Le 1er juin 2026, MiniMax a officiellement lancé son nouveau fleuron open-source : MiniMax-M3. C'est le premier modèle à poids ouverts de l'industrie à combiner trois capacités majeures en un seul modèle : des performances de programmation de pointe, une fenêtre de contexte de 1 million de jetons et une entrée multimodale native. Avec un score de 59,0 sur SWE-Bench Pro, il surpasse directement GPT-5.5 et Gemini 3.1 Pro, se rapprochant ainsi du niveau de Claude Opus 4.7.
Le prix est encore plus percutant. Le tarif officiel standard est de 0,60 $ en entrée / 2,40 $ en sortie pour 1 million de jetons, ce qui ne représente que 5 à 10 % du prix des modèles fermés équivalents. Pour le lancement, une réduction temporaire de 50 % est appliquée, ramenant le coût à 0,30 $ en entrée / 1,20 $ en sortie. Actuellement, MiniMax-M3 est disponible sur la plateforme APIYI (apiyi.com), aligné sur le prix promotionnel de 50 %, avec des bonus de recharge permettant d'atteindre un coût réel réduit d'environ 59 %. L'offre est valable jusqu'au 8 juin à minuit (UTC+8).
Cet article détaille les points forts de l'architecture, les résultats des benchmarks, la tarification et le code d'intégration pour vous aider à décider s'il est temps de migrer vers ce modèle pendant la période promotionnelle.

Qu'est-ce que MiniMax-M3 : le fleuron "trois-en-un" du camp open-source
MiniMax-M3 est le nouveau fleuron de MiniMax, succédant à la série M2, positionné comme un modèle généraliste orienté vers la programmation et les agents. Il utilise une architecture MoE (mélange d'experts) à granularité fine, avec environ 229,9 milliards de paramètres au total, dont environ 9,8 milliards sont activés par jeton, répartis sur 256 experts. Cela signifie que son coût d'inférence est plus proche d'un petit modèle de 10 milliards de paramètres, tout en offrant des capacités comparables aux meilleurs modèles de première catégorie.
Entraîné sur environ 100 000 milliards de jetons, il intègre des données entrelacées texte-image dès la phase de pré-entraînement. Ainsi, le multimodal de MiniMax-M3 est "natif" : les capacités de compréhension d'images et de vidéos sont directement intégrées dans l'espace sémantique, et non ajoutées via un encodeur visuel externe. Outre les entrées images et vidéos, il prend en charge l'utilisation d'ordinateurs (Computer Use), offrant ainsi des interfaces adaptées aux scénarios d'agents.
La société s'est engagée à rendre les poids du modèle et le rapport technique entièrement open-source dans les 10 jours suivant le lancement. Ils seront disponibles sur HuggingFace et GitHub, permettant le déploiement privé et le réglage fin (fine-tuning). En se référant à la licence MIT modifiée utilisée pour la série M2, le seuil d'utilisation commerciale devrait être très bas, sous réserve de la licence officielle lors de la publication.
Aperçu des spécifications clés de MiniMax-M3
| Dimension | Spécifications MiniMax-M3 |
|---|---|
| Date de lancement | 1er juin 2026 |
| Architecture | MoE à granularité fine, 229,9B paramètres totaux / 9,8B activés, 256 experts |
| Mécanisme d'attention | MSA (MiniMax Sparse Attention) |
| Fenêtre de contexte | 1 000 000 jetons (environ 5 fois la série M2) |
| Support modal | Entrée texte + image + vidéo, sortie texte, supporte les opérations sur ordinateur |
| Données d'entraînement | Environ 100T jetons, corpus multimodal entrelacé texte-image |
| Mode de réflexion | Mode "Thinking" activable, prix identique |
| Plan open-source | Ouverture des poids et du rapport technique sous 10 jours |
🎯 Conseil pour une expérience rapide : Si vous souhaitez vérifier immédiatement le niveau réel de MiniMax-M3, inutile d'attendre la publication des poids pour construire votre propre cluster. Nous vous recommandons de l'appeler directement via l'interface compatible OpenAI d'APIYI (apiyi.com) en utilisant le nom de modèle
MiniMax-M3. Vous pourrez effectuer des tests comparatifs en quelques minutes, et réduire vos coûts de moitié pendant la période promotionnelle.
