Cache petunjuk (Prompt Caching) hampir menjadi topik biaya yang tak terelakkan bagi semua pengguna API Model Bahasa Besar di tahun 2026. Untuk aplikasi RAG yang menjalankan petunjuk sistem 8K, perbedaan antara menggunakan cache dan tidak bisa membuat tagihan bulanan membengkak hingga lebih dari 10 kali lipat. Namun, banyak pengembang yang beralih antara OpenAI dan Anthropic sering terjebak pada detail tersembunyi—model penagihan cache kedua perusahaan ini sangat berbeda.

Perbedaan paling krusial sebenarnya hanya satu kalimat: Penulisan cache seri GPT dikenakan biaya 1x harga dasar tanpa premi, sedangkan penulisan cache seri Claude dikenakan premi 1,25x (5 menit) atau 2x (1 jam). Perbedaan ini terlihat kecil, namun dalam lalu lintas bisnis nyata, hal ini akan secara signifikan memengaruhi titik impas (break-even point). Artikel ini merujuk pada dokumentasi resmi kedua perusahaan untuk memeriksa aturan penagihan, kondisi pemicu, diskon pembacaan, strategi TTL, dan perhitungan balik modal guna membantu Anda membuat estimasi biaya yang lebih akurat.
5 Perbedaan Utama Cache Petunjuk GPT vs Claude
Langsung ke kesimpulan. Tabel di bawah ini adalah bagian yang paling layak untuk disimpan, karena merangkum 5 poin kunci yang paling sering diabaikan dalam lapisan cache kedua penyedia layanan tersebut.
| Dimensi | OpenAI GPT | Anthropic Claude |
|---|---|---|
| Penagihan Penulisan | 1x harga dasar, tanpa premi | 5 menit: 1,25x; 1 jam: 2x |
| Penagihan Pembacaan | Sekitar 0,1x (diskon hingga 90%) | 0,1x (harga setelah diskon 10%) |
| Cara Pemicu | Otomatis, tanpa ubah kode | Eksplisit opt-in, butuh cache_control |
| Ambang Batas Token | Seragam 1024 token | 1024 / 2048 / 4096 (tergantung model) |
| TTL Cache | Default 5–10 menit idle, maks 1 jam; mode ekstensi 24 jam | Default 5 menit, opsi 1 jam (penulisan 2x) |
Kunci untuk memahami tabel ini ada pada baris "Penagihan Penulisan". Logika OpenAI adalah: cache gratis untuk Anda, penulisan pertama dikenakan harga dasar, dan hit berikutnya diberikan diskon. Jadi, selama terjadi satu kali hit, Anda langsung masuk ke zona keuntungan murni. Logika Claude adalah: penulisan harus membayar premi terlebih dahulu, lalu mendapatkan diskon setelah hit, sehingga butuh "cukup banyak hit" untuk menutup biaya premi tersebut.
🎯 Saran Konfigurasi: Jika lalu lintas bisnis Anda tidak dapat diprediksi dan tingkat hit tidak stabil, disarankan untuk memilih mekanisme cache otomatis GPT guna mengurangi risiko. Jika tingkat hit sangat stabil (seperti layanan pelanggan, Agen, atau analisis dokumen panjang), kontrol eksplisit Claude justru dapat memberikan diskon yang lebih tinggi. API APIYI (apiyi.com) telah mendukung kedua model ini, Anda dapat melakukan pengujian perbandingan dalam satu token yang sama untuk menghindari kerumitan membuka banyak akun.
Penjelasan Mendalam Mekanisme Penagihan Cache Petunjuk GPT OpenAI
Dokumentasi resmi OpenAI menyatakan dengan sangat lugas mengenai Prompt Caching: "Caching terjadi secara otomatis, tanpa perlu tindakan eksplisit atau biaya tambahan untuk menggunakan fitur caching." Artinya: aktif secara otomatis, tanpa biaya tambahan, dan tidak perlu mengubah satu baris kode pun.
