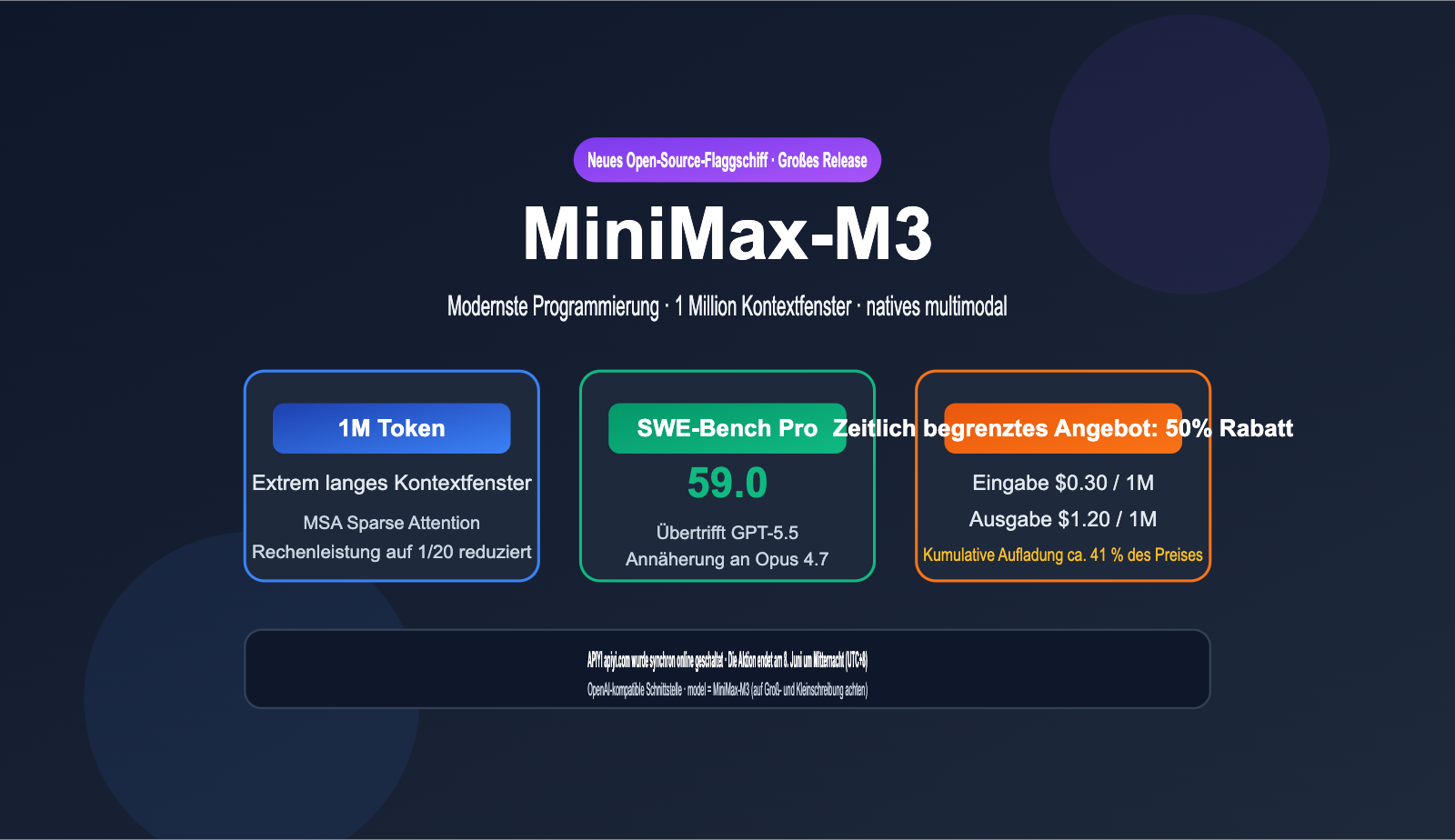
Am 1. Juni 2026 veröffentlichte MiniMax offiziell sein neues Open-Weight-Flaggschiff: MiniMax-M3. Dies ist das branchenweit erste Modell, das drei Kernfähigkeiten in einem einzigen Modell vereint: erstklassige Programmierleistung, ein Kontextfenster von 1 Million Token und native multimodale Eingabe. Mit einem Wert von 59,0 Punkten im SWE-Bench Pro übertrifft es GPT-5.5 und Gemini 3.1 Pro und nähert sich dem Niveau von Claude Opus 4.7.
