Autorennotiz: Tiefgehender Vergleich der drei stärksten KI-Modelle für mathematische Problemlösung im Jahr 2026, einschließlich autoritativer Benchmark-Daten wie AIME und MATH, um Ihnen zu helfen, das beste Modell für mathematisches Denken zu finden.
Die Frage, welches KI-Modell für mathematische Problemlösung am besten geeignet ist, bleibt eine der wichtigsten Entscheidungen für Entwickler und Studierende. Dieser Artikel vergleicht die drei neuesten, 2026 veröffentlichten Modelle für mathematisches Denken – Gemini 3.1 Pro Preview, Claude Sonnet 4.6 und GPT-5.4 – und gibt klare Empfehlungen basierend auf Benchmark-Ergebnissen, Denkfähigkeiten, API-Preisen und Anwendungsszenarien.
Kernwert: Nach der Lektüre dieses Artikels wissen Sie genau, welches KI-Modell Sie in verschiedenen mathematischen Problemlösungsszenarien wählen sollten und wie Sie es mit optimalen Kosten nutzen können.

Schnellüberblick: Kernvergleich mathematischer KI-Lösungsmodelle
Bevor wir in die detaillierte Analyse einsteigen, hier eine Tabelle mit den wichtigsten Daten, um Ihnen einen schnellen Überblick über die wesentlichen Unterschiede der drei KI-Modelle für mathematische Problemlösung zu geben.
| Vergleichsdimension | Gemini 3.1 Pro Preview | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|---|
| Veröffentlichungsdatum | 19. Februar 2026 | Anfang 2026 | 6. März 2026 |
| AIME 2025 | 92% (ohne Tools) | — | 100% (volle Punktzahl) |
| MATH-Benchmark | 95.1% | 89% | 88.6% |
| GPQA Diamond | 94.3% | 74.1% | 84.2% |
| ARC-AGI-2 | 77.1% | 58.3% | 73.3% |
| Eingabepreis | 2,00 $/1 Mio. Tokens | 3,00 $/1 Mio. Tokens | 2,50 $/1 Mio. Tokens |
| Ausgabepreis | 12,00 $/1 Mio. Tokens | 15,00 $/1 Mio. Tokens | 15,00 $/1 Mio. Tokens |
| Gesamtempfehlung | ⭐ Erste Wahl | ⭐ Erste Wahl zum Lernen | ⭐ Erste Wahl für Wettbewerbe |
Empfohlene Reihenfolge für mathematische KI-Lösungsmodelle
Aus der Perspektive des Gesamtnutzenverhältnisses geben wir die folgende Reihenfolgeempfehlung:
- Erste Wahl: Gemini 3.1 Pro Preview: Führt mit 95,1% im MATH-Benchmark, niedrigster Preis, stärkste allgemeine mathematische Fähigkeiten.
- Zweite Wahl: Claude Sonnet 4.6: Mathematische Fähigkeiten um 27 Prozentpunkte gestiegen, klare und verständliche Lösungswege, ideal für Lernszenarien.
- Wettbewerbsniveau: GPT-5.4: Volle Punktzahl (100%) bei AIME 2025, geeignet für anspruchsvolle Mathematikwettbewerbe und professionelle Forschung.
🎯 Technischer Tipp: Alle drei Modelle können über die Plattform APIYI (apiyi.com) einheitlich aufgerufen werden. Es wird empfohlen, sie mit Ihren konkreten mathematischen Problemen zu testen, um das Modell zu finden, das am besten zu Ihren Anforderungen passt.
Detaillierte Analyse der mathematischen Problemlösungsfähigkeiten von Gemini 3.1 Pro Preview
Gemini 3.1 Pro Preview ist das neueste Flaggschiffmodell von Google DeepMind, veröffentlicht am 19. Februar 2026. Dies ist die erste Verwendung einer ".1"-Versionsinkrementierung durch Google (bisher wurden für Zwischenupdates immer ".5" verwendet), was auf ein gezieltes Upgrade mit Fokus auf intelligente Schlussfolgerungsfähigkeiten hinweist.
Benchmark-Ergebnisse von Gemini 3.1 Pro in Mathematik
| Benchmark-Test | Punktzahl | Erläuterung |
|---|---|---|
| MATH | 95.1% | Umfassender mathematischer Test, der Algebra, Geometrie, Analysis und mehr abdeckt |
| AIME 2025 (ohne Tools) | 92% | American Invitational Mathematics Examination, Highschool-Wettbewerbsniveau |
| AIME 2025 (mit Code-Ausführung) | 100% | Vorgängermodell Gemini 3 Pro erreichte mit aktivierter Code-Ausführung volle Punktzahl |
| GPQA Diamond | 94.3% | Wissenschaftliche Fragen auf Graduierten-Niveau, führt alle Modelle auf diesem Level an |
| ARC-AGI-2 | 77.1% | Abstrakte Schlussfolgerungsfähigkeit, doppelt so hoch wie beim Vorgänger 3 Pro |
| MathArena Apex | Deutlich führend | Mehr als 20-fache Verbesserung gegenüber dem Vorgänger |
Gemini 3.1 Pro erzielte in 12 von 18 von Google offiziell veröffentlichten Haupt-Benchmark-Tests die beste Punktzahl. Besonders hervorzuheben ist die Leistung von 95,1% im MATH-Benchmark für mathematisches Denken, was bedeutet, dass es in allen mathematischen Teilbereichen wie Algebra, Geometrie, Wahrscheinlichkeitsrechnung und Analysis über starke Problemlösungsfähigkeiten verfügt.
