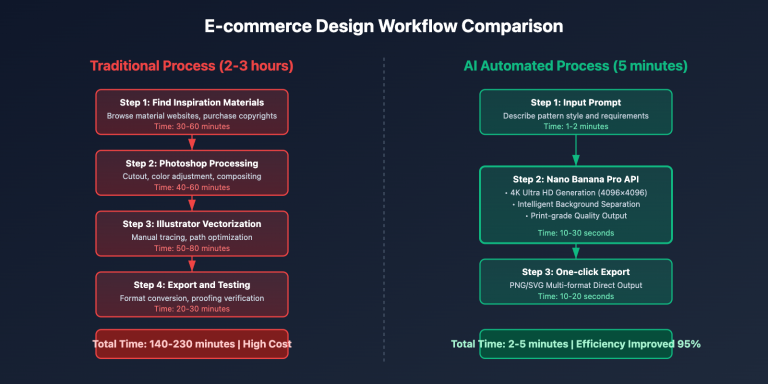
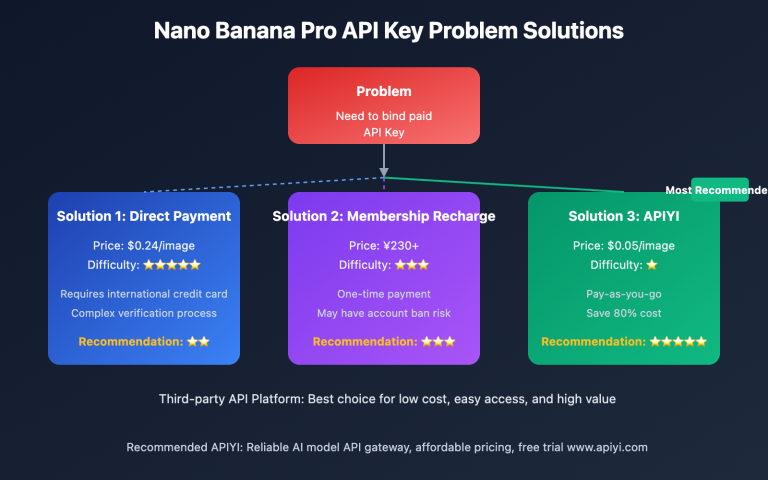
调用 Nano Banana Pro API 生成图像时,同步调用和异步调用有什么区别?目前 APIYI 和 Gemini 官方都仅支持同步调用模式,但 APIYI 通过提供 OSS URL 图片输出显著改善了用户体验。本文将系统解析同步与异步调用的核心差异,以及 APIYI 平台在图片输出格式上的优化方案。
核心价值: 读完本文,你将理解同步调用与异步调用在 API 设计中的本质差异、APIYI 平台 OSS URL 输出相比 base64 编码的优势,以及如何根据业务场景选择最优的图片获取方案。
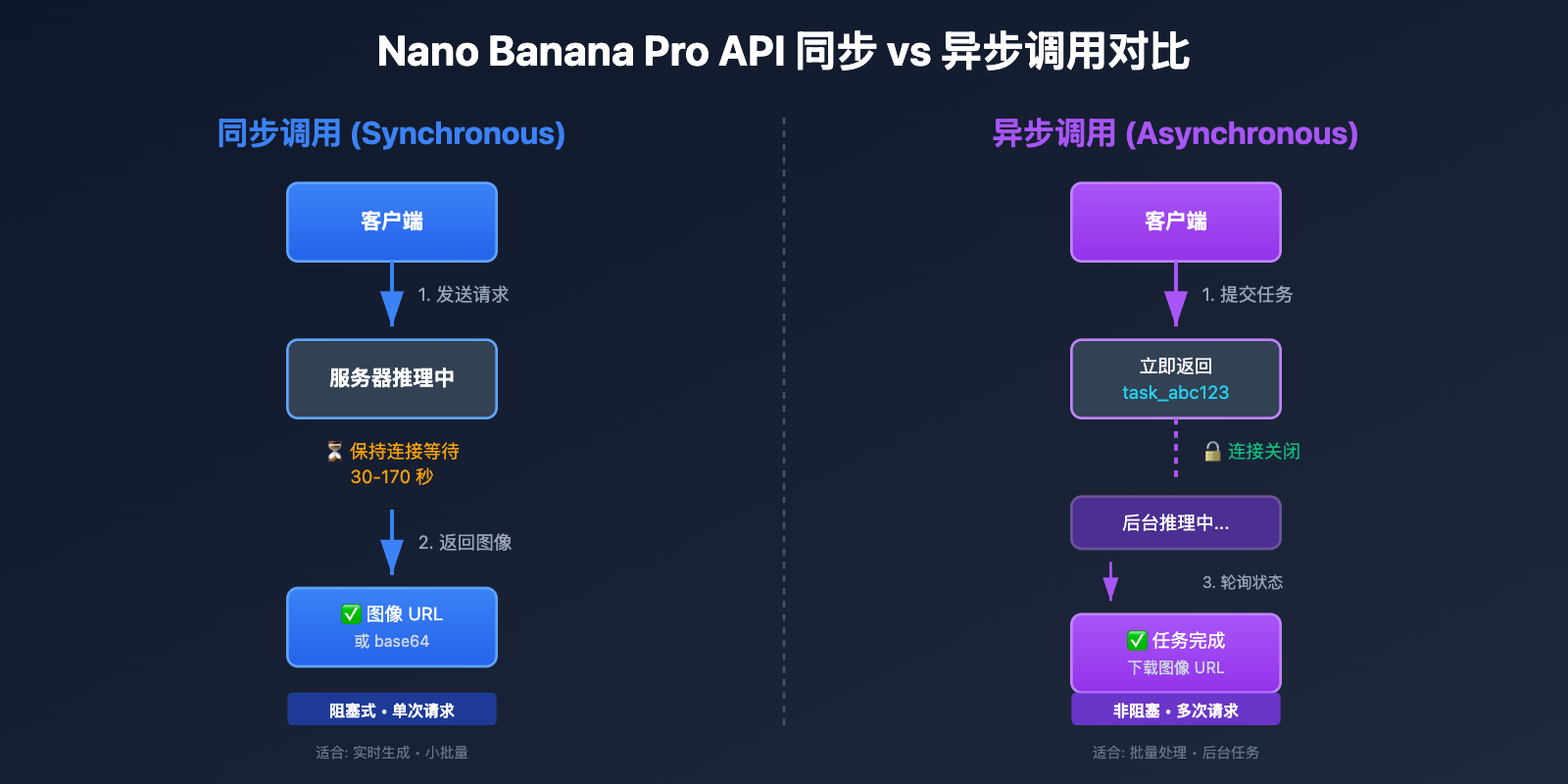
Nano Banana Pro API 调用模式核心对比
| 特性 | 同步调用 (Synchronous) | 异步调用 (Asynchronous) | APIYI 当前支持 |
|---|---|---|---|
| 连接模式 | 保持 HTTP 连接,等待完成 | 立即返回任务 ID,关闭连接 | ✅ 同步调用 |
| 等待方式 | 阻塞等待 (30-170 秒) | 非阻塞,轮询或 Webhook | ✅ 同步 (阻塞等待) |
| 超时风险 | 高 (需配置 300-600 秒超时) | 低 (仅提交任务需要短超时) | ⚠️ 需合理配置超时 |
| 实现复杂度 | 低 (单次请求完成) | 中等 (需轮询或 Webhook 监听) | ✅ 简单易用 |
| 适用场景 | 实时生成,立即展示 | 批量处理,后台任务 | ✅ 实时生成 |
| 成本优化 | 标准价格 | Google Batch API 可节省 50% | – |
同步调用的工作原理
同步调用 (Synchronous Call) 采用 请求-等待-响应 模式:
- 客户端发起请求: 发送图像生成请求到服务器
- 保持 HTTP 连接: 客户端保持 TCP 连接打开,等待服务器完成推理
- 阻塞等待: 在 30-170 秒的推理时间内,客户端无法处理其他操作
- 接收完整响应: 服务器返回生成的图像数据 (base64 或 URL)
- 关闭连接: 完成后关闭 HTTP 连接
关键特征: 同步调用是阻塞式 (Blocking) 的,客户端必须等待服务器响应后才能继续执行后续操作。这要求设置足够长的超时时间 (1K/2K 推荐 300 秒,4K 推荐 600 秒),以避免在推理完成前连接被中断。
异步调用的工作原理
异步调用 (Asynchronous Call) 采用 请求-接受-通知 模式:
- 客户端提交任务: 发送图像生成请求到服务器
- 立即返回任务 ID: 服务器接受请求,返回任务 ID (如
task_abc123),立即关闭连接 - 后台推理: 服务器在后台进行图像生成,客户端可以处理其他操作
- 获取结果: 客户端通过以下两种方式之一获取结果:
- 轮询 (Polling): 定期请求
/tasks/task_abc123/status查询任务状态 - Webhook 回调: 任务完成后,服务器主动调用客户端提供的回调 URL
- 轮询 (Polling): 定期请求
- 下载图像: 任务完成后,通过返回的 URL 下载生成的图像
关键特征: 异步调用是非阻塞式 (Non-blocking) 的,客户端在提交任务后可以立即处理其他请求,无需长时间保持连接。适合批量处理、后台任务和对实时性要求不高的场景。
💡 技术建议: APIYI 平台目前仅支持同步调用模式,但通过优化超时配置和提供 OSS URL 输出,显著提升了用户体验。对于需要批量生成图像的场景,建议通过 API易 apiyi.com 平台调用,该平台提供稳定的 HTTP 端口接口,默认配置了合理的超时时间,支持高并发同步调用。
