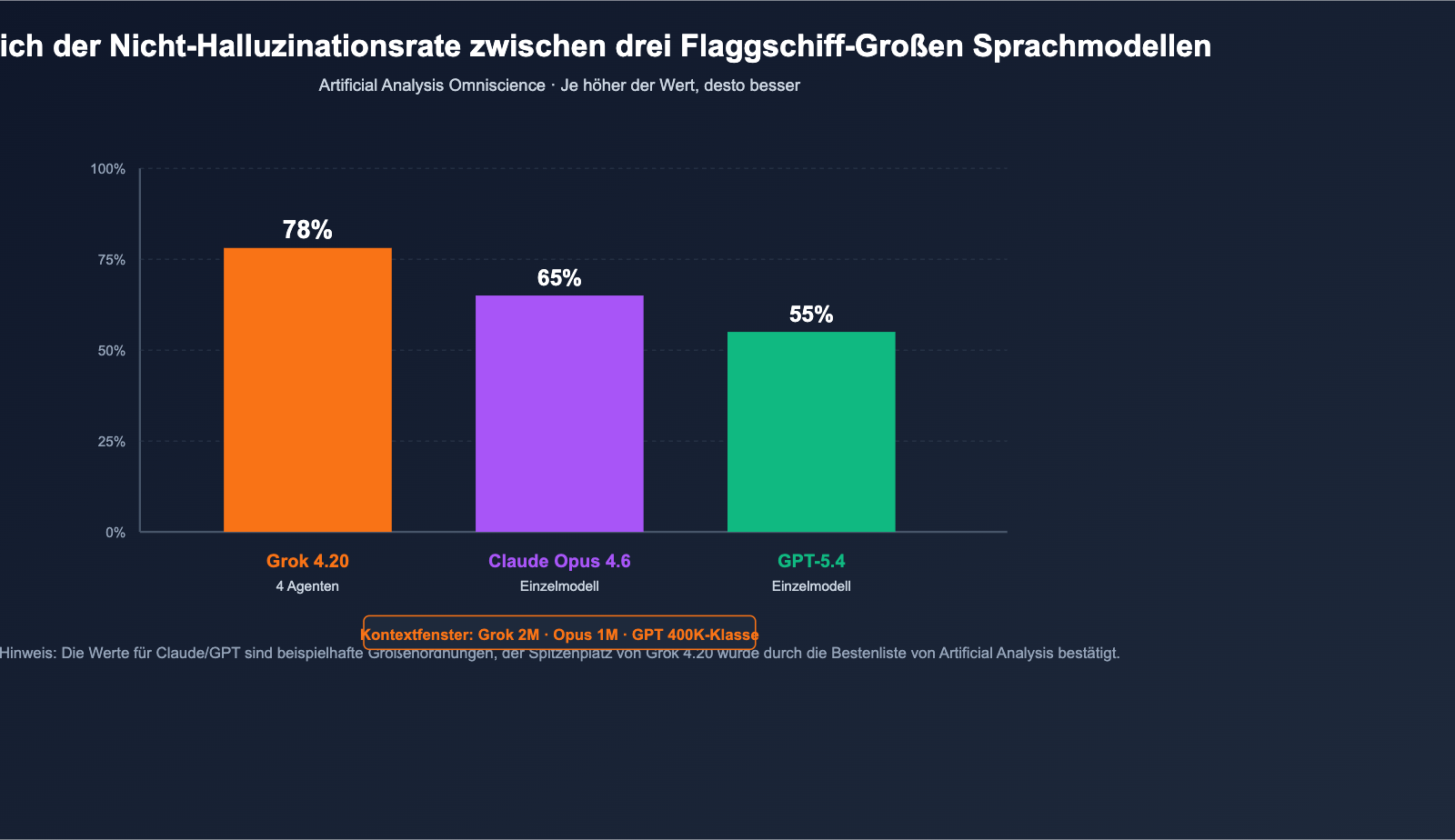
Am 17. Februar 2026 veröffentlichte xAI offiziell Grok 4.20 Beta. Mit einem unkonventionellen Ansatz übertrifft das Modell in der Kategorie „Halluzinationsrate“ – ein Bereich, der lange von der Claude- und GPT-Reihe dominiert wurde. Anstatt lediglich Parameter oder Inferenzschritte zu erhöhen, lässt das System 4 spezialisierte Agenten (Grok / Harper / Benjamin / Lucas) bei jeder komplexen Anfrage parallel arbeiten, debattieren und schließlich eine Antwort synthetisieren. Laut dem unabhängigen Tester Artificial Analysis Omniscience erreicht das Modell eine Halluzinationsrate von nur 78 % (die offizielle xAI-Angabe liegt bei 83 %). In öffentlichen Benchmarks übertrifft es damit Claude Opus 4.6 und GPT-5.4. Zudem erweitert Grok 4.20 das Kontextfenster auf 2 Mio. Token, was bei extrem langen Dokumenten und langfristigen Agentenaufgaben klare Vorteile bietet.
