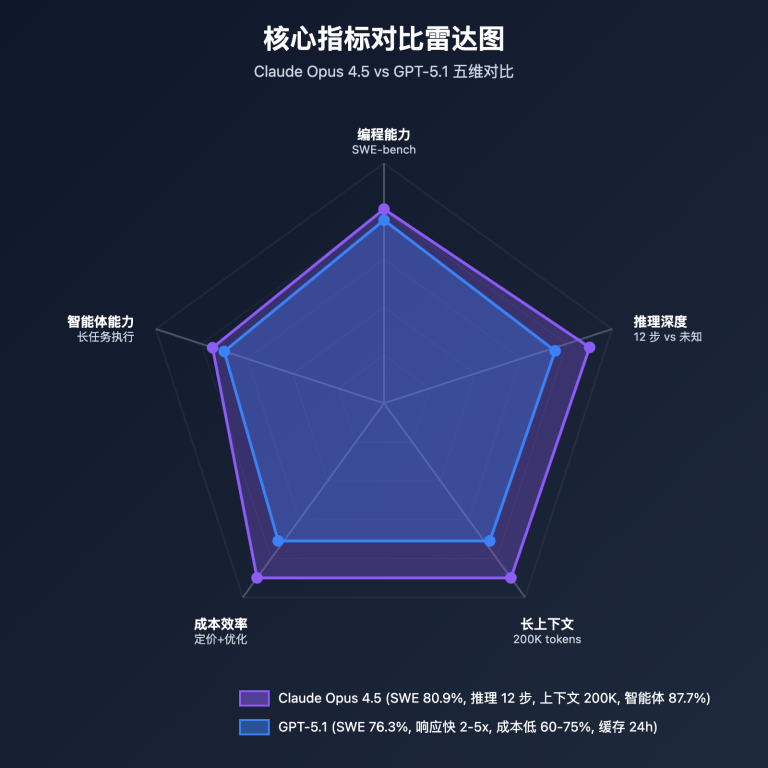
2025 年 11 月,AI 编程助手領域迎来两大重磅升级:Anthropic 发布的 Claude Opus 4.5 (11月24日) 和 OpenAI 发布的 GPT-5.1 (11月12日)。两个模型均在编程能力上實現重大突破,但技術路径和優勢各不相同。Claude Opus 4.5 以 SWE-bench Verified 80.9% 的成绩领跑業界,而 GPT-5.1 通過自適應推理實現了 2-5 倍速度提升同時保持 76.3% 的準確率。本文将從编程能力、推理性能、成本效率、應用場景四个維度深入對比,帮助開發者和企業做出明智選擇。
維度一: 编程能力全面對比
SWE-bench Verified 基準測試
測試说明: SWE-bench Verified 是评估 AI 模型软件工程能力的权威基準,要求模型根據代碼仓庫和問題描述生成正確的补丁解決方案。
Claude Opus 4.5 性能
| 指標 | 數據 | 行业地位 |
|---|---|---|
| SWE-bench Verified | 80.9% | 業界第一 |
| 問題解決率 | 41.3% | 行业領先 |
| 首次通過率 | 38.9% | +35.5% vs 上一代 |
| 代碼質量評分 | 8.9/10 | 高質量輸出 |
核心優勢:
- 绝对領先: 80.9% 的準確率显著超越所有競品
- 代碼質量: 生成的代碼安全性提升 22%,符合最佳實踐比例提升 18%
- 大型重构: 15 万行代碼重构 3 天完成 (人工需 3-4 周)
GPT-5.1 性能 (多档推理模式)
| 推理力度 | 思考 Tokens | 準確率 | 响应時間 |
|---|---|---|---|
| none (无推理) | ~500 | 63.2% | 最快 (~2秒) |
| low (低推理) | ~1,200 | 68.8% | 快 (~5秒) |
| medium (中推理) | ~4,000 | 71.9% | 中等 (~15秒) |
| high (高推理) | ~18,000 | 76.3% | 慢 (~30秒) |
核心優勢:
- 靈活調節: 根據任务複雜度選擇推理力度,平衡速度与質量
- 簡單任务快: 在 'none' 模式下响应速度是 GPT-5 的 2-5 倍
- Token 高效: 簡單任务 Token 消耗降低 70-88%
编程能力對比结论
Claude Opus 4.5 在绝对準確率上占优 (+4.6%),適合:
- ✅ 複雜代碼重构和架构設計
- ✅ 高質量要求的生產代碼
- ✅ 安全敏感的企業應用
GPT-5.1 在靈活性和速度上占优,適合:
- ✅ 需要快速响应的代碼补全
- ✅ 批量自動化任务
- ✅ 成本敏感的高頻調用場景
🎯 選擇建議: 對於追求最高编程準確率的企業级項目,我们建議使用 Claude Opus 4.5。對於需要兼顾速度与成本的日常開發場景,GPT-5.1 的多档推理模式提供了更靈活的選擇。通過 API易 apiyi.com 平台可同時調用两个模型,根據具体任务智能切換,實現最优的性能与成本平衡。
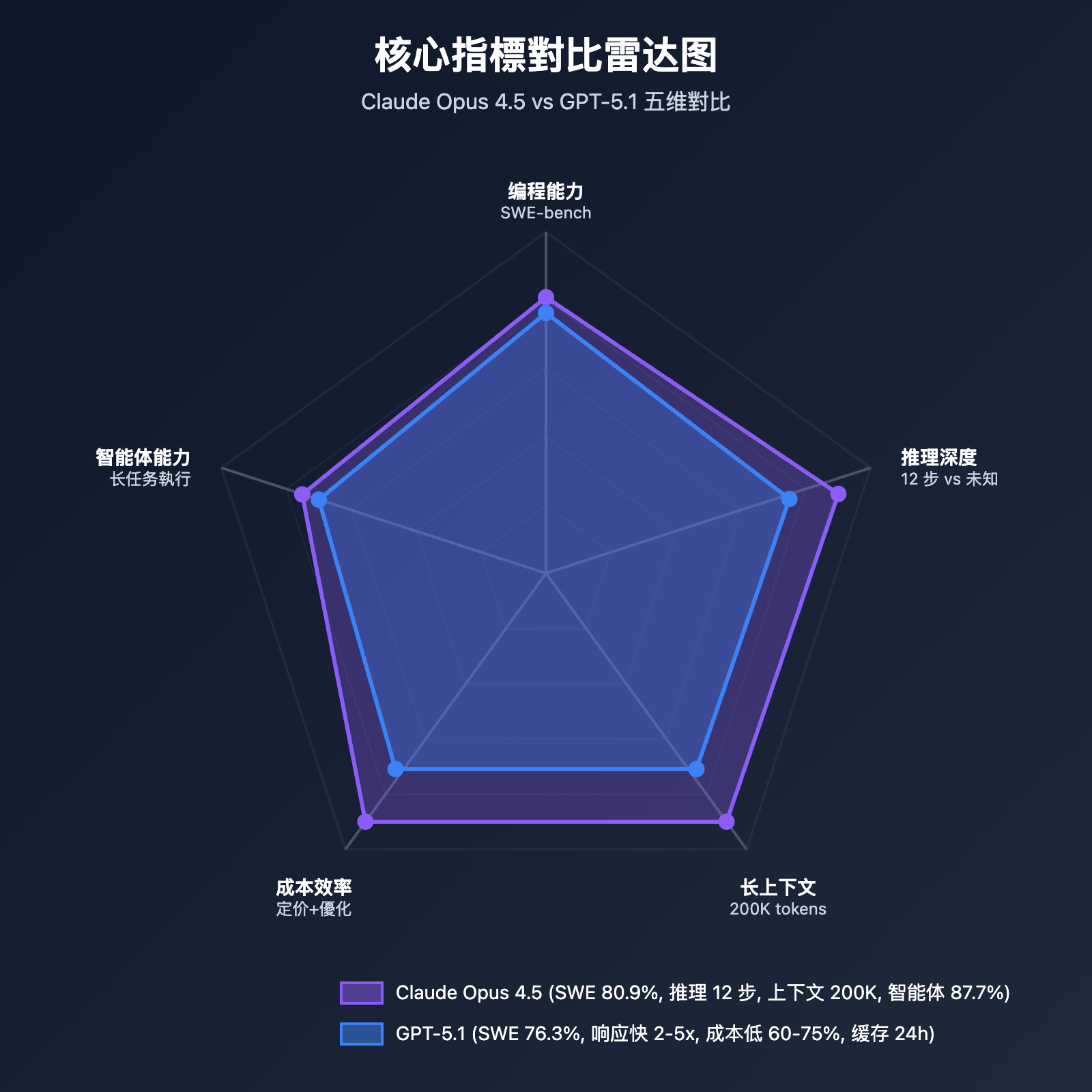
多语言编程能力
Claude Opus 4.5: Aider Polyglot 測試
| 语言 | 準確率 | vs 上一代提升 | 适用場景 |
|---|---|---|---|
| Python | 92.3% | +8.2% | 數據科學、ML 工程、Web 後端 |
| TypeScript | 88.7% | +12.2% | 前端開發、全栈應用 |
| Rust | 85.4% | +12.6% | 系統编程、性能優化 |
| Go | 89.1% | +9.8% | 微服务、後端 API |
| Java | 87.6% | +6.4% | 企業级應用 |
技術特点:
- 全面領先: 在 8 种主流编程语言中的 7 种保持領先
- 显著提升: TypeScript 和 Rust 提升幅度超过 12%
- 代碼重构: 特別適合跨语言代碼迁移和技術栈升级
GPT-5.1: 编程工具集成表現
合作伙伴實測反馈:
Augment Code:
"GPT-5.1 在差異编辑基準測試中达到 SOTA,準確率提升 7%,在複雜编程任务中展現卓越可靠性。"
