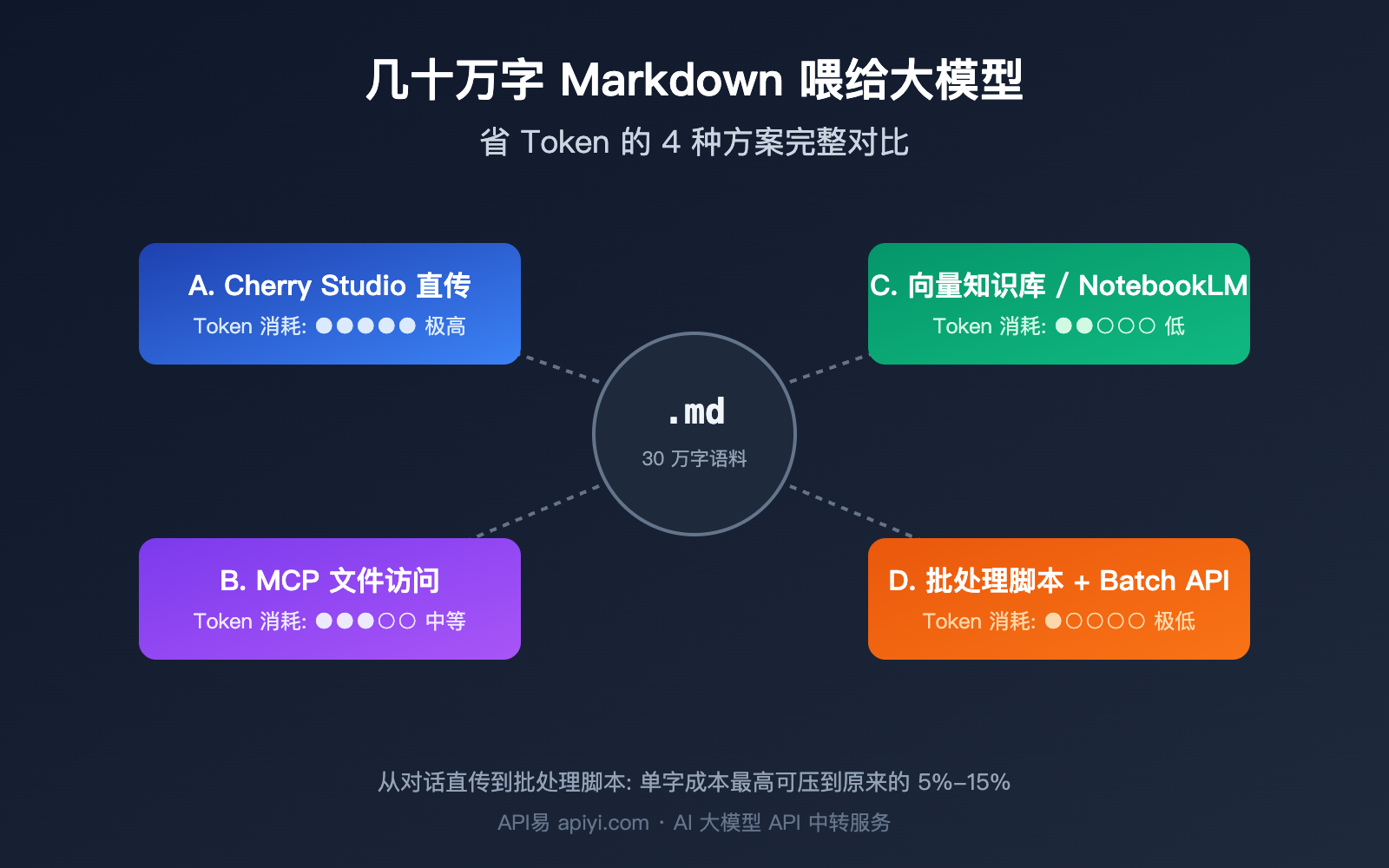
最近收到一个很典型的咨询:用户想把一位写作高手的几十万字文章「蒸馏」给大模型当风格底子,但不知道该把 Markdown 语料怎么塞进去最划算。常见的三种思路是:把文件一个个传进 Cherry Studio 这类对话工具、用 MCP 让模型直接调用硬盘上的文件、或者全部塞进知识库做 RAG。乍一看每种都能跑通,但当语料体量超过 30 万字时,Token 账单和延迟会迅速分化,选错方案动辄多花十倍预算。
这篇文章会把围绕大模型 Markdown 语料 省 Token的四种主流方案掰开揉碎对比:Token 实际消耗、单次任务成本、首 Token 延迟、可控性、以及不同语料规模下的最佳选择。最后给出一条分阶段的决策路径——前期探索用什么、规模化以后又该换成什么。如果你正在做风格蒸馏、知识库问答或语料微调前的清洗工作,读完应该能直接落地选型。
一、大模型 Markdown 语料 省 Token 的核心问题
在拆解方案之前,先把这个问题真正贵在哪里讲清楚。把几十万字 Markdown 喂给大模型,本质上是在四类成本之间做权衡:输入 Token、输出 Token、检索/索引成本、以及人力调试成本。
输入 Token 是最容易被低估的一项。一篇技术博客如果是 HTML 原始格式,转成 Markdown 之后通常能省下 70%~80% 的 Token,因为标签、样式、嵌入脚本都被剥离。这也是为什么所有处理大语料的流水线第一步都要先把内容统一成 Markdown 或 txt。把这件事做好,后续选哪种喂入方式的成本基线都会降一个台阶。
输出 Token 看似无关,但在「蒸馏」类任务里其实是隐性瓶颈。Claude Sonnet 和 Opus 都已经把 100 万 Token 上下文做成标准定价(Sonnet 输入 $3/M、Opus 输入 $5/M),理论上你可以一次性把几十万字塞进去,但单次响应的最大输出依然只有几万 Token,这意味着你没法用一次调用就完成全量改写。任务必须切片,这也直接决定了批处理脚本通常比交互式对话更适合规模化场景。
🎯 选型前的准备建议: 在挑方案之前,先把所有 Markdown 文件做一次脱敏和格式归一化处理。我们建议通过 API易 apiyi.com 平台先跑通小批量样本,确认每千字的实际 Token 消耗后,再决定走对话工具还是批处理脚本,避免后期成本失控。
二、4 种方案的核心差异与适用边界
四种方案各自有清晰的能力边界,理解差异比死记参数更重要。
2.1 方案 A:Cherry Studio 等对话工具直接上传
这是门槛最低的方式。Cherry Studio、Claude Desktop、ChatGPT 这类工具允许你把多个 Markdown 文件直接拖进对话框,模型把全部文件内容拼成一个长提示词处理。优点是零工程量、所见即所得;缺点是每开一个新会话都要重新喂一遍,Token 重复消耗严重,而且单次能塞下的文件量被上下文窗口卡死。