Penagihan Penulisan dan Pembacaan Cache GPT
Seri GPT tidak mengenakan biaya premium untuk penulisan cache. Saat Anda mengirimkan petunjuk sistem (system prompt) sebesar 8K untuk pertama kalinya, biaya yang dikenakan adalah harga input dasar—sama persis dengan kondisi tanpa cache. Mulai permintaan kedua, jika sistem mendeteksi bahwa awalan (prefix) tersebut telah di-cache, bagian yang terkena cache akan dikenakan biaya sekitar 10% dari harga dasar, sehingga Anda hemat 90%.
| Item | Metode Penagihan | Rasio terhadap Harga Dasar |
|---|---|---|
| Penulisan cache pertama kali | Sesuai harga input dasar | 1x (tanpa premium) |
| Pembacaan cache (hit) | Diskon cache hit | sekitar 0,1x |
| Biaya aktivasi | Sepenuhnya gratis | 0 |
| Perubahan kode konfigurasi | Nol | Tidak perlu |
Besaran diskon aktual secara resmi dinyatakan sebagai "hingga 90%", dengan sedikit perbedaan tergantung pada model dan tabel penagihan. Sebagai contoh, harga input dasar GPT-5.4 adalah $2/1M, dan harga hit cache adalah $0,20/1M, yang tepat 10%. Model yang sudah mendukung seperti GPT-4.1, GPT-4o, dan lainnya pada dasarnya mengikuti rasio ini.
🎯 Pengecekan Harga: Karena iterasi model OpenAI yang sering, harga diskon hit aktual mengacu pada tabel penagihan resmi. Disarankan untuk langsung memeriksa harga yang berlaku di pusat model APIYI apiyi.com. Platform akan menyinkronkan penyesuaian resmi tanpa membebankan biaya layanan proksi API tambahan; pengembang cukup membayar sesuai penggunaan Token aktual.
Kondisi Hit Cache GPT
Untuk memicu hit cache, dua kondisi berikut harus dipenuhi secara bersamaan:
- Panjang petunjuk ≥ 1024 token (kurang dari jumlah ini tidak akan masuk ke cache).
- Awalan petunjuk harus benar-benar konsisten dengan permintaan historis, dengan hit yang dipotong dalam kelipatan 128 token.
OpenAI menetapkan granularitas minimum hit cache pada 128 token, yang berarti untuk awalan stabil sebesar 1500 token, selama 1024 token pertama benar-benar konsisten, bagian sisanya akan di-hit secara bertahap dalam kelipatan 128. Kelemahan dari desain otomatis ini adalah kontrol yang kurang fleksibel—pengembang tidak dapat secara eksplisit menentukan "bagian mana yang harus di-cache", sehingga semua konten stabil harus diletakkan di bagian depan.
Perilaku TTL Cache GPT
OpenAI memberikan deskripsi yang sangat krusial mengenai TTL: awalan cache biasanya akan dihapus setelah 5–10 menit tidak aktif, dengan masa retensi maksimal 1 jam. Model yang lebih baru seperti GPT-5 dan GPT-4.1 juga mendukung "retensi diperpanjang" (extended retention) hingga maksimal 24 jam.
🎯 Tips Penggunaan: Saat mengakses seri GPT melalui APIYI apiyi.com, strategi cache otomatis OpenAI bersifat transparan terhadap jalur layanan proksi API, dengan tingkat hit yang sama dengan endpoint resmi. Ini berarti Anda dapat mengelola tagihan dan token OpenAI serta Claude secara terpadu melalui APIYI tanpa menambah biaya apa pun.
Penjelasan Mendalam Mekanisme Penagihan Cache Petunjuk Claude Anthropic
Filosofi desain Claude benar-benar berlawanan dengan OpenAI—mereka menganggap cache sebagai "kemampuan optimasi yang dapat dikonfigurasi secara aktif". Pengembang harus menyatakan secara eksplisit konten mana yang akan di-cache dan berapa lama. Konsekuensinya, penulisan dikenakan biaya premium, namun imbalannya adalah granularitas kontrol yang sangat tinggi.