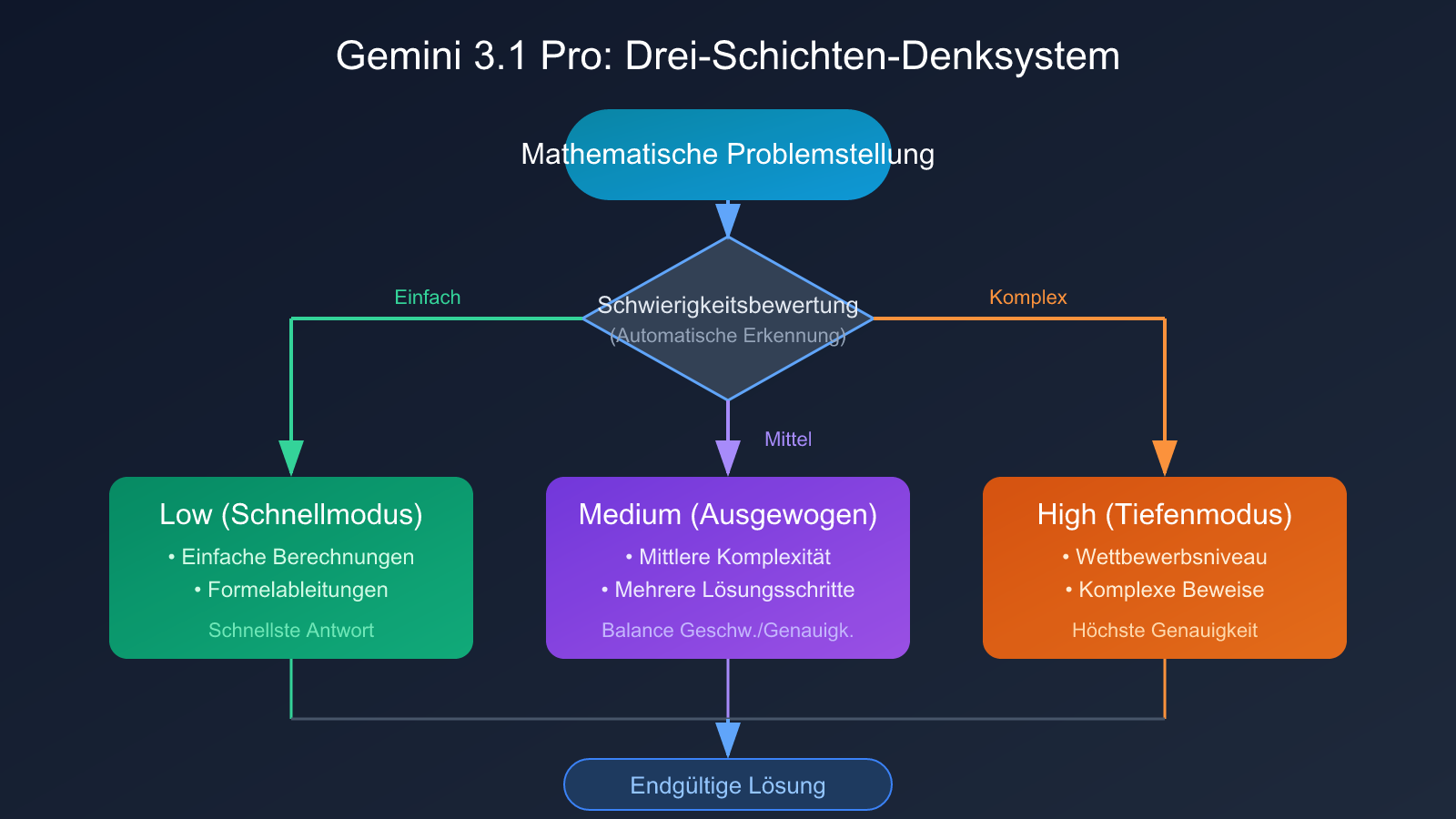
Drei-Schichten-Denksystem von Gemini 3.1 Pro
Gemini 3.1 Pro führt eine wichtige architektonische Innovation ein – das Drei-Schichten-Denksystem:
- Low (Schnellmodus): Verarbeitet einfache mathematische Berechnungen und Formelableitungen, schnellste Antwortzeiten.
- Medium (Ausgewogener Modus): Neue Zwischenschicht, verarbeitet mathematische Probleme mittlerer Schwierigkeit, balanciert Geschwindigkeit und Genauigkeit.
- High (Tiefenmodus): Verarbeitet komplexe Probleme mit mehreren Lösungsschritten, wie Mathematikaufgaben auf Wettbewerbsniveau.
Dieses Drei-Schichten-System ermöglicht es Entwicklern, Anfragen je nach Schwierigkeitsgrad des mathematischen Problems flexibel zu routen, ohne sich zwischen "schnell, aber ungenau" und "langsam, aber präzise" entscheiden zu müssen. Dieser architektonische Vorteil ist besonders in Szenarien mit Batch-Verarbeitung von Aufgaben unterschiedlicher Schwierigkeit (z.B. adaptive Aufgabenstellungssysteme auf Bildungsplattformen) von Bedeutung.
Praktische Erfahrung mit der mathematischen Problemlösung von Gemini 3.1 Pro
In der praktischen mathematischen Problemlösung lässt sich die Leistung von Gemini 3.1 Pro Preview als "umfassend und stabil" zusammenfassen:
- Algebra: Polynomoperationen, Gleichungssystemlösung, Ungleichungsbeweise – nahezu fehlerfrei, dank der hohen Abdeckung von 95,1% im MATH-Benchmark.
- Geometrie: Vollständige Schlussfolgerungsketten in analytischer und räumlicher Geometrie, besonders stark bei koordinatenbezogenen Berechnungsaufgaben.
- Wahrscheinlichkeit und Statistik: Klare Logik bei bedingten Wahrscheinlichkeiten, Kombinatorik etc., kann komplexe mehrstufige Berechnungen korrekt verarbeiten.
- Analysis: Genaue Lösung von bestimmten und unbestimmten Integralen, erkennt gängige Integrationstechniken und wendet sie korrekt an.
Die Leistung von Gemini 3.1 Pro, in 12 von 18 Haupt-Benchmarks die beste Punktzahl zu erzielen, ist kein Zufall. Sein Artificial Analysis Intelligence Index liegt bei 57 Punkten, gleichauf mit GPT-5.4 (xhigh) und damit weit über dem Median von 28 Punkten, was einen umfassenden Vorteil in der intelligenten Schlussfolgerung zeigt.
Claude Sonnet 4.6 Mathematische Fähigkeiten im Detail
Claude Sonnet 4.6 ist das neueste Mittelklasse-Modell von Anthropic und hat einen qualitativen Sprung in seinen mathematischen Denkfähigkeiten vollzogen – von 62 % bei der Vorgängerversion Sonnet 4.5 auf 89 %, ein Plus von satten 27 Prozentpunkten.
Benchmark-Ergebnisse von Claude Sonnet 4.6
| Benchmark-Test | Sonnet 4.6 | Sonnet 4.5 (Vorgänger) | Verbesserung |
|---|---|---|---|
| Mathematik Gesamt | 89% | 62% | +27 Prozentpunkte |
| ARC-AGI-2 | 58.3% | 13.6% | 4,3-fache Verbesserung |
| GPQA Diamond | 74.1% | — | Wissenschaftliches Denken auf Graduierten-Niveau |
| Programmierfähigkeit | 79.6% | — | Nahe an Opus 4.6 mit 80.8% |
| Finanzanalyse | 63.3% | — | Beste in seiner Klasse |
Der Sprung der mathematischen Fähigkeiten von 62 % auf 89 % ist eine der auffälligsten Veränderungen bei Sonnet 4.6. Das bedeutet, dass es sich von einem "Modell, das gelegentlich Fehler bei Matheaufgaben macht" zu einem "Modell, das komplexe Berechnungen zuverlässig bewältigen kann" entwickelt hat.
Adaptiver Denkmechanismus von Claude Sonnet 4.6
Ein weiteres Highlight von Claude Sonnet 4.6 ist der Mechanismus für adaptive Denktiefe (Adaptive Thinking):
- Einfache Probleme: Schnelle Antworten, keine Verschwendung von Denkressourcen. Zum Beispiel Grundrechenarten, einfache Gleichungslösungen.
- Mittelschwere Probleme: Angemessene Erweiterung der Denkkette. Zum Beispiel mehrstufige Algebra-Operationen, Wahrscheinlichkeitsberechnungen.
