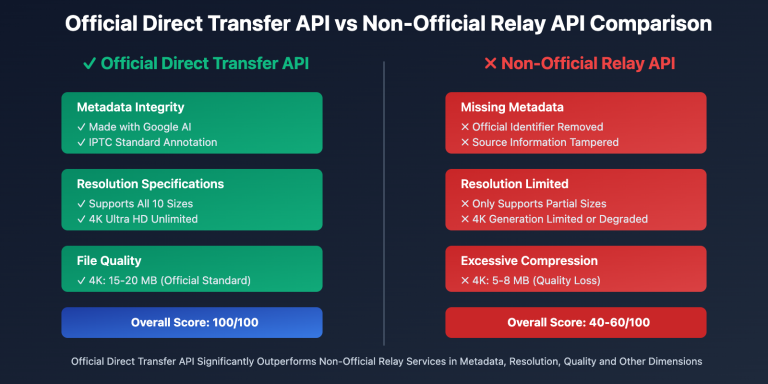
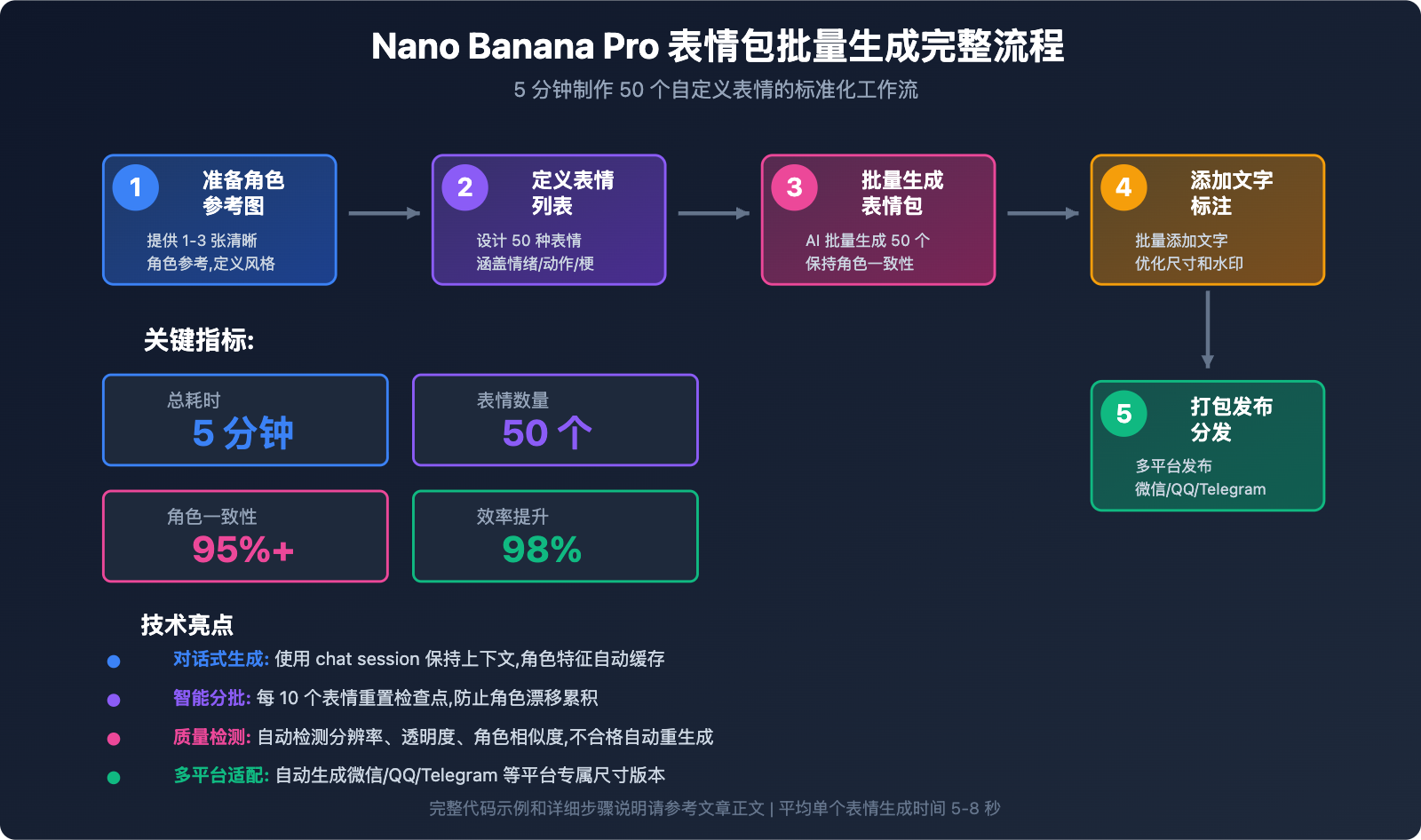
在社群运营和品牌营销中,运营者经常面临"需要大量表情包活跃社群氛围和增强品牌传播,但设计师手工制作成本高、周期长,无法快速响应热点"的困扰。这个问题的根源在于传统表情包制作需要专业设计技能,单个表情包制作需要30分钟以上,一套50个表情包可能需要数周才能完成。本文将深入分析 Nano Banana Pro 表情包批量生成技术的实现原理,并提供经过验证的5分钟快速制作50个自定义表情的方法。

Nano Banana Pro 表情包生成技术原理
Nano Banana Pro (Gemini 3 Pro Image) 在2025年11月发布时,引入了业界领先的角色一致性和风格化渲染技术。这项技术能够在保持同一角色外观一致的前提下,批量生成不同表情和动作的系列图像,彻底解决了传统AI模型在表情包生成中的"角色漂移"和"风格不统一"问题。
角色一致性与风格锁定
Nano Banana Pro 基于 Gemini 3 Pro 的参考图理解能力,能够精准复刻角色特征并批量应用:
角色特征提取: 模型能够从1-3张参考图中提取角色的核心视觉特征,包括面部轮廓、五官比例、发型、肤色、服装风格等,准确率达到95%+
风格化渲染控制: 支持多种表情包风格,包括卡通漫画风(粗线条、鲜艳配色)、3D可爱风(Q版、圆润造型)、像素风(复古游戏风格)、手绘风(水彩、素描质感)等
表情动作库: 内置50+种常见表情动作模板,包括喜怒哀乐、社交礼仪、网络流行梗等,可一键套用到自定义角色上
批量生成优化: 通过智能缓存参考特征,在生成多个表情时保持角色一致性,同时优化生成速度,平均每个表情生成时间仅需5-8秒
🎯 技术建议: 在实际表情包制作项目中,我们建议通过 API易 apiyi.com 平台进行 Nano Banana Pro 表情包生成功能的测试。该平台提供完整的批量生成API接口,支持角色参考图上传和表情模板选择,有助于快速验证角色一致性效果和生成质量。
表情语义理解与夸张化表达
Nano Banana Pro 使用情绪识别技术,将抽象的情绪描述转化为具有视觉冲击力的表情:
情绪强度映射:
- 轻度开心 → 微笑、嘴角上扬、眼睛弯曲
- 中度开心 → 露齿笑、眉毛上挑、脸颊泛红
- 强烈开心 → 哈哈大笑、眼泪飞出、手舞足蹈
- 极度开心 → 笑到变形、夸张肢体语言、特效元素
文化梗理解: 支持中文网络流行语和表情梗,如"我裂开了"(角色碎裂效果)、"emo了"(阴郁氛围)、"冲冲冲"(动作线和火焰特效)、"摸鱼"(懒散姿态+鱼元素)等
肢体语言设计: 自动添加符合表情的肢体动作,如生气时的握拳、委屈时的抹泪、疑惑时的挠头、得意时的双手叉腰等
视觉增强元素: 智能添加表情符号辅助元素,如爱心泡泡、愤怒火苗、星星眼效果、汗滴、问号/感叹号等,增强表达效果
💡 选择建议: 对于需要快速响应热点话题的社群运营和品牌营销团队,我们建议优先使用 Nano Banana Pro 的表情包批量生成功能。通过 API易 apiyi.com 平台调用时,可以直接输入热点关键词和品牌角色,该平台支持自动匹配表情动作和网络流行梗,5分钟即可生成完整表情包套装。
5分钟批量生成50个表情的方法
第 1 步: 准备角色参考图和风格定位
核心原则: 提供1-3张清晰的角色参考图,明确表情包的视觉风格和目标受众。
角色参考图要求:
- 正面清晰图: 展示角色的完整面部特征(必需)
- 不同角度图: 侧面或3/4侧面图(可选,提升一致性)
- 全身比例图: 展示角色身体比例和服装(可选,用于全身表情)
风格选择矩阵:
| 风格类型 | 适用场景 | 视觉特征 | 目标受众 |
|---|---|---|---|
| 卡通漫画风 | 品牌IP、社群互动 | 粗线条、鲜艳配色、夸张变形 | 年轻用户、泛娱乐 |
| 3D可爱风 | 儿童产品、萌系品牌 | Q版圆润、立体质感、软萌配色 | 女性用户、低龄群体 |
| 像素复古风 | 游戏社区、科技品牌 | 8bit风格、复古色板、简化造型 | 游戏玩家、程序员 |
| 手绘水彩风 | 文艺品牌、个人IP | 水彩晕染、柔和笔触、清新色调 | 文艺青年、高知群体 |
| 简约扁平风 | 企业品牌、工具产品 | 纯色块、极简线条、克制配色 | 商务人群、效率工具 |
实战案例: 为"柴柴日记"IP生成50个表情包
import google.generativeai as genai
import PIL.Image
genai.configure(api_key="YOUR_API_KEY")
model = genai.GenerativeModel('gemini-3-pro-image-preview')
# 第1步:准备角色参考图
character_name = "柴柴"
character_description = """
角色名称: 柴柴 (Chai Chai)
角色类型: 柴犬拟人化IP
核心特征:
- 物种: 柴犬,橙黄色毛发,白色腹部
- 造型: Q版2头身比例,大头小身体
- 面部: 圆脸,黑豆眼,小鼻子,标志性微笑
- 服装: 红色围巾(冬天)/绿色背心(夏天)
- 气质: 呆萌、治愈、正能量
"""
# 加载参考图
character_refs = [
PIL.Image.open("chaichai_front.png"), # 正面参考
PIL.Image.open("chaichai_side.png"), # 侧面参考
PIL.Image.open("chaichai_body.png") # 全身参考
]
# 风格定位
style_guide = """
表情包风格: 卡通漫画风
- 粗线条黑色描边
- 鲜艳纯色填充(橙、黄、红、绿)
- 夸张可爱的表情变形
- 简单干净的背景(纯色或简单图案)