Besonders beeindruckend ist die Preisgestaltung. Der offizielle Standardpreis liegt bei 0,60 $ für die Eingabe und 2,40 $ für die Ausgabe pro 1 Million Token – das sind lediglich 5 % bis 10 % der Kosten vergleichbarer Closed-Source-Modelle. Zum Start gibt es zudem einen zeitlich begrenzten Rabatt von 50 %, wodurch der Preis auf 0,30 $ (Eingabe) bzw. 1,20 $ (Ausgabe) sinkt. MiniMax-M3 ist ab sofort auf der APIYI-Plattform (apiyi.com) verfügbar. Dort wird der 50%-Rabatt der offiziellen Website übernommen, und durch zusätzliche Auflade-Boni sinken die effektiven Kosten auf bis zu 41 % des Standardpreises. Die Aktion läuft bis zum 8. Juni, 00:00 Uhr (UTC+8).
In diesem Artikel erläutern wir die Architektur-Highlights, Benchmark-Ergebnisse, Preisstufen und den Integrationscode für MiniMax-M3, damit Sie entscheiden können, ob sich ein Wechsel während des Aktionszeitraums für Sie lohnt.
Was ist MiniMax-M3: Das "Drei-in-Eins"-Flaggschiff des Open-Source-Lagers
MiniMax-M3 ist das neue Flaggschiff von MiniMax, das auf die M2-Serie folgt und als universelles Modell für Programmierung und Agenten-Szenarien konzipiert ist. Es verwendet eine feingranulare MoE-Architektur (Mixture of Experts) mit insgesamt ca. 229,9 Mrd. Parametern, wobei pro Token nur etwa 9,8 Mrd. Parameter über 256 Experten aktiviert werden. Das bedeutet, dass die Inferenzkosten eher denen eines kleinen 10B-Modells entsprechen, während die Leistung mit der ersten Garde der Flaggschiff-Modelle konkurriert.
Die Trainingsdaten umfassen etwa 100 Billionen Token, wobei bereits in der Vor-Trainingsphase gemischte Bild-Text-Daten integriert wurden. Daher ist die Multimodalität von MiniMax-M3 "nativ" – die Fähigkeiten zum Verständnis von Bildern und Videos sind direkt im semantischen Raum verankert und nicht erst nachträglich durch einen externen visuellen Encoder hinzugefügt. Neben der Eingabe von Bildern und Videos unterstützt es auch die Bedienung von Desktop-Computern (Computer Use), was ausreichend Schnittstellen für Agenten-Szenarien bietet.
MiniMax hat zugesichert, dass die Modellgewichte und der technische Bericht innerhalb von 10 Tagen nach der Veröffentlichung vollständig quelloffen zur Verfügung gestellt werden. Sie werden dann auf HuggingFace und GitHub abrufbar sein und sowohl die private Bereitstellung als auch das Fine-Tuning unterstützen. Basierend auf der modifizierten MIT-Lizenz der M2-Serie ist mit niedrigen Hürden für die kommerzielle Nutzung zu rechnen; die Details hängen von der offiziell veröffentlichten Lizenz ab.
Die technischen Spezifikationen von MiniMax-M3 im Überblick
| Dimension | MiniMax-M3 Spezifikation |
|---|---|
| Veröffentlichungsdatum | 1. Juni 2026 |
| Architektur | Feingranulares MoE, 229,9B Gesamtparameter / 9,8B aktiv, 256 Experten |
| Aufmerksamkeitsmechanismus | MSA (MiniMax Sparse Attention) |
| Kontextfenster | 1.000.000 Token (ca. 5-mal so groß wie bei der M2-Serie) |
| Modalitätsunterstützung | Text + Bild + Video-Eingabe, Text-Ausgabe, unterstützt Desktop-Bedienung |
| Trainingsdaten | ca. 100T Token, multimodale Bild-Text-Korpora |
| Denkmodus | Aktivierbarer "Thinking"-Modus, einheitliche Preisgestaltung |
| Open-Source-Plan | Offenlegung der Gewichte und des technischen Berichts innerhalb von 10 Tagen |
🎯 Empfehlung für einen schnellen Test: Wenn Sie die Leistungsfähigkeit von MiniMax-M3 sofort überprüfen möchten, müssen Sie nicht auf die Veröffentlichung der Gewichte warten, um einen eigenen Cluster aufzubauen. Wir empfehlen, die OpenAI-kompatible Schnittstelle von APIYI (apiyi.com) zu nutzen. Geben Sie einfach
MiniMax-M3als Modellnamen ein. So können Sie innerhalb weniger Minuten Vergleichstests durchführen und während des Aktionszeitraums die Kosten halbieren.
