在使用 Claude API 做長上下文調用時,很多開發者都遇到過同一個困惑:明明已經在 cache_control 字段裏聲明瞭緩存,但響應裏的 cache_creation_input_tokens 和 cache_read_input_tokens 仍然是 0,賬單上也看不到緩存摺扣。本文將系統拆解 Claude prompt caching 不命中的 5 大原因,重點講清楚最容易被忽視的「最低可緩存 Token 門檻」與「靜默失敗」機制。
核心價值: 讀完本文,你將看懂 Anthropic 各模型的最低緩存門檻、明白爲什麼短提示詞加 cache_control 也不報錯卻沒緩存,並學會用 4 行代碼判斷到底命沒命中。

Claude prompt caching 核心要點
Claude prompt caching 是 Anthropic 提供的提示詞緩存機制:把重複出現的系統提示詞、長文檔、工具定義存到一個臨時緩存裏,下一次命中時按讀價計費,比正常輸入價格便宜約 90%。它的關鍵特徵是「前綴匹配 + 顯式聲明 + 靜默失敗」,這三點決定了你大多數排查問題的方向。
| 要點 | 說明 | 排查價值 |
|---|---|---|
| 顯式聲明 | 必須在 system、messages 或 tools 內插入 cache_control 塊 |
漏寫或位置錯都不會有緩存 |
| 前綴匹配 | 命中要求緩存塊之前的所有內容字節級一致 | 哪怕多一個空格也會失效 |
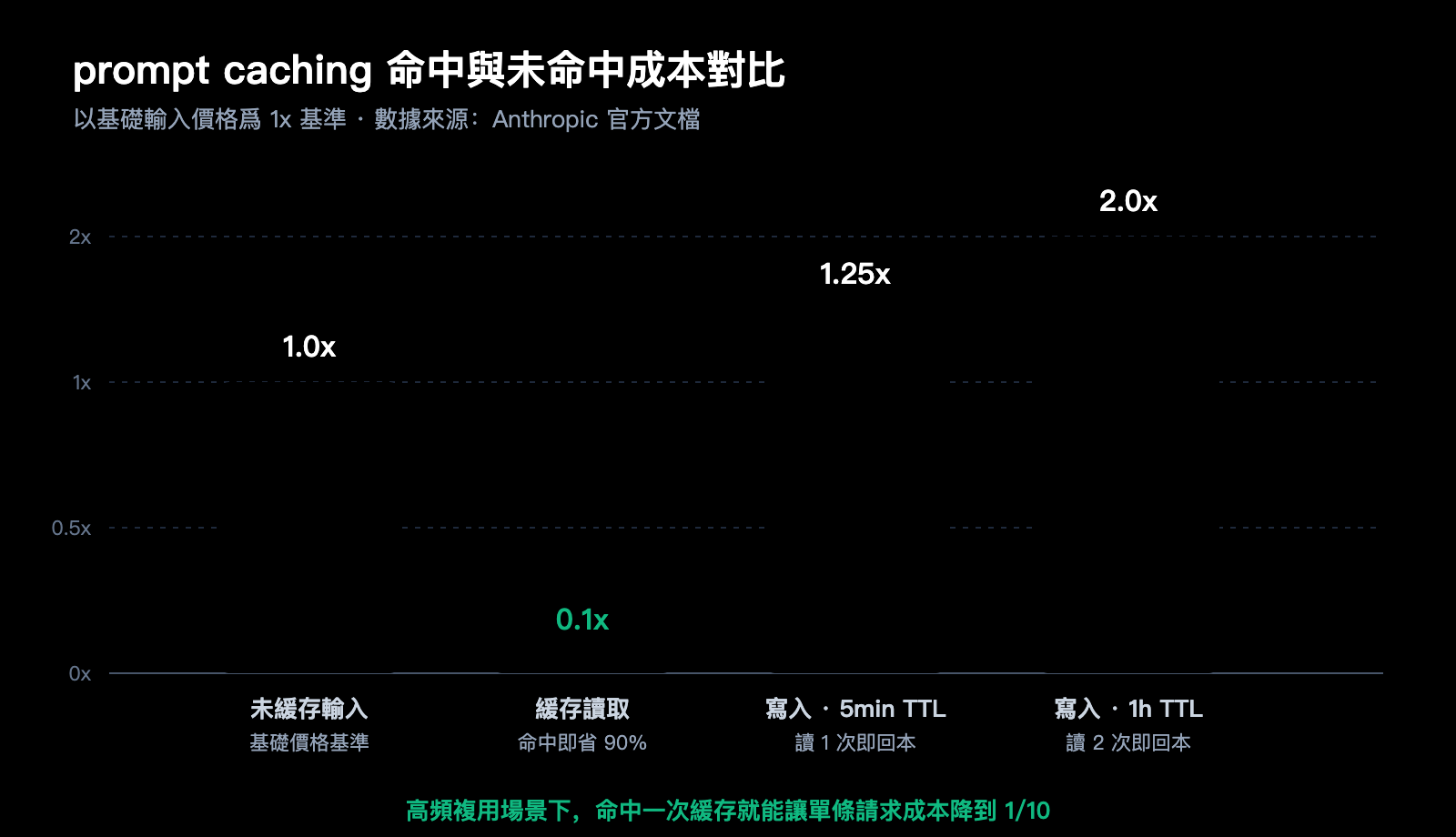
| 靜默失敗 | 不滿足條件的請求會正常返回,不報錯也不緩存 | 必須主動校驗 usage 字段 |
| TTL 限制 | 默認 5 分鐘,最長 1 小時 | 長間隔調用會自然過期 |
「靜默失敗」是這套機制最容易讓人翻車的部分。Anthropic 文檔明確指出:當你的請求不滿足緩存條件(例如長度不夠、前綴變了),API 仍然會返回正常的回答,但不會創建緩存、也不會讀緩存、更不會拋錯。這意味着你在調用代碼裏看不到任何異常,只能通過響應裏的 usage 對象主動檢查。
如果你正在通過 API易 apiyi.com 平臺調用 Claude 的 Sonnet、Opus、Haiku 系列模型,緩存邏輯和 Anthropic 官方接口完全一致,建議在落庫前先打印一次 usage 字段,確認緩存確實生效再上量。
Claude prompt caching 各模型最低 Token 門檻速查
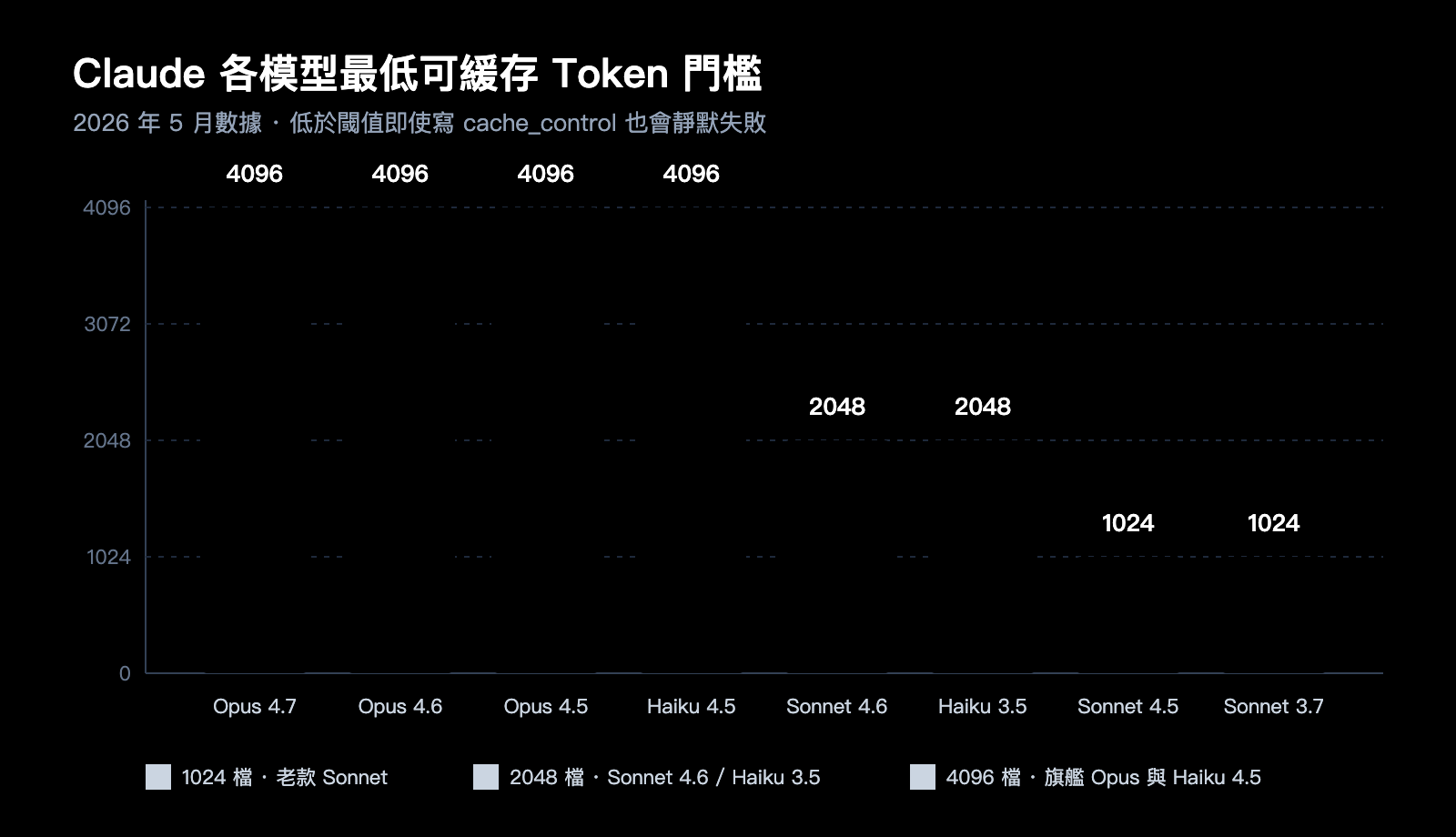
最常被忽視的不命中原因,是提示詞長度沒達到 Anthropic 對該模型設定的「最低可緩存 Token」門檻。低於這個長度,即使寫了 cache_control 也只會被當作普通請求處理。不同模型的門檻差距很大,下表是 2026 年 5 月當前的官方數據,建議直接收藏。
