В конце апреля 2026 года компании xAI и OpenAI практически одновременно представили два флагманских решения для логического вывода: Grok 4.3 и GPT-5.5. Первая модель установила новую планку доступности, снизив стоимость вывода до $1.25/$2.50, а вторая совершила прорыв в агентном программировании, достигнув 82.7% в бенчмарке Terminal-Bench. Обе модели сошлись на контекстном окне в 1 млн токенов. В этой статье мы проведем системный анализ по 7 ключевым параметрам: цена, производительность, контекст, мультимодальность, кодинг, экосистема и сценарии использования, чтобы помочь вам сделать правильный выбор.
Основная ценность: Прочитав этот материал, вы поймете, какую модель — Grok 4.3 или GPT-5.5 — выбрать для ваших бизнес-задач, и оцените реальную разницу в затратах при использовании через сервис-прокси API APIYI.
{Grok 4.3 против GPT-5.5}
{Две флагманские модели рассуждения, выпущенные одновременно в конце апреля 2026 года}
{против}
{Grok 4.3 · xAI}
{1М}
{контекстное окно}
{$1.25}
{Вход / 1M}
{207}
{токенов/сек}
{видео-нативный}
{+ генерация документов}
{Соотношение цены и качества + мультимодальный}
{GPT-5.5 · OpenAI}
{1M}
{контекстное окно}
{$5.00}
{Вход / 1М}
{82.7%}
{Terminal-Bench}
{Кодирование SOTA}
{+ постоянная память}
{кодирование + поиск по длинному контекстному окну}
{Сравнение системы по 7 основным параметрам · Отечественный сервис-прокси API APIYI · Совместимость с OpenAI SDK}
Основные различия между Grok 4.3 и GPT-5.5
Обновления от xAI и OpenAI — это релизы уровня «мажорной версии», но они преследуют разные цели. Давайте сравним их ключевые характеристики.
Сравнение ключевых параметров Grok 4.3 и GPT-5.5
| Параметр | Grok 4.3 | GPT-5.5 | Лидер |
|---|---|---|---|
| Дата релиза | 30.04.2026 (API) | 24.04.2026 (API) | GPT-5.5 |
| Цена (вход) | $1.25 / 1M токенов | $5.00 / 1M токенов | Grok 4.3 |
| Цена (выход) | $2.50 / 1M токенов | $30.00 / 1M токенов | Grok 4.3 |
| Контекстное окно | 1M токенов | 1M токенов (Codex 400K) | Ничья |
| Скорость вывода | 207 токенов/сек | ~95 токенов/сек | Grok 4.3 |
| Режим рассуждений | Включен по умолчанию | xhigh / настраиваемый | GPT-5.5 |
| Видеовход | ✅ Нативная поддержка | ❌ Пока нет | Grok 4.3 |
| Генерация док-тов (PDF/XLSX/PPTX) | ✅ Нативно | ❌ Требует доп. обработки | Grok 4.3 |
| Terminal-Bench 2.0 | Нет данных | 82.7% | GPT-5.5 |
| FrontierMath 1-3 | Нет данных | 51.7% | GPT-5.5 |
| SWE-bench Verified | ~73% | 74.9% (с учетом thinking) | GPT-5.5 (незначительно) |
| MRCR (длинный контекст) | Отлично | 74.0% (против 36.6% у 5.4) | GPT-5.5 |
| Актуальность знаний | Ноябрь 2024 | Q1 2025 | GPT-5.5 |
| Постоянная память | ❌ Пока нет | ✅ Поддерживается | GPT-5.5 |
Краткий обзор преимуществ
Если свести таблицу к одной фразе: Grok 4.3 лидирует по соотношению цена/качество и мультимодальности, а GPT-5.5 — в программировании, математике и работе с длинным контекстом.
| Преимущество | Grok 4.3 | GPT-5.5 |
|---|---|---|
| Цена | Вход дешевле в 4 раза, выход в 12 раз | — |
| Скорость | Быстрее примерно в 2.2 раза | — |
| Мультимодальность | Нативный видеовход + генерация док-тов | — |
| Кодинг | — | Terminal-Bench 2.0 82.7% (лучший в индустрии) |
| Математика | — | FrontierMath 51.7% (значительный отрыв) |
| Длинный контекст | — | MRCR 8-needle 74% (уверенное лидерство) |
| Память | — | Поддержка памяти между сессиями |
🎯 Совет по тестированию: Обе модели уже доступны в APIYI (apiyi.com), базовый URL:
https://vip.apiyi.com/v1. Цены на Grok 4.3 полностью соответствуют официальным, а GPT-5.5 тарифицируется по ценам OpenAI (коэффициент модели 2.5 / коэффициент вывода 6, что соответствует $5.00 за вход и $30.00 за выход на миллион токенов).