- Komplexe Probleme: Automatisches Auslösen tiefer Denkketten. Zum Beispiel Kombinatorik, Beweisaufgaben, Wettbewerbsniveau-Probleme.
Der Vorteil dieses adaptiven Mechanismus im praktischen Einsatz ist: Sie müssen die Denktiefe nicht manuell anpassen. Das Modell beurteilt automatisch den Schwierigkeitsgrad der mathematischen Aufgabe und weist entsprechende Rechenressourcen zu, um eine optimale Balance zwischen Latenz und Kosten zu erreichen.
Einzigartiger Vorteil von Claude Sonnet 4.6: Der Lösungsprozess
In mathematischen Lösungsszenarien hat Claude Sonnet 4.6 einen weithin anerkannten, einzigartigen Vorteil – die Klarheit des Lösungsprozesses. Mehrere Evaluierungen weisen darauf hin, dass Claude-Modelle bei der Erklärung mathematischer Konzepte am besten abschneiden. Darüber hinaus ist der von Anthropic eingeführte Learning Mode (Lernmodus) speziell dafür konzipiert, den Denkprozess von Schülern zu leiten, anstatt direkt die Antwort zu geben.
Das macht Claude Sonnet 4.6 besonders geeignet für:
- Szenarien der Mathematikausbildung und Nachhilfe
- Lernende, die die Lösungsschritte verstehen müssen
- Forscher, die ihre Lösungsansätze überprüfen möchten
💡 Lerntipp: Wenn Ihr Hauptbedarf das "Verstehen des mathematischen Lösungsprozesses" ist und nicht nur das Erhalten der Antwort, ist Claude Sonnet 4.6 die beste Wahl. Sie können über APIYI apiyi.com kostenlose Testguthaben erhalten, um den Detailgrad seines Lösungsprozesses zu erleben.
GPT-5.4 Mathematische Fähigkeiten im Detail
GPT-5.4 ist das neueste Flaggschiff-Modell von OpenAI, veröffentlicht am 6. März 2026. Es ist OpenAIs erstes Inferenzmodell, das in einem einzigen Standardmodell fortschrittliche Fachkenntnisse, Programmierfähigkeiten (von GPT-5.3-Codex), native Computeroperationen und ein 1,05-Millionen-Token-Kontextfenster vereint.
Benchmark-Ergebnisse von GPT-5.4
| Benchmark-Test | Punktzahl | Erläuterung |
|---|---|---|
| AIME 2025 | 100% (volle Punktzahl) | High-School-Mathematikwettbewerbsniveau, perfekte Leistung |
| GSM8K | 99% | Grundschul-Mathetextaufgaben, nahezu perfekt |
| MATH | 88.6% | Umfassender Mathematik-Denk-Benchmark |
| GPQA Diamond | 84.2% (Standard) / 92.8% (Hohes Denken) | Wissenschaftliches Denken auf Graduierten-Niveau |
| ARC-AGI-2 | 73.3% (Standard) / 83.3% (Pro) | Abstraktes Denkvermögen |
| FrontierMath (Vorgänger 5.2) | 40.3% | Neuer Rekord für Experten-Level-Frontiermathematik |
GPT-5.4 erzielte die erstaunliche Punktzahl von 100 % bei AIME 2025. Das bedeutet, dass es alle hochschwierigen Wettbewerbsaufgaben des American Invitational Mathematics Examination perfekt lösen kann. Für Nutzer, die Wettbewerbsniveau-Mathematikprobleme lösen müssen, ist diese Leistung äußerst überzeugend.
Es ist bemerkenswert, dass GPT-5.4 im MATH-Benchmark mit 88,6 % eine gewisse Lücke zu Gemini 3.1 Pro mit 95,1 % aufweist. Dies zeigt, dass GPT-5.4, obwohl es bei Wettbewerbsniveau-Herausforderungen perfekt abschneidet, in umfassenden Tests, die ein breites mathematisches Spektrum abdecken, nicht das stärkste ist.
Denkkonfigurationsoptionen von GPT-5.4
GPT-5.4 bietet mehrere Denkkonfigurationen, um sich an verschiedene mathematische Probleme anzupassen:
- GPT-5.4 Standard: Geeignet für tägliche mathematische Berechnungen und mittelschwierige Probleme.
- GPT-5.4 Thinking: Aktiviert fortgeschrittenes Denken, geeignet für komplexe mehrstufige Schlussfolgerungen und Beweise.
- GPT-5.4 Pro: Höchstleistungskonfiguration, ARC-AGI-2 erreicht 83,3 %, geeignet für Szenarien mit höchstem Schwierigkeitsgrad.
Es ist jedoch zu beachten, dass GPT-5.4 Pro mit 30,00 $/1 Mio. Input-Tokens + 180,00 $/1 Mio. Output-Tokens deutlich teurer ist als die Standardversion. Für die meisten mathematischen Lösungsszenarien ist die Standardversion ausreichend.
Praktische Erfahrung mit GPT-5.4 bei mathematischen Problemen
Die Leistung von GPT-5.4 bei Wettbewerbsniveau-Mathematikaufgaben ist besonders beeindruckend:
- Wettbewerbsmathematik: AMC/AIME-Niveau-Probleme aus Zahlentheorie, Kombinatorik und Geometrie werden nahezu perfekt beantwortet. Die volle Punktzahl von 100 % bei AIME ist wohlverdient.
- Beweisaufgaben: Kann vollständige mathematische Beweisketten aufbauen, logisch stringent, mit natürlichen Übergängen zwischen den Schritten.
- Angewandte Mathematik: Die Punktzahl von 99 % bei GSM8K zeigt, dass es auch bei praktischen Textaufgaben (wie Ingenieursberechnungen, Wirtschaftsmodellierung) sehr zuverlässig ist.
- Mehrstufiges Denken: Dank des extrem langen 1,05-Millionen-Token-Kontextfensters kann es gleichzeitig vollständige Denkketten beibehalten und extrem komplexe mehrstufige mathematische Probleme bearbeiten.
Ein einzigartiger Vorteil von GPT-5.4 ist, dass sein Vorgänger GPT-5.2 mit 40,3 % einen neuen Rekord bei FrontierMath (Experten-Level-Frontiermathematik) aufgestellt hat. Das bedeutet, dass die GPT-Serie auch bei wirklich fortschrittlichen, ungelösten mathematischen Problemen über gewisse Explorationsfähigkeiten verfügt, was andere Modelle derzeit kaum erreichen können.
