Autorennotiz: Neueste Bewertung vom März 2026 – Vergleich von 10 leichten Großen Sprachmodellen für Übersetzungsszenarien anhand von Geschwindigkeit, Übersetzungsqualität und Kosten, darunter Gemini 3 Flash, Claude Haiku 4.5, DeepSeek V3.2, GPT-5 Nano und weitere.
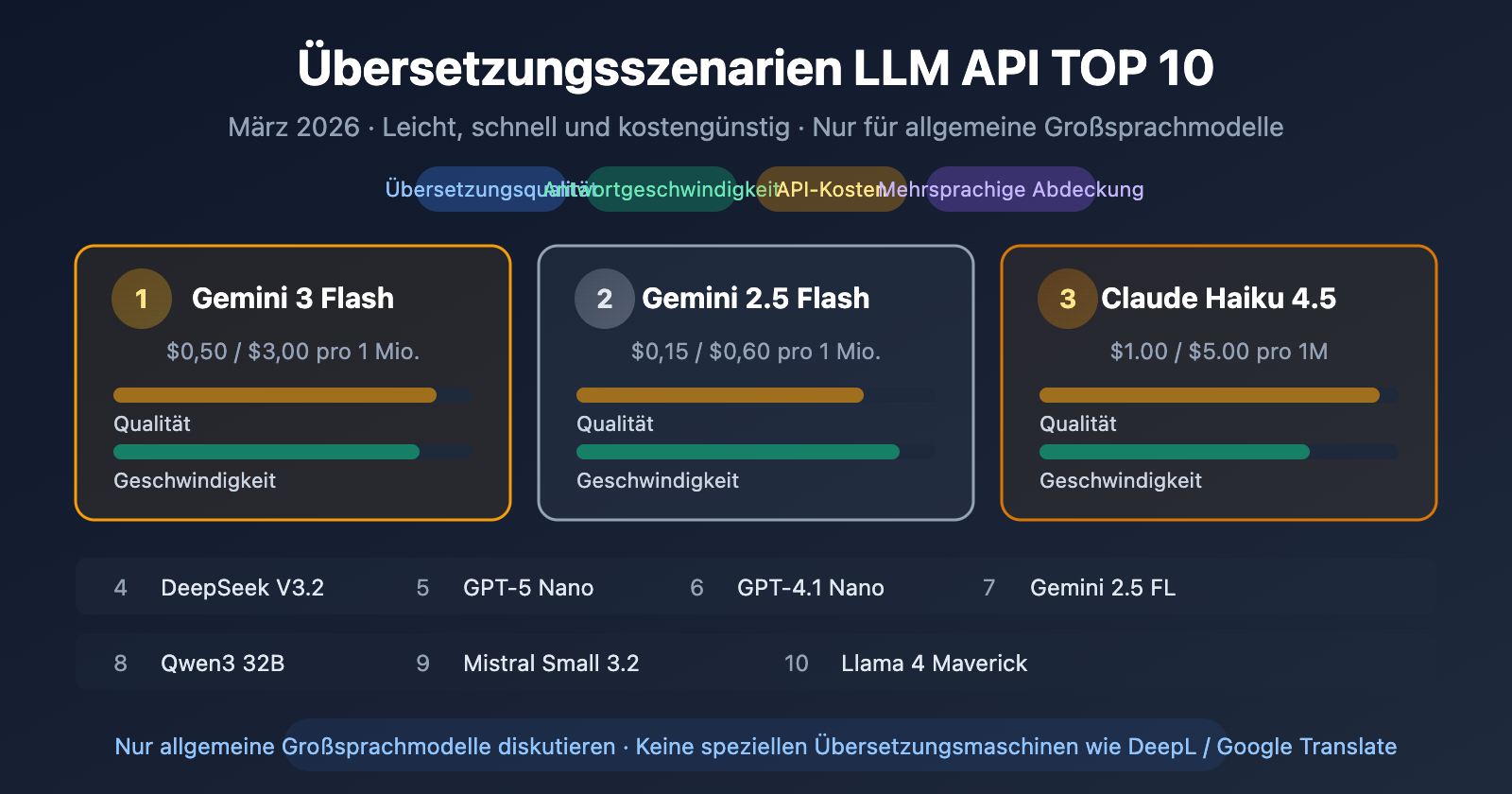
Die Verwendung von Großen Sprachmodellen für Übersetzungen ist 2026 bereits zur Standardlösung geworden. Aber die Frage stellt sich: Welches Modell sollte man für Übersetzungsszenarien wählen?
