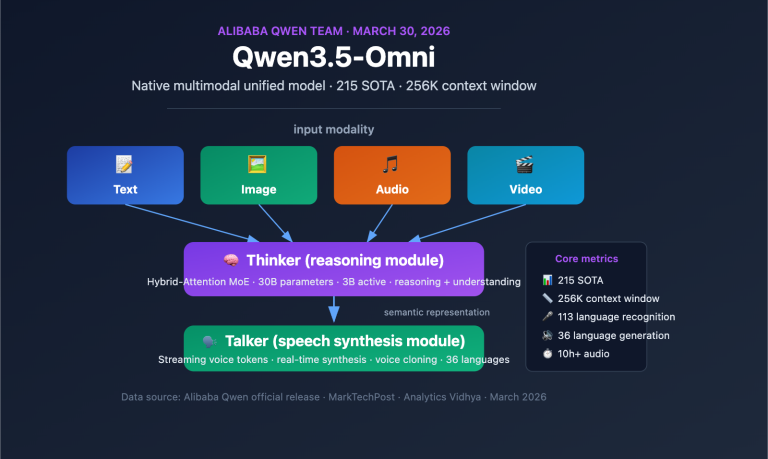
Decoding Qwen3.5-Omni Native Multimodal Model: Thinker-Talker Architecture Achieves Unified Processing of 4 Modalities and Speech Recognition for 113 Languages
description: A deep dive into the Qwen3.5-Omni native multimodal model, covering its Thinker-Talker MoE architecture, 256K context window, and Audio-Visual Vibe Coding capabilities. Author's Note: A detailed breakdown of the Alibaba Qwen3.5-Omni native multimodal model, covering its Thinker-Talker MoE architecture, 256K context window, audio-video encoding capabilities, and the emergent Audio-Visual Vibe Coding ability. On March…