Benchmark-Tests für mathematische KI-Modelle verstehen
Bevor wir mathematische KI-Modelle vergleichen, ist es wichtig, die Bedeutung und Schwerpunkte der einzelnen Benchmark-Tests zu verstehen, um die Modellfähigkeiten genauer beurteilen zu können:
| Benchmark-Test | Vollständiger Name | Testinhalt | Schwierigkeitsgrad |
|---|---|---|---|
| AIME 2025 | American Invitational Mathematics Examination | Originalaufgaben der amerikanischen Mathematikwettbewerbe, umfasst Zahlentheorie, Kombinatorik, Geometrie usw. | Oberstufen-Wettbewerbsniveau (Top 5% der Schüler) |
| MATH | Mathematics Aptitude Test of Heuristics | Umfassender Test, der 7 große Bereiche wie Algebra, Geometrie und Analysis abdeckt | Oberstufen- bis Bachelor-Niveau |
| GSM8K | Grade School Math 8K | 8000 Textaufgaben aus der Grund- und Mittelschulmathematik | Grundlegendes Niveau |
| GPQA Diamond | Graduate-Level Google-Proof QA | Wissenschaftliche Denkaufgaben auf Graduierten-Niveau, von Fachexperten erstellt | Master-/Promotionsniveau |
| ARC-AGI-2 | Abstraction and Reasoning Corpus | Erkennung neuer logischer Muster, testet abstraktes Denkvermögen | Allgemeine Intelligenz-Niveau |
| FrontierMath | Frontier Mathematics | Experten-Level-Fragen zu fortgeschrittener Mathematik, beinhaltet ungelöste oder neue Gebiete | Experten-/Forscher-Niveau |
Wichtige Erkenntnis: AIME legt mehr Wert auf wettbewerbsorientierte mathematische Techniken und kreatives Denken, während MATH die umfassende Abdeckung eines breiten Spektrums betont. Ein Modell, das bei AIME perfekt abschneidet, aber bei MATH nicht die höchste Punktzahl erreicht (wie GPT-5.4), zeigt, dass es bei kniffligen Wettbewerbsaufgaben extrem stark ist, aber in einigen grundlegenden Bereichen möglicherweise etwas schlechter abschneidet als Modelle mit höheren MATH-Werten.
Deshalb empfehlen wir Gemini 3.1 Pro Preview als erste Wahl für umfassende Leistung – ein MATH-Wert von 95,1% bedeutet, dass es in allen mathematischen Teilbereichen ausgewogenere Leistungen erbringt.
Es ist wichtig zu beachten, dass der AIME 2025 Benchmark mittlerweile gesättigt ist – mehrere Top-Modelle (in Kombination mit Code-Ausführung) erreichen 95% oder mehr, manche sogar die volle Punktzahl. Daher sind Benchmarks mit höherem Schwierigkeitsgrad wie MathArena Apex und FrontierMath besser geeignet, um die tatsächlichen mathematischen Fähigkeiten der Modelle zu unterscheiden. Bei MathArena Apex hat Gemini 3.1 Pro im Vergleich zur Vorgängerversion eine Steigerung um das über 20-fache erreicht, was auf eine extrem starke Grundlage für mathematisches Denken hindeutet.
Eine weitere wichtige Dimension ist ARC-AGI-2 (Abstraktes Denkvermögen). Dieser Test bewertet die Fähigkeit des Modells, völlig neue logische Muster zu erkennen – Muster, die das Modell während seines Trainings nie gesehen hat. Gemini 3.1 Pro Preview liegt mit 77,1% an der Spitze, was zeigt, dass es nicht nur bekannte Aufgabentypen lösen kann, sondern auch über eine stärkere Fähigkeit zur Verallgemeinerung und zum logischen Schluss verfügt und bei völlig neuen Arten mathematischer Probleme besser abschneidet.
Praktische Anwendung: Mathematische KI-Modelle per API aufrufen
Hier ist ein minimalistisches Codebeispiel für den API-Aufruf mathematischer KI-Modelle, das in nur 10 Zeilen Code läuft:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # APIYI einheitliche Schnittstelle
)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview", # Kann zu claude-sonnet-4.6 oder gpt-5.4 gewechselt werden
messages=[{"role": "user", "content": "Löse: Gegeben ist die arithmetische Folge {an} mit dem ersten Glied a1=2 und der Differenz d=3. Berechne die Summe S20 der ersten 20 Glieder."}]
)
print(response.choices[0].message.content)
Vollständigen Code für mathematische Problemlösung anzeigen (mit Mehr-Modell-Vergleich)
import openai
from typing import Optional
def solve_math(
problem: str,
model: str = "gemini-3.1-pro-preview",
system_prompt: Optional[str] = None
) -> str:
"""
Ruft ein KI-Modell zur Lösung einer mathematischen Aufgabe auf.
Args:
problem: Beschreibung der mathematischen Aufgabe
model: Modellname, unterstützt gemini-3.1-pro-preview / claude-sonnet-4.6 / gpt-5.4
system_prompt: System-Eingabeaufforderung, kann den Lösungsstil festlegen
Returns:
Die Lösungsantwort des Modells
"""
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # APIYI einheitliche Schnittstelle
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
else:
messages.append({
"role": "system",
"content": "Du bist ein Experte für mathematische Problemlösung. Löse mathematische Probleme mit klaren Schritten und erkläre die Begründung für jeden Schritt."
})
messages.append({"role": "user", "content": problem})
try:
response = client.chat.completions.create(
model=model,
messages=messages,
max_tokens=2000
)
return response.choices[0].message.content
except Exception as e:
return f"Fehler: {str(e)}"
# Anwendungsbeispiel: Dieselbe Aufgabe wird mit drei Modellen gelöst und verglichen
problem = "Im Dreieck ABC sind gegeben: a=5, b=7, C=60°. Berechne die Fläche des Dreiecks und die Länge der dritten Seite c."
models = ["gemini-3.1-pro-preview", "claude-sonnet-4.6", "gpt-5.4"]
for m in models:
print(f"\n{'='*50}")
print(f"Modell: {m}")
print(f"{'='*50}")
result = solve_math(problem, model=m)
print(result)
Empfehlung: Holen Sie sich über APIYI apiyi.com kostenlose Testguthaben. Mit einem einzigen API-Schlüssel können Sie die drei oben genannten mathematischen Modelle aufrufen und schnell die Unterschiede in ihrer Leistung bei Ihren konkreten Aufgaben vergleichen.
Preis- und Preis-Leistungs-Vergleich von KI-Modellen für mathematische Problemlösung
Bei der Auswahl eines KI-Modells für mathematische Problemlösung ist der Preis ein nicht zu vernachlässigender Faktor. Hier ist ein detaillierter Preisvergleich der drei Modelle:
| Preis-Dimension | Gemini 3.1 Pro Preview | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|---|
| Input-Preis | $2,00/1M Tokens | $3,00/1M Tokens | $2,50/1M Tokens |
| Output-Preis | $12,00/1M Tokens | $15,00/1M Tokens | $15,00/1M Tokens |
| Mischpreis (3:1) | $4,50/1M Tokens | $6,00/1M Tokens | $5,63/1M Tokens |
| Aufpreis für langes Kontextfenster | >200K verdoppelt | Keiner | >272K verdoppelt |
| Kontextfenster | 1M Tokens | Standardfenster | 1,05M Tokens |
| Maximale Ausgabe | 65.536 Tokens | Standardausgabe | 128.000 Tokens |
Analyse aus Preis-Leistungs-Sicht:
- Gemini 3.1 Pro Preview bietet das beste Preis-Leistungs-Verhältnis: Der Input-Preis beträgt nur $2,00/1M Tokens, und die MATH-Benchmark-Ergebnisse von 95,1 % sind führend. Laut Artificial Analysis liegen die Betriebskosten bei etwa 1/7,5 von Claude Opus 4.6, während die Leistung in mathematischen und Programmier-Benchmarks gleichauf oder sogar besser ist.
