一个有意思的发现~ 最近不少开发者在试用 MiniMax 2026 年 3 月发布的 M2.7 模型时,撞上了一个反直觉的问题:这款被称为"代码与 Agent 工作流之王"的旗舰模型,居然不支持图片输入。要知道,在 Claude 4、GPT-5、Gemini 3 都标配多模态能力的当下,一个 230B 参数的旗舰大模型不能识图确实让人意外。本文基于 MiniMax 官方文档、NVIDIA NIM 模型卡与 OpenRouter 公开规格,结合 API易 apiyi.com 在实际部署中的观察,深度解析 M2.7 "纯文本"定位背后的产品逻辑。

一、MiniMax M2.7 不支持图片输入是真的吗
先回答最直接的问题:是真的。根据 MiniMax 官方平台与 NVIDIA NIM 模型卡的公开规格,M2.7(包括 M2.7-highspeed 版本)目前仅支持文本输入,无法直接处理图像、音频或视频。这与上一代 M2.5 的纯文本定位一致,但与同期发布的 Claude 4 Opus、GPT-5、Gemini 3 系列"原生多模态"的主流形成鲜明对比。
1.1 MiniMax M2.7 的核心规格速览
M2.7 在 2026 年 3 月 18 日正式开放接口,采用 MoE(混合专家)架构,总参数 230B,激活参数 10B,主打"高性能 + 低成本"。
| 规格项 | 具体参数 |
|---|---|
| 发布日期 | 2026-03-18 |
| 架构类型 | MoE Transformer(256 专家,每 token 激活 8 个) |
| 总参数 / 激活参数 | 230B / 10B |
| 上下文窗口 | 204,800 tokens |
| 最大输出 | 131,072 tokens |
| 输入价格 | $0.279 / M tokens |
| 输出价格 | $1.20 / M tokens |
| 多模态支持 | ❌ 仅支持文本 |
| API 兼容 | Anthropic API + OpenAI API |
1.2 哪些场景下会"踩坑"
如果你的应用涉及截图问答、PDF 截图解析、商品图理解、UI 自动化视觉检测、多模态 RAG 中的图像检索等场景,直接调用 M2.7 会失败或得到无意义的输出。建议在路由层(如 LiteLLM、One API 或 API易 apiyi.com 这类统一中转网关)做模型类型判断,把图像类请求路由到 Claude、GPT-5 或 Gemini 3 系列再处理。
二、为什么 MiniMax M2.7 选择"纯文本"路线
M2.7 的纯文本定位不是技术能力不足,而是一个非常清晰的产品决策。MiniMax 此前已经发布过具备多模态能力的 abab 系列模型,完全有能力在 M 系列上加入视觉模块。但他们选择把 M2.7 的训练算力全部投入到"代码 + Agent"两个赛道,以换取在这两个方向上的极致表现。