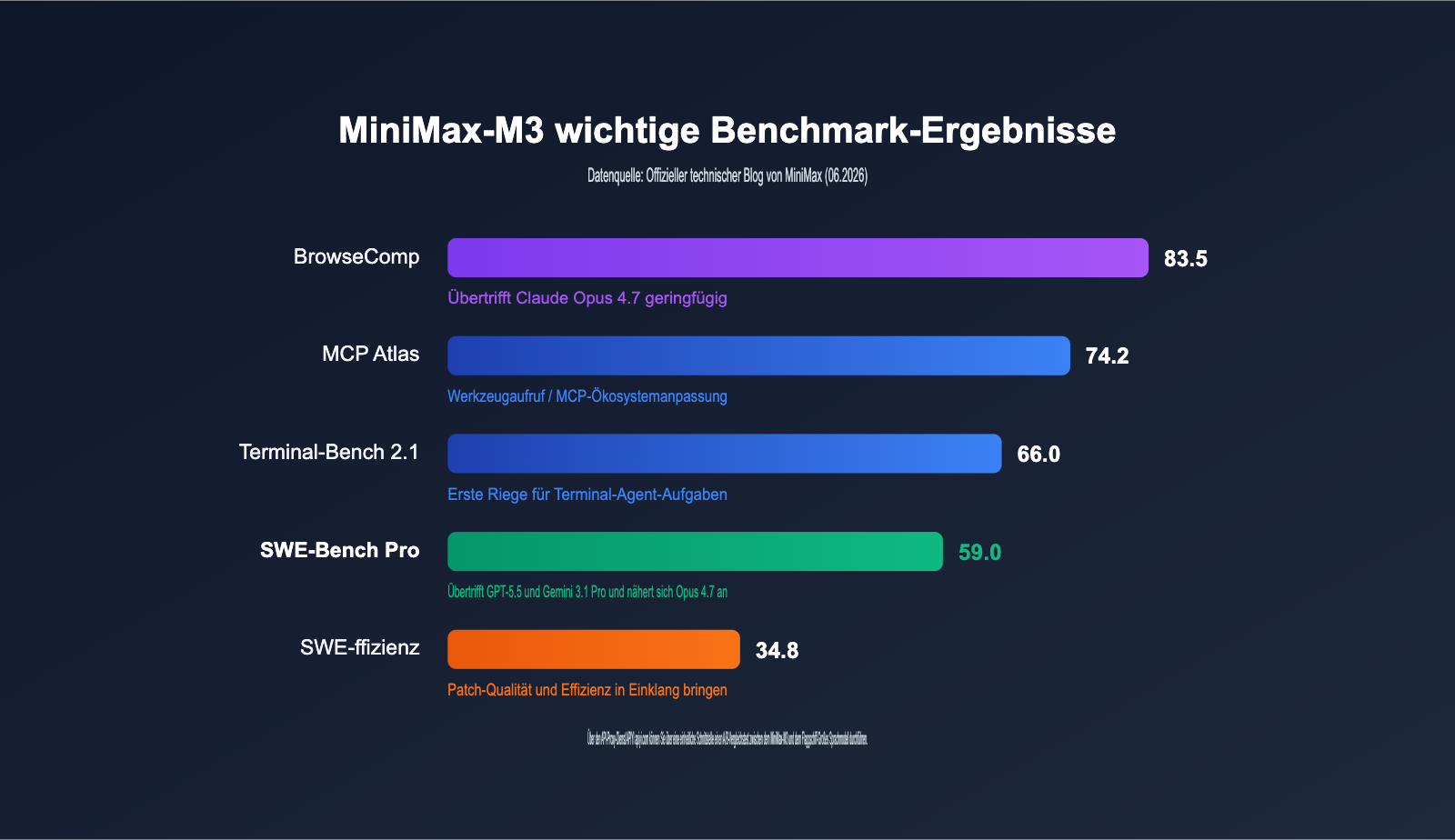
Benchmarkergebnisse von MiniMax-M3: Was bedeutet der SWE-Bench Pro Score von 59,0?