Que signifie le score de 59,0 de MiniMax-M3 au benchmark SWE-Bench Pro ?
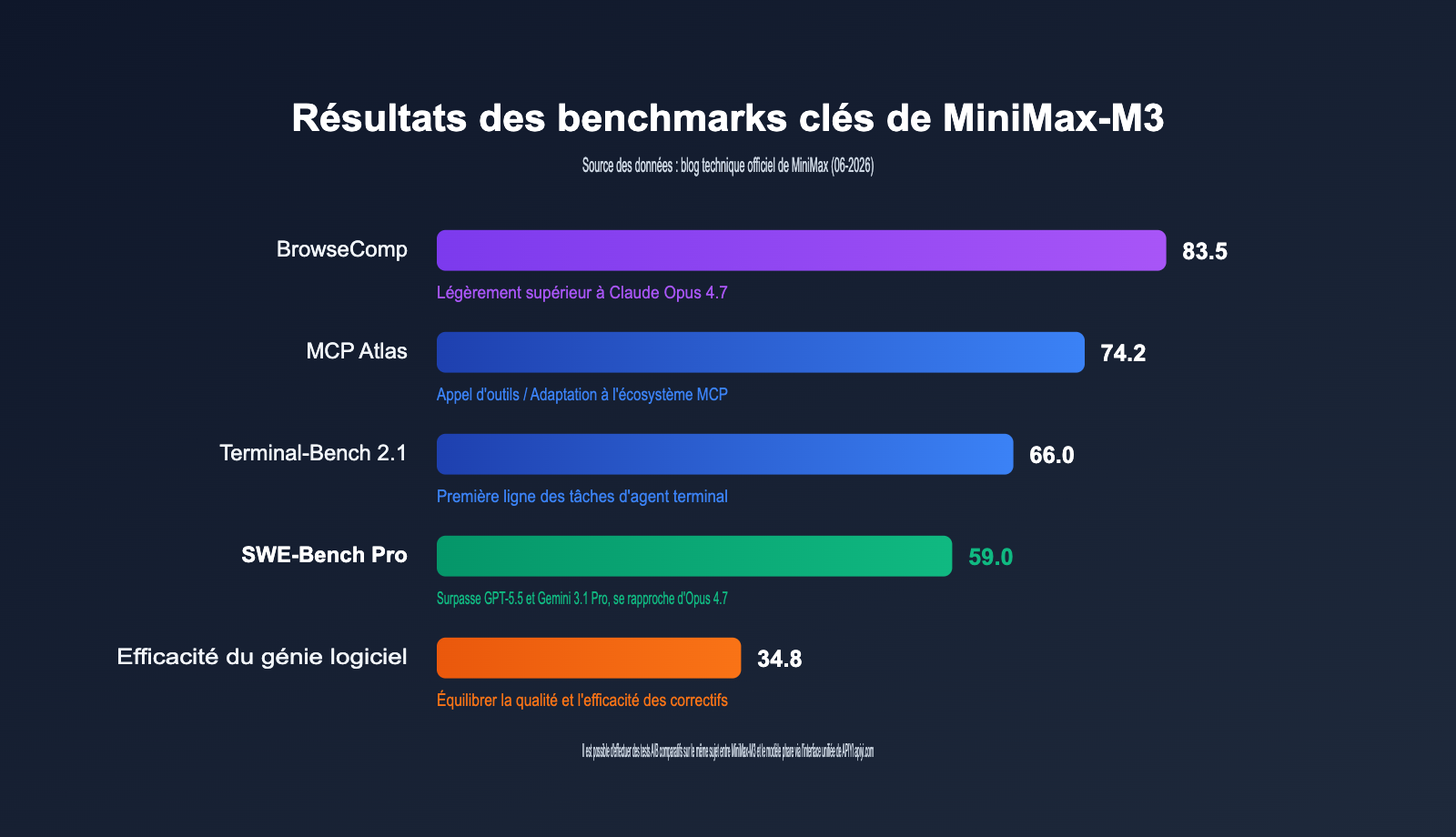
Le SWE-Bench Pro est actuellement reconnu comme l'un des benchmarks d'ingénierie logicielle réelle les plus exigeants. Il évalue la capacité de bout en bout d'un modèle à corriger des bugs et à rédiger des correctifs au sein de véritables dépôts de code. Avec un score de 59,0, les données officielles montrent que MiniMax-M3 surpasse à la fois GPT-5.5 et Gemini 3.1 Pro, et talonne de près Claude Opus 4.7. Pour un modèle bientôt open source avec moins de 10 milliards de paramètres activés, c'est la première fois que le camp open source dépasse les fleurons propriétaires sur ce benchmark.
