站长注:深度解析DeepSeek R1-0528相比旧版本的技术突破,揭秘从70%到87.5% AIME准确率提升背后的算法优化和思维深度革新
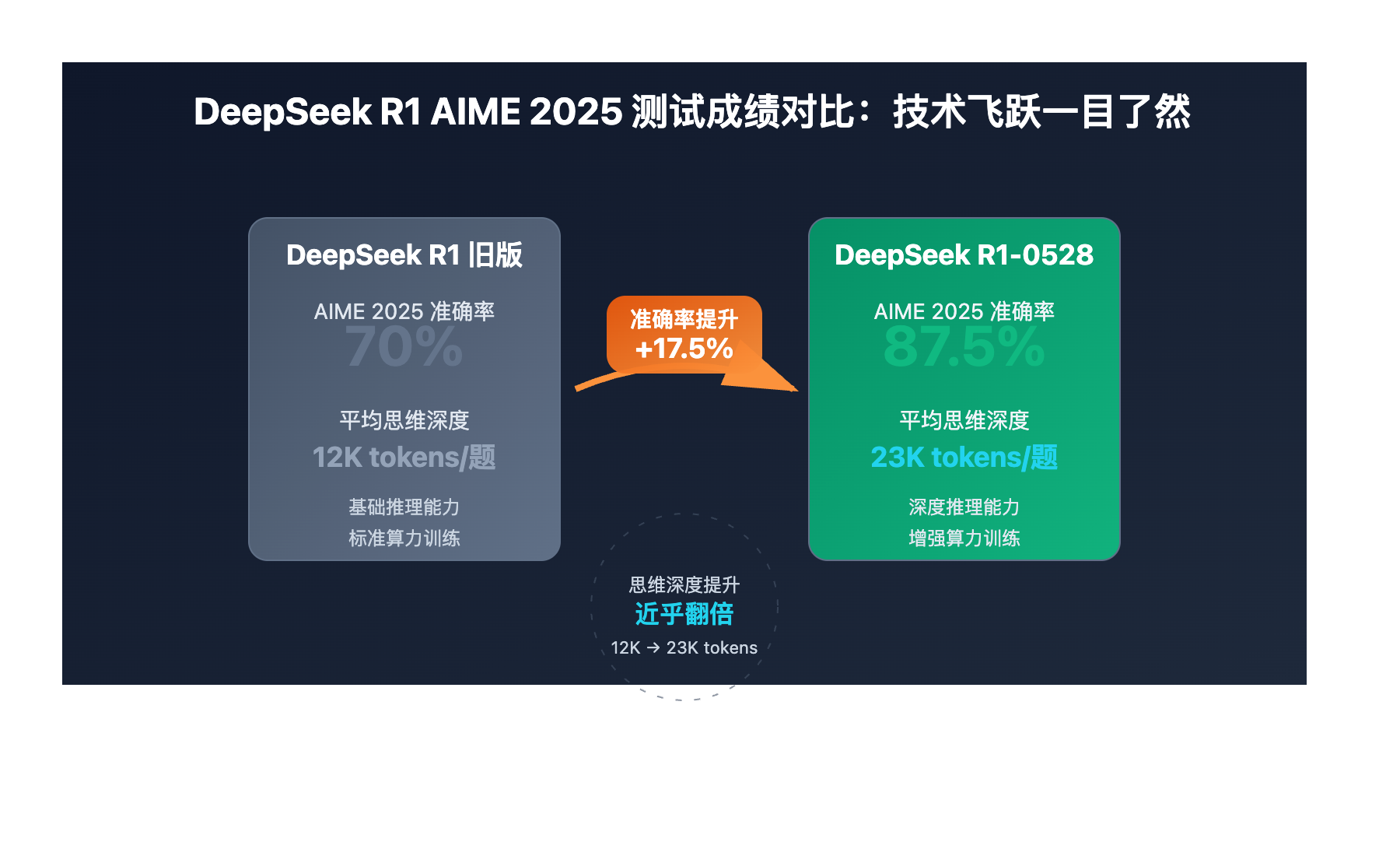
DeepSeek刚刚发布的R1-0528版本在AIME 2025测试中取得了令人瞩目的成绩:准确率从旧版的70%一跃提升至 87.5%,这个17.5个百分点的提升背后,隐藏着怎样的技术革新?这不仅仅是数字上的进步,更代表着AI推理能力的质的飞跃。
为了帮助大家更好地理解这一技术突破,我准备了详细的对比分析。建议可以配合 API易平台 的免费额度来测试(新用户有 300万 Tokens 免费体验),平台已经第一时间同步了DeepSeek-R1-0528,让你能直接感受这些技术改进的效果。
AIME测试突破 背景介绍
AIME(American Invitational Mathematics Examination)是美国高中数学竞赛中的精英赛事,被公认为测试AI推理能力的重要基准。DeepSeek R1-0528在这项测试中的表现突破,标志着国产AI在复杂数学推理领域达到了新的高度。
从官方数据来看,这次更新的核心在于后训练过程的算力投入增加,虽然仍使用2024年12月发布的DeepSeek V3 Base作为基座,但通过更深度的训练优化,实现了推理能力的显著提升。
AIME准确率提升 核心突破
以下是 DeepSeek R1-0528 相比旧版的核心技术突破:
| 技术维度 | 旧版本表现 | 新版本表现 | 提升幅度 |
|---|---|---|---|
| AIME 2025准确率 | 70% | 87.5% | +17.5% |
| 思维深度(tokens/题) | 12K | 23K | +91.7% |
| 推理复杂度 | 基础逻辑推理 | 深度多步推理 | 质的飞跃 |
