提示词缓存(Prompt Caching)几乎是 2026 年所有大模型 API 用户都绕不开的成本话题。同样跑一个 8K 系统提示词的 RAG 应用,开了缓存和没开缓存,月度账单可能差出 10 倍以上。但很多开发者在 OpenAI 与 Anthropic 之间切换时,会被一个隐藏细节绊到——两家的缓存计费模型完全不一样。

最关键的差异其实只有一句话:GPT 系列的缓存写入按基础价 1x 计费、不收溢价,而 Claude 系列的缓存写入会收 1.25x(5 分钟)或 2x(1 小时)的溢价。这个差别看起来微小,但放进真实业务流量里就会显著影响盈亏平衡点。本文基于两家官方文档逐项核对,把计费规则、触发条件、读取折扣、TTL 策略、回本测算讲清楚,帮你做出更准确的成本预估。
GPT 与 Claude 提示词缓存的 5 大核心差异
直接上结论。下面这张表是全文最值得收藏的一张表,它把两家在缓存层最容易被忽视的 5 个关键点放在一起,方便对照。
| 维度 | OpenAI GPT | Anthropic Claude |
|---|---|---|
| 写入计费 | 1x 基础价,无溢价 | 5min: 1.25x;1h: 2x |
| 读取计费 | 约 0.1x(最高 90% 折扣) | 0.1x(10% 折扣后价格) |
| 触发方式 | 全自动,无需改代码 | 显式 opt-in,需 cache_control |
| 最小 token 阈值 | 统一 1024 tokens | 1024 / 2048 / 4096(按模型不同) |
| 缓存 TTL | 默认 5–10 分钟空闲,最长 1 小时;扩展模式 24 小时 | 默认 5 分钟,可选 1 小时(2x 写入) |
读懂这张表的关键在于"写入计费"这一行。OpenAI 的逻辑是:缓存对你免费,第一次写入就是按基础价收费、第二次起的命中再给你打折,所以只要发生过一次命中,就立刻进入纯收益区。Claude 的逻辑是:写入要先付溢价,命中后再退还折扣,需要"够多次命中"才能把溢价摊回来。
🎯 配置建议:如果你的业务流量不可预测、命中率不稳定,建议优先选 GPT 的自动缓存机制以降低风险。如果命中率非常稳定(如客服、Agent、长文档分析),Claude 的显式控制反而能榨出更高折扣。两家模型 API易 apiyi.com 都已上线,可以同一把令牌内做对比测试,避免重复开账号。
OpenAI GPT 提示词缓存的计费机制详解
OpenAI 官方文档对 Prompt Caching 的措辞非常直白:"Caching happens automatically, with no explicit action needed or extra cost paid to use the caching feature." 翻译过来就是:自动启用、零额外费用、无需改一行代码。