Biaya Premium Penulisan dan Diskon Pembacaan Cache Claude
| Item | Pengali Penagihan | Penjelasan |
|---|---|---|
| Penulisan 5 menit | 1,25x harga input dasar | TTL default, mencakup sebagian besar skenario |
| Penulisan 1 jam | 2x harga input dasar | Cocok untuk sesi panjang, Agent, dll. |
| Pembacaan cache (hit) | 0,1x harga input dasar | Diskon 90% |
| Biaya aktivasi | 0 | Tanpa biaya aktivasi tambahan |
| Perubahan konfigurasi | Wajib menambahkan cache_control |
Opt-in eksplisit |
Sebagai contoh intuitif: harga input dasar Claude Opus 4.7 adalah $5/1M, penulisan 5 menit menjadi $6,25/1M, penulisan 1 jam menjadi $10/1M, dan pembacaan hit hanya $0,50/1M. Tabel harga ini tertulis dalam dokumentasi resmi Anthropic dan telah stabil selama beberapa kuartal.
Ambang Batas Token Minimum Cache Claude
Jumlah token minimum yang dapat di-cache pada Claude bervariasi tergantung modelnya, dan ini adalah jebakan pertama yang sering dialami banyak orang.
| Model | Token Minimum yang Dapat Di-cache |
|---|---|
| Claude Opus 4.7 / 4.6 / 4.5 | 4096 |
| Claude Haiku 4.5 | 4096 |
| Claude Sonnet 4.6 | 2048 |
| Claude Sonnet 4.5 / Opus 4.1 / Sonnet 4 | 1024 |
Jika awalan stabil Anda kurang dari ambang batas minimum model tersebut, meskipun Anda telah menambahkan cache_control, konten tersebut tidak akan benar-benar masuk ke lapisan cache. Permintaan akan diproses secara diam-diam sebagai jalur non-cache—tidak akan ada pesan kesalahan, tetapi Anda mungkin mengira cache sudah aktif padahal belum. Hal ini sangat penting pada Opus 4.7: 4096 token bukanlah ambang batas yang rendah, sehingga skenario percakapan singkat hampir tidak bisa memanfaatkannya.
🎯 Saran Pemilihan Model: Jika panjang konteks bisnis tidak stabil, disarankan untuk memprioritaskan Claude Sonnet 4.5 atau 4.6 karena memiliki ambang batas minimum yang lebih rendah sehingga lebih mudah untuk mendapatkan hit. Melalui APIYI apiyi.com, Anda dapat beralih antara Sonnet dan Opus dengan satu klik untuk menghindari masalah ambang batas model yang menyebabkan cache tidak berfungsi.
Breakpoint dan Batasan Konkurensi Cache Claude
Claude memungkinkan pengaturan hingga 4 breakpoint cache dalam satu permintaan, di mana setiap breakpoint dapat menentukan TTL yang berbeda. Ini adalah kemampuan terkuat yang membedakan Claude dari GPT—Anda dapat mengatur "petunjuk sistem" dengan cache 1 jam, "potongan basis pengetahuan" dengan cache 5 menit, dan "konteks pengguna" tanpa cache, dengan penagihan dan masa kedaluwarsa yang terpisah untuk ketiga bagian tersebut.
Dalam skenario konkurensi, perlu diperhatikan satu hal: entri cache Claude hanya akan berlaku untuk permintaan lain setelah respons pertama mulai dikembalikan. Jika Anda mengirimkan N permintaan dengan awalan yang sama secara paralel, hanya yang pertama yang akan menulis ke cache, sementara N-1 sisanya tetap dikenakan biaya dasar tanpa diskon hit. Oleh karena itu, saat melakukan pemanggilan batch, Anda perlu mengirim satu permintaan terlebih dahulu untuk memicu penulisan cache sebelum mengirim permintaan paralel sisanya.
🎯 Saran Pemanggilan Batch: Saat memanggil Claude melalui APIYI apiyi.com, disarankan untuk mengirim satu permintaan "pemanasan" (warm-up) untuk memicu penulisan cache sebelum memulai batch konkurensi. Tunggu hingga respons mulai muncul sebelum melepaskan permintaan paralel lainnya untuk menghindari biaya premium penulisan berulang dan menghemat anggaran Anda.
