作者注:深入分析 Sora 2 生成視頻時中文字亂碼的原因,提供角色一致性、後期處理、替代模型等 5 種解決方案
使用 Sora 2 生成視頻時,圖片背景中的漢字變成亂碼是許多創作者面臨的棘手問題。本文將深入分析 Sora 2 中文字亂碼 的技術原因,並提供 5 種經過驗證的解決方案。
核心價值: 讀完本文,你將瞭解 Sora 2 文字渲染的技術限制,掌握多種繞過中文亂碼問題的實用方法。
Sora 2 中文字亂碼核心要點
| 要點 | 說明 | 解決思路 |
|---|---|---|
| 技術限制 | Sora 2 的文字渲染對非英文語言支持較弱 | 理解限制,選擇合適的應對策略 |
| 像素生成原理 | AI 生成的是"視覺相似"的像素,而非精確字符 | 採用後期處理或替代方案 |
| 抽卡機制 | 即使同一提示詞,每次生成結果也不同 | 多次嘗試或使用一致性工具 |
| 角色一致性 | 可通過角色庫保持部分元素穩定 | 將文字元素轉化爲"角色"屬性 |
| 後期處理 | 專業創作者普遍採用後期疊加文字 | 使用 FFmpeg、Kapwing 等工具 |
Sora 2 中文字亂碼技術原因詳解
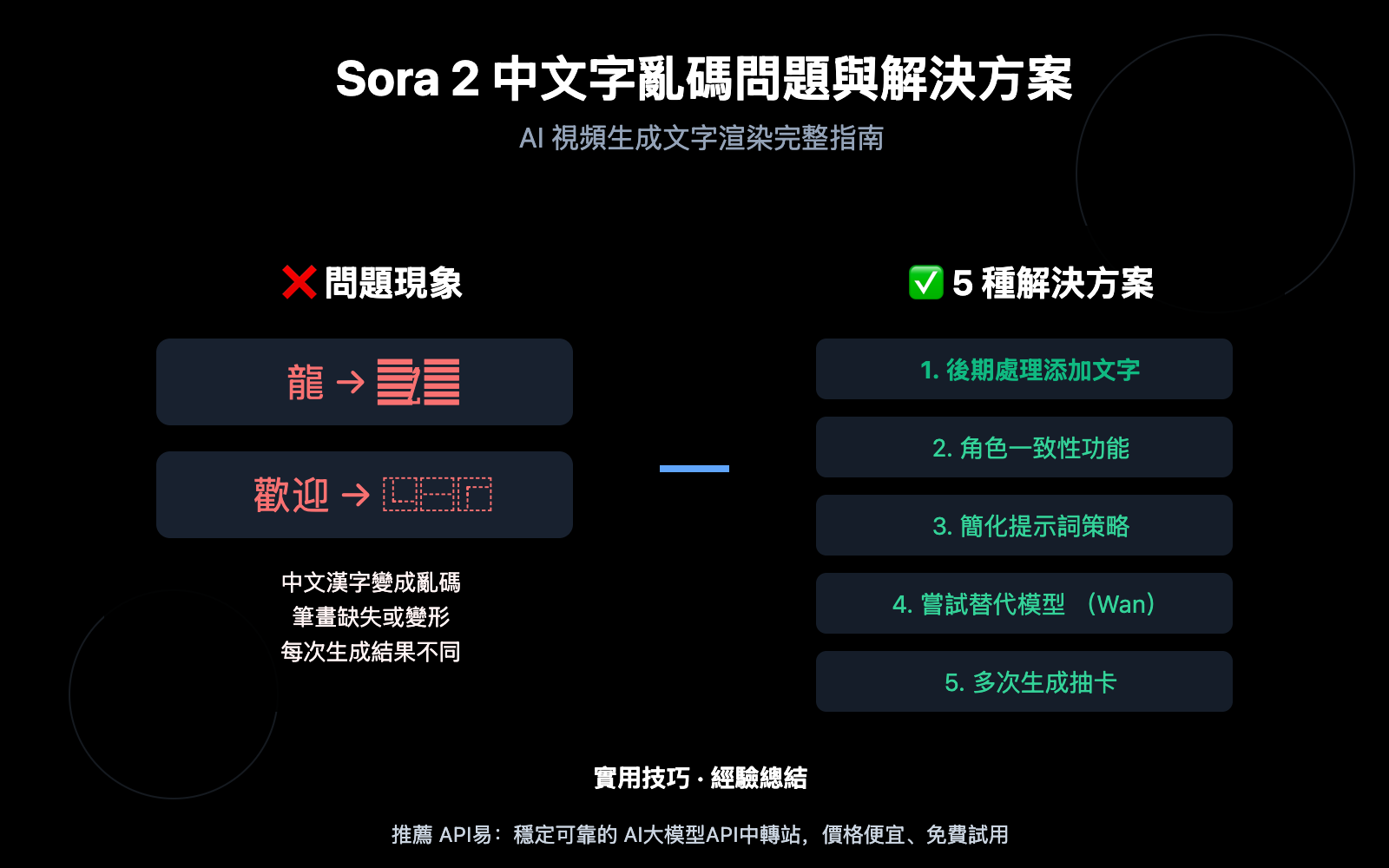
Sora 2 作爲 OpenAI 推出的視頻生成模型,其文字渲染問題源於底層技術架構。根據實際測試,Sora 2 生成的視頻中"任何場景中的文字通常都會變成亂碼或無意義的字符"。這一問題在中文等非拉丁語系文字上尤爲明顯。
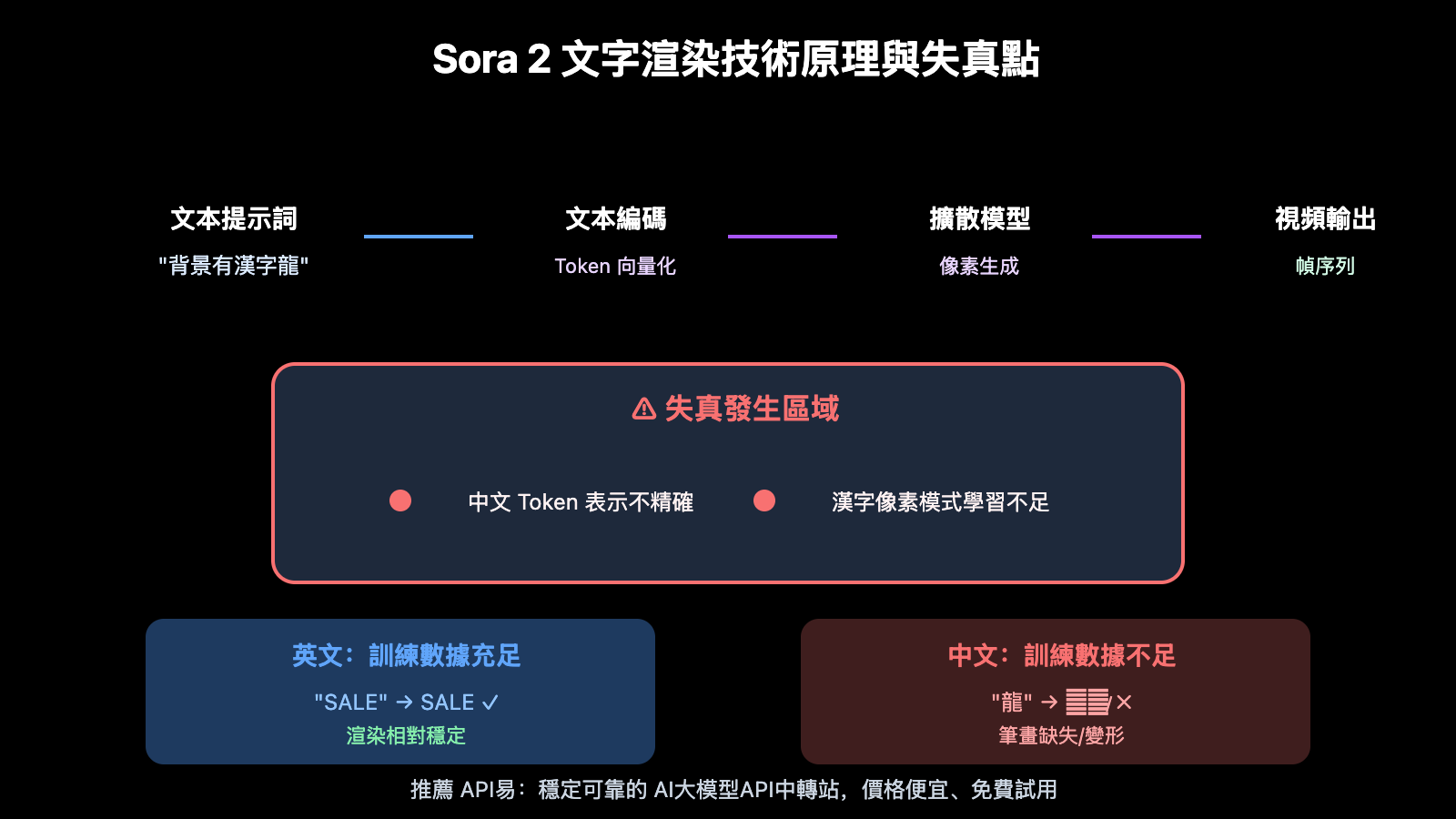
從技術原理來看,AI 視頻生成模型本質上是在生成"看起來像文字"的像素圖案,而非真正渲染字符。當模型在文本提示與視覺輸出之間進行映射時,會產生不確定性的疊加——提示詞中的細微歧義可能導致視覺表現的偏差、元素缺失或結果錯位。
英文渲染相對穩定的原因在於訓練數據中英文素材佔比更高。對於中文文字,建議使用 1-2 個字符的關鍵詞配合高對比度描述,因爲 Sora 2 對非英文語言的文字渲染仍然較弱,具體化描述可以減少模型的"猜測"空間。
Sora 2 中文字亂碼 5 種解決方案
方案一:後期處理添加文字(推薦)
