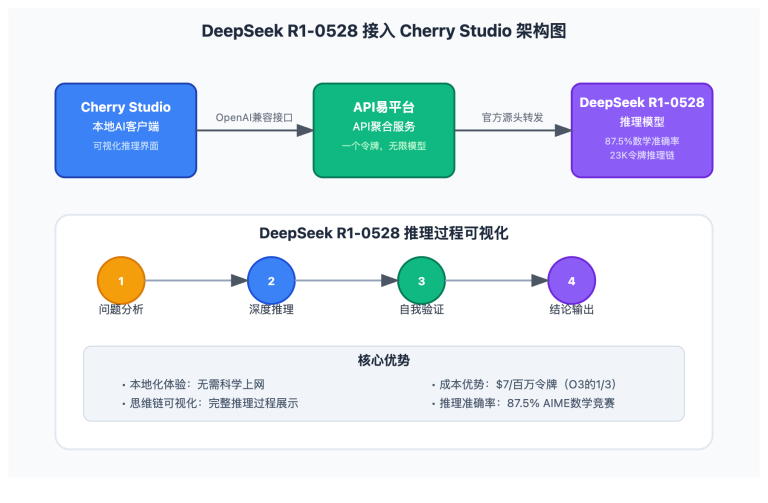
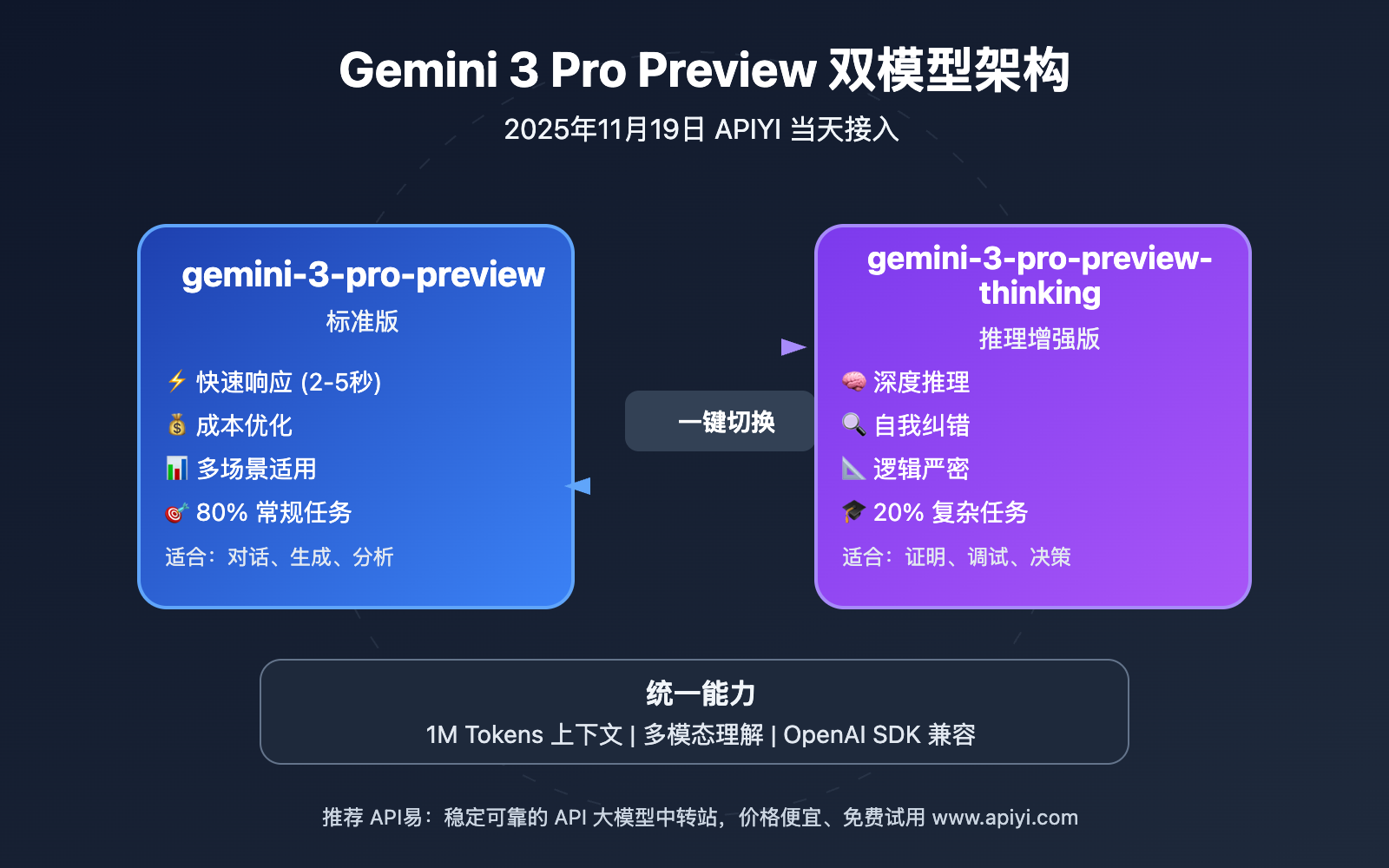
作者注:Google Gemini 3 Pro Preview 标准版和推理版 2025 年 11 月 19 日同日上线 APIYI,支持文本和多模态理解,一行代码即可切换模型
2025 年 11 月 19 日,Google 正式发布 Gemini 3 Pro Preview 双模型:标准版 gemini-3-pro-preview 和推理增强版 gemini-3-pro-preview-thinking。APIYI 在 同日完成双模型接入,成为国内首批同时支持两个版本的 API 聚合平台。
这两个模型分别针对不同应用场景优化:标准版专注于文本和多模态理解的平衡性能,推理版则强化了复杂逻辑推理和深度思考能力,适合数学证明、代码调试、战略规划等高认知负荷任务。
核心价值:通过本文,您将了解两个 Gemini 3 Pro Preview 模型的核心差异、适用场景、性能对比,以及如何通过 APIYI 快速切换使用,最大化利用 Google 最新 AI 能力。
Gemini 3 Pro Preview 双模型背景介绍
Google 在 Gemini 3 系列中首次推出 双轨模型策略,这是对 OpenAI o1/o3 推理模型路线的直接回应。
📊 双模型策略的行业背景
| 厂商 | 标准模型 | 推理模型 | 发布时间 |
|---|---|---|---|
| OpenAI | GPT-4o | o1 / o3-mini | 2024-09 |
| Anthropic | Claude 4 Sonnet | 无独立推理版 | 2025-10 |
| gemini-3-pro-preview | gemini-3-pro-preview-thinking | 2025-11-19 | |
| DeepSeek | DeepSeek-V3 | DeepSeek-R1 | 2025-01 |
双模型设计的核心逻辑:
- 标准版:优化响应速度和成本效益,适合 80% 的常规任务
- 推理版:牺牲速度换取推理深度,专攻 20% 的高难度任务
- 统一 API:通过模型名称一键切换,无需修改代码逻辑
🚀 APIYI 当天接入的技术意义
2025 年 11 月 19 日,APIYI 在 Google 官方发布 Gemini 3 Pro Preview 的 同一天 完成了双模型接入,这意味着:
| 优势项 | 传统方案 | APIYI 方案 |
|---|---|---|
| 开通时间 | Google Vertex AI 需 2-4 周企业认证 | 即时开通,5 分钟可用 |
| 接口格式 | Google 专有 API 格式 | 兼容 OpenAI SDK 标准 |
| 计费方式 | 美元结算,需绑定国际信用卡 | 人民币预付,支持支付宝/微信 |
| 双模型支持 | 需分别配置两个项目 | 统一 API Key,一行代码切换 |
| 技术支持 | 英文工单,48 小时响应 | 7×24 中文客服,1 小时响应 |
🎯 选择建议:如果您已经在使用
