作者注:在模型正价不换廉价渠道的前提下,详解 OpenClaw 如何通过控制输入 Token 长度省钱:新对话隔离任务、精准检索代码块代替全文塞入、上下文剪枝、QMD 本地搜索等 6 大策略
OpenClaw 费 Token 是出了名的——有用户一天烧掉 2150 万 Token,月账单 $600+。很多人的第一反应是换廉价模型渠道,但这会牺牲质量。真正的省 Token 方法是控制输入端——你喂给模型多少上下文,才是成本的决定性因素。本文聚焦一个核心问题:在不换模型、不降质量的前提下,如何把输入 Token 从"全文塞进去"降到"精准喂进去"。
核心价值: 读完本文,你将掌握 6 个控制输入 Token 的实战策略,预期节省 50-90% 的 Token 成本。

OpenClaw 省 Token 核心要点
先明确一个前提:本文讨论的是不换模型、不降质量的省 Token 方法。你用的是正价的 Claude Opus 4.6 或 GPT-5,模型不变,省的是输入端。
| 策略 | 节省比例 | 实施难度 | 核心思路 |
|---|---|---|---|
| 新对话隔离任务 | 60-80% | 低 | 每个独立任务开新对话,避免历史积累 |
| 精准检索代码块 | 40-95% | 中 | 只喂相关代码片段,不塞全文 |
| 上下文剪枝 | 30-50% | 低 | 手动或自动清理无用对话历史 |
| QMD 本地搜索 | 80-90% | 中 | 本地向量检索,只发送相关片段 |
| Prompt Caching | 80-90%(输入成本) | 低 | 利用缓存避免重复发送系统提示 |
| 关闭 Thinking 模式 | 10-50x | 低 | 非推理任务关闭思考模式 |
OpenClaw Token 消耗的底层机制
理解省 Token 的前提是理解 OpenClaw 为什么费 Token。
每一次你在 OpenClaw 中发送消息,它不是只发送你这一条——而是把整个对话历史全部重新发送给模型。对话越长,每次请求的输入 Token 就越大。
具体来说,一次请求的输入包含:
- 系统提示(System Prompt):OpenClaw 的核心指令,通常 2000-5000 Token
- AGENTS.md / SOUL.md:工作空间配置文件
- 加载的 Skills:每个启用的 Skill 都占 Token
