作者注:深度对比 2026 年最强的 3 款数学解题 AI 模型,含 AIME、MATH 等权威基准测试数据,帮你找到最适合的数学推理模型
数学解题用什么 AI 模型好,一直是开发者和学生群体最关心的选择之一。本文对比 Gemini 3.1 Pro Preview、Claude Sonnet 4.6 和 GPT-5.4 三款 2026 年最新发布的数学推理模型,从基准测试成绩、推理能力、API 价格和适用场景等维度给出明确建议。
核心价值:看完本文,你将明确在不同数学解题场景下该选择哪款 AI 模型,以及如何以最优成本调用它们。

数学解题 AI 模型 核心对比速览
在进入详细分析之前,先看一张核心数据对比表,帮你快速了解三款数学解题 AI 模型的关键差异。
| 对比维度 | Gemini 3.1 Pro Preview | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|---|
| 发布时间 | 2026 年 2 月 19 日 | 2026 年初 | 2026 年 3 月 6 日 |
| AIME 2025 | 92%(无工具) | — | 100%(满分) |
| MATH 基准 | 95.1% | 89% | 88.6% |
| GPQA Diamond | 94.3% | 74.1% | 84.2% |
| ARC-AGI-2 | 77.1% | 58.3% | 73.3% |
| 输入价格 | $2.00/1M tokens | $3.00/1M tokens | $2.50/1M tokens |
| 输出价格 | $12.00/1M tokens | $15.00/1M tokens | $15.00/1M tokens |
| 综合推荐 | ⭐ 首选推荐 | ⭐ 学习首选 | ⭐ 竞赛首选 |
数学解题 AI 模型推荐排序
从综合性价比角度,我们给出以下排序建议:
- 首选 Gemini 3.1 Pro Preview:MATH 基准 95.1% 领跑,价格最低,综合数学能力最强
- 次选 Claude Sonnet 4.6:数学能力跃升 27 个百分点,解题过程清晰易懂,适合学习场景
- 竞赛级 GPT-5.4:AIME 2025 满分 100%,适合高难度数学竞赛和专业研究
🎯 技术建议:三款模型均可通过 API易 apiyi.com 平台统一调用,建议在实际数学问题上逐一测试,选出最匹配你需求的模型。
Gemini 3.1 Pro Preview 数学解题能力详解
Gemini 3.1 Pro Preview 是 Google DeepMind 于 2026 年 2 月 19 日发布的最新旗舰模型。这是 Google 首次使用「.1」版本增量(此前中期更新一律使用「.5」),标志着这是一次专注于智能推理能力的定向升级。
Gemini 3.1 Pro 数学基准测试成绩
| 基准测试 | 得分 | 说明 |
|---|---|---|
| MATH | 95.1% | 涵盖代数、几何、微积分等多领域的综合数学测试 |
| AIME 2025(无工具) | 92% | 美国数学邀请赛,高中竞赛级难度 |
| AIME 2025(代码执行) | 100% | 前代 Gemini 3 Pro 开启代码执行后满分 |
| GPQA Diamond | 94.3% | 研究生级别科学问答,领先所有同级模型 |
| ARC-AGI-2 | 77.1% | 抽象推理能力,比前代 3 Pro 翻倍 |
| MathArena Apex | 显著领先 | 较前代提升超过 20 倍 |
Gemini 3.1 Pro 在 Google 官方公布的 18 项主流基准测试中,有 12 项取得了第一名的成绩。在数学推理方面,MATH 基准 95.1% 的表现尤为突出,意味着它在代数、几何、概率、微积分等各个数学子领域都具备极强的解题能力。
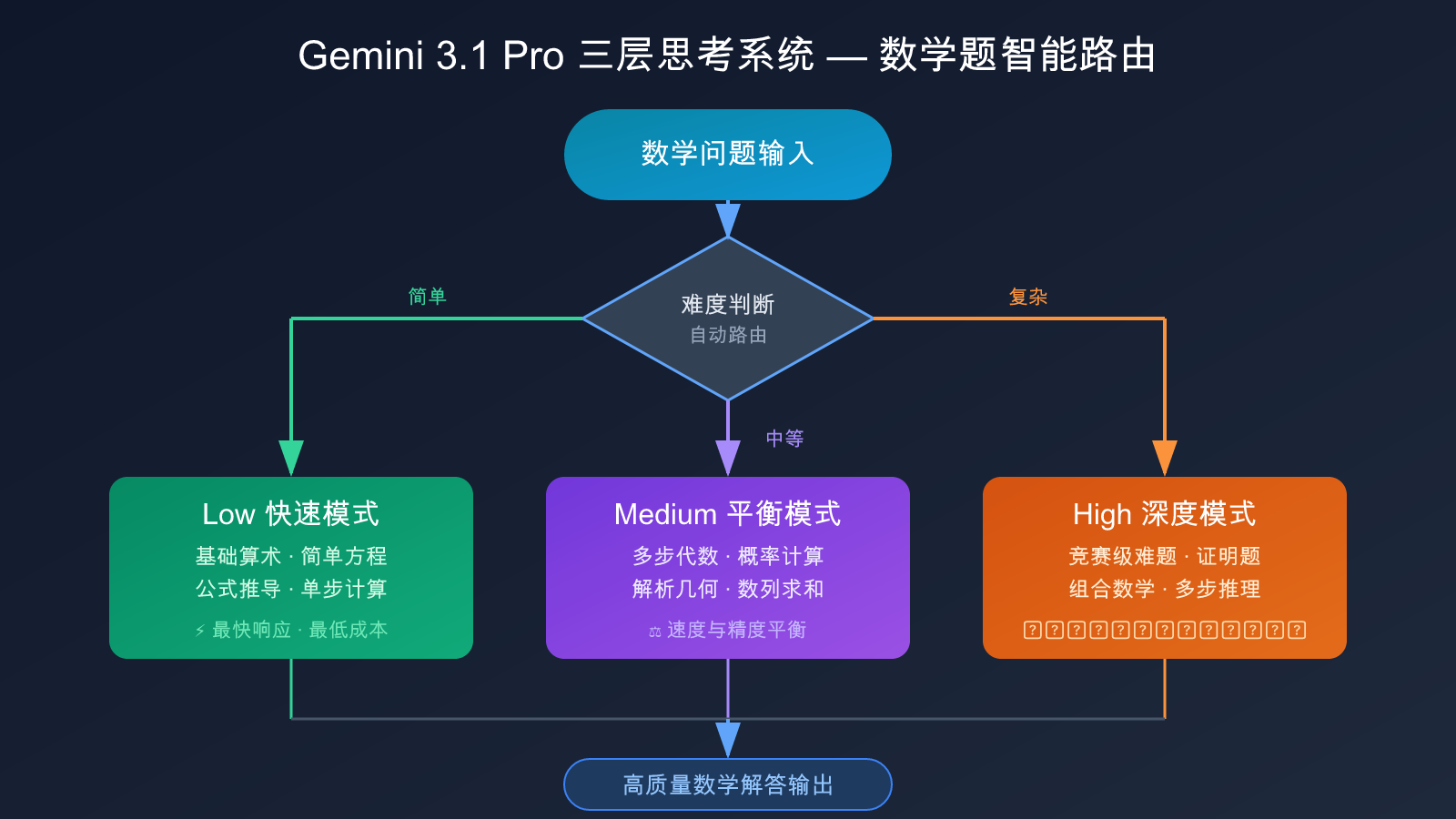
Gemini 3.1 Pro 三层思考系统
Gemini 3.1 Pro 引入了一个关键的架构创新——三层思考系统:
- Low(快速模式):处理简单的数学计算和公式推导,响应速度最快
- Medium(平衡模式):新增的中间层,处理中等难度的数学问题,平衡速度和准确性
- High(深度模式):处理复杂的多步推理问题,如竞赛级数学题
这个三层系统让开发者可以根据数学问题的难度灵活路由,不必在「快但粗糙」和「慢但精准」之间做二选一。对于批量处理不同难度数学题的场景(比如教育平台的自适应出题系统),这一架构优势尤为明显。
Gemini 3.1 Pro 数学解题实际体验
在实际数学解题中,Gemini 3.1 Pro Preview 的表现可以用「全面而稳定」来概括:
- 代数领域:多项式运算、方程组求解、不等式证明等问题几乎零失误,得益于 MATH 95.1% 的高覆盖率
- 几何领域:解析几何和立体几何的推理链完整,尤其在坐标系相关的计算题上表现出色
- 概率统计:条件概率、排列组合等问题的推理逻辑清晰,能够正确处理复杂的分步计算
- 微积分:定积分、不定积分的求解准确,能识别常见的积分技巧并正确运用
Gemini 3.1 Pro 在 18 项主流基准中 12 项第一的成绩并非偶然。其 Artificial Analysis Intelligence Index 得分为 57 分,与 GPT-5.4(xhigh)并列第一,远超中位数 28 分,体现了全方位的智能推理优势。
Claude Sonnet 4.6 数学解题能力详解
Claude Sonnet 4.6 是 Anthropic 发布的最新中端模型,在数学推理能力上实现了质的飞跃——从前代 Sonnet 4.5 的 62% 直接跃升至 89%,整整提高了 27 个百分点。
Claude Sonnet 4.6 数学基准测试成绩
| 基准测试 | Sonnet 4.6 | Sonnet 4.5(前代) | 提升幅度 |
|---|---|---|---|
| 数学综合 | 89% | 62% | +27 个百分点 |
| ARC-AGI-2 | 58.3% | 13.6% | 4.3 倍提升 |
| GPQA Diamond | 74.1% | — | 研究生级科学推理 |
| 编程能力 | 79.6% | — | 接近 Opus 4.6 的 80.8% |
| 金融分析 | 63.3% | — | 同级别最佳 |
数学能力从 62% 到 89% 的跃升是 Sonnet 4.6 最引人注目的变化之一。这意味着它从一个「偶尔在数学题上犯错的模型」,蜕变为一个「能够可靠处理复杂计算的模型」。
Claude Sonnet 4.6 自适应思考机制
Claude Sonnet 4.6 的另一个亮点是自适应思考深度(Adaptive Thinking)机制:
- 简单问题:快速响应,不浪费推理资源。例如基础算术、简单方程求解
- 中等问题:适度延伸思考链。例如多步骤代数运算、概率计算
- 复杂问题:自动触发深度推理链。例如组合数学、证明题、竞赛级问题
这种自适应机制在实际使用中的好处是:你不需要手动调节推理深度,模型会自动判断数学问题的难度并分配相应的计算资源,在延迟和成本之间取得最优平衡。
Claude Sonnet 4.6 的独特优势:解题过程
在数学解题场景中,Claude Sonnet 4.6 有一个被广泛认可的独特优势——解题过程的清晰度。多项评测指出,Claude 模型在解释数学概念方面表现最佳。此外,Anthropic 推出的 Learning Mode(学习模式)专门设计用于引导学生的推理过程,而非直接给出答案。
这使得 Claude Sonnet 4.6 特别适合:
- 数学教育和辅导场景
- 需要理解解题步骤的学习者
- 希望验证解题思路的研究人员
💡 学习建议:如果你的核心需求是「理解数学解题过程」而非仅获取答案,Claude Sonnet 4.6 是最佳选择。可通过 API易 apiyi.com 获取免费测试额度来体验其解题过程的详细程度。
GPT-5.4 数学解题能力详解