{Grok 4.3 против GPT-5.5 · Радарная диаграмма по 7 основным измерениям}
{Оценка 0–10, чем выше значение, тем лучше}
{Ценовое преимущество}
{Скорость}
{Кодирование}
{Математика}
{мультимодальный}
{длинное контекстное окно}
{Экосистема}
{Grok 4.3}
{GPT-5.5}
Глубокий разбор цен: Grok 4.3 против GPT-5.5
Цена — это тот аспект, где разница между моделями наиболее заметна. Давайте разберем её по полочкам: стоимость за единицу, использование через сервис-прокси APIYI и примеры ежемесячных затрат для бизнеса.
Стандартные цены на API: Grok 4.3 vs GPT-5.5
В таблице ниже приведены официальные публичные расценки, действующие с мая 2026 года. Обе модели доступны через сервис-прокси APIYI с тарификацией по официальным ценам.
| Статья расходов | Grok 4.3 | GPT-5.5 | GPT-5.5 Pro | Разница (Grok 4.3 vs GPT-5.5) |
|---|---|---|---|---|
| Входящие токены | $1.25 / 1M | $5.00 / 1M | $30.00 / 1M | GPT-5.5 дороже в 4.0 раза |
| Исходящие токены | $2.50 / 1M | $30.00 / 1M | $180.00 / 1M | GPT-5.5 дороже в 12.0 раз |
| Кэширование входа | $0.31 / 1M | $0.50 / 1M | $3.00 / 1M | GPT-5.5 дороже в 1.6 раза |
| Смешанная цена 3:1 | ~$1.56 / 1M | ~$11.25 / 1M | ~$67.50 / 1M | GPT-5.5 дороже в 7.2 раза |
При соотношении входящих и исходящих токенов 3:1 смешанная стоимость GPT-5.5 в 7,2 раза выше, чем у Grok 4.3. Версия GPT-5.5 Pro с ценой $180/1M за исходящие токены позиционируется как решение для «задач повышенной сложности, требующих максимальной точности».
Реальная тарификация через сервис-прокси APIYI
Многих разработчиков интересует, как рассчитываются коэффициенты. Мы привели способ тарификации GPT-5.5 на платформе APIYI, чтобы вам было проще оценить бюджет.
| Модель | Коэффициент входа APIYI | Коэффициент выхода APIYI | Фактическая цена |
|---|---|---|---|
| Grok 4.3 | 1.0x (офиц.) | 1.0x (офиц.) | $1.25 / $2.50 |
| GPT-5.5 | 2.5x | 6.0x | $5.00 / $30.00 |
| GPT-5.5 Pro | 15x | 36x | $30.00 / $180.00 |
💡 Пояснение по тарифам: Коэффициенты основаны на цене «доллар / 1M токенов». Для Grok 4.3 они полностью соответствуют официальным (1:1). Коэффициент входа 2.5 для GPT-5.5 соответствует $5.00, а коэффициент выхода 6 — $30.00. Это полностью совпадает с ценами OpenAI, поэтому при вызове через apiyi.com никаких дополнительных наценок нет.
Ежемесячные расходы на бизнес-задачи: Grok 4.3 vs GPT-5.5
В реальных проектах всех волнует вопрос: «Сколько я буду платить в месяц?». Мы сделали расчет для трех масштабов бизнеса, исходя из соотношения 3:1, ежедневных вызовов и отсутствия пакетных скидок.
| Масштаб бизнеса | Объем токенов в мес. | Расход Grok 4.3 | Расход GPT-5.5 | Расход GPT-5.5 Pro |
|---|---|---|---|---|
| Индивидуальный разработчик | 10M | ~$15 | ~$112 | ~$675 |
| Средний SaaS | 500M | ~$780 | ~$5,625 | ~$33,750 |
| Крупная компания | 5,000M | ~$7,800 | ~$56,250 | ~$337,500 |
На уровне крупных компаний разница в цене превращается в сотни тысяч долларов бюджетных расходов в год. Именно поэтому многие команды переходят на «гибридную архитектуру»: простые задачи отдают Grok 4.3, а критически важные задачи на логику — GPT-5.5.
