프롬프트 캐싱(Prompt Caching)은 2026년 대규모 언어 모델 API 사용자라면 누구나 고민해야 할 핵심 비용 이슈입니다. 8K 시스템 프롬프트를 사용하는 RAG 애플리케이션을 운영할 때, 캐싱 적용 여부에 따라 월간 청구 금액이 10배 이상 차이 날 수 있기 때문이죠. 하지만 많은 개발자가 OpenAI와 Anthropic 사이를 오가며 혼란을 겪는 숨겨진 디테일이 있습니다. 바로 두 회사의 캐싱 과금 모델이 완전히 다르다는 점입니다.

가장 결정적인 차이는 한 문장으로 요약됩니다. GPT 시리즈는 캐시 쓰기 시 기본 가격의 1배로 과금하며 추가 프리미엄이 없지만, Claude 시리즈는 캐시 쓰기 시 1.25배(5분) 또는 2배(1시간)의 프리미엄을 부과합니다. 이 차이는 작아 보이지만, 실제 비즈니스 트래픽에 적용하면 손익분기점에 큰 영향을 미칩니다. 본 글에서는 양사의 공식 문서를 바탕으로 과금 규칙, 트리거 조건, 읽기 할인, TTL 전략, 비용 회수 시뮬레이션까지 꼼꼼히 정리해 드립니다.
GPT와 Claude 프롬프트 캐싱의 5가지 핵심 차이
결론부터 말씀드리겠습니다. 아래 표는 이번 글에서 가장 중요한 핵심 요약표입니다. 캐싱 레이어에서 흔히 간과하기 쉬운 5가지 포인트를 비교했습니다.
| 구분 | OpenAI GPT | Anthropic Claude |
|---|---|---|
| 쓰기 과금 | 기본 가격 1배, 프리미엄 없음 | 5분: 1.25배; 1시간: 2배 |
| 읽기 과금 | 약 0.1배 (최대 90% 할인) | 0.1배 (10% 할인 후 가격) |
| 트리거 방식 | 완전 자동, 코드 수정 불필요 | 명시적 opt-in, cache_control 필요 |
| 최소 토큰 임계값 | 일괄 1024 토큰 | 1024 / 2048 / 4096 (모델별 상이) |
| 캐시 TTL | 기본 5~10분 유휴, 최대 1시간; 확장 모드 24시간 | 기본 5분, 선택 가능 1시간 (2배 쓰기) |
이 표를 이해하는 핵심은 '쓰기 과금' 행입니다. OpenAI의 논리는 "캐싱은 무료이며, 첫 쓰기는 기본 가격으로, 두 번째부터는 할인된 가격으로 제공한다"는 것입니다. 따라서 한 번이라도 캐시 적중이 발생하면 즉시 이익 구간으로 진입합니다. 반면 Claude의 논리는 "쓰기 시 프리미엄을 먼저 지불하고, 적중 시 할인을 적용받아 프리미엄을 상쇄한다"는 방식이라, 충분한 적중 횟수가 있어야 비용 효율이 발생합니다.
🎯 설정 제안: 비즈니스 트래픽을 예측하기 어렵고 적중률이 불안정하다면, 리스크를 줄일 수 있는 GPT의 자동 캐싱 메커니즘을 우선 고려하세요. 반면 적중률이 매우 안정적이라면(고객 센터, 에이전트, 긴 문서 분석 등), Claude의 명시적 제어를 통해 더 높은 할인을 끌어낼 수 있습니다. APIYI(apiyi.com)에서는 두 모델 모두 지원하므로, 계정을 여러 개 만들 필요 없이 동일한 토큰 내에서 비교 테스트를 진행해 보세요.
OpenAI GPT 프롬프트 캐싱(Prompt Caching) 과금 메커니즘 상세 분석
OpenAI 공식 문서에서 프롬프트 캐싱에 대해 설명하는 문구는 매우 직관적입니다. "Caching happens automatically, with no explicit action needed or extra cost paid to use the caching feature." 즉, 별도의 설정 없이 자동으로 활성화되며, 추가 비용이 전혀 들지 않고 코드 수정도 필요 없다는 뜻입니다.