這是專業創作者最常用的方法,也是目前最可靠的解決方案。核心思路是:生成不含文字的純淨視頻,然後在後期製作中疊加文字圖層。
推薦工具:
| 工具 | 特點 | 適用場景 |
|---|---|---|
| FFmpeg | 命令行工具,可批量處理 | 開發者、自動化流程 |
| Kapwing | 在線編輯器,操作簡單 | 快速疊加字幕和標題 |
| Descript | AI 輔助剪輯,支持字幕 | 長視頻、播客內容 |
| 剪映/CapCut | 中文界面,模板豐富 | 短視頻創作者 |
操作步驟:
- 在 Sora 2 提示詞中明確描述場景,但避免要求生成具體文字
- 下載生成的視頻素材
- 使用視頻編輯工具添加文字圖層
- 調整文字動畫與視頻畫面匹配
實踐建議: 將 Sora 2 的輸出視爲"原始素材"而非成品。專業工作流通常會進行後期增強,包括音效設計和調色處理。通過 API易 apiyi.com 可以批量調用 Sora 2 API 生成素材,再統一後期處理。
方案二:角色一致性功能
部分用戶嘗試將帶有文字的物品設置爲"角色",通過 Sora 2 的角色一致性功能來保持文字元素的穩定。
操作方式:
- 準備一張包含清晰中文文字的參考圖片
- 將該圖片作爲角色(Character)上傳
- 在提示詞中引用該角色
侷限性: 這種方法並非 100% 可靠。角色一致性功能主要針對人物面部和服裝設計,對於文字元素的復現能力有限。實測中,文字的筆畫細節仍可能出現偏差。
方案三:簡化提示詞策略
通過優化提示詞,可以在一定程度上提高文字渲染的成功率:
- 減少場景複雜度: 不要同時描述多個包含文字的元素
- 縮短視頻時長: 5 秒視頻比 10 秒視頻的文字穩定性更高
- 使用英文替代: 如果業務允許,優先使用英文標識
- 避免動態文字: 靜態文字比需要動畫的文字更容易保持穩定

方案四:嘗試替代模型
當前主流 AI 視頻生成模型中,阿里巴巴的 Wan 2.1/2.2 在中文文字渲染方面表現更優。
| 模型 | 中文文字能力 | 特點 |
|---|---|---|
| Wan 2.1 | ⭐⭐⭐⭐ | 首個支持中英文文字生成的視頻模型 |
| Wan 2.2 | ⭐⭐⭐⭐ | 支持鏡頭語言控制,畫面質感提升 |
| Sora 2 | ⭐⭐ | 英文相對穩定,中文較弱 |
