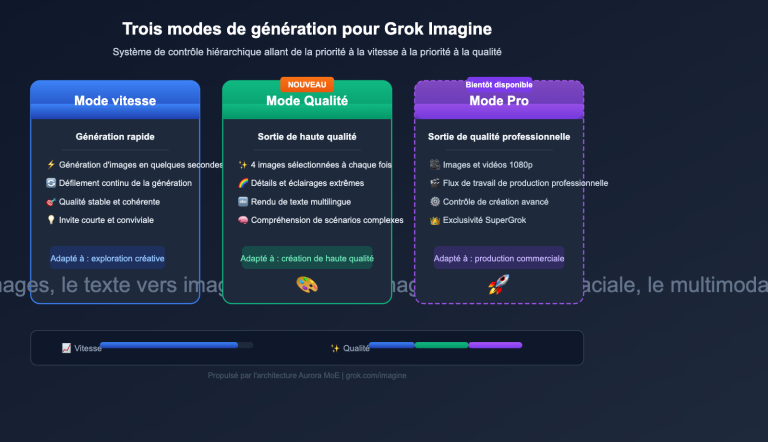
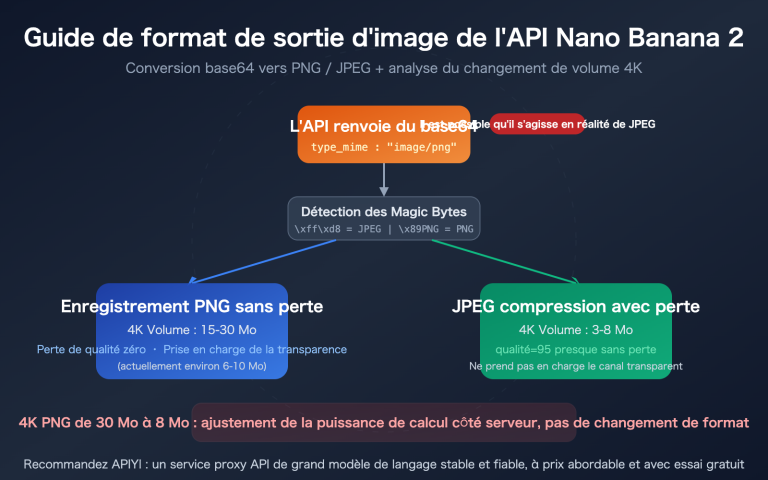
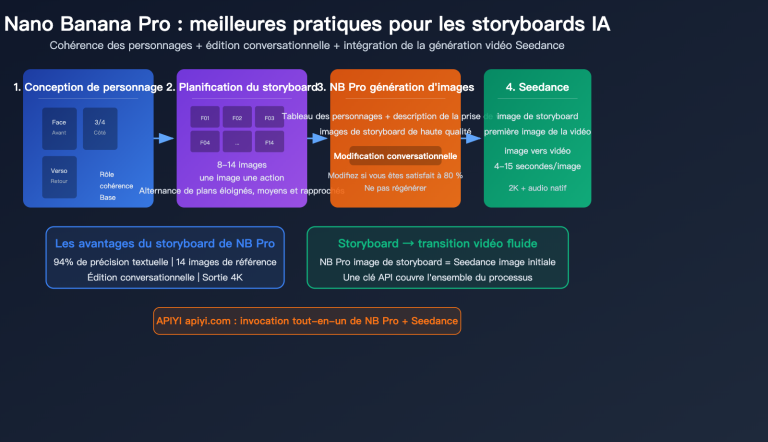
Le 21 avril 2026, OpenAI a officiellement lancé ChatGPT Images 2.0. Son modèle API associé, gpt-image-2, apporte une série d'améliorations majeures, notamment en matière de raisonnement, de recherche web en temps réel, de cohérence entre plusieurs images et de rendu de texte précis.
Dans la foulée, APIYI a déployé simultanément deux voies d'accès distinctes pour le gpt-image-2 :
- ① Version officielle (Proxy)
gpt-image-2: Facturation à l'usage, tarifs identiques à ceux d'OpenAI, remise de 15 % sur les recharges, approvisionnement stable et concurrence illimitée. - ② Version inversée
gpt-image-2-all: Facturation par requête, 0,03 $ / requête (avant remise), intégration simplifiée et coûts prévisibles.
