La caché de indicaciones (Prompt Caching) es un tema de costes ineludible para cualquier usuario de API de Modelos de Lenguaje Grande en 2026. Para una aplicación RAG que ejecute una indicación del sistema de 8K, la diferencia en la factura mensual entre tener la caché activada o desactivada puede superar las 10 veces. Sin embargo, muchos desarrolladores que alternan entre OpenAI y Anthropic se topan con un detalle oculto: los modelos de facturación de caché de ambas empresas son completamente diferentes.

La diferencia clave se resume en una frase: La escritura en caché de la serie GPT se factura al precio base (1x) sin sobrecoste, mientras que la de la serie Claude conlleva un sobrecoste del 1.25x (5 minutos) o 2x (1 hora). Esta diferencia parece pequeña, pero al aplicarla al tráfico real de un negocio, afecta significativamente al punto de equilibrio. Este artículo, basado en la documentación oficial de ambos, detalla las reglas de facturación, condiciones de activación, descuentos de lectura, estrategias de TTL y cálculos de retorno de inversión para ayudarte a realizar una estimación de costes más precisa.
5 diferencias clave entre la caché de indicaciones de GPT y Claude
Aquí tienes la conclusión. La siguiente tabla es la más valiosa de todo el artículo, ya que resume los 5 puntos críticos que a menudo se pasan por alto al comparar ambas plataformas.
| Dimensión | OpenAI GPT | Anthropic Claude |
|---|---|---|
| Facturación de escritura | Precio base 1x, sin sobrecoste | 5min: 1.25x; 1h: 2x |
| Facturación de lectura | Aprox. 0.1x (hasta 90% dto.) | 0.1x (precio tras 10% dto.) |
| Método de activación | Totalmente automático, sin cambios de código | Opt-in explícito, requiere cache_control |
| Umbral mínimo de tokens | Unificado: 1024 tokens | 1024 / 2048 / 4096 (según el modelo) |
| TTL de caché | 5–10 min inactividad (defecto), máx 1h; modo extendido 24h | 5 minutos (defecto), opcional 1 hora (2x escritura) |
La clave para entender esta tabla está en la fila de "Facturación de escritura". La lógica de OpenAI es: la caché es gratuita para ti; la primera escritura se cobra al precio base y las siguientes coincidencias (hits) tienen descuento, por lo que con una sola coincidencia ya entras en zona de beneficio neto. La lógica de Claude es: primero pagas el sobrecoste por escribir y luego recibes el descuento al acertar, por lo que necesitas "suficientes coincidencias" para amortizar ese sobrecoste.
🎯 Consejo de configuración: Si el tráfico de tu negocio es impredecible y la tasa de aciertos es inestable, te recomiendo priorizar el mecanismo de caché automática de GPT para reducir riesgos. Si tu tasa de aciertos es muy estable (como en atención al cliente, agentes o análisis de documentos largos), el control explícito de Claude te permitirá exprimir un mayor descuento. Ambos modelos ya están disponibles en APIYI (apiyi.com), por lo que puedes realizar pruebas comparativas con el mismo token sin necesidad de abrir cuentas duplicadas.
Análisis detallado del mecanismo de facturación de la caché de indicaciones de OpenAI GPT
La documentación oficial de OpenAI describe la caché de indicaciones (Prompt Caching) de forma muy directa: "El almacenamiento en caché ocurre automáticamente, sin necesidad de realizar ninguna acción explícita ni pagar costos adicionales por utilizar la función de caché". En otras palabras: se activa automáticamente, no tiene costo extra y no requiere cambiar ni una línea de código.
Facturación de escritura y lectura en la caché de GPT
La serie GPT no aplica ningún sobreprecio por la escritura en caché. La primera vez que envías una indicación del sistema de 8K, se te cobra según el precio base de entrada, exactamente igual que si no tuvieras la caché activada. A partir de la segunda vez, si el sistema reconoce que este prefijo ya está en caché, la parte coincidente se factura con un descuento de aproximadamente el 90% sobre el precio base.
| Ítem | Método de facturación | Proporción respecto al precio base |
|---|---|---|
| Primera escritura en caché | Precio base de entrada | 1x (sin sobreprecio) |
| Lectura con acierto de caché | Descuento por acierto | aprox. 0.1x |
| Costo de activación | Totalmente gratuito | 0 |
| Cambios en el código | Ninguno | No requiere |
El margen de descuento real se describe oficialmente como "hasta un 90%", variando ligeramente según el modelo y la tabla de tarifas. Por ejemplo, el precio base de entrada de GPT-5.4 es de $2/1M, mientras que el precio de acierto en caché es de $0.20/1M, exactamente el 10%. Los modelos compatibles como GPT-4.1 y GPT-4o siguen básicamente esta misma proporción.