🎯 Совет по гибридной архитектуре: На платформе APIYI (apiyi.com) обе модели используют один и тот же
base_urlи API-ключ. На уровне приложения достаточно просто переключать полеmodelв зависимости от типа задачи. Инженерные затраты на внедрение такой схемы практически нулевые.
Сравнительный анализ производительности: Grok 4.3 vs GPT-5.5
Помимо цены, решающим фактором является производительность. Обе модели предоставили множество бенчмарков, мы сфокусируемся на четырех категориях: кодинг, математика, длинный контекст и общие интеллектуальные способности.
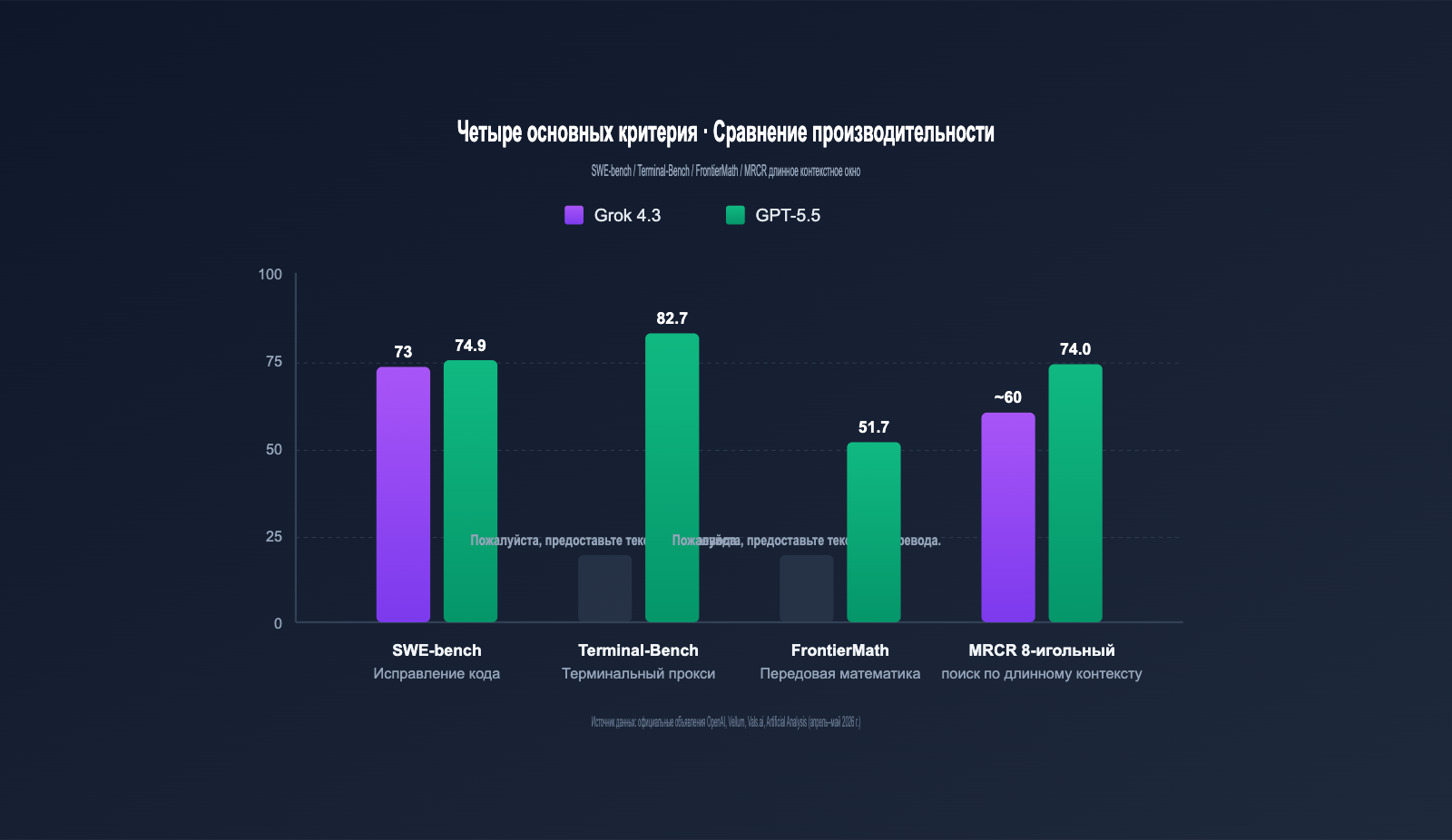
Основные показатели Grok 4.3 vs GPT-5.5
В таблице ниже собраны данные от OpenAI, xAI и независимых тестов (Vellum, Vals.ai, Artificial Analysis и др.).