| Veo 3.1 | ⭐⭐ | 與 Sora 2 類似,中文支持有限 |
| Kling 2.6 | ⭐⭐⭐ | 支持中英文語音同步 |
Wan 2.1 能夠在場景中清晰渲染中英文文字,適用於標識、標籤或文字疊加的需求。阿里雲計劃在 2025 年第二季度開源 WanX AI 視頻生成器核心,屆時開發者可以在本地部署並保持雲端版本 85% 的性能。
模型選擇建議: 根據具體需求選擇合適的模型。如需快速對比不同模型的文字渲染效果,可以通過 API易 apiyi.com 進行實際測試,平臺支持多種視頻生成模型的統一接口調用。
方案五:多次生成抽卡
AI 視頻生成具有隨機性,同一提示詞每次生成的結果都不同。對於簡單的中文文字需求,可以嘗試:
- 準備簡潔、明確的提示詞
- 多次生成(5-10 次)
- 從中挑選文字渲染最清晰的版本
這種方法成本較高,但對於 1-2 個漢字的簡單場景有時能獲得可接受的結果。
Sora 2 中文字亂碼方案對比
| 方案 | 可靠性 | 操作難度 | 成本 | 適用場景 |
|---|---|---|---|---|
| 後期處理 | ⭐⭐⭐⭐⭐ | 中等 | 低 | 所有需要精確文字的場景 |
| 角色一致性 | ⭐⭐ | 簡單 | 低 | 特定物品/標識的重複出現 |
| 簡化提示詞 | ⭐⭐ | 簡單 | 低 | 簡單文字、短視頻 |
| 替代模型 | ⭐⭐⭐⭐ | 中等 | 中 | 中文文字爲核心需求 |
| 多次抽卡 | ⭐⭐ | 簡單 | 高 | 1-2 個漢字的簡單場景 |
對比說明: 後期處理是目前最可靠的方案,適合對文字精度要求高的商業項目。如需批量生成視頻素材,推薦通過 API易 apiyi.com 調用 API,配合自動化後期處理流程。
常見問題
Q1: Sora 2 爲什麼對中文支持不好?
這與模型的訓練數據構成有關。Sora 2 的訓練數據中英文內容佔比較高,模型對英文字符的學習更充分。此外,中文漢字筆畫複雜,結構多樣,對生成模型的精度要求更高。AI 視頻生成本質上是生成"視覺相似"的像素,而非渲染精確字符,這導致複雜文字更容易出現偏差。
Q2: 使用角色一致性功能能完全解決中文亂碼嗎?
不能完全解決。角色一致性功能主要針對人物外觀設計,對文字元素的復現能力有限。用戶反饋顯示,即使將帶文字的物品設爲角色,每次生成時文字細節仍可能發生變化。這種方法可以作爲輔助手段,但不建議作爲唯一解決方案。