🎯 Verificación de precios: Debido a que los modelos de OpenAI se actualizan con frecuencia, los precios reales de acierto en caché deben consultarse en la tabla de tarifas oficial. Te recomendamos revisar los precios vigentes directamente en el panel de control de APIYI (apiyi.com); la plataforma sincroniza los ajustes oficiales y no cobra comisiones adicionales por el servicio proxy de API, por lo que los desarrolladores pagan según el uso real de tokens.
Condiciones de acierto de caché en GPT
Para activar un acierto de caché, deben cumplirse dos condiciones simultáneamente:
- La longitud de la indicación debe ser ≥ 1024 tokens (si es menor, no entra en la caché).
- El prefijo de la indicación debe ser idéntico a la solicitud histórica; el acierto se realiza en segmentos incrementales de 128 tokens.
OpenAI ha fijado la granularidad mínima de acierto en 128 tokens, lo que significa que en un prefijo estable de 1500 tokens, siempre que los primeros 1024 coincidan, el resto se irá acertando en incrementos de 128. El inconveniente de este diseño automatizado es que el control es limitado: los desarrolladores no pueden especificar explícitamente "qué parte debe almacenarse", por lo que es necesario colocar todo el contenido estable al principio.
Comportamiento del TTL de la caché de GPT
OpenAI ofrece una descripción clave sobre el TTL: los prefijos en caché suelen reciclarse tras 5–10 minutos de inactividad, con una retención máxima de 1 hora. Los modelos más recientes, como GPT-5 y GPT-4.1, también admiten una "retención extendida" de hasta 24 horas.
🎯 Consejo de uso: Al acceder a la serie GPT a través de APIYI (apiyi.com), la estrategia de caché automática de OpenAI es transparente para el enlace del servicio proxy de API, manteniendo la misma tasa de aciertos que una conexión directa a los puntos finales oficiales. Esto significa que puedes gestionar unificadamente las facturas y tokens de OpenAI y Claude a través de APIYI sin aumentar tus costos.
Análisis detallado del mecanismo de facturación de la caché de indicaciones de Anthropic Claude
La filosofía de diseño de Claude es totalmente opuesta a la de OpenAI: trata la caché como una "capacidad de optimización configurable activamente", donde los desarrolladores deben declarar explícitamente qué contenido almacenar y durante cuánto tiempo. El costo es un sobreprecio en la escritura, pero la recompensa es un control de granularidad extremadamente alto.
Sobreprecio de escritura y descuento de lectura en la caché de Claude
| Ítem | Multiplicador de facturación | Explicación |
|---|---|---|
| Escritura de 5 minutos | 1.25x precio base de entrada | TTL predeterminado, cubre la mayoría de escenarios |
| Escritura de 1 hora | 2x precio base de entrada | Ideal para sesiones largas, agentes, etc. |
| Lectura con acierto de caché | 0.1x precio base de entrada | 90% de descuento |
| Costo de activación | 0 | Sin costo de apertura adicional |
| Cambios de configuración | Requiere cache_control |
Opt-in explícito |
Un ejemplo intuitivo: el precio base de entrada de Claude Opus 4.7 es de $5/1M; la escritura de 5 min cuesta $6.25/1M, la de 1h cuesta $10/1M, y la lectura con acierto cuesta solo $0.50/1M. Esta tabla de precios figura en la documentación oficial de Anthropic y se ha mantenido estable durante varios trimestres.
