站长注:深度解析DeepSeek-R1-0528的思维链蒸馏技术,揭秘8B小模型如何通过蒸馏技术达到235B大模型的推理性能
DeepSeek刚刚发布的R1-0528版本带来了一个令整个AI界震惊的技术突破:通过 思维链蒸馏技术,他们成功让一个8B参数的小模型达到了235B级别的推理性能。这不仅仅是技术上的进步,更是对整个AI模型发展方向的重新定义。
接下来我们将通过实际数据来深入分析这一技术突破的意义。如果你想亲自体验这些先进模型的能力,可以先在 API易 注册一个免费账号(注册送 1.1 美金起),平台已经第一时间接入了DeepSeek-R1-0528,让你能够直接测试这些突破性技术。
模型蒸馏技术 背景介绍
在传统认知中,模型性能往往与参数规模成正比:参数越多,模型越强大,但同时也意味着更高的计算成本和推理延迟。DeepSeek-R1-0528的突破彻底颠覆了这一认知。
通过官方数据,我们看到了一个惊人的对比:
- DeepSeek-R1-0528-Qwen3-8B(8B参数)
- Qwen3-235B(235B参数)
在AIME 2024数学测试中,这两个模型的表现几乎相当,而参数差距却是30倍!

思维链蒸馏技术 核心突破
以下是 思维链蒸馏技术 的核心突破点:
| 技术维度 | 关键指标 | 技术价值 | 突破程度 |
|---|---|---|---|
| 推理深度 | 从12K tokens提升至23K tokens | 思维过程更加深入细致 | ⭐⭐⭐⭐⭐ |
| 准确率提升 | AIME 2025: 70% → 87.5% | 复杂推理任务表现显著增强 | ⭐⭐⭐⭐⭐ |
| 蒸馏效果 | 8B模型达到235B性能 | 小模型获得大模型能力 | ⭐⭐⭐⭐⭐ |
🔥 技术突破详解
思维深度的质变飞跃
DeepSeek-R1-0528最令人印象深刻的改进是思维深度的大幅提升。在AIME 2025测试中:
- 旧版本:平均每题使用12K tokens
- 新版本:平均每题使用23K tokens
这近乎翻倍的token使用量背后,代表的是模型在解题过程中进行了更为详尽和深入的思考。就像一个学生从匆忙做题转变为深思熟虑地分析每个步骤。
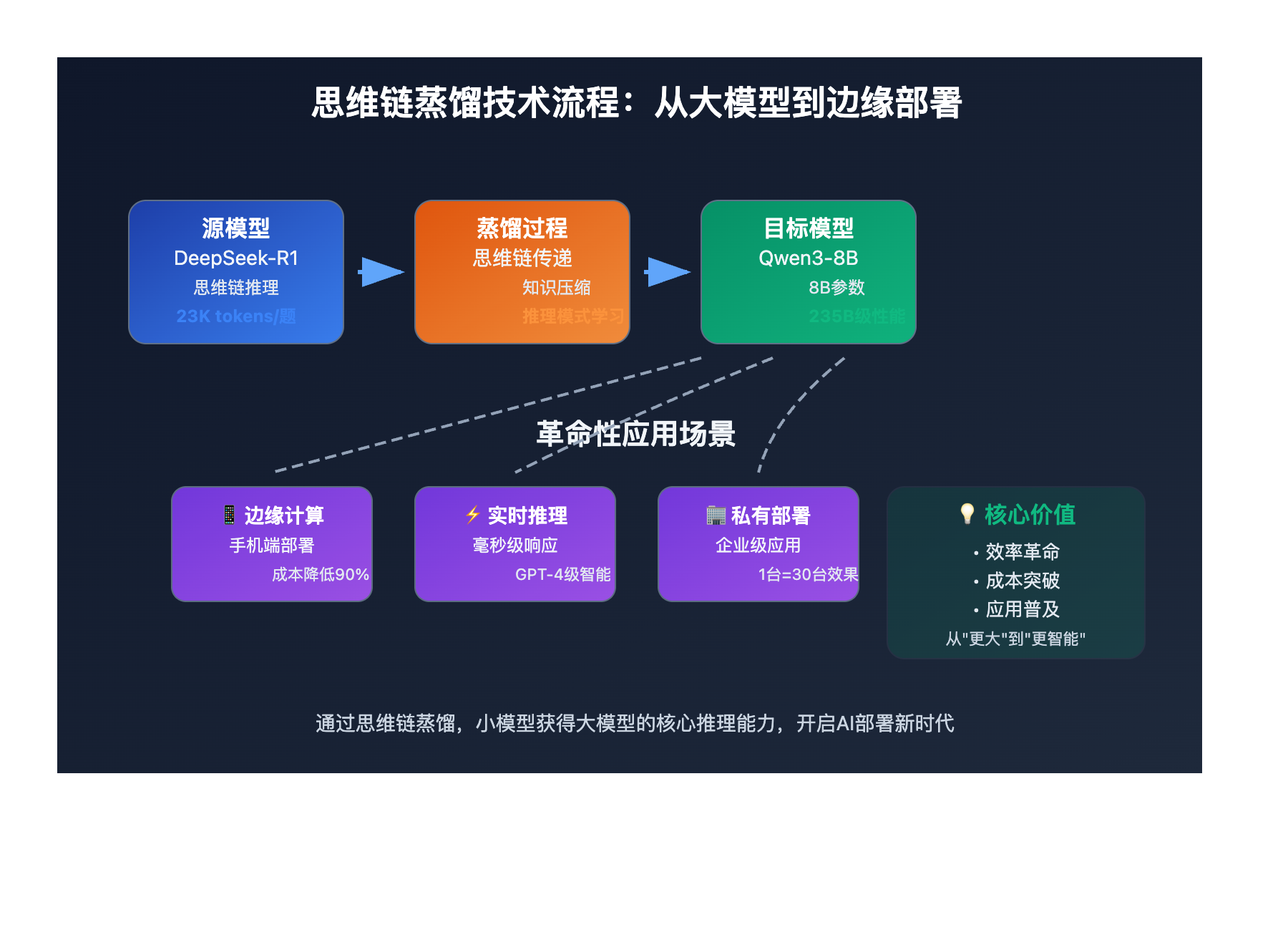
蒸馏技术的革命性应用
更加震撼的是蒸馏技术的应用效果。通过将DeepSeek-R1-0528的思维链蒸馏到Qwen3-8B Base模型,得到的DeepSeek-R1-0528-Qwen3-8B在数学测试中表现惊艳:
- 超越原始Qwen3-8B模型10.0%
- 与Qwen3-235B性能相当
- 仅次于DeepSeek-R1-0528主模型

模型蒸馏技术 应用场景
思维链蒸馏技术 在以下场景中具有革命性意义:
| 应用场景 | 适用对象 | 核心优势 | 预期效果 |
|---|---|---|---|
