Le 11 mai 2026, plusieurs utilisateurs de Reddit ont découvert une carte de modèle nommée « Omni » dans l'interface de l'application Gemini. La description indiquait : « Create with Gemini Omni: meet our new video model, remix your videos, edit directly in chat, try templates, and more ». Bien que Google n'ait pas encore fait de déclaration officielle, cette fuite a propulsé Gemini Omni sous le feu des projecteurs, à seulement une semaine de la Google I/O 2026 prévue les 19 et 20 mai.
Cet article s'appuie sur les derniers rapports de médias anglophones tels que 9to5google, TestingCatalog, ChromeUnboxed, Digit et WaveSpeed pour synthétiser les informations confirmées sur le modèle vidéo Gemini Omni en 8 points clés, couvrant le positionnement du produit, ses capacités fondamentales, ses limites de performance et son calendrier de lancement. Pour les développeurs et les équipes de contenu qui souhaitent anticiper les orientations technologiques avant la conférence, considérez ceci comme une note d'information factuelle plutôt que comme un recueil de spéculations.
Valeur ajoutée : Comprenez en 3 minutes le positionnement, les capacités, les performances et le calendrier de sortie de Gemini Omni, ainsi que les recommandations à adopter avant la Google I/O 2026.

Aperçu des informations clés sur le modèle vidéo Gemini Omni
Pour bien comprendre Gemini Omni, il faut d'abord distinguer les faits des suppositions. Le tableau ci-dessous regroupe les informations essentielles vérifiées par six médias anglophones pour éviter de se perdre dans les rumeurs éparses.
| Élément | Détails |
|---|---|
| Première apparition | 11/05/2026, apparition de la carte du modèle Omni dans l'interface Gemini |
| Source de la fuite | Captures d'écran d'utilisateurs Reddit, suivies par 9to5google et TestingCatalog |
| Type de modèle | Modèle multimodal de génération et d'édition vidéo |
| Description clé | Create with Gemini Omni: meet our new video model |
| Démo présentée | Scène de démonstration mathématique sur tableau noir, scène de dialogue dans un restaurant en bord de mer |
| Niveau de visibilité actuel | Probablement issu de la gamme Flash, la gamme Pro n'a pas encore fuité |
| Signal de consommation | Deux générations vidéo ont épuisé 86 % du quota quotidien du forfait AI Pro |
| Lancement officiel prévu | Google I/O 2026, 19-20 mai, San Francisco |
Il est important de souligner que la carte d'interface divulguée prouve seulement que Google a fait passer Omni au stade de test en version bêta, ce qui ne signifie pas que toutes les fonctionnalités seront accessibles à tous les utilisateurs dès la conférence I/O. Pour les développeurs qui suivent l'actualité de Gemini Omni, nous recommandons de créer un compte sur APIYI (apiyi.com) et de préparer votre base_url pour une interface unifiée. Ainsi, dès le lancement officiel par Google, vous pourrez basculer vers ce modèle dans votre code existant, économisant ainsi les coûts liés à la mise en place d'une nouvelle chaîne d'invocation.
Les 5 capacités clés du modèle vidéo Gemini Omni
Gemini Omni n'est pas un simple outil de « texte vers image » (ou vidéo). D'après les descriptions de l'interface utilisateur et les premières démonstrations, il fusionne la génération, l'édition, les modèles et l'interaction conversationnelle en un système unifié. Voici les 5 capacités confirmées par plusieurs médias, bien que le modèle soit encore en phase d'évolution rapide.
La première est l'édition vidéo conversationnelle. Les utilisateurs peuvent exprimer leurs besoins de modification directement dans la boîte de dialogue, comme changer un objet principal, modifier une scène ou réécrire une action spécifique. Le modèle génère alors une nouvelle séquence basée sur le clip existant, sans obliger l'utilisateur à intervenir manuellement sur une timeline. Cette capacité concurrence directement les outils de post-production traditionnels et constitue le point de différenciation clé d'Omni par rapport à Veo 3.1.