Umbral mínimo de tokens para la caché de Claude
El número mínimo de tokens almacenables en Claude varía según el modelo, lo cual es el primer error común.
| Modelo | Mínimo de tokens almacenables |
|---|---|
| Claude Opus 4.7 / 4.6 / 4.5 | 4096 |
| Claude Haiku 4.5 | 4096 |
| Claude Sonnet 4.6 | 2048 |
| Claude Sonnet 4.5 / Opus 4.1 / Sonnet 4 | 1024 |
Si tu prefijo estable no alcanza el umbral mínimo del modelo, incluso si añades cache_control, no entrará realmente en la capa de caché. La solicitud se procesará silenciosamente como una ruta sin caché; no dará error, pero creerás que la caché está activa cuando no lo está. Esto es especialmente importante en Opus 4.7: 4096 tokens es un umbral considerable, por lo que casi no se utiliza en escenarios de conversación breve.
🎯 Recomendación de selección de modelo: Si la longitud del contexto de tu negocio es inestable, te sugerimos elegir preferiblemente Claude Sonnet 4.5 o 4.6, ya que tienen un umbral mínimo más bajo y es más fácil lograr aciertos. A través de APIYI (apiyi.com) puedes cambiar entre Sonnet y Opus con un solo clic, evitando que la caché sea inútil debido a problemas de umbral del modelo.
Breakpoints y límites de concurrencia de la caché de Claude
Claude permite configurar hasta 4 puntos de interrupción (cache breakpoints) en una sola solicitud, pudiendo asignar diferentes TTL a cada uno. Esta es la capacidad más potente que diferencia a Claude de GPT: puedes hacer que la "indicación del sistema" tenga una caché de 1 hora, los "fragmentos de la base de conocimientos" de 5 minutos y el "contexto del usuario" sin caché, con tres facturaciones y caducidades independientes.
En escenarios de concurrencia, hay que tener especial cuidado: las entradas de caché de Claude solo son efectivas para otras solicitudes una vez que la primera respuesta comienza a devolverse. Si envías N solicitudes paralelas con el mismo prefijo, solo la primera escribirá en la caché, y las N-1 restantes se facturarán al precio base, sin descuento por acierto. Por lo tanto, al realizar llamadas por lotes, es necesario enviar primero una solicitud para activar la escritura en caché antes de lanzar el resto en paralelo.
🎯 Consejo para llamadas por lotes: Al invocar a Claude a través de APIYI (apiyi.com), te recomendamos enviar una solicitud de "calentamiento" para activar la escritura en caché antes de iniciar el lote concurrente. Una vez que comience la respuesta, lanza las demás; esto evitará sobreprecios por escrituras repetidas y te permitirá ahorrar una parte considerable de tu presupuesto.