- Claude Sonnet 4.6 ist preislich moderat: Die Preisgestaltung von $3,00/$15,00 entspricht der Vorgängerversion Sonnet 4.5, aber die mathematischen Fähigkeiten haben sich um 27 Prozentpunkte verbessert, was die Preis-Leistung erheblich steigert.
- GPT-5.4 Standard ist angemessen bepreist: Die Preisgestaltung von $2,50/$15,00 liegt in einem vernünftigen Rahmen. Bei Verwendung von GPT-5.4 Pro ($30/$180) steigen die Kosten jedoch erheblich.
💰 Kostenempfehlung: Für den täglichen Bedarf an mathematischer Problemlösung wird Gemini 3.1 Pro Preview für das beste Preis-Leistungs-Verhältnis empfohlen. Für eine weitere Kostenoptimierung können Sie eine API-Aggregator-Plattform in Betracht ziehen, um flexiblere Aufladeoptionen zu erhalten.
Praktische Kostenschätzung für mathematische Problemlösung
Um Ihnen ein besseres Verständnis der Kostenunterschiede zu vermitteln, finden Sie hier eine Kostenschätzung für ein typisches Szenario der mathematischen Problemlösung:
Szenario-Annahme: Tägliche Lösung von 100 mathematischen Aufgaben mittlerer Schwierigkeit, durchschnittlicher Verbrauch pro Aufgabe: 500 Input-Tokens + 1500 Output-Tokens.
| Modell | Tägliche Input-Kosten | Tägliche Output-Kosten | Tägliche Gesamtkosten | Monatliche Kosten (30 Tage) |
|---|---|---|---|---|
| Gemini 3.1 Pro | $0,10 | $1,80 | $1,90 | $57,00 |
| GPT-5.4 | $0,13 | $2,25 | $2,38 | $71,25 |
| Claude Sonnet 4.6 | $0,15 | $2,25 | $2,40 | $72,00 |
| GPT-5.4 Pro | $1,50 | $27,00 | $28,50 | $855,00 |
| DeepSeek R2 | $0,03 | $0,33 | $0,36 | $10,80 |
Aus der Kostenschätzung wird deutlich:
- Die monatlichen Kosten für Gemini 3.1 Pro Preview liegen bei etwa $57 und sind damit die wirtschaftlichste Option unter den drei Hauptmodellen.
- Die Kosten für Claude Sonnet 4.6 und GPT-5.4 Standard sind mit etwa $71-72/Monat ähnlich.
- Die Kosten für GPT-5.4 Pro sind mit $855/Monat sehr hoch und eignen sich nur für Szenarien mit ausreichendem Budget und dem Bedarf an höchster Genauigkeit.
- DeepSeek R2 bietet mit monatlichen Kosten von nur $10,80 eine äußerst wettbewerbsfähige Lösung.
Vergleich des umfassenden Intelligenzindex für mathematische Problemlösungs-KI-Modelle
Neben einzelnen Benchmark-Tests kann ein umfassender Intelligenzindex das Potenzial eines Modells für mathematisches Denken ganzheitlicher widerspiegeln. Der Artificial Analysis Intelligence Index ist eines der derzeit maßgeblichsten umfassenden Bewertungssysteme. Er berechnet einen Gesamtscore für Modelle basierend auf vier Dimensionen: logisches Denken, Wissen, Mathematik und Programmierung.
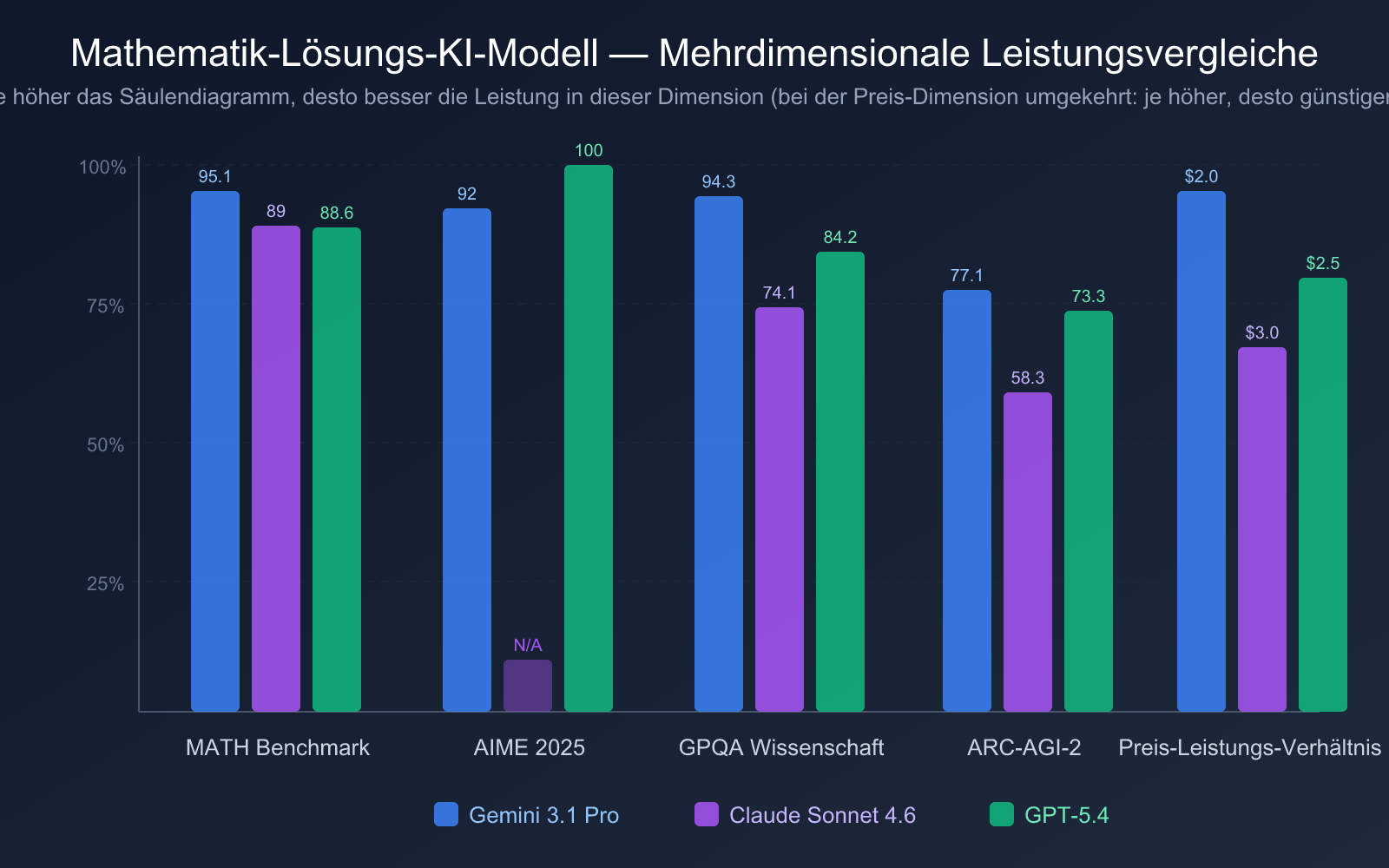
| Modell | Umfassender Intelligenzindex | AIME 2025 | MATH | GPQA Diamond | ARC-AGI-2 | Umfassende Bewertung |
|---|---|---|---|---|---|---|
| GPT-5.4 (xhigh) | 57 | 100% | 88.6% | 84.2% | 73.3% | König der Wettbewerbsaufgaben, geteilter erster Platz im Gesamtindex |
| Gemini 3.1 Pro Preview | 57 | 92% | 95.1% | 94.3% | 77.1% | Geteilter erster Platz im Gesamtindex, umfassendste mathematische Abdeckung |
| Claude Opus 4.6 | 53 | — | — | 91.3% | — | Spitzenklasse in wissenschaftlichem Denken und Erklärfähigkeit |
| Claude Sonnet 4.6 (max) | 52 | — | 89% | 74.1% | 58.3% | Hervorragendes Preis-Leistungs-Verhältnis, klarster Lösungsprozess |
Betrachtet man den umfassenden Intelligenzindex, teilen sich GPT-5.4 (xhigh) und Gemini 3.1 Pro Preview mit 57 Punkten den ersten Platz, jedoch mit unterschiedlichen Schwerpunkten:
- GPT-5.4: Glänzt bei Wettbewerbsaufgaben wie AIME mit perfekten 100%, aber der MATH-Gesamtbenchmark (88.6%) ist etwas niedriger.