GPT 캐시 쓰기 및 읽기 과금
GPT 시리즈는 캐시 쓰기에 대해 별도의 프리미엄을 부과하지 않습니다. 8K 분량의 시스템 프롬프트를 처음 보낼 때는 기본 입력 가격으로 청구되며, 이는 캐싱을 사용하지 않을 때와 동일합니다. 두 번째 요청부터는 시스템이 해당 접두사(prefix)가 이미 캐시되었음을 인식하면, 적중된 부분에 대해 기본 가격의 약 10% 수준으로 요금을 청구하여 90%의 비용을 절감해 줍니다.
| 항목 | 과금 방식 | 기본 가격 대비 비율 |
|---|---|---|
| 캐시 최초 쓰기 | 기본 입력 가격 적용 | 1x (추가 비용 없음) |
| 캐시 적중 읽기 | 캐시 적중 할인 적용 | 약 0.1x |
| 활성화 비용 | 완전 무료 | 0 |
| 코드 수정 필요성 | 없음 | 필요 없음 |
실제 할인 폭은 공식적으로 "최대 90%"라고 명시되어 있으며, 모델과 요금표에 따라 약간의 차이가 있습니다. 예를 들어 GPT-5.4의 기본 입력 가격이 $2/1M라면, 캐시 적중 가격은 $0.20/1M로 정확히 10% 수준입니다. GPT-4.1, GPT-4o 등 지원 모델들도 대체로 이 비율을 따릅니다.
🎯 가격 확인: OpenAI 모델은 업데이트가 잦으므로 실제 적중 할인 가격은 공식 요금표를 기준으로 합니다. APIYI(apiyi.com) 모델 광장에서 현재 적용 가격을 직접 확인하시는 것을 권장합니다. 플랫폼은 공식 조정 사항을 즉시 반영하며, 별도의 중계 수수료 없이 개발자가 실제 사용한 토큰 양만큼만 결제하면 됩니다.
GPT 캐시 적중 조건
캐시 적중을 유도하려면 다음 두 가지 조건을 동시에 만족해야 합니다.
- 프롬프트 길이 ≥ 1024 토큰 (이보다 짧으면 캐싱되지 않음).
- 프롬프트의 **접두사(prefix)**가 이전 요청과 완전히 일치해야 하며, 128 토큰 단위로 슬라이싱되어 적중이 결정됩니다.
OpenAI는 캐시 적중의 최소 단위를 128 토큰으로 설정했습니다. 이는 1500 토큰의 안정적인 접두사가 있을 때, 앞부분 1024 토큰만 일치하면 나머지 부분은 128 토큰 단위로 점진적으로 적중된다는 의미입니다. 이러한 자동화 설계의 단점은 제어력이 다소 떨어진다는 점입니다. 개발자가 "어느 부분을 반드시 캐싱할지" 명시적으로 지정할 수 없으므로, 변하지 않는 모든 내용을 앞부분에 배치해야 합니다.
GPT 캐시의 TTL(유효 기간) 동작
OpenAI는 TTL에 대해 매우 중요한 정보를 제공합니다. 캐시된 접두사는 보통 5~10분간 유휴 상태가 지속되면 회수되며, 최대 1시간까지 유지됩니다. GPT-5, GPT-4.1 등 최신 모델은 "확장 보존(extended retention)"을 지원하여 최대 24시간까지 유지할 수 있습니다.
🎯 사용 팁: APIYI(apiyi.com)를 통해 GPT 시리즈를 이용할 경우, OpenAI의 자동 캐싱 전략은 중계 경로에서도 투명하게 작동하며 적중률은 공식 엔드포인트와 동일합니다. 즉, 추가 비용 없이 APIYI를 통해 OpenAI와 Claude의 청구서 및 토큰을 통합 관리할 수 있습니다.
Anthropic Claude 프롬프트 캐싱 과금 메커니즘 상세 분석
Claude의 설계 철학은 OpenAI와 정반대입니다. Claude는 캐싱을 "능동적으로 설정해야 하는 최적화 기능"으로 간주합니다. 개발자가 어떤 내용을 얼마나 오래 캐시할지 명시적으로 선언해야 합니다. 그 대가로 쓰기 시 프리미엄이 붙지만, 매우 정밀한 제어가 가능하다는 장점이 있습니다.