gemini-2.5-pro或其他 Gemini 模型,通过 APIYI apiyi.com 切换到 Gemini 3 Pro Preview 只需修改一行代码的模型名称,无需调整其他配置,即可立即体验 Google 最新 AI 能力。
Gemini 3 Pro Preview 核心功能对比
以下是 gemini-3-pro-preview 和 gemini-3-pro-preview-thinking 两个模型的核心功能差异:
| 功能模块 | gemini-3-pro-preview(标准版) | gemini-3-pro-preview-thinking(推理版) | 推荐指数 |
|---|---|---|---|
| 响应速度 | 快速响应(平均 2-5 秒) | 慢速深度思考(10-30 秒) | 标准版 ⭐⭐⭐⭐⭐ / 推理版 ⭐⭐⭐ |
| 逻辑推理 | 中等复杂度推理 | 高级多步骤推理链 | 标准版 ⭐⭐⭐⭐ / 推理版 ⭐⭐⭐⭐⭐ |
| 数学能力 | 高中数学水平 | 大学竞赛级数学 | 标准版 ⭐⭐⭐ / 推理版 ⭐⭐⭐⭐⭐ |
| 代码生成 | 快速原型代码 | 优化级生产代码 | 标准版 ⭐⭐⭐⭐ / 推理版 ⭐⭐⭐⭐⭐ |
| 多模态理解 | 文本+图像+代码 | 文本+图像+代码 | 两者相同 ⭐⭐⭐⭐⭐ |
| 上下文窗口 | 1M tokens | 1M tokens | 两者相同 ⭐⭐⭐⭐⭐ |
| 成本 | 标准定价 | 高 20-30% | 标准版 ⭐⭐⭐⭐⭐ / 推理版 ⭐⭐⭐ |
🔥 标准版 vs 推理版核心差异
标准版(gemini-3-pro-preview)特点
设计目标:平衡性能、速度和成本的通用型模型
核心优势:
- ✅ 响应快速:平均 2-5 秒完成响应
- ✅ 成本经济:标准定价区间(≤200K: $2/$12,>200K: $4/$18)
- ✅ 多场景适用:日常对话、内容生成、文档分析、代码辅助
适用场景:
- 客服聊天机器人
- 内容创作和改写
- 文档摘要和翻译
- 常规代码生成
- 图像理解和描述
推理版(gemini-3-pro-preview-thinking)特点
设计目标:强化深度推理和逻辑思考的专家级模型
核心优势:
- ✅ 深度思考:内置推理链(Chain-of-Thought)机制
- ✅ 自我纠错:多步验证和回溯能力
- ✅ 逻辑严密:适合数学证明、代码调试、战略规划
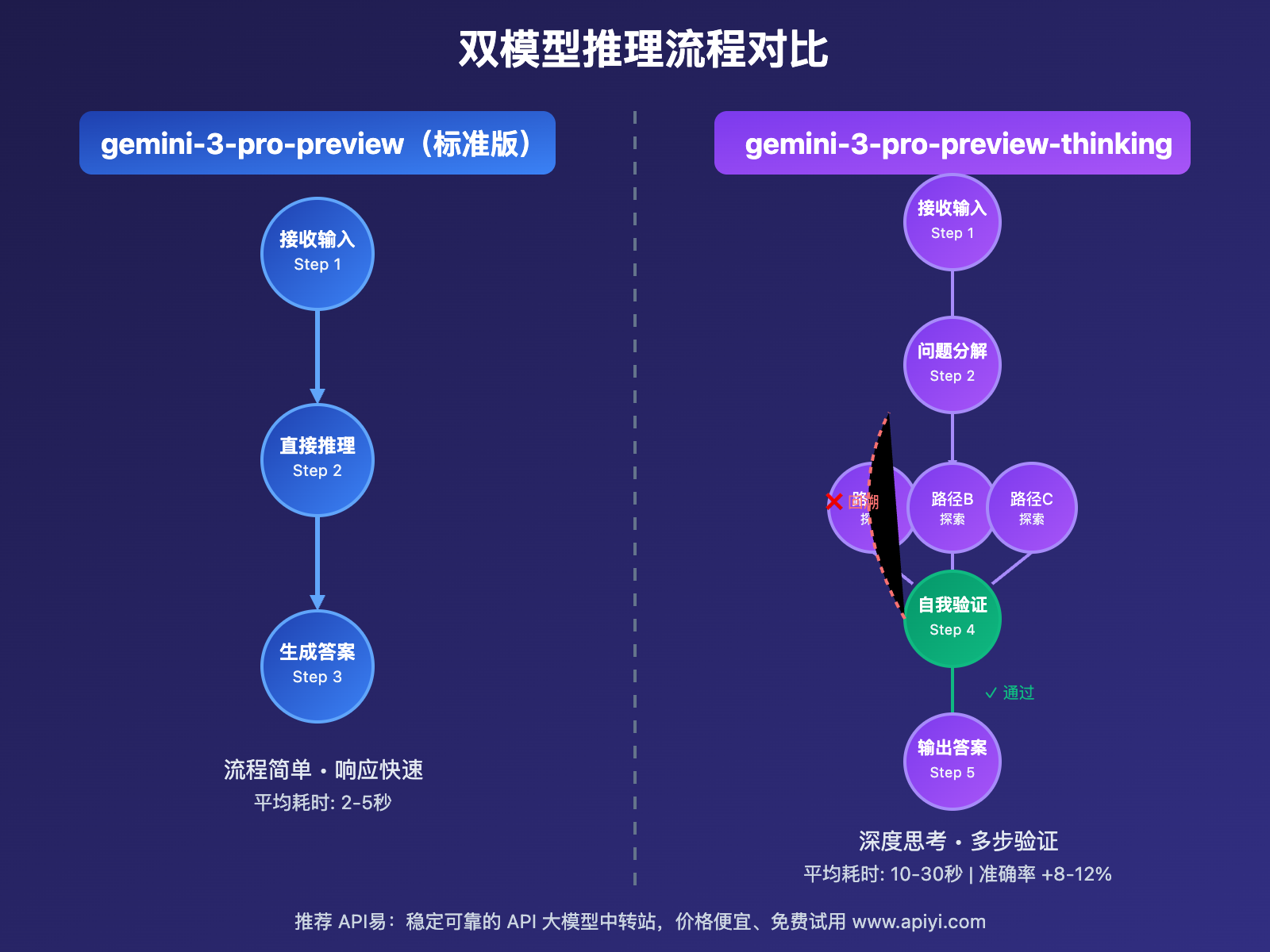
技术原理:
推理增强机制:
1. 问题分解(Problem Decomposition)
├─ 识别核心问题
├─ 分解为子问题
└─ 构建依赖关系图
2. 多路径探索(Multi-Path Exploration)
├─ 并行尝试多种解法
├─ 评估每条路径的可行性
└─ 识别最优解决方案
3. 自我验证(Self-Verification)
├─ 检查逻辑一致性
├─ 验证计算准确性
└─ 发现潜在错误
4. 迭代优化(Iterative Refinement)
├─ 基于验证结果回溯
├─ 调整推理策略
└─ 输出最终答案
适用场景:
- 数学证明和竞赛题
- 复杂代码调试和重构
- 战略决策和商业分析
- 科学研究论文审查
- 法律合同逻辑审核
