirarão naturalmente |
A "falha silenciosa" é a parte onde as pessoas mais tropeçam. A documentação da Anthropic é clara: quando sua requisição não atende às condições de cache (por exemplo, comprimento insuficiente ou prefixo alterado), a API ainda retornará uma resposta normal, mas não criará o cache, não lerá o cache e não lançará erros. Isso significa que você não verá nenhuma exceção no seu código de chamada; você deve verificar ativamente o objeto usage na resposta.
Se você estiver chamando os modelos das séries Sonnet, Opus e Haiku do Claude através da plataforma APIYI (apiyi.com), a lógica de cache é exatamente a mesma da interface oficial da Anthropic. Recomendamos imprimir o campo usage uma vez antes de colocar em produção para confirmar que o cache está realmente funcionando antes de escalar o uso.
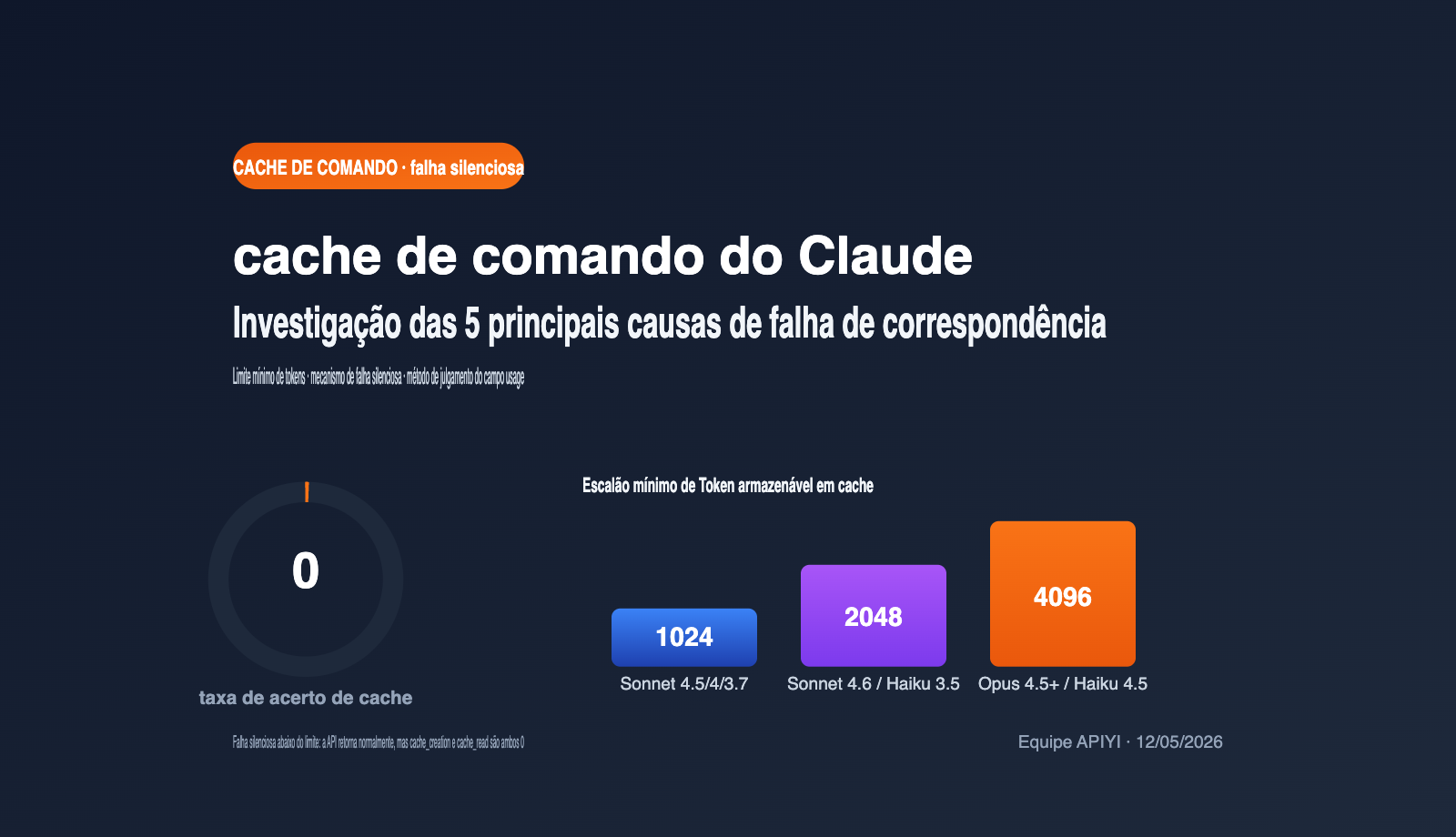
Consulta rápida: Limites mínimos de Token para prompt caching no Claude
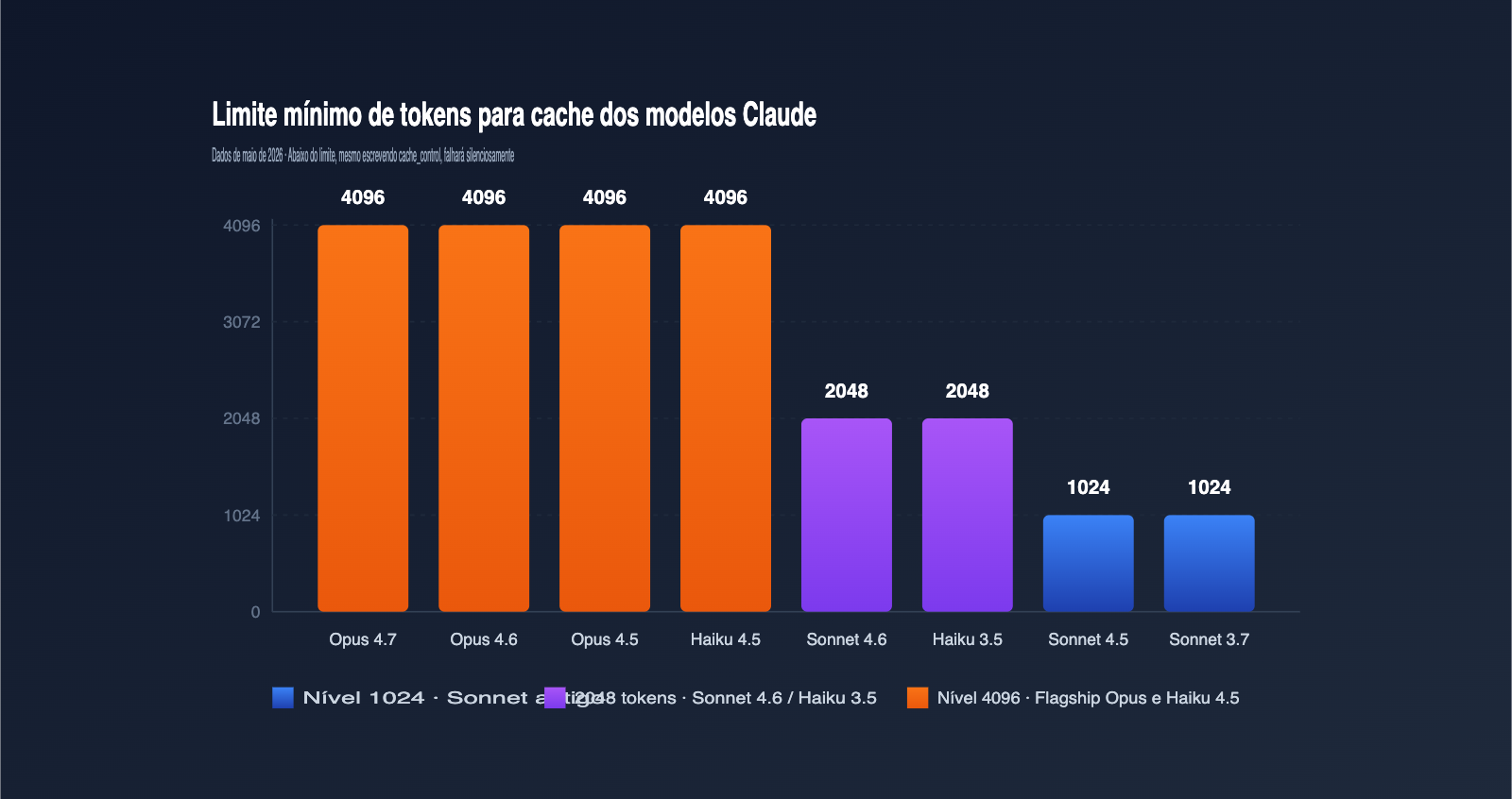
O motivo mais ignorado para a falta de acerto (cache miss) é que o comprimento do comando não atinge o limite de "Token mínimo cacheável" definido pela Anthropic para aquele modelo. Abaixo desse limite, mesmo que você inclua o cache_control, a solicitação será tratada como uma requisição comum. Os limites variam significativamente entre os modelos; a tabela abaixo contém os dados oficiais de maio de 2026. Recomendo salvar para consulta.