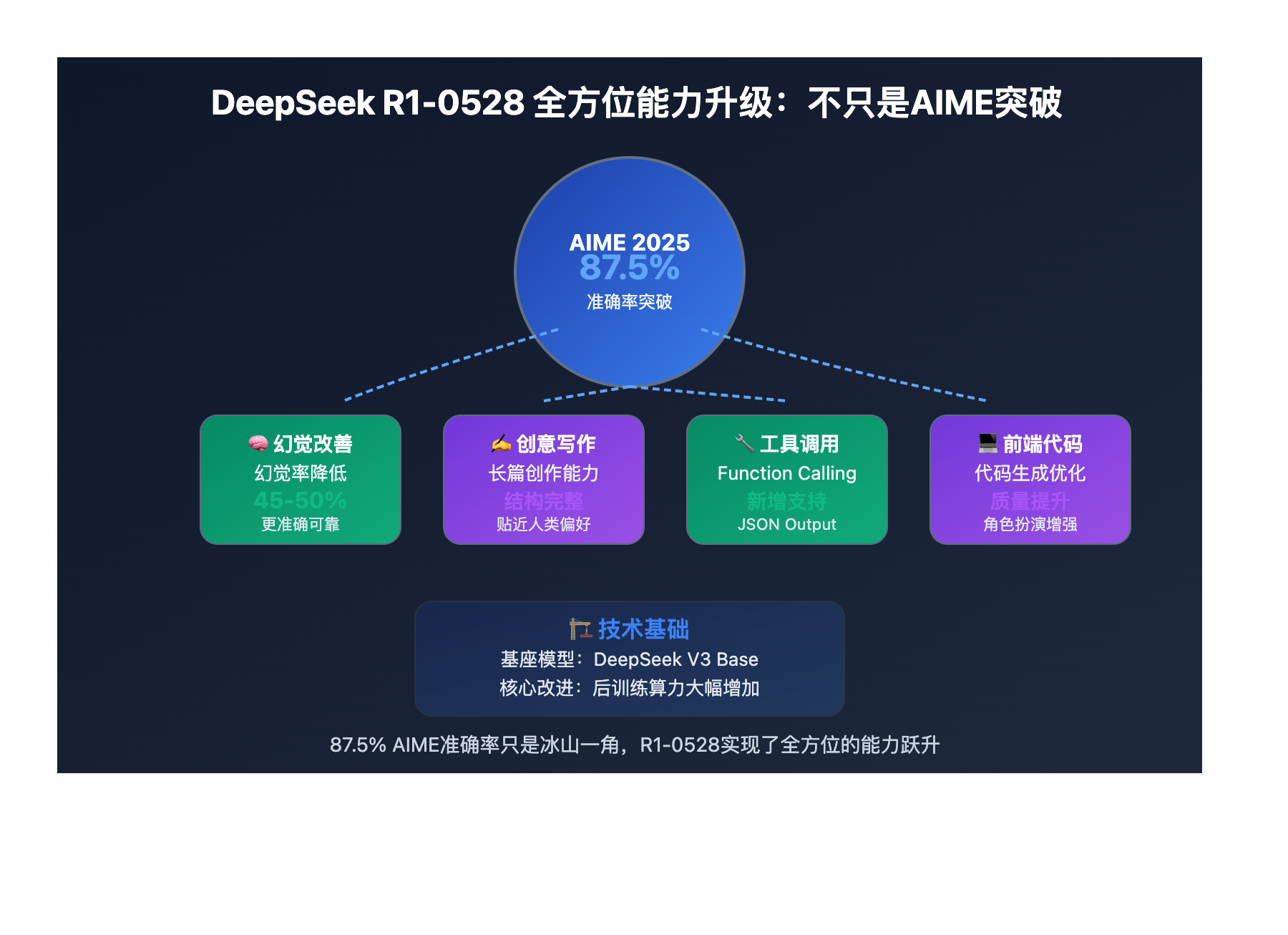
| 幻觉率 | 基准水平 | 降低45-50% | 显著改善 |
🔥 技术突破深度解析
算力投入的指数级增长
DeepSeek R1-0528最根本的改进来自于后训练过程中的算力大幅增加。虽然基座模型仍是DeepSeek V3 Base,但通过更深度的训练优化,模型在推理过程中展现出了质的变化。
具体表现:
- 思维深度翻倍:从12K tokens增长到23K tokens每题
- 推理路径多样化:能够探索更多解题路径
- 错误自我纠正:具备了更强的自我验证能力
推理质量的根本性提升
AIME测试的17.5%准确率提升,背后是推理质量的根本性改变。新版本不再满足于找到一个"看起来正确"的答案,而是会进行更深入的验证和推导。
关键改进点:
- 多路径验证:同一问题会从多个角度进行验证
- 步骤细化:将复杂问题分解为更多中间步骤
- 逻辑完整性检查:每个推理步骤都会进行逻辑验证

AIME准确率突破 应用场景
87.5% AIME准确率 的突破在以下场景中具有重要意义:
| 应用场景 | 适用对象 | 核心优势 | 预期效果 |
|---|---|---|---|
| 🎯 数学教育辅导 | 教育机构、学生 | 接近人类数学竞赛选手水平 | 高质量的数学问题解决和教学 |
| 🚀 科研计算辅助 | 研究人员、工程师 | 复杂数学推理能力显著提升 | 加速科研问题的解决过程 |
| 💡 逻辑推理应用 | 企业决策、分析师 | 多步骤复杂推理能力 | 提升决策分析的准确性 |
AIME准确率提升 开发指南
想要体验DeepSeek R1-0528的突破性能力,建议通过API接口进行深度测试。API易 已经第一时间同步了最新版本,你可以直接对比测试新旧版本的推理能力差异。
💻 AIME水平推理测试
# 🚀 测试DeepSeek-R1-0528的数学推理能力
curl https://vip.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $替换你的API易后台的Key$" \
-d '{
"model": "deepseek-r1",
"stream": false,
"max_tokens": 32000,
"messages": [
{"role": "system", "content": "请用详细的推理过程解决这个AIME级别的数学问题,展示你的思考步骤。"},
{"role": "user", "content": "在数列 {a_n} 中,a_1 = 1,对于所有正整数 n,都有 a_{n+1} = a_n + 2^n。求 a_{10} 的值。"}
]
}'
Python示例测试推理深度
from openai import OpenAI
client = OpenAI(api_key="你的Key", base_url="https://vip.apiyi.com/v1")
# 测试复杂数学推理
def test_aime_level_reasoning():
completion = client.chat.completions.create(
model="deepseek-r1",
stream=False,
max_tokens=32000, # 新版本建议设置更大值
messages=[
{"role": "system", "content": "请详细展示你的推理过程,包括每个步骤的验证。"},
{"role": "user", "content": """
一个正八面体的6个顶点分别标记为A、B、C、D、E、F。
如果我们要给每个顶点涂上红色、蓝色或绿色之一,
使得相邻的顶点颜色不同,有多少种不同的涂色方案?