La deuxième concerne la suppression de filigranes et le remplacement d'objets. Les premiers testeurs ont rapporté que les performances d'Omni sur les commandes « remove watermark » (supprimer le filigrane) et « swap object » (remplacer l'objet) sont nettement supérieures à ses capacités de génération d'image brute, ce qui en fait un argument de vente majeur. Étant donné la sensibilité de ces opérations, Google mettra probablement en place des contrôles de droits d'auteur et de conformité lors du lancement officiel.
La troisième est la génération native audio-vidéo conjointe. Les analyses de WaveSpeed et GeminiOmniAI convergent : Omni produit simultanément l'image et l'audio spatial synchronisé en une seule inférence, plutôt que de générer la vidéo puis d'y ajouter le son. Cette modélisation conjointe permet de réduire les problèmes classiques de l'IA vidéo, comme le décalage labial ou l'incohérence des sons ambiants.
La quatrième est la gestion d'une fenêtre de contexte de script ultra-longue. Plusieurs médias ont noté qu'Omni accepte des invites et des scripts beaucoup plus longs que Veo 3, ce qui facilite la narration multi-plans ou les présentations de produits détaillées. En s'appuyant sur la gestion de contexte long, spécialité de la gamme Gemini, cette capacité, si elle se confirme, creusera un écart significatif avec les modèles axés sur les vidéos courtes comme Sora.
La cinquième est la cohérence faciale et visuelle via image de référence. Omni permet d'utiliser une image de référence comme point d'ancrage pour l'identité, la lumière et les couleurs, garantissant que les actions générées conservent les caractéristiques visuelles des personnages ou des scènes. C'est idéal pour les publicités de marque, les vidéos basées sur des IP et le contenu de personnages numériques.
💡 Conseil pour bien démarrer : Avant l'ouverture officielle de Gemini Omni, vous pouvez utiliser la plateforme APIYI (apiyi.com) avec des modèles vidéo actuels comme Veo 3.1, Seedance 2 ou Hailuo pour perfectionner votre ingénierie d'invite. Une fois Omni disponible, vous pourrez basculer en douceur et réduire vos coûts d'expérimentation.
Hypothèse sur l'architecture à deux niveaux : Gemini Omni Flash et Pro
TestingCatalog et WaveSpeed ont remarqué que, bien que l'interface divulguée ne mentionne qu'un seul nom « Omni », les règles de nommage des cartes de modèles, les options de paramètres et la vitesse de traitement correspondent parfaitement à la structure « Flash + Pro » des autres membres de la famille Gemini. Le tableau ci-dessous résume les différences supposées entre ces deux lignes de produits pour aider les développeurs à anticiper leurs choix.
| Niveau | Positionnement supposé | Caractéristiques supposées | Scénarios d'utilisation |
|---|---|---|---|
| Gemini Omni Flash | Niveau haute fréquence | Rapide, faible coût par unité, qualité d'image moyenne | Vidéos courtes pour réseaux sociaux, tests A/B publicitaires, contenu de masse |
| Gemini Omni Pro | Niveau production haute qualité | Inférence lente, image détaillée, audio natif plus raffiné | Films de marque, scripts de vidéos longues, plans de qualité cinématographique |
Deux indices suggèrent que les démonstrations actuelles proviennent du niveau Flash : d'une part, la qualité des scènes (tableaux noirs mathématiques, restaurants) ne dépasse pas le niveau de Veo 3.1 ; d'autre part, le niveau Pro est généralement annoncé avec des capacités d'inférence intensive comme « Deep Think ». Lorsque Google annoncera le niveau Pro et sa tarification lors de l'I/O 2026, les développeurs pourront décider s'il est nécessaire d'utiliser les deux lignes de produits selon les cas d'usage.
