Anmerkung des Autors: Das Flaggschiff-Modell Grok 4.20 Beta von xAI wird kontinuierlich weiterentwickelt. Mit einer Halluzinationsrate von nur 78 % (branchenweit niedrigster Wert), nativer 4-Agenten-Kollaboration, einem Kontextfenster von 2 Millionen Token sowie Unterstützung für Sprachdialoge und Bild-/Videogenerierung analysiert dieser Artikel die Kernfähigkeiten und den praktischen Nutzen.
Das von Elon Musk geleitete Unternehmen xAI hat Anfang 2026 Grok 4.20 Beta veröffentlicht und seitdem kontinuierlich optimiert. Das Alleinstellungsmerkmal dieses Modells ist die "niedrigste Halluzinationsrate der Branche" – in den Artificial Analysis Omniscience-Tests erreichte es eine Nicht-Halluzinationsrate von 78 %. Gleichzeitig führt es eine native 4-Agenten-Architektur und ein Kontextfenster von 2 Millionen Token ein. Das April-Update verbesserte zudem die Befolgung von Anweisungen, den LaTeX-Satz und die Genauigkeit bei der Bildsuche.
Kernnutzen: Erfahren Sie in 5 Minuten alles über die Kernfähigkeiten von Grok 4.20 Beta, die Unterschiede zwischen den 3 Modellvarianten, die multimodalen Fähigkeiten sowie die Positionierung im Vergleich zu Claude und GPT.

Grok 4.20 Beta – Wichtige Informationen auf einen Blick
| Informationspunkt | Details |
|---|---|
| Veröffentlichungsdatum | 17. Feb. 2026 (Public Beta) / 10. März (API) |
| Entwickler | xAI (Elon Musk) |
| Kernpositionierung | Hohe Integrität + Multi-Agent + Multimodales Flaggschiff |
| Halluzinationsrate | 78 % Nicht-Halluzination (branchenweit führend) |
| Kontextfenster | 2 Millionen Token (Upgrade von 256K bei Grok 4) |
| Modellvarianten | Reasoning / Non-Reasoning / Multi-Agent |
| Ausgabegeschwindigkeit | 247,8 Tok/s (Median bei Reasoning-Modellen: 68,5) |
| Preisgestaltung | $2/MTok Input, $6/MTok Output |
| Multimodalität | Text/Bild/Video/Sprache Input & Output |
Marktpositionierung von Grok 4.20 Beta
In der Wettbewerbslandschaft der großen Sprachmodelle hat Grok 4.20 Beta einen differenzierten Weg eingeschlagen: Anstatt bei allen Benchmarks die höchsten Punktzahlen anzustreben, baut es seine einzigartigen Vorteile in den drei Dimensionen Integrität (geringe Halluzinationen), Geschwindigkeit und Multi-Agenten-Kollaboration aus.
Der Intelligenz-Index von Artificial Analysis liegt bei 48 Punkten – das ist deutlich höher als der Median von 31 Punkten bei Modellen in der gleichen Preisklasse, bleibt jedoch hinter den Spitzenwerten von Claude Opus 4.5 und GPT-5.4 zurück. Die Strategie von xAI lautet: Anstatt ein Modell zu liefern, das gelegentlich verblüfft, aber häufig Fehler macht, bieten wir ein Modell, auf das man sich stets verlassen kann.
Detaillierte Analyse der Kernfunktionen von Grok 4.20 Beta
Funktion 1: Niedrigste Halluzinationsrate der Branche
Die herausragendste Eigenschaft von Grok 4.20 Beta ist die Kontrolle von Halluzinationen:
| Bewertung | Grok 4.20 | Branchendurchschnitt | Anmerkung |
|---|---|---|---|
| AA-Omniscience Nicht-Halluzinationsrate | 78% | ~60-70% | Branchenspitze |
| Befolgen von Anweisungen | Top-Niveau | – | Strenge Einhaltung der Eingabeaufforderung |
| LaTeX-Satz | Kontinuierliche Optimierung | – | Verbesserungen durch April-Update |
Eine Nicht-Halluzinationsrate von 78 % bedeutet, dass Grok 4.20 bei faktischen Fragen etwa 4 von 5 Antworten korrekt wiedergibt – das ist der höchste Wert unter allen getesteten Modellen. Für Szenarien, die ein hohes Maß an Zuverlässigkeit erfordern (wie medizinische Beratung, Rechtsanalysen oder wissenschaftliche Forschung), ist eine niedrige Halluzinationsrate oft wertvoller als ein höherer "Intelligenzquotient".