"""}
]
)
return completion.choices[0].message
# 对比测试:创意写作能力
def test_creative_writing():
completion = client.chat.completions.create(
model="deepseek-r1",
messages=[
{"role": "user", "content": "写一篇关于AI技术发展的议论文,要求结构完整,论证有力,字数2000字左右。"}
]
)
return completion.choices[0].message
print("数学推理测试:", test_aime_level_reasoning())
print("创意写作测试:", test_creative_writing())
### 🎯 AIME准确率提升 技术验证策略
这里简单介绍下我们使用的API平台。API易 是一个AI模型聚合平台,特点是 一个令牌,无限模型,可以用统一的接口调用 DeepSeek-R1、Claude 4、Gemini 2.5 Pro、GPT-4o 等各种模型。这对于验证DeepSeek R1-0528的能力提升特别有用,你可以轻松进行横向对比。
平台优势:官方源头转发、不限速调用、按量计费、7×24技术支持。特别适合需要高质量推理能力的研究和开发场景。
🔥 针对 AIME级别推理 的推荐模型
| 模型名称 | 推理能力优势 | 适用场景 | 推荐指数 |
|---|---|---|---|
| DeepSeek-R1 | AIME 2025: 87.5%准确率,深度推理 | 复杂数学问题、逻辑推理 | ⭐⭐⭐⭐⭐ |
| GPT-4o | 综合推理能力强,响应稳定 | 多领域推理对比基准 | ⭐⭐⭐⭐ |
| Claude-Sonnet-4-Thinking | 思维链展示清晰,推理过程详细 | 推理过程分析和学习 | ⭐⭐⭐⭐ |
🎯 测试建议:基于 AIME准确率突破 的特点,我们推荐优先使用 DeepSeek-R1 进行数学推理测试,它在复杂推理任务中表现突出,同时可以用其他模型作为对比基准。
🎯 AIME级别推理 场景推荐表
| 使用场景 | 首选模型 | 备选模型 | 经济型选择 | 特点说明 |
|---|---|---|---|---|
| 🔥 数学竞赛辅导 | DeepSeek-R1 | GPT-4o | Claude-Sonnet-4 | 接近人类竞赛选手水平 |
| 🖼️ 科研计算辅助 | DeepSeek-R1 | Claude-Opus-4 | GPT-4o-Mini | 复杂推理+准确性验证 |
| 🧠 逻辑推理分析 | DeepSeek-R1 | Claude-Sonnet-4-Thinking | GPT-4o | 多步骤深度推理 |
💰 价格参考:具体价格请参考 API易价格页面
✅ AIME准确率提升 实际验证
| 验证要点 | 具体建议 | 注意事项 |
|---|---|---|
| 🎯 推理深度对比 | 使用相同题目测试token使用量变化 | 新版本max_tokens建议设置32K+ |
| ⚡ 准确率验证 | 选择AIME历年真题进行批量测试 | 关注推理过程的逻辑完整性 |
| 💡 多能力融合测试 | 测试数学+创意写作+工具调用组合 | 验证综合能力是否协调提升 |
在测试DeepSeek R1-0528的能力提升时,我发现通过API进行批量对比测试是最有效的方法。API易 的稳定服务在这种大量测试场景下表现可靠,避免了因服务不稳定影响测试结果的问题。
❓ AIME准确率突破 常见问题
Q1: 从70%到87.5%,这17.5%的提升有多大意义?