2.1 代码与 Agent 是 M2.7 的核心战场
根据官方 README 与 NVIDIA 技术博客描述,M2.7 专门为"多文件编辑、代码-运行-修复循环、测试驱动的修复、跨 Shell/浏览器/检索/代码运行器的长链工具调用"优化。在 SWE-bench、Aider Polyglot、Terminal Bench 等真实编码任务上,M2.7 的成绩接近 Claude 4 Sonnet,但激活参数只有 10B,推理成本仅为后者的约 1/8。
2.2 纯文本路线 vs 多模态路线的权衡
把训练资源压在单一方向上,带来的是确定性的收益和损失。下表整理了两条路线的核心权衡点:
| 维度 | 纯文本路线(M2.7 / DeepSeek-R1) | 多模态路线(Claude/GPT/Gemini) |
|---|---|---|
| 训练成本 | 集中,效率高 | 分散,数据成本高 |
| 单位 token 价格 | 较低($0.28-2 / M) | 较高($3-15 / M) |
| 文本/代码推理深度 | 通常更强 | 略弱但够用 |
| 图像/视频理解 | 不支持 | 原生支持 |
| 适用场景广度 | 偏聚焦 | 更通用 |
| 工程接入复杂度 | 低 | 低-中 |
2.3 通过工具调用"补全"多模态能力
虽然 M2.7 本身不识图,但它原生支持 MCP(Model Context Protocol)和 Function Calling。这意味着开发者可以让 M2.7 把图像理解任务"外包"给专门的视觉模型(如 Claude 4 Opus 或 Gemini 3 Vision),自己只负责调度与最终推理。这种"主控 + 视觉协作"的架构在 Agent 系统里非常常见。
三、2026 年多模态 API 真的是行业标配吗
直观感受上,"多模态 = 标配"几乎成了 2026 年的行业共识。但深入观察主流模型阵营,会发现这个判断需要分层理解。
3.1 主流闭源旗舰几乎全部支持多模态
Anthropic 的 Claude 4 系列、OpenAI 的 GPT-5 系列、Google 的 Gemini 3 Pro/Ultra 都已经把图像作为基础输入能力。Gemini 3 在 ScreenSpot-Pro 测试上从前代 11.4% 一跃提升到 72.7%,可以直接"看懂"屏幕截图并操作 UI;Claude 4 也强化了图表识别与 PDF 解析能力。
3.2 开源/性价比阵营出现明显分化
