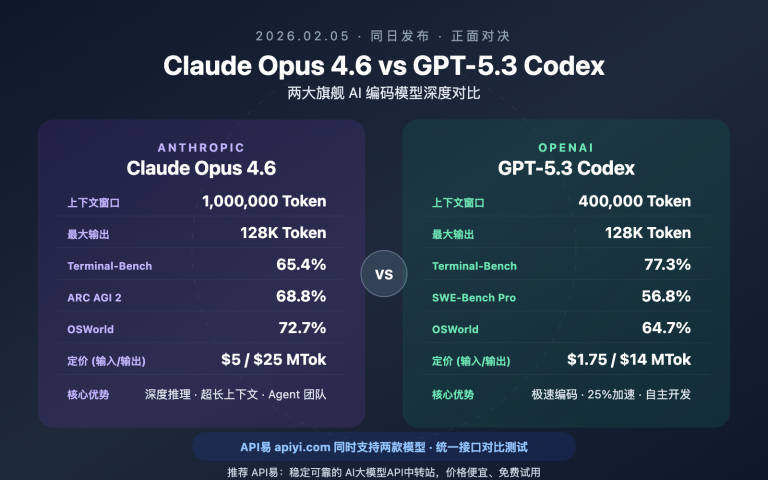
很多开发者在使用 Claude API 时都会遇到一个困惑:明明开启了 prompt caching,为什么账单上看不到缓存优惠?
答案往往很简单——你用的是 OpenAI 兼容模式调用,而 Claude 的缓存计费只支持 Anthropic 原生 Messages API 格式。
这不是 bug,而是 Anthropic 官方文档中明确说明的设计限制。本文将从技术原理、调用方式、定价对比 3 个维度,帮你彻底搞懂 Claude prompt caching 的正确用法,避免踩坑多花冤枉钱。
Claude Prompt Caching 缓存机制核心原理
在深入调用格式差异之前,先理解 Claude prompt caching 的工作原理。
Claude 缓存是如何工作的
当你发送一个启用了 prompt caching 的请求时,系统会执行以下流程:
- 检查缓存: 系统检查请求的 prompt 前缀是否已经在最近的查询中被缓存
- 命中缓存: 如果找到匹配,直接使用缓存版本,大幅减少处理时间和成本
- 写入缓存: 如果未命中,处理完整 prompt 并在响应开始后缓存前缀
| Claude Prompt Caching 核心参数 | 说明 |
|---|---|
| 缓存类型 | ephemeral (短暂缓存,目前唯一支持的类型) |
| 默认 TTL | 5 分钟 (每次命中自动刷新) |
| 可选 TTL | 1 小时 (额外付费) |
| 最大缓存断点 | 4 个 cache_control 标记 |
| 缓存顺序 | tools → system → messages |
| 缓存匹配方式 | 100% 完全一致的 prompt 前缀 |
Claude Prompt Caching 支持缓存的内容
Claude prompt caching 可以缓存请求中的大部分内容块:
- Tools:
tools数组中的工具定义 - System messages:
system数组中的内容块 - Text messages:
messages.content数组中的文本内容块 - Images & Documents: 用户消息中的图片和文档
- Tool use & tool results: 工具调用和结果的内容块
🎯 技术建议: 对于需要频繁调用相同系统提示词的场景,prompt caching 是最有效的成本优化手段。我们建议通过 API易 apiyi.com 平台使用 Anthropic 原生格式调用 Claude API,充分利用缓存计费优惠。
Anthropic 原生格式 vs OpenAI 兼容模式:Claude 缓存支持差异
这是本文最核心的部分——两种调用格式在 Claude 缓存功能上的根本差异。