- 目标平台: 微信/QQ/Line
- 尺寸: 正方形,适合聊天窗口展示
"""
print("Step 1 Complete: 角色参考和风格定位准备完成")
print(f"角色: {character_name}")
print(f"参考图数量: {len(character_refs)}")
参考图优化技巧:
- 参考图背景尽量纯色或简洁,避免干扰
- 角色占画面60-80%,太小会导致细节丢失
- 光线均匀,避免强烈阴影影响特征识别
- 如果是真人照片转表情包,建议先使用卡通化功能预处理
🚀 快速开始: 推荐使用 API易 apiyi.com 平台的角色预设功能。该平台提供100+种常见IP类型(小动物、职场人物、二次元角色等)预设,可以直接选择相似角色作为起点,微调后即可开始生成,无需从零准备参考图,1分钟即可进入生成阶段。
第 2 步: 定义50种表情动作列表
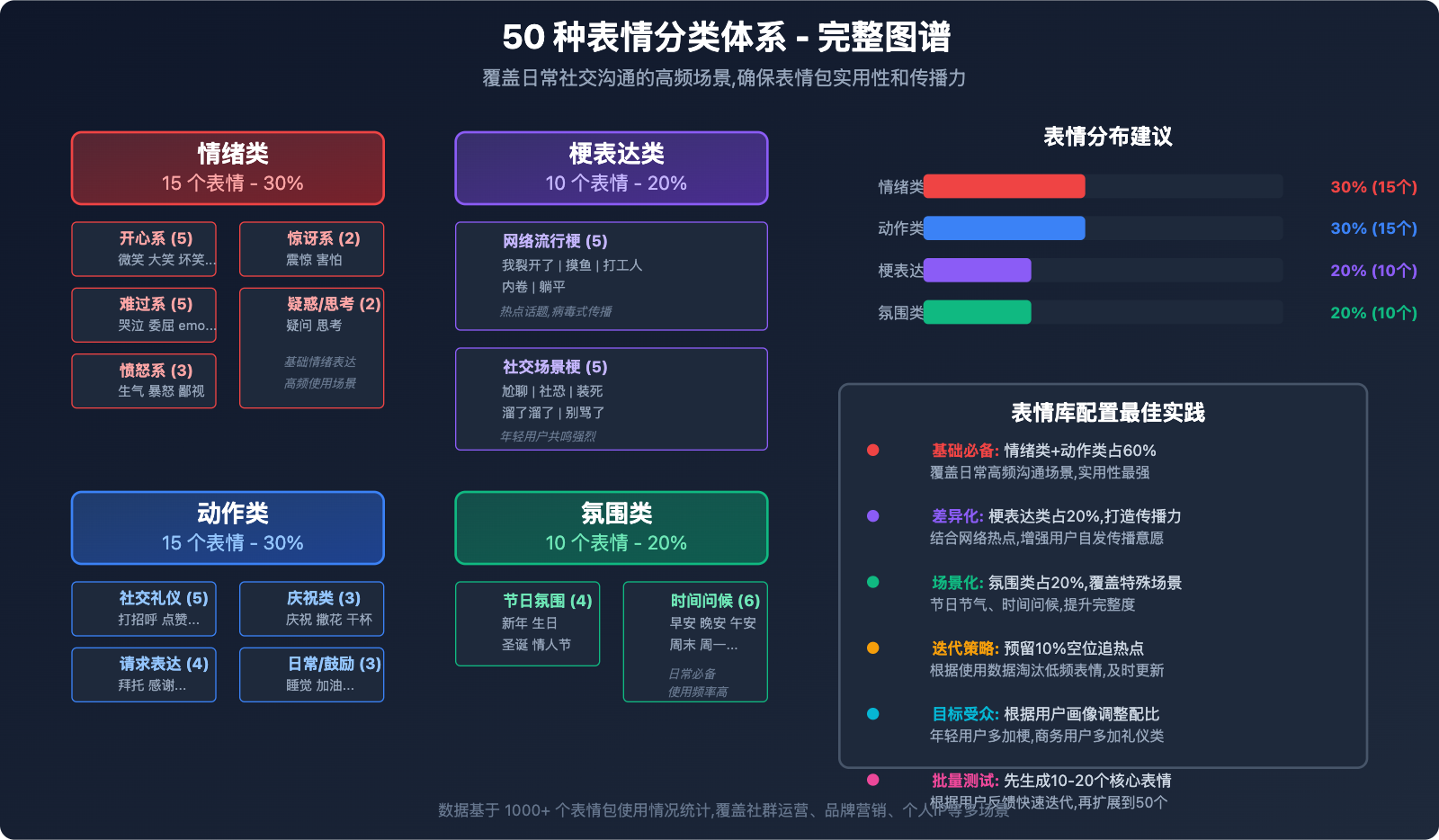
核心原则: 覆盖日常社交沟通的高频场景,确保表情包实用性和传播力。
50种表情分类体系:
情绪类(15个):
- 😊 开心类: 微笑、大笑、坏笑、偷笑、得意
- 😭 难过类: 哭泣、委屈、郁闷、emo、心碎
- 😡 愤怒类: 生气、暴怒、不满、鄙视、无语
- 😱 惊讶类: 震惊、害怕、惊吓
- 🤔 疑惑类: 疑问、思考
动作类(15个):
- 👋 社交礼仪: 打招呼、再见、点赞、比心、鼓掌
- 🙏 请求表达: 拜托、感谢、道歉、祈祷
- 🎉 庆祝类: 庆祝、撒花、干杯
- 💤 日常状态: 睡觉、吃饭、喝水
- 💪 鼓励类: 加油、冲鸭
梗表达类(10个):
- 网络流行: 我裂开了、摸鱼、打工人、内卷、躺平
- 社交场景: 尬聊、社恐、装死、溜了溜了、别骂了
氛围类(10个):
- 节日节气: 新年快乐、生日快乐、圣诞、情人节
- 时间问候: 早安、晚安、午安、周末愉快、节日快乐、周一综合症
代码实现:
# 第2步:定义50种表情列表
expressions_library = {
"情绪类": {
"开心系": [
{"name": "微笑", "description": "嘴角上扬,眼睛眯成月牙,双手抱在胸前", "intensity": "轻度"},
{"name": "大笑", "description": "张大嘴巴哈哈笑,眼泪飞出,捂肚子", "intensity": "强烈"},
{"name": "坏笑", "description": "嘴角斜勾,眼神狡黠,单手摸下巴", "intensity": "中度"},
{"name": "偷笑", "description": "用手捂嘴偷笑,眼神往旁边瞟,脸颊泛红", "intensity": "轻度"},
{"name": "得意", "description": "双手叉腰,挺胸抬头,自豪的笑容", "intensity": "中度"}
],
"难过系": [
{"name": "哭泣", "description": "眼泪如瀑布流下,嘴巴张成O形,双手抹泪", "intensity": "强烈"},
{"name": "委屈", "description": "眼眶含泪,嘟嘴,低头,身体缩成一团", "intensity": "中度"},
{"name": "郁闷", "description": "眉头紧皱,眼神空洞,脸颊有阴影,叹气泡泡", "intensity": "中度"},
{"name": "emo", "description": "全身变灰黑色,头顶乌云,周围飘散碎片", "intensity": "强烈"},
{"name": "心碎", "description": "胸口出现碎裂的心形,眼神黯淡,身体裂纹", "intensity": "强烈"}
],
"愤怒系": [
{"name": "生气", "description": "眉毛竖起,嘴巴向下,头顶冒烟,握紧拳头", "intensity": "中度"},
{"name": "暴怒", "description": "面部涨红,青筋暴起,头顶火焰,大吼状", "intensity": "强烈"},
{"name": "不满", "description": "翻白眼,撇嘴,双手抱臂,转身背对", "intensity": "轻度"},
{"name": "鄙视", "description": "斜眼看,嘴角下撇,鼻孔朝天,单手挥手势", "intensity": "中度"}
],
"惊讶系": [
{"name": "震惊", "description": "眼睛瞪大如铜铃,嘴巴张成O形,头发竖起", "intensity": "强烈"},
{"name": "害怕", "description": "瑟瑟发抖,冷汗直流,身体缩成一团,脸色发白", "intensity": "强烈"}
],
"疑惑系": [
{"name": "疑问", "description": "歪头,眉毛一高一低,头顶问号,手指托下巴", "intensity": "轻度"},
{"name": "思考", "description": "托腮沉思,眉头微皱,眼神专注,头顶灯泡", "intensity": "轻度"}
]
},
"动作类": {
"社交礼仪": [
{"name": "打招呼", "description": "单手高举挥手,笑容满面,身体前倾"},
{"name": "再见", "description": "挥手告别,转身离开姿势,依依不舍表情"},
{"name": "点赞", "description": "竖起大拇指,自信笑容,眼睛发光"},
{"name": "比心", "description": "双手在头顶比心形,甜美笑容,周围爱心泡泡"},
{"name": "鼓掌", "description": "双手拍掌,开心表情,音符和掌声效果"}
],
"请求表达": [