Dampak Premi Penulisan terhadap Tagihan Aktual: Perhitungan Titik Impas
Bagian ini akan mengonversi rasio abstrak menjadi nilai uang yang konkret. Kita asumsikan ada petunjuk sistem yang stabil sebesar 10.000 tokens, yang diminta N kali dalam jendela waktu 1 jam, dengan output yang diseragamkan sebesar 500 tokens. Mari kita lihat total biaya kedua penyedia pada nilai N yang berbeda.
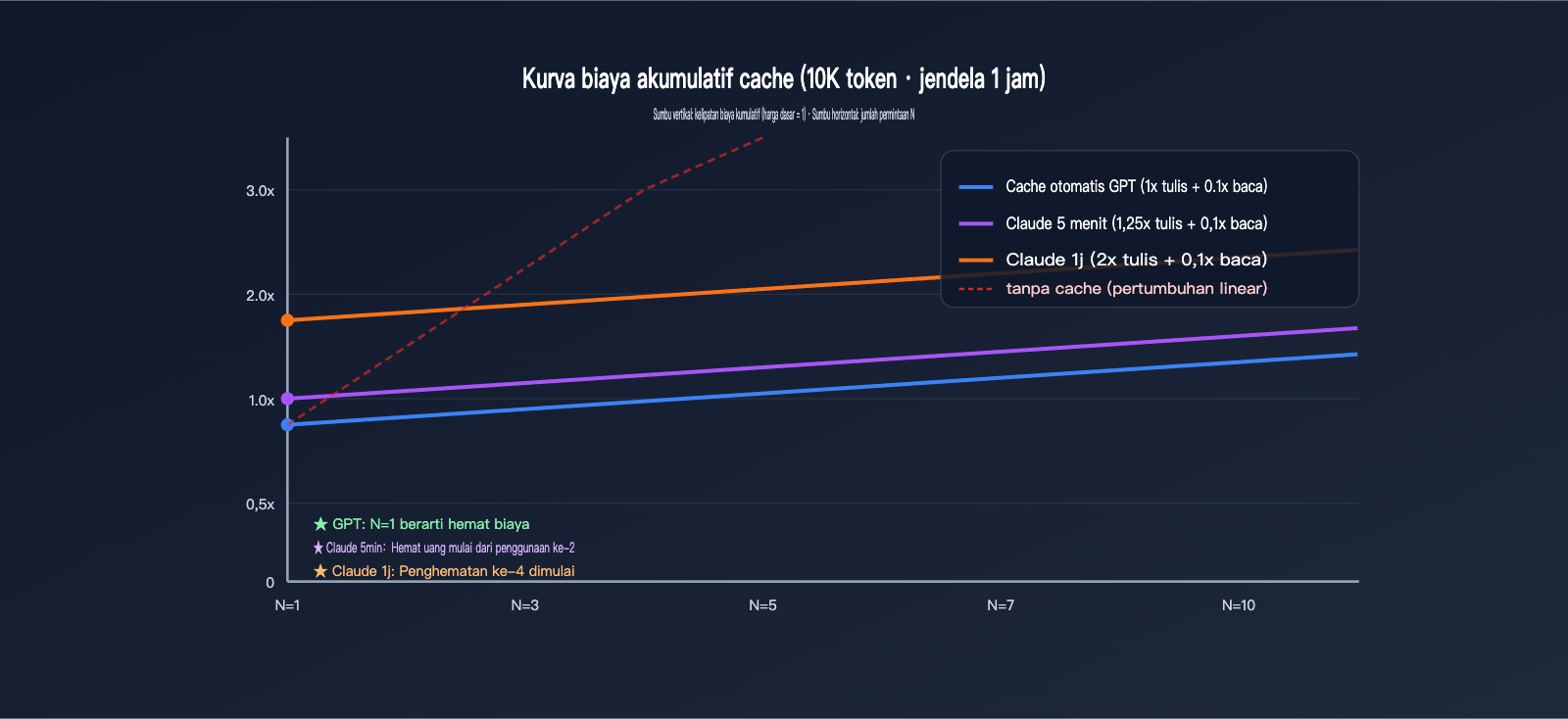
Untuk mempermudah perbandingan, asumsikan harga input dasar kedua penyedia dinormalisasi menjadi $X/1M tokens. Biaya dasar satu kali untuk 10.000 tokens = 10 × $X / 1000 = $0,01X. Di bawah ini kita hanya melihat bagian penagihan cache input, mengabaikan output (output dihitung berdasarkan harga masing-masing penyedia).