- Gemini 3.1 Pro: Bietet ein ausgewogeneres Profil mit einem starken MATH-Gesamtbenchmark (95.1%) und wissenschaftlichem Denken (GPQA Diamond 94.3%).
Das bedeutet: Wenn Ihre mathematischen Anforderungen auf Wettbewerbe und extrem schwierige Probleme ausgerichtet sind, ist GPT-5.4 die bessere Wahl. Benötigen Sie eine stabile Leistung über ein breites Spektrum mathematischer Gebiete hinweg, ist Gemini 3.1 Pro Preview die sicherere Option.
Empfehlungen für mathematische Problemlösungs-KI-Modelle nach Anwendungsszenario
Verschiedene mathematische Anwendungsszenarien stellen unterschiedliche Anforderungen an Modelle. Hier sind Empfehlungen basierend auf praktischen Nutzungsszenarien:
Mathematische Szenarien für Gemini 3.1 Pro Preview
- Umfassende Mathematik-Nachhilfeplattform: Abdeckung aller Bereiche wie Algebra, Geometrie, Analysis; stärkste Gesamtfähigkeit mit MATH 95.1%.
- Verarbeitung großer Mengen mathematischer Aufgaben: Niedrigster Preis; das dreistufige Denksystem passt sich automatisch dem Schwierigkeitsgrad an und senkt die Verarbeitungskosten.
- Szenarien mit wissenschaftlichen Berechnungen: Wissenschaftliches Denkvermögen von 94.3% (GPQA Diamond), ideal für Aufgaben an der Schnittstelle von Physik, Chemie und Mathematik.
- Visuelle mathematische Probleme: Die multimodalen Fähigkeiten von Gemini bieten Vorteile bei Aufgaben mit Diagrammen oder geometrischen Figuren.
Mathematische Szenarien für Claude Sonnet 4.6
- Mathematikunterricht und -nachhilfe: Lösungsprozess am klarsten; der "Learning Mode" führt Schüler gezielt zum Denken an, statt nur die Antwort zu geben.
- Lernen von Lösungswegen: In Szenarien, in denen verstanden werden muss "Warum macht man das so?", ist Claudes Erklärfähigkeit allgemein anerkannt. 70% der Nutzer bevorzugen Sonnet 4.6 gegenüber der Vorgängerversion 4.5, was auf einen qualitativen Sprung in der Benutzererfahrung hindeutet.
- Unterstützung in der mathematischen Forschung: Geeignet für Forscher, die detaillierte Herleitungen zur Überprüfung ihrer Gedankengänge benötigen; die adaptive Denktiefe passt sich automatisch der Problemkomplexität an.
- Büro- und Finanzberechnungen: 63.3% bei Finanzanalysen (bester in seiner Klasse); 1633 Elo im GDPval-AA für Büroproduktivität übertrifft sogar das teurere Opus 4.6.
- Kombination aus Programmierung und Mathematik: Programmierfähigkeit von 79.6% liegt nahe an Opus 4.6, ideal für Entwickler, die mathematische Berechnungsprogramme schreiben müssen.
Mathematische Szenarien für GPT-5.4
- Hochschwierige Mathematikwettbewerbe: 100% bei AIME, erste Wahl für Wettbewerbsaufgaben.
- Lange mathematische Ableitungen in Dokumenten: Kontextfenster von 1.05 Mio. Token, geeignet für komplexe Probleme, die viele mathematische Hintergrundinformationen erfordern.
- Professionelle mathematische Forschung: Der Vorgänger GPT-5.2 setzte mit 40.3% einen neuen Rekord bei FrontierMath, zeigt also starke Fähigkeiten in hochaktueller, expertennaher Mathematik.
- Investmentbanking und quantitative Finanzen: Hohe Punktzahl von 87.3% bei Investmentbanking-Modellierungsaufgaben, geeignet für anspruchsvolle finanzmathematische Szenarien.
Kombinierte Nutzungsstrategie: Beste Kombination für mathematische Problemlösungsmodelle
In realen Produktionsumgebungen setzen viele Teams auf kombinierte Nutzungsstrategien, um die besten Ergebnisse zu erzielen:
Strategie 1: Routing nach Schwierigkeitsgrad
- Grundlegende Aufgaben (Arithmetik, einfache Gleichungen) → Gemini 3.1 Pro Low-Modus (niedrigste Kosten)
- Mittelschwere Aufgaben (mehrschrittige Ableitungen, Textaufgaben) → Claude Sonnet 4.6 adaptiver Modus (klarer Lösungsprozess)
- Hochschwierige Aufgaben (Wettbewerbe, Beweise) → GPT-5.4 Thinking-Modus (höchste Genauigkeit)
Strategie 2: Kreuzvalidierung
- Zuerst schnelle Lösung mit Gemini 3.1 Pro (niedrige Kosten, hohe Geschwindigkeit)
- Kritische Ergebnisse mit GPT-5.4 zweitvalidieren (höchste Genauigkeit)
- Bei der Erklärung für den Nutzer mit Claude Sonnet 4.6 neu formulieren (klare Darstellung)
🚀 Umsetzungsempfehlung: Die oben genannten kombinierten Nutzungsstrategien lassen sich einfach über die APIYI-Plattform
apiyi.comumsetzen. Mit einem einzigen API-Schlüssel können alle Modelle aufgerufen werden, indem einfach dermodel-Parameter im Code geändert wird.