Kontinuierliche Optimierung im April: Die neueste Iteration verbessert die Fähigkeit zur Befolgung von Anweisungen sowie den LaTeX-Satz für mathematische Formeln weiter. Auch die Genauigkeit bei der Auslösung der Bildsuche wurde gesteigert.
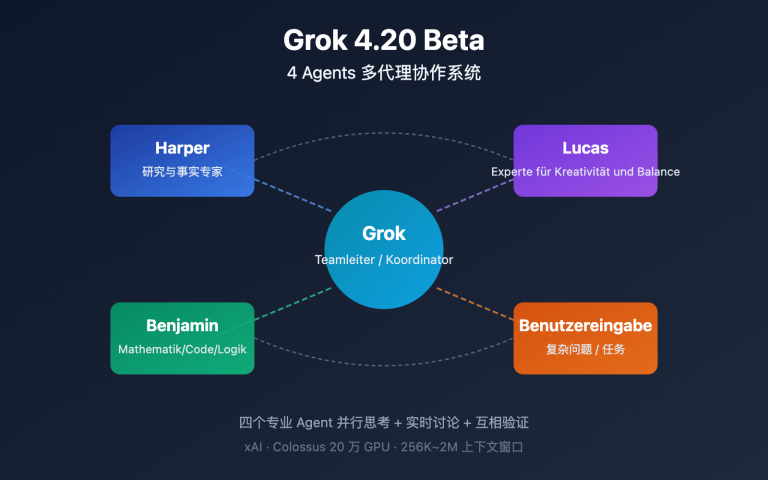
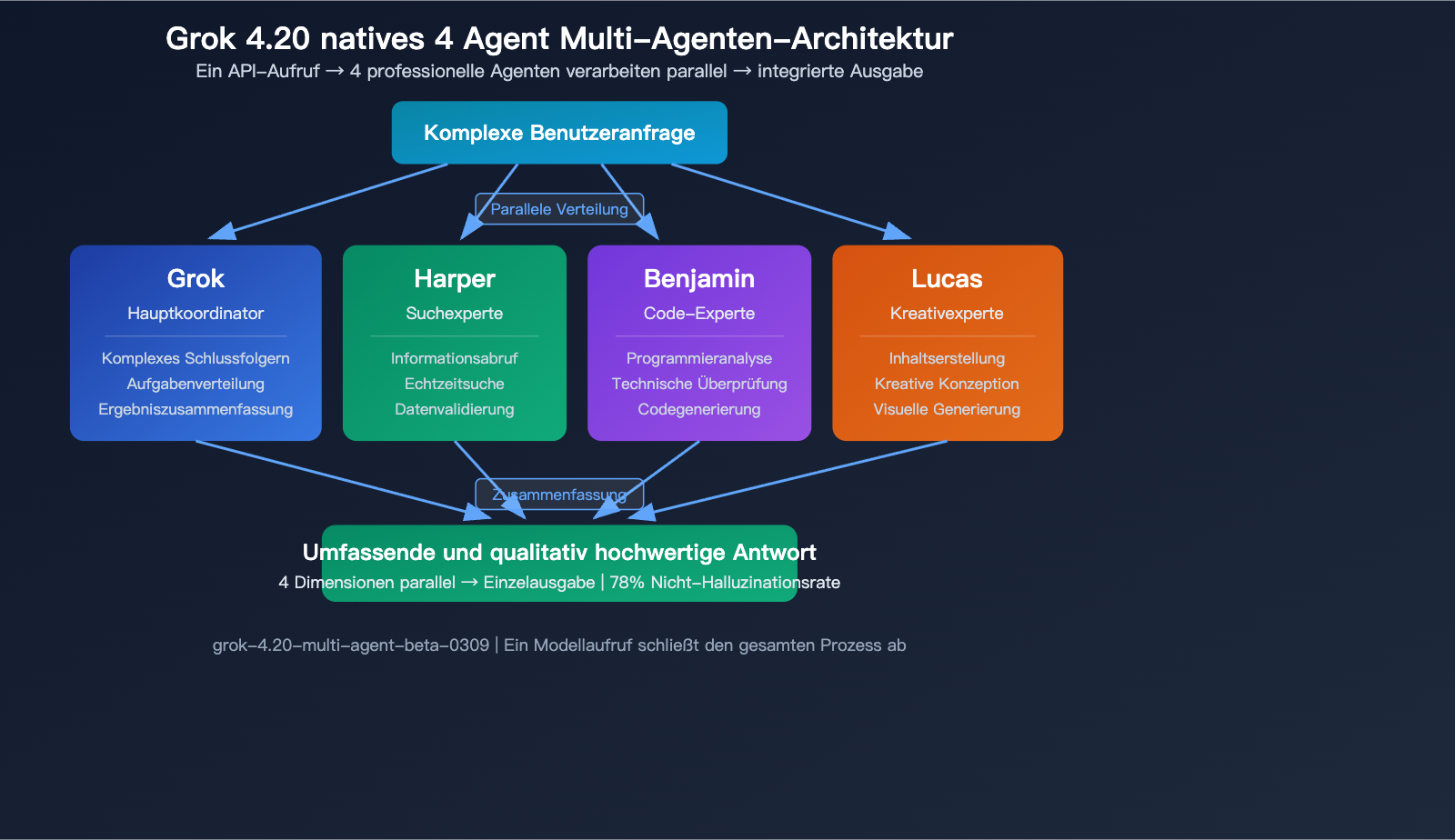
Funktion 2: Native 4-Agent-Multi-Agenten-Architektur
Grok 4.20 Beta führt die branchenweit erste native Multi-Agenten-API ein – ein einziger API-Aufruf, bei dem im Hintergrund 4 spezialisierte Agenten parallel arbeiten:
| Agent-Name | Fachgebiet | Rolle |
|---|---|---|
| Grok | Umfassende Schlussfolgerung und Dialog | Hauptkoordinator |
| Harper | Forschung und Informationsbeschaffung | Such-Experte |
| Benjamin | Programmierung und technische Analyse | Code-Experte |
| Lucas | Kreativität und Inhaltserstellung | Kreativ-Experte |
Wenn Sie eine komplexe Anfrage über die Multi-Agenten-API senden, arbeiten die 4 Agenten gleichzeitig parallel und bringen ihre jeweiligen Stärken ein, bevor Grok die Ergebnisse zusammenführt. Diese Architektur ist bei komplexen Aufgaben, die multidimensionale Fähigkeiten erfordern, deutlich effizienter.