开源阵营则呈现明显分化:一类是 Llama 3.2 Vision、Qwen3-VL、InternVL 等"全栈多模态"模型;另一类则是 DeepSeek-R1、MiniMax M2.7 等"专精文本/推理"的模型,通过聚焦获得性价比优势。这两类模型并不是简单的"高低之分",而是面向不同应用形态的差异化选择。
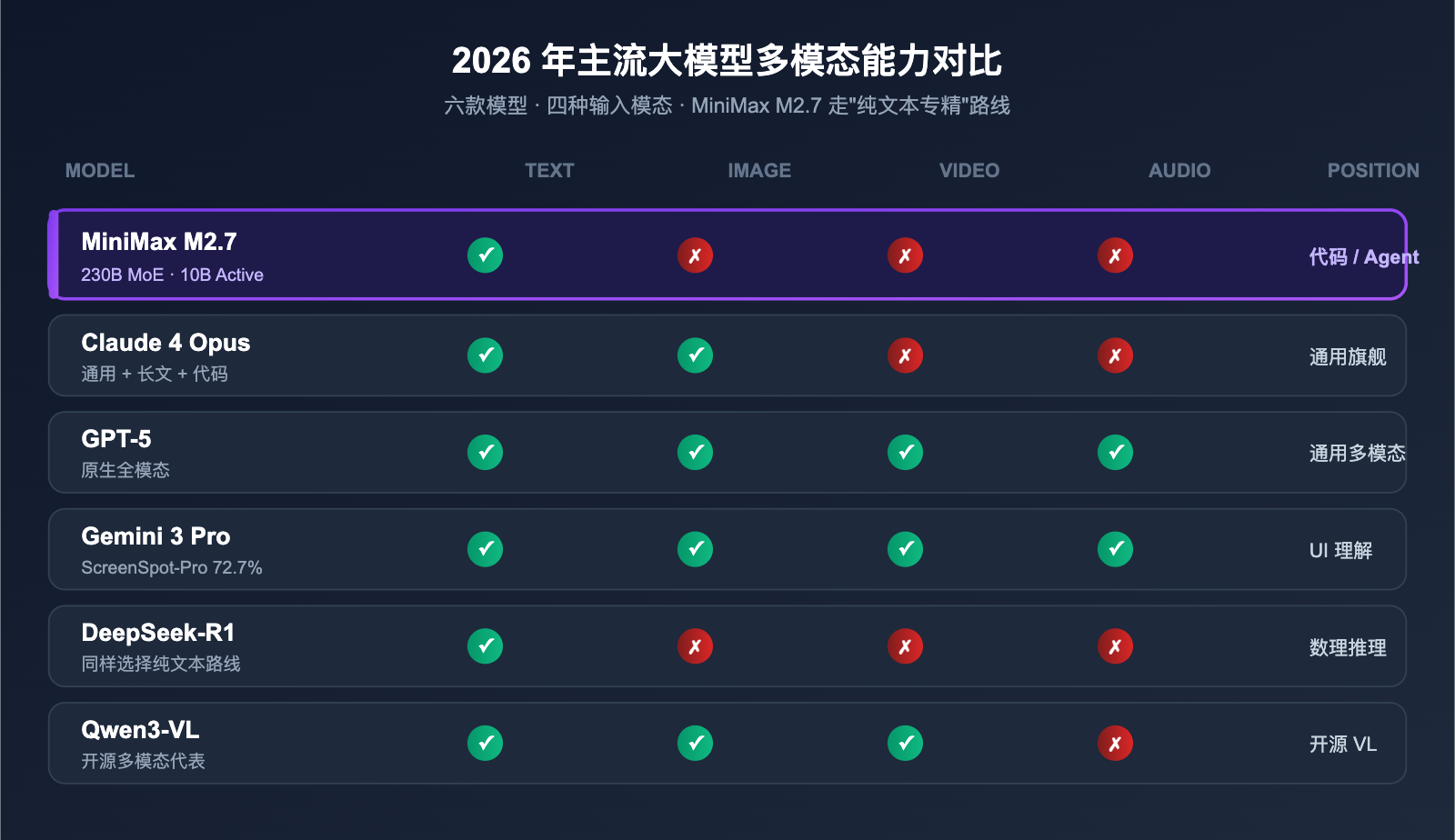
3.3 主流模型多模态能力对比
下表汇总了 2026 年 5 月主流大模型的多模态能力差异,可以快速看出 M2.7 在阵营中的定位:
| 模型 | 图像输入 | 视频输入 | 音频输入 | 主要定位 |
|---|---|---|---|---|
| MiniMax M2.7 | ❌ | ❌ | ❌ | 代码/Agent 推理 |
| Claude 4 Opus | ✅ | ❌ | ❌ | 通用 + 长文 + 代码 |
| GPT-5 | ✅ | ✅ | ✅ | 通用多模态 |
| Gemini 3 Pro | ✅ | ✅ | ✅ | 多模态 + UI 理解 |
| DeepSeek-R1 | ❌ | ❌ | ❌ | 数理推理 |
| Qwen3-VL | ✅ | ✅ | ❌ | 开源多模态 |
可以看出,"标配多模态"主要集中在闭源旗舰阵营。在开源与性价比阵营,专精文本仍然是一种有效的差异化路线。
四、没有原生视觉,如何让 MiniMax M2.7 处理图像
虽然 M2.7 自身不读图,但通过工具调用 + 路由的方式,完全可以构建"M2.7 主控 + 视觉模型协作"的混合架构,既享受 M2.7 的低成本,又不损失多模态体验。
4.1 推荐的混合调用架构
最常见的做法是:使用一个统一的网关(如 API易 apiyi.com 提供的多模型路由)把请求按内容类型分发。文本/代码请求走 M2.7,图像请求走 Claude 4 或 Gemini 3,再把视觉模型的输出文本回传给 M2.7 做最终推理与决策。这种架构对前端透明,无需修改业务侧的 SDK 调用方式。
4.2 Function Calling 中接入视觉模型
如果你的应用使用 Function Calling,可以为 M2.7 注册一个 analyze_image 工具,内部调用 Claude/GPT/Gemini 的视觉接口,把识别结果以 JSON 返回。M2.7 会根据用户请求自动判断何时调用这个工具,无需在 Prompt 层显式判断。这种模式适合 Agent 框架(如 LangGraph、CrewAI、OpenAI Agents SDK)。
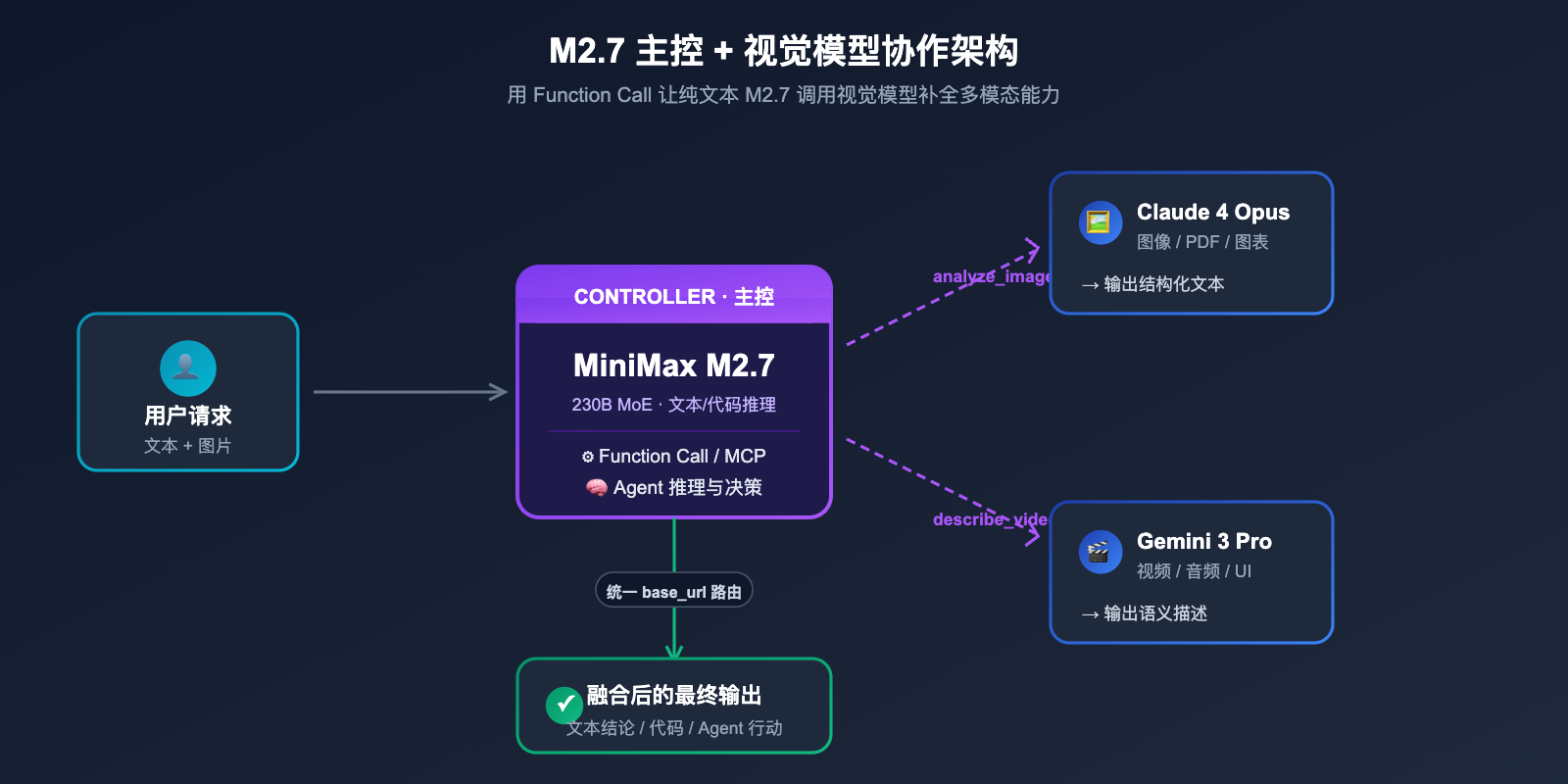
🎯 接入建议: 我们建议通过 API易 apiyi.com 一个 base_url 同时接入 M2.7 与多模态模型(如 Claude 4 Opus、Gemini 3 Pro),不再为每个厂商维护单独的 SDK 与密钥,可以大幅降低混合架构的工程复杂度,也方便统一观测 token 消耗与成本。