对于 5 万字以内的小样本任务,这种方式效率反而最高,因为你能用自然语言一边调一边看效果。但语料一旦超过 20 万字,就会频繁遇到上下文截断、长上下文延迟(首 Token 可能拖到 20-30 秒)和重复扣费问题。
2.2 方案 B:MCP 直连本地文件
MCP(Model Context Protocol)让模型像调用工具一样去读你硬盘上的文件。听起来很优雅:模型按需调用,不需要全量加载。但实测下来 MCP 的 Token 消耗经常被低估——一次工具调用返回的 JSON 哪怕只用得到 3 个字段,完整结构都会进入上下文,关键词匹配模式比向量检索多消耗约 3 倍 Token。
MCP 的真正强项是动态变化的数据源,比如实时日志、用户私有数据、或必须保持本地不出域的财务数据。对于「几十万字静态 Markdown」这种典型场景,MCP 是杀鸡用牛刀,而且容易在多轮调用中把上下文窗口提前耗光。
2.3 方案 C:向量化知识库 / NotebookLM
把所有文件切片、嵌入、入库,通过语义检索按需调用相关片段,这就是 RAG 路线。一个良好设计的 RAG 流水线每次查询只检索 5-20 个 chunk,通常合计 2000-10000 Token,相比全量加载能省 50-200 倍输入 Token。
NotebookLM 是 Google 提供的开箱即用 RAG 产品,自动处理嵌入、检索和引用,适合写作风格分析、文献综述、笔记问答这种偏读取的任务。它的局限是回答只基于源文件,不会主动联想训练数据,而且自定义程度有限。如果你需要复杂的检索策略或多步推理,自己搭一套向量知识库会更灵活。
🎯 方案 C 落地提醒: 向量知识库的检索质量直接决定输出质量,chunk 切分、embedding 模型、检索 top-k 都要根据语料调优。我们建议在 API易 apiyi.com 平台先用 Claude 或 GPT 跑一次小规模评测,对比不同检索参数下的回答准确率,再决定是否上 NotebookLM 还是自建。
2.4 方案 D:AI 写批处理脚本(规模化最优解)
这是问题原始答复里最被强调的方案:让 AI 帮你写一段批处理脚本,先用大模型处理 5-10 篇样本数据,人工或自动识别出可复用的规律(比如句式模板、段落结构、关键词分布),然后把规律固化进代码,让代码处理剩余的几十万字,大模型只在关键节点介入。
这本质上是「规则下沉」:大模型用来发现模式,代码负责批量执行。配合 Claude/GPT 的 Batch API(50% 折扣),整体成本通常只有方案 A 的 5%-15%。劣势是前期需要 1-2 天工程投入,不适合一次性任务。
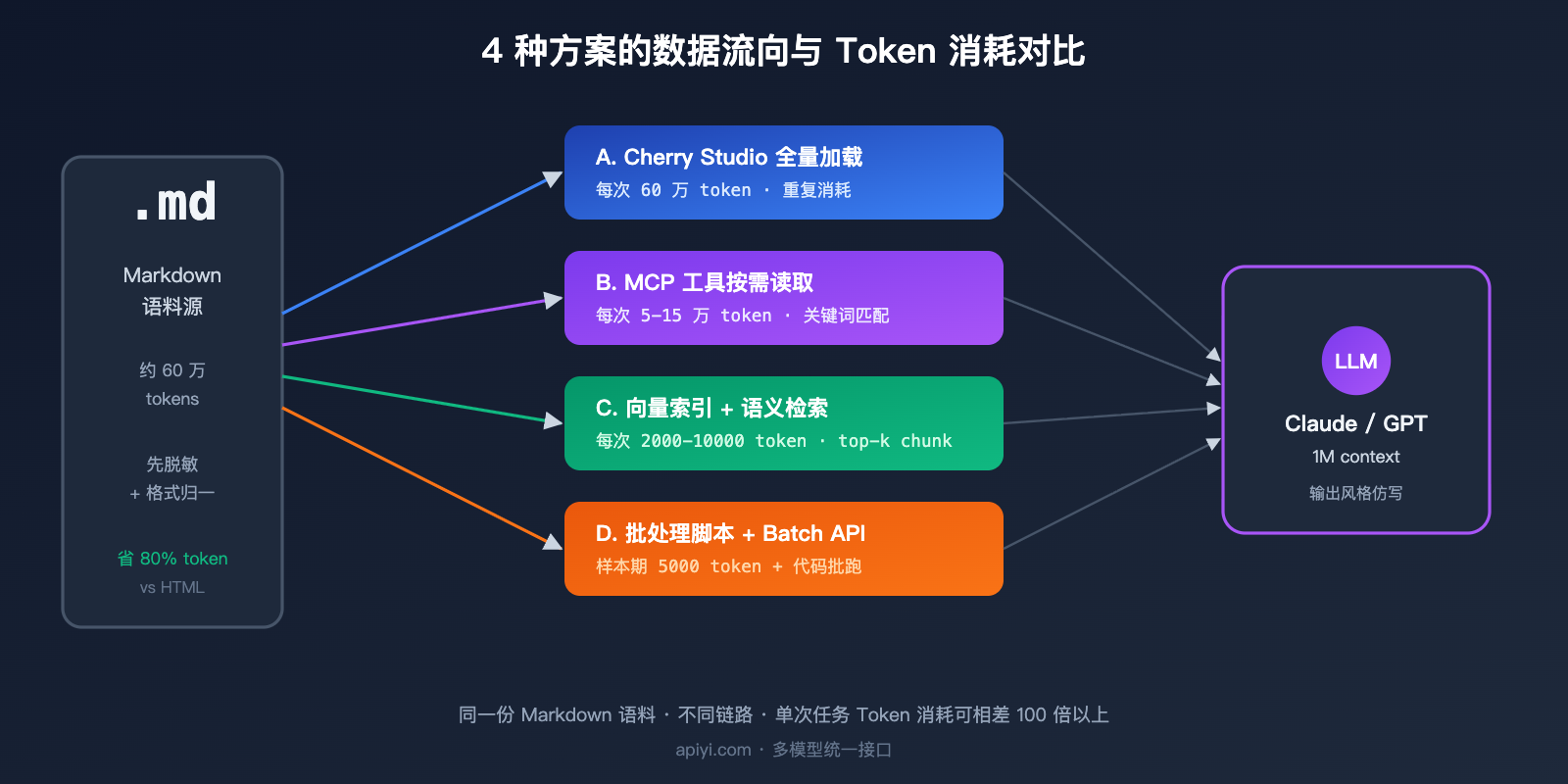
三、4 种方案的 Token 消耗与成本对比