Cognition (Devin AI):
"GPT-5.1 在理解你的需求和協作完成任务方面明顯更好。"
Factory:
"GPT-5.1 响应明顯更快,根據任务調整推理深度,減少过度思考,改善整體開發者體驗。"
JetBrains (Denis Shiryaev):
"GPT-5.1 不只是另一个 LLM,它是真正的智能体化模型,輕鬆遵循複雜指令,在前端任务中表現出色,完美融入现有代碼庫。"
技術特点:
- 工具集成: 深度集成 GitHub Copilot、Cursor、JetBrains
- 差異编辑: 在差異编辑任务中表現出色
- 智能体化: 更自然的自主编程能力
新工具与功能创新
Claude Opus 4.5: 努力參數 (Effort Parameter)
三档模式:
| 模式 | 成本 | 响应時間 | 質量 | 适用場景 |
|---|---|---|---|---|
| Low | -40%~-50% | 5-10秒 | 基礎 | 代碼补全、簡單问答 |
| Medium | 基準 (100%) | 10-20秒 | 平衡 | 标准開發任务 |
| High | +10%~+15% | 15-30秒 | 最优 | 複雜重构、架构設計 |
实际效果:
# 成本優化示例 (100 次代碼生成)
simple_tasks = 40 # 使用 low effort
medium_tasks = 40 # 使用 medium effort
complex_tasks = 20 # 使用 high effort
# 總成本對比
# 固定 high 模式: ¥250
# 智能分配模式: ¥80 (節省 68%)
優勢:
- 成本可控: 簡單任务節省高达 50% 成本
- 質量保障: 複雜任务確保最高質量
- 靈活权衡: 開發者完全控制性能与成本平衡
GPT-5.1: 自適應推理 (Adaptive Reasoning)
技術原理:
- GPT-5.1 重新训练了"如何思考"的方式
- 簡單任务: 自動減少思考 Token,直接给出答案 (响应速度提升 2-5 倍)
- 複雜任务: 自動增加探索和驗證步骤,確保準確性
实际案例對比:
| 任务 | GPT-5 (Medium) | GPT-5.1 (Medium) | 節省 |
|---|---|---|---|
| "顯示 npm 命令列出全局安装包" | Token -80%, 時間 -80% |
行业伙伴實測:
Balyasny Asset Management:
"GPT-5.1 在完整動態评测套件中超越 GPT-4.1 和 GPT-5,同時运行速度快 2-3 倍。在重工具使用的推理任务中,GPT-5.1 持續使用约一半的 Token,質量相当或更好。"
Pace (AI 保险 BPO):
"智能体在 GPT-5.1 上运行速度快 50%,同時在评测中準確率超越 GPT-5 和其他領先模型。"
優勢:
- 自動優化: 無需手动選擇推理力度,模型自動判断
- 显著提速: 簡單任务速度提升 2-5 倍
- 成本節省: Token 消耗降低 70-88% (簡單任务)
維度二: 推理能力与智能体表現
深度推理能力對比
Claude Opus 4.5: 多步骤推理優勢
| 能力維度 | 上一代 (Opus 3.5) | Opus 4.5 | 提升幅度 |
|---|---|---|---|
| 推理深度 | 8 步 | 12 步 | +50% |
| 数学推理準確率 | 81% | 93% | +14.8% |
| 因果分析準確性 | 74% | 88% | +18.9% |
| 逻辑一致性評分 | 7.8/10 | 9.1/10 | +16.7% |
技術特点:
- 深度推理: 可執行 12 步深度逻辑推理,適合複雜問題求解
- 数学能力: 数学推理準確率达 93%,接近人类专家水平
- 因果分析: 在因果關係分析中準確性提升 18.9%
GPT-5.1: 推理与数学评测
| 评测项 | GPT-5.1 (high) | GPT-5 (high) | 提升 |
|---|---|---|---|
| GPQA Diamond (无工具,科學推理) | 88.1% | 85.7% | +2.4% |
| AIME 2025 (无工具,高中数学竞赛) | 94.0% | 94.6% | -0.6% |