Die Rechenleistung wächst mit: Der Supercomputer-Cluster Colossus 2 von xAI wird schrittweise auf 1,5 GW ausgebaut, um die Skalierung von Grok 5 und weiteren Multi-Agenten-Systemen vorzubereiten. Dieser Artikel basiert auf englischsprachigen Primärquellen und erläutert die Architektur, Benchmarks, den „Heavy“-Modus, die API-Verfügbarkeit sowie Anwendungsfälle, damit Sie in unter 10 Minuten entscheiden können, ob sich ein Wechsel lohnt.
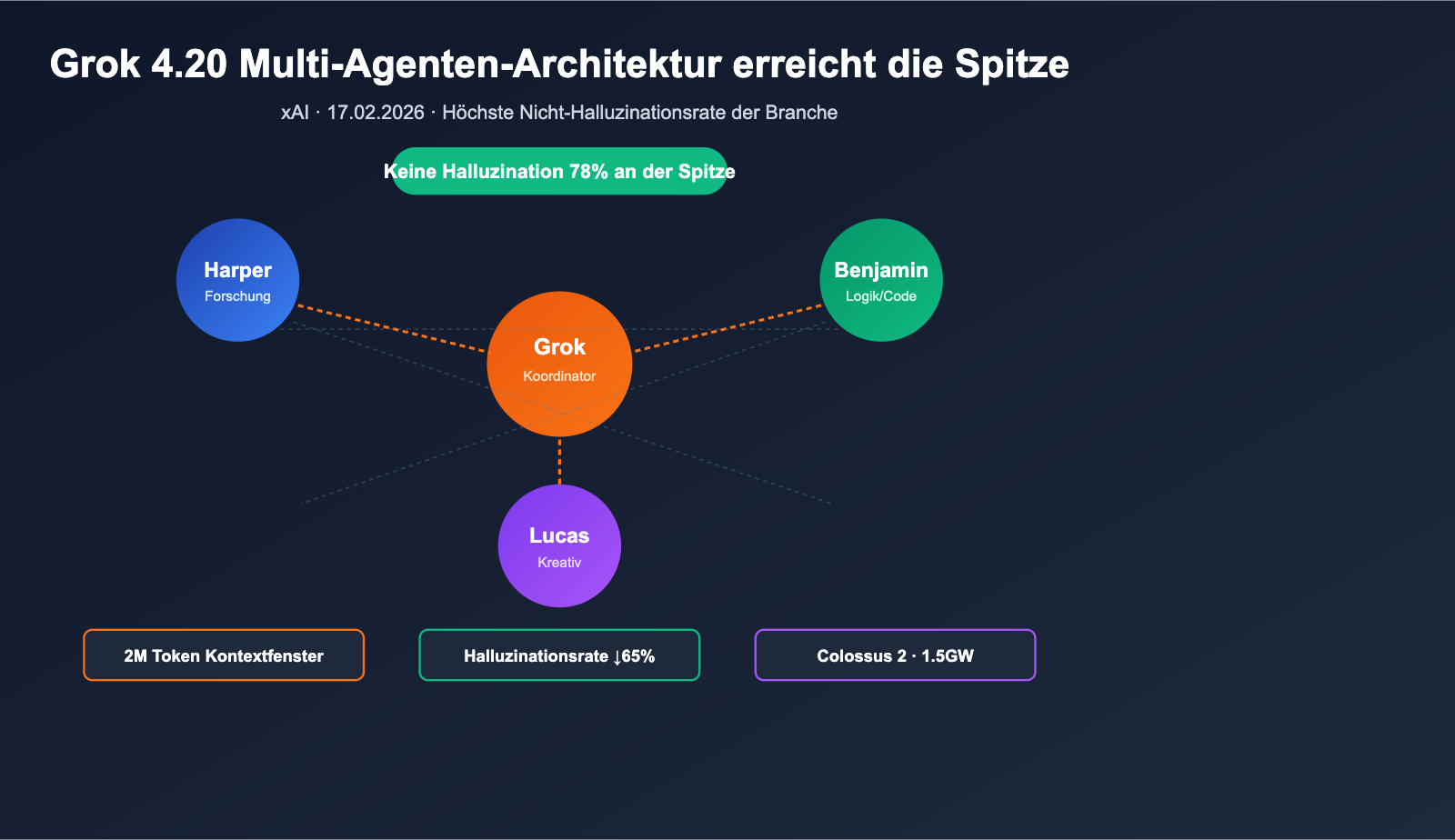
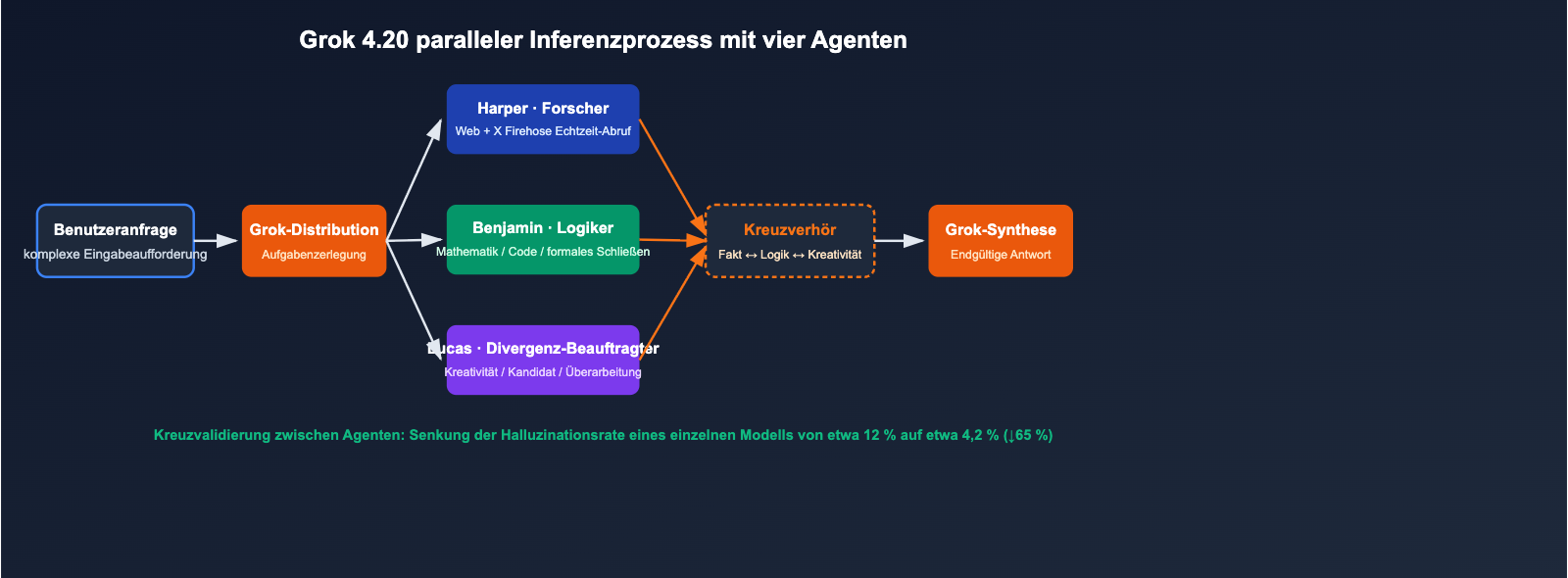
Der Kern der Multi-Agenten-Architektur von Grok 4.20
Im Gegensatz zum Mainstream-Ansatz „größeres Einzelmodell + tiefere Inferenzkette“ setzt Grok 4.20 auf eine Strategie der Schwarm-Intelligenz (Swarm-style Reasoning).