Claude 캐시 쓰기 프리미엄 및 읽기 할인
| 항목 | 과금 배율 | 설명 |
|---|---|---|
| 5분 쓰기 | 1.25x 기본 입력가 | 기본 TTL, 대부분의 상황에 적합 |
| 1시간 쓰기 | 2x 기본 입력가 | 긴 대화, 에이전트 등에 적합 |
| 캐시 적중 읽기 | 0.1x 기본 입력가 | 90% 할인 |
| 활성화 비용 | 0 | 추가 개통 비용 없음 |
| 설정 변경 | cache_control 추가 필수 |
명시적 선택(Opt-in) |
직관적인 예시를 들어보겠습니다. Claude Opus 4.7의 기본 입력 가격이 $5/1M라면, 5분 쓰기는 $6.25/1M, 1시간 쓰기는 $10/1M가 되며, 적중 시 읽기 비용은 $0.50/1M에 불과합니다. 이 요금표는 Anthropic 공식 문서에 명시되어 있으며 여러 분기 동안 안정적으로 유지되고 있습니다.
Claude 캐시의 최소 토큰 임계값
Claude의 최소 캐시 가능 토큰 수는 모델마다 다르며, 많은 사용자가 여기서 첫 번째 실수를 합니다.
| 모델 | 최소 캐시 가능 토큰 |
|---|---|
| Claude Opus 4.7 / 4.6 / 4.5 | 4096 |
| Claude Haiku 4.5 | 4096 |
| Claude Sonnet 4.6 | 2048 |
| Claude Sonnet 4.5 / Opus 4.1 / Sonnet 4 | 1024 |
안정적인 접두사가 해당 모델의 최소 임계값보다 짧으면 cache_control을 추가해도 실제로 캐시 계층에 저장되지 않습니다. 요청은 오류 없이 비캐시 경로로 처리되지만, 사용자는 캐싱이 적용된 것으로 착각할 수 있습니다. 특히 Opus 4.7의 경우 4096 토큰이라는 높은 문턱이 있어 짧은 대화에서는 캐싱 효과를 보기 어렵습니다.
🎯 모델 선택 제안: 비즈니스 컨텍스트 길이가 일정하지 않다면 최소 임계값이 낮아 적중하기 쉬운 Claude Sonnet 4.5 또는 4.6을 우선 고려하세요. APIYI(apiyi.com)에서는 Sonnet과 Opus를 클릭 한 번으로 전환할 수 있어, 모델 임계값 문제로 캐싱이 무용지물이 되는 상황을 방지할 수 있습니다.
Claude 캐시의 브레이크포인트(Breakpoint) 및 동시성 제한
Claude는 한 번의 요청에 최대 4개의 캐시 브레이크포인트를 설정할 수 있으며, 각 지점마다 다른 TTL을 지정할 수 있습니다. 이는 GPT와 차별화되는 Claude만의 강력한 기능입니다. "시스템 프롬프트"는 1시간 캐시, "지식 베이스 조각"은 5분 캐시, "사용자 컨텍스트"는 캐시하지 않는 식으로 독립적인 과금과 만료 관리가 가능합니다.
동시성 환경에서는 주의할 점이 있습니다. Claude의 캐시 항목은 첫 번째 응답이 반환되기 시작한 후에야 다른 요청에 적용됩니다. 동일한 접두사를 가진 요청을 N개 병렬로 보내면, 첫 번째 요청만 캐시에 기록되고 나머지 N-1개는 여전히 기본 가격으로 청구됩니다. 따라서 대량 호출 시에는 먼저 캐시 쓰기를 유도하는 요청을 하나 보낸 뒤, 나머지를 병렬로 처리하는 것이 좋습니다.
🎯 대량 호출 제안: APIYI(apiyi.com)를 통해 Claude를 호출할 때는 병렬 배치를 시작하기 전에 "워밍업" 요청을 단독으로 보내 캐시 쓰기를 유도하세요. 응답이 시작된 것을 확인한 후 병렬 요청을 보내면 중복 쓰기 프리미엄을 방지하여 예산을 크게 절감할 수 있습니다.