Dieser Artikel behandelt ausschließlich die Übersetzungsfähigkeiten von universellen Großen Sprachmodellen (LLM) und nicht spezialisierte Übersetzungsmaschinen wie DeepL oder Google Translate. Der Grund ist einfach: Die Stärke von LLM-Übersetzungen liegt in Kontextverständnis, Terminologiekonsistenz und Stilkontrolle – Aspekte, die spezialisierte Übersetzungsmaschinen schwer erreichen können.
Die Modellauswahl für Übersetzungsszenarien basiert auf drei Kernüberlegungen:
- Geschwindigkeit ist entscheidend: Übersetzungsaufgaben werden typischerweise in Batches verarbeitet, und Latenz wirkt sich direkt auf die Effizienz aus
- Qualität darf nicht leiden: Übersetzungsqualität ist nicht verhandelbar – schlechte Übersetzungen sind schlimmer als gar keine
- Kosten müssen kontrollierbar sein: Übersetzungen sind oft hochfrequente, großvolumige Aufgaben mit hohem Token-Verbrauch
Kernwert: Nach dem Lesen dieses Artikels wissen Sie genau, welche leichten Großen Sprachmodelle im März 2026 am besten für Übersetzungsszenarien geeignet sind und wie Sie basierend auf Budget und Qualitätsanforderungen die richtige Wahl treffen.
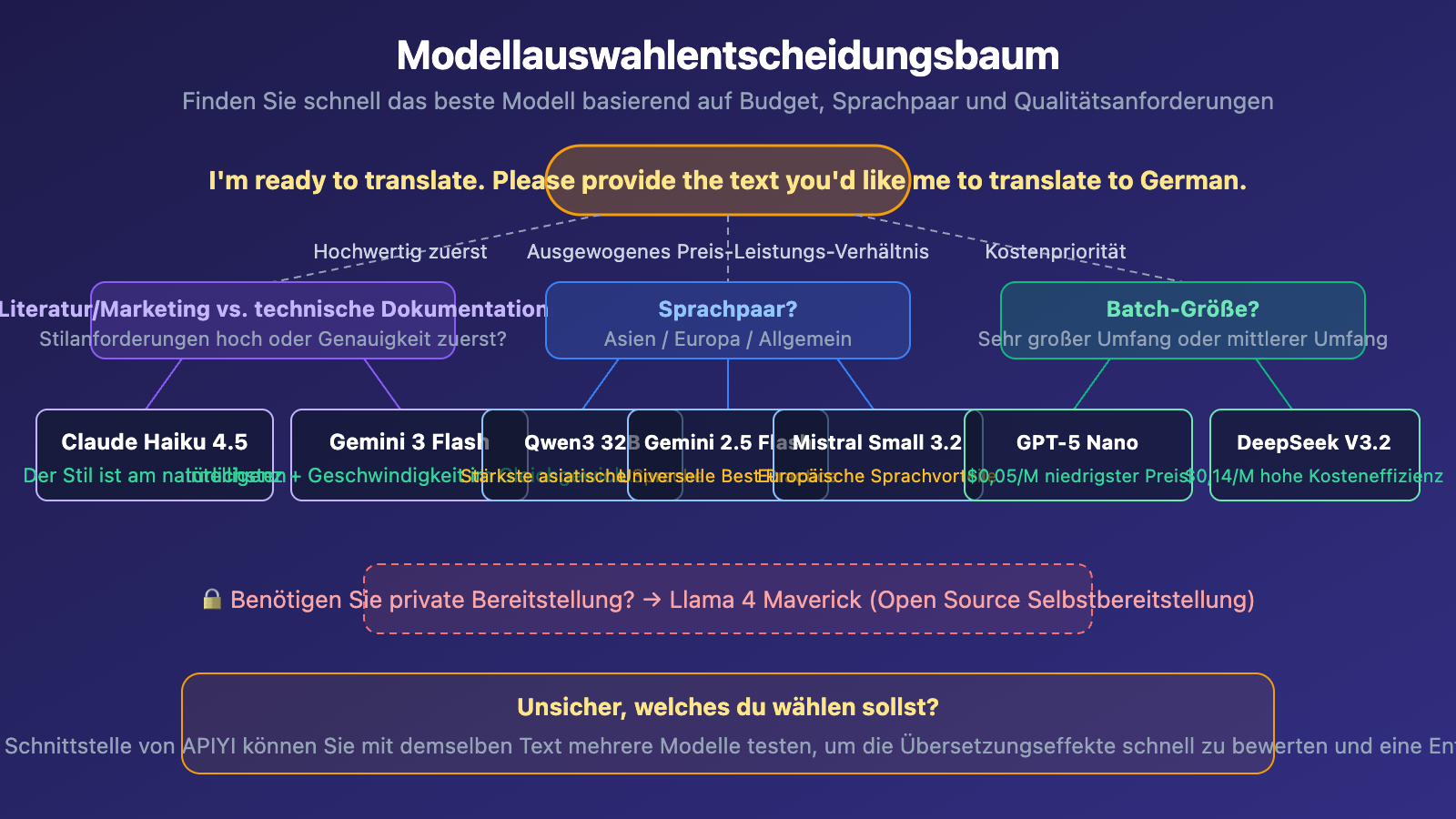
Übersicht der Top 10 Sprachmodelle für Übersetzungen
Die folgende Rangliste berücksichtigt drei Dimensionen – Übersetzungsqualität, Antwortgeschwindigkeit und API-Kosten – mit Fokus auf leichte, kostengünstige Modelle:
| Rang | Modell | Eingabe/Ausgabe-Preis (pro Million Token) | Kernstärken | Empfehlungsgrad |
|---|---|---|---|---|
| 🥇 1 | Gemini 3 Flash Preview | $0,50 / $3,00 | Intelligentestes Leichtgewicht-Modell, hervorragende Übersetzungsqualität | ⭐⭐⭐⭐⭐ |
| 🥈 2 | Gemini 2.5 Flash | $0,15 / $0,60 | Reif und stabil, starke Mehrsprachenfähigkeiten | ⭐⭐⭐⭐⭐ |
| 🥉 3 | Claude Haiku 4.5 | $1,00 / $5,00 | Beste Qualität für literarische Übersetzungen, starke Stilkontrolle | ⭐⭐⭐⭐⭐ |
| 4 | DeepSeek V3.2 | $0,14 / $0,28 | Extrem kostengünstig, hervorragende Chinesisch-Übersetzungsfähigkeiten | ⭐⭐⭐⭐ |
| 5 | GPT-5 Nano | $0,05 / $0,40 | Günstigstes OpenAI-Modell, extrem schnell | ⭐⭐⭐⭐ |
| 6 | GPT-4.1 Nano | $0,10 / $0,40 | Bewährte, stabile Wahl | ⭐⭐⭐⭐ |
| 7 | Gemini 2.5 Flash-Lite | $0,10 / $0,40 | Extrem niedrige Latenz, erste Wahl für Massenübersetzungen | ⭐⭐⭐⭐ |
| 8 | Qwen3 32B | $0,08 / $0,24 | Beste Leistung bei asiatischen Sprachen | ⭐⭐⭐⭐ |
| 9 | Mistral Small 3.2 | $0,06 / $0,18 | Klare Vorteile bei europäischen Sprachen | ⭐⭐⭐⭐ |
| 10 | Llama 4 Maverick | Open Source, Selbsthosting | Starke mehrsprachige Grundfähigkeiten, ideal für private Bereitstellung | ⭐⭐⭐ |
🎯 Auswahlempfehlung: Alle oben genannten Modelle können über die einheitliche Schnittstelle von APIYI unter apiyi.com aufgerufen werden. Mit einem einzigen API-Schlüssel können Sie verschiedene Modelle schnell testen und das beste Modell für Ihren Anwendungsfall finden.