Anthropic 官方明确声明
根据 Anthropic 官方 OpenAI SDK 兼容性文档的原文:
"Prompt caching is not supported, but it is supported in the Anthropic SDK"
这意味着,如果你通过 OpenAI 兼容模式 (/v1/chat/completions 端点) 调用 Claude,完全无法使用 prompt caching 功能。
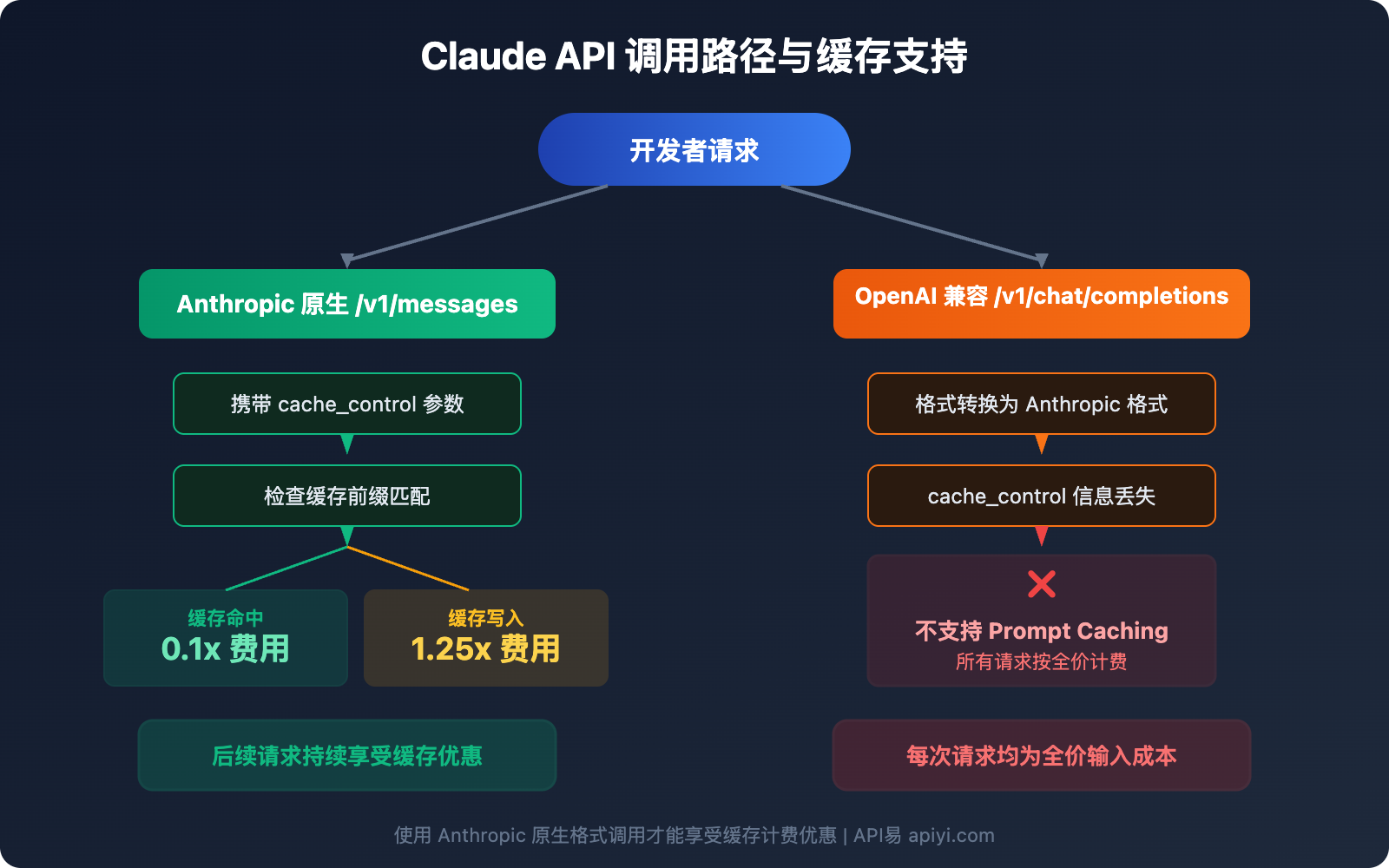
Claude API 两种调用格式功能对比
| 功能特性 | Anthropic 原生格式 | OpenAI 兼容模式 |
|---|---|---|
| Prompt Caching 缓存 | ✅ 完全支持 | ❌ 不支持 |
| PDF 文档处理 | ✅ 支持 | ❌ 不支持 |
| Citations 引用 | ✅ 支持 | ❌ 不支持 |
| Extended Thinking 完整输出 | ✅ 支持 | ⚠️ 部分支持 (无法查看思考过程) |
| Streaming 流式输出 | ✅ 支持 | ✅ 支持 |
| Tool Use 工具调用 | ✅ 支持 | ✅ 支持 |
| Vision 图像理解 | ✅ 支持 | ✅ 支持 |
| Structured Outputs | ✅ 支持 (strict 模式) | ❌ strict 参数被忽略 |
为什么 OpenAI 兼容模式不支持 Claude 缓存
OpenAI 兼容模式的设计定位是测试和对比模型能力,而非生产环境使用:
- 协议差异:
cache_control参数是 Anthropic Messages API 的原生字段,在 OpenAI chat completions 格式中没有对应字段 - 架构限制: 兼容层需要将 OpenAI 格式转换为 Anthropic 格式,这个转换过程中缓存控制信息会丢失
- 优先级考量: Anthropic 官方表示,兼容层的优先级低于原生 Claude API 的可靠性和功能完整性
💡 重要提示: 如果你的业务依赖 prompt caching 来控制成本,必须使用 Anthropic 原生 Messages API 格式,而不是 OpenAI 兼容模式。
Claude Prompt Caching 缓存定价详解:最高省 90% 成本
Claude prompt caching 的定价结构是它最吸引人的地方——缓存命中的读取价格仅为基础输入价格的 10%。
Claude 全模型缓存价格对比
| 模型 | 基础输入 | 5分钟缓存写入 | 1小时缓存写入 | 缓存读取 | 输出 |
|---|---|---|---|---|---|
| Claude Opus 4.6 | $5/MTok | $6.25/MTok | $10/MTok | $0.50/MTok | $25/MTok |