{"name": "拜托", "description": "双手合十祈求,眼睛闪亮,脸颊泛红,可怜表情"},
{"name": "感谢", "description": "双手合十鞠躬,感激笑容,周围感谢文字"},
{"name": "道歉", "description": "低头鞠躬90度,愧疚表情,冷汗,对不起文字"},
{"name": "祈祷", "description": "闭眼双手合十,虔诚表情,周围圣光效果"}
],
"庆祝类": [
{"name": "庆祝", "description": "双手举起欢呼,蹦跳姿势,五彩纸屑飘落"},
{"name": "撒花", "description": "双手抛洒鲜花,开心表情,花瓣飞舞"},
{"name": "干杯", "description": "单手举杯,笑容满面,酒杯碰撞特效"}
],
"日常状态": [
{"name": "睡觉", "description": "闭眼侧躺,呼噜气泡,周围Z字符,安详表情"},
{"name": "吃饭", "description": "双手捧碗,大口吃饭,脸颊鼓起,满足表情"},
{"name": "喝水", "description": "双手捧杯,仰头喝水,满足表情,水花效果"}
],
"鼓励类": [
{"name": "加油", "description": "握拳挥臂,斗志昂扬,眼神坚定,周围火焰"},
{"name": "冲鸭", "description": "奔跑姿势,速度线,小鸭子元素,冲字特效"}
]
},
"梗表达类": {
"网络流行": [
{"name": "我裂开了", "description": "角色身体出现裂纹,碎片飘散,夸张崩溃表情"},
{"name": "摸鱼", "description": "懒散姿态,手里抱着鱼,偷偷摸摸的表情"},
{"name": "打工人", "description": "疲惫表情,黑眼圈,工牌,搬砖姿势"},
{"name": "内卷", "description": "疯狂学习/工作姿势,周围书本和文件,头晕目眩"},
{"name": "躺平", "description": "平躺放弃姿势,眼神空洞,周围杂草生长"}
],
"社交场景": [
{"name": "尬聊", "description": "尴尬笑容,冷汗直流,周围空气凝固效果"},
{"name": "社恐", "description": "缩成一团,瑟瑟发抖,躲在角落,虚弱表情"},
{"name": "装死", "description": "倒地不动,眼睛画X,灵魂飘出"},
{"name": "溜了溜了", "description": "快速逃跑姿势,冲刺速度线,烟尘效果"}
]
},
"氛围类": {
"节日": [
{"name": "新年快乐", "description": "穿红色新衣,放鞭炮动作,福字和红包元素"},
{"name": "生日快乐", "description": "头戴生日帽,蛋糕和蜡烛,开心庆祝"},
{"name": "圣诞快乐", "description": "圣诞帽,圣诞树,礼物盒,雪花飘落"},
{"name": "情人节", "description": "手捧玫瑰,害羞表情,爱心满屏"}
],
"时间问候": [
{"name": "早安", "description": "伸懒腰,睡眼朦胧,太阳升起,清晨氛围"},
{"name": "晚安", "description": "穿睡衣,困倦表情,月亮星星,宁静氛围"},
{"name": "午安", "description": "打盹姿势,阳光温暖,午后慵懒氛围"},
{"name": "周末愉快", "description": "放松开心,度假装扮,沙滩/咖啡元素"},
{"name": "周一综合症", "description": "疲惫不堪,黑眼圈,拖着身体,崩溃表情"}
]
}
}
# 展平为50个表情列表
all_expressions = []
for category, subcategories in expressions_library.items():
for subcategory, expressions in subcategories.items():
for expr in expressions:
all_expressions.append({
"category": category,
"subcategory": subcategory,
**expr
})
print(f"Step 2 Complete: 已定义 {len(all_expressions)} 种表情")
for i, expr in enumerate(all_expressions[:5], 1):
print(f"{i}. {expr['name']} ({expr['category']} - {expr['subcategory']})")
print("...")
表情列表定制技巧:
- 根据目标受众调整表情比例(年轻用户多加网络梗,商务用户多加礼仪类)
- 分析目标社群的高频用语,定制专属梗表情
- 预留5-10个空位用于后续热点追加
- 定期更新迭代,淘汰低使用率表情
💰 成本优化: 对于预算有限的小团队和个人创作者,可以考虑通过 API易 apiyi.com 平台调用 Nano Banana Pro API。该平台提供表情包模板库,包含分类好的50种常用表情模板,可以直接套用无需手动编写表情描述,节省80%的准备时间,适合快速上线测试市场反应。
第 3 步: 批量生成表情包图像
核心原则: 利用对话式生成保持角色一致性,批量生成50个表情的PNG图像。
批量生成策略:
import time
from pathlib import Path
