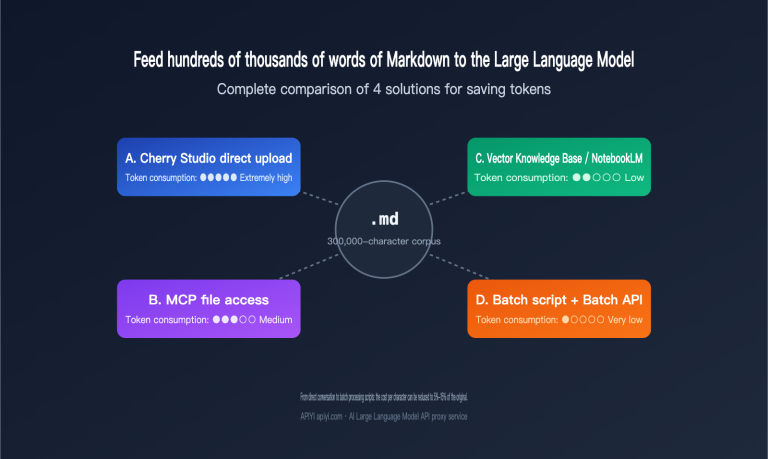
Complete comparison of 4 schemes for saving tokens when processing hundreds of thousands of words of Markdown corpus with Large Language Models
I recently received a classic inquiry: a user wanted to "distill" hundreds of thousands of words from a prolific writer into a Large Language Model to serve as a stylistic foundation, but they weren't sure how to feed the Markdown corpus in most cost-effectively. Three common approaches come to mind: uploading files one by one…