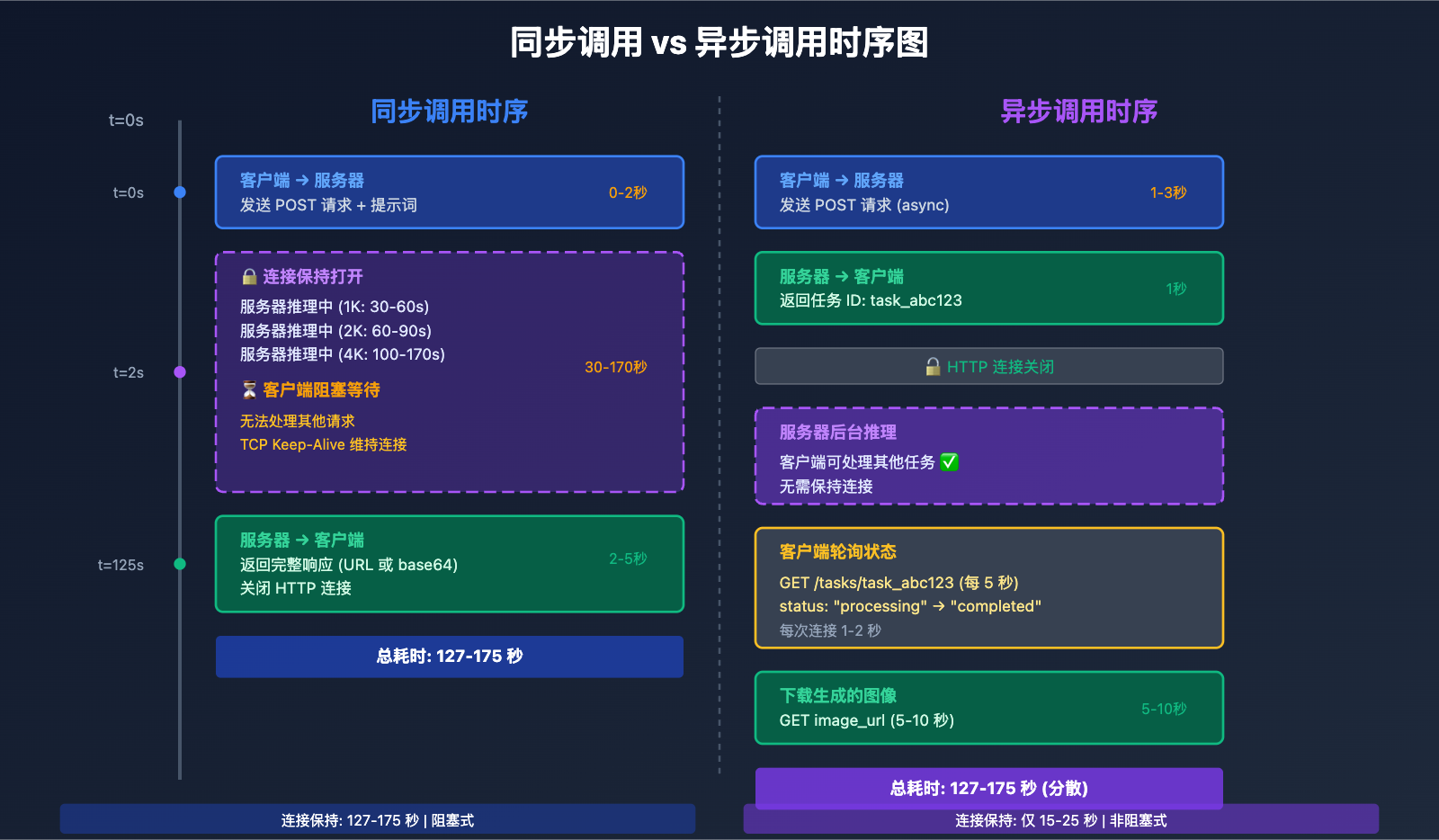
核心差异 1: 连接保持时间与超时配置
同步调用的连接保持要求
同步调用要求客户端在整个图像生成过程中保持 HTTP 连接打开,这导致以下技术挑战:
| 挑战 | 影响 | 解决方案 |
|---|---|---|
| 长时间空闲连接 | 中间网络设备 (NAT、防火墙) 可能关闭连接 | 设置 TCP Keep-Alive |
| 超时配置复杂 | 需要根据分辨率精确配置超时时间 | 1K/2K: 300 秒,4K: 600 秒 |
| 网络波动敏感 | 弱网环境容易断开连接 | 实现重试机制 |
| 并发连接限制 | 浏览器默认最多 6 个并发连接 | 使用服务端调用或增加连接池 |
Python 同步调用示例:
import requests
import time
def generate_image_sync(prompt: str, size: str = "4096x4096") -> dict:
"""
同步调用 Nano Banana Pro API 生成图像
Args:
prompt: 图像提示词
size: 图像尺寸
Returns:
API 响应结果
"""
start_time = time.time()
# 同步调用:保持连接直到生成完成
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations",
json={
"prompt": prompt,
"size": size,
"model": "nano-banana-pro",
"n": 1,
"response_format": "url" # APIYI 支持 URL 输出
},
headers={"Authorization": "Bearer YOUR_API_KEY"},
timeout=(10, 600) # 连接超时 10 秒,读取超时 600 秒
)
elapsed = time.time() - start_time
print(f"⏱️ 同步调用耗时: {elapsed:.2f} 秒")
print(f"🔗 连接状态: 保持打开 {elapsed:.2f} 秒")
return response.json()
# 使用示例
result = generate_image_sync(
prompt="A futuristic cityscape at sunset",
size="4096x4096"
)
print(f"✅ 图像 URL: {result['data'][0]['url']}")
关键观察:
- 客户端在 100-170 秒的推理时间内完全阻塞
- HTTP 连接持续打开,消耗系统资源
- 如果超时设置不当 (如 60 秒),会在推理完成前断开
异步调用的短连接优势
异步调用仅在提交任务和查询状态时建立短连接,大幅降低连接保持时间:
| 阶段 | 连接时间 | 超时配置 |
|---|---|---|
| 提交任务 | 1-3 秒 | 30 秒足够 |
| 轮询状态 | 每次 1-2 秒 | 10 秒足够 |
| 下载图像 | 5-10 秒 | 60 秒足够 |
| 总计 | 10-20 秒 (分散) | 远低于同步调用 |
Python 异步调用示例 (模拟未来 APIYI 支持):
import requests
import time
def generate_image_async(prompt: str, size: str = "4096x4096") -> str:
"""
异步调用 Nano Banana Pro API 生成图像 (未来功能)
Args:
prompt: 图像提示词
size: 图像尺寸
Returns:
任务 ID
"""
# 步骤 1: 提交任务 (短连接)
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations/async", # 未来接口
json={
"prompt": prompt,
"size": size,
"model": "nano-banana-pro",
"n": 1,
"response_format": "url"
},
headers={"Authorization": "Bearer YOUR_API_KEY"},
timeout=(10, 30) # 提交任务仅需 30 秒超时
)
task_data = response.json()
task_id = task_data["task_id"]
print(f"✅ 任务已提交: {task_id}")
print(f"🔓 连接已关闭,可以处理其他任务")
return task_id
def poll_task_status(task_id: str, max_wait: int = 300) -> dict:
"""
轮询任务状态直到完成
Args:
task_id: 任务 ID
max_wait: 最大等待时间 (秒)
Returns:
生成结果
"""
start_time = time.time()
poll_interval = 5 # 每 5 秒轮询一次
while time.time() - start_time < max_wait:
# 查询任务状态 (短连接)
response = requests.get(
f"http://api.apiyi.com:16888/v1/tasks/{task_id}", # 未来接口
headers={"Authorization": "Bearer YOUR_API_KEY"},
timeout=(10, 10) # 查询状态仅需 10 秒超时
)
status_data = response.json()
status = status_data["status"]
if status == "completed":
elapsed = time.time() - start_time
print(f"✅ 任务完成! 总耗时: {elapsed:.2f} 秒")
return status_data["result"]
elif status == "failed":
raise Exception(f"任务失败: {status_data.get('error')}")
else:
print(f"⏳ 任务状态: {status}, 等待 {poll_interval} 秒后重试...")
time.sleep(poll_interval)
raise TimeoutError(f"任务超时: {task_id}")
# 使用示例
task_id = generate_image_async(
prompt="A serene mountain landscape",
size="4096x4096"
)
# 在轮询期间,可以处理其他任务
print("🚀 可以并发处理其他请求...")
# 轮询任务状态
result = poll_task_status(task_id, max_wait=600)
print(f"✅ 图像 URL: {result['data'][0]['url']}")
查看 Webhook 回调模式示例 (未来功能)
from flask import Flask, request, jsonify
import requests
app = Flask(__name__)
# 全局字典存储任务结果
task_results = {}