| Claude Sonnet 4.6 | $3/MTok | $3.75/MTok | $6/MTok | $0.30/MTok | $15/MTok |
| Claude Sonnet 4.5 | $3/MTok | $3.75/MTok | $6/MTok | $0.30/MTok | $15/MTok |
| Claude Haiku 4.5 | $1/MTok | $1.25/MTok | $2/MTok | $0.10/MTok | $5/MTok |
MTok = 百万 Token。数据来源: Anthropic 官方定价页面 (2026年2月)
Claude 缓存定价计算规则
缓存定价遵循 3 个简单的乘数规则:
- 5 分钟缓存写入: 基础输入价格 × 1.25
- 1 小时缓存写入: 基础输入价格 × 2.0
- 缓存读取 (命中): 基础输入价格 × 0.1
以 Claude Sonnet 4.6 为例,假设你有一个 10 万 Token 的系统提示词:
| 场景 | 每次请求输入成本 | 10,000 次请求总成本 |
|---|---|---|
| 不使用缓存 | $0.30 | $3,000 |
| 首次请求 (缓存写入) | $0.375 | 一次性成本 |
| 后续请求 (缓存命中) | $0.03 | $300 |
| 节省比例 | 约 90% |
💰 成本优化: 对于重复使用相同 system prompt 的场景,通过 API易 apiyi.com 平台以 Anthropic 原生格式调用 Claude API,可以充分利用 prompt caching 实现最高 90% 的成本节省。
Claude Prompt Caching 实战代码:Anthropic 原生格式调用
下面通过具体代码示例,展示如何正确启用 Claude prompt caching。
基础调用示例:Anthropic 原生格式 + Extended Thinking
curl https://api.apiyi.com/v1/messages \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-YOUR_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-d '{
"model": "claude-sonnet-4-6",
"max_tokens": 16000,
"stream": false,
"thinking": {
"type": "enabled",
"budget_tokens": 10000
},
"messages": [
{
"role": "user",
"content": "What is 27 * 453?"