GPT-5.4 是 OpenAI 于 2026 年 3 月 6 日发布的最新旗舰模型。它是首个在同一默认模型中整合前沿专业能力、编程能力(来自 GPT-5.3-Codex)、原生计算机操作和 1.05M 上下文窗口的 OpenAI 推理模型。
GPT-5.4 数学基准测试成绩
| 基准测试 | 得分 | 说明 |
|---|---|---|
| AIME 2025 | 100%(满分) | 高中数学竞赛级别,完美表现 |
| GSM8K | 99% | 小学数学应用题,近乎完美 |
| MATH | 88.6% | 综合数学推理基准 |
| GPQA Diamond | 84.2%(标准)/ 92.8%(高推理) | 研究生级科学推理 |
| ARC-AGI-2 | 73.3%(标准)/ 83.3%(Pro) | 抽象推理能力 |
| FrontierMath(前代 5.2) | 40.3% | 专家级前沿数学新纪录 |
GPT-5.4 在 AIME 2025 上取得了满分 100% 的惊人成绩,这意味着它能完美解决美国数学邀请赛中的所有高难度竞赛题目。对于需要解决竞赛级数学问题的用户来说,这一表现极具说服力。
值得注意的是,GPT-5.4 在 MATH 基准上的得分为 88.6%,相比 Gemini 3.1 Pro 的 95.1% 有一定差距。这说明 GPT-5.4 虽然在竞赛级难题上表现完美,但在覆盖广泛数学领域的综合测试中并非最强。
GPT-5.4 推理配置选项
GPT-5.4 提供多种推理配置来适配不同的数学问题:
- GPT-5.4 标准版:适合日常数学计算和中等难度问题
- GPT-5.4 Thinking:启用高级推理,适合复杂多步推理和证明
- GPT-5.4 Pro:最高性能配置,ARC-AGI-2 可达 83.3%,适合最高难度场景
不过需要注意,GPT-5.4 Pro 的价格为 $30.00/1M 输入 + $180.00/1M 输出,成本远高于标准版。对于大多数数学解题场景,标准版已经足够。
GPT-5.4 数学解题实际体验
GPT-5.4 在竞赛级数学题上的表现尤其惊艳:
- 竞赛数学:AMC/AIME 级别的数论、组合、几何综合题几乎完美作答,满分 100% 的 AIME 成绩实至名归
- 证明题:能够构建完整的数学证明链条,逻辑严密,步骤之间的衔接自然
- 应用数学:GSM8K 99% 的成绩说明它在实际应用题(如工程计算、经济建模)上也非常可靠
- 多步推理:得益于 1.05M 的超长上下文窗口,能够在保持完整推理链的同时处理极其复杂的多步数学问题
GPT-5.4 的一个独特优势是其前代 GPT-5.2 在 FrontierMath(专家级前沿数学)上创下了 40.3% 的新纪录。这意味着 GPT 系列在真正前沿的、未解决的数学问题上也具备一定的探索能力,这是其他模型目前难以企及的。
数学解题 AI 模型 基准测试解读
在对比数学解题 AI 模型之前,有必要理解各项基准测试的含义和侧重点,以便更准确地判断模型能力:
| 基准测试 | 全称 | 测试内容 | 难度级别 |
|---|---|---|---|
| AIME 2025 | American Invitational Mathematics Examination | 美国数学邀请赛真题,涵盖数论、组合、几何等 | 高中竞赛级(Top 5% 学生) |
| MATH | Mathematics Aptitude Test of Heuristics | 覆盖代数、几何、微积分等 7 大领域的综合测试 | 高中到本科级别 |
| GSM8K | Grade School Math 8K | 8000 道小学到初中数学应用题 | 基础级别 |
| GPQA Diamond | Graduate-Level Google-Proof QA | 研究生级别的科学推理问题,由领域专家编写 | 研究生/博士级别 |
| ARC-AGI-2 | Abstraction and Reasoning Corpus | 全新逻辑模式识别,测试抽象推理能力 | 通用智能级别 |
| FrontierMath | Frontier Mathematics | 专家级前沿数学问题,涉及未解决或新领域 | 专家/研究员级别 |