| 🎯 边缘计算部署 | 移动端开发者 | 大模型能力+小模型资源消耗 | 在手机上运行235B级别推理 |
| 🚀 企业私有化部署 | 中小企业 | 降低硬件成本90%+ | 用1台服务器实现原本需要30台的效果 |
| 💡 实时推理应用 | AI产品开发者 | 保持强大能力的同时大幅提升响应速度 | 毫秒级响应+GPT-4级别智能 |
模型蒸馏技术 开发指南
在深入了解这项技术之前,建议先获得API访问权限来直接体验效果。API易 已经第一时间支持了DeepSeek-R1-0528,你可以直接对比测试蒸馏前后的性能差异。
💻 技术对比实践
# 🚀 测试DeepSeek-R1-0528原版模型
curl https://vip.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $替换你的API易后台的Key$" \
-d '{
"model": "deepseek-r1",
"stream": false,
"messages": [
{"role": "system", "content": "请用详细的推理过程解决这个数学问题。"},
{"role": "user", "content": "在一个正八边形中,从一个顶点到另一个顶点画对角线,最多能画多少条不相交的对角线?"}
]
}'
Python示例对比测试
from openai import OpenAI
client = OpenAI(api_key="你的Key", base_url="https://vip.apiyi.com/v1")
# 测试原版DeepSeek-R1
def test_original_model():
completion = client.chat.completions.create(
model="deepseek-r1",
stream=False,
messages=[
{"role": "system", "content": "请详细展示你的推理过程。"},
{"role": "user", "content": "解释为什么8B模型能达到235B模型的性能?"}
]
)
return completion.choices[0].message
# 测试其他推理模型进行对比
def test_comparison_models():
models = ["claude-sonnet-4", "gpt-4o", "deepseek-v3"]
results = {}
for model in models:
completion = client.chat.completions.create(
model=model,
messages=[
{"role": "user", "content": "简要分析模型蒸馏技术的优势"}
]
)
results[model] = completion.choices[0].message
return results