Q3: 如何選擇最適合的解決方案?
根據你的具體需求選擇:
- 商業項目/精確文字: 選擇後期處理方案
- 中文文字爲核心需求: 嘗試 Wan 2.1 等替代模型
- 簡單標識/品牌露出: 可嘗試角色一致性 + 多次抽卡
- 快速測試: 通過 API易 apiyi.com 批量調用不同模型進行對比
總結
Sora 2 中文字亂碼問題的核心要點:
- 技術限制客觀存在: Sora 2 對非英文文字的渲染能力確實有限,這是當前 AI 視頻生成技術的共同挑戰
- 後期處理最可靠: 將 Sora 2 輸出視爲原始素材,通過專業工具疊加文字是最穩定的工作流
- 替代模型值得嘗試: Wan 2.1 等中國廠商的模型在中文文字渲染方面有明顯優勢
面對 AI 視頻生成的文字渲染限制,務實的做法是接受技術邊界,選擇合適的解決方案。
推薦通過 API易 apiyi.com 快速測試不同視頻生成模型的效果,平臺提供免費額度和多模型統一接口,便於找到最適合你需求的解決方案。
📚 參考資料
⚠️ 鏈接格式說明: 所有外鏈使用
資料名: domain.com格式,方便複製但不可點擊跳轉,避免 SEO 權重流失。
-
OpenAI Sora 2 官方文檔: Sora 2 視頻生成指南
- 鏈接:
platform.openai.com/docs/guides/video-generation - 說明: 官方 API 文檔和最佳實踐
- 鏈接:
-
Sora 2 常見問題解決指南: 5 個最煩人的錯誤及修復方法
- 鏈接:
skywork.ai/blog/sora-2-how-to-fix-its-5-most-annoying-errors - 說明: 包含文字渲染問題的詳細分析
- 鏈接:
-
Wan AI 官方站點: 阿里巴巴開源視頻生成模型
- 鏈接:
wan.video - 說明: 中英文文字渲染能力較強的替代選擇
- 鏈接:
-
Kapwing 視頻編輯器: 在線視頻後期處理工具
- 鏈接:
kapwing.com - 說明: 適合快速添加字幕和文字疊加
- 鏈接:
作者: 技術團隊
技術交流: 歡迎在評論區討論,更多資料可訪問 API易 apiyi.com 技術社區