Kernbewertungsdimensionen für Übersetzungsmodelle
Die Auswahl eines Übersetzungsmodells darf sich nicht nur auf Benchmarks stützen. Wir definieren 4 Bewertungsdimensionen basierend auf realen Übersetzungsszenarien:
| Dimension | Gewichtung | Beschreibung | Messmethode |
|---|---|---|---|
| Übersetzungsqualität | 40% | Semantische Genauigkeit, natürliche Ausdrucksweise, konsistente Terminologie | COMET-Score + manuelle Bewertung |
| Antwortgeschwindigkeit | 25% | Latenz des ersten Tokens und Gesamtdurchsatz | TTFT + TPS |
| API-Kosten | 25% | Eingabe-/Ausgabepreis pro Million Token | Offizielle Preisgestaltung |
| Mehrsprachige Abdeckung | 10% | Anzahl unterstützter Sprachen und Qualität bei Minderheitssprachen | Sprachpaar-Abdeckungsquote |
Wichtige Erkenntnisse zur Auswahl von Übersetzungsmodellen
Die Evaluierungsergebnisse von WMT 2025 offenbaren einen wichtigen Trend: Traditionelle maschinelle Übersetzungssysteme sind bei oberflächlichen Metriken wie BLEU noch wettbewerbsfähig, aber Großsprachmodelle zeigen bei der semantischen Bewertungsmetrik COMET stärkere Leistungen. Das bedeutet: LLM-Übersetzungen mögen nicht immer wort-für-wort am präzisesten sein, aber bei „natürlich lesbar und sinngemäß korrekt" überlegen.
Für Übersetzungsszenarien ist die Übersetzungsqualität von Leichtgewicht-Modellen (Flash, Haiku, Nano usw.) bereits ausreichend gut – Übersetzung erfordert keine komplexe Reasoning-Fähigkeit, sondern vor allem Sprachverständnis und Generierungsfähigkeit, und genau das sind die Stärken von Leichtgewicht-Modellen.
Übersetzungsmodelle TOP10 – Detaillierte Analyse
Erste Liga: Optimale Übersetzungsqualität und Preis-Leistungs-Verhältnis
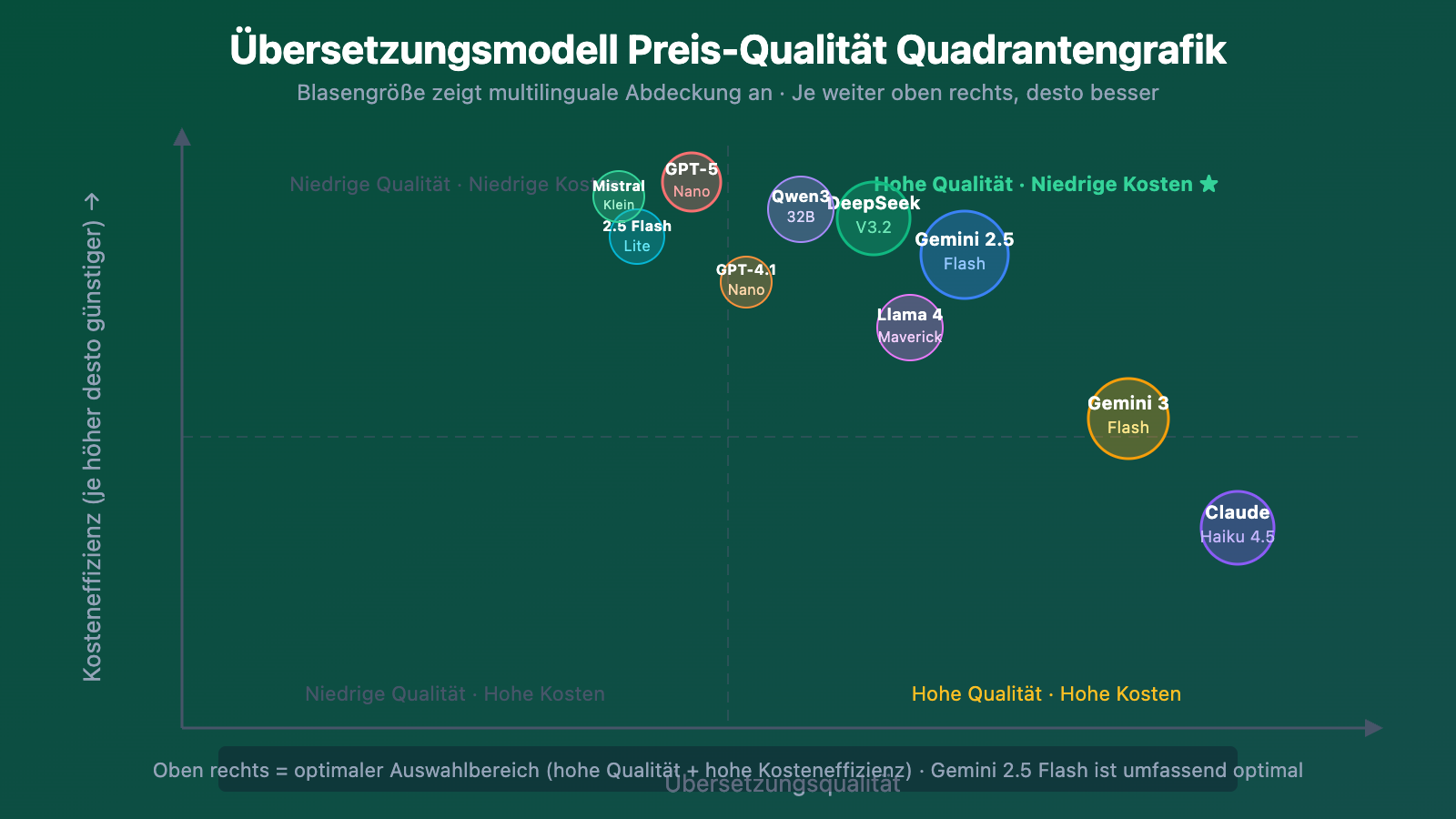