关键理解:AIME 更侧重竞赛级数学技巧和创造性思维,MATH 更侧重广泛领域的综合覆盖能力。一个模型在 AIME 上满分但 MATH 上不是最高分(如 GPT-5.4),说明它在竞赛级巧题上极强,但在某些基础领域的覆盖面可能略逊于 MATH 得分更高的模型。
这也是为什么我们推荐 Gemini 3.1 Pro Preview 作为综合首选——MATH 95.1% 意味着它在各个数学子领域都有更均衡的表现。
需要注意的是,AIME 2025 基准目前已趋于饱和——多款顶级模型(结合代码执行)都能达到 95% 以上甚至满分。因此,更能区分模型真实数学能力的是 MathArena Apex 和 FrontierMath 这类更高难度的基准。在 MathArena Apex 上,Gemini 3.1 Pro 较前代实现了超过 20 倍的提升,显示出极强的内在数学推理基础。
另一个值得关注的维度是 ARC-AGI-2(抽象推理能力)。这项测试评估模型识别全新逻辑模式的能力——这些模式是模型在训练中从未见过的。Gemini 3.1 Pro Preview 以 77.1% 领先,说明它不仅能解决见过的题型,还具备更强的泛化推理能力,面对全新类型的数学问题时表现更好。
数学解题 AI 模型 API 调用实战
以下是使用 API 调用数学解题 AI 模型的极简代码示例,10 行代码即可运行:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # API易 统一接口
)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview", # 可切换为 claude-sonnet-4.6 或 gpt-5.4
messages=[{"role": "user", "content": "求解: 已知等差数列{an}的首项a1=2,公差d=3,求前20项的和S20"}]
)
print(response.choices[0].message.content)
查看完整数学解题调用代码(含多模型对比)
import openai
from typing import Optional
def solve_math(
problem: str,
model: str = "gemini-3.1-pro-preview",
system_prompt: Optional[str] = None
) -> str:
"""
调用 AI 模型解数学题
Args:
problem: 数学题目描述
model: 模型名称,支持 gemini-3.1-pro-preview / claude-sonnet-4.6 / gpt-5.4
system_prompt: 系统提示词,可指定解题风格
Returns:
模型的解题响应
"""
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # API易 统一接口
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
else:
messages.append({
"role": "system",
"content": "你是一个数学解题专家,请用清晰的步骤解答数学问题,每步都要说明推理依据。"
})
messages.append({"role": "user", "content": problem})
try:
response = client.chat.completions.create(
model=model,
messages=messages,
max_tokens=2000
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# 使用示例:同一道题用三个模型解答对比
problem = "在三角形ABC中,已知a=5, b=7, C=60°,求三角形面积和第三边c的长度"
models = ["gemini-3.1-pro-preview", "claude-sonnet-4.6", "gpt-5.4"]