| Modelo | Token mínimo cacheável | Observações |
|---|---|---|
| Claude Opus 4.7 / 4.6 / 4.5 | 4096 | Flagship mais recente, limite mais alto |
| Claude Sonnet 4.6 | 2048 | Sonnet principal atual, limite dobrado |
| Claude Sonnet 4.5 / Sonnet 4 / Sonnet 3.7 | 1024 | Série Sonnet clássica |
| Claude Opus 4.1 / Opus 4 | 1024 | Geração anterior do Opus |
| Claude Haiku 4.5 | 4096 | Haiku tem limite maior que o Sonnet |
| Claude Haiku 3.5 | 2048 | Modelo rápido e estável |
Muitas pessoas se surpreendem ao ver esta tabela: por que um "modelo pequeno" como o Haiku 4.5 tem um limite tão alto quanto o Opus 4.7? O motivo é que a nova geração do Haiku utiliza uma janela de atenção mais longa, e o benefício de engenharia do cache só se torna significativo em prefixos maiores, por isso a Anthropic aumentou o limite em sua estratégia de produto.
O erro de julgamento mais comum na prática é o desenvolvedor projetar comandos baseados no hábito de 1024 tokens do antigo Sonnet 3.7. Ao mudar para o Sonnet 4.6, o cache para de funcionar e o desenvolvedor acha que há um erro no código. Se você utiliza vários modelos Claude via APIYI (apiyi.com), recomendo fortemente incluir esta tabela como parte da verificação de parâmetros, ajustando o limite dinamicamente com base no campo model.
5 motivos para o cache de prompt do Claude falhar
Após entender o "limite mínimo de Token" e as "falhas silenciosas", você pode diagnosticar sistematicamente os problemas de cache. Abaixo, os 5 motivos listados por frequência; os dois primeiros cobrem a maioria dos casos que encontramos no dia a dia.
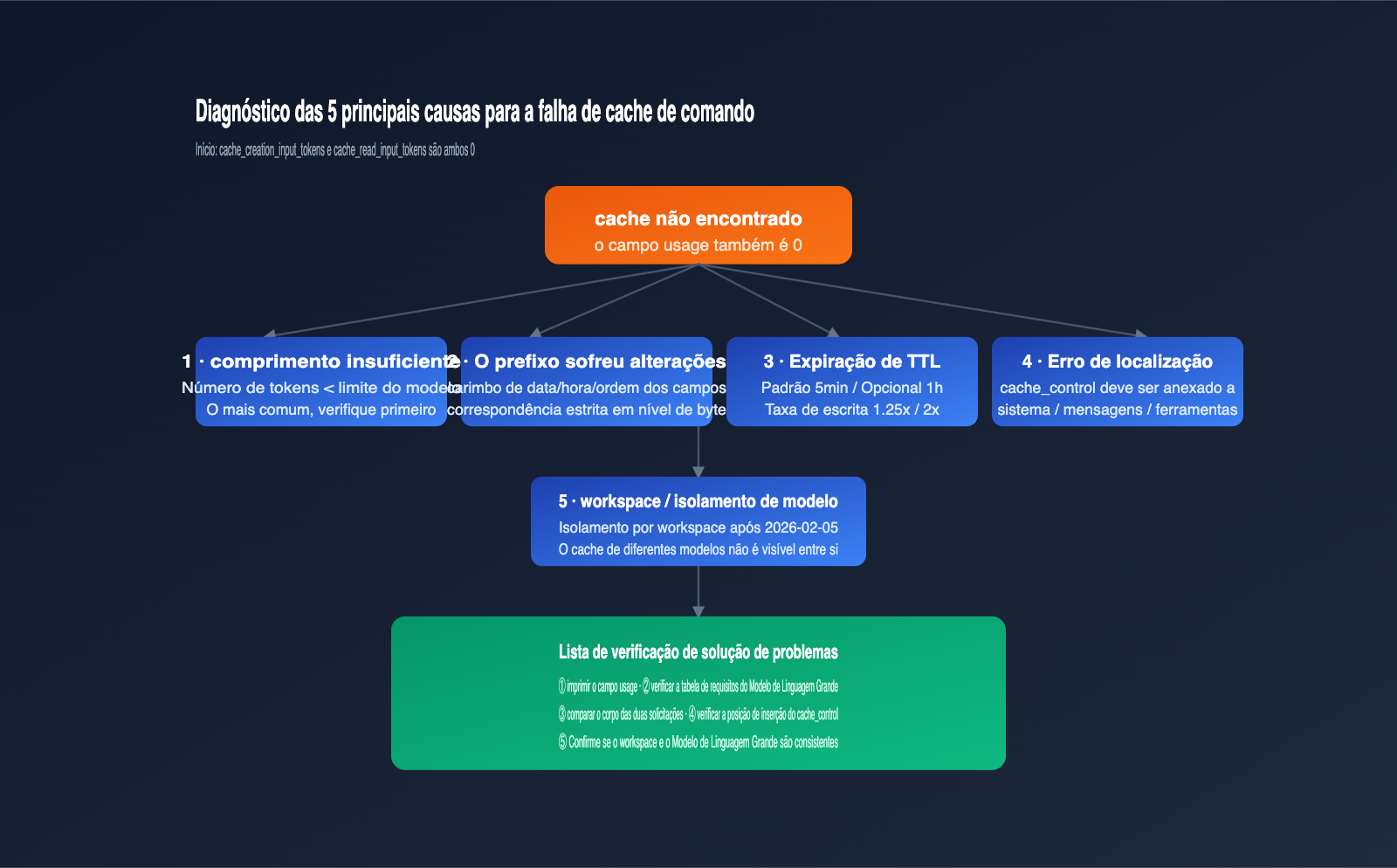
Motivo 1: Comprimento do comando abaixo do limite mínimo