print("原版模型推理:", test_original_model())
print("对比测试结果:", test_comparison_models())
### 🎯 模型蒸馏技术选择策略
这里简单介绍下我们使用的API平台。API易 是一个AI模型聚合平台,特点是 一个令牌,无限模型,可以用统一的接口调用 DeepSeek-R1、Claude 4、Gemini 2.5 Pro、GPT-4o 等各种模型。这对于研究模型蒸馏效果特别有用,你可以轻松对比不同模型在相同任务上的表现。
平台优势:官方源头转发、不限速调用、按量计费、7×24技术支持。特别适合需要大量测试对比的研究和开发场景。
🔥 针对 模型蒸馏研究 的推荐模型
| 模型名称 | 蒸馏技术相关优势 | 适用场景 | 推荐指数 |
|---|---|---|---|
| DeepSeek-R1 | 原版思维链推理模型,可作为蒸馏源 | 复杂推理任务基准测试 | ⭐⭐⭐⭐⭐ |
| Claude-Sonnet-4-Thinking | 思维链模式,便于对比蒸馏效果 | 推理过程对比分析 | ⭐⭐⭐⭐ |
| GPT-4o-Mini | 小模型代表,适合蒸馏目标对比 | 成本效益分析 | ⭐⭐⭐⭐⭐ |
🎯 研究建议:基于 模型蒸馏技术 的研究特点,我们推荐优先使用 DeepSeek-R1 作为蒸馏源模型,它在思维链推理方面表现突出,同时用 GPT-4o-Mini 等小模型作为对比基准。
🎯 模型蒸馏研究 场景推荐表
| 使用场景 | 首选模型 | 备选模型 | 经济型选择 | 特点说明 |
|---|---|---|---|---|
| 🔥 蒸馏效果评估 | DeepSeek-R1 | Claude-Sonnet-4-Thinking | GPT-4o-Mini | 全面的推理能力对比 |
| 🖼️ 成本效益分析 | GPT-4o-Mini | DeepSeek-V3 | Qwen系列 | 小模型性价比评估 |
| 🧠 推理深度测试 | DeepSeek-R1 | GPT-4o | Claude-Sonnet-4 | 思维链质量对比 |
💰 价格参考:具体价格请参考 API易价格页面
✅ 模型蒸馏技术 评估实践
| 评估要点 | 具体建议 | 注意事项 |
|---|---|---|
| 🎯 推理质量对比 | 使用相同测试集对比蒸馏前后模型表现 | 确保测试用例的代表性和难度梯度 |
| ⚡ 资源消耗测量 | 记录内存、计算时间、token使用量 | 在相同硬件环境下进行测试 |
| 💡 应用场景验证 | 在真实业务场景中测试蒸馏模型效果 | 关注边缘情况和异常处理能力 |
在研究模型蒸馏效果时,我发现多模型对比测试是关键。当你需要快速验证不同蒸馏策略的效果时,API易 的一站式服务就很有价值,避免了在多个平台间切换的麻烦。
❓ 模型蒸馏技术 常见问题
Q1: 为什么8B模型能达到235B模型的性能?这不是违反常识吗?