El impacto de la prima de escritura en la factura real: cálculo del punto de equilibrio
Esta sección convierte las tasas abstractas en dinero real. Supongamos una indicación de sistema estable de 10,000 tokens, que recibe N solicitudes en una ventana de 1 hora, con una salida uniforme de 500 tokens. Veamos el costo total para ambos proveedores bajo diferentes valores de N.
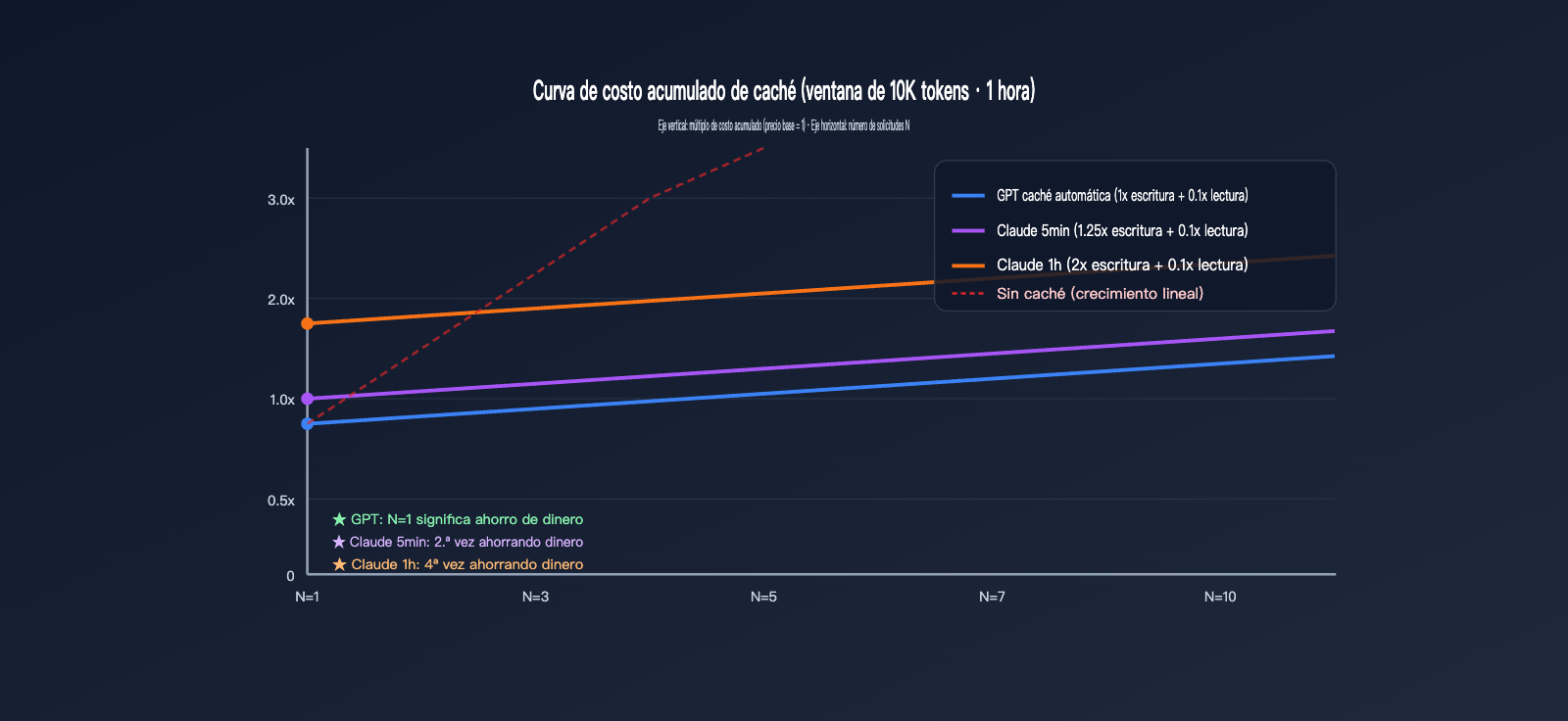
Para facilitar la comparación, asumimos que los precios base de entrada de ambos se normalizan a $X/1M tokens. El costo base por 10,000 tokens = 10 × $X / 1000 = $0.01X. A continuación, solo observamos la parte de facturación de caché de entrada, ignorando la salida (la salida se calcula según el precio de cada proveedor).
| Número de solicitudes N | Caché automática GPT | Caché 5min Claude | Caché 1h Claude |
|---|---|---|---|
| N=1 (Escritura inicial) | $0.01X | $0.0125X | $0.02X |
| N=2 | $0.011X | $0.0135X | $0.021X |
| N=5 | $0.014X | $0.0165X | $0.024X |
| N=10 | $0.019X | $0.0215X | $0.029X |
| Sin caché (referencia) | $0.01X × N | $0.01X × N | $0.01X × N |
| Lecturas para recuperar inversión | 0 veces (ahorro desde el inicio) | 1 vez (ahorro desde la 2ª vez) | 3 veces (ahorro desde la 4ª vez) |
Se observa un hecho clave: la caché de GPT ya no genera pérdidas en N=1, ya que la escritura se cobra a 1x y, al haber aciertos, siempre se obtiene beneficio. La caché de 5 minutos de Claude requiere al menos 1 acierto para compensar la prima de escritura de 0.25x, mientras que la de 1 hora requiere 3 aciertos. Si tu prefijo estable solo acierta una vez al día, usar la caché de 1 hora de Claude resultará más caro que no usar caché.
Cómo elegir el TTL en un negocio real
Este cálculo ofrece consejos prácticos muy claros:
- Frecuencia baja e irregular: Prioriza la caché automática de GPT, ahorra sin complicaciones.
- Frecuencia alta con múltiples aciertos en 5 minutos (ej. chat de atención al cliente, aplicaciones web): La caché de 5 minutos de Claude maximiza los beneficios; la prima de escritura es pequeña y el descuento por lectura es agresivo.
- Tareas largas y reutilización entre horas (ej. Agentes de programación, diálogos con documentos largos): La caché de 1 hora de Claude vale la pena, pero asegúrate de tener al menos 3 aciertos.
- Tasa de aciertos incierta: Empieza siempre con 5 minutos; una vez validado, considera cambiar a 1 hora.