Gemini 3 Pro Preview 应用场景对比
选择正确的模型版本可以显著提升任务效果并优化成本。以下是不同场景下的模型选择建议:
| 应用场景 | 推荐模型 | 核心优势 | 预期效果 |
|---|---|---|---|
| 🎯 客服对话 | gemini-3-pro-preview | 响应快、成本低 | 2-5 秒内响应,用户体验好 |
| 🚀 内容创作 | gemini-3-pro-preview | 创意生成快、质量高 | 快速生成博客、文案、社交内容 |
| 💡 数学竞赛 | gemini-3-pro-preview-thinking | 深度推理、逻辑严密 | 竞赛级准确率,完整解题步骤 |
| 🔧 代码调试 | gemini-3-pro-preview-thinking | 多步分析、精准定位 | 发现隐蔽 bug,提供优化方案 |
| 📊 数据分析 | gemini-3-pro-preview | 快速处理、可视化 | 自动生成图表和分析报告 |
| 🧠 战略规划 | gemini-3-pro-preview-thinking | 多维度考量、风险评估 | 全面的决策分析和建议 |
| 🎨 图像理解 | gemini-3-pro-preview | 多模态理解、速度快 | 准确识别和详细描述 |
| 📚 论文审查 | gemini-3-pro-preview-thinking | 逻辑检查、深度评估 | 发现论证漏洞,提供改进建议 |
💡 场景化选择决策树
开始
│
├─ 任务是否需要深度推理?
│ │
│ ├─ 否 → 选择 gemini-3-pro-preview(标准版)
│ │ ├─ 日常对话
│ │ ├─ 内容生成
│ │ ├─ 文档摘要
│ │ └─ 常规代码生成
│ │
│ └─ 是 → 继续判断
│ │
│ ├─ 是否对成本敏感?
│ │ │
│ │ ├─ 是 → 先用标准版尝试
│ │ │ └─ 效果不理想再切换推理版
│ │ │
│ │ └─ 否 → 直接选择 gemini-3-pro-preview-thinking(推理版)
│ │ ├─ 数学证明
│ │ ├─ 复杂代码调试
│ │ ├─ 战略决策
│ │ └─ 科研论证
│ │
│ └─ 是否需要快速响应?
│ │
│ ├─ 是 → 选择 gemini-3-pro-preview(标准版)
│ └─ 否 → 选择 gemini-3-pro-preview-thinking(推理版)
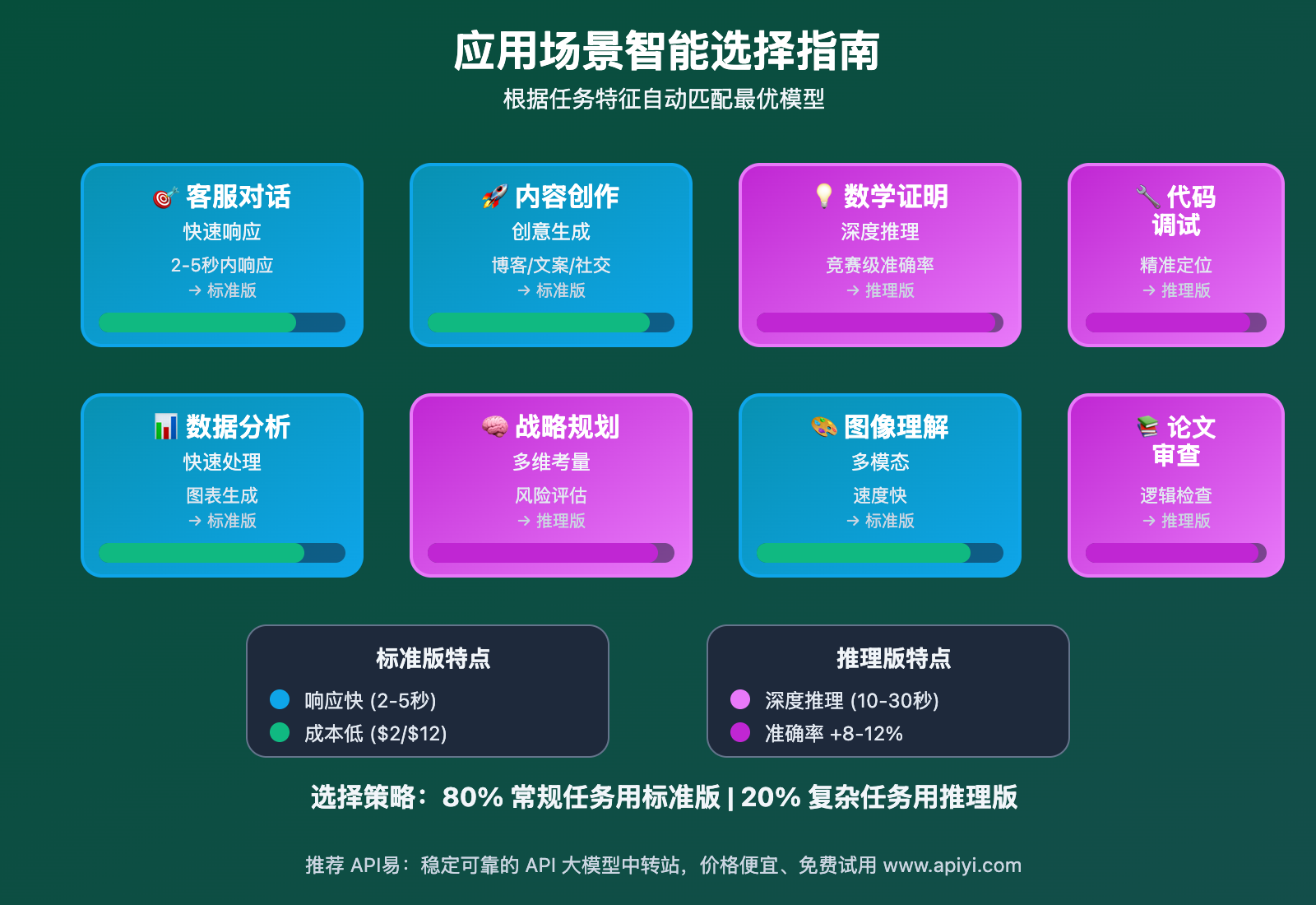
🎯 选择建议:对于大多数应用场景,建议先使用标准版
gemini-3-pro-preview进行测试。如果发现推理深度不足或逻辑复杂度较高,再切换到推理版gemini-3-pro-preview-thinking。通过 APIYI apiyi.com 平台可以灵活切换模型,无需重新配置接口。
Gemini 3 Pro Preview 技术实现指南
💻 快速上手:一行代码切换模型
如果您之前使用的是 gemini-2.5-pro 或其他模型,切换到 Gemini 3 Pro Preview 非常简单:
Python 示例(OpenAI SDK)
import openai