Este é o assassino número um. Por exemplo, se você declara o cache no Sonnet 4.6, mas o comando do sistema tem apenas 1500 tokens, o cache não será criado. O método de diagnóstico é simples: use um tokenizer local para estimar o total de tokens do comando do sistema + definições de ferramentas + histórico de mensagens, e compare com os limites da tabela acima.
Uma situação mais sutil é a "sobreposição de múltiplos blocos cache_control". A estratégia da Anthropic é que "cada ponto de interrupção de cache deve fazer com que o conteúdo acumulado antes dele atinja o limite do modelo", caso contrário, o ponto de interrupção falha. Recomendo que iniciantes usem apenas um bloco cache_control até se familiarizarem com o mecanismo.
Motivo 2: Qualquer alteração em nível de byte no prefixo do cache
O prompt caching é uma correspondência estrita de prefixo, o que significa que se o seu comando do sistema, definições de ferramentas ou histórico de mensagens tiverem um único caractere diferente, o cache será considerado inválido e deverá ser reescrito. "Falsas alterações" comuns incluem:
- Lógica de renderização com timestamp no comando do sistema, fazendo com que cada requisição seja diferente.
- Definições de ferramentas serializadas em ordem alfabética, mas com campos variando devido à natureza não ordenada de dicionários em Python.
- Processamento de
trimoudedupeem mensagens históricas, causando pequenas diferenças na mesma conversa.
A maneira mais direta de diagnosticar isso é comparar o payload completo de duas requisições. Se você usa o APIYI (apiyi.com) para o serviço proxy de API, pode gerar o hash do corpo da requisição nos logs do gateway; se o hash for diferente, você localizou a derivação do prefixo.