4.3 推荐的推理参数
MiniMax 官方推荐 M2.7 使用相对偏高的采样参数:temperature=1.0、top_p=0.95、top_k=40。这与多数模型的低温度建议不同,实测在编码与 Agent 场景下,这套参数能产出质量更高、更具创造性的代码补全。如果你之前的 Prompt 模板默认 temperature=0,在 M2.7 上反而可能拿到僵化、重复的输出,需要重新调优。
五、MiniMax M2.7 vs 多模态模型的选型决策
到底什么时候选 M2.7、什么时候选多模态旗舰?核心要看你的应用是"文本/代码主导"还是"多模态主导",而不是单纯比谁的参数更大。
5.1 文本/代码主导场景优选 M2.7
如果你的产品 90% 以上请求是文本类(代码生成、文档问答、Agent 编排、长文摘要),M2.7 是当下性价比最高的选择之一。230B 总参数带来的能力上限接近 Claude 4 Sonnet,但单位 token 价格只有后者的零头,对高并发的 SaaS 后端尤为友好。
5.2 多模态高频场景优选 Claude / Gemini
如果你的核心场景是图像理解(OCR、UI 自动化、商品识别、医疗影像辅助)、视频分析或音频处理,直接选 Claude 4 Opus、GPT-5 或 Gemini 3 Pro 会比"M2.7 + 视觉模型"的混合架构更简洁可靠,减少跨模型调用的延迟与失败率。
5.3 不同场景的选型建议
| 应用场景 | 优先模型 | 备选方案 |
|---|---|---|
| 代码生成 / 重构 | MiniMax M2.7 | Claude 4 Sonnet |
| Agent 工具调用 | MiniMax M2.7 | GPT-5 |
| 长文档问答(200K 以内) | MiniMax M2.7 | Claude 4 Opus |
| 图像 OCR / 截图问答 | Gemini 3 Pro | Claude 4 Opus |
| 视频分析 | Gemini 3 Pro | GPT-5 |
| 多模态 RAG | Claude 4 Opus | Gemini 3 Pro |
| 混合任务(文本主导 + 少量图像) | M2.7 + 视觉模型组合 | Claude 4 Opus 单模型 |
🎯 选型建议: 选哪个模型本质上不是"谁更强",而是"谁更匹配你的请求分布"。建议通过 API易 apiyi.com 平台用真实流量做 A/B 测试,对比相同任务下不同模型的成本与质量,再确定最终的主力模型组合。
六、MiniMax M2.7 常见问题解答