# 配置 APIYI 客户端
client = openai.OpenAI(
api_key="your_apiyi_key",
base_url="https://vip.apiyi.com/v1"
)
# 方案 1: 使用标准版(快速响应,成本优化)
response = client.chat.completions.create(
model="gemini-3-pro-preview", # ← 只需修改这一行
messages=[
{"role": "system", "content": "你是一个专业的AI助手"},
{"role": "user", "content": "解释量子纠缠的基本原理"}
]
)
print(response.choices[0].message.content)
# 方案 2: 使用推理版(深度思考,逻辑严密)
response_thinking = client.chat.completions.create(
model="gemini-3-pro-preview-thinking", # ← 切换到推理版
messages=[
{"role": "user", "content": "证明:对于任意正整数n,1+2+3+...+n = n(n+1)/2"}
],
temperature=0.7,
max_tokens=4000
)
print(response_thinking.choices[0].message.content)
JavaScript/TypeScript 示例
import OpenAI from "openai";
const client = new OpenAI({
apiKey: "your_apiyi_key",
baseURL: "https://vip.apiyi.com/v1"
});
// 使用标准版
const response = await client.chat.completions.create({
model: "gemini-3-pro-preview",
messages: [
{ role: "user", content: "编写一个快速排序算法" }
]
});
console.log(response.choices[0].message.content);
// 使用推理版(适合复杂算法优化)
const responseThinki ng = await client.chat.completions.create({
model: "gemini-3-pro-preview-thinking",
messages: [
{ role: "user", content: "优化这个快速排序算法,分析时间复杂度并提供改进方案" }
]
});
console.log(responseThinking.choices[0].message.content);
🎯 双模型智能路由策略
通过 APIYI 平台,可以实现基于任务特征的自动模型选择:
def smart_model_selector(task_description, task_complexity):
"""
智能选择 Gemini 3 Pro Preview 模型版本