Motivo 3: TTL expirado
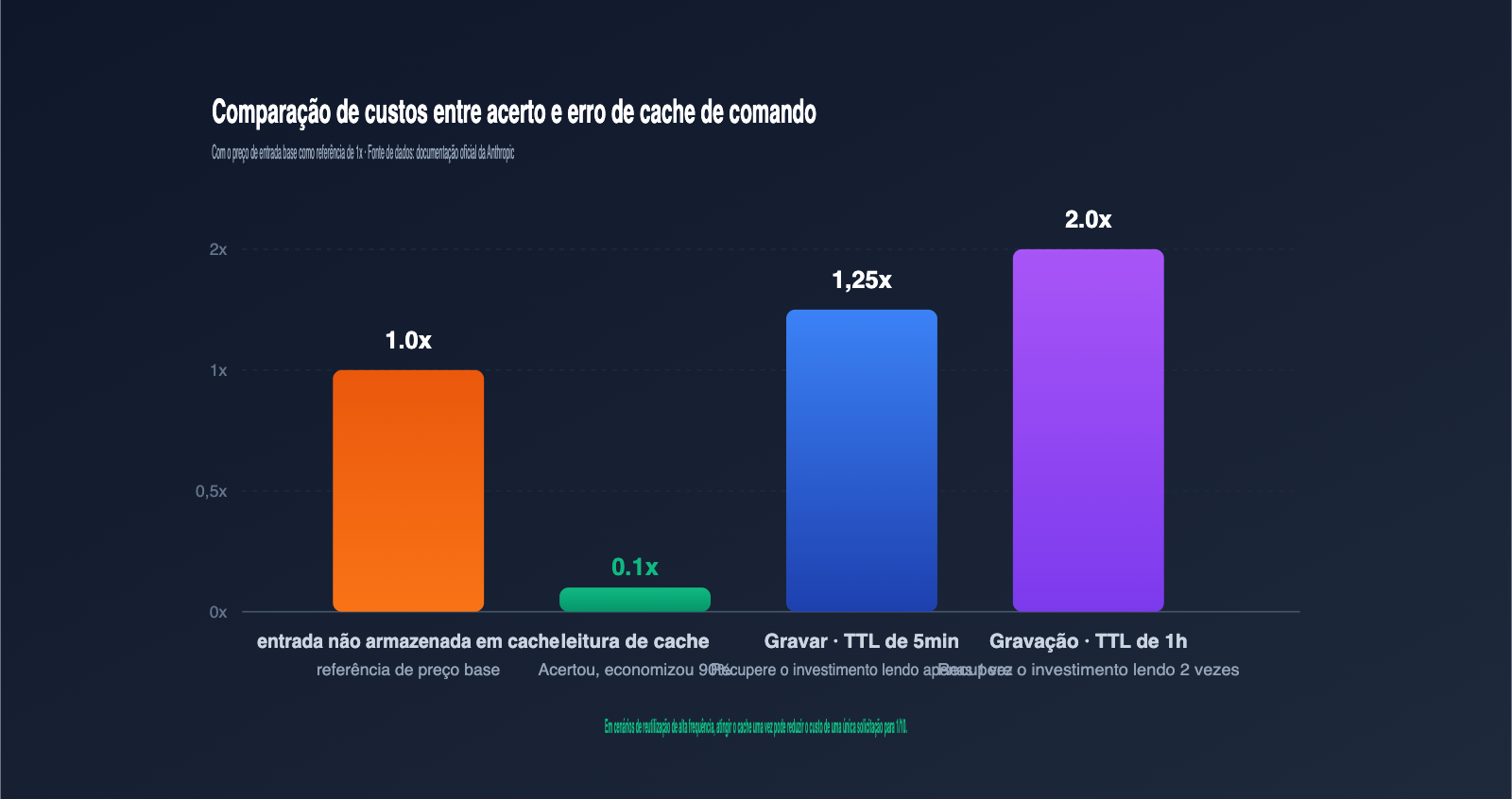
O TTL padrão é de 5 minutos. Após esse intervalo, a entrada do cache é liberada e a próxima requisição acionará uma nova gravação. O preço de gravação com TTL de 1 hora é o dobro do preço básico de entrada; avalie se vale a pena ativar com base na frequência de chamadas.
O sinal de que o TTL expirou é: cache_creation_input_tokens torna-se subitamente um valor diferente de zero, quando você esperava que a requisição lesse o cache. Se isso ocorrer, reduza o intervalo entre as requisições ou mude para "ttl": "1h".
Motivo 4: Erro na posição do cache_control
O cache_control deve ser anexado a um bloco de conteúdo específico dentro dos arrays system, messages ou tools, e o tipo deve ser obrigatoriamente ephemeral. Erros comuns incluem:
- Colocar o
cache_controlnos parâmetros de nível superior demessages.create()em vez de em um bloco de conteúdo. - Declarar na mensagem do
userno arraymessages, mas o prefixo que você deseja cachear é, na verdade, osystem. - Escrever múltiplos
cache_controlna mesma mensagem, mas nenhum atingir o limite de 2048.