- 完整对话历史:从会话开始到现在的所有消息
- 工具调用结果:每次文件读取、命令执行的输出
- Memory 检索结果:从记忆库检索的相关内容
一个持续 30 分钟的 OpenClaw 会话,最后一条消息的输入 Token 可能已经达到 10 万甚至 100 万——而前 29 分钟的大部分内容对当前任务都不再有用。
策略一:OpenClaw 不同任务新开对话
这是最简单也最有效的策略。
为什么新对话能省 Token
假设你在同一个会话里做了 3 件事:修 Bug A → 写功能 B → 重构模块 C。到第三个任务时,模型的输入包含了前两个任务的所有对话历史和文件读取结果——但这些对重构模块 C 完全没用。
同一会话:
任务 A 对话历史(20K Token)
+ 任务 A 文件内容(30K Token)
+ 任务 B 对话历史(25K Token)
+ 任务 B 文件内容(40K Token)
+ 任务 C 当前消息(5K Token)
= 120K Token 输入(其中 115K 都是历史包袱)
新开会话:
任务 C 当前消息(5K Token)
+ 系统提示(3K Token)
= 8K Token 输入(节省 93%)
在对话场景里的最佳实践
| 场景 | 是否新开会话 | 原因 |
|---|---|---|
| 切换到完全不同的任务 | 新开 | 前一个任务的上下文完全无用 |
| 同一功能的迭代调整 | 继续 | 需要之前的讨论上下文 |
| 修不同文件的不同 Bug | 新开 | 每个 Bug 独立,不需要交叉上下文 |
| 同一模块的连续修改 | 继续 | 模型需要理解之前的修改意图 |
| 对话超过 20 轮 | 新开或 compact | 历史积累已经很多 |
🎯 实操建议: 一个简单的判断标准——如果你需要说"忘掉前面的,现在做另一件事",那就直接开新对话。
这个原则不仅适用于 OpenClaw,也适用于 Claude Code 和其他 AI 编码工具。通过 API易 apiyi.com 调用的每次独立 API 请求天然就是"新会话",不存在上下文积累问题。
策略二:OpenClaw 精准检索代码块,不塞全文
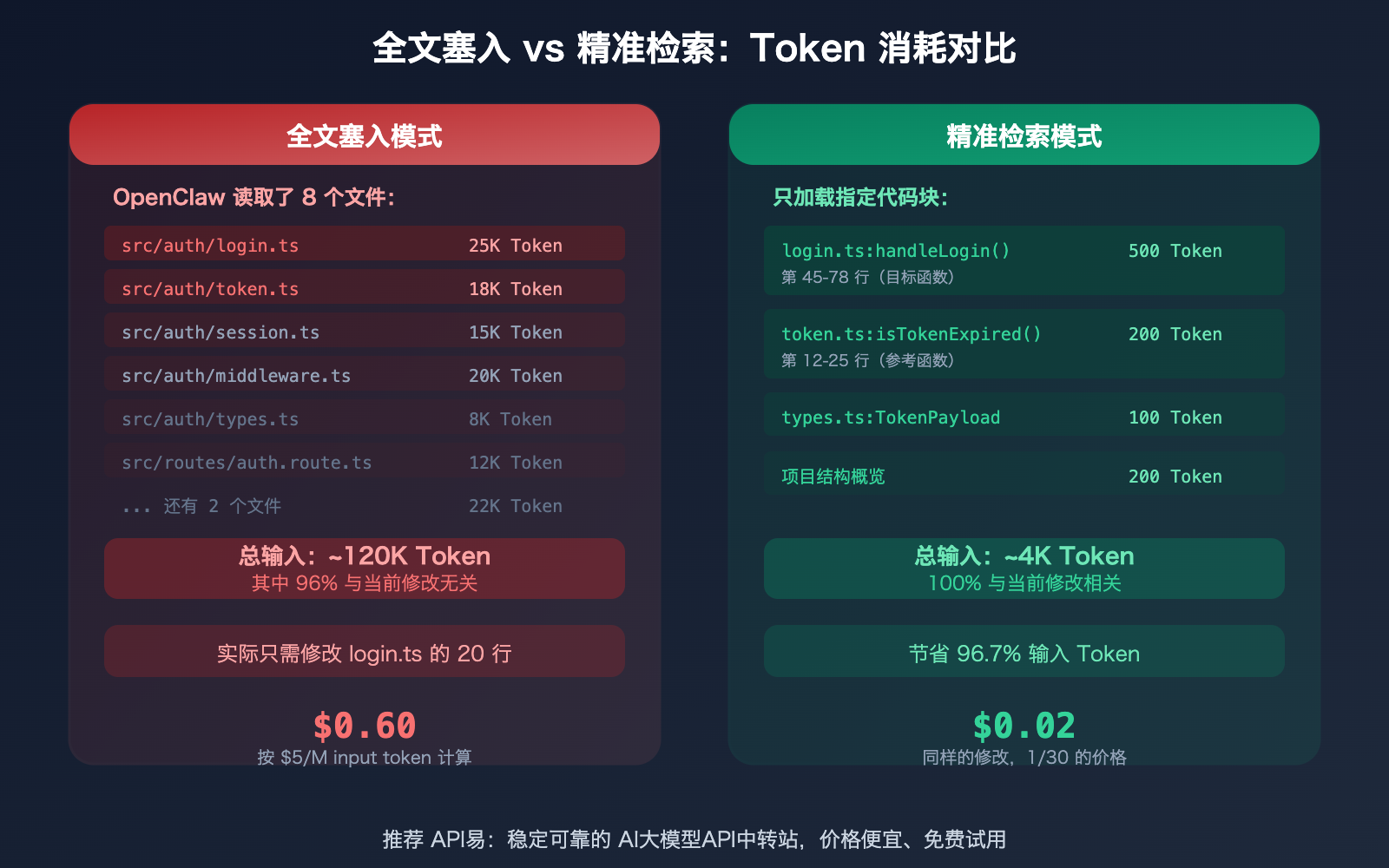
这是本文的核心重点——如何只让模型看到需要修改的代码块,而不是把整个文件甚至整个项目塞进去?