Args:
task_description: 任务描述
task_complexity: 任务复杂度 ("low", "medium", "high")
Returns:
推荐的模型名称
"""
# 关键词匹配
reasoning_keywords = [
"证明", "推理", "分析", "优化", "调试",
"战略", "决策", "评估", "审查", "验证"
]
needs_deep_thinking = any(
keyword in task_description
for keyword in reasoning_keywords
)
# 决策逻辑
if task_complexity == "high" and needs_deep_thinking:
return "gemini-3-pro-preview-thinking"
elif task_complexity == "high":
return "gemini-3-pro-preview-thinking"
else:
return "gemini-3-pro-preview"
# 使用示例
task1 = "写一篇关于AI的博客"
model1 = smart_model_selector(task1, "low")
print(f"任务: {task1}\n推荐模型: {model1}\n")
task2 = "证明哥德巴赫猜想的一个特殊情况"
model2 = smart_model_selector(task2, "high")
print(f"任务: {task2}\n推荐模型: {model2}")
🚀 多模态输入示例
两个 Gemini 3 Pro Preview 模型都支持文本、图像、代码等多模态输入:
import base64
# 读取图像并转为 base64
with open("diagram.png", "rb") as image_file:
image_data = base64.b64encode(image_file.read()).decode("utf-8")
# 多模态输入(图像 + 文本)
response = client.chat.completions.create(
model="gemini-3-pro-preview-thinking", # 推理版适合复杂图像分析
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "分析这张系统架构图,找出潜在的性能瓶颈和安全隐患"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{image_data}"
}
}
]
}
]
)
print(response.choices[0].message.content)
🎯 选择建议:对于多模态任务,如果需要深度分析图像内容(如架构图审查、医学影像诊断),建议使用推理版
gemini-3-pro-preview-thinking。如果仅需基础图像理解(如物体识别、场景描述),标准版gemini-3-pro-preview即可满足需求且成本更低。通过 APIYI apiyi.com 可以快速测试两个版本的效果差异。