쓰기 프리미엄이 실제 청구서에 미치는 영향: 손익분기점 계산
이번 섹션에서는 추상적인 배율을 구체적인 금액으로 환산해 보겠습니다. 10,000 토큰의 안정적인 시스템 프롬프트를 1시간 동안 N번 요청하고, 출력은 500 토큰으로 고정한다고 가정했을 때, 두 업체의 N값에 따른 총비용을 비교해 보겠습니다.
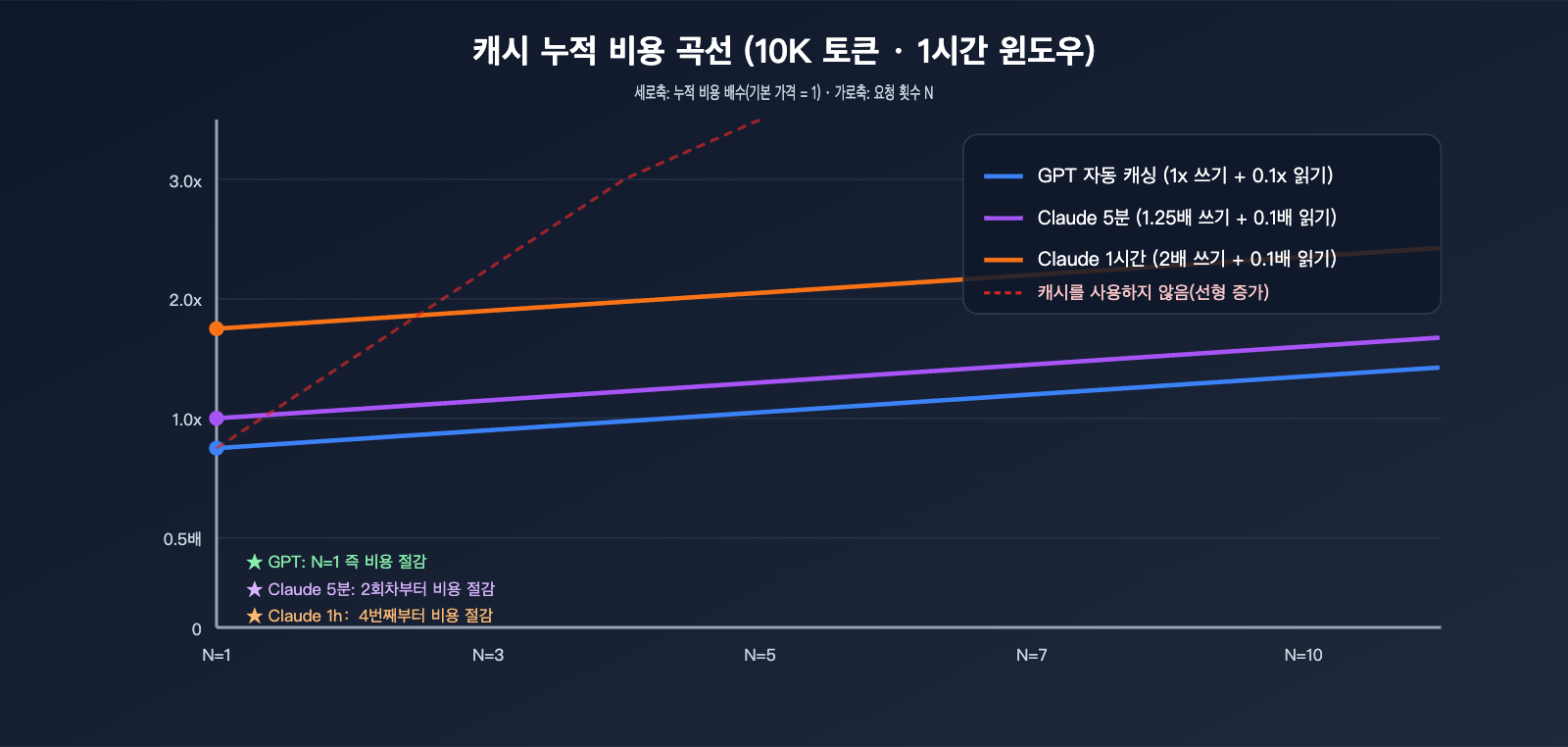
비교를 위해 양사의 기본 입력 가격을 $X/1M 토큰으로 정규화합니다. 10,000 토큰의 단일 기본 비용 = 10 × $X / 1000 = $0.01X입니다. 아래에서는 입력단 캐시 비용만 고려하고 출력은 제외했습니다(출력은 각 사의 자체 가격 적용).