for m in models:
print(f"\n{'='*50}")
print(f"模型: {m}")
print(f"{'='*50}")
result = solve_math(problem, model=m)
print(result)
建议:通过 API易 apiyi.com 获取免费测试额度,一个 API Key 即可调用上述三款数学解题模型,快速对比它们在你实际题目上的表现差异。
数学解题 AI 模型 价格与性价比对比
选择数学解题 AI 模型时,价格是一个不可忽视的因素。以下是三款模型的详细价格对比:
| 价格维度 | Gemini 3.1 Pro Preview | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|---|
| 输入价格 | $2.00/1M tokens | $3.00/1M tokens | $2.50/1M tokens |
| 输出价格 | $12.00/1M tokens | $15.00/1M tokens | $15.00/1M tokens |
| 混合价格(3:1) | $4.50/1M tokens | $6.00/1M tokens | $5.63/1M tokens |
| 长上下文加价 | >200K 翻倍 | 无 | >272K 翻倍 |
| 上下文窗口 | 1M tokens | 标准窗口 | 1.05M tokens |
| 最大输出 | 65,536 tokens | 标准输出 | 128,000 tokens |
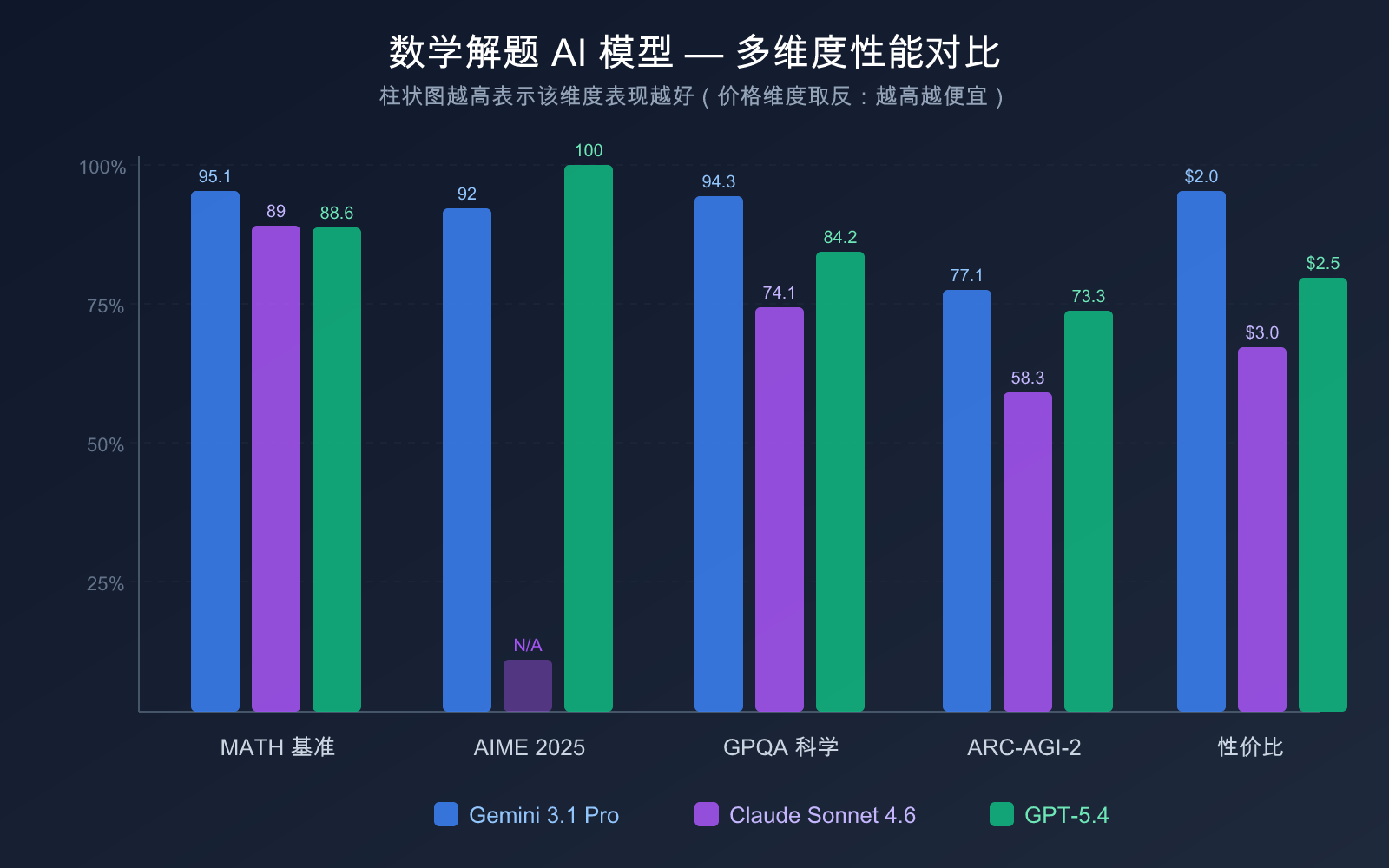
从性价比角度分析:
- Gemini 3.1 Pro Preview 性价比最高:输入价格仅 $2.00/1M tokens,且 MATH 基准成绩 95.1% 领先。据 Artificial Analysis 分析,其运营成本约为 Claude Opus 4.6 的 1/7.5,却在数学和编程基准上持平甚至超越
- Claude Sonnet 4.6 价格适中:$3.00/$15.00 的定价与前代 Sonnet 4.5 持平,但数学能力提升了 27 个百分点,性价比大幅改善
- GPT-5.4 标准版价格合理:$2.50/$15.00 的定价在合理范围内,但如果使用 GPT-5.4 Pro($30/$180),成本将大幅上升
💰 成本建议:对于日常数学解题需求,推荐使用 Gemini 3.1 Pro Preview 获得最优性价比。如需进一步优化成本,可考虑使用 API 聚合平台获取更灵活的充值方案。
数学解题成本实际估算
为了帮你更直观地理解成本差异,以下是一个典型数学解题场景的成本估算:
场景假设:每天解答 100 道中等难度数学题,每题平均消耗 500 输入 tokens + 1500 输出 tokens。
| 模型 | 日输入成本 | 日输出成本 | 日总成本 | 月成本(30天) |
|---|---|---|---|---|
| Gemini 3.1 Pro | $0.10 | $1.80 | $1.90 | $57.00 |
| GPT-5.4 | $0.13 | $2.25 | $2.38 | $71.25 |
| Claude Sonnet 4.6 | $0.15 | $2.25 | $2.40 | $72.00 |
| GPT-5.4 Pro | $1.50 | $27.00 | $28.50 | $855.00 |
| DeepSeek R2 | $0.03 | $0.33 | $0.36 | $10.80 |
从成本估算可以清晰看到:
- Gemini 3.1 Pro Preview 的月成本约 $57,是三款主力模型中最经济的
- Claude Sonnet 4.6 和 GPT-5.4 标准版的成本相近,约 $71-72/月
- GPT-5.4 Pro 的成本高达 $855/月,仅适合预算充裕且需要极致准确率的场景