SWE-Bench Pro gilt derzeit als einer der anspruchsvollsten Benchmarks für reale Softwareentwicklung. Er prüft die End-to-End-Fähigkeiten eines Modells, in echten Code-Repositories Fehler zu beheben und Patches zu erstellen. Mit einem Score von 59,0 übertrifft MiniMax-M3 laut offiziellen Vergleichsdaten sowohl GPT-5.5 als auch Gemini 3.1 Pro und liegt nur knapp hinter Claude Opus 4.7. Für ein Modell, das kurz vor der Open-Source-Veröffentlichung steht und weniger als 10 Mrd. Parameter besitzt, ist dies das erste Mal, dass ein Open-Source-Modell in diesem Benchmark die proprietären Flaggschiff-Modelle überholt.
Neben der Programmierung sind auch die Agenten-Metriken beeindruckend: 66,0 Punkte im Terminal-Bench 2.1, 74,2 Punkte im MCP Atlas und 83,5 Punkte bei autonomen Browse-Aufgaben (BrowseComp) – letzteres übertrifft sogar leicht Claude Opus 4.7. Im multimodalen Bereich übertrifft das Modell im SVG-Bench Opus 4.7, und beim Dokumentenverständnis (OmniDocBench) liegt es vor Gemini 3.1 Pro.
Natürlich ist es kein vollständiger Durchmarsch. Im PostTrainBench, der die Fähigkeiten des nachträglichen Trainings in der Forschung bewertet, erreicht MiniMax-M3 0,37 Punkte, was unter dem Wert von Claude Opus 4.7 (0,42) liegt und etwa auf dem Niveau von GPT-5.5 (0,39) ist. Ein wichtiger Hinweis: Diese Zahlen stammen derzeit aus dem offiziellen technischen Blog; unabhängige Tests durch Dritte laufen noch. Für geschäftskritische Anwendungen empfehlen wir, eigene Tests durchzuführen.
Vergleich von MiniMax-M3 mit führenden Flaggschiff-Modellen
| Benchmark | MiniMax-M3 | Fazit |
|---|---|---|
| SWE-Bench Pro | 59,0 | Übertrifft GPT-5.5 & Gemini 3.1 Pro, nähert sich Opus 4.7 |
| Terminal-Bench 2.1 | 66,0 | Spitzenklasse bei Terminal-Agent-Aufgaben |
| BrowseComp | 83,5 | Übertrifft leicht Claude Opus 4.7 |
| MCP Atlas | 74,2 | Starke Fähigkeiten bei Tool-Aufrufen & MCP-Integration |
| SWE-fficiency | 34,8 | Ausgewogenes Verhältnis von Patch-Qualität & Effizienz |
| PostTrainBench | 0,37 | Unter Opus 4.7 (0,42), gleichauf mit GPT-5.5 (0,39) |