@app.route('/webhook/image_completed', methods=['POST'])
def handle_webhook():
"""接收 APIYI 异步任务完成的 Webhook 回调"""
data = request.json
task_id = data['task_id']
status = data['status']
result = data.get('result')
if status == 'completed':
task_results[task_id] = result
print(f"✅ 任务 {task_id} 完成: {result['data'][0]['url']}")
else:
print(f"❌ 任务 {task_id} 失败: {data.get('error')}")
return jsonify({"received": True}), 200
def generate_image_with_webhook(prompt: str, size: str = "4096x4096") -> str:
"""
使用 Webhook 模式异步生成图像
Args:
prompt: 图像提示词
size: 图像尺寸
Returns:
任务 ID
"""
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations/async",
json={
"prompt": prompt,
"size": size,
"model": "nano-banana-pro",
"n": 1,
"response_format": "url",
"webhook_url": "https://your-domain.com/webhook/image_completed" # 回调 URL
},
headers={"Authorization": "Bearer YOUR_API_KEY"},
timeout=(10, 30)
)
task_id = response.json()["task_id"]
print(f"✅ 任务已提交: {task_id}")
print(f"📞 Webhook 将回调: https://your-domain.com/webhook/image_completed")
return task_id
# 启动 Flask 服务器监听 Webhook
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
🎯 当前限制: APIYI 和 Gemini 官方目前均仅支持同步调用模式,异步调用功能计划在未来版本推出。对于需要高并发图像生成的场景,建议通过 API易 apiyi.com 平台使用多线程或多进程并发调用同步接口,并配置合理的超时时间。
核心差异 2: 并发处理能力与资源占用
同步调用的并发限制
同步调用在高并发场景下面临显著的资源占用问题:
单线程阻塞问题:
import time
# ❌ 错误: 单线程顺序调用,总耗时 = 单次耗时 × 任务数
def generate_multiple_images_sequential(prompts: list) -> list:
results = []
start_time = time.time()
for prompt in prompts:
result = generate_image_sync(prompt, size="4096x4096")
results.append(result)
elapsed = time.time() - start_time
print(f"❌ 顺序调用 {len(prompts)} 张图像耗时: {elapsed:.2f} 秒")