Au-delà de la programmation, les indicateurs liés aux agents sont tout aussi impressionnants. Il obtient 66,0 points au Terminal-Bench 2.1, 74,2 points au MCP Atlas, et 83,5 points sur les tâches de navigation autonome BrowseComp — ce dernier score dépassant même légèrement celui de Claude Opus 4.7. Sur le plan multimodal, il surpasse Opus 4.7 au SVG-Bench et dépasse Gemini 3.1 Pro au benchmark de compréhension de documents OmniDocBench.
Bien sûr, il ne domine pas tout. Sur le PostTrainBench, qui évalue les capacités de post-entraînement scientifique, MiniMax-M3 obtient 0,37, ce qui est inférieur aux 0,42 de Claude Opus 4.7 et globalement équivalent aux 0,39 de GPT-5.5. Un rappel important : ces chiffres proviennent principalement du blog technique officiel ; des tests indépendants tiers sont en cours. Pour vos besoins critiques, nous vous conseillons d'effectuer vos propres évaluations.
Comparaison de MiniMax-M3 avec les principaux modèles phares
| Benchmark | MiniMax-M3 | Conclusion comparative |
|---|---|---|
| SWE-Bench Pro | 59,0 | Dépasse GPT-5.5 et Gemini 3.1 Pro, approche Opus 4.7 |
| Terminal-Bench 2.1 | 66,0 | Premier rang pour les tâches d'agent en terminal |
| BrowseComp | 83,5 | Dépasse légèrement Claude Opus 4.7 |
| MCP Atlas | 74,2 | Forte capacité d'appel d'outils et d'adaptation à l'écosystème MCP |
| SWE-fficiency | 34,8 | Équilibre entre qualité des correctifs et efficacité |
| PostTrainBench | 0,37 | Inférieur à Opus 4.7 (0,42), égal à GPT-5.5 (0,39) |
Si vous souhaitez vérifier ces chiffres par vous-même, vous pouvez utiliser la plateforme APIYI pour invoquer simultanément MiniMax-M3, GPT-5.5 et Claude Opus 4.7 avec la même invite. La plateforme unifie le format de l'interface, et il suffit de modifier un paramètre model pour changer de modèle, ce qui est idéal pour les tests A/B.
Analyse de l'architecture MiniMax-M3 : comment l'attention creuse MSA permet de gérer 1M de contexte
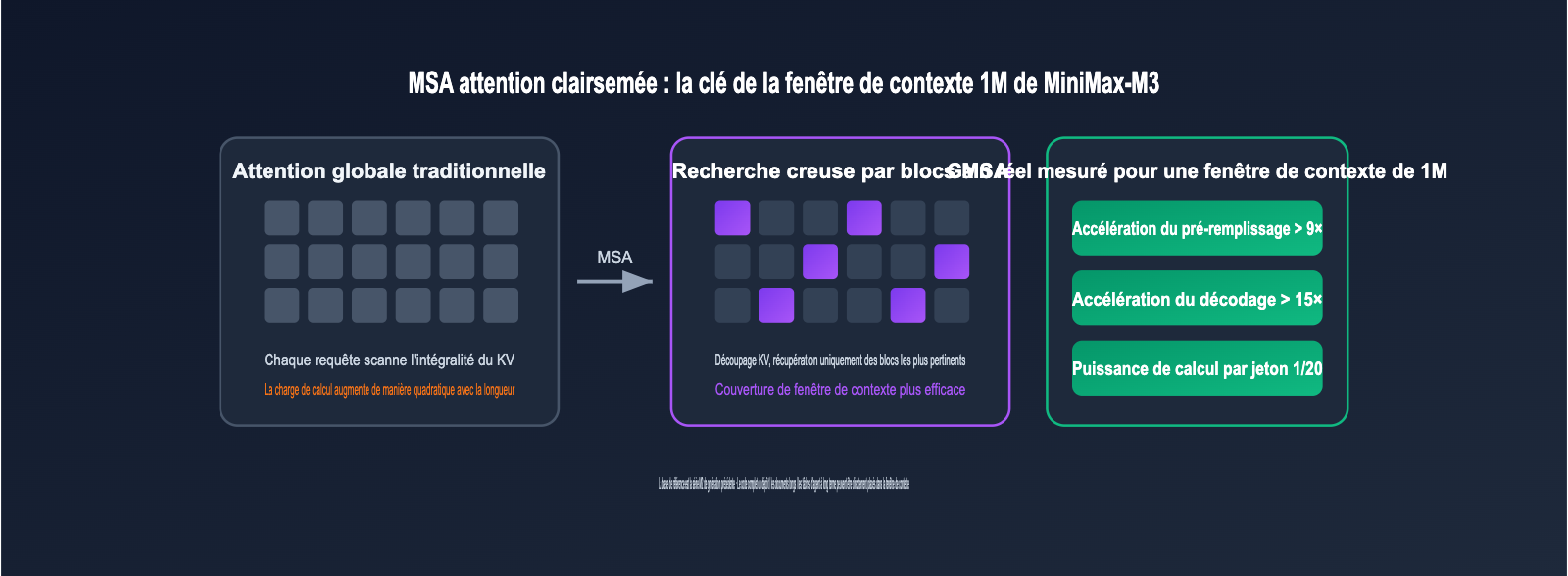