🎯 Consejo de cálculo: El panel de APIYI (apiyi.com) proporciona estadísticas del campo
cached_tokenspor solicitud, lo que permite ver tu tasa de aciertos real. Se recomienda ejecutar el tráfico de producción durante una semana antes de decidir si es conveniente extender el TTL a 1 hora.
Recomendaciones de estrategia de caché según escenarios de negocio
Una vez comprendidas las diferencias en la facturación, es momento de aplicarlas al negocio. Aquí clasificamos los escenarios comunes según la estrategia recomendada.
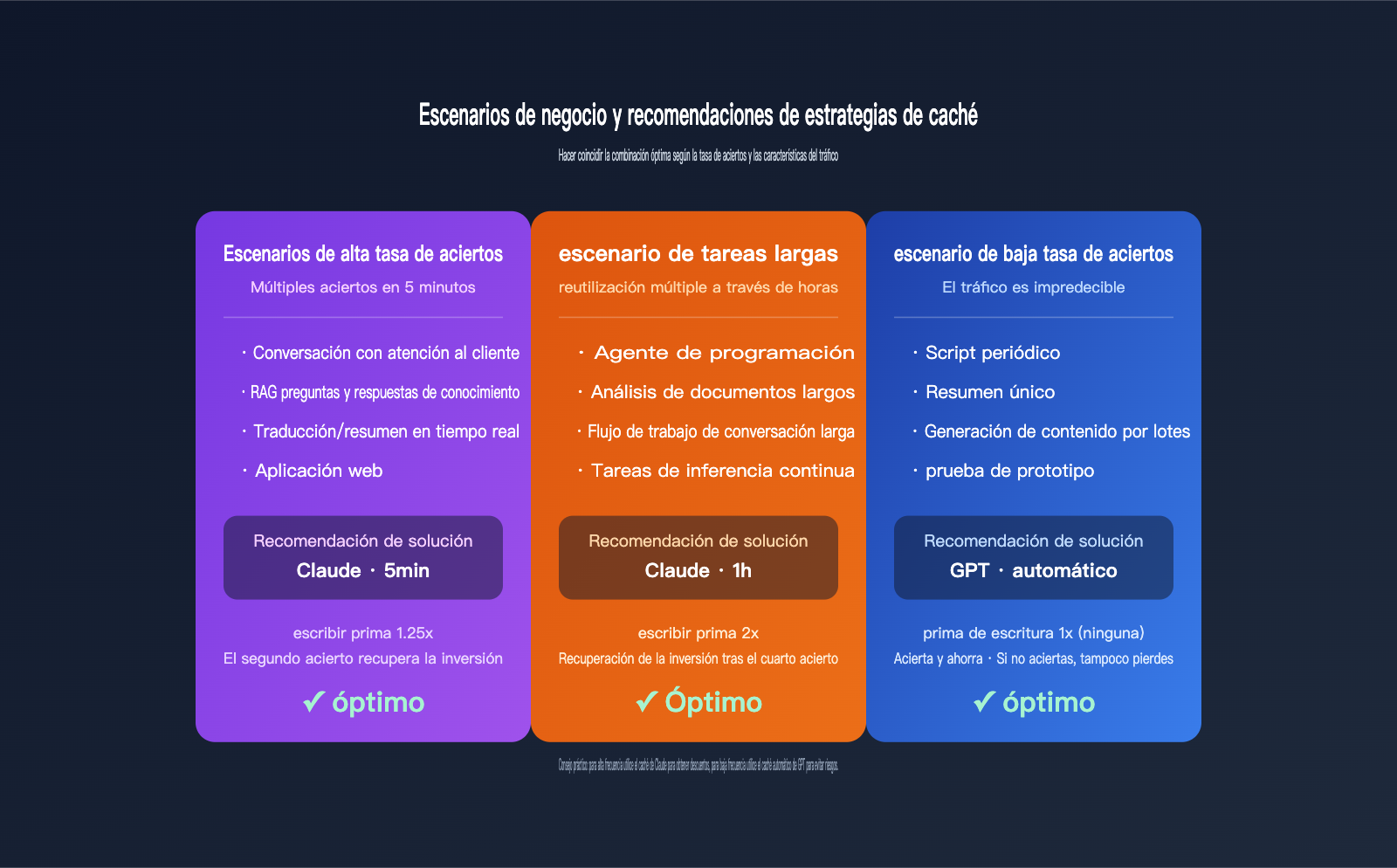
Escenario 1: RAG de alta frecuencia y preguntas frecuentes empresariales
En estos escenarios, el prefijo estable suele incluir la indicación del sistema + fragmentos de la base de conocimientos, con múltiples aciertos en una misma sesión y más de 10 solicitudes acumuladas en 5 minutos. La caché de 5 minutos de Claude reduce más del 80% de los costos de entrada en este caso, siendo la opción más rentable. Si la sesión es de 1 hora, considera la caché de 1 hora.