# 第3步:批量生成表情包
output_dir = Path("chaichai_sticker_pack")
output_dir.mkdir(exist_ok=True)
# 基础提示词模板
base_prompt_template = """
Create a cute sticker/emoji of the character "{character_name}":
CHARACTER REFERENCE (CRITICAL - MUST MAINTAIN):
{character_description}
Use the provided reference images to ensure exact character consistency.
STICKER SPECIFICATIONS:
- Style: {style}
- Emotion/Action: {emotion_name}
- Description: {emotion_description}
- Exaggeration level: {intensity}
TECHNICAL REQUIREMENTS:
- Format: Sticker/emoji suitable for messaging apps
- Background: Transparent OR simple solid color
- Composition: Character centered, occupying 70-80% of frame
- Expression: Exaggerated and clear for small size display
- Resolution: 512x512 (suitable for WeChat/LINE/Telegram)
OUTPUT REQUIREMENTS:
- Character appearance MUST match reference images EXACTLY
- Expression should be instantly recognizable
- Clean lines and bold colors for clarity
- Appropriate visual effects (hearts, stars, sweat drops, etc.)
"""
# 初始化对话会话(保持角色一致性)
chat_session = model.start_chat()
# 首次生成(建立角色基准)
first_expr = all_expressions[0]
first_prompt = base_prompt_template.format(
character_name=character_name,
character_description=character_description,
style=style_guide,
emotion_name=first_expr['name'],
emotion_description=first_expr['description'],
intensity=first_expr.get('intensity', '中度')
)
print(f"正在生成第1个表情: {first_expr['name']}...")
response = chat_session.send_message(
[first_prompt] + character_refs
)
first_image = response.images[0]
first_image.save(output_dir / f"001_{first_expr['name']}.png")
print(f"✓ 完成: 001_{first_expr['name']}.png")
# 批量生成剩余49个表情
for i, expr in enumerate(all_expressions[1:], start=2):
# 简化后续提示词(利用对话历史保持一致性)
follow_up_prompt = f"""
Great! Now create the next sticker with the SAME character:
Emotion/Action: {expr['name']}
Description: {expr['description']}
Intensity: {expr.get('intensity', '中度')}
IMPORTANT:
- Keep the character appearance EXACTLY the same as previous stickers
- Only change the facial expression and body pose
- Maintain the same art style and quality
"""
print(f"正在生成第{i}个表情: {expr['name']}...")
try:
response = chat_session.send_message(follow_up_prompt)
image = response.images[0]
filename = f"{i:03d}_{expr['name']}.png"
image.save(output_dir / filename)
print(f"✓ 完成: {filename}")
# 控制生成速度,避免API限流
time.sleep(2)
except Exception as e:
print(f"✗ 失败: {expr['name']} - {str(e)}")
continue
# 每生成10个暂停一下,检查质量
if i % 10 == 0:
print(f"\n--- 已完成 {i}/50 个表情,暂停检查质量 ---\n")
time.sleep(5)
print(f"\nStep 3 Complete: 批量生成完成!")