Cela signifie que les développeurs peuvent désormais exploiter ces deux approches techniques sous un seul compte, leur permettant de choisir avec souplesse en fonction des besoins de leur projet, tout en équilibrant qualité, coût et stabilité. Cet article détaille les différences fondamentales, la structure tarifaire, les paramètres pris en charge, les cas d'usage typiques et les méthodes d'intégration rapide.

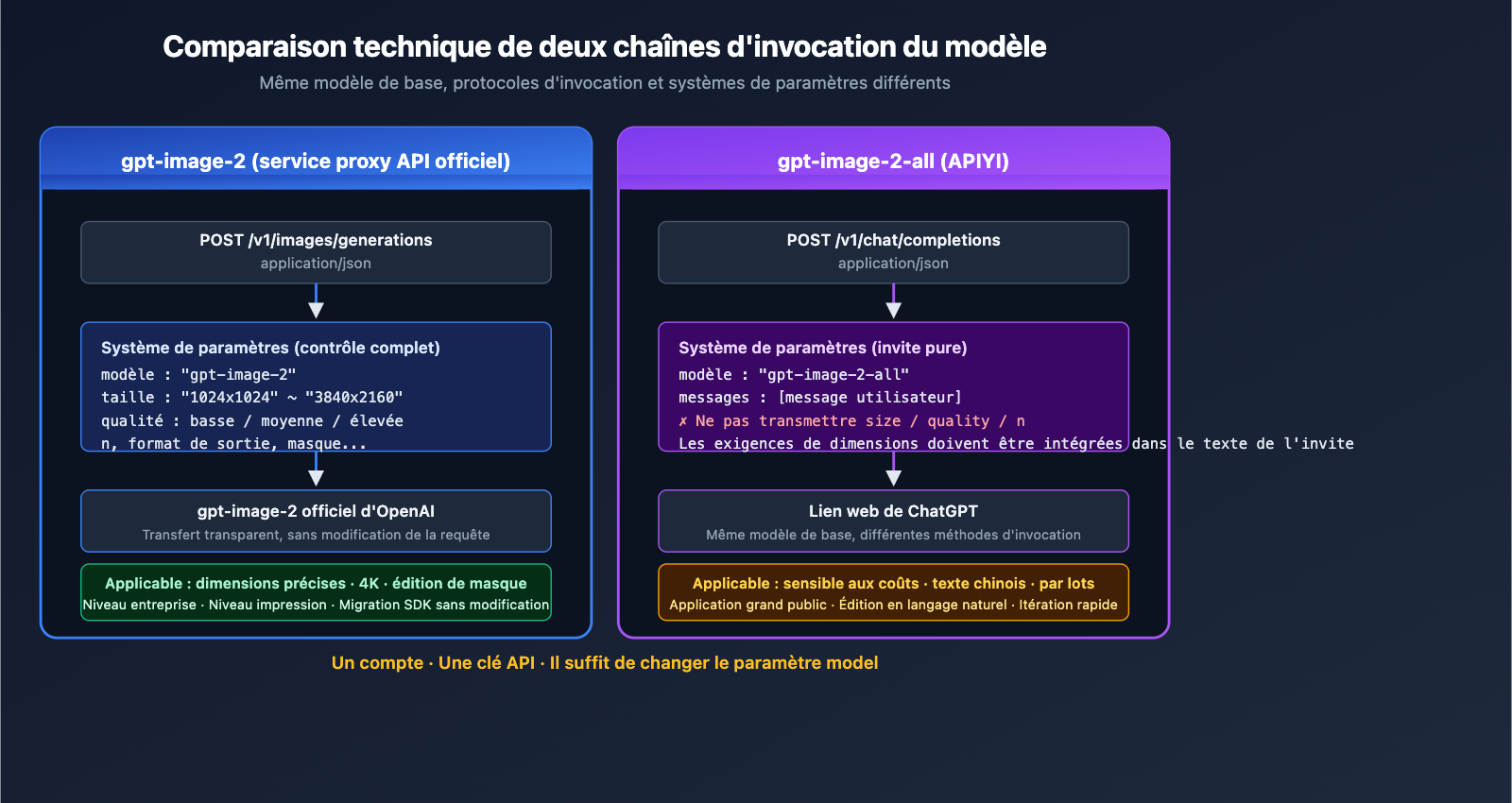
I. Aperçu des informations clés sur le lancement des deux modèles GPT-image-2 d'APIYI
Vous pouvez rapidement comparer les différences fondamentales entre les deux modèles grâce au tableau ci-dessous.