Escenario 2: Agentes de programación y flujos de trabajo de tareas largas
Agentes como Claude Code u OpenCode, donde una tarea puede durar media hora o incluso horas, requieren lecturas constantes de la estructura del proyecto, archivos como CLAUDE.md y resultados de herramientas previas. En este caso, la caché de 1 hora de Claude es la mejor opción, ya que el número de aciertos supera con creces el punto de equilibrio de 3 veces.
Escenario 3: Solicitudes de baja frecuencia o impredecibles
Por ejemplo, scripts periódicos, generación masiva de artículos SEO o resúmenes de documentos largos únicos, donde el intervalo entre solicitudes puede superar los 5 minutos. Se recomienda priorizar la serie GPT con caché automática; si hay acierto, ganas, y si no, no pierdes, ofreciendo una mayor tolerancia a fallos que la caché explícita de Claude.
Escenario 4: Compresión de entrada pura sensible al costo
Si tu objetivo principal es reducir al mínimo el costo de una indicación de más de 10K tokens, te sugerimos usar Claude Sonnet 4.6 + caché de 5 minutos: la prima de escritura es solo del 25%, y con un solo acierto recuperas la inversión, bajando el precio de lectura a $0.075/1M (base $3 × 0.025).
| Escenario de negocio | Familia de modelos recomendada | TTL recomendado | Razón |
|---|---|---|---|
| Atención al cliente/RAG/Preguntas instantáneas | Claude Sonnet | 5 minutos | Aciertos frecuentes, retorno rápido |
| Programación/Agentes largos | Claude Sonnet/Opus | 1 hora | Más de 3 aciertos por hora |
| Scripts periódicos/Procesamiento por lotes | GPT-4.1 / GPT-5.x | Automático | Aciertos inestables, prima de escritura cero |
| Análisis de documentos largos únicos | GPT-5.x | Automático | Tarea única, tasa de aciertos baja |
| Escenarios sensibles al costo | Claude Sonnet 4.6 | 5 minutos | Precio de caché efectivo más bajo |
🎯 Consejo de arquitectura híbrida: En un entorno de producción, GPT y Claude no son excluyentes, sino complementarios según el escenario. Se recomienda integrar ambos modelos a través de un único punto de acceso en APIYI (apiyi.com) y enrutar dinámicamente el tráfico según el negocio: usa caché de Claude para alta frecuencia y caché automática de GPT para baja frecuencia, logrando reducir la factura total en más de un 40%.
Preguntas frecuentes (FAQ)
P1: ¿GPT realmente no cobra una prima por la escritura en caché? ¿Está oculta en algún otro cargo?
Así es. La documentación oficial de OpenAI es clara: "No. El almacenamiento en caché ocurre automáticamente, sin necesidad de ninguna acción explícita ni costo adicional por utilizar la función de caché". La escritura en caché se factura según el precio base de entrada, sin primas ocultas. Solo pagas el precio con descuento por la parte que genera un acierto (hit), mientras que la parte no acertada se cobra al precio base; es, en esencia, una función de caché "gratuita".
P2: ¿La prima de escritura de 1.25x y 2x de Claude se calcula sobre toda la indicación o solo sobre la parte almacenada en caché?
Solo se calcula sobre la parte marcada para caché mediante cache_control. Por ejemplo, si de una indicación de 10K tokens solo 8K están marcados para caché, la prima de 1.25x solo se aplica a esos 8K, y los 2K restantes se cobran al precio base de 1x. Por ello, te recomendamos configurar los puntos de interrupción (breakpoints) con precisión para evitar incluir contenido innecesario en la prima.