问题本质:"全文塞进去"为什么浪费
研究数据显示,AI 编码 Agent 有 80% 的 Token 浪费在"找东西"上。典型场景:你让 OpenClaw 修改一个函数,它先读了 25 个文件,只为找到那 3 个真正相关的函数——读取 25 个文件的 Token 成本全部算在你头上。
一个 1000 行的文件大约 15,000-25,000 Token。如果你只需要修改其中的 20 行(约 300-500 Token),但整个文件都被喂给模型,那 96-98% 的输入 Token 就浪费了。
OpenClaw 精准检索代码块的 4 个方法
方法一:明确指定文件和行号
不要说"修改登录功能",而是说"修改 src/auth/login.ts 的第 45-78 行 handleLogin 函数"。越精准的指令,OpenClaw 读取的文件越少。
❌ "修复登录 Bug"
→ OpenClaw 读取 10+ 文件,消耗 200K+ Token
✅ "修复 src/auth/login.ts 第 52 行的空指针检查"
→ OpenClaw 只读 1 个文件的相关部分,消耗 ~20K Token
方法二:利用 QMD 本地语义搜索
OpenClaw 的 QMD(Quick Memory Database)可以在本地建立向量索引,检索相关代码片段后只发送最相关的内容给模型。
启用方式:在 OpenClaw 设置中开启 QMD,它会自动索引你的项目文件和对话历史。后续查询时,QMD 先在本地找到相关代码块,只把精准匹配的片段发送给模型。
方法三:使用 @file 语法定向引用
在 OpenClaw 中可以用 @file 语法精确引用文件,避免模型自行搜索:
修改 @src/auth/login.ts 中的 handleLogin 函数,
添加对 refreshToken 过期的处理逻辑。
参考 @src/auth/token.ts 中的 isTokenExpired 方法。
这样 OpenClaw 只加载你指定的 2 个文件,而不是扫描整个 src/auth/ 目录。
方法四:项目结构文件引导
在 AGENTS.md 或 SOUL.md 中写明项目结构概览,让 OpenClaw 知道"哪个功能在哪个文件",减少探索式的文件扫描。
## 项目结构
- 认证相关: src/auth/ (login.ts, token.ts, session.ts)
- 用户管理: src/user/ (profile.ts, settings.ts)
- API 路由: src/routes/ (auth.route.ts, user.route.ts)
这个概览本身只占几百 Token,但能帮 OpenClaw 省掉数万 Token 的盲目文件扫描。
策略三至六:OpenClaw 进阶省 Token 技巧
策略三:上下文剪枝(Context Pruning)
OpenClaw 支持手动和自动的上下文剪枝。当对话过长时,可以清理掉不再需要的历史消息。
OpenClaw 2026.3.7 引入了 Context Engine Plugins,允许第三方插件提供替代的上下文管理策略(之前这部分是硬编码在核心中的)。lossless-claw 插件可以在不丢失关键信息的前提下压缩对话历史。
实操建议:
- 每完成一个子任务后,手动清理无关的工具调用输出
- 设置
contextTokens: 50000限制上下文窗口大小 - 使用 compact 功能压缩对话历史
策略四:QMD 本地语义搜索
QMD(Quick Memory Database)是 OpenClaw 的本地向量搜索功能。它在本地设备上建立向量数据库,索引对话历史和文档。查询时先在本地搜索相关内容,只把最相关的片段发送给模型。
效果:减少 80-90% 的输入 Token 成本。
策略五:利用 Prompt Caching
Claude 和 GPT 模型家族都支持 Prompt Caching——当系统提示或常用上下文没有变化时,API 自动使用缓存版本,输入 Token 成本降低 80-90%。
但有一个关键限制: 通过 OpenAI 兼容格式(/v1/chat/completions)调用 Claude 时不支持 Prompt Caching,必须使用 Anthropic 原生格式(/v1/messages)。如果你通过 API易 apiyi.com 调用,平台支持原生格式的 Prompt Caching。
策略六:非推理任务关闭 Thinking
Thinking/Reasoning 模式会让 Token 消耗暴增 10-50 倍。如果当前任务不需要深度推理(比如简单的格式化、文件移动、文本替换),关闭 Thinking 模式能大幅节省。
| 任务类型 | 是否需要 Thinking | Token 差异 |
|---|---|---|
| 复杂 Bug 分析 | 需要 | 正常消耗 |
| 架构设计 | 需要 | 正常消耗 |
| 简单格式化 | 不需要 | 关闭后省 10-50x |
| 文件移动/重命名 | 不需要 | 关闭后省 10-50x |
| 生成样板代码 | 看情况 | 简单模板可关闭 |
提示: Claude Code 的 Context Compaction 和 OpenClaw 的 Context Pruning 解决的是同一个问题——控制累积的输入 Token。如果你同时使用两个工具,可以通过 API易 apiyi.com 统一管理 API 调用额度。
OpenClaw 与 Claude Code 省 Token 对比
两个工具面对的问题一样,但解决方案有差异。

常见问题
Q1: 新开对话后,模型不了解项目背景怎么办?