把抽象差异落到数字上,才能真正算出账。下面这张表基于一个具体场景做对比:用户要蒸馏 30 万字 Markdown 语料(约 60 万 Token),最终输出 100 篇风格仿写文章(每篇约 2000 字)。
| 方案 | 单次输入 Token | 总输入 Token | 总输出 Token | 估算成本(Sonnet) | 首 Token 延迟 |
|---|---|---|---|---|---|
| A. 对话工具直传 | 60 万 | 6000 万(100 次) | 600 万 | ≈ $270 | 20-30 秒 |
| B. MCP 文件访问 | 5-15 万(分次) | 1500 万 | 600 万 | ≈ $135 | 8-15 秒 |
| C. 向量知识库 | 5000-1 万 | 100 万 | 600 万 | ≈ $93 | 1-2 秒 |
| D. 批处理脚本 + Batch API | 5000(样本期)+ 代码处理 | 100 万 | 600 万 | ≈ $46 | 异步 |
可以看到方案 D 的成本只有方案 A 的约 17%,而且延迟最稳定。如果再叠加 Batch API 的 50% 折扣,D 方案实际花费还能再降一半。Claude 1M context 把超长上下文做成标准定价之后,方案 A 不再被加价 2 倍,但重复输入相同语料的浪费依然存在——这是对话式工作流绕不开的硬伤。
🎯 成本验证建议: 上面的成本是基于公开报价估算,实际数字会因 prompt 设计、缓存命中率、是否启用 prompt caching 有 30%-50% 浮动。我们建议在 API易 apiyi.com 控制台开启用量监控,前 3 天每天对账,把抽象的预算变成可视化的曲线,再决定要不要把更多任务迁到 Batch API。
下面这张表把四种方案的工程复杂度也拉进来,方便横向看:
| 维度 | 方案 A 对话直传 | 方案 B MCP | 方案 C 向量知识库 | 方案 D 批处理脚本 |
|---|---|---|---|---|
| 工程投入 | 几乎为零 | 中等 | 中等偏高 | 高(前期) |
| 上手时间 | 5 分钟 | 1-2 小时 | 半天到 1 天 | 1-2 天 |
| 可复现性 | 弱(对话历史易丢) | 中 | 强 | 极强 |
| 适合语料规模 | < 5 万字 | 5-30 万字动态数据 | 10 万字 – 1000 万字静态 | 30 万字以上 |
| 输出可控性 | 受上下文长度限制 | 受工具调用次数限制 | 受检索质量限制 | 完全可控 |
四、不同语料规模下的场景推荐
把方案套到具体场景里更直观。下面分三种规模给出推荐路径。
4.1 小语料(< 5 万字)学习探索期