A prática correta é inserir o cache_control diretamente no bloco onde você deseja que o cache "termine". O cache será bloqueado desde o início do prompt até o final desse bloco.
Motivo 5: Cache não compartilhado entre workspaces ou modelos
Desde 5 de fevereiro de 2026, a Anthropic alterou o limite de isolamento do cache de prompt para o "nível de workspace", o que significa que caches entre diferentes workspaces não são visíveis entre si. Se suas duas chamadas usam chaves API diferentes ou workspaces diferentes, o cache não será reutilizado.
A mesma lógica se aplica ao nível do modelo. Gravar um cache no Sonnet 4.6 e tentar acessá-lo no Sonnet 4.5 nunca funcionará. Ao agendar múltiplos modelos, é melhor manter um script de pré-aquecimento de cache para cada dimensão de modelo ou reutilizar o mesmo workspace upstream via plataformas de agregação como o APIYI (apiyi.com) para evitar a fragmentação do cache.
Verificação de acerto e lógica de decisão do cache de prompts do Claude
O primeiro passo para diagnosticar problemas de falta de acerto (cache miss) é sempre "imprimir o campo usage". A Anthropic inclui um objeto usage em cada resposta de messages.create, contendo 4 campos cruciais que são a única fonte confiável para determinar o status do cache.
Código de verificação minimalista
import anthropic
client = anthropic.Anthropic(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com"
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system=[{
"type": "text",
"text": LONG_SYSTEM_PROMPT, # Deve ser ≥ 2048 tokens
"cache_control": {"type": "ephemeral"}
}],
messages=[{"role": "user", "content": "sua pergunta"}]
)
u = response.usage
print(f"Escrita no cache: {u.cache_creation_input_tokens}")
print(f"Leitura do cache: {u.cache_read_input_tokens}")
print(f"Entrada não cacheada: {u.input_tokens}")
Use este código como um modelo de diagnóstico. Sempre que suspeitar que o cache não está funcionando, execute-o primeiro e verifique os campos retornados para identificar a origem do problema.
Ver versão completa encapsulada
import anthropic
import logging
MIN_TOKENS = {
"claude-opus-4-7": 4096,
"claude-opus-4-6": 4096,
"claude-opus-4-5": 4096,
"claude-sonnet-4-6": 2048,
"claude-sonnet-4-5": 1024,
"claude-haiku-4-5": 4096,
"claude-haiku-3-5": 2048,
}
def call_with_cache_check(model: str, system_text: str, user_msg: str):
client = anthropic.Anthropic(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com"
)
response = client.messages.create(
model=model,
max_tokens=1024,
system=[{
"type": "text",
"text": system_text,
"cache_control": {"type": "ephemeral"}
}],
messages=[{"role": "user", "content": user_msg}]
)
u = response.usage
if u.cache_creation_input_tokens == 0 and u.cache_read_input_tokens == 0:
logging.warning(
f"Cache não ativado, possivelmente abaixo do limite de {MIN_TOKENS.get(model)} tokens"
)
return response
Tabela de decisão de status de acerto
cache_creation_input_tokens |
cache_read_input_tokens |
Conclusão |
|---|---|---|
| > 0 | = 0 | Primeira escrita no cache (normal) |
| = 0 | > 0 | Acerto de cache (ideal) |
| > 0 | > 0 | Acerto parcial, nova parte foi escrita |
| = 0 | = 0 | Não cacheado, verifique os 5 motivos principais |
A última linha indica o problema. Ao vê-la, vá direto ao motivo 1 e verifique os 5 pontos. Se sua equipe exige alta estabilidade, você pode encapsular essa lógica de verificação em um middleware na cadeia de chamadas da APIYI (apiyi.com) para disparar alertas imediatos.
4 Dicas práticas para atingir o limite mínimo de tokens
Quando confirmar que o problema é a "falta de comprimento", o próximo passo é garantir que o prefixo do cache atinja o limite. Abaixo, 4 dicas ordenadas por recomendação; as 3 primeiras quase não têm efeitos colaterais.
| Técnica | Cenário | Aumento de Tokens | Observações |
|---|---|---|---|
| Base de conhecimento completa | Comando muito curto | +2000~4000 | Deve ser relevante sempre |
| Definição de ferramentas | Aplicações com várias ferramentas | +500~2000 | O campo tools também pode ser cacheado |
| Exemplos few-shot | Tarefas complexas | +1000~3000 | Exemplos devem ter valor de generalização |
| Preenchimento com texto irrelevante | Emergência | Qualquer | Não recomendado, afeta a qualidade |
A primeira técnica, "base de conhecimento completa", é a mais estável. Se sua aplicação já possui uma base (FAQ, guias de estilo, SOPs), insira-a no topo do bloco system com cache_control para superar os 4096 tokens.