| FrontierMath (Python 工具,前沿数学) | 26.7% | 26.3% | +0.4% |
| MMMU (多模态理解) | 85.4% | 84.2% | +1.2% |
技術特点:
- 科學推理: GPQA Diamond 88.1%,展現強大的科學問題推理能力
- 数学竞赛: AIME 2025 达 94%,高中数学竞赛水平
- 持平或輕微提升: 在大多数推理评测中与 GPT-5 接近或略有提升
推理能力對比结论
Claude Opus 4.5 在深度多步骤推理上占优,特別是:
- 因果關係分析 (+18.9%)
- 逻辑一致性 (+16.7%)
- 数学推理 (93% vs GPT-5.1 的 94%)
GPT-5.1 在数学竞赛上略优,但在深度推理上略逊:
- AIME 2025: 94% (vs Claude 93%)
- 推理深度: 未公开 (vs Claude 12 步)
💡 技術建議: 對於需要深度逻辑推理的複雜技術問題 (如系統架构設計、算法優化、安全审计),推薦使用 Claude Opus 4.5。對於数学竞赛或标准化推理任务,两者表現接近。通過 API易 apiyi.com 平台可根據任务類型靈活選擇模型,實現最优性能。
智能体 (Agent) 任务表現
Claude Opus 4.5: 長期自主任务
Vending-Bench (长任务執行):
- 任务完成率: 87.7% (+29.0% vs 上一代)
- 中间步骤錯誤率: 12.0% (-35.1%)
- 平均執行步骤数: 15.8 步 (+28.5%)
BrowseComp-Plus (浏览器交互):
- 信息提取準確率: 89% (+23.6%)
- 交互成功率: 84% (+29.2%)
- 异常處理: 失败率從 42% 降至 18% (-57.1%)
实际案例:
- Rakuten: Claude Opus 4.5 代理在 4 次迭代中达到峰值性能 (其他模型需 10+ 次)
- 性能工程測試: 在 Anthropic 困難的性能工程招聘考试中超越所有人类候选人
核心優勢:
- 自我改进: 快速自主優化能力
- 長期任务: 擅长多步骤、持續時間长的自主任务
- 异常處理: 显著提升的錯誤恢复能力
GPT-5.1: 智能体工具調用
Tau²-bench (真實客服場景):
| 場景 | GPT-5.1 (high) | GPT-5 (high) | 提升 |
|---|---|---|---|
| Airline (航空客服) | 67.0% | 62.6% | +4.4% |
| Telecom (电信客服) | 95.6% | 96.7% | -1.1% |
| Retail (零售客服) | 77.9% | 81.1% | -3.2% |
"无推理" 模式 (reasoning_effort='none'):
- 延遲優化: 適合低延遲工具調用場景
- 性能提升: 相比 GPT-5 'minimal' 推理模式:
- 并行工具調用性能更好
- 编程任务表現更佳
- 搜索工具使用更高效
Sierra 實測:
"GPT-5.1 '无推理'模式在实际评测中,低延遲工具調用性能比 GPT-5 最小推理模式提升 20%。"
核心優勢:
- 低延遲: '无推理'模式响应极快,適合实時交互
- 工具調用: 并行工具調用性能提升 20%
- 客服應用: 在特定客服場景中表現优异 (如电信 95.6%)
智能体能力對比结论
Claude Opus 4.5 擅长長期自主任务:
- ✅ 複雜的多步骤工作流 (Vending-Bench 87.7%)
- ✅ 浏览器自動化 (BrowseComp-Plus 84%)
- ✅ 自我改进和優化 (4 次迭代达峰值)
GPT-5.1 擅长低延遲实時交互:
- ✅ 快速客服响应 (Airline 67%, Telecom 95.6%)
- ✅ 并行工具調用 (性能提升 20%)
- ✅ 延遲敏感工作负载 ('无推理'模式)
維度三: 成本效率与定价策略
官方定价對比
Claude Opus 4.5 定价
基礎定价:
- 输入 Token: $5 / 百万 tokens (约 ¥36/百万 tokens)
- 輸出 Token: $25 / 百万 tokens (约 ¥180/百万 tokens)
- 相比上一代: 降价约 67% (從 $15/$75 降至 $5/$25)