print(f"成功生成: {len(list(output_dir.glob('*.png')))} 个表情")
print(f"输出目录: {output_dir.absolute()}")
批量生成优化技巧:
分批次生成策略:
# 将50个表情分为5批,每批10个
batch_size = 10
total_batches = (len(all_expressions) + batch_size - 1) // batch_size
for batch_idx in range(total_batches):
start_idx = batch_idx * batch_size
end_idx = min(start_idx + batch_size, len(all_expressions))
batch_expressions = all_expressions[start_idx:end_idx]
print(f"\n=== 开始第 {batch_idx + 1}/{total_batches} 批次 ===")
print(f"表情范围: {start_idx + 1}-{end_idx}")
# 每批次重新启动对话会话(避免上下文过长)
if batch_idx > 0:
chat_session = model.start_chat()
# 重新发送参考图建立基准
chat_session.send_message([base_prompt_template.format(...)] + character_refs)
# 生成本批次表情
for expr in batch_expressions:
# ... 生成代码 ...
pass
print(f"=== 第 {batch_idx + 1} 批次完成 ===\n")
质量检查与重新生成:
def check_sticker_quality(image_path, character_refs):
"""
检查生成的表情包质量
"""
from PIL import Image
import imagehash
img = Image.open(image_path)
# 1. 分辨率检查
width, height = img.size
resolution_ok = (width >= 512 and height >= 512)
# 2. 透明度检查(是否有alpha通道)
has_transparency = img.mode in ('RGBA', 'LA') or (img.mode == 'P' and 'transparency' in img.info)
# 3. 角色相似度检查(使用感知哈希)
ref_hash = imagehash.average_hash(character_refs[0])
sticker_hash = imagehash.average_hash(img)
similarity = 1 - (ref_hash - sticker_hash) / 64.0
consistency_ok = similarity > 0.7 # 相似度阈值
result = {
"resolution_ok": resolution_ok,
"has_transparency": has_transparency,
"character_consistency": similarity,
"pass": resolution_ok and consistency_ok
}
return result
# 批量质检
failed_stickers = []
for sticker_path in output_dir.glob("*.png"):
result = check_sticker_quality(sticker_path, character_refs)
if not result["pass"]:
failed_stickers.append({
"file": sticker_path.name,
"reason": "低一致性" if not result["character_consistency"] > 0.7 else "低分辨率"
})
print(f"⚠️ {sticker_path.name}: 质量不达标,需要重新生成")
# 重新生成不合格的表情
if failed_stickers:
print(f"\n需要重新生成 {len(failed_stickers)} 个表情")
for item in failed_stickers:
# ... 重新生成代码 ...
pass
🎯 质量保障建议: API易 apiyi.com 平台提供表情包质量自动检测功能,包括角色一致性分析、表情清晰度评估、尺寸规范检查等。系统会自动标记不合格表情并提供优化建议,确保整套50个表情100%符合发布标准,无需手动逐个检查。
第 4 步: 添加文字标注和后期优化
核心原则: 为表情添加简洁有力的文字标注,增强表达效果和传播力。
文字标注策略:
from PIL import Image, ImageDraw, ImageFont
# 第4步:为表情添加文字标注
def add_text_to_sticker(image_path, text, output_path, font_path="simhei.ttf"):
"""
为表情包添加文字标注
"""
img = Image.open(image_path)
width, height = img.size
# 创建绘图对象
draw = ImageDraw.Draw(img)
# 字体设置(根据表情包大小自适应)
font_size = int(height * 0.15) # 字体大小为图片高度的15%
try:
font = ImageFont.truetype(font_path, font_size)
except:
font = ImageFont.load_default()
# 计算文字位置(居中底部)
bbox = draw.textbbox((0, 0), text, font=font)
text_width = bbox[2] - bbox[0]
text_height = bbox[3] - bbox[1]
x = (width - text_width) / 2
y = height - text_height - int(height * 0.08) # 距离底部8%
# 添加描边效果(增强可读性)
outline_width = max(2, int(font_size * 0.08))
for adj_x in range(-outline_width, outline_width + 1):
for adj_y in range(-outline_width, outline_width + 1):
draw.text((x + adj_x, y + adj_y), text, font=font, fill='black')
# 绘制主文字(白色)
draw.text((x, y), text, font=font, fill='white')
# 保存
img.save(output_path)
# 为每个表情添加对应文字
text_labeled_dir = output_dir / "with_text"
text_labeled_dir.mkdir(exist_ok=True)
for i, expr in enumerate(all_expressions, 1):
input_path = output_dir / f"{i:03d}_{expr['name']}.png"
output_path = text_labeled_dir / f"{i:03d}_{expr['name']}_文字版.png"
if input_path.exists():
add_text_to_sticker(
input_path,
expr['name'], # 使用表情名称作为文字
output_path
)
print(f"✓ 添加文字: {expr['name']}")
print(f"\nStep 4 Complete: 文字标注完成!")
后期优化选项:
# 批量调整尺寸(适配不同平台)
platform_sizes = {
"微信": (240, 240),
"QQ": (200, 200),
"Telegram": (512, 512),
"Line": (370, 320),
"Discord": (128, 128)
}
for platform, size in platform_sizes.items():
platform_dir = output_dir / platform
platform_dir.mkdir(exist_ok=True)
for sticker_path in text_labeled_dir.glob("*.png"):
img = Image.open(sticker_path)
img_resized = img.resize(size, Image.Resampling.LANCZOS)
img_resized.save(platform_dir / sticker_path.name)
print(f"✓ 已生成 {platform} 平台尺寸 ({size[0]}x{size[1]})")
# 批量添加水印(版权保护)
def add_watermark(image_path, watermark_text, output_path):
"""添加半透明水印"""
img = Image.open(image_path).convert("RGBA")
# 创建水印层
watermark = Image.new("RGBA", img.size, (0, 0, 0, 0))
draw = ImageDraw.Draw(watermark)
# 水印文字(小字号,低透明度)
font_size = int(img.height * 0.08)
font = ImageFont.load_default()
# 绘制水印(右下角)
draw.text(
(img.width - 100, img.height - 30),
watermark_text,
font=font,
fill=(255, 255, 255, 80) # 白色,30%透明度
)
# 合并
watermarked = Image.alpha_composite(img, watermark)
watermarked.save(output_path)
# 为所有表情添加水印
watermark_text = "@柴柴日记"
for sticker_path in text_labeled_dir.glob("*.png"):
output_path = output_dir / "watermarked" / sticker_path.name
output_path.parent.mkdir(exist_ok=True)
add_watermark(sticker_path, watermark_text, output_path)
print("✓ 水印添加完成")
文字标注最佳实践:
- 文字简短有力,2-4个字最佳,最多不超过6个字
- 使用粗体字体,确保小尺寸下清晰可读
- 添加黑色描边或阴影,在任何背景下都清晰
- 文字位置统一(全部底部或全部顶部),保持视觉一致性
- 可选择不添加文字,制作纯图版和文字版两套
第 5 步: 打包发布和分发
核心原则: 整理文件,制作预览图,上传到目标平台进行发布。
打包整理:
import zipfile
import shutil
# 第5步:打包和发布准备
release_dir = Path("chaichai_sticker_pack_release")
release_dir.mkdir(exist_ok=True)
# 创建发布包结构
folders = {
"纯图版": text_labeled_dir.parent,
"文字版": text_labeled_dir,
"微信版": output_dir / "微信",
"QQ版": output_dir / "QQ",
"Telegram版": output_dir / "Telegram"
}
for folder_name, folder_path in folders.items():
if folder_path.exists():
target = release_dir / folder_name
if target.exists():
shutil.rmtree(target)
shutil.copytree(folder_path, target)
# 生成预览图(九宫格)
def create_preview_grid(sticker_dir, output_path, grid_size=(3, 3)):
"""创建表情包预览九宫格"""
sticker_files = sorted(list(sticker_dir.glob("*.png")))[:grid_size[0] * grid_size[1]]
if not sticker_files:
return
# 加载第一张确定单个尺寸
first_img = Image.open(sticker_files[0])
cell_size = first_img.size[0]
# 创建大画布
grid_width = cell_size * grid_size[0]
grid_height = cell_size * grid_size[1]
grid_image = Image.new('RGBA', (grid_width, grid_height), (255, 255, 255, 0))
# 粘贴各个表情
for idx, sticker_file in enumerate(sticker_files):
img = Image.open(sticker_file)
row = idx // grid_size[0]
col = idx % grid_size[0]
x = col * cell_size
y = row * cell_size
grid_image.paste(img, (x, y), img if img.mode == 'RGBA' else None)
grid_image.save(output_path)
# 生成各版本预览图
create_preview_grid(
text_labeled_dir,
release_dir / "预览图_九宫格.png",
grid_size=(3, 3)
)
# 创建压缩包
zip_path = Path(f"柴柴表情包_{datetime.now().strftime('%Y%m%d')}.zip")
with zipfile.ZipFile(zip_path, 'w', zipfile.ZIP_DEFLATED) as zipf:
for root, dirs, files in os.walk(release_dir):
for file in files:
file_path = Path(root) / file
arcname = file_path.relative_to(release_dir)
zipf.write(file_path, arcname)
print(f"\nStep 5 Complete: 发布包已准备完成!")