GPT 缓存的写入与读取计费
GPT 系列对缓存写入不收任何溢价。你第一次发送一条 8K 的系统提示词时,按 base 输入价格收费——和不开缓存一模一样。从第二次开始,如果系统识别到这段前缀已被缓存,就把命中部分以约基础价 10% 的优惠价计费,节省 90%。
| 项目 | 计费方式 | 与基础价比例 |
|---|---|---|
| 缓存首次写入 | 按基础输入价 | 1x(无溢价) |
| 缓存命中读取 | 缓存命中折扣 | 约 0.1x |
| 启用费用 | 完全免费 | 0 |
| 配置代码改动 | 零 | 无需 |
实际折扣幅度官方表述为"up to 90%",按模型与计费表小有差别。例如 GPT-5.4 的基础输入价为 $2/1M,缓存命中价为 $0.20/1M,正好是 10%。GPT-4.1、GPT-4o 等已支持模型也基本遵循这个比例。
🎯 价格核对:由于 OpenAI 模型迭代频繁,实际命中折扣价以官方计费表为准。建议在 API易 apiyi.com 后台模型广场直接查看当前生效价格,平台会同步官方调整,不会另收中转手续费,开发者按实际 Token 用量结算即可。
GPT 缓存的命中条件
要触发缓存命中,必须同时满足两个条件:
- 提示词长度 ≥ 1024 tokens(短于此数不进入缓存)。
- 提示词的前缀需与历史请求完全一致,命中以 128 token 增量切片。
OpenAI 把缓存命中的最小颗粒定在 128 tokens,意味着一段 1500 token 的稳定前缀,只要前 1024 tokens 完全一致,剩余部分以 128 增量逐步命中。这种自动化设计的代价是控制力较弱——开发者无法显式指定"哪段一定要缓存",必须把所有稳定内容前置。
GPT 缓存的 TTL 行为
OpenAI 对 TTL 给了一段非常关键的描述:缓存前缀通常在 5–10 分钟空闲后被回收,最长保留 1 小时。GPT-5、GPT-4.1 等较新模型还支持"extended retention",最长可至 24 小时。
🎯 使用提示:通过 API易 apiyi.com 接入 GPT 系列时,OpenAI 的自动缓存策略对中转链路是透明的,命中率和直连官方端点一致。这意味着你可以在不增加任何成本的前提下,用 API易统一管理 OpenAI 与 Claude 的账单与令牌。
Anthropic Claude 提示词缓存的计费机制详解
Claude 的设计哲学和 OpenAI 完全相反——它把缓存当成一项"可主动配置的优化能力",开发者必须显式声明哪些内容要缓存、缓存多久。代价是写入要付溢价,回报是控制粒度极高。