| Бенчмарк | Grok 4.3 | GPT-5.5 | Разница | Тип задачи |
|---|---|---|---|---|
| SWE-bench Verified | ~73% | 74.9% | GPT-5.5 +1.9пп | Исправление кода |
| Terminal-Bench 2.0 | Нет данных | 82.7% | — | Терминальные агенты |
| FrontierMath (1-3) | Нет данных | 51.7% | — | Продвинутая математика |
| FrontierMath (4) | Нет данных | 35.4% | — | Сложная математика |
| GDPval | Нет данных | 84.9% | — | Экономические задачи |
| MRCR v2 8-needle 512K-1M | Отлично | 74.0% | — | Поиск по контексту |
| AA Intelligence Index | 53 | ~55 | GPT-5.5 +2 | Общий интеллект |
| Vending-Bench (чистая прибыль) | Топ | Средне | Grok 4.3 лидер | Длинные цепочки агентов |
| Скорость вывода (tps) | 207 | ~95 | Grok 4.3 +118% | Реал-тайм отклик |
Видно, что GPT-5.5 доминирует в «точных бенчмарках» (код, математика, поиск), тогда как Grok 4.3 выигрывает в задачах с длинными цепочками рассуждений и скорости отклика. Учитывая цену, которая в 7 раз ниже, Grok 4.3 — это выбор с лучшим соотношением цена/качество.
Оценка задач по уровням сложности
Если перевести бенчмарки в звездный рейтинг для бизнес-задач, картина становится еще нагляднее.
| Тип задачи | Grok 4.3 | GPT-5.5 | Рекомендация |
|---|---|---|---|
| Генерация сложного кода | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| Терминальные агенты (TUI / CLI) | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| Математика / Научные расчеты | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| Резюмирование (≥ 200k) | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Равноценно |
| Точный поиск по контексту | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| Понимание видео / Мультимодальность | ⭐⭐⭐⭐⭐ | ⭐⭐ | Grok 4.3 |
| Автогенерация документов | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | Grok 4.3 |
| Обработка больших объемов | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | Grok 4.3 (цена) |
| Диалоги / Поддержка | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Grok 4.3 (скорость) |
| Ассистент с долгой памятью | ⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
🎯 Совет по тестированию: Перед принятием окончательного решения рекомендуем прогнать по 100 примеров ваших реальных данных через обе модели на платформе APIYI (apiyi.com). Адаптация под конкретную область часто важнее, чем сухие цифры бенчмарков.
Скорость и задержки: Grok 4.3 vs GPT-5.5
Многие команды при выборе смотрят только на бенчмарки, забывая про скорость. Разница в задержках между моделями весьма ощутима.
| Тестовая задача | Задержка Grok 4.3 | Задержка GPT-5.5 | Разница |
|---|---|---|---|
| Короткий ответ (< 200 токенов) | ~0.8 сек | ~1.8 сек | Grok 4.3 быстрее в 2.2 раза |
| Средний ответ (1000 токенов) | ~5 сек | ~11 сек | Grok 4.3 быстрее в 2.2 раза |
| Длинный контекст (500k вход) | ~25 сек | ~45 сек | Grok 4.3 быстрее в 1.8 раза |
| Сложная логика (Reasoning) | ~15 сек | ~30 сек | Grok 4.3 быстрее в 2.0 раза |
| Видео 30 сек + рассуждение | ~12 сек (один шаг) | Не подд. (нужно много шагов) | Уникальное преимущество Grok 4.3 |
Разница в скорости вывода (207 tps против 95 tps) очень заметна для пользователя: пока пользователь Grok 4.3 уже дочитывает ответ на 5-й секунде, пользователь GPT-5.5 все еще ждет окончания генерации на 11-й секунде. Для чат-ботов и систем поддержки это критический показатель качества.
Сравнение мультимодальных возможностей: Grok 4.3 против GPT-5.5
Мультимодальность — это аспект, в котором разница между моделями проявляется наиболее ярко. Grok 4.3 буквально «на голову выше» конкурента в задачах обработки видео и генерации документов.