| Jumlah Permintaan N | Cache Otomatis GPT | Cache 5 menit Claude | Cache 1 jam Claude |
|---|---|---|---|
| N=1 (Penulisan pertama) | $0,01X | $0,0125X | $0,02X |
| N=2 | $0,011X | $0,0135X | $0,021X |
| N=5 | $0,014X | $0,0165X | $0,024X |
| N=10 | $0,019X | $0,0215X | $0,029X |
| Tanpa Cache (Referensi) | $0,01X × N | $0,01X × N | $0,01X × N |
| Bacaan untuk Balik Modal | 0 kali (Hemat sejak awal) | 1 kali (Hemat mulai ke-2) | 3 kali (Hemat mulai ke-4) |
Kita bisa melihat fakta kunci: Cache GPT sudah tidak rugi pada N=1—karena penulisan dikenakan biaya 1x, dan saat hit mendapatkan diskon, ini selalu menguntungkan. Cache 5 menit Claude membutuhkan setidaknya 1 kali hit untuk menutupi premi penulisan 0,25x, sedangkan cache 1 jam membutuhkan 3 kali hit. Jika awalan stabil Anda hanya hit 1 kali dalam sehari, menggunakan cache 1 jam Claude justru lebih mahal daripada tidak menggunakan cache sama sekali.
Cara Memilih TTL dalam Bisnis Nyata
Perhitungan ini memberikan saran praktis yang sangat jelas:
- Frekuensi rendah, tidak teratur: Prioritaskan cache otomatis GPT, hemat tanpa perlu berpikir.
- Frekuensi tinggi, sering hit dalam 5 menit (seperti percakapan layanan pelanggan, aplikasi Web): Cache 5 menit Claude memberikan keuntungan maksimal, premi penulisan kecil, diskon baca besar.
- Tugas panjang, penggunaan ulang lintas jam (seperti Coding Agent, percakapan dokumen panjang): Cache 1 jam Claude layak digunakan, tetapi pastikan setidaknya ada 3 kali hit.
- Tingkat hit tidak pasti: Selalu jalankan dengan 5 menit terlebih dahulu, setelah berjalan lancar baru pertimbangkan untuk beralih ke 1 jam.
🎯 Saran Perhitungan: Backend APIYI apiyi.com menyediakan statistik bidang
cached_tokensberdasarkan dimensi permintaan, Anda dapat langsung melihat tingkat hit aktual Anda. Disarankan untuk menjalankan lalu lintas produksi selama seminggu sebelum memutuskan untuk secara agresif menarik TTL ke 1 jam.
Rekomendasi Strategi Cache dalam Berbagai Skenario Bisnis
Setelah memahami perbedaan penagihan, barulah hal ini menjadi bermakna bagi bisnis Anda. Berikut adalah pengelompokan skenario umum berdasarkan strategi yang direkomendasikan.