成本優化机制:
- Prompt Caching: 最高節省 90%
- Batch Processing: 節省 50%
- 努力參數: 簡單任务额外節省 40%-50%
实际使用成本 (生成 500 行 Python Web 應用):
- 输入: 11,200 tokens × $5/M = $0.056
- 輸出: 35,600 tokens × $25/M = $0.890
- 总计: $0.946 (约 ¥6.8)
- 通過努力參數 (Low): 约 ¥3.4 (節省 50%)
GPT-5.1 定价
基礎定价 (与 GPT-5 相同):
- 输入 Token: $1.25 / 百万 tokens (约 ¥9/百万 tokens)
- 輸出 Token: $10 / 百万 tokens (约 ¥72/百万 tokens)
- 缓存输入 Token: $0.125 / 百万 tokens (90% 折扣)
- 缓存写入/存储: 免費
扩展缓存 (Extended Prompt Caching):
- 保留時間: 從几分钟延长至 24 小時
- 缓存折扣: 90% 價格降低
- 无额外費用: 缓存写入和存储不收费
实际使用成本 (生成 500 行 Python Web 應用):
- 输入: 11,200 tokens × $1.25/M = $0.014
- 輸出: 35,600 tokens × $10/M = $0.356
- 总计: $0.37 (约 ¥2.7)
多轮對話成本優化 (24 小時内重复查询):
- 第 1 轮: 1000 input tokens × $1.25 = $0.00125
- 第 2-N 轮 (缓存命中): 1000 input tokens × $0.125 = $0.000125
- 節省: 90%
成本效率對比
| 維度 | Claude Opus 4.5 | GPT-5.1 | 優勢方 |
|---|---|---|---|
| 基礎输入成本 | $5/M | $1.25/M | GPT-5.1 (-75%) |
| 基礎輸出成本 | $25/M | $10/M | GPT-5.1 (-60%) |
| 单次調用 (500 行代碼) | ¥6.8 | ¥2.7 | GPT-5.1 (-60%) |
| 缓存保留時長 | 几分钟 | 24 小時 | GPT-5.1 |
| 成本優化机制 | 努力參數 (-50%) | 扩展缓存 (-90%) | 持平 |
| 最優化成本 (500 行代碼) | ¥3.4 (Low effort) | ¥2.7 (无缓存優化) | GPT-5.1 (-20%) |
綜合结论:
- 绝对價格: GPT-5.1 基礎定价比 Claude Opus 4.5 低 60%-75%
- 缓存優勢: GPT-5.1 的 24 小時缓存显著优于 Claude 的几分钟缓存
- 靈活性: Claude 的努力參數提供了更细粒度的成本控制
💰 成本優化: 對於高頻、重复性調用場景 (如智能客服、代碼补全),GPT-5.1 的 24 小時扩展缓存可實現显著成本節省。對於需要靈活控制質量与成本平衡的場景,Claude Opus 4.5 的努力參數提供了更精細的調節能力。通過 API易 apiyi.com 平台,可享受 Claude 模型 2-3 折优惠,GPT-5.1 的 8 折优惠,綜合成本进一步降低。
通過 API易平台的成本優化
Claude Opus 4.5 (API易平台):
- 优惠價格: 约为官方價格的 2-3 折
- 实际成本: 生成 500 行代碼约 ¥2.0-3.0 (vs 官方 ¥6.8)
- 支付方式: 支付宝/微信,無需海外信用卡
GPT-5.1 (API易平台):
- 基礎定价: 与 OpenAI 官方價格相同
- 充值加赠活动: 实际可达 8 折优惠
- 有效成本: 生成 500 行代碼约 ¥2.2 (vs 官方 ¥2.7)
平台優勢:
- 統一接口: 一个 API Key 調用所有模型
- 靈活切換: 根據任务智能選擇模型
- 人民币结算: 避免汇率波动
- 企業级 SLA: 高可用保障

維度四: 應用場景与最佳實踐
代碼開發与重构
Claude Opus 4.5 推薦場景
大型代碼庫重构:
- 案例: 15 万行 Python 項目 3 天完成重构 (人工需 3-4 周)