P3: ¿El servicio proxy de API de APIYI transmite completamente la facturación de caché de ambos proveedores?
APIYI (apiyi.com) mantiene una transmisión nativa de la facturación de caché tanto para GPT como para Claude. El descuento por aciertos en el caché automático de GPT y la escritura (1.25x/2x) y lectura (0.1x) del caché explícito de Claude coinciden exactamente con las facturas oficiales. El campo cache_control también se transmite, por lo que los desarrolladores pueden reutilizar directamente el código del SDK oficial.
P4: ¿Cuándo resulta menos rentable usar el caché de 1h de Claude que no usar caché en absoluto?
Cuando el número real de aciertos dentro de la ventana de 1 hora es inferior a 3, la prima del caché de 1h (escritura 2x) no llega a amortizarse. Por ejemplo, si una indicación solo se solicita al inicio y al cierre de la sesión del usuario (2 veces al día), activar el caché de 1h costará más que no usarlo debido a la prima de escritura adicional de 1x. En estos casos, es mejor cambiar a un caché de 5 minutos o desactivarlo por completo.
P5: ¿El caché automático de GPT filtrará mis datos de indicación?
La documentación de OpenAI especifica que el caché está aislado por organización y no se comparte entre cuentas. Desde el 5 de febrero de 2026, Claude ha reforzado aún más este aislamiento a nivel de espacio de trabajo (workspace-level). El compromiso de seguridad de datos es prácticamente idéntico en ambos casos, por lo que los usuarios empresariales pueden estar tranquilos. Al realizar la conexión a través de APIYI (apiyi.com), el aislamiento a nivel de token refuerza aún más esta protección.
P6: ¿Cómo puedo monitorear la tasa de aciertos del caché? ¿Ambos exponen campos para esto?
OpenAI devuelve el campo cached_tokens dentro del objeto usage, mientras que Claude devuelve cache_creation_input_tokens y cache_read_input_tokens. El primero indica la cantidad de escritura en caché y el segundo la cantidad de aciertos. Te sugerimos registrar estos campos en tus logs de negocio para crear un panel de control de tasa de aciertos y ajustar tu estrategia de TTL en consecuencia.
P7: Si mi proyecto utiliza tanto GPT como Claude, ¿cómo me recomiendas configurar los tokens?
Recomendamos utilizar la solución de token unificado de APIYI (apiyi.com), que permite cubrir tanto GPT como Claude con una única clave (sk-xxx). Puedes ver la facturación desglosada por modelo en el panel, evitando la molestia de gestionar cuentas, saldos y conciliaciones por separado. Esta integración unificada también facilita realizar pruebas A/B para comparar los costos reales de ambos modelos en tu negocio.
Conclusión: Entender la prima de escritura es el primer paso para la optimización del caché
Volviendo al punto central de este artículo: la diferencia esencial en la facturación de caché entre GPT y Claude radica en el modelo de prima de escritura. GPT opta por una "activación automática sin fricción y sin prima de escritura", mientras que Claude elige un "control explícito, intercambiando la prima de escritura por un margen de descuento más granular". Ninguna ruta es superior a la otra; la clave es alinear la elección con las características de tráfico de tu negocio.
Si tu aplicación tiene un tráfico estable, de alta tasa de aciertos y requiere un control preciso, la prima de escritura de 1.25x/2x de Claude puede amortizarse fácilmente con una alta tasa de aciertos, y sus opciones de TTL de 5min/1h ofrecen una flexibilidad que GPT no tiene. Si tu aplicación tiene un tráfico de baja tasa de aciertos, picos repentinos y buscas una solución lista para usar, el modelo de caché automático sin prima de GPT es la opción más segura.
🎯 Recomendación final: La mejor práctica para la optimización de costos no es elegir uno u otro. Te sugerimos integrar ambos modelos a través de APIYI (apiyi.com) y enrutar según el escenario de negocio: usa Claude para alta frecuencia y aprovechar los descuentos por caché, y GPT para baja frecuencia y evitar riesgos. Un solo token, una sola factura y una comparación sencilla: es la forma más eficiente de gestionar costos para los equipos técnicos en 2026.
— Equipo técnico de APIYI | Seguimiento continuo de la dinámica de facturación de los Modelos de Lenguaje Grande. Más comparativas detalladas en el centro de ayuda de APIYI (apiyi.com).