Entscheidungsempfehlungen für KI-Modelle zur mathematischen Problemlösung
Basierend auf der obigen Analyse finden Sie hier Entscheidungsempfehlungen für verschiedene Nutzergruppen:
| Nutzertyp | Empfohlenes Modell | Begründung |
|---|---|---|
| Schüler/Selbstlernende | Claude Sonnet 4.6 | Klarer Lösungsweg, "Learning Mode" fördert eigenständiges Denken |
| Entwickler von Bildungsplattformen | Gemini 3.1 Pro Preview | Beste Gesamtleistung, niedrigster Preis, dreistufiges Denken passt sich dem Schwierigkeitsgrad an |
| Wettbewerbsteilnehmer/Trainer | GPT-5.4 | Volle Punktzahl bei AIME, stärkste Fähigkeiten für Wettbewerbsprobleme |
| Forscher | Gemini 3.1 Pro Preview | GPQA Diamond 94,3%, führend bei interdisziplinären Fähigkeiten (Wissenschaft + Mathematik) |
| Unternehmen mit Massenverarbeitung | Gemini 3.1 Pro Preview | Bestes Preis-Leistungs-Verhältnis, Eingabepreis von $2,00/1M Tokens |
| Quantitative Finanzteams | GPT-5.4 | Investment Banking Modellierung 87,3%, stärkste Fähigkeiten für finanzmathematische Szenarien |
💡 Auswahlhinweis: Die Wahl des richtigen KI-Modells für mathematische Problemlösung hängt hauptsächlich von Ihrem konkreten Anwendungsfall ab. Wenn Sie unsicher sind, welches Modell am besten passt, empfehlen wir, über die Plattform APIYI (apiyi.com) alle drei Modelle mit derselben Mathematikaufgabe zu testen und die endgültige Wahl basierend auf Lösungsqualität und Antwortgeschwindigkeit zu treffen. Die Plattform unterstützt einen einheitlichen API-Aufruf, was einen schnellen Vergleich und Wechsel erleichtert.
Weitere beachtenswerte Modelle für mathematische Problemlösung
Neben den drei Hauptmodellen gibt es noch einige weitere KI-Modelle, die in bestimmten Szenarien für mathematische Problemlösung beachtenswert sind:
| Modellname | AIME 2025 | Kernvorteil | API-Preis (Eingabe/Ausgabe) | Geeignetes Szenario |
|---|---|---|---|---|
| DeepSeek R2 | Besiegte Gemini 3.1 Pro | Extremes Preis-Leistungs-Verhältnis | $0,55/$2,19 pro 1M | Budgetsensitive Massenverarbeitung mathematischer Aufgaben |
| Claude Opus 4.6 | — | GPQA 91,3%, tiefste Erklärungen | $15/$75 pro 1M | Hochwertige Forschung und tiefgehende Schlussfolgerungen |
| Qwen3-235B | 89,2% | Stärkstes Open-Source-Modell | Kosten für eigene Bereitstellung | Szenarien, die eine private Bereitstellung erfordern |
| DeepSeek R1 | Ca. 87,5% | Open-Source-Benchmark, 671B MoE | Kosten für eigene Bereitstellung | Open-Source-Community-Forschung und Weiterentwicklung |
| MiMo-V2-Flash | 94,1% | Inferenzkosten nur 2,5% von Claude | Sehr niedrig | Ultra-großvolumige, kostengünstige Inferenz |
Besonders hervorzuheben ist DeepSeek R2, das Gemini 3.1 Pro Preview bei AIME schlug, während der Preis nur etwa 1/4 beträgt. Wenn Ihr Szenario für mathematische Problemlösung extrem budgetempfindlich ist, ist DeepSeek R2 eine äußerst wettbewerbsfähige Wahl.
MiMo-V2-Flash erreichte bei AIME 2025 eine hohe Punktzahl von 94,1%, während die Inferenzkosten nur 2,5% von Claude betragen. Es eignet sich hervorragend für Bildungstechnologieplattformen, die eine massenhafte Verarbeitung mathematischer Aufgaben benötigen.
Optimierungstechniken für Eingabeaufforderungen bei mathematischen KI-Modellen
Unabhängig vom gewählten Modell können gute Eingabeaufforderungen die Qualität der mathematischen Problemlösung erheblich verbessern. Hier sind erprobte Techniken für Eingabeaufforderungen:
- Aufgabentyp klar angeben: Kennzeichnen Sie in der Eingabeaufforderung "Dies ist eine kombinatorische Mathematikaufgabe" oder "Dies ist eine analytische Geometrieaufgabe", um dem Modell zu helfen, die richtige Lösungsstrategie aufzurufen.
- Schrittweise Lösung anfordern: Fügen Sie "Bitte leiten Sie schrittweise ab und kennzeichnen Sie in jedem Schritt den verwendeten Satz oder die Formel" hinzu, um die Lesbarkeit des Lösungsprozesses zu verbessern.
- Ausgabeformat vorgeben: Z.B. "Bitte geben Sie mathematische Formeln im LaTeX-Format aus" oder "Markieren Sie die endgültige Antwort mit einem Kasten".
- Hintergrundbedingungen angeben: Z.B. "Nehmen Sie an, dass x eine positive ganze Zahl ist" oder "Lösen Sie im Bereich der reellen Zahlen", um unnötige Fallunterscheidungen durch das Modell zu vermeiden.
- Kreuzvalidierung mit mehreren Modellen: Überprüfen Sie die Konsistenz wichtiger Ergebnisse mit verschiedenen Modellen, um die Zuverlässigkeit zu erhöhen.
Häufig gestellte Fragen
Q1: Sind die Benchmark-Ergebnisse von KI-Modellen für mathematische Problemlösung vertrauenswürdig?
Benchmarks bieten standardisierte Vergleichsmöglichkeiten, aber die tatsächliche Leistung hängt auch von Faktoren wie Aufgabentyp und Qualität der Eingabeaufforderung ab. AIME und MATH sind derzeit die renommiertesten Benchmarks für mathematisches Denken und werden in Wissenschaft und Industrie weitgehend anerkannt. Es wird empfohlen, neben den Benchmark-Daten auch Ihre eigenen Aufgaben zu testen und zu validieren.
Q2: Ich bin Student. Welches KI-Modell für mathematische Problemlösung sollte ich wählen?