}
]
}'
上面是一个基础的 Anthropic 原生格式调用,使用了 Extended Thinking 功能。接下来看如何在此基础上启用 prompt caching。
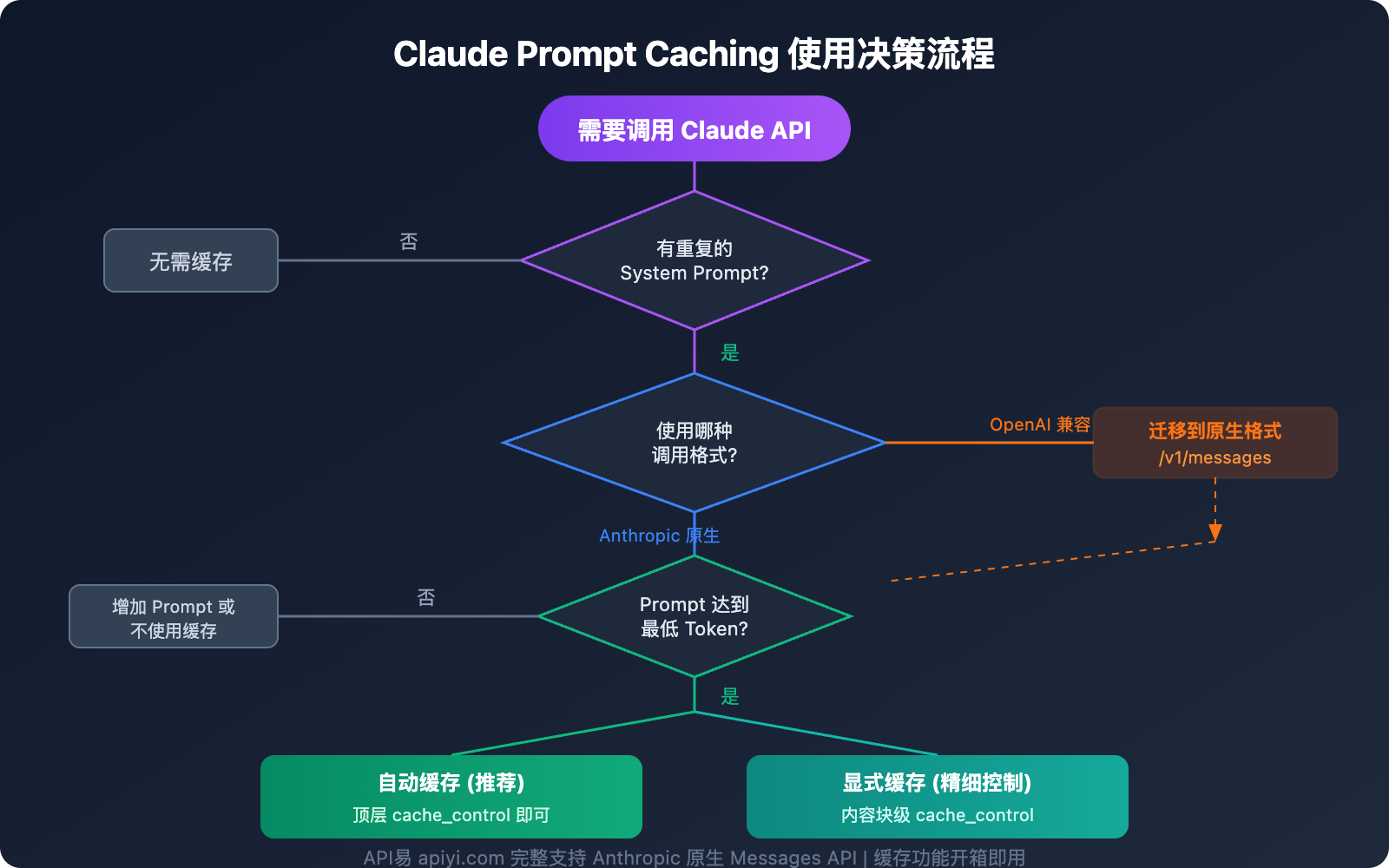
自动缓存模式:最简单的 Claude 缓存启用方式
自动缓存是启用 Claude prompt caching 最简单的方式——只需在请求体顶层添加 cache_control 字段:
curl https://api.apiyi.com/v1/messages \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-YOUR_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-d '{
"model": "claude-sonnet-4-6",
"max_tokens": 1024,
"cache_control": {"type": "ephemeral"},
"system": "你是一个专业的技术文档助手,帮助用户理解 AI 模型的使用方法和最佳实践。你的回答应该准确、简洁、实用。",
"messages": [
{"role": "user", "content": "Claude Sonnet 4.6 有哪些主要特性?"},
{"role": "assistant", "content": "Claude Sonnet 4.6 是 Anthropic 推出的高性能模型..."},
{"role": "user", "content": "它的上下文窗口有多大?"}
]
}'
自动缓存模式下,系统会自动将缓存断点放在最后一个可缓存的内容块上。在多轮对话中,缓存点会随着对话增长自动前移。
显式缓存模式:精确控制 Claude 缓存内容
对于需要精细控制缓存行为的场景,可以在特定内容块上放置 cache_control:
📄 展开查看完整的显式缓存代码示例
curl https://api.apiyi.com/v1/messages \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-YOUR_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-d '{
"model": "claude-sonnet-4-6",
"max_tokens": 1024,
"system": [
{
"type": "text",
"text": "你是一个法律文档分析助手,擅长分析合同条款和法律风险。"
},
{
"type": "text",
"text": "[这里放入一份 50 页的法律合同全文...约 10 万 Token 的内容]",
"cache_control": {"type": "ephemeral"}
}
],
"messages": [
{
"role": "user",
"content": "请分析这份合同中的关键条款和潜在风险。"
}
]
}'
在这个示例中,大量的法律文档被标记为缓存内容。首次请求会写入缓存,后续 5 分钟内对同一文档的不同问题查询,都会命中缓存,只需支付 10% 的读取费用。
1 小时长效缓存:Claude 扩展缓存时长
如果 5 分钟默认缓存时长不够用,可以选择 1 小时缓存:
"cache_control": {"type": "ephemeral", "ttl": "1h"}