Die Aufgabenverteilung der 4 Agenten
| Rolle | Name | Aufgabe | Kernkompetenz |
|---|---|---|---|
| Koordinator | Grok | Aufgabenzerlegung, Debatten-Schlichtung, Synthese | Orchestrierung / Schlichtung |
| Rechercheur | Harper | Echtzeit-Websuche + X-Datenabruf | Faktenabgleich, Aktualitätsprüfung |
| Logiker | Benjamin | Mathematik, Code, strukturierte Schlussfolgerung | Code-Verifizierung, formale Logik |
| Divergenz-Agent | Lucas | Kreativ-Output, Lösungsentwicklung, Formulierung | Varianten-Generierung, Optimierung |
Sobald eine komplexe Anfrage eingeht, ruft Harper Echtzeit-Kontext ab, während Benjamin simultan Logik- und Code-Analysen durchführt und Lucas verschiedene Antwortmöglichkeiten generiert. Abschließend koordiniert Grok die Debatte und führt die Ergebnisse zu einer finalen Antwort zusammen. Dieser Prozess ersetzt die „einmalige Vorwärts-Inferenz“ durch eine mehrstufige interne Beratung zwischen den vier spezialisierten Rollen.
Warum Halluzinationen reduziert werden
Herkömmliche LLMs halluzinieren oft, weil ihnen die Selbstprüfung bei unbekannten Inhalten fehlt. Grok 4.20 nutzt agentenübergreifende Kreuzvalidierung als natürlichen Fakten-Check:
- Harper erkennt, wenn Benjamins Schlussfolgerung den neuesten Web- oder X-Daten widerspricht → Korrektur;
- Benjamin erkennt, wenn die mathematische Logik von Lucas’ kreativem Ansatz fehlerhaft ist → Veto;
- Grok gibt als Koordinator nur Antworten aus, die von allen Parteien widerspruchsfrei bestätigt wurden.
Offiziellen Angaben zufolge senkt dieser Mechanismus die Halluzinationsrate des Basismodells von etwa 12 % auf ca. 4,2 %, was einer Reduktion um 65 % entspricht.
🎯 Hinweis zur Architektur: Das Multi-Agenten-System ist keine „Kettenschaltung aus 4 Einzelmodellen“, sondern ein paralleler 4-Wege-Prozess mit Debatte während einer einzigen Vorwärts-Inferenz. Teams, die den Unterschied testen möchten, können Grok 4.20 über den API-Proxy-Dienst von APIYI (apiyi.com) direkt aufrufen, um dieselben Eingabeaufforderungen bei verschiedenen Modellen parallel laufen zu lassen und Halluzinationsraten zu vergleichen.
Grok 4.20: Wichtige Kennzahlen und Branchenvergleich
Die Aussagekraft von Benchmarks hängt stark vom verwendeten Testdatensatz ab. Im Folgenden sind die selbst gemeldeten Daten und unabhängige Testergebnisse getrennt aufgeführt.
Überblick über öffentliche Benchmarks
| Kennzahl | Grok 4.20 | Claude Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| Artificial Analysis Omniscience (Halluzinationsrate) | 78% (Spitzenreiter) | Zweitplatziert | Dritter |
| xAI-interne Halluzinationsrate (gesamt) | ca. 83% | — | — |
| Halluzinationsrate (relativ zu Grok 4.1 Basis) | 4,22% (↓65%) | — | — |
| LMArena Thinking Elo | 1483 | — | — |
| Kontextfenster | 2.000.000 Token | 200K (1M erweitert) | 400K-Klasse |
| Architektur | 4 Agenten parallel (Heavy-Modus 16) | Einzelmodell | Einzelmodell |
Heavy-Modus: Skalierung von 4 auf 16 Agenten
Neben der Standardkonfiguration mit 4 Agenten bietet Grok 4.20 den Heavy-Modus: Wenn eine tiefere Schlussfolgerung erforderlich ist, wird die Anzahl der Agenten von 4 auf 16 erhöht. Dies deckt einen breiteren Diskussionsraum ab und ermöglicht eine höherdimensionale Kreuzvalidierung von Beweisketten. Der Preis dafür sind höhere Kosten pro Anfrage und eine längere Latenz. Dies eignet sich für Szenarien, in denen "Genauigkeit entscheidend und Kosten zweitrangig" sind (Investment Research, Compliance-Audits, Sicherheitsanalysen usw.).