Claude 缓存的写入溢价与读取折扣
| 项目 | 计费倍率 | 说明 |
|---|---|---|
| 5 分钟写入 | 1.25x 基础输入价 | 默认 TTL,覆盖大多数场景 |
| 1 小时写入 | 2x 基础输入价 | 适合长会话、Agent 等 |
| 缓存命中读取 | 0.1x 基础输入价 | 折扣 90% |
| 启用费用 | 0 | 无额外开通费 |
| 配置改动 | 必须加 cache_control |
显式 opt-in |
举一个直观的例子:Claude Opus 4.7 基础输入价 $5/1M,5min 写入即 $6.25/1M、1h 写入即 $10/1M,命中读取仅 $0.50/1M。这一价格表写在 Anthropic 官方文档里,已稳定多个季度。
Claude 缓存的最小 token 阈值
Claude 的最小可缓存 token 数因模型而异,这是很多人踩的第一个坑。
| 模型 | 最小可缓存 tokens |
|---|---|
| Claude Opus 4.7 / 4.6 / 4.5 | 4096 |
| Claude Haiku 4.5 | 4096 |
| Claude Sonnet 4.6 | 2048 |
| Claude Sonnet 4.5 / Opus 4.1 / Sonnet 4 | 1024 |
如果你的稳定前缀不到该模型的最小阈值,即便加了 cache_control 也不会真正进入缓存层,请求会被静默处理为非缓存路径——不会报错,但你以为开了缓存其实没开。这点在 Opus 4.7 上尤其重要:4096 tokens 是个不低的门槛,简短的对话场景几乎用不上。
🎯 模型选型建议:如果业务上下文长度不稳定,建议优先选 Claude Sonnet 4.5 或 4.6,最小阈值更低、命中更容易。通过 API易 apiyi.com 可以一键切换 Sonnet 与 Opus,避免因为模型阈值问题导致缓存形同虚设。
Claude 缓存的 breakpoint 与并发限制
Claude 允许在一条请求中设置最多 4 个 cache breakpoint,不同断点可以指定不同 TTL。这是 Claude 区别于 GPT 的最强能力——你可以让"系统提示词"用 1 小时缓存、"知识库片段"用 5 分钟缓存、"用户上下文"不缓存,三段独立计费、独立失效。
并发场景下要特别注意一点:Claude 的缓存条目只有在第一次响应开始返回后才对其他请求生效。如果你并行发了 N 个相同前缀的请求,只有第一个会写缓存,其余 N-1 个仍按基础价计费,没有命中折扣。所以批量调用时需要先发一发触发缓存写入,再并行剩余请求。