| 模型 | 最低可緩存 Token | 備註 |
|---|---|---|
| Claude Opus 4.7 / 4.6 / 4.5 | 4096 | 最新旗艦,門檻拉到最高 |
| Claude Sonnet 4.6 | 2048 | 當前主力 Sonnet,門檻翻倍 |
| Claude Sonnet 4.5 / Sonnet 4 / Sonnet 3.7 | 1024 | 歷史經典 Sonnet 系列 |
| Claude Opus 4.1 / Opus 4 | 1024 | 老一代 Opus |
| Claude Haiku 4.5 | 4096 | Haiku 反而比 Sonnet 高 |
| Claude Haiku 3.5 | 2048 | 長期穩定的快速模型 |
很多人第一次看到這張表會愣住:爲什麼 Haiku 4.5 這種「小模型」的門檻反而和 Opus 4.7 一樣高?原因是新一代 Haiku 用了更長的注意力窗口,緩存命中的工程意義只有在更長的前綴上才顯著,所以 Anthropic 在產品策略上把門檻推上去了。
實踐中最常見的誤判,是開發者按照舊版 Sonnet 3.7 的 1024 習慣去設計提示詞,切到 Sonnet 4.6 之後突然失效,卻以爲是代碼寫錯。如果你在 API易 apiyi.com 上同時調用多代 Claude 模型,強烈建議把這張表作爲參數檢查的一部分,按 model 字段動態判斷門檻。
Claude prompt caching 不命中的 5 大原因
理解了「最低 Token 門檻」和「靜默失敗」之後,就可以系統排查不命中問題了。下面這 5 個原因按出現頻率排序,前兩個佔據了我們日常調試遇到的大多數案例。
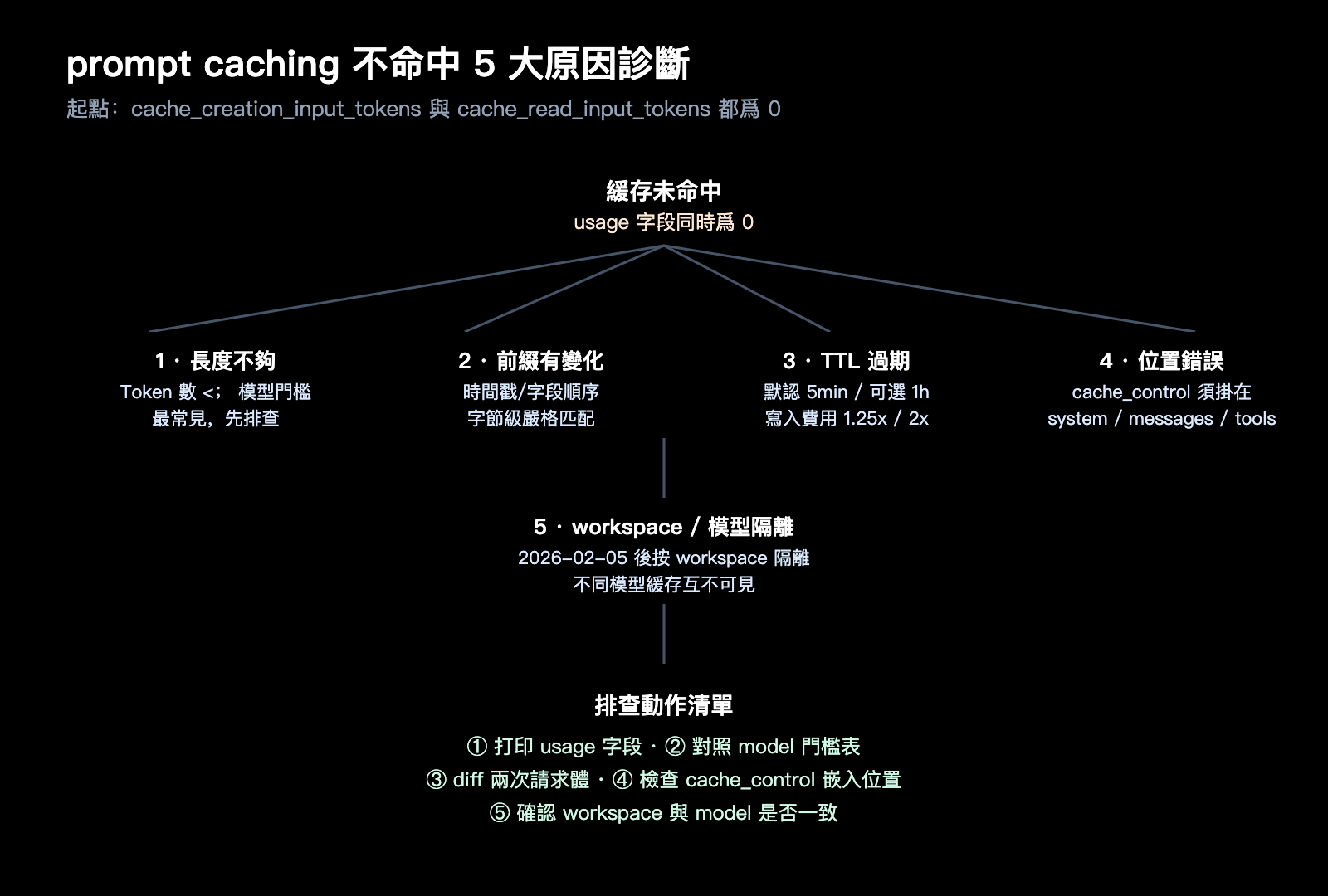
原因 1:提示詞長度低於最低門檻
這是絕對的頭號殺手。例如你在 Sonnet 4.6 上聲明緩存,但實際系統提示詞只有 1500 token,緩存就完全不會建立。診斷方法很簡單:先用本地 tokenizer 估算一下系統提示詞 + 工具定義 + 已緩存消息部分的 Token 總量,再對照上表的門檻。
更隱蔽的情況是「多個 cache_control 塊疊加」。Anthropic 的策略是「每個緩存斷點都要讓其前面的累計內容達到模型門檻」,否則該斷點失效。建議初學者只使用一個 cache_control 塊,等熟悉機制後再做分層緩存。
原因 2:緩存前綴有任何字節級變化
prompt caching 是嚴格的前綴匹配,意味着你的系統提示詞、工具定義、消息歷史,只要有一個字符不一樣,緩存就視爲失效,必須重新寫入。常見的「僞變化」包括:
- 系統提示詞裏夾了帶時間戳的渲染邏輯,每次請求時間都不同
- 工具定義按字典順序序列化時,因爲 Python 字典無序導致字段順序漂移
- 對歷史消息做了 trim 或 dedupe 處理,導致同一段對話出現細微差異
排查這種問題最直接的辦法是對兩次請求的完整 payload 做 diff 比對。如果你在自研網關裏用 API易 apiyi.com 做統一中轉,可以在網關日誌裏直接把請求體 hash 出來,發現 hash 不一致就基本能定位到前綴漂移。
原因 3:TTL 已過期
默認 TTL 是 5 分鐘,超過這個間隔後,舊緩存條目會被釋放,下一次請求會重新觸發寫入。1 小時 TTL 寫入價格是基礎輸入價的 2 倍,要按調用頻率衡量是否值得開啓。
判斷 TTL 過期的特徵是:cache_creation_input_tokens 突然變成非零數值,而你以爲這條請求應該讀緩存。如果發現這種情況,可以縮短兩次請求間隔,或者切到 "ttl": "1h" 長 TTL。
原因 4:cache_control 位置錯誤
cache_control 必須掛在 system、messages 或 tools 數組裏的具體內容塊上,並且 type 一定是 ephemeral。常見錯誤用法包括:
- 把
cache_control放在了messages.create()的頂層參數而不是某個 content block 上 - 在
messages數組裏的 user 消息上聲明,但前綴實際想緩存的是 system - 同一條 message 裏寫了多個 cache_control 但都沒達到 2048 門檻
正確做法是把 cache_control 直接嵌在你希望「截止到此爲止」的那個 block 內部,緩存會從 prompt 開頭一直鎖到這個 block 結尾。
原因 5:跨工作區或跨模型導致緩存不共享
自 2026 年 2 月 5 日起,Anthropic 把 prompt cache 的隔離邊界改爲「工作區級別」,意味着不同 workspace 之間的緩存互不可見。如果你的兩次調用分別走了不同的 API Key、不同的 workspace,緩存自然不能複用。
模型層面也是一樣的邏輯。把同一份提示詞在 Sonnet 4.6 上寫入緩存,下次切到 Sonnet 4.5 調用,絕不會命中。多模型調度時,最好按 model 維度分別維護一份緩存預熱腳本,或者通過 API易 apiyi.com 這類聚合平臺直接複用同一個上游 workspace,避免緩存碎片化。
Claude prompt caching 命中校驗代碼與判斷邏輯
排查不命中問題的第一步永遠是「打印 usage 字段」。Anthropic 在每次 messages.create 的返回裏都會附帶一個 usage 對象,裏面有 4 個關鍵字段,是判斷緩存狀態的唯一可靠依據。