此时核心目标是快速验证想法,而不是追求成本最优。方案 A 对话直传是最合理的选择,把所有文件拖进 Cherry Studio 或 Claude Desktop,直接和模型对话调试 prompt。这一阶段你应该重点关注:模型是不是真的能抓住目标作者的风格特征?哪些维度是可量化的(句长、用词、句式)?哪些是模糊的(语气、节奏)?这些问题在小样本下成本极低,几美元就能跑完。
4.2 中等语料(5-30 万字)研究分析期
进入这个区间,方案 A 的重复输入开销会快速膨胀。此时最佳实践是切到方案 C 向量知识库或 NotebookLM,把样本写入向量库后用语义检索按需调用。如果你只是做内容分析、风格归纳、问答式探索,NotebookLM 几乎零工程量就能跑;如果需要更复杂的多步推理,自己搭一套基于 Claude 或 GPT 的 RAG 系统。
🎯 中等规模选型提示: NotebookLM 适合纯读取分析,但不支持自定义检索策略和复杂工作流。我们建议在 API易 apiyi.com 平台上对接 Claude Sonnet 或 Opus 1M context 来跑 RAG,既享受标准定价又能灵活控制 chunk 数和检索权重,适合需要长期运营的语料库。
4.3 大规模语料(30 万字以上)生产期
到了几十万字甚至上百万字的量级,方案 D 批处理脚本几乎是唯一可持续的选择。把任务拆成「样本发现规律 → 代码批量处理 → 大模型只做关键节点」三段式工作流,配合 Batch API 异步执行,可以把单字成本压到原来的 5%-15%。这个阶段你需要的不是更聪明的 prompt,而是更工程化的流水线。

五、分阶段省 Token 决策建议
把上面的分析浓缩成一张实操路径表,可以直接照着选:
| 触发条件 | 推荐方案 | 关键动作 |
|---|---|---|
| 语料 < 5 万字 / 一次性探索 | 方案 A 对话直传 | 直接拖文件、调 prompt、记录有效提示词 |
| 5-30 万字 / 静态语料 / 偏读取分析 | 方案 C 向量知识库 | 选 NotebookLM 或自建 RAG,优先调 chunk 和 top-k |
| 30 万字以上 / 重复任务 / 需要量产 | 方案 D 批处理脚本 + Batch API | 让 AI 帮你写脚本,样本期人工验证规律 |
| 动态变化数据 / 必须本地不出域 | 方案 B MCP | 限定工具调用次数,慎用关键词检索 |
实际项目中常见的组合是「方案 A 起步,方案 C 中段,方案 D 收尾」。这是因为任务理解本身就是渐进的:小样本对话帮你弄清楚要做什么、衡量标准是什么;中等样本帮你验证检索质量和泛化能力;大规模阶段则是把已经成熟的流程固化进代码。
跳过中间阶段直接上批处理脚本是常见误区——你会发现脚本写得很完美,但跑出来的结果不达预期,因为最初的 prompt 还没有充分调优。反过来,长期停留在对话阶段也会浪费 Token,几百美元的账单可能只买到几十个有效样本。