Funktion 3: 2 Millionen Token Kontextfenster
Das Kontextfenster von Grok 4.20 wurde gegenüber dem Vorgänger Grok 4 von 256K auf 2 Millionen Token erweitert – das derzeit längste Fenster unter allen gängigen API-Modellen:
| Modell | Kontextfenster | Vergleich |
|---|---|---|
| Grok 4.20 Beta | 2 Millionen Token | Längstes der Branche |
| GPT-5.4 (erweitert) | 1 Million Token | 2x Grok |
| Claude Opus 4.5 | 200K Token | 10x Grok |
| Gemini 2.5 Pro | 1 Million Token | 2x Grok |
2 Millionen Token entsprechen etwa 1,5 Millionen chinesischen Schriftzeichen oder 3 Millionen englischen Wörtern – genug Platz für einen kompletten Roman oder ein umfangreiches Code-Repository.
🎯 Empfehlung für Entwickler: Grok 4.20 Beta bietet einzigartige Vorteile bei der Halluzinationskontrolle und der Kontextlänge. Über APIYI (apiyi.com) können Sie sowohl Grok 4.20 als auch Claude und GPT einbinden, um die Zuverlässigkeit und Genauigkeit verschiedener Modelle bei Ihren spezifischen Aufgaben direkt zu vergleichen.