- DeepSeek R2 以 $10.80/月 的超低成本提供了极具竞争力的方案
数学解题 AI 模型 综合智能指数对比
除了单项基准测试,综合智能指数能更全面地反映模型的数学推理潜力。Artificial Analysis Intelligence Index 是目前最权威的综合评估体系之一,它基于推理、知识、数学和编程四个维度计算模型的综合得分。
| 模型 | 综合智能指数 | AIME 2025 | MATH | GPQA Diamond | ARC-AGI-2 | 综合评价 |
|---|---|---|---|---|---|---|
| GPT-5.4(xhigh) | 57 | 100% | 88.6% | 84.2% | 73.3% | 竞赛题王者,综合指数并列第一 |
| Gemini 3.1 Pro Preview | 57 | 92% | 95.1% | 94.3% | 77.1% | 综合指数并列第一,数学覆盖最全 |
| Claude Opus 4.6 | 53 | — | — | 91.3% | — | 科学推理和解释能力顶尖 |
| Claude Sonnet 4.6(max) | 52 | — | 89% | 74.1% | 58.3% | 性价比优秀,解题过程最清晰 |
从综合智能指数来看,GPT-5.4(xhigh)和 Gemini 3.1 Pro Preview 以 57 分并列第一,但两者的侧重点不同:
- GPT-5.4:在 AIME 这类竞赛题上表现完美(100%),但 MATH 综合基准(88.6%)略低
- Gemini 3.1 Pro:在 MATH 综合基准(95.1%)和科学推理 GPQA Diamond(94.3%)上更均衡
这意味着如果你的数学需求偏向竞赛和极端难题,GPT-5.4 更胜一筹;如果需要覆盖广泛数学领域的稳定表现,Gemini 3.1 Pro Preview 是更安全的选择。
数学解题 AI 模型 场景推荐
不同的数学应用场景对模型有不同的需求。以下是基于实际使用场景的推荐方案:
选择 Gemini 3.1 Pro Preview 的数学场景
- 综合数学辅导平台:覆盖代数、几何、微积分等全领域,MATH 95.1% 的综合能力最强
- 大批量数学题处理:价格最低,三层思考系统可自动适配题目难度,降低处理成本
- 科学计算结合场景:GPQA Diamond 94.3% 的科学推理能力,适合物理、化学与数学交叉的题目
- 可视化数学问题:在处理包含图表、几何图形的数学题上,Gemini 的多模态能力具有优势
选择 Claude Sonnet 4.6 的数学场景
- 数学教育和辅导:解题过程最清晰,Learning Mode 专门引导学生推理,不直接给答案而是引导思考
- 解题步骤学习:需要理解「为什么这样做」的场景,Claude 的解释能力被公认最佳。70% 的用户偏好 Sonnet 4.6 而非前代 4.5,说明其用户体验有了质的飞跃
- 数学研究辅助:适合需要详细推导过程的研究人员验证思路,自适应思考深度可以自动匹配问题复杂度
- 办公和金融计算:金融分析 63.3% 同级最佳,办公生产力 GDPval-AA 得分 1633 Elo 甚至超越了更昂贵的 Opus 4.6
- 编程+数学结合:编程能力 79.6% 接近 Opus 4.6,适合需要编写数学计算程序的开发者
选择 GPT-5.4 的数学场景
- 高难度数学竞赛:AIME 满分 100%,竞赛级数学题的首选模型
- 长文档数学推理:1.05M 上下文窗口,适合处理需要大量数学背景信息的复杂问题
- 专业数学研究:前代 GPT-5.2 在 FrontierMath 上创下 40.3% 的新纪录,专家级前沿数学能力强
- 投行和量化金融:投行建模任务 87.3% 的高分,适合高端金融数学场景
混合使用策略:数学解题模型最佳组合
在实际生产环境中,很多团队采用混合使用策略来获得最佳效果:
策略一:难度分级路由
- 基础题(算术、简单方程)→ Gemini 3.1 Pro Low 模式,成本最低
- 中等题(多步推理、应用题)→ Claude Sonnet 4.6 自适应模式,解题过程清晰