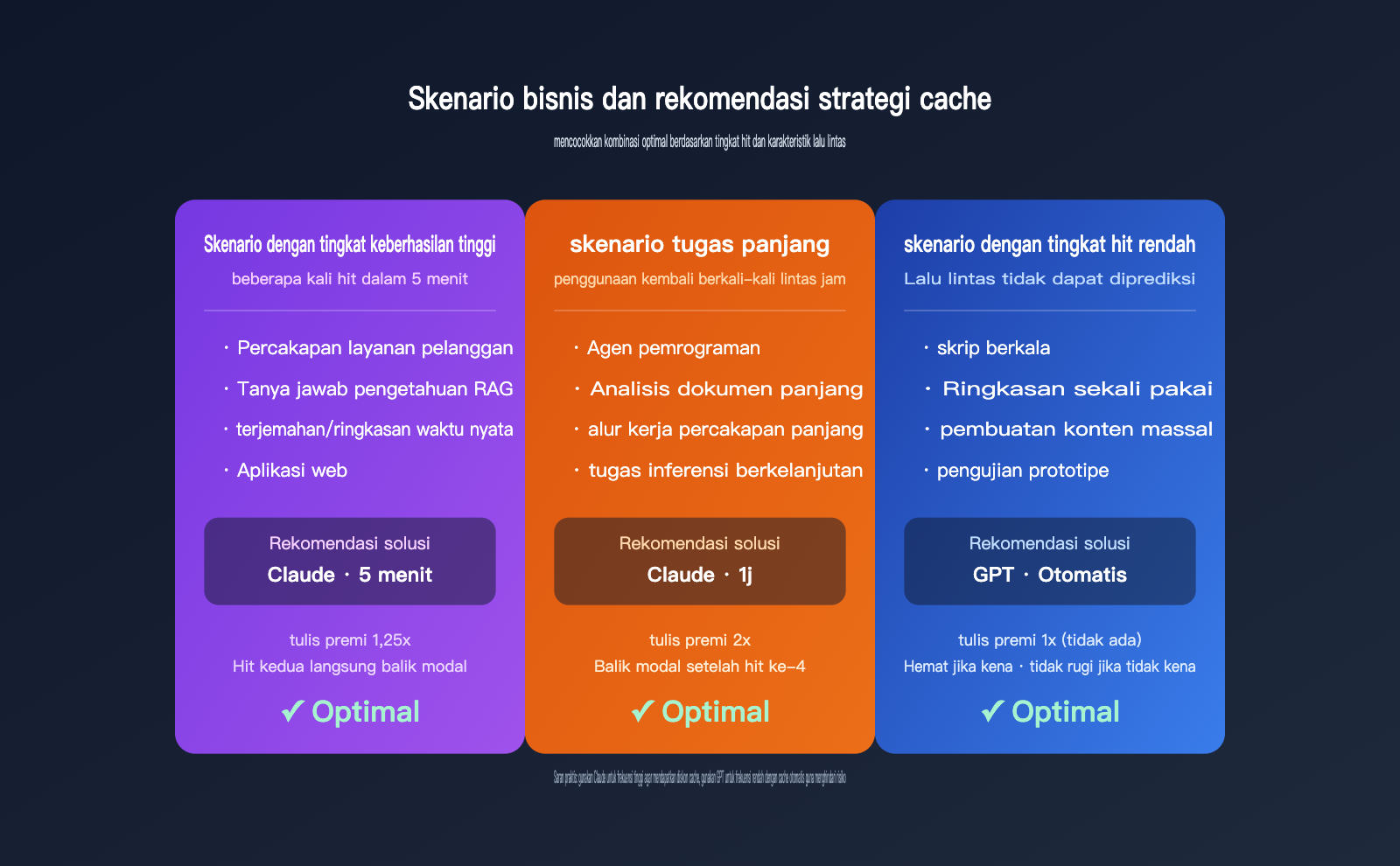
Skenario 1: RAG Frekuensi Tinggi dan Tanya Jawab Pengetahuan Perusahaan
Awalan stabil untuk skenario seperti ini biasanya berisi petunjuk sistem + potongan basis pengetahuan, dengan beberapa hit dalam satu sesi, dan jumlah permintaan kumulatif dalam 5 menit dengan mudah menembus angka 10. Cache 5 menit Claude dalam skenario ini dapat menekan biaya input hingga lebih dari 80%, yang paling hemat biaya. Jika sesi berlangsung 1 jam, pertimbangkan cache 1 jam.
Skenario 2: Agen Pemrograman dan Alur Kerja Tugas Panjang
Agen pengodean seperti Claude Code atau OpenCode, tugas tunggal mungkin berlangsung setengah jam atau bahkan beberapa jam, selama waktu tersebut berulang kali membaca struktur proyek, CLAUDE.md, dan hasil pemanggilan alat sebelumnya. Dalam skenario ini, cache 1 jam Claude adalah solusi optimal, karena jumlah hit jauh lebih tinggi daripada titik impas 3 kali.
Skenario 3: Permintaan Frekuensi Rendah atau Tidak Dapat Diprediksi
Misalnya skrip berkala, pembuatan artikel SEO massal, ringkasan dokumen panjang sekali pakai, interval setiap permintaan mungkin jauh melebihi 5 menit. Disarankan untuk memprioritaskan penggunaan seri GPT dengan cache otomatis, hit berarti untung, tidak hit pun tidak rugi, jauh lebih toleran terhadap kesalahan daripada cache eksplisit Claude.