Une fenêtre de contexte d'un million de jetons n'est pas une nouveauté, mais la rendre économiquement viable l'est. La réponse de MiniMax-M3 est le MSA (MiniMax Sparse Attention) développé en interne. Le calcul de l'attention totale traditionnelle croît de manière quadratique avec la longueur du contexte, tandis que le MSA découpe le cache KV en blocs. Chaque requête récupère précisément les blocs KV les plus pertinents, permettant une couverture de contexte effective bien plus élevée.
Les données techniques fournies sont assez impressionnantes : avec un contexte de 1M de jetons, la charge de calcul par jeton de MiniMax-M3 est 20 fois inférieure à celle de la génération précédente M2 ; le pré-remplissage (prefill) est accéléré de plus de 9 fois, et le décodage (decode) de plus de 15 fois ; au niveau des opérateurs, il est 4 fois plus rapide que le Flash-Sparse-Attention open source. En d'autres termes, intégrer tout un dépôt de code, des centaines de pages PDF ou une heure de vidéo de réunion dans le contexte ne pose plus de problème de latence ou de coût.
Pour les développeurs, cela signifie concrètement que de nombreuses tâches sur de longs documents qui nécessitaient auparavant du découpage RAG, de la recherche vectorielle ou des résumés multi-étapes peuvent désormais être traitées en une seule fois directement dans l'invite. Les tâches d'agent à long terme n'ont plus besoin de compresser fréquemment l'historique, ce qui améliore considérablement la cohérence des tâches.
💡 Conseil pour les tests de contexte long : La facturation du contexte de 1M est divisée en deux paliers, le prix unitaire doublant au-delà de 512K jetons en entrée. Nous vous suggérons de tester d'abord les résultats sur la console APIYI (apiyi.com) avec des documents réels de 200K à 400K jetons. Une fois la qualité validée, vous pourrez passer à des entrées plus longues. Les statistiques d'utilisation de la plateforme vous aideront à calculer précisément le coût en jetons de chaque invocation.