Gemini 3 Flash Preview ist die erste Wahl für Übersetzungsszenarien im März 2026. Mit einem Score von 71 auf dem Artificial Analysis Intelligence Index übertrifft es Gemini 2.5 Flash um 13 Punkte und behält gleichzeitig die charakteristische niedrige Latenz der Flash-Serie. Bei der Übersetzungsqualität kommt Gemini 3 Flash dem Pro-Level nahe – das Kontextfenster von einer Million Token ermöglicht hervorragende Ergebnisse bei der Verarbeitung langer Dokumente.
Gemini 2.5 Flash ist eine bewährte, ausgereifte Lösung. Google bestätigt offiziell, dass es sich für „häufige, latenzarme Übersetzungs- und Klassifizierungsaufgaben" eignet. Die Latenz ist niedriger als bei 2.0 Flash, und mit $0,15/$0,60 ist es die beste Wahl für Massenübersetzungen.
Claude Haiku 4.5 hat besondere Stärken bei der Übersetzungsqualität – Anthropic-Modelle setzen beim Umgang mit Sprachstil und Kontext Maßstäbe in der Branche. Haiku 4.5 übersetzt nicht nur präzise, sondern „liest sich wie von Menschen geschrieben". Mit $1,00/$5,00 ist die Preisgestaltung für ein leichtes Modell etwas höher, aber für Literaturübersetzungen und Marketing-Texte, wo Qualität entscheidend ist, lohnt sich dieser Aufpreis.
Zweite Liga: Extreme Kosteneffizienz
DeepSeek V3.2 bietet überraschende Übersetzungsqualität zum Preis von $0,14/$0,28. Die neu eingeführte DeepSeek Sparse Attention (DSA) erhält die Kontextkohärenz bei Langdokument-Übersetzungen. Mit Unterstützung für über 100 Sprachen und besonders starken Chinesisch-Fähigkeiten zeigen Community-Rückmeldungen, dass V3.2 „konsistent die Kohärenz der Zielsprache" bewahrt.
GPT-5 Nano ist OpenAIs günstigstes Modell mit nur $0,05 pro Million Input-Token. Das 200K-Kontextfenster ist größer als GPT-4o-mini mit 128K und bietet Vorteile bei längeren Dokumenten. Obwohl es das leichteste GPT-Modell ist, sind Übersetzung und Keyword-Generierung seine Stärken.
GPT-4.1 Nano – Obwohl OpenAI neue Projekte auf GPT-5 Nano ausrichtet, hat sich 4.1 Nano in Produktionsumgebungen bei Übersetzungsaufgaben bewährt. Wenn Sie vorhersehbare Ausgabequalität bevorzugen, bleibt 4.1 Nano eine zuverlässige Wahl.