| Dimension | gpt-image-2 (Proxy) |
gpt-image-2-all (Inversé) |
|---|---|---|
| Positionnement | Relais transparent officiel OpenAI | Simulation de l'appel web ChatGPT |
| Mode de facturation | Facturation réelle par Token | Fixe 0,03 $ / requête |
| Prix de référence | 1024² medium ≈ 0,053 $, 2K medium ≈ 0,05 $ | 0,03 $ / requête, indépendamment de la taille/qualité |
| Remise de recharge | 15 % pendant la période promotionnelle | 15 % pendant la période promotionnelle |
| Résolution | Jusqu'à 4K (3840×2160) | Sortie entre 1K et 2K |
| Niveaux de qualité | auto / low / medium / high | Aucun contrôle de paramètre |
| Paramètres supportés | Paramètres complets (size, quality, n, mask, etc.) |
Paramètres classiques non supportés, via prompt |
| Point de terminaison | /v1/images/generations + /v1/images/edits |
/v1/chat/completions (recommandé) |
| Limites de concurrence | Non soumis aux limites Tier d'OpenAI | Aucune limite |
| Vitesse de génération | 100-120 s (3-5 min pour 4K haute qualité) | ~30 s |
| Support natif du chinois | Oui | Optimisation native des invites en chinois |
| Documentation | docs.apiyi.com/api-capabilities/gpt-image-2/overview | docs.apiyi.com/api-capabilities/gpt-image-2-all/overview |
Les deux modèles peuvent être testés en ligne sur imagen.apiyi.com, ce qui permet de comparer intuitivement les différences de sortie entre les deux voies sans avoir à écrire de code.
二、Analyse approfondie du modèle officiel gpt-image-2
2.1 Positionnement technique du modèle officiel
La version officielle gpt-image-2 est un proxy transparent de l'API officielle d'OpenAI. APIYI n'effectue que les opérations suivantes :
- Transfert de protocole : Compatibilité totale avec le point de terminaison
/v1/images/generationsd'OpenAI. - Substitution d'authentification : Les développeurs utilisent une clé API APIYI, remplacée en backend par l'autorisation OpenAI.
- Comptabilité et facturation : Facturation basée sur la consommation réelle de jetons (tokens).
- Zéro traitement de contenu : Aucune modification de l'invite (prompt), aucun filtrage des sorties.
La valeur directe est la suivante : la qualité de sortie est identique à celle d'OpenAI, tout en levant les goulots d'étranglement de concurrence liés aux niveaux (Tier). Les comptes officiels Tier 1 sont limités à 5 générations par minute, une restriction qui ne s'applique pas aux canaux officiels d'APIYI.
2.2 Matrice de résolution supportée par le modèle officiel
La version officielle conserve l'intégralité du système de dimensions d'OpenAI :
| Dimensions prédéfinies | Ratio d'aspect | Usage typique |
|---|---|---|
| 1024 × 1024 | 1:1 | Avatars, Instagram |
| 1536 × 1024 | 3:2 | En-têtes de blog |
| 1024 × 1536 | 2:3 | Affiches mobiles |
| 2048 × 2048 | 1:1 | Images de marque haute résolution |
| 2048 × 1152 | 16:9 | Couvertures vidéo |
| 3840 × 2160 | 16:9 (4K) | Supports d'impression |
| 2160 × 3840 | 9:16 (4K) | Publicités verticales grand format |
| Personnalisé | Max 3:1 | Bannières, images longues |
Contraintes pour les dimensions personnalisées : Côté long ≤ 3840 px, les deux côtés doivent être des multiples de 16, et le nombre total de pixels doit se situer entre 655 360 et 8 294 400.