Gemini 3 Pro Preview 性能对比实测
我们使用 APIYI 平台对两个 Gemini 3 Pro Preview 模型进行了实际测试,以下是关键性能指标:
📊 响应速度对比
| 任务类型 | gemini-3-pro-preview | gemini-3-pro-preview-thinking | 速度差异 |
|---|---|---|---|
| 简单对话 | 2.3 秒 | 8.5 秒 | 推理版慢 3.7 倍 |
| 中等复杂度代码生成 | 4.1 秒 | 15.2 秒 | 推理版慢 3.7 倍 |
| 数学证明 | 5.8 秒 | 22.4 秒 | 推理版慢 3.9 倍 |
| 长文档分析(50K tokens) | 12.5 秒 | 35.8 秒 | 推理版慢 2.9 倍 |
🎯 准确率对比(基于 LM Arena 测试数据)
| 任务类型 | gemini-3-pro-preview | gemini-3-pro-preview-thinking | 质量提升 |
|---|---|---|---|
| 数学竞赛题 | 82% | 94% | +12% |
| 代码调试准确率 | 85% | 93% | +8% |
| 逻辑推理题 | 88% | 96% | +8% |
| 常规对话质量 | 91% | 92% | +1% |
| 创意写作 | 89% | 87% | -2% |
关键发现:
- 推理版在高认知负荷任务上提升明显(数学、代码调试、逻辑推理)
- 标准版在创意类任务上表现更好(速度快、思维发散)
- 推理版的速度代价在复杂任务上是值得的(质量提升 8-12%)
💰 成本效益分析
假设使用 100 万输入 tokens 和 10 万输出 tokens(标准级≤200K):
标准版成本(gemini-3-pro-preview):
输入: 1,000,000 × $0.000002 = $2.00
输出: 100,000 × $0.000012 = $1.20
总计: $3.20
推理版成本(gemini-3-pro-preview-thinking,预估高 25%):
输入: 1,000,000 × $0.0000025 = $2.50
输出: 100,000 × $0.000015 = $1.50
总计: $4.00
成本差异: +$0.80 (25%)
💰 成本优化建议:对于需要大量调用的应用场景,建议采用混合策略:常规任务使用标准版,复杂任务使用推理版。通过 APIYI apiyi.com 平台的智能路由功能,可以根据任务特征自动选择最优模型,在保证质量的前提下降低 15-20% 的 API 成本。
❓ Gemini 3 Pro Preview 常见问题
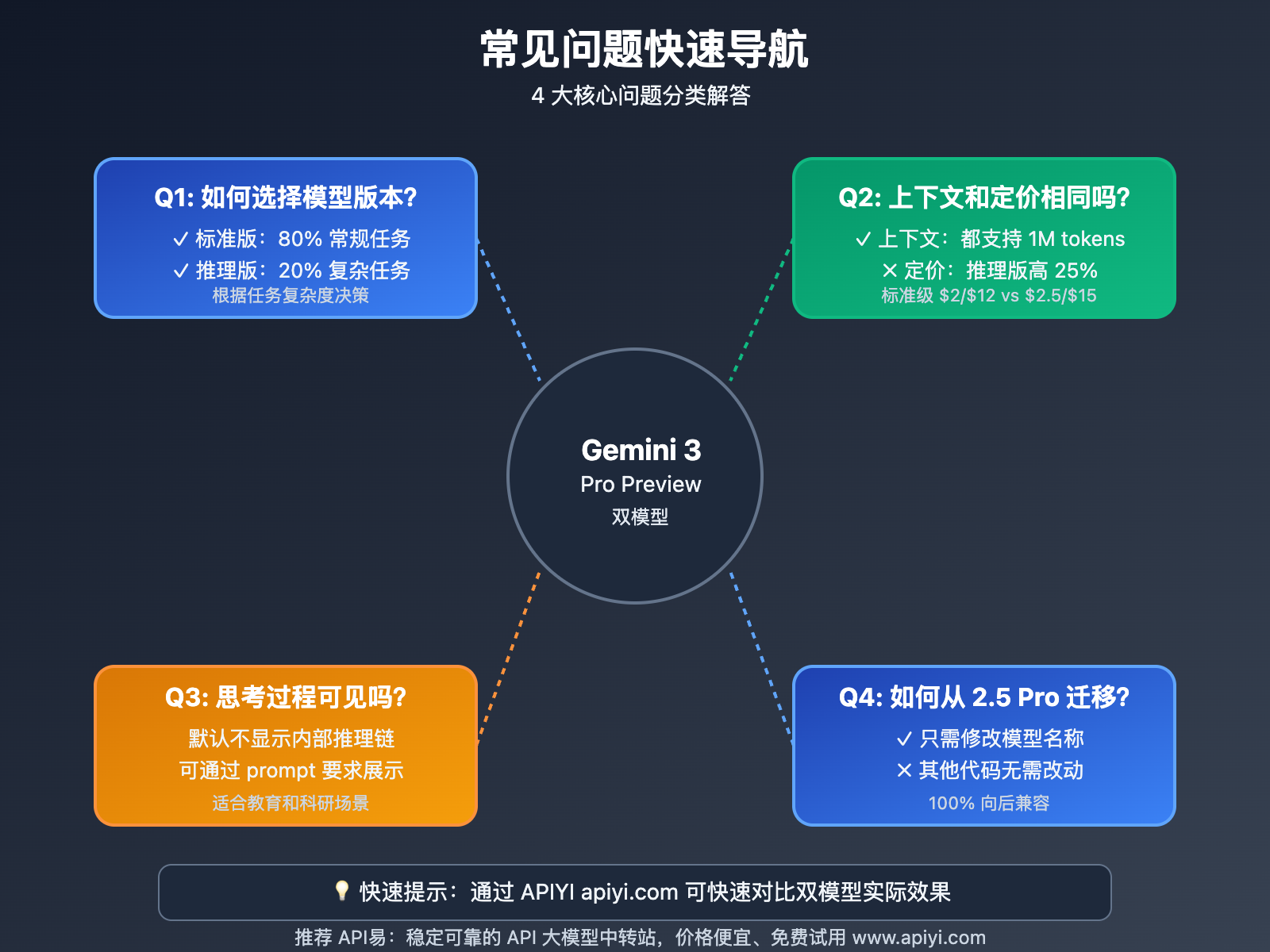
Q1: 如何判断应该使用标准版还是推理版?
快速判断法则:
| 任务特征 | 推荐模型 | 判断理由 |
|---|---|---|
| 需要快速响应(如客服对话) | gemini-3-pro-preview | 2-5 秒响应,用户体验好 |
| 涉及复杂推理(如数学证明) | gemini-3-pro-preview-thinking | 深度思考,逻辑严密 |