Tarifs de l'API MiniMax-M3 : -50 % temporaire + bonus de recharge pour un coût réel d'environ 41 %
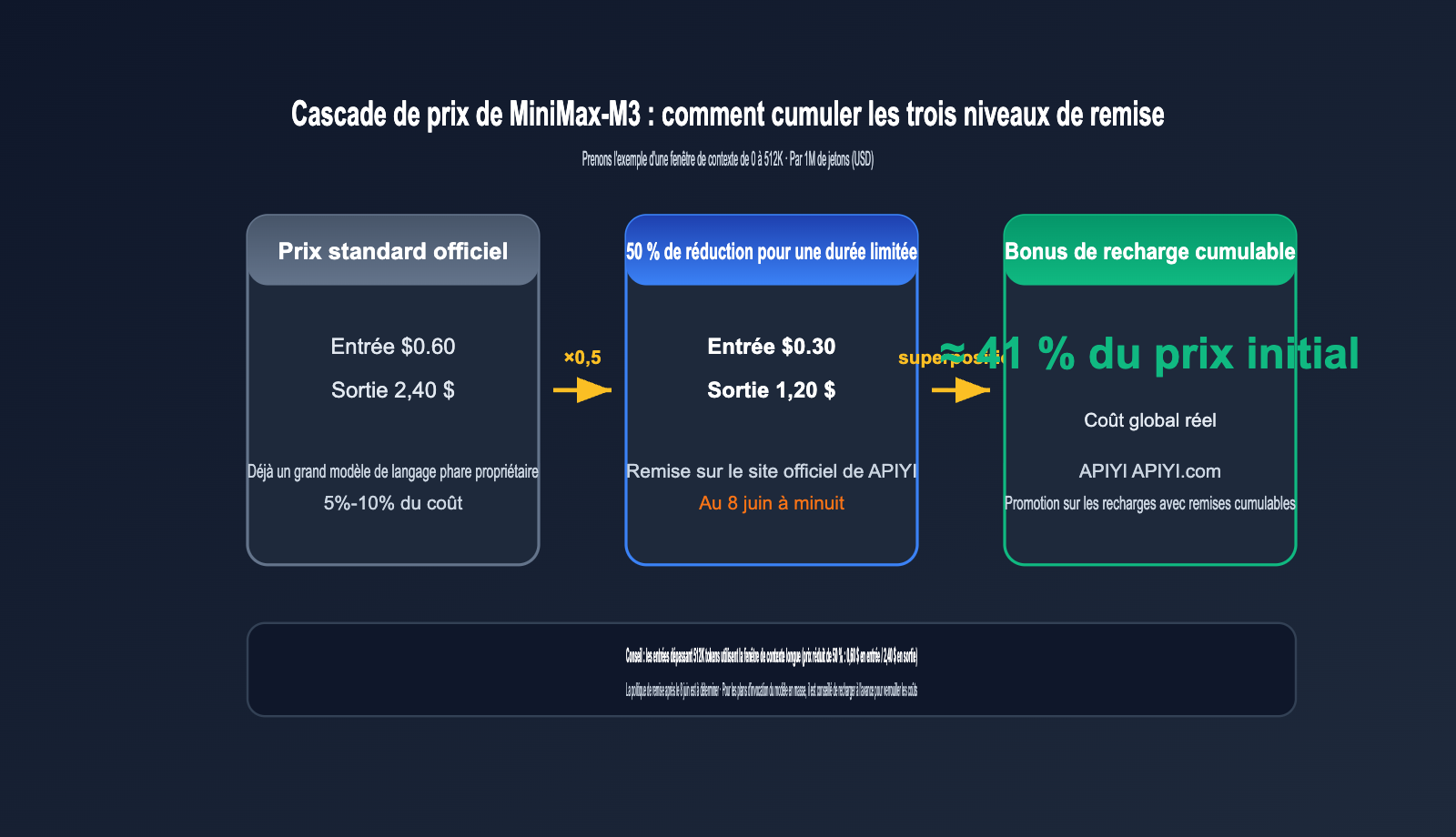
La tarification de MiniMax-M3 repose sur un modèle par paliers basé sur la longueur de l'entrée. Les entrées de 0 à 512K tokens suivent le tarif standard, tandis que celles dépassant 512K relèvent du tarif "long contexte". Durant la période de lancement, une remise de 50 % est appliquée sur toute la gamme. APIYI (apiyi.com) a aligné ses tarifs sur cette remise officielle. Cette offre est valable jusqu'au 8 juin 2026 à minuit (UTC+8) ; la politique tarifaire ultérieure reste à définir.