Modus- und Szenario-Übersicht
| Modus | Anzahl Agenten | Anwendungsbereich | Merkmale |
|---|---|---|---|
| Grok 4.20 Nicht-Schlussfolgerungs-Modus | 1 | Chat, Q&A | Niedrige Latenz, kostengünstig |
| Grok 4.20 Schlussfolgerungs-Modus | 1 + CoT | Mathematik, Code | Mittlere Kosten |
| Grok 4.20 Multi-Agent (Standard) | 4 | Komplexe Anfragen, Faktenprüfung | Deutlich reduzierte Halluzinationen |
| Grok 4.20 Heavy | 16 | Professionelle Forschung, Compliance | Höchste Genauigkeit |
🎯 Empfehlung zur Benchmark-Interpretation: Zwischen Selbsttests und unabhängigen Tests eines Modells kann es Abweichungen von 5 bis 10 Prozentpunkten geben. Bevorzugen Sie bei der Modellauswahl unabhängige Benchmarks wie Artificial Analysis. Durch den Vergleich von Grok 4.20 / Opus 4.6 / GPT-5.4 mit denselben Eingabeaufforderungen über APIYI (apiyi.com) erhalten Sie ein realistischeres Bild der Leistung in Ihrem geschäftlichen Kontext.
2M-Kontext von Grok 4.20 und die Colossus 2-Rechenbasis
Architektonische Innovationen erfordern Hardware-Unterstützung. Die zwei grundlegenden Upgrades von Grok 4.20 sind ebenfalls bemerkenswert.
Der Wert des 2M-Token-Kontexts
Grok 4.20 erweitert das Kontextfenster auf 2.000.000 Token, was bedeutet:
- Dokumente im Umfang ganzer Bücher können direkt in die Eingabeaufforderung eingefügt werden, ohne manuelle Aufteilung;
- Lange Dialoge / Agenten-Sitzungen behalten ihre vollständige Historie;
- Code-Reviews über mehrere Dateien können mittelgroße Monorepos abdecken;
- In Kombination mit Harpers Echtzeit-Abruffähigkeiten entsteht ein Vorteil durch die Kombination aus "langem Gedächtnis + Echtzeit-Fakten".
Colossus 2 Supercomputer-Cluster auf 1,5 GW aufgerüstet
Der von xAI für die Grok-Serie entwickelte Colossus 2 Supercomputer-Cluster wird auf eine Rechenleistung von 1,5 GW aufgerüstet. Dieses Infrastrukturziel ist auf Grok 5 und noch größere Multi-Agenten-Systeme ausgerichtet. Die direkten Auswirkungen für Entwickler:
- Höhere Verfügbarkeit bei Schlussfolgerungen und höhere Parallelitätsgrenzen;
- Schnellere Iterationsgeschwindigkeit für neue Modellversionen;
- Grok 4.20 kann bereits den Heavy-Modus mit "16 Agenten × 2M Kontext" bewältigen, wobei die Rechenbasis direkt aus diesem Cluster stammt.

Schnellstart: Grok 4.20 API-Aufruf und Integration über APIYI
Grundlegendes Aufrufbeispiel (OpenAI-kompatibel)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="YOUR_API_KEY",
)
# Standard-Modus mit 4 Multi-Agenten
resp = client.chat.completions.create(
model="grok-4-20",
messages=[
{"role": "system", "content": "Du bist ein sachlicher Forschungsassistent."},
{"role": "user", "content": "Fasse die Daten zu den weltweiten KI-Chip-Auslieferungen im Q1 2026 zusammen und nenne die wichtigsten Quellen."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
Aufruf des Heavy-Modus (16 Agenten)
# Der Heavy-Modus eignet sich für Szenarien mit hoher Genauigkeit, hat jedoch höhere Latenz und Kosten
resp = client.chat.completions.create(
model="grok-4-20-heavy",
messages=[
{"role": "user", "content": "Erstelle eine Zusammenfassung der Risikopunkte und eine Querverweisprüfung für dieses 800-seitige Compliance-Dokument."},
],
max_tokens=16384,
)
📎 Ausklappen für ein Beispiel mit 2M Kontextfenster
# Das 2M-Kontextfenster kann ein ganzes Buch oder ein komplettes Repository auf einmal verarbeiten
with open("large_repo_dump.txt", "r") as f:
repo_text = f.read() # Kann Millionen von Token umfassen
resp = client.chat.completions.create(
model="grok-4-20",
messages=[
{"role": "system", "content": "Du bist ein erfahrener Code-Reviewer."},
{"role": "user", "content": f"Hier ist der gesamte Repository-Code. Bitte identifiziere die 5 kritischsten Probleme:\n\n{repo_text}"},
],
max_tokens=8192,
)
Vorteile der Integration über die APIYI-Plattform
Die API für Grok 4.20 ist jetzt offiziell auf APIYI apiyi.com verfügbar. Die Preise entsprechen denen der offiziellen Website, bieten jedoch folgende zusätzliche Vorteile:
- Auflade-Aktionen mit bis zu 15 % Rabatt, wodurch die langfristigen Nutzungskosten unter denen einer Direktverbindung liegen;
- Unbegrenzte Parallelität, ideal für die Stapelverarbeitung im Heavy-Modus;
- OpenAI-kompatible Schnittstelle, keine Anpassung des bestehenden Codes erforderlich – einfach
base_urlundmodelaustauschen; - Abrechnung über dasselbe Konto wie bei Claude, GPT und anderen Modellen, was A/B-Tests mit verschiedenen Modellen erleichtert.