極簡校驗代碼
import anthropic
client = anthropic.Anthropic(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com"
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system=[{
"type": "text",
"text": LONG_SYSTEM_PROMPT, # 必須 ≥ 2048 token
"cache_control": {"type": "ephemeral"}
}],
messages=[{"role": "user", "content": "your question"}]
)
u = response.usage
print(f"寫緩存: {u.cache_creation_input_tokens}")
print(f"讀緩存: {u.cache_read_input_tokens}")
print(f"未緩存輸入: {u.input_tokens}")
把這段代碼當作排查模板。每當懷疑緩存沒生效時,第一時間跑一遍,看返回字段就能鎖定問題方向。
查看完整封裝版本
import anthropic
import logging
MIN_TOKENS = {
"claude-opus-4-7": 4096,
"claude-opus-4-6": 4096,
"claude-opus-4-5": 4096,
"claude-sonnet-4-6": 2048,
"claude-sonnet-4-5": 1024,
"claude-haiku-4-5": 4096,
"claude-haiku-3-5": 2048,
}
def call_with_cache_check(model: str, system_text: str, user_msg: str):
client = anthropic.Anthropic(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com"
)
response = client.messages.create(
model=model,
max_tokens=1024,
system=[{
"type": "text",
"text": system_text,
"cache_control": {"type": "ephemeral"}
}],
messages=[{"role": "user", "content": user_msg}]
)
u = response.usage