Pour les équipes développant des applications de génération vidéo, l'approche la plus réaliste consiste à utiliser l'interface d'agrégation multi-modèles d'APIYI (apiyi.com) comme base, afin de concevoir une couche intermédiaire « agnostique au modèle » pour la gestion des invites, des paramètres et des flux de rappel. Une fois qu'Omni Flash et Pro seront réellement disponibles, il suffira de modifier le champ model pour intégrer ces nouvelles capacités sans interruption de service.
Analyse des relations entre Gemini Omni, Veo 3.1, Seedance 2 et Sora
Pour comprendre le positionnement de Gemini Omni sur le marché, il est indispensable de l'intégrer dans le paysage actuel des modèles vidéo. Le tableau comparatif ci-dessous présente les différences de capacités des modèles les plus en vue au 12 mai 2026. Notez que les données relatives à Omni restent des estimations.
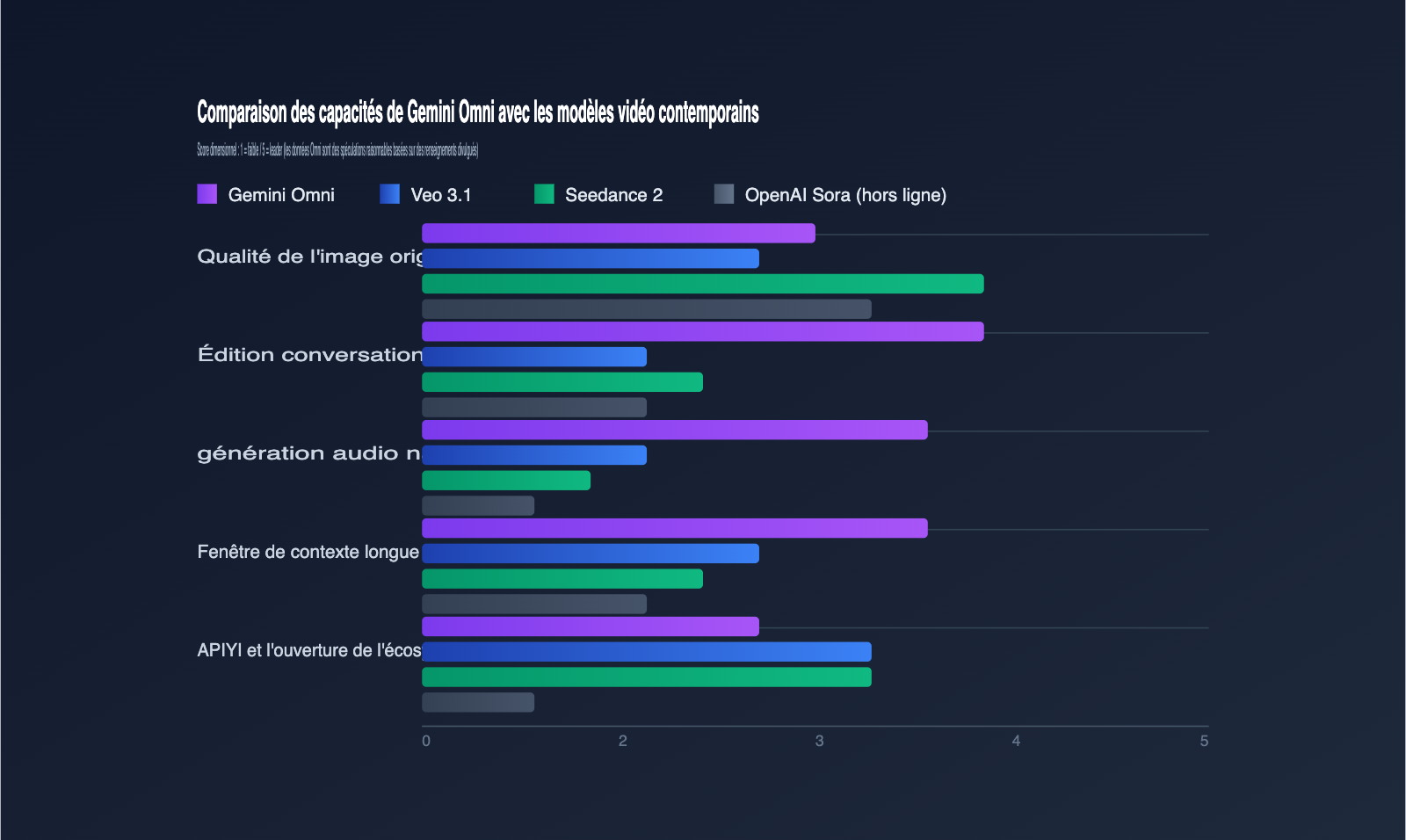
| Dimension | Gemini Omni | Veo 3.1 | Seedance 2 | OpenAI Sora |
|---|---|---|---|---|
| Positionnement principal | Génération vidéo + édition conversationnelle | Génération vidéo | Génération vidéo haute fidélité | Retiré début 2026 |
| Qualité d'image brute | Moyenne à élevée (estimée) | Moyenne | Référence actuelle du secteur | Niveau historique élevé |
| Édition conversationnelle | Point fort majeur | Non supporté | Support limité | Plus mis à jour |