- 高难度题(竞赛、证明)→ GPT-5.4 Thinking 模式,准确率最高
策略二:交叉验证
- 先用 Gemini 3.1 Pro 快速解题(成本低、速度快)
- 关键结果用 GPT-5.4 二次验证(准确率高)
- 需要解释给用户时用 Claude Sonnet 4.6 重新表述(表达清晰)
🚀 实施建议:上述混合使用策略可通过 API易 apiyi.com 平台轻松实现,一个 API Key 即可调用所有模型,只需在代码中切换 model 参数。
数学解题 AI 模型 决策建议
综合上述分析,以下是针对不同用户群体的决策建议:
| 用户类型 | 推荐模型 | 推荐理由 |
|---|---|---|
| 学生/自学者 | Claude Sonnet 4.6 | 解题过程清晰,Learning Mode 引导思考 |
| 教育平台开发者 | Gemini 3.1 Pro Preview | 综合能力最强,价格最低,三层思考适配难度 |
| 竞赛选手/教练 | GPT-5.4 | AIME 满分,竞赛级问题解答能力最强 |
| 科研人员 | Gemini 3.1 Pro Preview | GPQA Diamond 94.3%,科学+数学交叉能力领先 |
| 企业批量处理 | Gemini 3.1 Pro Preview | 性价比最高,$2.00/1M tokens 输入价格 |
| 金融量化团队 | GPT-5.4 | 投行建模 87.3%,金融数学场景最强 |
💡 选择建议:选择哪款数学解题 AI 模型主要取决于你的具体应用场景。如果你不确定哪款最适合,我们建议通过 API易 apiyi.com 平台用同一道数学题测试三款模型,根据解题质量和响应速度做出最终选择。平台支持统一接口调用,便于快速对比和切换。
其他值得关注的数学解题模型
除了上述三款主力模型,还有几款在特定场景下值得关注的数学解题 AI 模型:
| 模型名称 | AIME 2025 | 核心优势 | API 价格(输入/输出) | 适合场景 |
|---|---|---|---|---|
| DeepSeek R2 | 击败 Gemini 3.1 Pro | 极致性价比 | $0.55/$2.19 per 1M | 预算敏感的批量数学处理 |
| Claude Opus 4.6 | — | GPQA 91.3%,解释最深 | $15/$75 per 1M | 高端科研和深度推理 |
| Qwen3-235B | 89.2% | 开源最强 | 自部署成本 | 需要私有化部署的场景 |
| DeepSeek R1 | 约 87.5% | 开源标杆,671B MoE | 自部署成本 | 开源社区研究和二次开发 |
| MiMo-V2-Flash | 94.1% | 推理成本仅 Claude 的 2.5% | 极低 | 超大规模低成本推理 |
其中特别值得关注的是 DeepSeek R2,它在 AIME 上击败了 Gemini 3.1 Pro Preview,而价格仅为后者的 1/4 左右。如果你的数学解题场景对预算极其敏感,DeepSeek R2 是一个极具竞争力的选择。
而 MiMo-V2-Flash 在 AIME 2025 上达到了 94.1% 的高分,推理成本却仅为 Claude 的 2.5%,非常适合需要大规模批量处理数学题的教育科技平台。
数学解题 AI 模型提示词优化技巧
无论选择哪款模型,好的提示词都能显著提升数学解题质量。以下是经过验证的数学解题提示词技巧:
- 明确题目类型:在提示词中标注「这是一道组合数学题」或「这是解析几何题」,帮助模型调用正确的解题策略
- 要求分步解答:添加「请逐步推导,每步标注使用的定理或公式」,提升解题过程的可读性
- 指定输出格式:如「请用 LaTeX 格式输出数学公式」或「最终答案用方框标注」
- 提供背景约束:如「假设 x 为正整数」或「在实数范围内求解」,避免模型产生不必要的分类讨论
- 多模型交叉验证:对关键结果,用不同模型验证答案一致性,提升置信度
常见问题
Q1:数学解题 AI 模型的基准测试成绩可信吗?