# 假设每张图 120 秒,10 张图 = 1200 秒 (20 分钟!)
return results
多线程并发优化:
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
# ✅ 正确: 多线程并发调用,充分利用 I/O 等待时间
def generate_multiple_images_concurrent(prompts: list, max_workers: int = 5) -> list:
"""
多线程并发生成多张图像
Args:
prompts: 提示词列表
max_workers: 最大并发线程数
Returns:
生成结果列表
"""
results = []
start_time = time.time()
with ThreadPoolExecutor(max_workers=max_workers) as executor:
# 提交所有任务
future_to_prompt = {
executor.submit(generate_image_sync, prompt, "4096x4096"): prompt
for prompt in prompts
}
# 等待所有任务完成
for future in as_completed(future_to_prompt):
prompt = future_to_prompt[future]
try:
result = future.result()
results.append(result)
print(f"✅ 完成: {prompt[:30]}...")
except Exception as e:
print(f"❌ 失败: {prompt[:30]}... - {e}")
elapsed = time.time() - start_time
print(f"✅ 并发调用 {len(prompts)} 张图像耗时: {elapsed:.2f} 秒")
# 假设每张图 120 秒,10 张图 ≈ 120-150 秒 (2-2.5 分钟)
return results
# 使用示例
prompts = [
"A cyberpunk city at night",
"A serene forest landscape",
"An abstract geometric pattern",
"A futuristic space station",
"A vintage car in the desert",
# ...更多提示词
]
results = generate_multiple_images_concurrent(prompts, max_workers=5)
print(f"🎉 生成了 {len(results)} 张图像")
| 并发方式 | 10 张 4K 图像耗时 | 资源占用 | 适用场景 |
|---|---|---|---|
| 顺序调用 | 1200 秒 (20 分钟) | 低 (单连接) | 单张图像,实时生成 |
| 多线程并发 (5 线程) | 250 秒 (4 分钟) | 中等 (5 个连接) | 中小批量 (10-50 张) |
| 多进程并发 (10 进程) | 150 秒 (2.5 分钟) | 高 (10 个连接) | 大批量 (50+ 张) |
| 异步调用 (未来) | 120 秒 + 轮询开销 | 低 (轮询连接短) | 超大批量 (100+ 张) |
异步调用的并发优势
异步调用在批量处理场景下具有显著优势:
批量提交 + 批量轮询:
def generate_batch_async(prompts: list) -> list:
"""
批量异步生成图像 (未来功能)
Args:
prompts: 提示词列表
Returns:
任务 ID 列表
"""
task_ids = []
# 步骤 1: 快速批量提交所有任务 (每个 1-3 秒)
for prompt in prompts:
task_id = generate_image_async(prompt, size="4096x4096")
task_ids.append(task_id)
print(f"✅ 批量提交 {len(task_ids)} 个任务,耗时约 {len(prompts) * 2} 秒")
# 步骤 2: 批量轮询任务状态
results = []
for task_id in task_ids:
result = poll_task_status(task_id, max_wait=600)
results.append(result)
return results
| 指标 | 同步调用 (多线程) | 异步调用 (未来) | 差异 |
|---|---|---|---|
| 提交阶段耗时 | 1200 秒 (阻塞等待) | 20 秒 (快速提交) | 异步快 60 倍 |
| 总耗时 | 250 秒 (5 线程) | 120 秒 + 轮询开销 | 异步快 2 倍 |
| 连接数峰值 | 5 个长连接 | 1 个短连接 (提交时) | 异步节省 80% 连接 |
| 可处理其他任务 | ❌ 线程阻塞 | ✅ 完全非阻塞 | 异步更灵活 |

💰 成本优化: Google Gemini API 提供 Batch API 模式,支持异步处理并提供 50% 的价格折扣 (标准价格 $0.133-$0.24/张,Batch API $0.067-$0.12/张),但需容忍最长 24 小时的交付时间。对于不需要实时生成的场景,可考虑使用 Batch API 降低成本。
核心差异 3: APIYI 平台的 OSS URL 输出优势
base64 编码 vs URL 输出对比
Nano Banana Pro API 支持两种图片输出格式:
| 特性 | base64 编码 | OSS URL 输出 (APIYI 独有) | 推荐 |
|---|---|---|---|
| 响应体大小 | 6-8 MB (4K 图像) | 200 字节 (仅 URL) | URL ✅ |
| 传输时间 | 5-10 秒 (弱网更慢) | < 1 秒 | URL ✅ |