| Audio natif | Sortie synchrone en une inférence | Post-traitement requis | Post-traitement requis | Pas d'audio natif |
| Ouverture API | Prévue avec I/O | Vertex AI / Gemini API | Volcengine | Fermé |
| Licence commerciale | À annoncer | Commercialisé | Commercialisé | Suspendu |
Le véritable atout de Gemini Omni n'est pas de remplacer des modèles comme Seedance 2, qui excellent par leur qualité d'image, mais d'utiliser les capacités multimodales de Gemini pour compresser le flux de travail « génération → modification → régénération » directement dans la fenêtre de discussion. Pour les développeurs, cela signifie que le format des applications de génération vidéo pourrait évoluer d'un modèle « éditeur + modèle » vers un modèle « conversation + modèle ».
Le vide laissé par OpenAI après le retrait de Sora début 2026 offre à Gemini Omni une opportunité idéale. Si votre équipe évalue encore sur quel écosystème de génération vidéo miser, je vous suggère d'utiliser l'interface de proxy unifiée d'APIYI (apiyi.com) pour accéder simultanément à Veo 3.1 et Seedance 2, puis d'ajouter une chaîne d'invocation pour Omni après sa sortie officielle, afin de reporter votre décision finale après la conférence.
Observations sur la démo de Gemini Omni et limites d'utilisation