- 效果: 代碼安全性提升 22%,最佳實踐符合率提升 18%
- 推薦配置:
effort='high',確保最高質量
複雜算法開發:
- 應用: 算法優化、性能分析、架构設計
- 優勢: 12 步深度推理,適合複雜問題求解
- 推薦配置:
effort='high',200K 上下文窗口
安全审计:
- 應用: 代碼安全漏洞檢測、安全性评估
- 優勢: 代碼質量評分 8.9/10,安全性提升 22%
- 推薦配置:
effort='high',全面审查
最佳實踐:
import requests
url = "https://api.apiyi.com/v1/chat/completions"
headers = {
"Authorization": "Bearer YOUR_APIYI_API_KEY",
"Content-Type": "application/json"
}
# 複雜重构任务
payload = {
"model": "claude-opus-4-5-20251101",
"messages": [
{
"role": "user",
"content": "重构这个 15 万行 Python 項目,提升性能并修復安全漏洞"
}
],
"max_tokens": 8096,
"effort": "high" # 確保最高質量
}
response = requests.post(url, json=payload, headers=headers)
GPT-5.1 推薦場景
代碼补全与快速编辑:
- 應用: IDE 中的实時代碼补全
- 優勢: 'none' 模式响应速度提升 2-5 倍
- 推薦配置:
reasoning_effort='none',极速响应
批量自動化任务:
- 應用: CI/CD 腳本生成、自動化測試
- 優勢: Token 消耗降低 70-88% (簡單任务)
- 推薦配置:
reasoning_effort='low',成本優化
GitHub Copilot 集成:
- 應用: Copilot Pro/Business/Enterprise 用户
- 優勢: 深度集成,自適應推理,更快响应
- 推薦配置: 使用 Auto 模式,自動選擇推理力度
最佳實踐:
import openai
# 快速代碼补全
response = openai.chat.completions.create(
model="gpt-5.1",
reasoning_effort="none", # 极速响应
messages=[
{"role": "user", "content": "补全这个函数: def calculate_tax("}
]
)
# 複雜代碼生成
response = openai.chat.completions.create(
model="gpt-5.1-codex",
reasoning_effort="high", # 最高準確率
prompt_cache_retention="24h", # 启用扩展缓存
messages=[
{"role": "user", "content": "生成完整的订单管理系統 API"}
]
)
智能客服与企業自動化
Claude Opus 4.5 推薦場景
複雜客服問題處理:
- 應用: 技術支持、售後服务、投诉處理
- 優勢: 深度推理 12 步,逻辑一致性 9.1/10
- 推薦配置:
effort='medium',平衡速度与質量
企業级工作流自動化:
- 應用: RPA、數據處理、跨系統集成
- 優勢: 长上下文 200K tokens,適合複雜工作流
- 推薦配置:
effort='medium',持續穩定运行
GPT-5.1 推薦場景
快速客服响应:
- 應用: 在線客服、FAQ 機器人
- 優勢: '无推理'模式,低延遲响应
- 案例: Pace (AI 保险 BPO) 速度提升 50%
- 推薦配置:
reasoning_effort='none',极速交互
客服智能路由:
- 應用: 航空、电信、零售客服
- 優勢: Tau²-bench 电信場景 95.6% 準確率
- 推薦配置:
reasoning_effort='low',快速準確
实际案例:
# API易平台統一接口調用
# 場景1: 複雜技術問題 (使用 Claude Opus 4.5)
response = client.chat.completions.create(