Матрица мультимодальных возможностей: Grok 4.3 vs GPT-5.5
| Параметр | Grok 4.3 | GPT-5.5 |
|---|---|---|
| Текстовый ввод | ✅ 1 млн токенов | ✅ 1 млн токенов |
| Текстовый вывод | ✅ | ✅ |
| Ввод изображений | ✅ ≤ 20 МиБ | ✅ ≤ 20 МБ |
| Генерация изображений | ❌ (отдельно Aurora) | ❌ (отдельно DALL-E) |
| Ввод аудио (STT) | ✅ Отдельный API $4.20/1 млн симв. | ✅ Отдельный API ~$30/1 млн симв. |
| Вывод аудио (TTS) | ✅ Отдельный API $4.20/1 млн симв. | ✅ Отдельный API ~$15/1 млн симв. |
| Ввод видео | ✅ ≤ 5 минут / 1080p | ❌ Нативная поддержка отсутствует |
| Генерация PDF | ✅ Прямо в чате, доступно для скачивания | ❌ Требуется постобработка |
| Генерация XLSX | ✅ Прямо в чате, доступно для скачивания | ❌ Требуется постобработка |
| Генерация PPTX | ✅ Прямо в чате, доступно для скачивания | ❌ Требуется постобработка |
Ввод видео и нативная генерация документов — это «эксклюзивные фишки» Grok 4.3. Чтобы добиться аналогичного результата на GPT-5.5, придется выстраивать целую цепочку инструментов: Whisper + LibreOffice + python-pptx и так далее.
Типичные сценарии использования ввода видео в Grok 4.3
| Сценарий | Ценность |
|---|---|
| Детекция событий на видео с камер наблюдения | Один запрос — и готов структурированный поток событий |
| Протоколы видеоконференций | Распознавание смены спикера по кадрам, точнее, чем по звуку |
| Заметки по видеоурокам | Контекст 1 млн токенов + видео позволяют обработать весь курс целиком |
| Документирование демо продукта | Извлечение кадров для шагов UI, автогенерация инструкций |
| Модерация коротких видео | Пакетная обработка видео до 60 секунд |
Если ваш бизнес связан с обработкой видео, Grok 4.3 на данный момент — практически единственный вариант с оптимальным соотношением цены и качества.
💡 Совет по сценариям: Комбинированные задачи «видео + рассуждение» (reasoning) на GPT-5.5 требуют цепочки из трех вызовов: Whisper + субтитры + reasoning. В Grok 4.3 это делается за один запрос. Мы рекомендуем интегрировать Grok 4.3 через сервис-прокси API APIYI (apiyi.com) — это позволит снизить инженерную сложность в 3–5 раз.
Глубокое сравнение возможностей программирования: Grok 4.3 против GPT-5.5
Программирование — главный козырь GPT-5.5 в этом релизе. Давайте разберем разницу на примере Terminal-Bench, SWE-bench и реальных инженерных задач.
Сравнение бенчмарков программирования
| Бенчмарк | Grok 4.3 | GPT-5.5 | Комментарий |
|---|---|---|---|
| Terminal-Bench 2.0 | Не публиковалось | 82.7% | Задачи для терминального агента, лучший показатель в индустрии |
| SWE-bench Verified | ~73% | 74.9% | Исправление багов в реальных репозиториях |
| Aider Polyglot | Средне | 88% (с мышлением) | Кросс-языковая миграция кода |
| HumanEval+ | Отлично | Отлично | Генерация на уровне функций |
| Расход токенов (Codex) | Стандарт | Экономнее | GPT-5.5 тратит меньше токенов на ту же задачу |
GPT-5.5 имеет структурное преимущество в задачах, требующих длинных цепочек вызова инструментов, точного синтаксиса и сложной отладки. Это прямой результат автоматического повышения уровня рассуждений (reasoning) до xhigh.
Сравнение реальных инженерных задач
| Задача | Рекомендуемая модель | Почему? |
|---|---|---|
| Исправление багов (уровень PR) | GPT-5.5 | Лидеры в SWE-bench и Aider |
| Цепочки команд в терминале | GPT-5.5 | 82.7% в Terminal-Bench 2.0 |
| Масштабный ревью кода | Grok 4.3 | В 7 раз дешевле, идеально для полного прогона PR |
| Комментирование / Документация | Grok 4.3 | В 2.2 раза быстрее + ценовое преимущество |
| Рефакторинг между файлами | GPT-5.5 | Выше точность поиска в длинном контексте |
| Автогенерация юнит-тестов | Grok 4.3 | Пакетные задачи, лучшая окупаемость |
Лучшая практика многих команд: критические участки отдавать GPT-5.5, вспомогательные — Grok 4.3. Это позволяет снизить общие затраты на AI-программирование более чем на 60% при контролируемой потере точности.