Grok 4.20 Beta: 3 Modellvarianten
Die Grok 4.20 Modellfamilie
xAI hat drei verschiedene Grok 4.20-Varianten veröffentlicht, die bei identischer Preisgestaltung unterschiedliche Schwerpunkte setzen:
| Variante | Modell-ID | Kernkompetenz | Anwendungsfall |
|---|---|---|---|
| Non-Reasoning | grok-4.20-beta-0309-non-reasoning | Schnelle, direkte Antworten | Alltagsgespräche, einfache Aufgaben |
| Reasoning | grok-4.20-beta-0309-reasoning | Tiefe Schlussfolgerungsketten | Komplexe Analysen, Mathematik |
| Multi-Agent | grok-4.20-multi-agent-beta-0309 | 4 Agenten parallel | Komplexe, mehrdimensionale Aufgaben |
Preis-Analyse von Grok 4.20
| Preisposten | Grok 4.20 | Grok 4 (Vorgänger) | Änderung |
|---|---|---|---|
| Input | $2/MTok | $3/MTok | -33% |
| Output | $6/MTok | $15/MTok | -60% |
| Drei Varianten | Gleicher Preis | – | Wahl nach Bedarf |
Die Preisgestaltung von Grok 4.20 ist äußerst wettbewerbsfähig: Mit $2 für Input und $6 für Output liegt das Modell 33-60 % unter dem Vorgänger Grok 4. Im Vergleich zur Konkurrenz: GPT-5.4 Standard kostet $2,5/$15, und Claude Opus 4.5 ist noch teurer. Unter den Modellen in dieser Preisklasse bietet Grok 4.20 die niedrigste Halluzinationsrate und die höchste Geschwindigkeit (247,8 Tok/s).
Grok 4.20 Rapid Learning Architektur
Eine einzigartige Technologie von Grok 4.20 ist die Rapid Learning-Architektur: Das Modell aktualisiert seine Fähigkeiten wöchentlich automatisch auf Basis echter Nutzerdaten, ohne dass manuelle neue Versionen veröffentlicht werden müssen. Das bedeutet, dass Ihr Grok 4.20 mit der Zeit kontinuierlich besser wird – die April-Version von Grok 4.20 ist bereits leistungsfähiger als die Februar-Version.
💡 Differenzierungsmerkmal: Rapid Learning ist exklusiv bei Grok – bei anderen Modellen erfordern Updates eine neue Versionsnummer, während Grok 4.20 innerhalb derselben Version stetig weiterentwickelt wird. Deshalb ist die "kontinuierliche Iteration im April" für Grok-Nutzer besonders wichtig.
Grok 4.20 Beta: Multimodale Fähigkeiten
Die vollständige multimodale Matrix von Grok 4.20
| Modalität | Input | Output | Anmerkung |
|---|---|---|---|
| Text | ✓ | ✓ | Kernkompetenz |
| Bild | ✓ | ✓ | Grok Imagine API |
| Video | ✓ | ✓ | End-to-End Videogenerierung |
| Sprache | ✓ | ✓ | Grok Voice mit geringer Latenz |
| Code | ✓ | ✓ | Spezialität des Benjamin-Agenten |
| Suche | – | ✓ | Echtzeit-Websuche |
Grok Voice: Sprachfähigkeiten
Grok Voice ist eine der am stärksten differenzierten multimodalen Funktionen in Grok 4.20:
- Sprache mit geringer Latenz: Unterstützt Echtzeit-Sprachdialoge in Dutzenden Sprachen
- Tool-Aufrufe: Im Sprachmodus können Werkzeuge und Suchen ausgelöst werden
- Echtzeitdaten: Zugriff auf Live-Webdaten während des Sprachdialogs
- Agent-API: Über API in Drittanbieter-Anwendungen integrierbar
Damit ist Grok 4.20 nicht nur ein Textmodell, sondern ein vollwertiger KI-Assistent, der "hören, sprechen, sehen und suchen" kann.
Grok Imagine: Bild- und Videogenerierung
xAI hat mit Grok 4.20 die Grok Imagine API eingeführt – eine einheitliche Suite für die End-to-End Video- und Audiogenerierung. Sie unterstützt die Erstellung von Bildern und Videos aus Textbeschreibungen, wobei die Genauigkeit bei der Bildsuche mit dem April-Update weiter verbessert wurde.