Grille tarifaire de l'API MiniMax-M3 (par 1M de tokens)
| Palier de facturation | Entrée (prix remisé -50 %) | Sortie (prix remisé -50 %) | Prix standard après remise (Entrée/Sortie) |
|---|---|---|---|
| Entrée 0-512K | 0,30 $ | 1,20 $ | 0,60 $ / 2,40 $ |
| Entrée > 512K | 0,60 $ | 2,40 $ | 1,20 $ / 4,80 $ |
Pour vous donner une idée concrète : pour une tâche de revue de code d'un million de tokens, un modèle propriétaire haut de gamme pourrait vous coûter plus de dix dollars, alors que le MiniMax-M3 ne vous coûtera que quelques dizaines de cents en période promotionnelle, soit un écart de coût de 10 à 20 fois. Pour les pipelines d'agents à haute fréquence, la migration de code en masse ou le traitement de longs documents, cette économie peut financer une machine de développement en un mois.
Sur la plateforme APIYI, vous pouvez réduire encore davantage vos coûts. Les bonus de recharge de la plateforme sont cumulables avec la remise de 50 % sur les modèles, permettant d'atteindre un coût réel d'environ 41 % du tarif initial. Si votre équipe a un volume d'invocation du modèle stable, recharger votre compte avant le 8 juin est l'option la plus rentable.
Démarrage rapide avec l'API MiniMax-M3 : connexion en 5 minutes
MiniMax-M3 utilise le protocole standard compatible OpenAI sur la plateforme APIYI. Tout SDK, framework ou client prenant en charge une base_url personnalisée peut s'y connecter sans problème. Seul point d'attention : le nom du modèle MiniMax-M3 est sensible à la casse, le M doit être en majuscule. Utiliser minimax-m3 provoquera une erreur de modèle inexistant.
La connexion se fait en trois étapes : inscrivez-vous sur APIYI (apiyi.com) et créez une clé API ; pointez la base_url vers https://api.apiyi.com/v1 ; et renseignez le paramètre model avec MiniMax-M3. Voici l'exemple Python le plus simple :
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1" # Interface unifiée APIYI
)
response = client.chat.completions.create(
model="MiniMax-M3", # Attention à la casse, le M doit être en majuscule
messages=[
{"role": "user", "content": "Implémente une fonction Fibonacci avec cache LRU en Python"}
]
)
print(response.choices[0].message.content)
Pour transmettre des images ou des vidéos, utilisez le format de message multimodal d'OpenAI en remplaçant content par un tableau incluant image_url. MiniMax-M3 effectuera la compréhension visuelle et la génération de code dans la même session. Pour les outils d'agents comme Cline, Cursor ou OpenClaw, il suffit de modifier la base_url et le nom du modèle dans les paramètres pour remplacer le moteur de votre assistant de programmation par MiniMax-M3.
Guide rapide des cas d'usage de MiniMax-M3
| Cas d'usage | Adaptabilité | Note |
|---|---|---|
| Programmation par agent / Correction de bugs | ⭐⭐⭐⭐⭐ | SWE-Bench Pro 59.0, conserve le contexte sur les tâches longues |
| Analyse et migration de dépôts de code complets | ⭐⭐⭐⭐⭐ | 1M de contexte permet d'accueillir un dépôt de taille moyenne |
| Analyse de documents longs / multimodaux | ⭐⭐⭐⭐⭐ | OmniDocBench dépasse Gemini 3.1 Pro |
| Agent de navigation autonome et appel d'outils | ⭐⭐⭐⭐ | BrowseComp 83.5, MCP Atlas 74.2 |
| Post-entraînement scientifique / Raisonnement avancé | ⭐⭐⭐ | PostTrainBench inférieur à Opus 4.7, routage mixte recommandé |
Le routage mixte est l'approche la plus pragmatique : confiez 80 % des tâches quotidiennes de codage et de documents à MiniMax-M3, et réservez les tâches de raisonnement les plus complexes à Claude Opus 4.7 ou GPT-5.5. Grâce à l'interface unifiée d'APIYI, une seule base de code permet de mettre en œuvre cette stratégie de "rentabilité par palier", sans avoir à gérer les clés et SDK de multiples fournisseurs.