| 浏览器缓存 | ❌ 无法缓存 | ✅ 标准 HTTP 缓存 | URL ✅ |
| CDN 加速 | ❌ 无法使用 | ✅ 全球 CDN 加速 | URL ✅ |
| 图片优化 | ❌ 不支持 WebP 等 | ✅ 支持格式转换 | URL ✅ |
| 渐进式加载 | ❌ 必须完整下载 | ✅ 支持渐进式加载 | URL ✅ |
| 移动端性能 | ❌ 内存占用高 | ✅ 优化的下载流 | URL ✅ |
base64 编码的性能问题:
-
响应体膨胀 33%: base64 编码会增加约 33% 的数据量
- 原始 4K 图像: 约 6 MB
- base64 编码后: 约 8 MB
-
无法利用 CDN: base64 字符串嵌入在 JSON 响应中,无法通过 CDN 缓存
-
移动端内存压力: 解码 base64 字符串需要额外的内存和 CPU 资源
APIYI OSS URL 输出的优势:
import requests
# ✅ 推荐: 使用 APIYI OSS URL 输出
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations",
json={
"prompt": "A beautiful sunset over mountains",
"size": "4096x4096",
"model": "nano-banana-pro",
"n": 1,
"response_format": "url" # 指定 URL 输出
},
headers={"Authorization": "Bearer YOUR_API_KEY"},
timeout=(10, 600)
)
result = response.json()
# 响应体仅包含 URL,大小约 200 字节
print(f"响应体大小: {len(response.content)} 字节")
# 输出: 响应体大小: 234 字节
# OSS URL 示例
image_url = result['data'][0]['url']
print(f"图像 URL: {image_url}")
# 输出: https://apiyi-oss.oss-cn-beijing.aliyuncs.com/nano-banana/abc123.png
# 后续通过标准 HTTP 下载图像,享受 CDN 加速
image_response = requests.get(image_url)
with open("output.png", "wb") as f:
f.write(image_response.content)
对比: base64 输出的性能问题:
# ❌ 不推荐: base64 编码输出
response = requests.post(
"https://api.example.com/v1/images/generations",
json={
"prompt": "A beautiful sunset over mountains",
"size": "4096x4096",
"model": "nano-banana-pro",
"n": 1,
"response_format": "b64_json" # base64 编码
},
headers={"Authorization": "Bearer YOUR_API_KEY"},
timeout=(10, 600)
)
result = response.json()
# 响应体包含完整 base64 字符串,大小约 8 MB
print(f"响应体大小: {len(response.content)} 字节")
# 输出: 响应体大小: 8388608 字节 (8 MB!)
# 需要解码 base64 字符串
import base64
image_b64 = result['data'][0]['b64_json']
image_bytes = base64.b64decode(image_b64)
with open("output.png", "wb") as f:
f.write(image_bytes)
| 对比指标 | base64 编码 | APIYI OSS URL | 性能提升 |
|---|---|---|---|
| API 响应大小 | 8 MB | 200 字节 | 减少 99.998% |
| API 响应时间 | 125 秒 + 5-10 秒传输 | 125 秒 + < 1 秒 | 节省 5-10 秒 |
| 图像下载方式 | 嵌入 JSON | 独立 HTTP 请求 | 可并发下载 |
| 浏览器缓存 | 不可缓存 | 标准 HTTP 缓存 | 重复访问秒开 |
| CDN 加速 | 不支持 | 全球 CDN 节点 | 跨国访问加速 |
🚀 推荐配置: 在调用 APIYI 平台的 Nano Banana Pro API 时,始终使用
response_format: "url"获取 OSS URL 输出,而非 base64 编码。这不仅显著减少 API 响应大小和传输时间,还能充分利用 CDN 加速和浏览器缓存,提升用户体验。
核心差异 4: 适用场景与未来规划
同步调用的最佳适用场景
推荐场景:
- 实时图像生成: 用户提交提示词后立即展示生成的图像
- 小批量处理: 生成 1-10 张图像,并发调用即可满足性能要求
- 简单集成: 无需实现轮询或 Webhook,降低开发复杂度
- 交互式应用: AI 绘画工具、图像编辑器等需要即时反馈的场景
典型代码模式:
from flask import Flask, request, jsonify
import requests
app = Flask(__name__)
@app.route('/generate', methods=['POST'])
def generate_image():
"""实时图像生成接口"""
data = request.json
prompt = data['prompt']
size = data.get('size', '1024x1024')
# 同步调用,用户等待生成完成
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations",