Vergleich: Grok 4.20 Beta und Wettbewerber
Grok 4.20 vs. GPT-5.4 vs. Claude Opus 4.5
| Vergleichsdimension | Grok 4.20 Beta | GPT-5.4 | Claude Opus 4.5 |
|---|---|---|---|
| Halluzinationsrate | 78% (niedrigste) | ~65% | ~70% |
| Intelligenzindex | 48 | ~55+ | ~55+ |
| Kontextfenster | 2 Mio. Token | 272K-1M | 200K |
| Ausgabegeschwindigkeit | 247,8 tok/s | ~100 tok/s | ~80 tok/s |
| Eingabepreis | $2/MTok | $2,5/MTok | Höher |
| Ausgabepreis | $6/MTok | $15/MTok | Höher |
| Multi-Agent | Nativ 4 Agenten | Nein | Nein |
| Sprachdialog | Nativ unterstützt | Begrenzt | Nein |
| Computersteuerung | Nein | Nativ unterstützt | Begrenzt |
| Programmierung | Überdurchschnittlich | Top | Top |
Stärken von Grok 4.20: Halluzinationskontrolle, Geschwindigkeit, Preisgestaltung, Kontextlänge, Multi-Agent-Fähigkeit, Sprachunterstützung.
Schwächen von Grok 4.20: Reine Intelligenz-/Schlussfolgerungs-Benchmarks, spezialisierte Programmier-Benchmarks.
Auswahlempfehlung: Wenn Genauigkeit und Zuverlässigkeit der Antworten für Sie oberste Priorität haben, ist Grok 4.20 die erste Wahl. Wenn Sie Wert auf Programmierfähigkeiten und komplexe Schlussfolgerungen legen, sind Claude oder GPT stärker.
🚀 Vergleichs-Tipp: Über APIYI (apiyi.com) können Sie Grok 4.20, GPT-5.4 und Claude gleichzeitig einbinden. Mit einem einzigen API-Schlüssel wechseln Sie flexibel zwischen den drei Modellen und finden schnell das für Ihr Szenario am besten geeignete.
API-Anbindung für Grok 4.20 Beta
Schnelle Anbindung über APIYI
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Non-Reasoning-Modus (schnelle Antwort)
response = client.chat.completions.create(
model="grok-4.20-beta-0309-non-reasoning",
messages=[{"role": "user", "content": "Erkläre die Grundprinzipien der Quantenberechnung"}]
)
print(response.choices[0].message.content)
Aufruf für Reasoning- und Multi-Agent-Modus anzeigen
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Reasoning-Modus (tiefe Schlussfolgerung)
response = client.chat.completions.create(
model="grok-4.20-beta-0309-reasoning",
messages=[{"role": "user", "content": "Analysiere die Risikopunkte der globalen Lieferkette für KI-Chips"}]
)
# Multi-Agent-Modus (4 Agenten parallel)
response = client.chat.completions.create(
model="grok-4.20-multi-agent-beta-0309",
messages=[{
"role": "user",
"content": "Schreibe einen Forschungsbericht über die Kommerzialisierungsaussichten der Quantenberechnung"
}]
)
# 4 Agenten (Grok/Harper/Benjamin/Lucas) arbeiten parallel
print(response.choices[0].message.content)
💰 Kostenvorteil: Die Preisgestaltung von $2/$6 für Grok 4.20 gehört zu den niedrigsten unter den aktuellen Flaggschiff-Modellen. Durch die Nutzung von APIYI (apiyi.com) können Sie Ihre Kosten weiter optimieren und bei Bedarf nahtlos zwischen Grok, Claude, GPT und Gemini wechseln.
Häufig gestellte Fragen
Q1: Welche der drei Varianten von Grok 4.20 sollte ich wählen?
Für tägliche Konversationen wählen Sie „Non-Reasoning“ (am schnellsten), für komplexe Analysen „Reasoning“ (tiefergehend) und für multidimensionale, komplexe Aufgaben „Multi-Agent“ (4 Agenten parallel). Alle drei Varianten haben die gleiche Preisgestaltung ($2/$6 MTok) und können je nach Aufgabe flexibel gewechselt werden. Über APIYI apiyi.com können Sie alle Varianten mit einem einzigen Schlüssel aufrufen.
Q2: Was bedeutet die niedrigste Halluzinationsrate bei Grok 4.20?