Wenn Sie diese Zahlen selbst validieren möchten, können Sie auf der APIYI-Plattform dieselbe Eingabeaufforderung verwenden, um MiniMax-M3, GPT-5.5 und Claude Opus 4.7 gleichzeitig aufzurufen. Die Plattform vereinheitlicht das Schnittstellenformat, sodass Sie für A/B-Tests lediglich den Modellparameter ändern müssen.
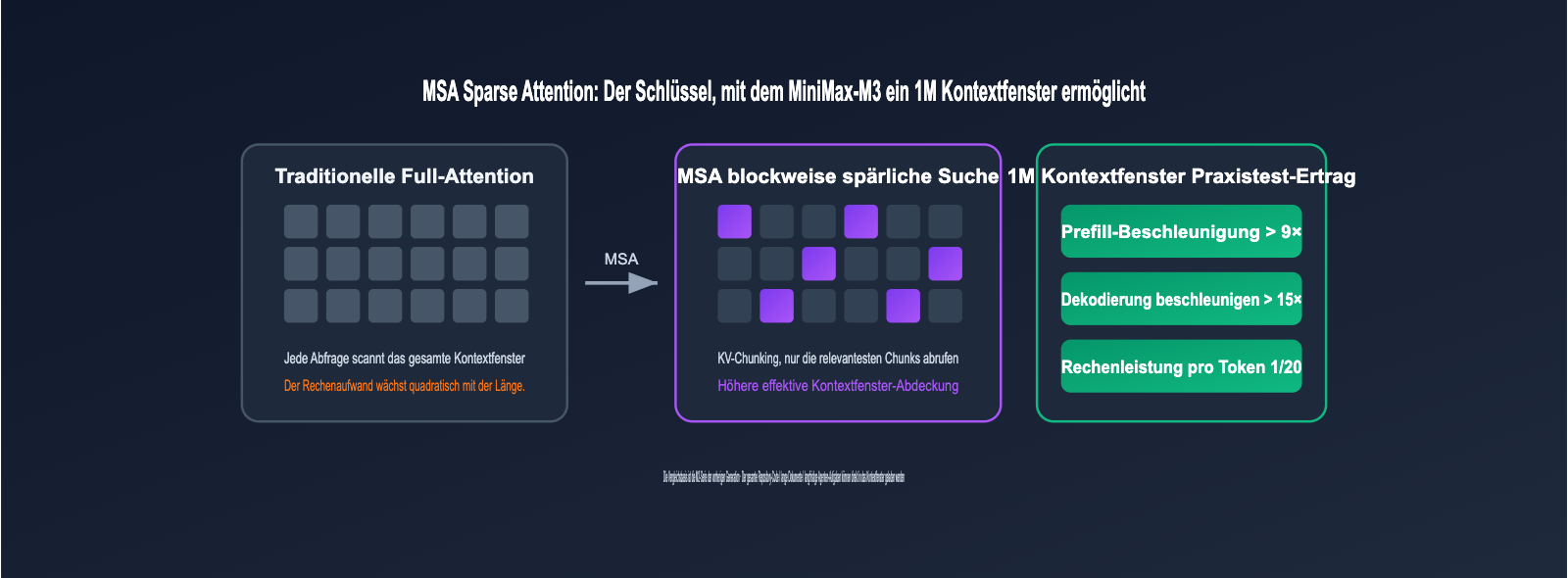
Architektur von MiniMax-M3: Wie MSA Sparse Attention das 1M-Kontextfenster ermöglicht
Ein Kontextfenster von 1 Million Token ist nichts Ungewöhnliches, aber es wirtschaftlich nutzbar zu machen, ist die eigentliche Herausforderung. Die Antwort von MiniMax-M3 ist die selbst entwickelte MSA (MiniMax Sparse Attention). Während der Rechenaufwand herkömmlicher Full-Attention-Mechanismen quadratisch mit der Kontextlänge wächst, unterteilt MSA den KV-Cache in Blöcke. Jeder Query sucht präzise nur die relevantesten KV-Blöcke, was eine höhere effektive Kontextabdeckung ermöglicht.
Die offiziellen technischen Daten sind beeindruckend: Bei einem Kontext von 1M Token beträgt der Rechenaufwand pro Token bei MiniMax-M3 nur 1/20 der Vorgängergeneration M2. Die Prefill-Geschwindigkeit wurde um das Neunfache und die Dekodierung um das 15-Fache gesteigert; auf Operatorebene ist es viermal schneller als das Open-Source-Modell Flash-Sparse-Attention. Mit anderen Worten: Das Einlesen ganzer Code-Repositories, hunderter PDF-Seiten oder einstündiger Konferenzvideos ist hinsichtlich Latenz und Kosten kein Hindernis mehr.
Für Entwickler bedeutet das direkt: Viele Aufgaben, die früher RAG-Splitting, Vektorsuche oder mehrstufige Zusammenfassungen erforderten, können jetzt "in einem Rutsch" direkt in die Eingabeaufforderung eingefügt werden. Auch bei langfristigen Agenten-Aufgaben ist eine häufige Komprimierung der Historie nicht mehr nötig, was die Aufgabenkohärenz deutlich verbessert.
💡 Hinweis zum Testen langer Kontexte: Die Abrechnung für 1M Kontext erfolgt in zwei Stufen; ab einer Eingabe von über 512K verdoppelt sich der Stückpreis. Wir empfehlen, im APIYI-Kontrollzentrum (apiyi.com) zunächst mit realen Dokumenten im Bereich von 200K-400K zu testen, um die Qualität zu prüfen, bevor Sie längere Eingaben verwenden. Die Nutzungsstatistik der Plattform hilft Ihnen dabei, die Token-Kosten für jeden Aufruf präzise zu berechnen.