Dritte Liga: Spezialisierte Szenarien
Gemini 2.5 Flash-Lite ist speziell für latenzempfindliche Aufgaben konzipiert – 1,5x schneller als 2.0 Flash. Mit $0,10/$0,40 gehört es zu den günstigsten Optionen. Ideal für Echtzeit-Übersetzungen und nutzergenerierte Inhalte, wo extrem niedrige Latenz erforderlich ist.
Qwen3 32B glänzt bei asiatischen Sprachen (Chinesisch, Japanisch, Koreanisch, Südostasien). Es übertrifft DeepSeek-V3 und Qwen2.5 in den MGSM- und MMMLU-Mehrsprachentests. 68% der großen asiatischen Unternehmen setzen auf die Qwen-Serie. Mit $0,08/$0,24 ist die Preisgestaltung hochkonkurrenzfähig.
Mistral Small 3.2 zeigt mit 24B Parametern hervorragende Leistung bei europäischen Sprachen. Mit $0,06/$0,18 gehört es zu den günstigsten kommerziellen APIs – ideal für Massenübersetzungen von Französisch, Deutsch, Spanisch und anderen europäischen Sprachen.
Llama 4 Maverick ist die beste Open-Source-Lösung für Mehrsprachigkeit – 17B aktive Parameter plus 128 Experten in der MoE-Architektur übertreffen GPT-4o bei Mehrsprachenverständnis. Geeignet für private Übersetzungsbereitstellungen mit hohen Datenschutzanforderungen.
Praktischer Tipp: Papierparameter sind nur Referenzen – die tatsächliche Übersetzungsqualität variiert stark je nach Sprachenpaar und Inhaltstyp. Wir empfehlen A/B-Tests über APIYI unter apiyi.com, um Übersetzungsergebnisse verschiedener Modelle mit identischen Texten zu vergleichen.
Kostenvergleich für Übersetzungsmodelle
Angenommen, ein typisches Übersetzungsszenario: 1.000 Artikel pro Monat, durchschnittlich 2.000 Zeichen pro Artikel (etwa 3.000 Token Input + 3.000 Token Output), insgesamt etwa 6 Millionen Token:
| Modell | Geschätzte Monatskosten | Relative Kosten | Geeignete Szenarien |
|---|---|---|---|
| GPT-5 Nano | $2,70 | 1x (Basis) | Massenübersetzung, kostensensitiv |
| Mistral Small 3.2 | $1,44 | 0,53x | Europäische Sprachen, Massenübersetzung |
| Qwen3 32B | $1,92 | 0,71x | Asiatische Sprachenübersetzung |
| Gemini 2.5 Flash-Lite | $3,00 | 1,11x | Echtzeit-Übersetzung |
| DeepSeek V3.2 | $2,52 | 0,93x | Allgemeine Übersetzung, Chinesisch-Fokus |
| Gemini 2.5 Flash | $4,50 | 1,67x | Hochwertige Allgemeinübersetzung |
| GPT-4.1 Nano | $3,00 | 1,11x | Stabilität im Vordergrund |
| Gemini 3 Flash Preview | $21,00 | 7,78x | Höchste Qualitätsübersetzung |
| Claude Haiku 4.5 | $36,00 | 13,33x | Literatur-/Marketing-Übersetzung |
| Llama 4 Maverick | Kosten für Eigenbereitstellung | Abhängig von Hardware | Private Bereitstellung |
🎯 Kostenoptimierungstipp: Die meisten Übersetzungsprojekte profitieren von einer gestaffelten Strategie – wichtige Inhalte mit Claude Haiku 4.5 oder Gemini 3 Flash für Qualität, Masseninhalt mit DeepSeek V3.2 oder GPT-5 Nano zur Kostenkontrolle. Mit APIYI unter apiyi.com können Sie flexibel zwischen Modellen wechseln, ohne mehrere API-Schlüssel zu verwalten.
Häufig gestellte Fragen zu Übersetzungsmodellen
F1: Warum wird nicht empfohlen, Flaggschiff-Modelle (Claude Opus, GPT-5) für Übersetzungen zu verwenden?
Übersetzungsaufgaben erfordern keine komplexen Reasoning-Fähigkeiten. Die Stärke von Flaggschiff-Modellen liegt in mehrstufigem Reasoning und komplexem Instruction-Following – aber der Kern von Übersetzung ist Sprachverständnis und -generierung, genau das, wofür leichtgewichtige Modelle optimiert sind. Opus für Übersetzungen zu nutzen kostet 10–50 mal mehr und ist deutlich langsamer, während die Verbesserung der Übersetzungsqualität minimal ausfällt.