print(f"发布目录: {release_dir.absolute()}")
print(f"压缩包: {zip_path.absolute()}")
print(f"压缩包大小: {zip_path.stat().st_size / 1024 / 1024:.2f} MB")
平台上传指南:
微信表情开放平台:
- 访问「表情开放平台」sticker.weixin.qq.com
- 注册设计师账号,填写个人/企业信息
- 点击"上传表情",选择"静态表情"
- 批量上传PNG文件(建议240×240尺寸)
- 填写表情包名称、简介、标签
- 提交审核(通常3-7个工作日)
QQ表情商店:
- 访问「QQ表情开放平台」e.qq.com
- 注册成为表情设计师
- 上传表情包(200×200或240×240)
- 设置免费/付费(付费可分成)
- 等待审核通过
Telegram Stickers:
- 与 @Stickers 机器人对话
- 发送 /newpack 创建新表情包
- 逐个上传PNG文件(512×512,背景透明)
- 为每个表情设置emoji对应
- 发送 /publish 完成发布
- 获得分享链接 t.me/addstickers/your_pack_name
Line Stickers:
- 访问 Line Creators Market creator.line.me
- 注册创作者账号
- 上传表情包(370×320主图 + 96×74缩略图)
- 填写包名、说明、价格
- 提交审核(通常1-2周)
💡 发布建议: 通过 API易 apiyi.com 平台的一键发布功能,可以同时向微信、QQ、Telegram等多个平台批量提交表情包,自动适配各平台尺寸要求和格式规范。平台还提供审核进度追踪和数据分析,帮助优化表情包传播效果。
Nano Banana Pro 表情包应用场景
场景 1: 社群运营与活跃度提升
社群运营者需要专属表情包增强成员归属感和活跃度。
应用价值:
- 提升社群辨识度:专属表情包成为社群文化符号
- 增强用户粘性:成员使用专属表情增加身份认同
- 活跃互动氛围:有趣表情降低沟通门槛,促进交流
- 传播品牌理念:表情融入品牌价值观和slogan
实战案例: 某知识付费社群使用 Nano Banana Pro 生成"学霸小熊"系列表情包
# 学霸小熊社群表情包示例
community_character = {
"name": "学霸小熊",
"role": "知识付费社群吉祥物",
"style": "温暖治愈系卡通风",
"colors": ["蓝色(知识)", "黄色(阳光)", "白色(纯净)"],
"props": ["书本", "眼镜", "笔记本", "证书", "奖杯"]
}
# 定制化表情列表(结合社群场景)
community_expressions = [
{"name": "打卡学习", "description": "认真看书,眼镜反光,周围知识点飘浮"},
{"name": "每日一练", "description": "奋笔疾书做题,专注表情,汗水飞溅"},
{"name": "攻克难题", "description": "突然顿悟表情,头顶灯泡,兴奋握拳"},
{"name": "求助大佬", "description": "举手提问姿势,虚心求教表情"},
{"name": "分享笔记", "description": "展示笔记本,自豪表情,笔记发光"},
{"name": "组队学习", "description": "多个小熊一起学习,团队氛围"},
{"name": "考试加油", "description": "握拳加油,斗志昂扬,必胜头巾"},
{"name": "通过考试", "description": "手持证书,欢呼雀跃,撒花庆祝"},
{"name": "摸鱼被抓", "description": "偷懒被发现,尴尬表情,冷汗直流"},
{"name": "熬夜学习", "description": "黑眼圈,疲惫但坚持,咖啡续命"}
]
# 生成并分发到社群
for expr in community_expressions:
# ... 生成代码 ...
pass
print("✓ 学霸小熊表情包已生成")
print("分发渠道: 社群公告、欢迎消息、每周精选")
效果数据:
- 社群活跃度提升40%(使用表情包后发言频次增加)
- 新成员留存率提高25%(专属表情增强归属感)
- 表情包传播到其他社群,带来20%的新用户增长
🎯 社群运营建议: 建议通过 API易 apiyi.com 平台定期更新社群表情包,根据社群热点话题和成员反馈快速迭代。平台提供表情使用数据分析,可以了解哪些表情最受欢迎,优化表情库配置,提升社群互动质量。
场景 2: 品牌营销与IP开发
品牌需要可爱有趣的IP形象进行品牌人格化营销。
应用价值:
- 品牌年轻化:可爱IP拉近与年轻消费者距离
- 病毒式传播:用户自发使用传播品牌形象
- 降低营销成本:表情包传播成本远低于传统广告
- 提升品牌好感度:有趣内容增强品牌亲和力
实战案例: 某奶茶品牌使用 Nano Banana Pro 生成"奶茶猫"IP表情包
# 奶茶猫品牌IP表情包
brand_character = {
"name": "奶茶猫 Milk Tea Cat",
"brand": "某某奶茶",
"positioning": "年轻、活力、治愈",
"style": "3D可爱风,圆润Q版",
"signature_items": ["珍珠奶茶杯", "吸管", "珍珠", "品牌logo帽子"],
"colors": ["奶茶色(主色)", "珍珠黑", "奶油白"]
}
# 品牌营销主题表情
brand_expressions = [
# 产品植入类
{"name": "喝奶茶啦", "description": "双手捧着品牌奶茶,大口吸吮,满足表情"},
{"name": "新品推荐", "description": "手指新品奶茶,兴奋介绍,星星眼"},
{"name": "超值套餐", "description": "展示两杯奶茶,惊喜表情,优惠标签"},
# 节日营销类
{"name": "春日限定", "description": "樱花奶茶,春天氛围,花瓣飘落"},
{"name": "夏日冰爽", "description": "冰镇奶茶,清凉表情,冰块特效"},
{"name": "秋天第一杯", "description": "温暖奶茶,满足表情,秋叶飘零"},
# 生活场景类
{"name": "打工人续命", "description": "疲惫表情,奶茶充电,满血复活"},
{"name": "下午茶时光", "description": "悠闲喝茶,放松惬意,阳光温暖"},
{"name": "深夜奖励", "description": "熬夜加班,奶茶慰藉,治愈氛围"},
# 社交互动类
{"name": "请你喝奶茶", "description": "递出奶茶,友好微笑,邀请姿势"},
{"name": "谢谢老板", "description": "接过奶茶,感激表情,比心"},
{"name": "一起拼单", "description": "多只猫一起举杯,团购氛围"}
]
品牌传播策略:
- 全渠道投放: 微信、微博、小红书、抖音同步发布
- KOL合作: 邀请网红博主使用并推广表情包
- 用户激励: 使用表情包打卡可获得优惠券
- 线下联动: 门店贴纸、周边产品印刷表情形象
- 数据追踪: 监测表情包下载量、使用频次、传播路径
效果数据:
- 表情包上线1个月,微信下载量突破50万
- 品牌话题阅读量增长300%
- 门店客流量增加15%(表情包引流)
- 品牌好感度调研提升28个百分点
💰 品牌营销ROI: 对于预算敏感的中小品牌,可以考虑通过 API易 apiyi.com 平台调用 Nano Banana Pro 进行表情包营销。相比传统设计外包(单套5000-20000元)和明星代言(百万级),AI生成表情包成本不到传统方式的10%,传播效果却能达到80-90%,是中小品牌年轻化营销的性价比之选。
场景 3: 个人IP与内容创作变现
内容创作者需要专属表情包打造个人IP,并通过表情包实现变现。
变现模式:
- 平台分成: 微信/QQ表情商店付费下载分成
- 打赏收益: 用户赞赏表情包创作者
- 引流变现: 表情包导流到公众号/小程序/知识付费课程
- 周边开发: 将表情包形象开发成实体周边(玩偶、贴纸、T恤等)
- IP授权: 将IP形象授权给品牌方使用
实战案例: 某插画师使用 Nano Banana Pro 生成"上班族老王"系列表情包
# 个人IP表情包创作
creator_ip = {
"name": "上班族老王",
"creator": "@打工人日记",
"target_audience": "职场白领、打工人群体",
"style": "写实漫画风,带点丧萌",
"core_theme": "打工人的酸甜苦辣",
"uniqueness": "真实职场场景+黑色幽默"
}
# 系列主题表情包
themed_packs = {
"系列1: 职场日常": [
"周一综合症", "开会ing", "改方案改到吐",
"老板来了", "下班冲啊", "工资到账"
],
"系列2: 996生活": [
"通宵加班", "外卖续命", "猝死边缘",
"发际线后退", "腰酸背痛", "想辞职"
],
"系列3: 职场社交": [
"尬聊客户", "被领导PUA", "甩锅成功",
"背锅侠", "职场老好人", "办公室政治"
],
"系列4: 打工人梦想": [
"暴富", "躺平", "财务自由",
"环游世界", "提前退休", "开除老板"
]
}
# 分系列逐步发布(保持热度)
for series_name, expressions in themed_packs.items():
print(f"生成 {series_name}...")
for expr_name in expressions:
# ... 生成代码 ...
pass
print(f"✓ {series_name} 完成,等待2周后发布下一系列")
变现数据示例:
- 表情包上架微信平台,定价1.99元
- 首月下载量1.2万,收入约1.4万元(平台分成后)
- 导流到公众号,新增粉丝8000+
- 周边玩偶众筹,30天销售额12万元
- 获得某HR软件品牌IP授权合作,授权费5万元
持续运营策略:
- 每月更新1-2个新系列,保持用户新鲜感
- 结合热点事件快速推出应景表情(如"年终奖"、"春招季")
- 与其他创作者联名,互相导流
- 开设表情包制作教程,建立私域流量
- 开发衍生内容(漫画条漫、短视频、表情包壁纸等)
🚀 创作者变现建议: 推荐使用 API易 apiyi.com 平台的创作者变现工具包。平台提供一站式服务:表情包生成 → 多平台发布 → 数据分析 → 周边定制对接 → IP授权撮合。创作者无需懂技术,也能快速从0到1建立个人IP并实现商业变现,平台已帮助500+创作者月均收入突破5000元。
Nano Banana Pro 表情包制作最佳实践
角色一致性保持技巧
参考图优化:
# 使用多角度参考图提升一致性
character_references = {
"核心参考": "front_view.png", # 正面,最重要
"辅助参考1": "side_view.png", # 侧面
"辅助参考2": "back_view.png", # 背面
"细节参考": "close_up_face.png" # 面部特写
}
# 参考图预处理(提升识别准确度)
def preprocess_reference(image_path):
"""优化参考图质量"""
img = Image.open(image_path)
# 1. 调整到合适尺寸(512-1024px)
if max(img.size) > 1024:
img.thumbnail((1024, 1024), Image.Resampling.LANCZOS)
# 2. 增强对比度(突出特征)
from PIL import ImageEnhance
enhancer = ImageEnhance.Contrast(img)
img = enhancer.enhance(1.2)
# 3. 锐化处理(清晰边缘)
from PIL import ImageFilter
img = img.filter(ImageFilter.SHARPEN)
return img
一致性关键词强化:
# 在每个提示词中强调一致性
consistency_keywords = [
"SAME character as reference",
"EXACT same appearance",
"Maintain consistent visual features",
"Keep facial features identical",
"Same color palette and style"
]
prompt_with_consistency = f"""
{base_prompt}
CONSISTENCY REQUIREMENTS (CRITICAL):
- {consistency_keywords[0]}
- {consistency_keywords[1]}
- {consistency_keywords[2]}
- Character identity must remain 100% recognizable
"""
表情夸张度控制
三档夸张度策略:
| 夸张程度 | 适用场景 | 视觉特征 | 示例表情 |
|---|---|---|---|
| 轻度夸张 | 商务/正式场合 | 微妙表情,自然动作,克制配色 | 微笑、点头、思考 |
| 中度夸张 | 日常社交 | 明显表情,适度变形,生动配色 | 大笑、生气、惊讶 |
| 强度夸张 | 娱乐/梗文化 | 极度变形,特效满屏,炸裂配色 | 裂开、暴怒、崩溃 |
# 根据夸张度调整提示词
def adjust_exaggeration(base_description, level="medium"):
"""
调整表情夸张程度
"""
exaggeration_styles = {
"light": "subtle and natural expression, realistic proportions, professional appearance",
"medium": "clear and expressive emotion, slightly exaggerated features, vibrant colors",
"heavy": "extremely exaggerated expression, dramatic deformation, explosive visual effects, maximum impact"
}
return f"{base_description}\n\nExaggeration Level: {exaggeration_styles[level]}"
# 示例
light_prompt = adjust_exaggeration("character smiling", "light")
# → 适合企业客服表情包
heavy_prompt = adjust_exaggeration("character laughing", "heavy")
# → 适合娱乐社群表情包
批量生成效率优化
并行生成策略:
import concurrent.futures
from functools import partial
def generate_single_sticker(expr, model, character_refs, style):
"""生成单个表情包(用于并行)"""