Skenario 4: Kompresi Input Murni yang Sensitif terhadap Biaya
Jika tujuan utama Anda adalah menekan petunjuk 10K+ tokens ke biaya terendah, disarankan untuk langsung menggunakan Claude Sonnet 4.6 + cache 5 menit: premi penulisan hanya 25%, setelah hit hanya perlu 1 kali untuk balik modal, harga baca ditekan hingga $0,075/1M (dasar $3 × 0,025).
| Skenario Bisnis | Keluarga Model Rekomendasi | TTL Rekomendasi | Alasan |
|---|---|---|---|
| Layanan Pelanggan/RAG/Tanya Jawab Instan | Claude Sonnet | 5 menit | Hit sering, balik modal cepat |
| Pemrograman/Tugas Agen Panjang | Claude Sonnet/Opus | 1 jam | Hit lintas jam lebih dari 3 kali |
| Skrip Berkala/Pemrosesan Batch | GPT-4.1 / GPT-5.x | Otomatis | Hit tidak stabil, nol premi penulisan |
| Analisis Dokumen Panjang Sekali Pakai | GPT-5.x | Otomatis | Tugas tunggal, tingkat hit rendah |
| Skenario Sensitif Biaya Murni | Claude Sonnet 4.6 | 5 menit | Harga cache efektif terendah |
🎯 Saran Arsitektur Hibrida: Di lingkungan produksi, GPT dan Claude bukanlah pilihan "salah satu", melainkan kombinasi berdasarkan skenario. Disarankan untuk mengakses kedua model melalui satu pintu masuk APIYI apiyi.com, dan merutekan lalu lintas bisnis secara dinamis di frontend: hit tinggi menggunakan cache Claude, hit rendah menggunakan cache otomatis GPT, tagihan keseluruhan dapat ditekan hingga lebih dari 40%.
FAQ Pertanyaan Umum
Q1: Apakah GPT benar-benar tidak mengenakan biaya tambahan untuk penulisan cache? Apakah ada biaya tersembunyi?
Ya, dokumen resmi OpenAI menyatakan: "No. Caching happens automatically, with no explicit action needed or extra cost paid to use the caching feature." Penulisan cache ditagihkan sesuai harga input dasar tanpa biaya tambahan tersembunyi. Anda hanya membayar harga diskon untuk bagian yang terkena hit (terpakai), dan bagian yang tidak terkena hit dibayar dengan harga dasar. Bisa dibilang fitur cache ini diberikan secara "gratis".
Q2: Apakah biaya tambahan penulisan 1,25x dan 2x pada Claude dihitung berdasarkan seluruh petunjuk atau hanya bagian cache saja?
Hanya bagian yang ditandai dengan cache_control yang dihitung. Misalnya, dari 10K petunjuk hanya 8K yang ditandai untuk cache, maka biaya tambahan 1,25x hanya berlaku untuk 8K tersebut, sedangkan 2K sisanya tetap mengikuti harga dasar 1x. Oleh karena itu, disarankan untuk mengatur breakpoint dengan cermat agar tidak memasukkan konten yang tidak perlu ke dalam biaya tambahan.
Q3: Apakah layanan proksi API APIYI meneruskan penagihan cache dari kedua penyedia secara transparan?
APIYI apiyi.com meneruskan penagihan cache GPT dan Claude secara asli (transparan). Diskon hit otomatis pada GPT, serta penulisan 1,25x/2x dan pembacaan 0,1x pada Claude, semuanya sesuai dengan tagihan resmi. Bidang cache_control juga didukung, sehingga pengembang dapat langsung menggunakan kembali kode SDK resmi.
Q4: Kapan penggunaan cache 1 jam pada Claude justru lebih merugikan daripada tidak menggunakan cache sama sekali?