| 요청 횟수 N | GPT 자동 캐시 | Claude 5분 캐시 | Claude 1시간 캐시 |
|---|---|---|---|
| N=1(최초 작성) | $0.01X | $0.0125X | $0.02X |
| N=2 | $0.011X | $0.0135X | $0.021X |
| N=5 | $0.014X | $0.0165X | $0.024X |
| N=10 | $0.019X | $0.0215X | $0.029X |
| 캐시 미사용(참조) | $0.01X × N | $0.01X × N | $0.01X × N |
| 손익분기점 | 0회(첫 회부터 절약) | 1회(2회부터 절약) | 3회(4회부터 절약) |
핵심 사실을 알 수 있습니다. GPT 캐시는 N=1일 때부터 손해가 아닙니다. 쓰기 비용이 1배로 청구되고 적중 시 할인이 적용되므로 항상 이득이기 때문입니다. Claude 5분 캐시는 0.25배의 쓰기 프리미엄을 상쇄하기 위해 최소 1번의 적중이 필요하며, 1시간 캐시는 3번의 적중이 필요합니다. 만약 특정 안정적 접두사가 하루에 1번만 적중한다면, Claude 1시간 캐시를 사용하는 것이 오히려 캐시를 쓰지 않는 것보다 비쌉니다.
실제 업무에서 TTL을 선택하는 방법
이 계산을 통해 다음과 같은 실무 제언을 드릴 수 있습니다.
- 빈도가 낮고 불규칙함: GPT 자동 캐시 우선 사용 (고민 없이 절약 가능).
- 빈도가 높고 5분 내 여러 번 적중 (고객 상담, 웹 앱 등): Claude 5분 캐시가 수익 극대화 (쓰기 프리미엄은 낮고 읽기 할인폭이 큼).
- 긴 작업, 시간 단위로 반복 재사용 (코딩 에이전트, 긴 문서 대화): Claude 1시간 캐시가 유효하지만, 최소 3번 이상의 적중 보장 필요.
- 적중률 불확실: 항상 5분으로 시작하고, 잘 작동하면 1시간으로 변경 고려.
🎯 측정 제언: APIYI(apiyi.com) 백엔드에서는 요청 단위의
cached_tokens통계를 제공하므로 실제 적중률을 바로 확인할 수 있습니다. 프로덕션 트래픽을 일주일 정도 돌려본 후 TTL을 1시간으로 공격적으로 늘릴지 결정하는 것을 추천합니다.
다양한 비즈니스 시나리오별 캐시 전략 추천
비용 차이를 이해했다면 이제 실제 업무에 적용할 차례입니다. 자주 쓰이는 시나리오별 추천 전략은 다음과 같습니다.