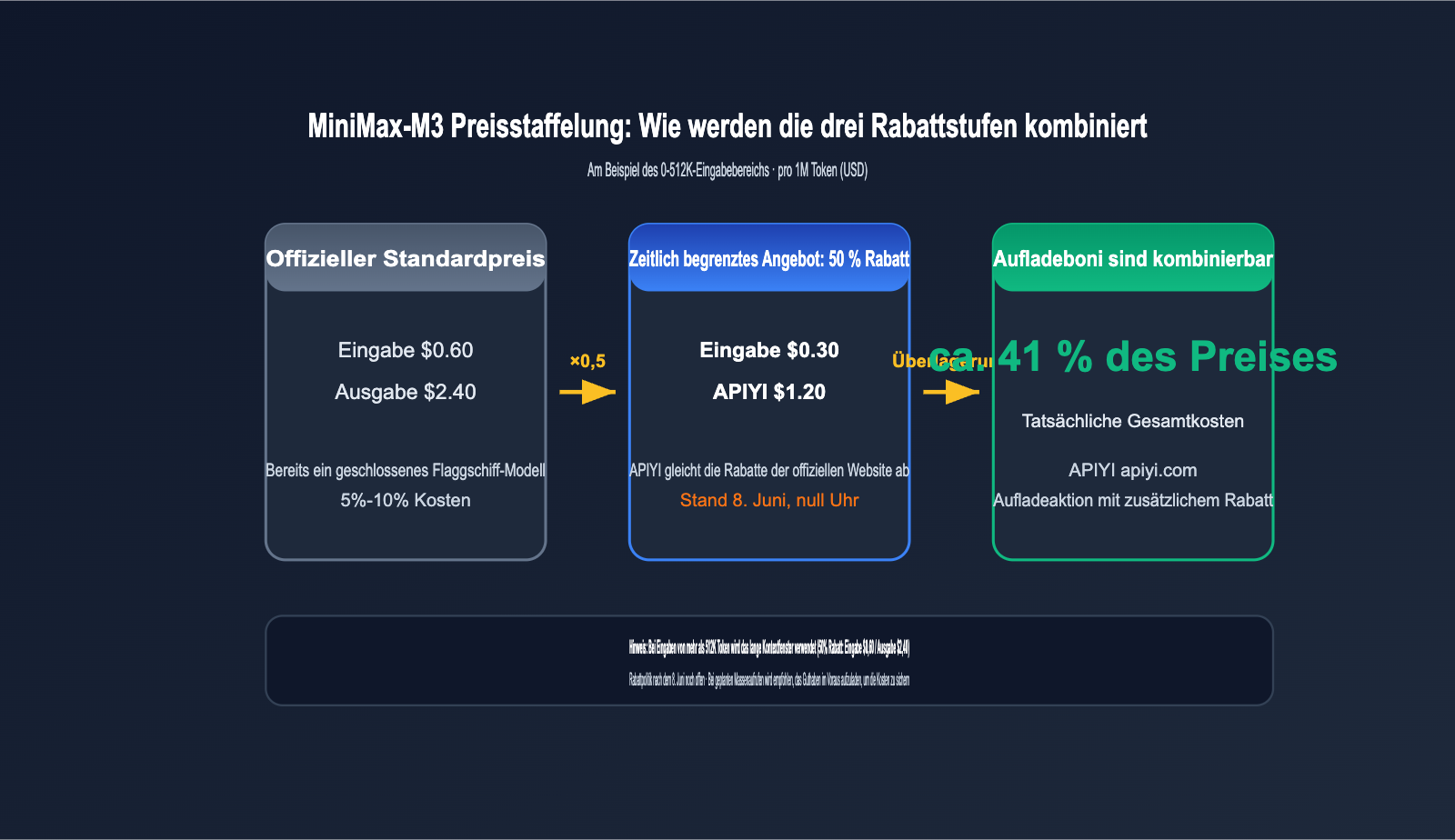
MiniMax-M3 API-Preise: Zeitlich begrenzter Rabatt von 50 % + Aufladebonus für bis zu 58,9 % Ersparnis
Die Preisgestaltung von MiniMax-M3 basiert auf einem gestaffelten Modell, das sich nach der Eingabelänge richtet. Eingaben von 0-512K Tokens fallen unter den Standardtarif, während alles darüber als Langkontext abgerechnet wird. Zum Start gibt es einen Rabatt von 50 % auf das gesamte Sortiment. APIYI (apiyi.com) hat die offiziellen Rabatte bereits übernommen. Die Aktion läuft bis zum 8. Juni 2026 um Mitternacht (UTC+8); die Rabattpolitik für die Zeit danach wird noch festgelegt.
MiniMax-M3 API-Preistabelle (pro 1M Tokens)
| Abrechnungsstufe | Eingabe (50 % Aktionspreis) | Ausgabe (50 % Aktionspreis) | Standardpreis nach Aktion (Ein-/Ausgabe) |
|---|---|---|---|
| 0-512K Eingabe | $0,30 | $1,20 | $0,60 / $2,40 |
| Über 512K Eingabe | $0,60 | $2,40 | $1,20 / $4,80 |
Um ein Gefühl für diese Preise zu bekommen: Ein Code-Review-Task mit einer Million Tokens kostet bei führenden Closed-Source-Modellen oft über zehn Dollar. Mit dem Aktionspreis von MiniMax-M3 zahlen Sie nur einen Bruchteil eines Dollars – ein Kostenunterschied um den Faktor 10 bis 20. Bei hochfrequenten Agenten-Pipelines, massenhaften Code-Migrationen oder der Verarbeitung langer Dokumente spart diese Differenz innerhalb eines Monats die Kosten für einen ganzen Entwicklungsrechner.