Au-delà de la liste des capacités et des estimations, un autre indice mérite l'attention : les performances réelles et les données d'utilisation des premières démos. 9to5google a rapporté deux démos publiques couvrant des défis complexes comme le rendu de texte et la narration en plan-séquence.
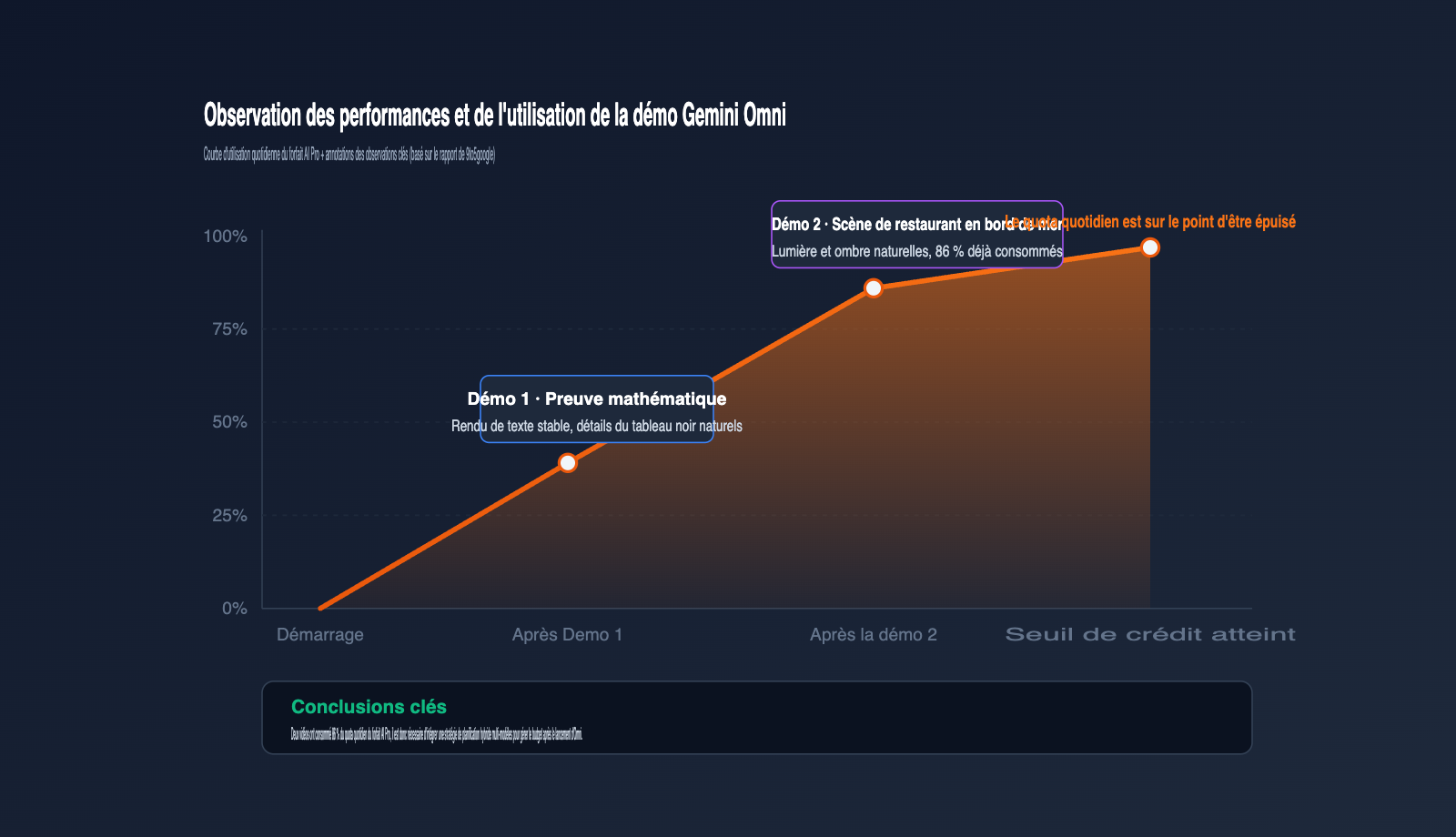
| Thème de la démo | Éléments clés de l'invite | Conclusion de l'observation |
|---|---|---|
| Tableau de démonstration mathématique | Professeur écrivant une identité trigonométrique | Rendu de texte stable, quelques défauts de raccord d'écriture |
| Restaurant en bord de mer | Deux hommes dînant dans un restaurant haut de gamme | Profondeur de champ, éclairage et émotions naturels |
| Échantillon d'utilisation | Deux invites vidéo | Épuisement de 86 % du quota quotidien du forfait AI Pro |
Les données d'utilisation sont le détail le plus souvent négligé dans cette fuite. Deux vidéos consomment plus de la moitié du quota quotidien, ce qui signifie qu'Omni consomme nettement plus de puissance de calcul que des modèles classiques comme Imagen 4 ou Gemini 2.5 Flash. Google a déjà précisé dans une autre annonce qu'il introduirait des « limites d'utilisation explicites » pour les comptes Gemini, ce qui indique qu'Omni adoptera probablement une politique de quotas assez stricte après son lancement.