基准测试提供了标准化的横向对比依据,但实际效果还受题目类型、提示词质量等因素影响。AIME 和 MATH 是目前最权威的数学推理基准,被学术界和工业界广泛认可。建议在参考基准数据的同时,用你自己的实际题目进行测试验证。
Q2:我是学生,应该选哪个数学解题 AI 模型?
建议首选 Claude Sonnet 4.6。它的解题过程最为清晰,每一步都有明确的推理说明,非常适合学习和理解数学解题思路。Anthropic 的 Learning Mode 功能还能引导你自己思考,而非直接给答案。如果遇到特别难的竞赛题,可以切换到 GPT-5.4 寻求帮助。
Q3:如何快速开始测试这些数学解题 AI 模型?
推荐使用支持多模型统一接口的 API 聚合平台进行测试:
- 访问 API易 apiyi.com 注册账号
- 获取 API Key 和免费测试额度
- 使用本文提供的 Python 代码示例,修改 model 参数即可切换不同模型
- 用相同的数学题分别测试三款模型,对比解题质量和响应速度
Q4:这些数学解题 AI 模型支持 LaTeX 公式输出吗?
三款模型都支持 LaTeX 格式的数学公式输出。在提示词中添加「请用 LaTeX 格式输出所有数学公式」即可。Gemini 3.1 Pro 和 GPT-5.4 的 LaTeX 格式化更规范,Claude Sonnet 4.6 则在公式之间的文字解释上更详细。对于需要直接复制公式到论文的场景,建议使用 Gemini 或 GPT。
Q5:数学解题 AI 模型能处理图片中的数学题吗?
Gemini 3.1 Pro Preview 和 GPT-5.4 都支持多模态输入,可以直接上传包含数学题的图片进行解答。Gemini 在处理包含几何图形和手写公式的图片上表现尤为出色。Claude Sonnet 4.6 同样支持图片输入,但在复杂几何图形的识别上略逊于 Gemini。如果你的数学题经常以图片形式出现(如拍照搜题),Gemini 3.1 Pro Preview 是最佳选择。
总结
数学解题 AI 模型的核心选择要点:
- 综合能力首选 Gemini 3.1 Pro Preview:MATH 95.1% 综合领先,$2.00/1M tokens 价格最优,三层思考系统灵活适配不同难度
- 学习理解首选 Claude Sonnet 4.6:数学能力跃升 27 个百分点至 89%,解题步骤清晰,自适应思考深度平衡成本与质量
- 竞赛难题首选 GPT-5.4:AIME 2025 满分 100%,1.05M 超长上下文,高难度推理能力无出其右
没有一款模型在所有数学场景中都是最优解。2026 年数学解题 AI 模型的竞争格局可以这样总结:
- 综合覆盖:Gemini 3.1 Pro Preview 以 MATH 95.1% 和最低价格占据综合首选位置
- 学习教育:Claude Sonnet 4.6 凭借 27 个百分点的数学跃升和无与伦比的解题解释能力,成为教育场景的最佳选择
- 极限竞赛:GPT-5.4 以 AIME 满分的绝对实力,在高难度数学竞赛领域无人能及
- 预算优先:DeepSeek R2 以不到 Gemini 1/4 的价格提供可比的数学推理能力
最明智的策略是根据你的实际需求选择合适的模型,甚至在不同难度的题目上混合使用多款模型,充分利用每款模型的独特优势。
推荐通过 API易 apiyi.com 快速测试和对比这些模型,平台提供免费额度和统一 API 接口,一次接入即可灵活调用所有主流数学推理模型,轻松实现多模型混合使用策略。
📚 参考资料
-
Google DeepMind Gemini 3.1 Pro 模型卡:官方基准数据和技术细节
- 链接:
deepmind.google/models/model-cards/gemini-3-1-pro/ - 说明: 包含完整的基准测试成绩和架构说明
- 链接:
-
Anthropic Claude Sonnet 4.6 发布说明:数学推理能力提升详情
- 链接:
docs.anthropic.com - 说明: 包含 Sonnet 4.6 与前代对比数据和自适应思考机制说明
- 链接:
-
OpenAI GPT-5.4 发布公告:最新模型功能和基准数据
- 链接:
openai.com/index/introducing-gpt-5-4/ - 说明: 包含 GPT-5.4 完整基准测试成绩和推理配置说明
- 链接:
-
Artificial Analysis 模型评测:独立第三方基准对比平台
- 链接:
artificialanalysis.ai/evaluations/aime-2025 - 说明: 提供 AIME 2025 等基准测试的独立排行榜和分析
- 链接:
-
AIME 2025 基准排行榜:数学推理能力权威对比
- 链接:
vals.ai/benchmarks/aime - 说明: 持续更新的 AI 数学推理基准排行数据
- 链接:
作者:APIYI 技术团队
技术交流:欢迎在评论区分享你的数学解题 AI 使用体验,更多模型调用教程可访问 API易 docs.apiyi.com 文档中心