F2: Gemini 3 Flash Preview ist noch eine Vorschauversion – kann ich sie in der Produktion einsetzen?
Die Preview-Version zeigt in Übersetzungsszenarien stabiles Verhalten. Übersetzungsaufgaben stellen geringere Anforderungen an die Determinismus des Modells als beispielsweise Programmieraufgaben, und die Übersetzungsqualität der Preview-Version übertrifft bereits Gemini 2.5 Pro. Wenn Sie maximale Stabilität anstreben, können Sie zunächst Gemini 2.5 Flash (bereits GA) verwenden und nach der offiziellen Veröffentlichung von Gemini 3 Flash migrieren.
F3: Wie vergleiche ich schnell die Übersetzungsergebnisse verschiedener Modelle?
Ich empfehle, eine API-Aggregationsplattform zu nutzen, die mehrere Modelle unterstützt:
- Registrieren Sie sich auf APIYI unter apiyi.com
- Erhalten Sie einen einheitlichen API-Schlüssel und kostenloses Kontingent
- Rufen Sie verschiedene Modelle mit demselben Text auf
- Vergleichen Sie die Übersetzungsergebnisse hinsichtlich Genauigkeit, Natürlichkeit und Terminologiekonsistenz
Zusammenfassung
Die wichtigsten Punkte bei der Auswahl von Großen Sprachmodellen für Übersetzungsszenarien im Jahr 2026:
- Die Gemini-Flash-Serie ist die optimale Lösung für Übersetzungen: Gemini 3 Flash Preview bietet die höchste Qualität, Gemini 2.5 Flash das beste Preis-Leistungs-Verhältnis und Flash-Lite die niedrigste Latenz – Google hat in diesem Bereich einen klaren Vorteil
- Claude Haiku 4.5 eignet sich für hochwertige Übersetzungen: Bei literarischen Übersetzungen, Marketing-Texten und anderen Szenarien, in denen es auf natürliche Lesbarkeit ankommt, ist Haikus Sprachstil-Kontrolle das Aufpreisen wert
- DeepSeek V3.2 und GPT-5 Nano sind die erste Wahl für kostensensitive Anwendungen: Bei großvolumigen Übersetzungsaufgaben ist das Preis-Leistungs-Verhältnis dieser beiden Modelle unschlagbar
Die Auswahl eines Übersetzungsmodells ist im Grunde ein Balanceakt zwischen Qualität, Geschwindigkeit und Kosten. Ich empfehle, über APIYI (apiyi.com) praktische Tests durchzuführen – die Plattform unterstützt einheitliche API-Aufrufe für alle genannten Modelle und hilft Ihnen, schnell die beste Lösung für Ihr Szenario zu finden.
📚 Referenzmaterialien
-
Artificial Analysis Modell-Rangliste: Umfassende Leistungs- und Preisvergleichsdaten für LLMs
- Link:
artificialanalysis.ai/leaderboards/models - Beschreibung: Bietet Intelligence Index, Latenz und Preisvergleiche für verschiedene Modelle
- Link:
-
WMT 2025 Maschinelle Übersetzungsbewertung: Der maßgeblichste Benchmark für maschinelle Übersetzung
- Link:
aclanthology.org/events/wmt-2025/ - Beschreibung: Systemische Bewertungsergebnisse für 30 Sprachpaare
- Link:
-
LLM API Preisvergleich: Echtzeit-aktualisierte LLM API-Preisdaten
- Link:
pricepertoken.com - Beschreibung: Preisdaten für über 300 Modelle mit Rechner-Funktionalität
- Link:
-
Google Gemini 3 Flash Ankündigung: Offizielle technische Details zu Gemini 3 Flash
- Link:
blog.google/products-and-platforms/products/gemini/gemini-3-flash/ - Beschreibung: Enthält Benchmark-Ergebnisse und Preisinformationen
- Link:
Autor: APIYI Technical Team
Technischer Austausch: Diskussionen sind in den Kommentaren willkommen. Weitere Ressourcen finden Sie im APIYI Dokumentationszentrum unter docs.apiyi.com