在AIME这种高难度数学竞赛中,17.5%的提升是巨大的飞跃:
- 绝对难度:AIME是美国数学奥林匹克的选拔赛,题目难度极高
- 提升幅度:相对提升达到25%(17.5/70),这是质的变化
- 竞争水平:87.5%的准确率已经接近国际顶尖模型如o3、Gemini-2.5-Pro
类比理解:就像一个学生从数学竞赛的"省级水平"一跃成为"国家队候选",这不是量的积累,而是质的飞跃。
Q2: 思维深度从12K到23K tokens意味着什么?
思维深度翻倍代表推理质量的根本性改变:
计算复杂度角度:
- 12K tokens ≈ 中等复杂度推理
- 23K tokens ≈ 深度多步验证推理
实际意义:
- 更多验证步骤:不满足于第一个答案,会进行多路径验证
- 更细致的分解:将复杂问题拆解为更多中间步骤
- 自我纠错能力:能够发现并修正推理过程中的错误
成本考虑:虽然token使用量增加,但推理准确性的大幅提升使得性价比反而更高。
Q3: DeepSeek R1-0528还有哪些重要改进?
除了AIME突破,还有多个重要提升:
幻觉问题改善:
- 幻觉率降低45-50%
- 在改写润色、总结摘要、阅读理解场景表现显著提升
创意写作增强:
- 支持更长篇幅的创作(议论文、小说、散文)
- 写作风格更贴近人类偏好
- 结构内容更加完整
功能扩展:
- 新增Function Calling支持
- 支持JSON Output
- 前端代码生成能力提升
- 角色扮演能力优化
API改进:
- max_tokens语义调整,现在包含思考过程
- 默认32K,最大64K token限制
🏆 为什么选择「API易」体验AIME级别推理
| 核心优势 | 具体说明 | 推理测试价值 |
|---|---|---|
| 🛡️ 第一时间同步更新 | • DeepSeek-R1-0528当天上线 • 无需等待官方接口配额 • 稳定的高质量推理服务 |
抢先体验突破性能力 |
| 🎨 丰富的对比模型 | • 同时支持多种顶级推理模型 • 便于横向能力对比 • 统一接口降低测试成本 |
一个令牌,对比所有顶级模型 |
| ⚡ 推理友好的配置 | • 支持大token量推理调用 • 不限速适合深度推理 • 详细的推理过程展示 |
充分发挥模型推理能力 |
| 🔧 开发者优化 | • OpenAI兼容接口 • 完善的错误处理 • 推理参数灵活配置 |
专注推理能力测试 |
| 💰 推理成本优化 | • 按实际使用计费 • 高质量推理的性价比 • 批量测试优惠 |
推理质量与成本的最佳平衡 |
💡 AIME测试示例
以验证87.5%准确率为例,你可以:
- 选择AIME历年真题进行批量测试
- 对比DeepSeek-R1与其他顶级模型的表现
- 分析推理过程的深度和准确性
- 验证在复杂数学问题上的实际能力
🎯 总结
DeepSeek R1-0528从70%到87.5%的AIME准确率提升,不仅仅是数字上的进步,更代表着国产AI在复杂推理领域的 历史性突破。这一成就将DeepSeek R1推向了与国际顶尖模型同台竞技的水平。
技术突破回顾:
- 推理深度革命:思维token使用量翻倍,推理质量质变
- 准确率飞跃:17.5%的提升代表着从"优秀"到"顶尖"的跨越
- 综合能力提升:不仅是数学推理,幻觉改善、创意写作等全面升级
- 应用价值扩大:从研究工具升级为实用的AI助手
以上分析展示了DeepSeek R1-0528技术飞跃的深层价值。如果你想要实际验证这些突破性能力,可以结合 API易 的免费额度进行深度测试,确认效果后再制定具体的应用策略。
有任何技术问题,欢迎添加站长微信 8765058 交流讨论,会分享《大模型使用指南》等资料包。

📝 本文作者:API易团队
🔔 关注更新:欢迎关注我们的更新,持续分享 AI 开发经验和最新动态。