🎯 阶段切换的判断信号: 当你发现连续 5 次以上对话都在用相似的 prompt 处理类似文件,就说明该切到向量知识库了;当你每次任务都要重复输入相同的检索逻辑,就说明该写脚本了。我们建议在 API易 apiyi.com 平台开启 prompt 缓存和用量统计,让切换时机有数据支撑而不是凭感觉。
六、批处理脚本方案的最小可运行例子
为了让方案 D 更具体,这里给一段极简版的批处理脚本骨架,演示「样本发现 → 规则固化 → 批量执行」的核心流程:
import os, json
from anthropic import Anthropic
client = Anthropic(base_url="https://vip.apiyi.com")
def extract_style_features(markdown_text: str) -> dict:
"""用大模型从单篇文章提取可量化的风格特征。"""
resp = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1500,
messages=[{"role": "user", "content": f"""
请从下面这篇 Markdown 文章中提取写作风格特征,输出 JSON,包含:
- avg_sentence_length: 平均句长
- paragraph_structure: 段落结构模式
- key_phrases: 高频短语前 10 个
- tone: 语气标签(如严谨/通俗/犀利)
文章内容:
{markdown_text}
"""}],
)
return json.loads(resp.content[0].text)
# 样本期: 用 10 篇文章发现规律
samples = [open(f, encoding="utf-8").read() for f in os.listdir("samples")[:10]]
features = [extract_style_features(s) for s in samples]
# 规律固化: 把高频特征写进配置文件,后续由代码直接套用
with open("style_profile.json", "w", encoding="utf-8") as f:
json.dump(features, f, ensure_ascii=False, indent=2)
样本期跑完之后,真正的批量改写阶段可以完全用代码套用 style_profile.json 里的规则,大模型只在「最终润色」这一步介入,Token 消耗可以从十万级压到几千。
🎯 批处理脚本的 API 接入建议: 上面的
base_url指向 API易 apiyi.com 的中转端点,可以直接复用 Anthropic 官方 SDK,无需改代码。我们建议在脚本里加上 retry 和 cost tracking 逻辑,跑长任务时一旦超预算就自动停,这是大规模批处理最容易踩坑的地方。