if u.cache_creation_input_tokens == 0 and u.cache_read_input_tokens == 0:
logging.warning(
f"緩存未生效,疑似低於 {MIN_TOKENS.get(model)} token 門檻"
)
return response
命中狀態判斷表
cache_creation_input_tokens |
cache_read_input_tokens |
判斷結論 |
|---|---|---|
| > 0 | = 0 | 首次寫入緩存(正常) |
| = 0 | > 0 | 命中緩存(最理想) |
| > 0 | > 0 | 部分命中,新增部分被寫入 |
| = 0 | = 0 | 未緩存,需要排查上述 5 大原因 |
最後一行就是出現問題時的特徵。看到這一行就直接跳到原因 1 開始排查,按 5 個方向逐一對照即可。如果團隊對接口穩定性要求高,可以把這套判斷邏輯包成中間件掛在 API易 apiyi.com 調用鏈路上,觸發告警時立即通知排查。
湊夠最低 Token 門檻的 4 種實用技巧
當你確認是「長度不夠」導致不命中後,下一步就是想辦法讓緩存前綴達到門檻。下面 4 個技巧按推薦程度排序,前 3 種幾乎沒有副作用。
| 技巧 | 適用場景 | 大致增加 Token | 注意事項 |
|---|---|---|---|
| 完整知識庫 | 系統提示詞太薄 | +2000~4000 | 必須每次都真的會用 |
| 工具定義集中託管 | 多工具應用 | +500~2000 | tools 字段同樣可緩存 |
| 常用 few-shot 示例 | 任務化提示 | +1000~3000 | 示例要有泛化價值 |
| 填充無關文本 | 應急 | 任意 | 不推薦,影響輸出質量 |
第一種「完整知識庫」是最穩的做法。如果你的應用本來就有一份內部知識庫,例如產品 FAQ、風格指南、流程 SOP,可以一次性塞進 system 塊頂部並打上 cache_control,讓長度直接超過 4096,所有模型一次性滿足門檻。
第二種「工具定義」常被忽略。Anthropic 的 tools 字段同樣支持 cache_control,對於多工具 Agent 應用尤其有效。一份典型的工具描述加上 JSON Schema 就輕鬆突破 2048。
第三種「few-shot 示例」適合複雜任務化場景。把 3-5 個標準案例放在 system 末尾,既能提升輸出穩定性,又可以把 Token 數從 1500 提到 2500-3500,剛好越過 Sonnet 4.6 的門檻。
第四種「填充無關文本」純屬應急,不建議日常使用,因爲模型仍然會讀那些填充文本,可能影響輸出風格。如果實在沒辦法湊長度,可以考慮通過 API易 apiyi.com 平臺切換到門檻較低的 Sonnet 4.5 或 Sonnet 3.7,讓現有提示詞直接落入 1024 門檻區間。