A segunda, "definição de ferramentas", é frequentemente ignorada. O campo tools da Anthropic suporta cache_control, sendo eficaz para agentes multiferramentas.
A terceira, "exemplos few-shot", é ideal para tarefas complexas. Colocar 3-5 casos padrão no final do system melhora a estabilidade e aumenta a contagem de tokens para o patamar necessário.
A quarta, "preenchimento com texto irrelevante", é apenas para emergências. Se não houver outra opção, considere usar a plataforma APIYI (apiyi.com) para alternar para modelos com limites menores, como o Sonnet 4.5 ou 3.7.
Perguntas Frequentes
Q1: Adicionei o cache_control, mas não está armazenando em cache. A API está com bug?
Muito provavelmente não é um bug, mas sim um mecanismo de falha silenciosa. O primeiro passo é verificar o limite mínimo de tokens correspondente ao campo model e, em seguida, imprimir o objeto usage. Em 99% dos casos, o problema é o comprimento insuficiente ou a alteração do prefixo.
Q2: O custo de cache_creation_input_tokens é caro?
A escrita com TTL de 5 minutos custa 1,25 vezes o preço base de entrada, e o TTL de 1 hora custa 2 vezes. O preço de leitura é 0,1 vez. De modo geral, um cache de 5 minutos se paga após ser lido uma vez, e um cache de 1 hora após duas leituras; quanto mais reutilizado, maior o benefício.
Q3: A documentação antiga dizia que o limite mínimo do Sonnet era 1024, por que mudou para 2048 na nova versão?
Este é um novo limite que surgiu apenas no Sonnet 4.6. As versões Sonnet 4.5 e anteriores continuam com 1024. Recomenda-se manter uma tabela de mapeamento "modelo → limite" no seu código e determinar dinamicamente com base no modelo chamado. Ao utilizar o APIYI (apiyi.com), a nomenclatura do campo model é exatamente igual à oficial da Anthropic, permitindo que você reutilize a mesma lógica de mapeamento.
Q4: Como usar vários blocos cache_control de forma segura?
Cada cache_control exige que o prefixo acumulado atinja o limite, caso contrário, esse ponto de interrupção falhará. Para iniciantes, recomendo colocar apenas um ponto de interrupção e armazenar todo o bloco system em cache. Se precisar dividir em camadas, coloque a "base de conhecimento que muda pouco" na primeira camada e as "definições de ferramentas que mudam ocasionalmente" na segunda.
Q5: Posso usar plataformas de serviço proxy de API domésticas para testar o prompt caching?
Sim. As interfaces da série Claude em plataformas de agregação como o APIYI (apiyi.com) são totalmente compatíveis com a oficial da Anthropic, incluindo os campos cache_control, ttl e usage. Os desenvolvedores podem realizar a depuração e o aumento de escala nessas plataformas, mantendo a lógica de cache e as regras de cobrança consistentes.
Conclusão
O prompt caching do Claude parece simples, bastando adicionar um campo cache_control, mas, na prática, você pode ser surpreendido pela "falha silenciosa + limite mínimo de tokens + correspondência estrita de prefixo". A lista de verificação de 5 pontos e a tabela de acertos fornecidas neste artigo podem ajudar os desenvolvedores a identificar 90% dos problemas de não correspondência em menos de 5 minutos.
A recomendação para implementação é criar um middleware padrão para validação, transformar a tabela de limites dos modelos em constantes no código e criar scripts separados para o pré-aquecimento do cache. Se o seu negócio alterna frequentemente entre vários modelos, você pode gerenciar centralmente as chamadas do Claude através da plataforma APIYI (apiyi.com), reutilizando a mesma estratégia de cache e lógica de monitoramento, evitando custos ocultos causados pela fragmentação do cache e inconsistência de limites entre diferentes ambientes.
Autor: Equipe Técnica APIYI
Contato: Obtenha suporte completo para depuração de toda a série de modelos Claude e prompt caching através do APIYI (apiyi.com)
Data de atualização: 12/05/2026