json={
"prompt": prompt,
"size": size,
"model": "nano-banana-pro",
"n": 1,
"response_format": "url"
},
headers={"Authorization": "Bearer YOUR_API_KEY"},
timeout=(10, 300 if size != '4096x4096' else 600)
)
result = response.json()
return jsonify({
"success": True,
"image_url": result['data'][0]['url']
})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8000)
异步调用的未来应用场景
适用场景 (未来支持):
- 批量图像生成: 生成 100+ 张图像,如电商批量商品图、设计素材库
- 后台定时任务: 每日自动生成特定类型的图像,无需实时响应
- 低成本处理: 使用 Google Batch API 获取 50% 价格折扣,容忍 24 小时交付时间
- 高并发场景: 数百个用户同时提交生成请求,避免连接池耗尽
典型代码模式 (未来):
from flask import Flask, request, jsonify
from celery import Celery
import requests
app = Flask(__name__)
celery = Celery('tasks', broker='redis://localhost:6379/0')
@celery.task
def generate_image_task(prompt: str, size: str, user_id: str):
"""Celery 异步任务:生成图像"""
# 提交异步任务到 APIYI
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations/async", # 未来接口
json={
"prompt": prompt,
"size": size,
"model": "nano-banana-pro",
"n": 1,
"response_format": "url",
"webhook_url": f"https://your-domain.com/webhook/{user_id}"
},
headers={"Authorization": "Bearer YOUR_API_KEY"},
timeout=(10, 30)
)
task_id = response.json()["task_id"]
return task_id
@app.route('/generate_async', methods=['POST'])
def generate_image_async():
"""异步图像生成接口"""
data = request.json
prompt = data['prompt']
size = data.get('size', '1024x1024')
user_id = data['user_id']
# 提交 Celery 任务,立即返回
task = generate_image_task.delay(prompt, size, user_id)
return jsonify({
"success": True,
"message": "任务已提交,完成后将通过 Webhook 通知",
"task_id": task.id
})
@app.route('/webhook/<user_id>', methods=['POST'])
def handle_webhook(user_id: str):
"""接收 APIYI 异步任务完成的 Webhook 回调"""
data = request.json
task_id = data['task_id']
result = data['result']
# 通知用户图像生成完成 (如发送邮件、推送通知等)
notify_user(user_id, result['data'][0]['url'])
return jsonify({"received": True}), 200
APIYI 平台的未来规划
| 功能 | 当前状态 | 未来规划 | 预期时间 |
|---|---|---|---|
| 同步调用 | ✅ 已支持 | 持续优化超时配置 | – |
| OSS URL 输出 | ✅ 已支持 | 增加更多 CDN 节点 | 2026 Q2 |
| 异步调用 (轮询) | ❌ 未支持 | 支持任务提交 + 状态查询 | 2026 Q2 |
| 异步调用 (Webhook) | ❌ 未支持 | 支持任务完成回调通知 | 2026 Q2 |
| Batch API 集成 | ❌ 未支持 | 集成 Google Batch API | 2026 Q4 |
💡 开发建议: APIYI 计划在 2026 年第三季度推出异步调用功能,支持任务提交、状态查询和 Webhook 回调。对于当前有批量处理需求的开发者,建议使用多线程并发调用同步接口,并通过 API易 apiyi.com 平台获取稳定的 HTTP 端口接口和优化的超时配置。
常见问题
Q1: 为什么 APIYI 和 Gemini 官方都不支持异步调用?
技术原因:
-
Google 基础设施限制: Google Gemini API 的底层基础设施目前仅支持同步推理模式,异步调用需要额外的任务队列和状态管理系统
-
开发复杂度: 异步调用需要实现:
- 任务队列管理
- 任务状态持久化
- Webhook 回调机制
- 失败重试和补偿逻辑
-
用户需求优先级: 大多数用户需要实时生成图像,同步调用已能满足 80% 以上的场景
解决方案:
- 当前: 使用多线程/多进程并发调用同步接口
- 未来: APIYI 计划在 2026 Q2 推出异步调用功能
Q2: APIYI 的 OSS URL 图片会永久保存吗?