🎯 批量调用建议:通过 API易 apiyi.com 调用 Claude 时,建议在发起并发批次前,先单发一条"热身"请求触发缓存写入,等其响应开始后再放并发,可避免重复写入溢价,能省下不少预算。
写入溢价对真实账单的影响:盈亏平衡点测算
这一节把抽象的倍率换算成具体钱数。我们假设一段 10,000 tokens 的稳定系统提示词,在 1 小时窗口内被请求 N 次,输出统一为 500 tokens,看两家在不同 N 下的总成本。
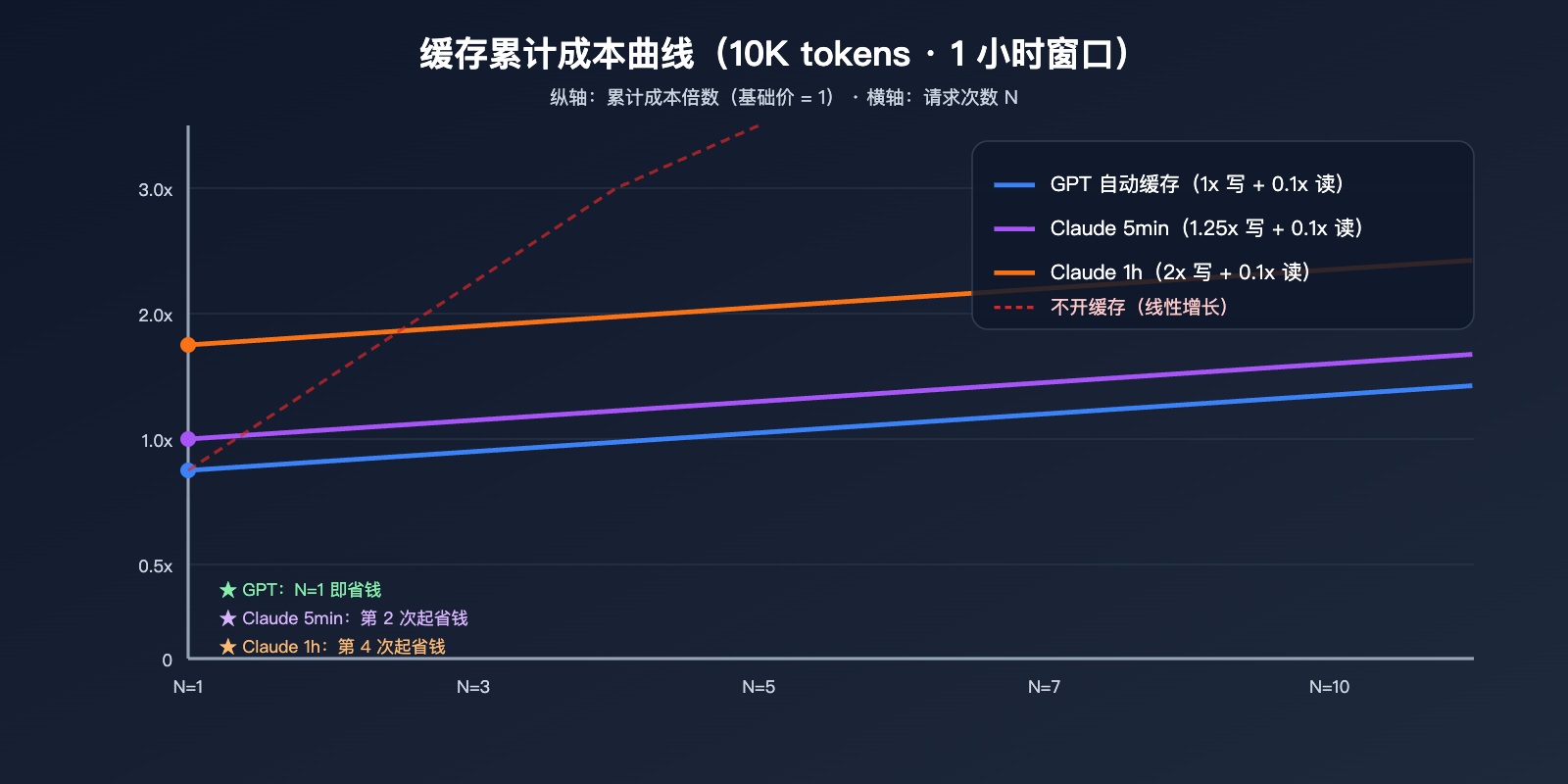
为了便于对比,假设两家基础输入价均归一化为 $X/1M tokens。10,000 tokens 单次基础成本 = 10 × $X / 1000 = $0.01X。下面只看输入端缓存计费部分,忽略输出(输出按各家自家价算)。
| 请求次数 N | GPT 自动缓存 | Claude 5min 缓存 | Claude 1h 缓存 |
|---|---|---|---|
| N=1(首次写入) | $0.01X | $0.0125X | $0.02X |
| N=2 | $0.011X | $0.0135X | $0.021X |
| N=5 | $0.014X | $0.0165X | $0.024X |
| N=10 | $0.019X | $0.0215X | $0.029X |
| 不开缓存(参照) | $0.01X × N | $0.01X × N | $0.01X × N |
| 回本所需读取次数 | 0 次(首次起省钱) | 1 次(第 2 次起省钱) | 3 次(第 4 次起省钱) |
可以看到一个关键事实:GPT 缓存在 N=1 就已经不亏了——因为写入按 1x 收费、命中时再打折,永远都是赚的。Claude 5min 缓存需要至少 1 次命中才能把 0.25x 的写入溢价摊回来,1h 缓存则要 3 次命中。如果你的某段稳定前缀一天内只命中 1 次,用 Claude 1h 缓存反而比不开缓存更贵。
真实业务里如何选 TTL
这个测算给出的实操建议非常清晰:
- 频次低、不规则:优先 GPT 自动缓存,无脑省。
- 频次高、5 分钟内多次命中(如客服会话、Web 应用):Claude 5min 缓存收益最大化,写入溢价小、读取折扣狠。
- 长任务、跨小时多次复用(如 Coding Agent、长文档对话):Claude 1h 缓存值得,但要保证至少 3 次命中。
- 不确定命中率:永远先按 5min 跑,跑通后再考虑切 1h。