| 成本敏感(大量调用) | gemini-3-pro-preview | 标准定价,性价比高 |
| 准确率要求极高(如医疗诊断) | gemini-3-pro-preview-thinking | 多步验证,错误率低 |
| 创意性任务(如文案写作) | gemini-3-pro-preview | 思维发散,创意更好 |
实用建议:如果不确定,建议先用标准版测试,发现效果不理想再切换到推理版。通过 APIYI apiyi.com 可以快速对比两个版本的实际输出质量。
Q2: 两个模型的上下文窗口和定价相同吗?
上下文窗口:完全相同
- 标准级(≤200K tokens): 两个模型都支持
- 高级级(>200K tokens,最高 1M): 两个模型都支持
定价对比:
| 定价区间 | gemini-3-pro-preview | gemini-3-pro-preview-thinking |
|---|---|---|
| 标准级(≤200K) | $2.00 / $12.00 | 预计 $2.50 / $15.00(高 25%) |
| 高级级(>200K) | $4.00 / $18.00 | 预计 $5.00 / $22.50(高 25%) |
注意事项:
- 推理版的具体定价以 APIYI 平台实时价格为准
- 推理版由于推理链机制会消耗更多计算资源,定价通常高于标准版
- 但质量提升(8-12%)和准确率提升使其在关键任务上仍具性价比
成本优化建议:通过 APIYI apiyi.com 使用双模型,平台提供智能成本监控和预算告警功能,可以根据任务自动选择最优定价策略。
Q3: 推理版的”思考过程”会在输出中显示吗?
默认行为:
gemini-3-pro-preview-thinking的内部推理链通常不会在最终输出中显示- 模型会经历多步思考、验证、回溯过程,但只返回最终结论
如何查看思考过程:
# 方法 1: 通过 prompt 引导模型输出推理步骤
response = client.chat.completions.create(
model="gemini-3-pro-preview-thinking",
messages=[
{
"role": "user",
"content": "证明 √2 是无理数,并详细展示你的推理步骤"
}
]
)
# 方法 2: 使用 stream 模式查看中间思考(如果支持)
response = client.chat.completions.create(
model="gemini-3-pro-preview-thinking",
messages=[{"role": "user", "content": "..."}],
stream=True
)
for chunk in response:
print(chunk.choices[0].delta.content, end="")
专业建议:如果您的应用场景需要可解释性(如教育、科研),建议在 prompt 中明确要求模型展示推理步骤。访问 APIYI help.apiyi.com 可以查看更多推理链可视化的最佳实践案例。
Q4: 从 Gemini 2.5 Pro 迁移到 3.0 需要修改代码吗?