model="claude-opus-4-5-20251101",
messages=[{"role": "user", "content": "用户报告系統性能下降,请分析日志并给出解決方案"}],
effort="high"
)
# 場景2: 快速FAQ响应 (使用 GPT-5.1)
response = client.chat.completions.create(
model="gpt-5.1",
reasoning_effort="none",
messages=[{"role": "user", "content": "如何重置密码?"}]
)
數據分析与研究辅助
Claude Opus 4.5 推薦場景
複雜數據分析:
- 應用: 多维數據分析、因果關係推断
- 優勢: 因果分析準確性 88%,逻辑一致性 9.1/10
- 推薦配置:
effort='high',深度分析
技術文檔生成:
- 應用: API 文檔、技術报告、用户手册
- 優勢: 长上下文 200K tokens,完整理解代碼庫
- 推薦配置:
effort='medium',質量穩定
GPT-5.1 推薦場景
数学与科學推理:
- 應用: 数学竞赛辅导、科學問題解答
- 優勢: AIME 2025 达 94%,GPQA Diamond 88.1%
- 推薦配置:
reasoning_effort='high',最高準確率
多模态內容理解:
- 應用: 图文混合內容分析
- 優勢: MMMU 评测 85.4%
- 推薦配置:
reasoning_effort='medium',綜合理解
🚀 快速開始: 對於需要同時使用 Claude Opus 4.5 和 GPT-5.1 的開發者,推薦通過 API易 apiyi.com 平台的統一 SDK。平台提供 OpenAI 兼容接口,一套代碼即可調用所有模型,根據任务類型智能切換,享受 Claude 2-3 折、GPT-5.1 8 折的优惠價格,綜合降低成本 40%-60%。
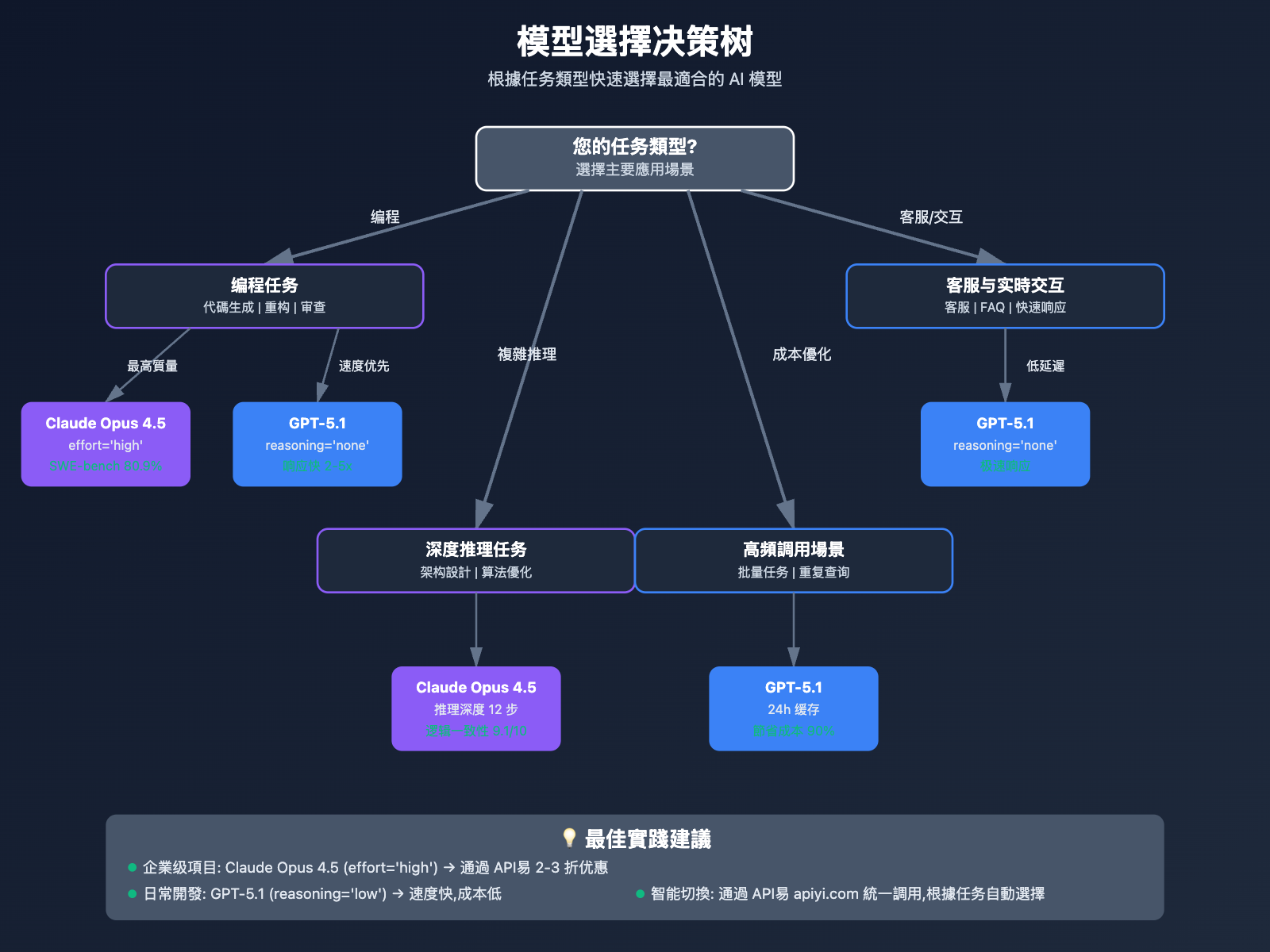
選擇决策树
根據任务類型選擇
選擇 Claude Opus 4.5 的場景
✅ 最高编程準確率需求 (SWE-bench 80.9%):
- 企業级生產代碼開發
- 關鍵业务逻辑實現
- 安全敏感的應用開發
✅ 大型代碼庫重构:
- 15 万行以上代碼重构
- 跨语言代碼迁移
- 技術栈升级
✅ 深度逻辑推理任务:
- 系統架构設計
- 複雜算法優化
- 因果關係分析 (88% 準確性)
✅ 長期自主任务:
- 自主代理工作流 (Vending-Bench 87.7%)
- 浏览器自動化 (BrowseComp-Plus 84%)
- 自我改进型智能体 (4 次迭代达峰值)
✅ 长上下文理解 (200K tokens):
- 完整代碼庫分析
- 大型技術文檔生成
- 多轮技術對話
選擇 GPT-5.1 的場景
✅ 速度优先需求 (响应速度提升 2-5 倍):
- 实時代碼补全
- 快速客服响应
- 低延遲交互應用
✅ 成本優化需求 (基礎定价低 60-75%):
- 高頻 API 調用場景
- 批量自動化任务
- 預算受限的初创團隊
✅ 缓存優化場景 (24 小時缓存保留):
- 长時間编程會话
- 多轮對話系統
- 重复查询場景
✅ 工具集成需求:
- GitHub Copilot 深度用户
- Cursor、JetBrains 等 IDE 集成
- 已有 OpenAI 生态系統
✅ 数学与科學推理:
- 数学竞赛辅导 (AIME 94%)
- 科學問題解答 (GPQA 88.1%)
- 前沿数学研究 (FrontierMath 26.7%)
組合使用策略
推薦工作流 (通過 API易平台統一調用):
from apiyi import APIYI
client = APIYI(api_key="YOUR_APIYI_API_KEY")
def intelligent_model_selection(task_type, complexity):
"""根據任务類型和複雜度智能選擇模型"""
if complexity == "high" and task_type in ["code_refactor", "architecture"]:
# 高複雜度代碼任务 → Claude Opus 4.5
return {