🎯 测算建议:API易 apiyi.com 后台提供按请求维度的 cached_tokens 字段统计,可以直接看出你的真实命中率。建议先跑一周生产流量,再决定是否激进地把 TTL 拉到 1 小时。
不同业务场景下的缓存策略推荐
理解了计费差异之后,落到具体业务上才有意义。这里把常见场景按推荐策略归类。
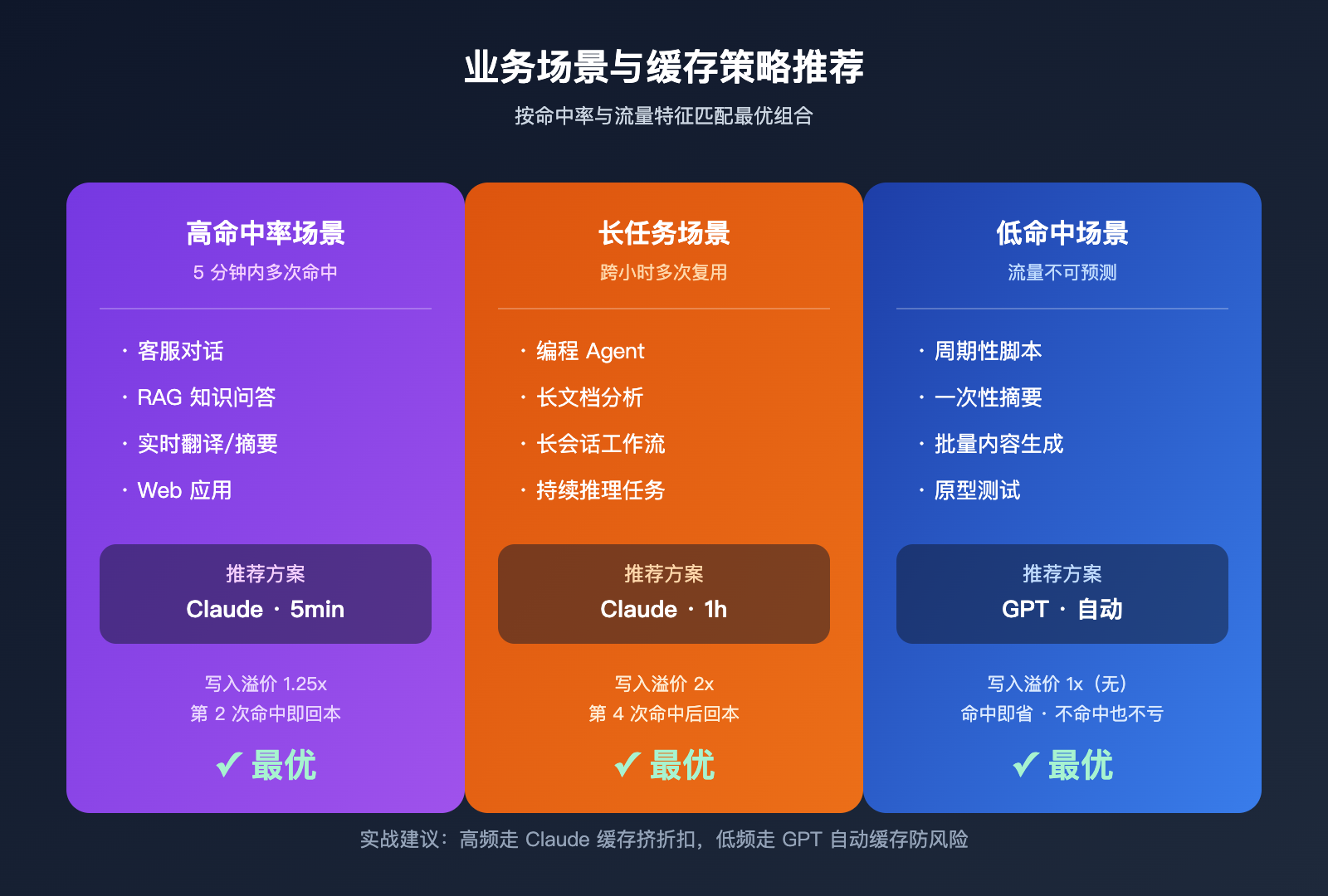
场景一:高频 RAG 与企业知识问答
这类场景的稳定前缀通常包含系统提示词 + 知识库片段,单次会话内多轮命中,5 分钟内累计请求数轻松破 10。Claude 5min 缓存在这种场景下能压低 80% 以上的输入成本,最划算。如果是 1 小时长会话,可考虑 1h 缓存。
场景二:编程 Agent 与长任务工作流
像 Claude Code、OpenCode 这类编码 Agent,单次任务可能持续半小时甚至几小时,期间反复读取项目结构、CLAUDE.md、之前的工具调用结果。这种场景下 Claude 1h 缓存是最优解,因为命中次数远高于 3 次的盈亏平衡点。
场景三:低频或不可预测请求
例如周期性脚本、批量 SEO 文章生成、一次性长文档摘要,每次请求间隔可能远超 5 分钟。建议优先用 GPT 系列加自动缓存,命中就赚、不命中也不亏,比 Claude 显式缓存的容错性高得多。
场景四:成本敏感的纯输入压缩
如果你的核心目标是把 10K+ token 的提示词压成最低成本,建议直接用 Claude Sonnet 4.6 + 5min 缓存:写入溢价仅 25%,命中后只要 1 次即可回本,读取价格压到 $0.075/1M(基础 $3 × 0.025)这种程度。
| 业务场景 | 推荐模型族 | 推荐 TTL | 原因 |
|---|---|---|---|
| 客服/RAG/即时问答 | Claude Sonnet | 5 分钟 | 命中频繁,回本快 |
| 编程/长 Agent 任务 | Claude Sonnet/Opus | 1 小时 | 跨小时命中超过 3 次 |
| 周期性脚本/批处理 | GPT-4.1 / GPT-5.x | 自动 | 命中不稳定,零写入溢价 |
| 一次性长文档分析 | GPT-5.x | 自动 | 单次任务,命中率低 |
| 纯成本敏感场景 | Claude Sonnet 4.6 | 5 分钟 | 最低有效缓存价 |
🎯 混合架构建议:在生产环境里,GPT 与 Claude 不是二选一,而是按场景搭配。建议通过 API易 apiyi.com 单一入口同时接入两家模型,前端按业务流量动态路由:高命中走 Claude 缓存,低命中走 GPT 自动缓存,整体账单可压低 40% 以上。
常见问题 FAQ
Q1:GPT 真的不收缓存写入溢价吗?是不是隐藏在某个费用里?