Pour les petites et moyennes équipes, l'approche la plus pragmatique est de ne pas lier la génération vidéo à un canal unique. Je recommande, lors de l'appel de la série Gemini via la plateforme APIYI (apiyi.com), de diviser votre budget quotidien en appels mixtes vers plusieurs modèles : utilisez Veo 3.1 ou Seedance 2 pour le contenu à haute fréquence, et réservez Omni pour les démonstrations clés. Cela vous permet de bénéficier des capacités différenciées d'Omni sans risquer de bloquer votre trésorerie à cause de la politique de quotas d'une seule plateforme.
L'impact du modèle vidéo Gemini Omni pour les développeurs et l'industrie
En synthétisant ces signaux, nous pouvons évaluer l'impact potentiel de Gemini Omni sous deux angles : celui des développeurs et celui de l'industrie. Cette analyse ne se contente pas de répéter les spécifications techniques ni de céder à un battage médiatique excessif, mais repose sur une déduction logique à partir des informations disponibles.
Impact sur les développeurs d'applications de génération vidéo
La première vague d'impact concerne directement les équipes qui développent des solutions SaaS de génération vidéo. Omni place l'édition conversationnelle au premier plan, ce qui signifie que l'interface utilisateur traditionnelle des éditeurs vidéo n'est plus une option incontournable. Les développeurs doivent désormais décider s'ils souhaitent faire de l'interface de dialogue leur point d'entrée unique ou conserver une timeline comme filet de sécurité.
La deuxième vague concerne les créateurs de contenu vidéo par IA et les MCN (Multi-Channel Networks). La génération native audio-vidéo réduira considérablement la charge de travail liée à la post-production, mais les quotas journaliers limités restreindront le volume de vidéos qu'un créateur individuel peut produire. Une stratégie prudente consiste à utiliser Omni comme un « amplificateur de plans clés », tout en continuant à s'appuyer sur des modèles moins coûteux pour le contenu standard.
Si votre produit dépend d'une API de génération vidéo, je vous conseille de prendre dès maintenant quelques mesures sur la plateforme APIYI (apiyi.com) : premièrement, unifiez la couche d'encapsulation pour toutes les invocations de modèles vidéo ; deuxièmement, créez une bibliothèque de tests A/B pour vos invites ; et troisièmement, préparez trois préréglages de secours (Omni, Veo, Seedance) pour vos flux de travail critiques afin d'éviter les fluctuations de quotas le jour du lancement.
Impact sur le paysage de l'industrie de la vidéo par IA
Depuis le retrait de Sora d'OpenAI, la place de leader dans le secteur de la vidéo par IA a oscillé entre Veo, Seedance et Runway Gen-4. Une fois que Gemini Omni prendra réellement en charge l'audio-vidéo natif et une fenêtre de contexte étendue, il transférera directement le « fossé multimodal de Google » dans le domaine de la génération vidéo, exerçant ainsi une pression sur les autres acteurs du marché.
Du point de vue de l'écosystème, il est fort probable que Google distribue Omni via trois canaux simultanés : l'application Gemini, Vertex AI et AI Studio. Cela signifie qu'Omni apparaîtra aussi bien dans les discussions grand public que dans les produits existants sous forme d'API pour développeurs ou d'outils d'agent d'entreprise. Si votre équipe a besoin de gérer de manière centralisée les points d'entrée des invocations en interne, vous pouvez utiliser APIYI (apiyi.com) pour regrouper les multiples canaux d'invocation d'Omni, Veo et Seedance sous une seule facture et un journal d'audit unique.
Chronologie autour de l'I/O 2026 pour le modèle vidéo Gemini Omni
Pour aider votre équipe à planifier l'intégration, voici les informations publiques organisées par date. Notez que les dates antérieures au 19 mai sont des événements confirmés, tandis que celles qui suivent sont des estimations basées sur le rythme habituel.