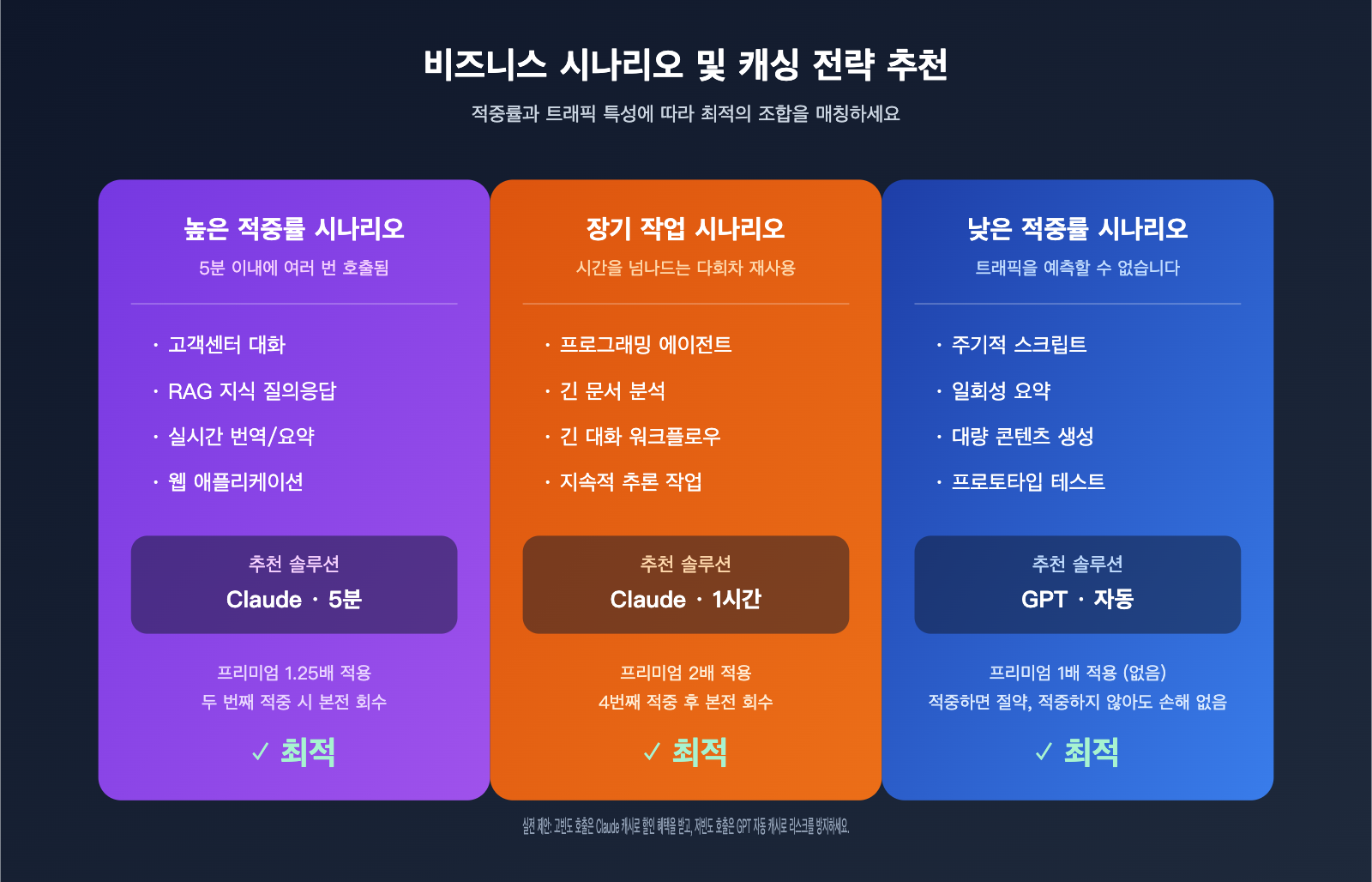
시나리오 1: 고빈도 RAG 및 기업 지식 질의응답
이러한 시나리오의 안정적 접두사는 일반적으로 시스템 프롬프트 + 지식 베이스 조각을 포함하며, 단일 세션 내 다회 적중이 발생하여 5분 내 누적 요청 수가 쉽게 10회를 넘습니다. Claude 5분 캐시는 이 시나리오에서 입력 비용을 80% 이상 절감할 수 있어 가장 경제적입니다. 1시간 이상의 긴 세션이라면 1시간 캐시를 고려해 보세요.
시나리오 2: 프로그래밍 에이전트 및 긴 작업 워크플로우
Claude Code, OpenCode와 같은 코딩 에이전트는 단일 작업이 30분에서 몇 시간까지 지속될 수 있으며, 그동안 프로젝트 구조, CLAUDE.md, 이전 도구 호출 결과 등을 반복적으로 읽습니다. 이 경우 Claude 1시간 캐시가 최적의 선택입니다. 적중 횟수가 손익분기점인 3회를 훨씬 상회하기 때문입니다.