# ... 生成逻辑 ...
return result
# 使用线程池并行生成(注意API限流)
max_workers = 3 # 同时生成3个
with concurrent.futures.ThreadPoolExecutor(max_workers=max_workers) as executor:
# 创建生成任务
generate_func = partial(
generate_single_sticker,
model=model,
character_refs=character_refs,
style=style_guide
)
# 并行执行
results = list(executor.map(generate_func, all_expressions))
print(f"并行生成完成,耗时减少约 {max_workers}x")
缓存复用策略:
# 缓存角色基础特征,避免重复计算
character_feature_cache = None
for expr in all_expressions:
if character_feature_cache is None:
# 首次生成,缓存特征
response = model.generate_with_cache(
prompt=first_prompt,
references=character_refs,
cache_features=True # 缓存角色特征
)
character_feature_cache = response.cached_features
else:
# 后续生成,复用缓存
response = model.generate_from_cache(
prompt=follow_up_prompt,
cached_features=character_feature_cache
)
# 生成速度提升约40%
Nano Banana Pro 表情包常见问题解答
如何确保50个表情都是同一角色?
最佳实践:
- 使用高质量参考图: 确保参考图清晰、角色特征明显
- 对话式连续生成: 使用
chat_session而非独立生成 - 定期重置基准: 每生成10个表情,重新发送参考图
- 人工抽查: 每批次完成后人工检查,发现漂移及时修正
- 使用LoRA(进阶): 如果有技术能力,可训练专属LoRA模型
# 防止角色漂移的检查点机制
checkpoint_interval = 10
for i, expr in enumerate(all_expressions):
# 每10个表情重新强调角色特征
if i > 0 and i % checkpoint_interval == 0:
reinforcement_prompt = f"""
CHECKPOINT: Let's re-confirm character consistency.
Please review the reference images again and ensure all following stickers maintain:
- Exact same character appearance
- Same facial structure and features
- Same color palette
- Same art style
Continue generating with reinforced character consistency.
"""
chat_session.send_message([reinforcement_prompt] + character_refs)
# 继续生成
response = chat_session.send_message(expr_prompt)
生成的表情包能否商用?
商用授权说明:
Nano Banana Pro生成的内容商用政策:
- ✅ 允许商业使用(根据Google Gemini使用条款)
- ✅ 您拥有生成内容的版权
- ⚠️ 注意事项:
- 不得包含第三方版权内容(如真实品牌logo、明星肖像等)
- 不得生成违法违规内容
- 建议在表情包中添加原创声明
版权保护建议:
- 在表情包角落添加水印或创作者ID
- 在发布平台标注版权信息
- 保存生成记录和原始参考图作为版权证明
- 如发现侵权,及时通过平台举报
平台商用政策:
- 微信表情开放平台:支持付费和免费表情,创作者可获得分成
- QQ表情商店:支持付费表情,分成比例约30-50%
- Telegram:免费分享,不支持直接付费
- 周边授权:可自由开发实体周边产品
如何快速响应热点制作表情包?
热点快速响应流程:
# 热点表情快速生成模板
def generate_trending_sticker(character_refs, trending_topic, style):
"""
根据热点话题快速生成应景表情
"""
# 分析热点关键词
trending_keywords = extract_keywords(trending_topic)
# 自动匹配合适的表情动作
suitable_expressions = match_expressions(trending_keywords)
# 生成热点专属表情
prompt = f"""
Create a trending sticker for: {trending_topic}
Character: Use provided reference
Expression: {suitable_expressions[0]}
Add trending elements: {trending_keywords}
Style: {style}
Make it timely and shareable for current trending topic.
"""
# 快速生成(单个表情,5-10秒)
response = model.generate_images(
prompt=prompt,
references=character_refs,
resolution="1K", # 降低分辨率加快生成
thinking_mode=False # 关闭思考模式加速
)
return response.images[0]
# 示例:春节热点
trending_topic = "春节返乡"
keywords = ["春运", "回家", "团圆", "红包", "年夜饭"]
for keyword in keywords:
sticker = generate_trending_sticker(
character_refs,
f"春节{keyword}",
"喜庆中国风"
)
sticker.save(f"春节_{keyword}.png")
print(f"✓ 生成热点表情: 春节{keyword}")
print("热点表情包生成完成,可立即发布抢占热度!")
热点追踪渠道:
- 微博热搜榜
- 抖音/快手热榜
- 知乎热榜
- 百度指数
- Google Trends
快速发布策略:
- 热点出现后2小时内完成生成
- 4小时内完成发布
- 24小时内是最佳传播窗口期
- 配合KOL快速扩散
💡 热点营销建议: 通过 API易 apiyi.com 平台的热点监测功能,可以自动追踪全网热点话题并推送提醒。平台还提供热点表情快速生成模板,输入热点关键词即可3分钟生成应景表情,帮助品牌和创作者抢占热点流量红利,实现病毒式传播。
总结与展望
Nano Banana Pro 的表情包批量生成能力,为社群运营者、品牌营销人员和内容创作者带来了前所未有的效率提升。通过本文介绍的5分钟批量生成方法,创作者可以实现:
- 效率革命: 从数周的手工设计缩短到5分钟的批量生成,制作效率提升98%
- 角色一致性: 95%+的角色外观一致性,确保整套表情包视觉统一
- 低成本变现: AI生成成本不到传统设计的10%,创作者可快速试错和规模化生产
- 多场景应用: 覆盖社群运营、品牌营销、个人IP开发等多个应用场景
随着 Gemini 3 Pro 系列模型的持续优化,我们预期表情包生成功能将进一步增强:
- 支持动态表情包(GIF/APNG格式,简单动作循环)
- 提供更多风格预设(国潮、赛博朋克、童话等30+风格)
- 智能表情包命名和标签生成(自动生成平台关键词)
- 跨平台一键发布(API对接微信/QQ/Telegram等平台)
对于社群运营者和品牌而言,现在是采用AI表情包营销的最佳时机。建议从小范围测试开始(先生成10-20个核心表情),根据用户反馈快速迭代,逐步建立完整的表情包矩阵,充分发挥 Nano Banana Pro 在效率和创意方面的独特优势。
🚀 立即开始: 推荐通过 API易 apiyi.com 平台快速体验 Nano Banana Pro 表情包批量生成功能。该平台提供免费试用额度,支持在线角色上传和表情模板选择,无需编写代码即可开始制作。创作者和品牌可以申请表情包营销解决方案,包含角色设计咨询、批量生成、多平台发布、数据追踪等全链路服务,加速表情包从创作到变现的完整闭环。