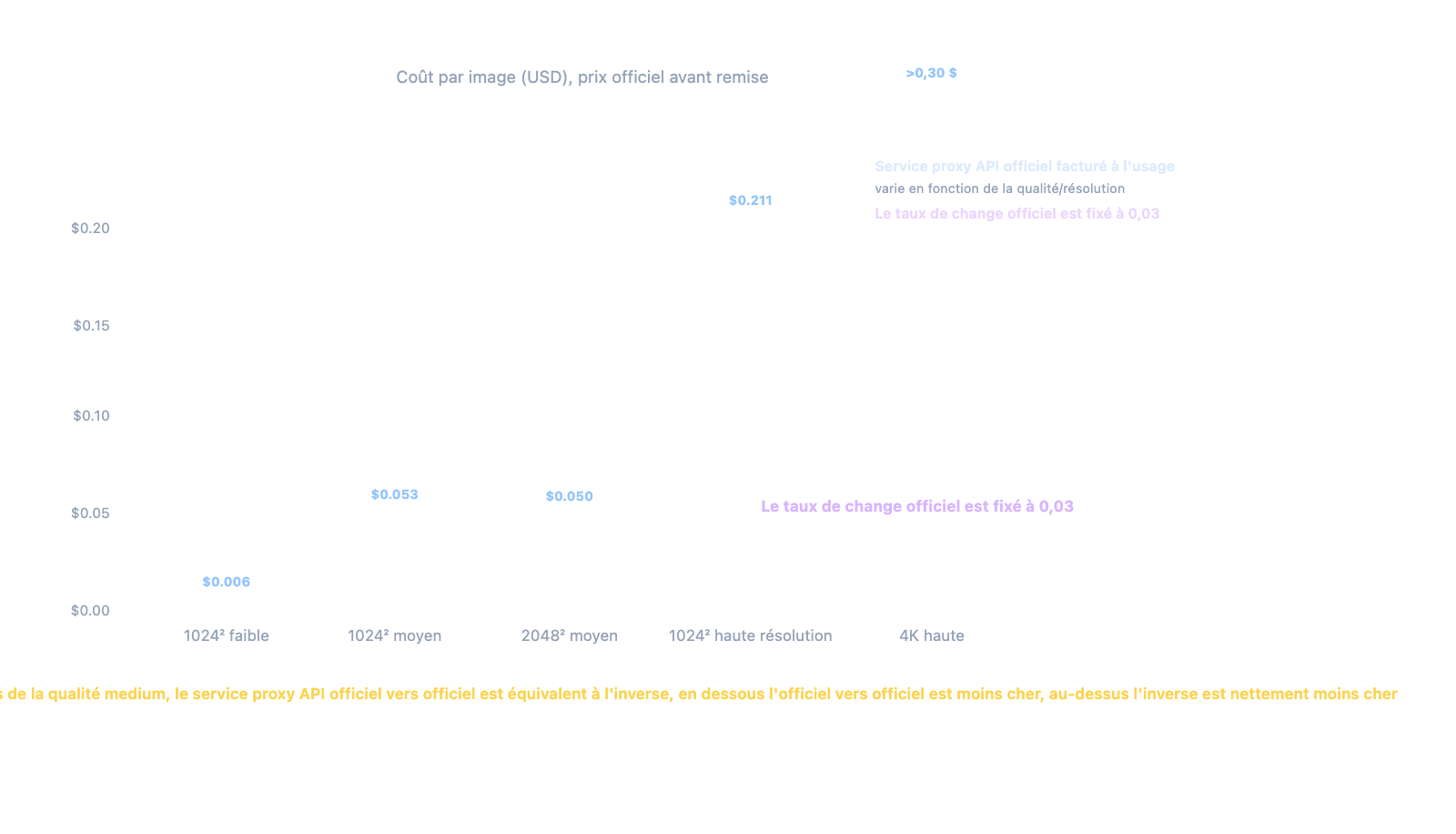
2.3 Quatre niveaux de qualité et tarification du modèle officiel
La tarification est alignée sur les tarifs officiels d'OpenAI :
| Résolution × Qualité | Prix unitaire (officiel) | Prix payé (-15%) |
|---|---|---|
| 1024² low | 0,006 $ | 0,0051 $ |
| 1024² medium | 0,053 $ | 0,045 $ |
| 1024² high | 0,211 $ | 0,179 $ |
| 2048² medium | ≈ 0,05 $ | ≈ 0,043 $ |
| 1024×1536 medium | 0,041 $ | 0,035 $ |
| 1024×1536 high | 0,165 $ | 0,140 $ |
Facturation des jetons : entrée texte/image 8 $/1M, sortie image 30 $/1M, entrée en cache 2 $/1M.