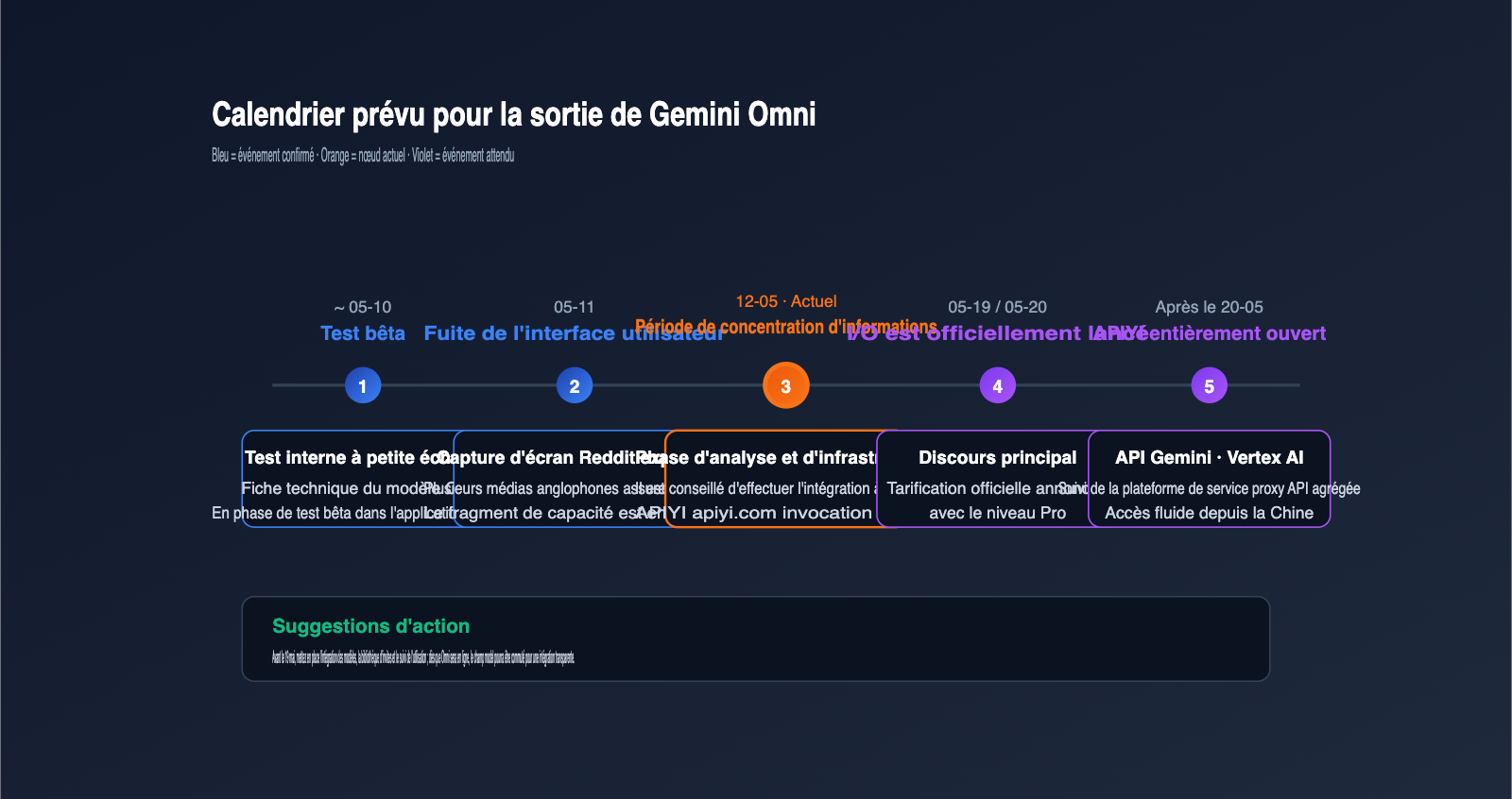
| Étape | Date | Événement clé |
|---|---|---|
| Test en gris | Avant le 11/05/2026 | Test interne de la fiche modèle Omni par Google |
| Fuite UI | 11/05/2026 | Capture d'écran sur Reddit, reprise par plusieurs médias anglophones |
| Période de collecte | 12/05 au 18/05/2026 | Analyse et pré-lancement par les fabricants et médias |
| Lancement officiel | 19/05 au 20/05/2026 | Keynote Google I/O 2026 et accès développeurs |
| Lancement API | Après le 20/05/2026 | Ouverture progressive de Gemini API / Vertex AI / AI Studio |
| Ouverture proxy local | Synchronisé avec l'API | Suivi de configuration par les plateformes agrégatrices comme APIYI (apiyi.com) |
Foire aux questions
Q1 : Gemini Omni sera-t-il vraiment lancé lors de la conférence I/O 2026 ?