시나리오 3: 저빈도 또는 예측 불가능한 요청
주기적 스크립트, 대량 SEO 기사 생성, 일회성 긴 문서 요약 등은 요청 간격이 5분을 훨씬 넘을 수 있습니다. 이 경우 GPT 시리즈와 자동 캐시를 우선 사용하는 것이 좋습니다. 적중하면 이득이고 적중하지 않아도 손해가 없어 Claude의 명시적 캐시보다 오류 허용 범위가 훨씬 넓습니다.
시나리오 4: 비용 민감형 순수 입력 압축
핵심 목표가 10K+ 토큰의 프롬프트를 최소 비용으로 압축하는 것이라면, Claude Sonnet 4.6 + 5분 캐시 조합을 추천합니다. 쓰기 프리미엄이 25%에 불과하고, 적중 시 1번만으로도 본전을 찾을 수 있으며, 읽기 가격을 $0.075/1M 수준까지 낮출 수 있습니다.
| 비즈니스 시나리오 | 추천 모델군 | 추천 TTL | 이유 |
|---|---|---|---|
| 고객 상담/RAG/즉시 질의응답 | Claude Sonnet | 5분 | 적중 빈도 높음, 빠른 본전 회수 |
| 프로그래밍/긴 에이전트 작업 | Claude Sonnet/Opus | 1시간 | 시간 단위 적중 3회 이상 |
| 주기적 스크립트/배치 처리 | GPT-4.1 / GPT-5.x | 자동 | 적중 불안정, 쓰기 프리미엄 없음 |
| 일회성 긴 문서 분석 | GPT-5.x | 자동 | 단일 작업, 낮은 적중률 |
| 순수 비용 민감형 시나리오 | Claude Sonnet 4.6 | 5분 | 최저 유효 캐시 가격 |
🎯 하이브리드 아키텍처 제언: 프로덕션 환경에서 GPT와 Claude는 양자택일이 아니라 시나리오별 조합이 필요합니다. APIYI(apiyi.com) 단일 입구를 통해 두 모델을 모두 연결하고, 프론트엔드에서 비즈니스 트래픽에 따라 동적 라우팅을 수행하세요. 적중률이 높으면 Claude 캐시로, 낮으면 GPT 자동 캐시로 보내면 전체 비용을 40% 이상 절감할 수 있습니다.
자주 묻는 질문 FAQ
Q1: GPT는 정말 캐시 쓰기 프리미엄이 없나요? 어딘가에 숨겨진 비용이 있는 건 아닌가요?
네, 맞습니다. OpenAI 공식 문서에 따르면 "No. Caching happens automatically, with no explicit action needed or extra cost paid to use the caching feature."라고 명시되어 있습니다. 캐시 쓰기는 기본 입력 가격으로 계산되며 별도의 숨겨진 프리미엄은 없습니다. 적중된 부분에 대해서만 할인된 가격을 지불하고, 적중되지 않은 부분은 기본 가격을 지불하게 되므로 사실상 캐시 기능을 "무료"로 제공받는 셈입니다.
Q2: Claude의 1.25배 및 2배 쓰기 프리미엄은 전체 프롬프트 기준인가요, 아니면 캐시된 부분만 계산하나요?
cache_control로 캐시 처리된 부분만 계산합니다. 예를 들어 10K 프롬프트 중 8K만 캐시로 지정했다면, 1.25배 프리미엄은 이 8K에만 적용되며 나머지 2K는 1배 기본 가격이 적용됩니다. 따라서 불필요한 내용까지 프리미엄이 붙지 않도록 breakpoint를 세밀하게 설정하는 것을 권장합니다.
Q3: APIYI 중계 서비스는 두 업체의 캐시 비용을 그대로 전달하나요?
APIYI apiyi.com은 GPT와 Claude의 캐시 비용을 원본 그대로 전달합니다. GPT의 자동 캐시 적중 할인, Claude의 명시적 캐시 1.25배/2배 쓰기 및 0.1배 읽기 비용 모두 공식 청구서와 동일합니다. cache_control 필드도 그대로 전달되므로 개발자는 공식 SDK 코드를 그대로 활용할 수 있습니다.
Q4: Claude 1시간 캐시를 사용하는 것이 오히려 손해인 경우는 언제인가요?