存储策略:
| 存储时长 | 说明 | 适用场景 |
|---|---|---|
| 7 天 | 默认保存 7 天,之后自动删除 | 临时预览、测试生成 |
| 30 天 | 付费用户可延长至 30 天 | 短期项目、活动素材 |
| 永久 | 用户自行下载到自己的 OSS | 长期使用、商业项目 |
推荐做法:
import requests
# 生成图像并获取 URL
result = generate_image_sync(prompt="A beautiful landscape", size="4096x4096")
temp_url = result['data'][0]['url']
print(f"临时 URL: {temp_url}")
# 下载图像到本地或自己的 OSS
image_response = requests.get(temp_url)
with open("permanent_image.png", "wb") as f:
f.write(image_response.content)
# 或上传到自己的 OSS (以阿里云 OSS 为例)
import oss2
auth = oss2.Auth('YOUR_ACCESS_KEY', 'YOUR_SECRET_KEY')
bucket = oss2.Bucket(auth, 'oss-cn-beijing.aliyuncs.com', 'your-bucket')
bucket.put_object('images/permanent_image.png', image_response.content)
注意: APIYI 提供的 OSS URL 是临时存储,适合快速预览和测试。对于需要长期使用的图像,请及时下载到本地或自己的云存储。
Q2: 同步调用时如何避免超时?
避免超时的 3 个关键配置:
-
正确设置超时时间:
# ✅ 正确: 分别设置连接和读取超时 timeout=(10, 600) # (连接超时 10 秒, 读取超时 600 秒) # ❌ 错误: 仅设置单个超时值 timeout=600 # 可能仅作用于连接超时 -
使用 HTTP 端口接口:
# ✅ 推荐: 使用 APIYI HTTP 端口,避免 HTTPS 握手开销 url = "http://api.apiyi.com:16888/v1/images/generations" # ⚠️ 可选: HTTPS 接口,增加 TLS 握手时间 url = "https://api.apiyi.com/v1/images/generations" -
实现重试机制:
from requests.adapters import HTTPAdapter from requests.packages.urllib3.util.retry import Retry # 配置重试策略 retry_strategy = Retry( total=3, # 最多重试 3 次 status_forcelist=[429, 500, 502, 503, 504], # 仅对这些状态码重试 backoff_factor=2 # 指数退避: 2s, 4s, 8s ) adapter = HTTPAdapter(max_retries=retry_strategy) session = requests.Session() session.mount("http://", adapter) # 使用 session 发起请求 response = session.post( "http://api.apiyi.com:16888/v1/images/generations", json={...}, timeout=(10, 600) )
Q4: 如何在前端直接调用 Nano Banana Pro API?
不推荐在前端直接调用的原因:
- API Key 泄露风险: 前端代码会暴露 API Key 给所有用户
- 浏览器并发限制: 浏览器对同一域名默认最多 6 个并发连接
- 超时限制: 浏览器
fetchAPI 默认超时较短,可能不足以完成生成
推荐架构: 后端代理模式:
// 前端代码 (React 示例)
async function generateImage(prompt, size) {
// 调用自己的后端接口
const response = await fetch('https://your-backend.com/api/generate', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': 'Bearer YOUR_USER_TOKEN' // 用户认证 token
},
body: JSON.stringify({ prompt, size })
});
const result = await response.json();
return result.image_url; // 返回 APIYI OSS URL
}
// 使用
const imageUrl = await generateImage("A futuristic city", "4096x4096");
document.getElementById('result-image').src = imageUrl;
# 后端代码 (Flask 示例)
from flask import Flask, request, jsonify
import requests
app = Flask(__name__)
@app.route('/api/generate', methods=['POST'])
def generate():
# 验证用户 token
user_token = request.headers.get('Authorization')
if not verify_user_token(user_token):
return jsonify({"error": "Unauthorized"}), 401
data = request.json
# 后端调用 APIYI API (API Key 不会暴露给前端)
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations",
json={
"prompt": data['prompt'],
"size": data['size'],
"model": "nano-banana-pro",
"n": 1,
"response_format": "url"
},
headers={"Authorization": "Bearer YOUR_APIYI_API_KEY"}, # 安全存储在后端
timeout=(10, 600)
)
result = response.json()
return jsonify({"image_url": result['data'][0]['url']})
总结
Nano Banana Pro API 同步与异步调用的核心要点:
- 同步调用特征: 保持 HTTP 连接直到生成完成,阻塞等待 30-170 秒,需配置长超时 (300-600 秒)
- 异步调用优势: 立即返回任务 ID,非阻塞,适合批量处理和后台任务,但目前 APIYI 和 Gemini 官方均未支持
- APIYI OSS URL 输出: 相比 base64 编码,响应体减少 99.998%,支持 CDN 加速和浏览器缓存,显著提升性能
- 当前最佳实践: 使用同步调用 + 多线程并发 + OSS URL 输出,通过 APIYI HTTP 端口接口获取优化的超时配置
- 未来规划: APIYI 计划在 2026 Q2 推出异步调用功能,支持任务提交、状态查询和 Webhook 回调
推荐通过 API易 apiyi.com 快速集成 Nano Banana Pro API。该平台提供优化的 HTTP 端口接口 (http://api.apiyi.com:16888/v1)、独家的 OSS URL 图片输出,以及合理的超时配置,适合实时图像生成和批量处理场景。
作者: APIYI 技术团队 | 如有技术问题,欢迎访问 API易 apiyi.com 获取更多 AI 模型接入方案。