🎯 Integrations-Tipp: Da der Token-Verbrauch im Heavy-Modus pro Aufruf um ein Vielfaches höher ist, kommt der Vorteil der unbegrenzten Parallelität hier besonders zum Tragen. Wir empfehlen neuen Teams, die grundlegende Logik zunächst im Nicht-Inferenz-Modus auf APIYI apiyi.com zu testen und erst danach kritische Workflows auf den Multi-Agenten- oder Heavy-Modus umzustellen.
Typische Anwendungsfälle für Grok 4.20
Die 5 besten Workloads für Grok 4.20
| Szenario | Empfohlener Modus | Hauptvorteil |
|---|---|---|
| Faktencheck für Nachrichten/Berichte | Multi-Agent (Standard) | Harper Echtzeit-Suche + agentenübergreifende Validierung |
| Investment-Research & Compliance | Heavy | 16 Agenten reduzieren Fehler bei kritischen Fakten |
| Analyse ganzer Bücher / Repositories | Multi-Agent + 2M | Einmalige Verarbeitung ohne Aufteilung |
| Mehrstufige Agenten-Workflows | Multi-Agent | Integrierter Koordinator reduziert Engineering-Aufwand |
| Echtzeit-Stimmungsanalyse / Social Media | Multi-Agent | Native Anbindung von Harper an den X Firehose |
Nicht empfohlene Szenarien
- Millisekunden-IDE-Vervollständigung: Die Latenz durch parallele Multi-Agenten ist nicht für Tab-basierte Interaktionen geeignet;
- Extrem kostengünstige Stapelverarbeitung: Der Heavy-Modus ist zu teuer; hier sind Nicht-Inferenz-Modi oder Modelle der Haiku-Klasse wirtschaftlicher;
- Strenge Anforderungen an lokale Bereitstellung: Grok 4.20 ist derzeit nur als API verfügbar, es gibt keine selbst gehosteten Gewichte.
🎯 Empfehlung zur Migration: Verlagern Sie Workflows mit hoher "Halluzinations-Sensibilität" (Compliance, Medizin, Finanzanalyse) bevorzugt auf den Grok 4.20 Multi-Agenten-Modus. Nutzen Sie das Abrechnungs-Dashboard von APIYI apiyi.com, um die Kosten pro Workflow zu analysieren und den geschäftlichen Mehrwert durch reduzierte Halluzinationen zu quantifizieren.
Häufig gestellte Fragen (FAQ)
F1: Welche Nicht-Halluzinationsrate ist glaubwürdiger: 78 % oder 83 %?
78 % stammen aus dem unabhängigen Testdatensatz von Artificial Analysis Omniscience und gelten derzeit als die verlässlichsten Daten; 83 % sind das Ergebnis von xAI-internen Tests auf einem breiteren Datensatz. Wir empfehlen, sich bei der Modellauswahl primär an unabhängigen Benchmarks und sekundär an offiziellen Daten zu orientieren. Beide Quellen stimmen jedoch darin überein: Grok 4.20 übertrifft bei der Halluzinationsfreiheit mittlerweile Claude Opus 4.6 und GPT-5.4.
F2: Bedeuten 4 Agenten, dass ich 4-mal den API-Aufruf tätigen muss?
Nein. Die Orchestrierung der Multi-Agenten erfolgt serverseitig bei xAI, für den Nutzer bleibt es bei einem einzigen Modellaufruf. Die Token-Abrechnung fällt höher aus als im Einzelagenten-Modus, ist jedoch deutlich günstiger als eine Lösung, bei der man selbst 4 Anfragen clientseitig verkettet, und bietet zudem eine geringere Latenz.