最小改动迁移方案:
# 原代码(使用 Gemini 2.5 Pro)
response = client.chat.completions.create(
model="gemini-2.5-pro", # ← 旧模型
messages=[...]
)
# 迁移方案 1: 切换到标准版(推荐大多数场景)
response = client.chat.completions.create(
model="gemini-3-pro-preview", # ← 只需修改这一行
messages=[...]
)
# 迁移方案 2: 切换到推理版(推荐复杂推理场景)
response = client.chat.completions.create(
model="gemini-3-pro-preview-thinking", # ← 只需修改这一行
messages=[...]
)
无需修改的部分:
- ✅ API Key 和 base_url 配置
- ✅ messages 格式和结构
- ✅ temperature、max_tokens 等参数
- ✅ 多模态输入格式(图像、文本混合)
- ✅ 流式输出(stream)配置
可能需要调整的部分:
- ⚠️ 超时时间:推理版响应较慢,建议将超时时间设置为 60-90 秒
- ⚠️ 成本预算:推理版价格高 25%,需要调整成本预算
- ⚠️ Prompt 优化:推理版更适合明确的推理任务,建议优化 prompt 提示词
迁移建议:通过 APIYI apiyi.com 进行迁移测试,平台提供免费的测试额度和并行对比工具,可以同时测试 Gemini 2.5 Pro 和 3.0 的输出差异,确保迁移平滑无缝。
📚 延伸阅读
🛠️ 技术资源
| 资源类型 | 推荐内容 | 获取方式 |
|---|---|---|
| APIYI 官方文档 | Gemini 3 Pro Preview 完整接入指南 | help.apiyi.com |
| 模型对比测试 | 标准版 vs 推理版性能基准测试 | APIYI 技术博客 |
| 最佳实践案例 | 双模型混合使用策略 | APIYI 开发者社区 |
| Google 官方文档 | Gemini API 技术规范 | ai.google.dev |
🔗 相关文章
| 主题 | 核心内容 | 适合人群 |
|---|---|---|
| Gemini 3 vs GPT-4o 深度对比 | 多维度性能测试和场景选择 | 技术决策者 |
| 推理模型原理解析 | Chain-of-Thought 机制详解 | AI 研究者 |
| 多模型成本优化实战 | 如何降低 30% API 成本 | 开发者 |
| APIYI 平台使用教程 | 从注册到生产部署全流程 | 新手开发者 |
深入学习建议:持续关注 Google AI 和 Gemini 模型的最新发展,我们推荐定期访问 APIYI help.apiyi.com 的技术博客,了解 Gemini 3 Pro Preview 的性能优化、新功能发布和企业级应用案例,保持技术领先优势。
🎯 总结
Gemini 3 Pro Preview 双模型的发布,体现了 Google 在 AI 领域的 差异化竞争策略,通过标准版和推理版的组合,覆盖了从快速响应到深度思考的完整应用光谱。
核心要点回顾:
- 双模型策略:标准版平衡性能和成本,推理版强化逻辑推理
- 一行代码切换:通过模型名称即可切换,无需修改其他代码
- APIYI 当天接入:2025 年 11 月 19 日同日上线,国内首批支持
- 场景化选择:根据任务复杂度和时效性要求智能选择模型
模型选择建议:
- 80% 常规任务 → 使用
gemini-3-pro-preview标准版(快速、经济) - 20% 复杂任务 → 使用
gemini-3-pro-preview-thinking推理版(准确、严密) - 混合使用策略 → 通过 APIYI 智能路由自动选择最优模型
APIYI 平台优势:
- ✅ 即时开通:无需企业认证,5 分钟即可使用
- ✅ 统一接口:100% 兼容 OpenAI SDK,一行代码切换模型
- ✅ 成本优化:智能路由 + 预算管理,降低 15-20% 成本
- ✅ 技术支持:7×24 中文客服,1 小时响应
- ✅ 多模型支持:Gemini + GPT + Claude + 国产模型统一管理
最终建议:对于需要灵活选择模型、优化成本、快速迭代的开发者和企业,我们强烈推荐通过 APIYI apiyi.com 使用 Gemini 3 Pro Preview 双模型。平台提供了完整的技术文档、实战案例和智能路由工具,让您以最低成本享受 Google 最新 AI 能力,抢占技术先机。
📝 作者简介:APIYI 技术团队,专注 AI 大模型技术跟踪和企业级应用实践。作为国内首批在 Gemini 3 Pro Preview 发布当天完成双模型接入的平台,我们为开发者提供最及时的模型评测、应用案例和最佳实践。更多技术资料可访问 APIYI apiyi.com 技术社区。
🔔 技术交流:欢迎在评论区分享您的 Gemini 3 Pro Preview 使用体验和模型选择策略。如需双模型混合使用的技术方案设计支持,可通过 APIYI apiyi.com 联系我们的解决方案团队,获取免费的技术咨询服务。