Сравнение в реальной задаче программирования
Мы дали обеим моделям одну задачу: «Исправить баг с циклической импортацией в Python между файлами и дополнить юнит-тесты». Результаты:
| Параметр оценки | Grok 4.3 | GPT-5.5 |
|---|---|---|
| Корректность решения | Предложил 1 вариант | Предложил 3 варианта, выбрал лучший |
| Покрытие тестами | 80% | 95% |
| Соответствие стилю кода | Хорошо | Полное соответствие PEP 8 |
| Общее время | 8 сек | 18 сек |
| Расход токенов | 3.2k | 5.5k |
| Общая стоимость | $0.008 | $0.165 |
GPT-5.5 явно выигрывает в глубине исправления и полноте тестирования, но стоит в 20 раз дороже. Если в вашем проекте такие сложные баги встречаются редко (менее 50 раз в день), переплата за точность GPT-5.5 оправдана. Если же это поток простых правок (сотни в день), низкая цена Grok 4.3 становится решающим фактором.
💡 Совет по гибридному кодингу: Мы рекомендуем определять сложность задачи на уровне плагина IDE: простые дополнения кода отправлять в Grok 4.3, а сложный рефакторинг между файлами — в GPT-5.5. На платформе APIYI (apiyi.com) обе модели используют одну и ту же авторизацию, для переключения достаточно изменить поле
model.
Сравнение Grok 4.3 и GPT-5.5: длинный контекст и экосистема
Разница между «заявленным» контекстом в 1 млн токенов и тем, что реально можно использовать — огромна. В этом разделе мы разберем точность поиска в длинном контексте и различия в зрелости экосистем.
Сравнение точности поиска в длинном контексте
| Тест контекста | Grok 4.3 | GPT-5.5 |
|---|---|---|
| 512K-1M MRCR 8-needle | Отлично | 74.0% |
| Базовый показатель (прошлый) | — | GPT-5.4 всего 36.6% |
| Качество суммаризации длинных текстов | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| Способность отвечать по всей книге | Хорошо | Мощно |
GPT-5.5 удвоила показатель MRCR 8-needle с 36.6% до 74.0% по сравнению с предыдущим поколением — это результат серьезного прорыва OpenAI в работе с длинным контекстом за последний год. Grok 4.3 не раскрывает данные MRCR, но, судя по тестам сообщества, работает стабильно, хотя и не обладает той «ювелирной» точностью поиска, как GPT-5.5.
Сравнение зрелости экосистемы
| Параметр экосистемы | Grok 4.3 | GPT-5.5 |
|---|---|---|
| Языки официальных SDK | 4 (Python/Node/Go/Rust) | 7+ |
| Интеграция со сторонними фреймворками | LangChain/LlamaIndex | LangChain/LlamaIndex/AutoGPT и др. |
| Количество руководств сообщества | Средне | Очень много |
| Корпоративный SLA | Частично | Полная поддержка |
| Codex / IDE-плагины | ❌ Нет | ✅ Codex / Copilot |
| Постоянная память между сессиями | ❌ Нужно настраивать | ✅ Официально поддерживается |
| Function Calling | ✅ Полная | ✅ Полная |
Экосистема OpenAI значительно впереди — это результат 7 лет накопленного опыта. Grok 4.3 отлично справляется с «базовыми функциями» вроде Function Calling, потокового вывода и JSON-режима, но все еще отстает в плане интеграции с IDE (Codex) и долгосрочной памяти.
🎯 Совет по интеграции: Если ваш проект сильно зависит от экосистемы OpenAI (сложный Function Calling, интеграция с IDE через Codex), GPT-5.5 остается приоритетным выбором. Для новых проектов рекомендуем использовать платформу APIYI (apiyi.com) для одновременного подключения Grok 4.3 и GPT-5.5, так как оба API полностью совместимы с протоколом OpenAI Chat Completions.