💡 Stratégie d'optimisation des coûts : Pour l'exploration initiale, nous recommandons d'utiliser la qualité "low" ou "medium" pour une itération rapide, puis de passer à "high" pour la version finale. Grâce à l'offre de recharge de 15 % de réduction sur APIYI apiyi.com, le coût réel est inférieur à une connexion directe avec OpenAI.
2.4 Scénarios adaptés au modèle officiel
- Besoin de contrôle précis de la résolution (images e-commerce, supports d'impression)
- Besoin de sortie 4K (publicités grand écran, fonds d'écran)
- Besoin d'édition locale par masque (retouche produit, restauration d'image)
- Exigences élevées de compatibilité SDK (migration sans modification du code existant)
- Exigences SLA de niveau entreprise (accords personnalisés possibles)
三、Analyse approfondie du modèle inversé gpt-image-2-all
3.1 Positionnement technique du modèle inversé
gpt-image-2-all est une implémentation inversée simulant la chaîne d'appel de la version web de ChatGPT, caractérisée par une tarification fixe + absence de paramètres.
Pour les développeurs, la principale différence réside dans la méthode d'appel :
- Pas de passage par
/v1/images/generations, mais par/v1/chat/completions. - Pas besoin de transmettre les paramètres
size,quality,n(les transmettre déclencherait une erreur de validation). - La résolution et le ratio d'aspect sont spécifiés par le langage naturel dans l'invite.
- Une seule image générée par appel.
3.2 Logique de tarification fixe du modèle inversé
gpt-image-2-all adopte un prix fixe de 0,03 $ par appel, que vous génériez une image 1K ou 2K, et quelle que soit la longueur de l'invite (les requêtes échouées ne sont pas facturées).
La valeur ajoutée :
| Scénario | Officiel (à l'usage) | Inversé (fixe) | Avantage |
|---|---|---|---|
| Petite image 1024² medium | 0,053 $ | 0,030 $ | Inversé -43% |
| Image moyenne 2048² medium | ~0,05 $ | 0,030 $ | Inversé -40% |
| Image haute qualité 1024² high | 0,211 $ | 0,030 $ | Inversé -86% |
| Image 4K haute qualité | > 0,20 $ | Non supporté | Officiel requis |
En résumé : pour les images de qualité moyenne à basse, le modèle inversé est bien moins cher ; mais pour la 4K et les détails précis, le modèle officiel est indispensable.
3.3 Caractéristiques des dimensions de sortie du modèle inversé
Le modèle inversé utilise le langage naturel pour spécifier les dimensions. Le modèle génère des images entre 1K et 2K. Dimensions courantes :
| Description du ratio dans l'invite | Résolution de sortie réelle |
|---|---|
| "Carré 1:1" | 1254 × 1254 |
| "Paysage 16:9" | 1672 × 941 |
| "Portrait 9:16" | 941 × 1672 |
| "Ultra-large 3:1" | Le modèle peut ne pas suivre strictement |
Important : Le modèle inversé ne garantit pas un contrôle au pixel près, il est donc idéal pour les scénarios où les dimensions exactes sont secondaires.
3.4 Capacités uniques du modèle inversé
Bien qu'il manque certains paramètres de contrôle, le modèle inversé possède des atouts exclusifs :
① Optimisation native des invites en chinois
Le modèle inversé est optimisé pour les invites en chinois, offrant une meilleure précision de rendu pour les textes intégrés dans les affiches, infographies ou menus.
② Fusion et édition multi-images
En utilisant des références comme "Image 1/Image 2" dans l'invite, vous pouvez effectuer des compositions. Le modèle officiel le permet aussi, mais la syntaxe du modèle inversé est plus naturelle.