Eine Nicht-Halluzinationsrate von 78 % bedeutet, dass Grok bei faktischen Antworten weniger dazu neigt, Informationen zu „erfinden“ als andere Modelle. Für Szenarien, die eine hohe Zuverlässigkeit erfordern (Medizin, Recht, Wissenschaft, Unternehmensentscheidungen), ist dies wertvoller als ein höherer „Intelligenz-Index“. Bei kreativem Schreiben und Brainstorming kann eine moderate „Halluzination“ jedoch sogar ein Vorteil sein.
Q3: Wird Grok 4.20 weiter aktualisiert?
Ja. Grok 4.20 nutzt eine „Rapid Learning“-Architektur, die auf Basis von Nutzerdaten wöchentlich automatisch optimiert wird. Die Updates im April haben bereits die Befolgung von Anweisungen, den LaTeX-Satz und die Bildsuche verbessert. Die Fähigkeiten unter derselben Modell-ID werden kontinuierlich gesteigert, ohne dass auf eine neue Versionsnummer gewartet werden muss. Wenn Sie den Dienst über APIYI apiyi.com nutzen, profitieren Sie automatisch von den neuesten Optimierungen.
Zusammenfassung
Die Kernwerte von Grok 4.20 Beta im Überblick:
- Branchenweit niedrigste Halluzinationsrate: 78 % Nicht-Halluzinationsrate bietet einen einzigartigen Vorteil in Szenarien, die hohe Zuverlässigkeit erfordern.
- Native Multi-Agenten-Struktur: 4 Agenten (Grok/Harper/Benjamin/Lucas) arbeiten parallel zusammen, was die Effizienz bei komplexen Aufgaben steigert.
- 2 Millionen Token Kontextfenster: Das längste unter den gängigen API-Modellen, kombiniert mit einer Geschwindigkeitsvorteil von 247,8 Tok/s.
- Kontinuierliche Evolution: „Rapid Learning“ sorgt für wöchentliche automatische Updates; die April-Version ist bereits leistungsfähiger als die Erstveröffentlichung im Februar.
Grok 4.20 Beta verfolgt einen differenzierten Ansatz – anstatt in allen Bereichen das Maximum anzustreben, setzt es neue Maßstäbe in den Dimensionen Vertrauenswürdigkeit, Geschwindigkeit und Multi-Agenten-Kooperation. Wir empfehlen, über APIYI apiyi.com sowohl Grok 4.20 als auch Claude und GPT einzubinden, um mit einem einzigen Schlüssel verschiedene Modelle zu vergleichen und die für Ihr Szenario am besten geeignete Lösung zu finden.
📚 Referenzmaterialien
-
xAI offizielle Grok 4.20 Updates: Aktuelle Neuigkeiten und Funktionsankündigungen
- Link:
x.ai/news - Beschreibung: Enthält das kontinuierliche Iterationsprotokoll und Funktions-Updates für Grok 4.20
- Link:
-
Artificial Analysis – Grok 4.20 Bewertung: Unabhängige Analysen und Daten von Drittanbietern
- Link:
artificialanalysis.ai/models/grok-4-20 - Beschreibung: Umfasst detaillierte Analysen zu Intelligenz-Index, Halluzinationsrate, Geschwindigkeit und Preisgestaltung
- Link:
-
Grok 4.20 Multi-Agenten-Details: Vollständiger Vergleich der 4 Modellvarianten
- Link:
help.apiyi.com/en/grok-4-20-beta-4-models-multi-agent-reasoning-api-guide-en.html - Beschreibung: Enthält detaillierte Anwendungsszenarien für Reasoning, Non-Reasoning und Multi-Agent-Modelle
- Link:
-
Grok 4.20 Beta im Überblick: Tiefenanalyse von Architektur und Funktionen
- Link:
buildfastwithai.com/blogs/grok-4-20-beta-explained-2026 - Beschreibung: Umfasst eine detaillierte Erläuterung der Rapid-Learning-Architektur und der multimodalen Fähigkeiten
- Link:
Autor: APIYI Technik-Team
Technischer Austausch: Teilen Sie gerne Ihre Erfahrungen mit Grok 4.20 in den Kommentaren. Weitere Informationen zur Anbindung von KI-Modellen finden Sie im APIYI Dokumentationszentrum unter docs.apiyi.com.