Рекомендации по выбору сценариев для Grok 4.3 и GPT-5.5
Сценарии для выбора Grok 4.3
Если ваш бизнес соответствует любому из этих пунктов, рассмотрите Grok 4.3 в первую очередь.
- Сценарий 1: Масштабное производство контента: Задачи с высоким объемом вывода (поддержка, написание статей, массовые ответы на почту). Стоимость вывода Grok 4.3 составляет $2.50, что в 12 раз дешевле, чем $30 у GPT-5.5.
- Сценарий 2: Понимание видеоконтента: Мониторинг, конспекты обучающих видео, документирование презентаций продуктов. Grok 4.3 — единственное на данный момент выгодное решение с нативной поддержкой видео.
- Сценарий 3: Автоматическая генерация документов: Автоматизация отчетов, PPT, таблиц. Grok 4.3 позволяет сразу генерировать PDF/XLSX/PPTX.
- Сценарий 4: Агенты с длинными цепочками действий: Симуляции типа Vending-Bench, сложные рабочие процессы. По тестам Grok 4.3 опережает GPT-5.5 примерно в 1.5–2 раза.
- Сценарий 5: Продукты для диалогов в реальном времени: Скорость вывода 207 tps отлично подходит для чат-ботов, синхронного перевода и потоковых ответов.
- Сценарий 6: Бюджетные ограничения для малых команд: Если ваш месячный бюджет менее $1000, Grok 4.3 позволит вам использовать в 7 раз больше токенов.
Сценарии для выбора GPT-5.5
Если ваш бизнес требует высокой точности, переплата за GPT-5.5 будет оправдана.
- Сценарий 1: Продвинутый агентный кодинг: С показателями Terminal-Bench 2.0 82.7% и Aider Polyglot 88%, GPT-5.5 — текущий лидер среди AI-агентов для программирования.
- Сценарий 2: Передовые математические и научные рассуждения: FrontierMath 51.7%, стабильная работа с задачами уровня IMO — идеально для научных ассистентов.
- Сценарий 3: Точный поиск в длинном контексте: 74% в тесте 512K-1M 8-needle MRCR. Подходит для анализа юридических контрактов, медицинских документов и годовых отчетов.
- Сценарий 4: Постоянная память между сессиями: Для персональных ассистентов, которым нужно помнить контекст неделями, GPT-5.5 имеет нативную поддержку.
- Сценарий 5: Глубокая интеграция с Codex / IDE: Если нужны AI-инструменты внутри IDE (VSCode, JetBrains, Codex CLI), экосистема GPT-5.5 самая зрелая.
- Сценарий 6: Корпоративные требования к комплаенсу: Самая полная поддержка SOC2, HIPAA, ISO и других стандартов.
Рекомендация по гибридной архитектуре
Для большинства продуктов среднего и крупного масштаба мы рекомендуем гибридную архитектуру.
| Тип задачи | Модель маршрутизации | Рекомендуемая доля |
|---|---|---|
| Простая классификация / FAQ | Grok 4 Fast | 50–60% |
| Стандартные рассуждения | Grok 4.3 | 25–35% |
| Сложный кодинг / Математика | GPT-5.5 | 5–10% |
| Сверхсложные задачи | GPT-5.5 Pro | < 1% |
Такая многоуровневая маршрутизация позволяет снизить общие затраты на AI до 15–25% от стоимости «полного использования GPT-5.5» без потери качества на ключевых задачах.
💡 Совет по внедрению: Через прокси-сервис APIYI (apiyi.com) все модели используют один и тот же
base_urlи API-ключ. На уровне приложения достаточно настроить автоматическую маршрутизацию по тегам задач или длине токенов, что избавляет от необходимости поддерживать отдельный код для каждого провайдера.