③ Édition en langage naturel (sans masque)
Pour modifier une image existante, pas besoin de masque : dites simplement "Change la couleur du vêtement du personnage en rouge".
④ Avantage de vitesse
Temps de génération moyen d'environ 30 secondes, nettement plus rapide que les 100-120 secondes du modèle officiel.
3.5 Limitations du modèle inversé
- Expiration des URL d'images (24h) : Les liens CDN R2 sont valides 24h, transférez-les vers votre propre stockage.
- Pas de streaming : Le paramètre
stream=trueest inopérant. - Une image par appel : Pour le traitement par lots, utilisez des appels concurrents.
- Timeout conseillé à 300s : Inclut le temps d'upload et de téléchargement.
3.6 Scénarios adaptés au modèle inversé
- Tâches par lots sensibles au coût (budget prévisible).
- Rendu de texte en chinois (menus, affiches, infographies).
- Itération rapide (génération en 30 secondes).
- Édition en langage naturel (pour ceux qui veulent éviter les masques).
- Applications grand public (interactivité, flexibilité des dimensions).
Quatre. Prise en main rapide des deux modèles APIYI GPT-image-2
4.1 Portail de test en ligne
Les deux modèles sont intégrés à l'outil de test visuel d'APIYI sur imagen.apiyi.com. Les développeurs et designers peuvent ainsi :
- Comparer sans coder : Saisissez la même invite et comparez les résultats des deux modèles côte à côte.
- Ajuster les paramètres : La version "官转" (passerelle officielle) permet de régler la taille (
size) et la qualité (quality) pour ressentir intuitivement les différences. - Exporter le code : Une fois satisfait, générez directement les fragments de code en curl, Python ou Node.js.
C'est la manière la plus directe de se familiariser avec les capacités de chaque modèle. Nous vous recommandons vivement de passer 10 minutes à tester les deux sur imagen.apiyi.com avant votre première intégration.
4.2 Exemple Python pour le modèle gpt-image-2 (passerelle officielle)
from openai import OpenAI
import base64
client = OpenAI(
api_key="VOTRE_CLE_API_APIYI",
base_url="https://api.apiyi.com/v1"
)
response = client.images.generate(
model="gpt-image-2",
prompt="Salon de style minimaliste moderne, grandes baies vitrées, lumière naturelle entrant en oblique",
size="2048x1152",
quality="medium",
n=1,
output_format="png"
)
image_bytes = base64.b64decode(response.data[0].b64_json)
with open("output.png", "wb") as f:
f.write(image_bytes)
Point clé : Cette version utilise le SDK OpenAI standard. Le code est identique à celui utilisé pour OpenAI, il suffit de remplacer base_url et api_key.
4.3 Exemple Python pour le modèle gpt-image-2-all (version optimisée)
from openai import OpenAI
client = OpenAI(
api_key="VOTRE_CLE_API_APIYI",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-image-2-all",
messages=[
{
"role": "user",
"content": "Générer une affiche de salon style minimaliste moderne au format paysage 16:9, "
"grandes baies vitrées, lumière naturelle entrant en oblique, "
'rendu avec une police chinoise grasse en haut à droite indiquant "Vie Nordique"'
}
]
)
print(response.choices[0].message.content)
Point clé : Cette version utilise le point de terminaison chat/completions. La réponse contient le lien vers l'image ou les données base64. Attention, ne transmettez pas les paramètres size/quality/n, sinon une erreur sera renvoyée.
4.4 Architecture hybride : Exemple de routage
En production, nous recommandons une utilisation combinée des deux modèles, en routant la tâche selon ses caractéristiques :
def generate_image(prompt: str, task_type: str):
# Routage vers le modèle optimisé pour les tâches de texte ou de masse
if task_type in ["batch", "draft", "chinese_text"]:
return client.chat.completions.create(
model="gpt-image-2-all",
messages=[{"role": "user", "content": prompt}]
)
# Routage vers le modèle officiel pour des exigences de haute qualité
elif task_type in ["print", "4k", "precise_size"]:
return client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="3840x2160",
quality="high"
)
# Comportement par défaut
else:
return client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1024",
quality="medium"
)
Grâce à cette stratégie de routage, vous pouvez obtenir le meilleur rapport coût-qualité au sein d'un même compte APIYI.