Si l'on se fie aux habitudes de nommage de Google et au rythme des fuites, l'I/O 2026 semble être la fenêtre de lancement la plus logique. Toutefois, l'ouverture de l'API dès le 19 mai dépendra des annonces faites sur place par Google. Nous vous conseillons de prévoir une fenêtre de lancement entre le 19 et le 20 mai, tout en conservant une marge d'une semaine pour un déploiement progressif.
Q2 : Quel est le lien entre Gemini Omni et Veo 3.1 ?
Il existe actuellement trois interprétations principales : Omni serait le nouveau nom public de Veo, Omni serait un modèle distinct de Veo, ou Omni serait un modèle omni-modèle de niveau supérieur unifiant l'image et la vidéo. Au vu des descriptions de l'interface utilisateur ayant fuité, la troisième hypothèse est la plus probable, mais elle reste à confirmer par Google.
Q3 : Les développeurs basés en Chine pourront-ils utiliser Gemini Omni ?
Dès que Google ouvrira l'invocation du modèle Omni via l'API Gemini et Vertex AI, les développeurs pourront y accéder via des plateformes d'agrégation comme APIYI (apiyi.com). Il est conseillé de configurer dès maintenant le base_url de la gamme Gemini sur cette plateforme pour éviter toute précipitation le jour du lancement.
Q4 : La qualité d’image des premières démos semble inférieure à celle de Seedance 2, cela signifie-t-il qu’Omni n’est pas performant ?
Il est trop tôt pour conclure. De nombreux médias supposent que les démos actuelles proviennent de la version Flash, et que la version Omni Pro n'a pas encore été dévoilée. De plus, la force d'Omni réside dans ses capacités d'édition et son traitement audio natif ; la compétition sur la qualité d'image pure n'est pas son objectif principal.
Q5 : Est-il inutile d’attendre Omni ? Quel modèle vidéo utiliser en attendant ?
Nous recommandons Veo 3.1 comme solution polyvalente, Seedance 2 pour une qualité d'image supérieure, et Hailuo pour les projets sensibles aux coûts. Vous pouvez accéder à ces trois modèles via APIYI (apiyi.com) et ajouter une quatrième chaîne d'invocation dès qu'Omni sera officiellement disponible.
Conclusion
La fuite prématurée concernant Gemini Omni a propulsé les discussions sur les modèles vidéo au sommet des priorités avant la Google I/O 2026. D'après les informations disponibles, son argument de vente principal ne réside pas dans la qualité d'image, mais dans sa combinaison d'édition conversationnelle, d'audio/vidéo natif et de sa large fenêtre de contexte. L'objectif est de déplacer le flux de travail de génération vidéo de l'éditeur vers la fenêtre de dialogue.
Avant le 19 mai, la stratégie la plus intelligente n'est pas de spéculer sur les détails, mais de mettre en place l'infrastructure nécessaire. En préparant une interface unifiée pour les modèles, une bibliothèque d'invites et un suivi de la consommation, le coût de transition vers Omni sera minime. Nous conseillons aux équipes de préparer leur déploiement via des plateformes comme APIYI (apiyi.com) afin de limiter le travail d'intégration de Gemini Omni à seulement 1 ou 2 jours.
Auteur : Équipe technique APIYI
Contact : Obtenez le guide d'intégration dès la sortie de Gemini Omni via APIYI (apiyi.com)
Date de mise à jour : 12-05-2026