"model": "claude-opus-4-5-20251101",
"effort": "high"
}
elif task_type == "code_completion" or complexity == "low":
# 代碼补全或簡單任务 → GPT-5.1 (无推理模式)
return {
"model": "gpt-5.1",
"reasoning_effort": "none"
}
elif task_type == "customer_service":
# 客服場景 → GPT-5.1 (低推理模式)
return {
"model": "gpt-5.1",
"reasoning_effort": "low",
"prompt_cache_retention": "24h"
}
elif task_type == "math_reasoning":
# 数学推理 → GPT-5.1 (高推理模式)
return {
"model": "gpt-5.1",
"reasoning_effort": "high"
}
else:
# 默认平衡選擇 → Claude Opus 4.5 (中努力)
return {
"model": "claude-opus-4-5-20251101",
"effort": "medium"
}
# 示例使用
config = intelligent_model_selection("code_refactor", "high")
response = client.chat.completions.create(
**config,
messages=[{"role": "user", "content": "重构这段代碼"}]
)
成本優化建議:
- 簡單任务: GPT-5.1 (reasoning_effort='none') – 最低成本
- 中等任务: GPT-5.1 (reasoning_effort='low') 或 Claude (effort='low') – 平衡選擇
- 複雜任务: Claude Opus 4.5 (effort='high') – 最高質量
- 重复查询: GPT-5.1 + 24h 缓存 – 最大化缓存收益
- 长上下文: Claude Opus 4.5 (200K tokens) – 更强理解
常见問題解答
問題 1: Claude Opus 4.5 和 GPT-5.1 哪个编程能力更强?
回答: Claude Opus 4.5 在绝对编程準確率上領先。
數據對比:
- Claude Opus 4.5: SWE-bench Verified 80.9% (業界第一)
- GPT-5.1 (high): SWE-bench Verified 76.3%
- 領先幅度: Claude 領先 +4.6%
但是,GPT-5.1 在靈活性和速度上占优:
- 簡單任务响应速度提升 2-5 倍
- Token 消耗降低 70-88% (簡單任务)
- 多档推理模式,靈活权衡速度与質量
推薦:
- 追求最高準確率 → Claude Opus 4.5
- 需要快速响应 → GPT-5.1 (reasoning_effort='none' 或 'low')
- 預算受限 → GPT-5.1 (基礎定价低 60-75%)
問題 2: 成本方面哪个更划算?
回答: GPT-5.1 基礎定价更低,但綜合成本取决于具体使用場景。
基礎定价對比:
- GPT-5.1: $1.25/$10 (输入/輸出)
- Claude Opus 4.5: $5/$25 (输入/輸出)
- GPT-5.1 基礎定价低 60-75%
通過 API易平台優化後:
- Claude Opus 4.5: 约 2-3 折 (生成 500 行代碼约 ¥2.0-3.0)
- GPT-5.1: 约 8 折 (生成 500 行代碼约 ¥2.2)
- 綜合成本接近,GPT-5.1 略低
成本優化策略:
- 高頻重复調用: GPT-5.1 + 24h 缓存 (節省 90%)
- 簡單任务批量: Claude (effort='low') 或 GPT-5.1 (reasoning_effort='none')
- 複雜任务少量: Claude (effort='high') 確保質量,避免重复調用
問題 3: 如何在 API易平台同時使用两个模型?