1 小时缓存适用于:
- Agent 工作流中的长时间任务 (超过 5 分钟)
- 用户对话间隔可能超过 5 分钟的场景
- 需要更高 rate limit 利用率的场景 (缓存命中不扣减 rate limit)
🚀 快速开始: 推荐使用 API易 apiyi.com 平台快速测试 Claude prompt caching 功能。该平台完整支持 Anthropic 原生 Messages API 格式,包括
cache_control参数,5 分钟即可完成集成验证。
Claude Prompt Caching 缓存性能监控与调试
启用缓存后,需要通过 API 响应中的 usage 字段来监控缓存效果。
Claude 缓存响应中的关键字段
{
"usage": {
"input_tokens": 50,
"cache_creation_input_tokens": 100000,
"cache_read_input_tokens": 0,
"output_tokens": 500
}
}
| 字段 | 含义 |
|---|---|
input_tokens |
缓存断点之后的输入 Token 数 |
cache_creation_input_tokens |
本次写入缓存的 Token 数 |
cache_read_input_tokens |
从缓存读取的 Token 数 |
output_tokens |
输出 Token 数 |
总输入 Token 计算公式:
total_input = cache_read_input_tokens + cache_creation_input_tokens + input_tokens
Claude 缓存未命中的常见原因排查
如果你发现缓存始终未命中,检查以下问题:
- 调用格式错误: 使用了 OpenAI 兼容模式而非 Anthropic 原生格式
- 内容不一致: 缓存匹配要求 100% 完全一致的 prompt 前缀
- Token 不足: 未达到模型的最低缓存 Token 数要求
- 超时失效: 超过 5 分钟未使用导致缓存过期
- 参数变更: 修改了
tool_choice、图片内容或 thinking 参数
Claude 各模型最低缓存 Token 要求
| 模型系列 | 最低可缓存 Token 数 |
|---|---|
| Claude Opus 4.6 / Opus 4.5 | 4,096 tokens |
| Claude Sonnet 4.6 / Sonnet 4.5 / Sonnet 4 / Opus 4.1 / Opus 4 | 1,024 tokens |
| Claude Haiku 4.5 | 4,096 tokens |
| Claude Haiku 3.5 / Haiku 3 | 2,048 tokens |
如果你的 prompt 不到最低 Token 数,即使标记了 cache_control 也不会生效——请求会正常处理但不会缓存。
🎯 调试技巧: 在 API易 apiyi.com 平台调用 Claude API 时,可以通过响应中的
usage字段快速判断缓存是否生效。如果cache_read_input_tokens为 0 且cache_creation_input_tokens也为 0,说明缓存功能未正确启用。
Claude Prompt Caching 缓存常见问题 FAQ
Q1: OpenAI 兼容模式下调用 Claude 能使用缓存吗?