F3: Was ist der Unterschied zwischen dem Heavy-Modus und dem normalen Multi-Agenten-Modus?
Der Heavy-Modus erhöht die Anzahl der parallelen Agenten von 4 auf 16. Dies steigert die Genauigkeit bei komplexen Schlussfolgerungen und langen Beweisketten weiter, führt jedoch zu deutlich höheren Kosten und Latenzen pro Anfrage. Wir empfehlen diesen Modus nur für Szenarien, in denen jeder Fehler hohe Kosten verursacht, wie etwa in den Bereichen Compliance, Medizin oder Investment-Research. Über APIYI (apiyi.com) können Sie Anfragen gezielt an verschiedene Modi routen und so "Rechenleistung nach Wert" einsetzen.
F4: Kann das 2M-Kontextfenster wirklich voll ausgenutzt werden?
Ja. Grok 4.20 gibt den tatsächlich nutzbaren Kontext an, nicht nur das theoretische Limit. Beachten Sie jedoch: Mit zunehmender Kontextlänge steigen die Kosten pro Token und die Latenz linear an. Bei extrem großen Kontexten empfehlen wir die Kombination aus Kontextkomprimierung + Harper-Retrieval der Multi-Agenten.
F5: Was ist der Unterschied zwischen der Nutzung über APIYI und der offiziellen Website?
Die Preise sind identisch mit der offiziellen Website, durch Auflade-Aktionen sind jedoch bis zu 15 % Rabatt möglich. Der entscheidende Vorteil ist die unbegrenzte Parallelität, was besonders für Batch-Aufrufe im Heavy-Modus ideal ist. Die Schnittstelle bleibt OpenAI-kompatibel; auf Code-Ebene muss lediglich die base_url auf apiyi.com angepasst werden.
F6: Wird Grok 4.20 Grok 5 ersetzen?
Nein. Grok 5 bleibt das Flaggschiff der nächsten Generation von xAI, unterstützt durch das Colossus 2 1.5GW-Cluster. Die Positionierung von Grok 4.20 ist eher als "Validierung des Multi-Agenten-Paradigmas auf der 4er-Architektur" zu verstehen, um die technische Basis für die skalierten Multi-Agenten von Grok 5 zu schaffen.
Fazit: Das Multi-Agenten-Paradigma verändert die Landschaft der Flaggschiff-Modelle
Grok 4.20 ist nicht nur ein Versions-Update, sondern markiert einen Wandel im Wettbewerb der Flaggschiff-Modelle: Der Fokus verschiebt sich von "größeren Modellen mit tieferen Schlussfolgerungsketten" hin zu "Multi-Agenten-Gruppen-Inferenz mit Echtzeit-Beweisprüfung". Die Kombination aus einer unabhängigen Nicht-Halluzinationsrate von 78 % und einem 2M-Kontextfenster bedeutet, dass risikobehaftete Geschäftsbereiche (Compliance, Investment-Research, Medizin, Recht) erstmals eine "halluzinationsarme Vorzugslösung" über eine allgemeine API erhalten.
Für Entwickler besteht der erste Schritt nicht darin, alle Modelle zu ersetzen, sondern die fehleranfälligsten Prozesse bevorzugt auf den Grok 4.20 Multi-Agenten-Modus umzustellen und Standardprozesse bei kostengünstigeren Modellen zu belassen – eine hybride Orchestrierung. Der Branchentrend zeigt, dass Grok 5 und das 1.5GW-Cluster von Colossus 2 diesen Vorteil weiter ausbauen werden. Eine frühzeitige Integration bedeutet einen Wissensvorsprung bei der Multi-Agenten-Steuerung.
🎯 Handlungsempfehlung: Die Grok 4.20 API ist jetzt offiziell bei APIYI (apiyi.com) verfügbar. Die Preise entsprechen der offiziellen Website, es gibt 15 % Rabatt bei Aufladungen und – entscheidend – keine Begrenzung der Parallelität. Dies ist ideal für Multi-Agenten-Setups, den Heavy-Modus und Anwendungen mit hohem Durchsatz bei 2M-Kontext. Mit einem OpenAI-kompatiblen Code-Snippet können Sie sofort starten und Ihre "halluzinationskritischen" Workflows migrieren.
— APIYI Team (Technisches Team von APIYI apiyi.com)