Claude Sonnet 4.6 ist die erste Wahl. Sein Lösungsprozess ist am klarsten, jeder Schritt wird mit einer eindeutigen Erklärung versehen, was ideal zum Lernen und Verstehen mathematischer Lösungsansätze ist. Der "Learning Mode" von Anthropic kann Sie außerdem dazu anleiten, selbst zu denken, anstatt direkt die Antwort zu geben. Bei besonders schwierigen Wettbewerbsaufgaben können Sie zu GPT-5.4 wechseln.
Q3: Wie kann ich diese KI-Modelle für mathematische Problemlösung schnell testen?
Empfohlen wird die Nutzung einer API-Aggregationsplattform mit einheitlicher Schnittstelle für mehrere Modelle:
- Besuchen Sie APIYI apiyi.com und registrieren Sie ein Konto
- Erhalten Sie einen API-Schlüssel und kostenloses Testguthaben
- Verwenden Sie die in diesem Artikel bereitgestellten Python-Codebeispiele und ändern Sie einfach den
model-Parameter, um zwischen verschiedenen Modellen zu wechseln - Testen Sie die drei Modelle mit derselben mathematischen Aufgabe und vergleichen Sie Lösungsqualität und Antwortgeschwindigkeit
Q4: Unterstützen diese KI-Modelle für mathematische Problemlösung die Ausgabe von LaTeX-Formeln?
Alle drei Modelle unterstützen die Ausgabe mathematischer Formeln im LaTeX-Format. Fügen Sie einfach in die Eingabeaufforderung "Bitte geben Sie alle mathematischen Formeln im LaTeX-Format aus" ein. Gemini 3.1 Pro und GPT-5.4 formatieren LaTeX korrekter, während Claude Sonnet 4.6 ausführlichere Textbeschreibungen zwischen den Formeln liefert. Für Szenarien, in denen Formeln direkt in Arbeiten kopiert werden müssen, wird die Verwendung von Gemini oder GPT empfohlen.
Q5: Können KI-Modelle für mathematische Problemlösung Bilder mit mathematischen Aufgaben verarbeiten?
Gemini 3.1 Pro Preview und GPT-5.4 unterstützen beide multimodale Eingaben, sodass Sie direkt Bilder mit mathematischen Aufgaben hochladen und lösen können. Gemini ist besonders gut in der Verarbeitung von Bildern mit geometrischen Formen und handgeschriebenen Formeln. Claude Sonnet 4.6 unterstützt ebenfalls Bildeingaben, ist aber bei der Erkennung komplexer geometrischer Formen Gemini leicht unterlegen. Wenn Ihre mathematischen Aufgaben häufig in Bildform vorliegen (z.B. bei der Suche nach Lösungen durch Fotografieren), ist Gemini 3.1 Pro Preview die beste Wahl.
Zusammenfassung
Die wichtigsten Auswahlkriterien für KI-Modelle zur mathematischen Problemlösung:
- Beste Gesamtleistung: Gemini 3.1 Pro Preview: Führend mit MATH 95,1%, optimaler Preis von $2,00/1M Tokens, flexibles dreistufiges Denksystem für unterschiedliche Schwierigkeitsgrade.
- Beste Wahl zum Lernen und Verstehen: Claude Sonnet 4.6: Mathematische Fähigkeiten um 27 Prozentpunkte auf 89% gesteigert, klare Lösungsschritte, adaptive Denktiefe balanciert Kosten und Qualität.
- Beste Wahl für Wettbewerbsaufgaben: GPT-5.4: Volle 100% bei AIME 2025, 1,05M langer Kontext, unübertroffene Fähigkeiten bei hochkomplexen Schlussfolgerungen.
Kein Modell ist in allen mathematischen Szenarien die optimale Lösung. Die Wettbewerbslandschaft der KI-Modelle für mathematische Problemlösung im Jahr 2026 lässt sich wie folgt zusammenfassen:
- Umfassende Abdeckung: Gemini 3.1 Pro Preview nimmt mit MATH 95,1% und dem niedrigsten Preis die Position der ersten Wahl für die Gesamtleistung ein.
- Bildung und Lernen: Claude Sonnet 4.6 ist dank einer Steigerung der mathematischen Fähigkeiten um 27 Prozentpunkte und unübertroffener Erklärungsfähigkeiten die beste Wahl für Bildungsszenarien.
- Extreme Wettbewerbe: GPT-5.4 ist mit seiner absoluten Stärke von 100% bei AIME im Bereich hochschwieriger Mathematikwettbewerbe unerreicht.
- Priorität Budget: DeepSeek R2 bietet vergleichbare mathematische Denkfähigkeiten zu weniger als einem Viertel des Preises von Gemini.
Die klügste Strategie ist, basierend auf Ihren tatsächlichen Anforderungen das passende Modell zu wählen oder sogar mehrere Modelle für Aufgaben unterschiedlicher Schwierigkeitsgrade zu mischen, um die einzigartigen Vorteile jedes Modells voll auszuschöpfen.
Wir empfehlen, diese Modelle schnell über APIYI apiyi.com zu testen und zu vergleichen. Die Plattform bietet kostenloses Guthaben und eine einheitliche API-Schnittstelle. Mit einer einzigen Integration können Sie alle gängigen mathematischen Denkmodelle flexibel aufrufen und so mühelos eine Strategie zur gemischten Nutzung mehrerer Modelle umsetzen.
📚 Referenzen
-
Google DeepMind Gemini 3.1 Pro Model Card: Offizielle Benchmark-Daten und technische Details
- Link:
deepmind.google/models/model-cards/gemini-3-1-pro/ - Beschreibung: Enthält vollständige Benchmark-Ergebnisse und Architekturbeschreibungen
- Link:
-
Anthropic Claude Sonnet 4.6 Release Notes: Details zur Verbesserung der mathematischen Fähigkeiten
- Link:
docs.anthropic.com - Beschreibung: Enthält Vergleichsdaten von Sonnet 4.6 mit Vorgängermodellen und Erklärungen zum adaptiven Denkmechanismus
- Link:
-
OpenAI GPT-5.4 Release Announcement: Neueste Modellfunktionen und Benchmark-Daten
- Link:
openai.com/index/introducing-gpt-5-4/ - Beschreibung: Enthält vollständige Benchmark-Ergebnisse und Erklärungen zur Reasoning-Konfiguration von GPT-5.4
- Link:
-
Artificial Analysis Model Evaluations: Unabhängige Drittanbieter-Benchmark-Vergleichsplattform
- Link:
artificialanalysis.ai/evaluations/aime-2025 - Beschreibung: Bietet unabhängige Ranglisten und Analysen für Benchmarks wie AIME 2025
- Link:
-
AIME 2025 Benchmark Leaderboard: Autoritativer Vergleich mathematischer Fähigkeiten
- Link:
vals.ai/benchmarks/aime - Beschreibung: Kontinuierlich aktualisierte Daten zur AI-Mathematik-Benchmark-Rangliste
- Link:
Autor: APIYI Technik-Team
Technischer Austausch: Teile deine Erfahrungen mit KI für mathematische Aufgaben gerne in den Kommentaren. Weitere Tutorials zum Modellaufruf findest du im APIYI-Dokumentationszentrum unter docs.apiyi.com