是的,OpenAI 官方文档原话:「No. Caching happens automatically, with no explicit action needed or extra cost paid to use the caching feature.」缓存写入按基础输入价计费,没有任何隐性溢价。你只为命中部分付折扣价,未命中部分按基础价付,相当于"白送"了缓存功能。
Q2:Claude 的 1.25x 与 2x 写入溢价是按整段提示词算还是只算缓存部分?
只算被 cache_control 标记进缓存的部分。例如 10K 提示词中只有 8K 被标记缓存,那 1.25x 溢价仅作用于这 8K,剩下 2K 仍按 1x 基础价。所以建议精细化设置 breakpoint,避免把不必要的内容也卷入溢价。
Q3:APIYI 中转站对两家的缓存计费是否完全透传?
API易 apiyi.com 对 GPT 与 Claude 的缓存计费保持原生透传。GPT 自动缓存的命中折扣、Claude 显式缓存的 1.25x/2x 写入与 0.1x 读取,账单端均与官方一致。cache_control 字段也支持透传,开发者可以直接复用官方 SDK 代码。
Q4:什么时候用 Claude 1h 缓存反而比不开缓存更亏?
当 1 小时窗口内的实际命中次数 < 3 次时,1h 缓存(2x 写入)的溢价摊不回来。比如某段提示词只在用户首次和退出时各请求一次,全天就 2 次,开 1h 缓存比不开缓存还要多花 1x 的写入溢价。这种场景下要么改用 5min 缓存、要么彻底关掉缓存。
Q5:GPT 的自动缓存是否会泄露我的提示词数据?
OpenAI 文档明确说明缓存按 organization 维度隔离,不会跨账号共享。Claude 自 2026-02-05 起进一步收紧到 workspace-level 隔离。两家在数据安全上的承诺基本一致,企业级用户可以放心使用。通过 API易 apiyi.com 接入时,令牌维度的隔离也会进一步加强这一保护。
Q6:缓存命中率怎么监控?两家都有暴露字段吗?
OpenAI 在 usage 对象里返回 cached_tokens 字段,Claude 在 usage 里返回 cache_creation_input_tokens 和 cache_read_input_tokens。前者表示缓存写入量、后者是命中量。建议把这两个字段写入业务日志,做命中率仪表盘后再调整 TTL 策略。
Q7:如果项目同时用 GPT 和 Claude,建议怎么配置令牌?
推荐用 API易 apiyi.com 的统一令牌方案,一把 sk-xxx 同时覆盖 GPT 与 Claude。后台账单可分模型查看,避免在两家分别开账号、分别管理余额、分别对账的麻烦。这种统一接入还方便做 A/B 切换,比较两边在同一业务上的实际成本。
总结:理解写入溢价是缓存优化的第一步
回到本文的核心论点:GPT 与 Claude 缓存计费的本质差异是写入侧的溢价模型——GPT 选择"零摩擦自动启用、写入不溢价",Claude 选择"显式控制、用写入溢价换更细粒度的折扣空间"。两种路线没有绝对优劣,关键是匹配业务流量特征。
如果你的应用属于高命中、稳定流量、需要精细控制的场景,Claude 的 1.25x / 2x 写入溢价可以靠高命中率轻松摊销,5min/1h 双 TTL 提供了 GPT 没有的灵活性。如果你的应用属于低命中、突发流量、追求开箱即用的场景,GPT 的自动缓存零溢价模型就是最稳妥的选择。
🎯 最终建议:成本优化的最佳实践是不要二选一。建议通过 API易 apiyi.com 同时接入两家模型,按业务场景路由——高频走 Claude 缓存挤折扣,低频走 GPT 自动缓存防风险。一把令牌、一份账单,轻松对比,是 2026 年技术团队最高效的成本管理姿势。
— APIYI 技术团队 | 持续追踪大模型计费动态,更多深度对比见 API易 apiyi.com 帮助中心