七、常见问题 FAQ
Q1:Claude Sonnet 和 Opus 都已经有 100 万 Token 上下文,直接全量塞进去不行吗?
技术上可行,但有两个隐性成本。一是首 Token 延迟会拖到 20-30 秒,交互体验差;二是同一段语料每次会话都要重新输入,几次下来比 RAG 贵 50-200 倍。1M context 适合做一次性的全局推理(比如「跨文档找矛盾」),不适合反复访问同一份语料。我们建议在 API易 apiyi.com 上用 Sonnet 1M 跑全局推理任务、用 Haiku 跑批处理细分任务,组合起来性价比最高。
Q2:NotebookLM 和自己搭向量库怎么选?
如果只是个人或小团队做静态语料分析、风格研究、问答查询,NotebookLM 上手最快,直接拖文件就能用。如果需要定制 chunk 策略、控制检索权重、对接业务系统、或者用别家的模型做生成,自建向量库更灵活。
Q3:MCP 真的没用吗?
完全不是。MCP 的强项在于「数据频繁变动」或「不能离开本地」的场景,比如读取实时日志、查询私有数据库、调用内部 API。对于静态 Markdown 语料,RAG 几乎在所有维度都更优,这才是结论。
Q4:Batch API 真的能省 50% 吗?响应慢不慢?
Batch API 是异步的,通常 24 小时内返回结果,价格是标准 API 的 50%。对于「蒸馏写作风格生成 100 篇仿写文章」这种不要求实时的任务非常合适。叠加 1M context 标准定价后,综合成本可以压到原来的 30%-40%。我们建议在 API易 apiyi.com 平台先用同步 API 跑通流程,再切到 Batch 模式批量产出。
Q5:语料里有图片、表格、代码块怎么办?
Markdown 本身已经把这些结构保留得很好,但要注意:大段代码块会占用大量 Token,如果只是分析文字风格,可以先用脚本剥离代码;表格如果太复杂建议转成 CSV 单独存储,只把摘要塞给大模型,这能进一步节省 30% 以上的 Token。
八、总结
回到最初那个问题:几十万字 Markdown 该用哪种方式喂大模型?答案不是单选,而是分阶段组合。小样本探索期用对话直传最快,中等规模研究期用向量知识库或 NotebookLM 最稳,规模化生产期一定要切到批处理脚本配合 Batch API,把大模型的角色从「执行者」收敛到「规律发现者」,代码才是真正负责跑量的那一环。
理解这条路径之后,大模型 Markdown 语料 省 Token这件事就从「选哪个工具」变成了「选哪个阶段用哪个组合」。如果你现在正卡在某个阶段不确定要不要切换,可以先用 API易 apiyi.com 平台跑一次小规模评测,把每千字成本、检索准确率、首 Token 延迟三组数据拉出来比对,决策会清晰很多。希望这篇对比能帮你少走几条弯路,把预算花在真正产出价值的环节上。
—— APIYI Team(api.apiyi.com)