利用 OpenClaw 的 Memory 系统和 AGENTS.md 文件。Memory 会自动在新会话中检索相关的项目背景信息(只发送最相关的片段,而不是全部历史)。AGENTS.md 中写好项目结构和关键约定,每次新会话自动加载——这比把 20 轮对话历史全部带入高效得多。
Q2: 怎么知道当前会话的 Token 消耗了多少?
OpenClaw 的对话记录保存在 .openclaw/agents.main/sessions/ 目录下的 JSONL 文件中,你可以直接查看每次请求的 Token 数量。更方便的做法是使用 API 提供商的用量面板——通过 API易 apiyi.com 调用时,后台可以看到每次请求的精确 Token 消耗和费用。
Q3: QMD 和直接用 grep 搜索有什么区别?
grep 是精确匹配——你搜"handleLogin"只能找到包含这个字符串的地方。QMD 是语义搜索——你搜"用户登录的错误处理",它能找到所有语义相关的代码块,即使代码中没有"登录"或"错误处理"这些字符串。语义搜索的精准度更高,送给模型的无关内容更少,省的 Token 更多。
Q4: Heartbeat 为什么会消耗大量 Token?
OpenClaw 的 Heartbeat(心跳)机制会定期检查任务状态。如果设置间隔太短(比如每 5 分钟),每次心跳都会带上完整的会话上下文发送给模型——有用户发现自动邮件检查功能一天烧掉了 $50。解决方法:延长心跳间隔,或者在不需要自动监控时暂停 Heartbeat。
总结
OpenClaw 省 Token 的核心要点(不换模型、不降质量):
- 输入 Token 是成本大头(70-85%): 每次请求都把全部对话历史重发,对话越长越贵。最简单的省法是不同任务新开对话
- 精准检索代码块是最大杠杆: 从"全文塞进去"(120K Token)到"精准喂进去"(4K Token),同样的修改节省 96%。方法:明确指定文件行号、@file 引用、QMD 语义搜索、AGENTS.md 结构声明
- 三阶段优化路径: 5 分钟见效(新对话 + 关 Thinking,省 50%)→ 30 分钟见效(精准指令 + 限制上下文,省 80%)→ 长期(QMD + Caching,省 97%)
推荐通过 API易 apiyi.com 管理 OpenClaw 的 API 调用,平台提供精确的 Token 用量统计和费用监控,帮你量化每次优化的实际效果。
📚 参考资料
-
OpenClaw Token 使用与成本控制指南: 官方的 Token 管理文档
- 链接:
docs.openclaw.ai/reference/token-use - 说明: 包含 contextTokens 配置和 Heartbeat 优化
- 链接:
-
OpenClaw 省 Token 实战:从 $600 降到 $20: 完整的三阶段优化框架
- 链接:
blog.laozhang.ai/en/posts/openclaw-save-money-practical-guide - 说明: 包含具体的配置参数和预期节省比例
- 链接:
-
AI 编码 Agent 80% Token 浪费在找东西: 上下文精准度研究
- 链接:
medium.com/@jakenesler/context-compression-to-reduce-llm-costs - 说明: 解释了为什么精准检索比加大上下文窗口更有效
- 链接:
-
API易文档中心: Token 用量统计和费用监控
- 链接:
docs.apiyi.com - 说明: 支持 OpenClaw 和 Claude Code 的 API 调用管理
- 链接:
作者: APIYI 技术团队
技术交流: 欢迎在评论区讨论,更多资料可访问 API易 docs.apiyi.com 文档中心