回答: API易 apiyi.com 平台提供統一的 OpenAI 兼容接口,一个 API Key 即可調用所有模型。
示例代碼:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# 調用 Claude Opus 4.5
response1 = client.chat.completions.create(
model="claude-opus-4-5-20251101",
messages=[{"role": "user", "content": "複雜重构任务"}],
extra_body={"effort": "high"}
)
# 調用 GPT-5.1
response2 = client.chat.completions.create(
model="gpt-5.1",
messages=[{"role": "user", "content": "快速代碼补全"}],
extra_body={"reasoning_effort": "none"}
)
優勢:
- 一个 API Key 調用所有模型
- 統一的錯誤處理和重试机制
- 人民币结算,無需海外信用卡
- 享受 Claude 2-3 折、GPT-5.1 8 折优惠
問題 4: 响应速度哪个更快?
回答: 取决于推理模式。
Claude Opus 4.5:
- Low Effort: 5-10 秒
- Medium Effort: 10-20 秒
- High Effort: 15-30 秒
GPT-5.1:
- reasoning_effort='none': 2-5 秒 (最快,比 GPT-5 快 2-5 倍)
- reasoning_effort='low': 5-10 秒
- reasoning_effort='medium': 10-20 秒
- reasoning_effort='high': 20-40 秒
结论:
- 最快: GPT-5.1 (reasoning_effort='none') – 適合代碼补全、快速客服
- 平衡: Claude (effort='medium') 或 GPT-5.1 (reasoning_effort='low')
- 質量优先: Claude (effort='high') – 响应時間略长,但準確率最高
問題 5: 哪个更適合初学者?
回答: 两者都適合,但侧重点不同。
Claude Opus 4.5 更適合:
- ✅ 追求最高質量的学习者
- ✅ 需要详细解释和推理过程的場景
- ✅ 希望代碼示例更符合最佳實踐
- ✅ 進行大型項目学习和實踐
GPT-5.1 更適合:
- ✅ 需要快速反馈的初学者
- ✅ 預算受限的学生和自学者
- ✅ 使用 GitHub Copilot 等工具的開發者
- ✅ 需要高頻查询和练习的場景
推薦起步方式:
- 在 API易 apiyi.com 注册并充值 ¥50-100
- 先測試 GPT-5.1 (reasoning_effort='low') 快速入门
- 對比 Claude Opus 4.5 (effort='medium') 的代碼質量
- 根據个人偏好和預算選擇主力模型
- 複雜問題使用 Claude,簡單查询使用 GPT-5.1
💡 選擇建議: 通過 API易 apiyi.com 平台可以低成本同時體驗两个模型。平台提供新用户优惠,充值 ¥100 即可充分測試两个模型的实际表現,找到最適合自己的 AI 编程助手。
總結与升级建議
Claude Opus 4.5 和 GPT-5.1 代表了 2025 年 AI 编程助手的两个技術方向,各有千秋:
Claude Opus 4.5 核心優勢:
- 绝对領先的编程能力: SWE-bench 80.9%,業界第一
- 深度推理能力: 12 步推理深度,因果分析 88%
- 长上下文處理: 200K tokens,適合大型代碼庫
- 長期自主任务: Vending-Bench 87.7%,4 次迭代达峰值
- 努力參數: 靈活权衡性能与成本,節省高达 50%
GPT-5.1 核心優勢:
- 响应速度快: 簡單任务速度提升 2-5 倍
- 成本低: 基礎定价比 Claude 低 60-75%
- 扩展缓存: 24 小時保留,節省 90% 成本
- 自適應推理: 自動調節思考深度,Token 消耗降低 70-88%
- 工具生态: 深度集成 GitHub Copilot、Cursor、JetBrains
選擇建議:
- 企業级高質量代碼開發 → Claude Opus 4.5 (effort='high')
- 日常開發和代碼补全 → GPT-5.1 (reasoning_effort='none' 或 'low')
- 大型代碼庫重构 → Claude Opus 4.5 (200K 上下文)
- 智能客服和实時交互 → GPT-5.1 ('无推理'模式,低延遲)
- 成本優化場景 → GPT-5.1 (24h 缓存 + 8 折优惠)
平台推薦:
- 統一接口: API易 apiyi.com 提供統一的 OpenAI 兼容接口
- 优惠定价: Claude 2-3 折,GPT-5.1 8 折,綜合節省 40%-60%
- 靈活切換: 一套代碼調用所有模型,根據任务智能選擇
- 企業服务: 支持批量充值、发票开具、企業级 SLA
🚀 快速開始: 推薦通過 API易 apiyi.com 平台同時體驗 Claude Opus 4.5 和 GPT-5.1。平台提供新用户充值优惠,¥100 即可充分測試两个模型在实际項目中的表現,找到最適合您的 AI 编程助手組合,實現性能与成本的最优平衡!
无论選擇哪个模型,Claude Opus 4.5 和 GPT-5.1 都代表了当前 AI 编程助手的最高水平,将显著提升開發效率、降低编程门槛、加速软件创新!