不能。 这是 Anthropic 官方明确声明的限制。OpenAI 兼容模式 (/v1/chat/completions 端点) 不支持 prompt caching。你必须使用 Anthropic 原生 Messages API 格式 (/v1/messages 端点) 才能使用缓存功能。
通过 API易 apiyi.com 平台,你可以同时使用两种格式调用 Claude API——如果需要缓存功能,选择 /v1/messages 端点即可。
Q2: Claude 缓存写入比普通输入贵,还值得用吗?
绝对值得。 缓存写入仅比基础输入贵 25% (5 分钟 TTL),但缓存命中只需要 10% 的费用。只要同一内容被使用 2 次以上,就能回本并开始省钱。以 10 万 Token 的 system prompt 为例:
- 无缓存: 每次 $0.30 (Sonnet 4.6)
- 缓存写入: $0.375 (仅首次)
- 缓存读取: $0.03 (后续每次)
- 第 2 次调用就开始省钱
Q3: 如何在代码中从 OpenAI 格式迁移到 Anthropic 原生格式?
关键改动点:
- 端点:
/v1/chat/completions→/v1/messages - 请求头: 添加
anthropic-version: 2023-06-01 - 消息格式:
messages数组结构基本一致 - System prompt: 从
messages中提取到独立的system字段 - 添加
cache_control参数
API易 apiyi.com 平台同时支持两种端点,迁移时只需修改请求路径和格式即可,无需更换 API Key。
Q4: Claude 缓存可以跨请求共享吗?
缓存在同一 Workspace 内共享 (2026年2月5日起从组织级改为 Workspace 级隔离)。不同组织之间绝不共享缓存。
Q5: 缓存和 Batch API 可以叠加使用吗?
可以。 Batch API 提供 50% 折扣,缓存定价的乘数在此基础上叠加。两者结合可以实现最大的成本优化。建议在批量处理场景下使用 1 小时缓存 TTL 以提高命中率。
总结:Claude Prompt Caching 缓存计费的 3 个核心要点
通过本文的分析,关于 Claude prompt caching 缓存计费,你需要记住 3 个关键点:
- 只支持 Anthropic 原生格式: 缓存功能仅在
/v1/messages端点可用,OpenAI 兼容模式 (/v1/chat/completions) 不支持 - 缓存命中成本仅 10%: 首次写入多付 25%,但后续每次命中只需基础价格的十分之一,2 次调用即可回本
- 正确的调用方式是关键: 使用
cache_control: {"type": "ephemeral"}参数,确保达到模型最低缓存 Token 要求
推荐通过 API易 apiyi.com 平台体验 Claude prompt caching 的完整功能。该平台完整支持 Anthropic 原生 Messages API,帮助你以最优成本使用 Claude 模型。
参考资料
-
Anthropic 官方 Prompt Caching 文档: Claude API 缓存功能详解
- 链接:
platform.claude.com/docs/en/build-with-claude/prompt-caching
- 链接:
-
Anthropic 官方定价页面: Claude 模型和缓存定价
- 链接:
platform.claude.com/docs/en/about-claude/pricing
- 链接:
-
OpenAI SDK 兼容性文档: 兼容模式功能限制说明
- 链接:
platform.claude.com/docs/en/api/openai-sdk
- 链接:
📝 作者: APIYI Team | API易技术团队,专注 AI 大模型 API 集成与技术分享。访问 apiyi.com 获取更多技术教程。