Cinq. Analyse de l'impact des modèles APIYI GPT-image-2 sur les équipes produit
5.1 Impact sur les startups et développeurs indépendants
Valeur ajoutée : Réduction des coûts d'essai et levée des barrières à l'entrée.
Avant, le principal point de friction pour les nouveaux développeurs utilisant OpenAI était la limite de 5 images/minute (Tier 1) et les délais d'activation de compte. Avec APIYI :
- Utilisation immédiate après inscription.
- Prix fixe de 0,03 $ par image pour la version optimisée, rendant le budget prévisible.
- Prototypage rapide avec la version optimisée, passage à la version officielle lors de la mise en ligne.
Cela signifie que le temps entre "l'envie d'essayer" et "le premier résultat" est réduit à 5 minutes.
5.2 Impact sur les équipes e-commerce et création de contenu
Valeur ajoutée : Réduction des coûts de production en masse de 40 à 85 %.
Pour une équipe e-commerce générant 5 000 images par mois (1024×1024, qualité moyenne) :
- OpenAI direct : 5 000 × 0,053 $ = 265 $/mois + limites de débit.
- APIYI (Passerelle officielle) : 5 000 × 0,053 $ × 0,85 = 225 $/mois + aucune limitation de concurrence.
- APIYI (Version optimisée) : 5 000 × 0,03 $ × 0,85 = 128 $/mois + production rapide.
Si les exigences de précision dimensionnelle sont flexibles, passer intégralement à la version optimisée permet d'économiser plus de 50 % des coûts.
5.3 Impact sur les clients entreprise
Valeur ajoutée : Flexibilité dans les choix technologiques.
Auparavant, les entreprises devaient choisir entre OpenAI et des alternatives tierces. Désormais, elles peuvent combiner :
- Flux métier critiques : Via la passerelle officielle pour garantir la qualité et les SLA.
- Tâches en masse : Via la version optimisée pour maximiser les économies.
- Tests A/B : Comparaisons batch sur
imagen.apiyi.comavant de décider de l'investissement.
Les services aux entreprises d'APIYI proposent également des canaux dédiés, des garanties SLA et des factures conformes.
5.4 Impact sur les produits d'IA outils
Valeur ajoutée : Équilibre entre expérience utilisateur et contrôle des coûts.
Beaucoup de produits B2C devaient arbitrer entre "bonne qualité" et "contrôle des coûts". Avec la matrice à deux modèles :
- Utilisateurs gratuits → Version optimisée (0,03 $/image) pour une disponibilité de base.
- Utilisateurs payants → Version officielle (qualité élevée) pour une expérience différenciée.
- Utilisateurs entreprise → Version officielle (4K) pour les besoins d'impression.

VI. FAQ sur les deux modèles GPT-image-2 d'APIYI
Q1 : Y a-t-il une grande différence de qualité d'image entre les deux modèles ?
Pour les scénarios de qualité moyenne ou inférieure (1024 medium et moins), la différence est minime et difficile à distinguer à l'œil nu. Pour les scénarios de haute qualité (1024 high / 2K / 4K), la version officielle (官转) a un avantage net, car elle permet de spécifier explicitement quality="high" et une résolution précise. Nous vous conseillons d'effectuer quelques tests comparatifs avec le même prompt sur imagen.apiyi.com pour juger par vous-même.
Q2 : La version "reverse" (官逆) gpt-image-2-all est-elle moins performante que le modèle officiel ?
Non. gpt-image-2-all utilise toujours le modèle gpt-image-2 d'OpenAI en arrière-plan, mais passe par le flux d'interaction web de ChatGPT. La différence fondamentale réside dans la gestion des paramètres et le modèle de tarification, et non dans les poids du modèle.
Q3 : Puis-je utiliser les deux modèles sous un seul compte APIYI ?
Oui, c'est tout à fait possible. La clé API de votre compte APIYI (apiyi.com) peut invoquer à la fois gpt-image-2 et gpt-image-2-all ; il suffit de basculer le paramètre model. La facturation sera consolidée sur une seule et même facture.