FAQ : Questions fréquentes sur MiniMax-M3
Q1 : Quand se termine l'offre de réduction de 50 % sur MiniMax-M3 ?
L'offre prend fin le 8 juin 2026 à minuit (UTC+8), en synchronisation avec le site officiel de MiniMax et la plateforme APIYI. Aucune information n'a été communiquée sur la politique tarifaire ultérieure, mais il est probable que les tarifs standards soient rétablis. Si vous prévoyez des invocations de modèle en volume, nous vous conseillons d'effectuer vos rechargements avant cette date limite ; en cumulant les bonus de recharge, le coût réel peut descendre jusqu'à environ 41 % du tarif initial.
Q2 : MiniMax-M3 est-il réellement open source ? Peut-on télécharger les poids dès maintenant ?
L'équipe officielle s'est engagée à publier les poids du modèle et le rapport technique dans les 10 jours suivant le lancement, probablement sur la page HuggingFace de MiniMaxAI. À l'heure où nous écrivons ces lignes, les poids n'ont pas encore été mis en ligne. Les équipes qui ne peuvent pas attendre pour un déploiement local peuvent commencer par tester les performances via l'API, puis évaluer les besoins matériels pour une instance privée — avec 230 milliards de paramètres MoE, les exigences en mémoire vidéo (VRAM) pour un déploiement local sont loin d'être négligeables.
Q3 : La fenêtre de contexte de 1M est-elle un argument marketing ou est-elle réellement utilisable ?
L'architecture MSA rend la fenêtre de contexte de 1M réellement exploitable sur le plan technique : la vitesse de pré-remplissage (prefill) est multipliée par plus de 9, la vitesse de décodage par 15, et la charge de calcul par jeton est réduite à 1/20e par rapport à la génération précédente. Attention toutefois aux paliers de facturation : au-delà de 512K en entrée, le prix unitaire double. Il est donc conseillé de gérer la longueur du contexte en fonction des besoins réels de la tâche plutôt que de le remplir inutilement.
Q4 : Comment choisir entre MiniMax-M3, GPT-5.5 et Claude Opus 4.7 ?
Tout dépend du type de tâche et de votre budget. Pour les agents de programmation, les contextes longs et les scénarios multimodaux, le rapport qualité-prix de MiniMax-M3 est actuellement sans égal. Pour les tâches de raisonnement complexe de haut niveau et la recherche scientifique, Opus 4.7 conserve un avantage. Nous vous recommandons d'effectuer des tests comparatifs à petite échelle sur la plateforme APIYI avec vos propres invites (prompts) ; les données seront bien plus probantes que n'importe quel classement.
Conclusion : MiniMax-M3 rend les capacités "flagship" accessibles à tous
Le lancement de MiniMax-M3 a fait l'effet d'une bombe sur le marché des modèles en 2026 : poids open source, score de 59,0 sur SWE-Bench Pro (dépassant GPT-5.5), fenêtre de contexte d'un million de jetons et multimodalité native, le tout pour un prix officiel représentant seulement 5 à 10 % de celui des modèles propriétaires haut de gamme. Même si des tests tiers venaient à nuancer certains scores, sa domination en termes de "rapport qualité-prix" sera difficile à contester.
À court terme, la fenêtre tarifaire est l'opportunité à saisir : la réduction de 50 % (0,30 $ en entrée / 1,20 $ en sortie par million de jetons) est valable jusqu'au 8 juin à minuit. Sur APIYI (apiyi.com), vous pouvez cumuler cette offre avec les bonus de recharge pour atteindre un coût réel d'environ 41 %. La stratégie la plus prudente consiste à lancer vos tests avec un coût minimal avant de décider de basculer vos flux de production.
Pour plus de détails sur l'offre et les dernières actualités du modèle, consultez l'annonce officielle d'APIYI : docs.apiyi.com/news/minimax-m3-launch
Auteur : Équipe APIYI
Spécialistes de l'agrégation d'API de grands modèles de langage et des meilleures pratiques. Pour plus d'évaluations de modèles et de guides d'intégration, visitez APIYI sur apiyi.com.