常見問題
Q1: 我加了 cache_control 但沒緩存,是不是 API 出 bug 了?
大概率不是 bug,而是觸發了靜默失敗機制。第一步先檢查 model 字段對應的最低 Token 門檻,第二步打印 usage 對象。99% 的情況都是長度不夠或前綴變化導致。
Q2: cache_creation_input_tokens 收費貴不貴?
5 分鐘 TTL 寫入是基礎輸入價的 1.25 倍,1 小時 TTL 是 2 倍。讀取價是 0.1 倍。一般來說,5min 緩存被讀 1 次就回本,1h 緩存被讀 2 次回本,多次複用越多收益越大。
Q3: 舊版文檔說 Sonnet 最低是 1024,新版怎麼變成 2048 了?
這是 Sonnet 4.6 纔出現的新門檻。Sonnet 4.5 及更老版本仍然是 1024。建議在代碼裏維護一份「model → 門檻」映射表,按調用模型動態判斷。通過 API易 apiyi.com 調用時,model 字段的命名和 Anthropic 官方完全一致,可以直接複用同一份映射邏輯。
Q4: 多個 cache_control 塊怎麼用才安全?
每個 cache_control 都要求前綴累計達到門檻,否則該斷點失效。新手建議只放一個斷點,把整個 system 塊都緩存。如果非要分層,可以把「極少變化的知識庫」放第一層,「偶爾變化的工具定義」放第二層。
Q5: 我能用國內中轉平臺測試 prompt caching 嗎?
可以。API易 apiyi.com 等聚合中轉平臺的 Claude 系列接口與 Anthropic 官方完全兼容,包括 cache_control、ttl、usage 字段。開發者可以在中轉平臺上完成調試和上量,緩存邏輯、計費規則保持一致。
總結
Claude prompt caching 看起來只是加一個 cache_control 字段那麼簡單,但真正用起來會被「靜默失敗 + 最低 Token 門檻 + 前綴嚴格匹配」這三件事坑到。本文給出的 5 大原因排查清單和命中判斷表,可以幫助開發者把 90% 的不命中問題在 5 分鐘內定位清楚。
落地建議是把校驗代碼做成默認中間件、把模型門檻表做成代碼常量、把緩存預熱做成單獨腳本。如果你的業務在多模型之間頻繁切換,可以通過 API易 apiyi.com 平臺統一管理 Claude 調用入口,複用同一份緩存策略和監控邏輯,避免不同環境之間出現緩存碎片化和門檻不一致帶來的隱性成本。
作者: APIYI 技術團隊
聯繫: 通過 API易 apiyi.com 獲取 Claude 全系列模型與 prompt caching 完整調試支持
更新時間: 2026-05-12