Q4 : Les images générées par la version "reverse" expirent après 24 heures, que faire ?
La meilleure pratique consiste à télécharger immédiatement l'image vers votre propre stockage objet (OSS / S3 / R2) dès réception de la réponse, sans dépendre de l'URL renvoyée par APIYI. Si vous utilisez response_format="b64_json", vous obtiendrez directement les données en base64, éliminant ainsi tout problème d'expiration.
Q5 : Comment migrer mon code utilisant le SDK officiel d'OpenAI ?
- Pour passer à la version officielle
gpt-image-2: modifiez simplementbase_urletapi_key, le reste du code demeure inchangé. - Pour passer à la version "reverse"
gpt-image-2-all: vous devez utiliser le point de terminaisonchat/completions, supprimer les paramètressize/quality, et intégrer vos exigences de dimensions directement dans le prompt.
Nous vous recommandons de tester d'abord sur imagen.apiyi.com pour confirmer que la qualité de sortie répond à vos attentes avant de passer en production.
Q6 : Les deux modèles supportent-ils les prompts en chinois ?
Les deux le supportent, mais avec des nuances. La version "reverse" gpt-image-2-all est optimisée nativement pour les prompts en chinois, ce qui est particulièrement visible lors du rendu de texte en chinois. La version officielle supporte le chinois, mais est davantage alignée sur la distribution d'entraînement native des prompts en anglais. Pour la production, nous recommandons de tester selon votre cas d'usage.
Q7 : La promotion de 15 % sur les recharges s'applique-t-elle aux deux modèles ?
Oui. Le solde rechargé peut couvrir toutes les invocations de modèles sur APIYI, y compris gpt-image-2 (officiel), gpt-image-2-all (reverse), ainsi que d'autres modèles d'image comme Nano Banana Pro/2 ou Imagen. Les règles spécifiques de la promotion sont disponibles sur apiyi.com.
Q8 : Les entreprises peuvent-elles bénéficier de tarifs préférentiels ou de canaux dédiés ?
Oui. APIYI propose un canal commercial pour les grands comptes. Selon votre volume mensuel, vous pouvez demander des remises personnalisées, des canaux à haute concurrence, des engagements SLA, des factures conformes et un support technique dédié. Contactez directement l'équipe commerciale d'APIYI sur apiyi.com pour obtenir une offre sur mesure.
VII. Résumé du lancement des deux modèles GPT-image-2 sur APIYI
Une image résume la valeur ajoutée de ce lancement :
Un compte, deux voies, trois choix :
- Priorité qualité →
gpt-image-2(officiel), facturation à l'usage + 15 % de remise- Priorité coût →
gpt-image-2-all(reverse), prix fixe de 0,03 $ par requête- Stratégie hybride → Version officielle pour les tâches critiques, version reverse pour les tâches en masse
Pour les équipes évaluant ou utilisant déjà gpt-image-2, voici la marche à suivre recommandée :
- Visitez immédiatement
imagen.apiyi.compour tester les deux modèles en ligne. - Comparez les résultats avec une série de prompts types pour évaluer les différences de qualité et de vitesse.
- Planifiez le routage en concevant une stratégie d'invocation hybride selon vos besoins métier.
- Maîtrisez les coûts en profitant de la promotion de 15 % et en utilisant la version reverse pour les explorations en masse.
- Contactez le support entreprise via le canal commercial d'APIYI sur apiyi.com pour des solutions sur mesure.
La génération d'images est entrée dans une nouvelle ère de "parallélisme des voies + segmentation métier". Un modèle unique ou une tarification unique ne peuvent plus couvrir tous les besoins. Ce lancement simultané chez APIYI redonne le pouvoir aux développeurs : combinez les deux voies de manière flexible pour trouver la solution optimale.
À propos de l'auteur : L'équipe technique d'APIYI, dédiée à fournir aux développeurs et aux entreprises des services d'API de grands modèles de langage stables, transparents et complets. Visitez le site officiel apiyi.com pour accéder à la documentation la plus récente et aux détails des services entreprise pour les modèles phares comme gpt-image-2, gpt-image-2-all et Nano Banana Pro.