Auf der APIYI-Plattform können Sie die Kosten sogar noch weiter senken. Die Aufladeboni der Plattform lassen sich mit dem 50%-Rabatt kombinieren, wodurch die tatsächlichen Kosten auf bis zu ca. 41,1 % des ursprünglichen Preises sinken. Wenn Ihr Team ohnehin ein stabiles Volumen an Modellaufrufen hat, ist eine Aufladung vor dem 8. Juni die wirtschaftlichste Entscheidung.
MiniMax-M3 API: Schneller Einstieg in 5 Minuten
MiniMax-M3 nutzt auf der APIYI-Plattform das standardmäßige OpenAI-kompatible Protokoll. Jedes SDK, Framework oder jeder Client, der eine benutzerdefinierte base_url unterstützt, kann nahtlos integriert werden. Ein wichtiger Hinweis: Der Modellname MiniMax-M3 unterscheidet strikt zwischen Groß- und Kleinschreibung. Das M muss großgeschrieben werden; minimax-m3 führt zu einer Fehlermeldung, dass das Modell nicht existiert.
Die Integration erfolgt in drei Schritten: Registrieren Sie sich auf APIYI (apiyi.com) und erstellen Sie einen API-Schlüssel. Setzen Sie die base_url auf https://api.apiyi.com/v1 und geben Sie als Modellparameter MiniMax-M3 an. Hier ist ein einfaches Python-Beispiel:
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1" # APIYI einheitliche Schnittstelle
)
response = client.chat.completions.create(
model="MiniMax-M3", # Achtung: Groß-/Kleinschreibung, M muss groß sein
messages=[
{"role": "user", "content": "Implementiere eine Fibonacci-Funktion mit LRU-Cache in Python"}
]
)
print(response.choices[0].message.content)
Wenn Sie Bilder oder Videos übertragen müssen, verwenden Sie einfach das multimodale Nachrichtenformat von OpenAI und ändern Sie den content in ein Array, das die image_url enthält. MiniMax-M3 übernimmt dann in derselben Sitzung sowohl die visuelle Analyse als auch die Codegenerierung. Agenten-Tools wie Cline, Cursor oder OpenClaw können ebenfalls direkt auf MiniMax-M3 umgestellt werden, indem Sie einfach die base_url und den Modellnamen in den Einstellungen anpassen.
Anwendungsbereiche für MiniMax-M3 im Überblick
| Szenario | Eignung | Erläuterung |
|---|---|---|
| Agenten-Programmierung / Bugfixing | ⭐⭐⭐⭐⭐ | SWE-Bench Pro 59.0, behält Kontext bei langen Aufgaben |
| Analyse & Migration ganzer Repositories | ⭐⭐⭐⭐⭐ | 1M Kontext bietet Platz für mittelgroße Repositories |
| Analyse langer Dokumente / multimodal | ⭐⭐⭐⭐⭐ | OmniDocBench übertrifft Gemini 3.1 Pro |
| Autonomes Browsing & Tool-Use-Agenten | ⭐⭐⭐⭐ | BrowseComp 83.5, MCP Atlas 74.2 |
| Forschung / fortgeschrittenes Reasoning | ⭐⭐⭐ | PostTrainBench schwächer als Opus 4.7, für gemischtes Routing geeignet |
Ein gemischtes Routing ist in der Praxis oft am sinnvollsten: Tägliche, hochfrequente Coding- und Dokumentenaufgaben werden zu 80 % von MiniMax-M3 übernommen, während die komplexesten Reasoning-Aufgaben an Claude Opus 4.7 oder GPT-5.5 delegiert werden. Über die einheitliche Schnittstelle von APIYI können Sie dieses "Preis-Leistungs-Layering" mit einem einzigen Code-Satz umsetzen, ohne mehrere Anbieter-Schlüssel und SDKs verwalten zu müssen.
FAQ zu MiniMax-M3
F1: Wann endet die 50%-Rabattaktion für MiniMax-M3?