Jika jumlah hit aktual dalam jendela 1 jam kurang dari 3 kali, biaya tambahan cache 1 jam (penulisan 2x) tidak akan tertutupi. Misalnya, jika suatu petunjuk hanya diminta sekali saat pengguna masuk dan sekali saat keluar (total 2 kali sehari), mengaktifkan cache 1 jam justru akan memakan biaya tambahan penulisan 1x lebih banyak daripada tidak mengaktifkannya sama sekali. Dalam skenario ini, sebaiknya gunakan cache 5 menit atau matikan cache sepenuhnya.
Q5: Apakah cache otomatis GPT akan membocorkan data petunjuk saya?
Dokumen OpenAI dengan jelas menyatakan bahwa cache diisolasi berdasarkan dimensi organisasi dan tidak dibagikan antar akun. Sejak 5 Februari 2026, Claude juga memperketat isolasi ke tingkat workspace. Komitmen kedua perusahaan terhadap keamanan data pada dasarnya sama, sehingga pengguna tingkat perusahaan dapat menggunakannya dengan tenang. Saat mengakses melalui APIYI apiyi.com, isolasi tingkat token akan semakin memperkuat perlindungan ini.
Q6: Bagaimana cara memantau rasio hit cache? Apakah keduanya menyediakan bidang untuk itu?
OpenAI mengembalikan bidang cached_tokens dalam objek usage, sedangkan Claude mengembalikan cache_creation_input_tokens dan cache_read_input_tokens dalam usage. Yang pertama menunjukkan jumlah penulisan cache, dan yang kedua adalah jumlah hit. Disarankan untuk mencatat kedua bidang ini ke dalam log bisnis Anda untuk membuat dasbor rasio hit sebelum menyesuaikan strategi TTL.
Q7: Jika proyek menggunakan GPT dan Claude secara bersamaan, bagaimana sebaiknya konfigurasi token dilakukan?
Kami merekomendasikan solusi token terpadu dari APIYI apiyi.com, di mana satu sk-xxx dapat mencakup GPT dan Claude sekaligus. Tagihan di latar belakang dapat dilihat per model, sehingga menghindari kerumitan mengelola akun, saldo, dan rekonsiliasi secara terpisah. Akses terpadu ini juga memudahkan pengalihan A/B untuk membandingkan biaya aktual kedua model pada bisnis yang sama.
Kesimpulan: Memahami Biaya Tambahan Penulisan adalah Langkah Pertama Optimasi Cache
Kembali ke poin utama artikel ini: Perbedaan mendasar antara penagihan cache GPT dan Claude terletak pada model biaya tambahan di sisi penulisan—GPT memilih "aktif otomatis tanpa hambatan, tanpa biaya tambahan penulisan", sementara Claude memilih "kontrol eksplisit, menukar biaya tambahan penulisan dengan ruang diskon yang lebih detail". Tidak ada yang mutlak lebih baik, kuncinya adalah menyesuaikan dengan karakteristik lalu lintas bisnis Anda.
Jika aplikasi Anda memiliki lalu lintas yang stabil dengan hit tinggi dan memerlukan kontrol presisi, biaya tambahan penulisan 1,25x / 2x pada Claude dapat dengan mudah ditutupi oleh rasio hit yang tinggi, ditambah fleksibilitas TTL ganda 5 menit/1 jam yang tidak dimiliki GPT. Jika aplikasi Anda memiliki lalu lintas rendah, tidak menentu, dan mengutamakan kemudahan penggunaan, model cache otomatis tanpa biaya tambahan dari GPT adalah pilihan yang paling aman.
🎯 Saran Akhir: Praktik terbaik untuk optimasi biaya adalah tidak memilih salah satu. Kami menyarankan untuk mengakses kedua model melalui APIYI apiyi.com dan melakukan routing berdasarkan skenario bisnis—gunakan Claude untuk frekuensi tinggi guna mengejar diskon cache, dan gunakan GPT untuk frekuensi rendah guna menghindari risiko. Satu token, satu tagihan, perbandingan yang mudah; ini adalah cara paling efisien bagi tim teknis di tahun 2026 untuk mengelola biaya.
— Tim Teknis APIYI | Terus melacak dinamika penagihan Model Bahasa Besar, lihat perbandingan mendalam lainnya di pusat bantuan APIYI apiyi.com