1시간 윈도우 내 실제 적중 횟수가 3회 미만일 때, 1시간 캐시(2배 쓰기)의 프리미엄을 상쇄하기 어렵습니다. 예를 들어 특정 프롬프트가 사용자의 첫 접속과 종료 시에만 각각 한 번씩, 하루에 총 2번만 요청된다면 1시간 캐시를 켜는 것이 오히려 1배의 쓰기 프리미엄을 더 지불하게 됩니다. 이런 상황에서는 5분 캐시로 변경하거나 아예 캐시를 끄는 것이 좋습니다.
Q5: GPT의 자동 캐시는 제 프롬프트 데이터를 유출할 위험이 없나요?
OpenAI 문서는 캐시가 조직(organization) 단위로 격리되어 있으며 계정 간 공유되지 않는다고 명확히 밝히고 있습니다. Claude 또한 2026년 2월 5일부터 워크스페이스(workspace) 단위 격리로 더욱 강화되었습니다. 두 업체 모두 데이터 보안에 대한 약속이 일관되므로 기업용 사용자도 안심하고 사용할 수 있습니다. APIYI apiyi.com을 통해 접속하면 토큰 단위의 격리가 추가되어 보안이 더욱 강화됩니다.
Q6: 캐시 적중률은 어떻게 모니터링하나요? 두 업체 모두 관련 필드를 제공하나요?
OpenAI는 usage 객체 내에 cached_tokens 필드를 반환하며, Claude는 usage 내에 cache_creation_input_tokens(캐시 쓰기량)와 cache_read_input_tokens(적중량)를 반환합니다. 이 필드들을 비즈니스 로그에 기록하여 적중률 대시보드를 만든 후 TTL 전략을 조정하는 것을 추천합니다.
Q7: 프로젝트에서 GPT와 Claude를 동시에 사용한다면 토큰을 어떻게 구성하는 것이 좋을까요?
APIYI apiyi.com의 통합 토큰 방식을 추천합니다. 하나의 sk-xxx 토큰으로 GPT와 Claude를 모두 커버할 수 있습니다. 모델별로 청구서를 확인할 수 있어 각 업체에 따로 가입하고 잔액을 관리하며 정산하는 번거로움을 줄일 수 있습니다. 이러한 통합 접속 방식은 A/B 테스트를 통해 동일 업무에서 두 모델의 실제 비용을 비교하기에도 매우 편리합니다.
요약: 쓰기 프리미엄을 이해하는 것이 캐시 최적화의 첫걸음
본문의 핵심으로 돌아가 보겠습니다. GPT와 Claude의 캐시 비용 차이는 쓰기 측면의 프리미엄 모델에 있습니다. GPT는 "마찰 없는 자동 활성화, 쓰기 프리미엄 없음"을 선택했고, Claude는 "명시적 제어, 쓰기 프리미엄을 통한 더 세밀한 할인 공간 확보"를 선택했습니다. 두 방식에 절대적인 우열은 없으며, 비즈니스 트래픽 특성에 맞추는 것이 중요합니다.
높은 적중률과 안정적인 트래픽, 세밀한 제어가 필요한 환경이라면 Claude의 1.25배/2배 쓰기 프리미엄은 높은 적중률로 충분히 상쇄 가능하며, 5분/1시간 이중 TTL은 GPT가 제공하지 못하는 유연함을 줍니다. 반면 낮은 적중률과 돌발적인 트래픽, 즉시 사용 가능한 환경을 선호한다면 GPT의 자동 캐시 무프리미엄 모델이 가장 안전한 선택입니다.
🎯 최종 제안: 비용 최적화의 모범 사례는 하나만 선택하는 것이 아닙니다. APIYI apiyi.com을 통해 두 모델을 동시에 연동하고 비즈니스 시나리오에 따라 라우팅하세요. 고빈도 요청은 Claude 캐시로 할인을 챙기고, 저빈도 요청은 GPT 자동 캐시로 리스크를 방지하세요. 하나의 토큰, 하나의 청구서로 간편하게 비교하는 것이 2026년 기술 팀의 가장 효율적인 비용 관리 전략입니다.
— APIYI 기술팀 | 대규모 언어 모델 비용 동향을 지속적으로 추적합니다. 더 자세한 비교는 APIYI apiyi.com 도움말 센터에서 확인하세요.