Die Aktion endet am 8. Juni 2026 um Mitternacht (UTC+8), synchron zwischen der APIYI-Plattform und der offiziellen MiniMax-Website. Über die anschließende Preisgestaltung wurde offiziell noch nichts bekannt gegeben; erfahrungsgemäß kehren die Preise dann auf das Standardniveau zurück. Falls Sie umfangreiche Modellaufrufe planen, empfehlen wir, das Guthaben vor Ablauf der Frist aufzuladen. Durch die Kombination mit den Aufladeboni lassen sich die tatsächlichen Kosten auf etwa 41 % des Standardpreises senken.
F2: Ist MiniMax-M3 wirklich Open Source? Kann man die Gewichte bereits herunterladen?
Der Hersteller hat zugesagt, die Modellgewichte und den technischen Bericht innerhalb von 10 Tagen nach Veröffentlichung bereitzustellen, voraussichtlich auf der HuggingFace-Seite von MiniMaxAI. Zum Zeitpunkt dieses Artikels sind die Gewichte noch nicht hochgeladen. Teams, die nicht auf eine lokale Bereitstellung warten können, sollten zunächst die API nutzen, um die Leistung zu validieren, bevor sie Hardware-Investitionen für eine private Instanz tätigen – bei einem MoE-Modell mit 230 Mrd. Parametern sind die Anforderungen an den Grafikspeicher nicht zu unterschätzen.
F3: Ist das 1M-Kontextfenster nur Marketing oder wirklich nutzbar?
Die MSA-Architektur macht das 1M-Kontextfenster technisch tatsächlich einsatzbereit: Die Prefill-Geschwindigkeit steigt um das Neunfache, die Dekodierung um das 15-Fache, und der Rechenaufwand pro Token sinkt auf 1/20 im Vergleich zur Vorgängergeneration. Achten Sie jedoch auf die Abrechnungsstufen: Bei Eingaben über 512K verdoppelt sich der Preis pro Einheit. Wir empfehlen, die Länge des Kontextfensters je nach tatsächlichem Aufgabenbedarf zu steuern, anstatt es blind vollständig zu füllen.
F4: Wie entscheide ich mich zwischen MiniMax-M3, GPT-5.5 und Claude Opus 4.7?
Das hängt vom Aufgabentyp und dem Budget ab. Bei Programmier-Agenten, langem Kontext und multimodalen Dokumentenszenarien ist das Preis-Leistungs-Verhältnis von MiniMax-M3 derzeit ungeschlagen. Für komplexeste Schlussfolgerungen und wissenschaftliche Aufgaben hat Opus 4.7 weiterhin die Nase vorn. Wir empfehlen, reale Eingabeaufforderungen auf der APIYI-Plattform für kleine Vergleichstests zu nutzen; diese Daten sind aussagekräftiger als jede Bestenliste.
Fazit: MiniMax-M3 macht Flaggschiff-Leistung zum Schnäppchenpreis
Die Veröffentlichung von MiniMax-M3 ist eine echte Überraschung für den Modellmarkt 2026: Open-Source-Gewichte, ein SWE-Bench Pro-Ergebnis von 59,0 (übertrifft GPT-5.5), 1 Million Kontextfenster und native multimodale Fähigkeiten – und das bei einem offiziellen Preis, der nur 5–10 % der geschlossenen Flaggschiff-Modelle beträgt. Selbst wenn spätere Tests Dritter die Werte leicht nach unten korrigieren sollten, bleibt die Dominanz in Sachen "Preis-Leistung" kaum zu erschüttern.
Kurzfristig ist das aktuelle Zeitfenster für den Preis am attraktivsten: Der zeitlich begrenzte Rabatt von 50 % ($0,30 für Eingabe / $1,20 für Ausgabe pro 1M Token) endet am 8. Juni um Mitternacht. Auf APIYI (apiyi.com) können Sie dies mit Aufladeaktionen kombinieren, um effektiv etwa 41 % des Preises zu zahlen. Die sicherste Strategie ist es, die Evaluierung mit minimalen Kosten zu starten, bevor Sie entscheiden, ob Sie Ihren Produktions-Traffic umstellen.
Weitere Details zur Aktion und aktuelle Modell-Updates finden Sie in der offiziellen Ankündigung von APIYI: docs.apiyi.com/news/minimax-m3-launch
Autor: APIYI Team
Wir konzentrieren uns auf die Aggregation von KI-Großmodell-APIs und Best Practices. Für weitere Modellbewertungen und Integrationsleitfäden besuchen Sie bitte APIYI unter apiyi.com.