这确实颠覆了传统认知,但关键在于知识压缩和传递方式的革新:
- 思维链蒸馏:不是简单复制参数,而是学习推理过程
- 质量vs数量:235B模型的很多参数可能是冗余的,8B模型通过精准学习核心推理模式,避免了冗余
- 任务专精:蒸馏后的模型在特定任务(如数学推理)上高度优化
就像一个专业的象棋选手,虽然大脑容量有限,但在象棋领域可以击败通用智能更高的对手。
Q2: 这种蒸馏技术的重要意义具体体现在哪些方面?
学术界意义:
- 证明了"大即是美"理论的局限性
- 为推理模型研究开辟了新方向:专注于推理质量而非模型规模
- 提供了新的研究范式:如何更有效地传递和压缩知识
工业界影响:
- 成本革命:部署成本降低90%以上
- 边缘计算突破:强大AI能力可在移动设备运行
- 能耗优化:大幅降低AI推理的能源消耗
- 实时应用:毫秒级响应成为可能
Q3: 如何评估模型蒸馏的效果?有什么标准指标吗?
核心评估维度:
- 任务性能保持率:蒸馏后模型在原任务上的表现/原模型表现
- 推理质量对比:思维链的逻辑性、完整性、准确性
- 资源效率提升:相同任务下的计算资源消耗对比
- 泛化能力测试:在未见过的测试集上的表现
具体指标:
- AIME等标准测试集得分
- Token使用效率(正确答案/使用token数)
- 推理时间和内存消耗
- 边缘案例处理能力
🏆 为什么选择「API易」体验模型蒸馏技术
| 核心优势 | 具体说明 | 研究价值 |
|---|---|---|
| 🛡️ 第一时间接入新模型 | • DeepSeek-R1-0528当天接入 • 无需等待官方平台排队 • 稳定的API服务保障 |
抢占研究先机 |
| 🎨 丰富的对比模型 | • 同时支持多种推理模型 • 便于横向对比测试 • 统一接口降低测试成本 |
一个令牌,对比所有模型 |
| ⚡ 研究友好的服务 | • 不限速调用适合大量测试 • 详细的用量统计 • 技术支持团队 |
提升研究效率 |
| 🔧 开发者友好 | • OpenAI兼容接口 • 完善的文档和示例 • 快速集成 |
专注核心研究 |
| 💰 成本可控 | • 按量计费,测试成本可预期 • 免费额度供初步验证 • 批量优惠政策 |
降低研究门槛 |
💡 研究示例
以模型蒸馏效果评估为例,你可以:
- 同时调用DeepSeek-R1和其他模型进行对比
- 批量测试不同prompt策略的效果
- 量化分析推理质量和成本效益
- 快速迭代优化蒸馏策略
🎯 总结
DeepSeek-R1-0528的模型蒸馏突破,不仅仅是技术数字上的提升,更是对整个AI发展路径的重新思考。当一个8B模型能够达到235B模型的推理性能时,我们看到的是 效率革命的开始。
核心意义回顾:
- 技术突破:证明了智能可以被更有效地压缩和传递
- 成本革命:将强大AI能力的门槛降低了90%以上
- 应用普及:让边缘设备也能运行"大模型级别"的智能
- 研究方向:从"更大"转向"更智能"的发展路径
通过本文的分析,模型蒸馏技术的价值已经非常明显。如果你想要实际体验这些突破性模型的能力,可以结合 API易 的免费额度先进行测试,确认效果后再制定具体的应用策略。
有任何技术问题,欢迎添加站长微信 8765058 交流讨论,会分享《大模型使用指南》等资料包。

📝 本文作者:API易团队
🔔 关注更新:欢迎关注我们的更新,持续分享 AI 开发经验和最新动态。