6.1 M2.7 真的完全不能处理图片吗
是的,直接把图片文件(base64 或 URL)放进 messages,会被接口拒绝或返回错误。唯一可行的方式是先用其他视觉模型把图片转为文本描述,再把描述传给 M2.7 做后续推理。
6.2 M2.7 和 M2.7-highspeed 有什么区别
两者输出结果一致,只是响应速度不同。M2.7-highspeed 适合对延迟敏感的场景(如 IDE 实时补全),M2.7 标准版适合大批量异步任务。两个版本可以在 API易 apiyi.com 控制台通过模型名称切换,接口参数完全兼容。
6.3 M2.7 是开源模型吗,能否本地部署
可以,M2.7 是开放权重模型,可在 HuggingFace 下载并自托管。但需要至少 8 张 A100 / H100 才能跑满 200K 上下文,本地部署成本远高于 API 调用,除非有严格的数据合规要求,否则不建议自建。
6.4 M2.7 是否兼容 Anthropic / OpenAI 的官方 SDK
完全兼容。可以直接使用 anthropic 或 openai 官方 SDK,只需把 base_url 指向中转网关(如 API易 apiyi.com 的统一接入端点),并切换 model 名称即可,无需重写任何业务逻辑。这也是混合架构最省力的接入方式。
6.5 多模态需求多的团队是否就不该考虑 M2.7
不一定。即使是多模态应用,文本推理与编排仍占大量请求量。建议把多模态部分留给 Claude/Gemini,文本编排与决策部分交给 M2.7,可以显著降低整体推理成本。如需定制混合方案,可以联系 API易 apiyi.com 商务团队获取架构建议。
七、总结:多模态是趋势,但"专精"也仍是有效路线
MiniMax M2.7 不支持图片输入,既是事实,也是有意为之的产品策略。在 2026 年这个多模态成为闭源旗舰标配的节点上,MiniMax 选择把所有训练资源集中在代码与 Agent 两个最有差异化的赛道,换来了接近 Claude 4 Sonnet 的代码能力和远低于后者的推理成本。
对开发者来说,这意味着模型选型不再是"谁更全能"的简单比较,而是"谁更匹配你的请求分布"。文本/代码主导的场景下,M2.7 仍然是当下最具性价比的选择之一;多模态高频场景则该交给 Claude 4 Opus、GPT-5 或 Gemini 3 等专业选手。两者通过统一网关组合使用,往往能拿到最优的成本与效果平衡。
如需在同一个 base_url 下统一接入 M2.7 与各家多模态旗舰,可以访问 API易 apiyi.com 官方文档查看完整的模型列表与接入示例。
作者: APIYI Team — 持续为全球 AI 开发者提供稳定、高效的 API 中转与多模型路由服务,详情访问 apiyi.com