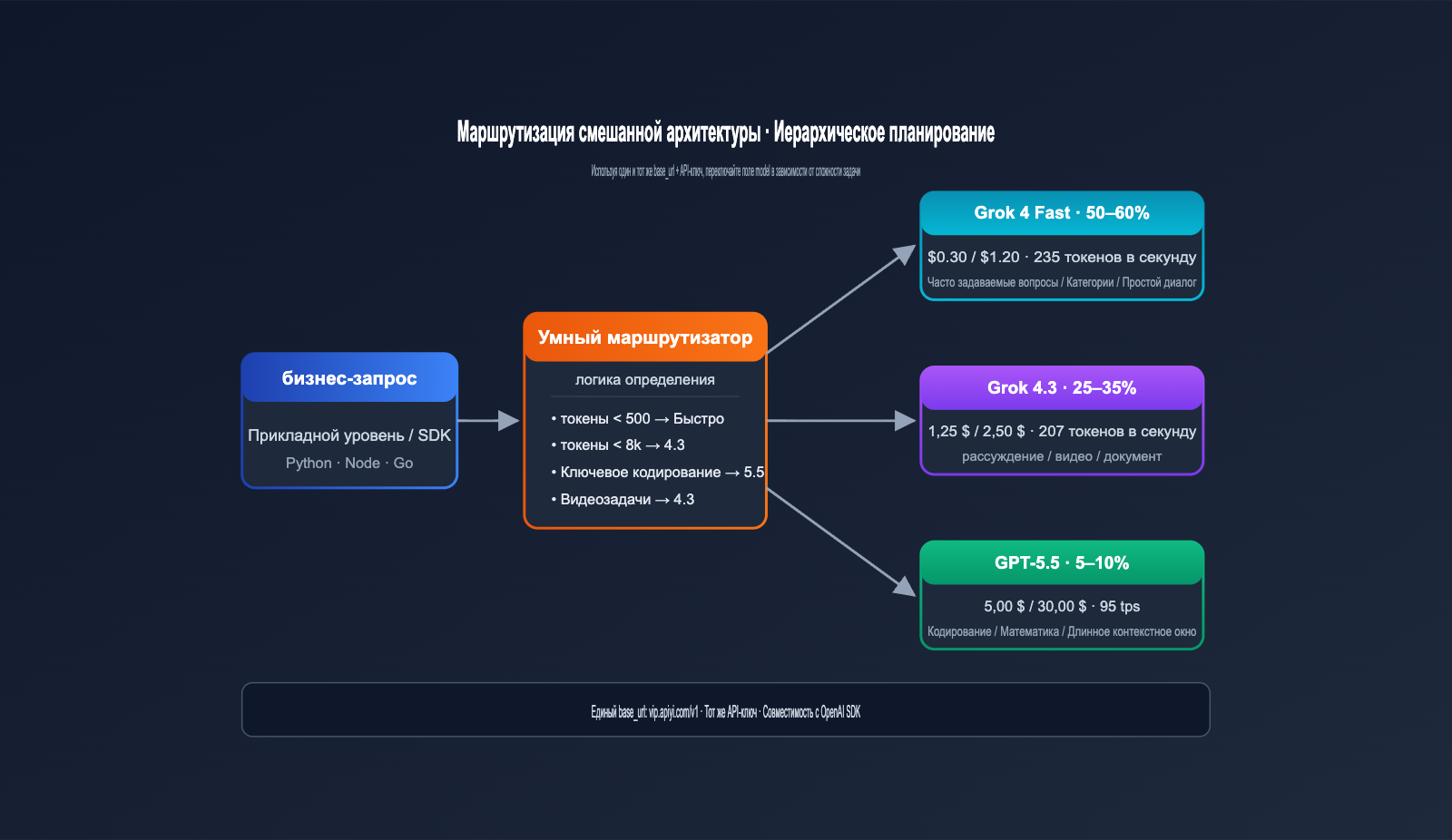
Пример экономии затрат при гибридной архитектуре Grok 4.3 и GPT-5.5
Ниже приведено сравнение затрат средней SaaS-команды в мае 2026 года до и после перехода на гибридную архитектуру. Продукт объединяет «умную поддержку + AI-ассистента для кода + анализ данных», ежемесячный объем вызовов — около 800 млн токенов.
| Показатель | Полный GPT-5.5 | Гибридная архитектура (Grok 4.3 + GPT-5.5) |
|---|---|---|
| Доля простых FAQ | 60% | Grok 4 Fast |
| Доля стандартной поддержки | 30% | Grok 4.3 |
| Доля сложного кода / анализа | 10% | GPT-5.5 |
| Ежемесячные затраты | ~$9,000 | ~$2,100 |
| Качество ключевых задач | 100% (база) | ~98% (база) |
| Скорость простых задач | Средняя | В 2 раза быстрее |
Гибридная архитектура снизила затраты до 23% от исходных при практически неизменном качестве ключевых задач, а скорость ответа на простые запросы даже выросла. Это наиболее выгодное архитектурное обновление для команд среднего и крупного масштаба.
🎯 Совет по внедрению: Рекомендуем использовать стратегию двойной маршрутизации: проверка длины токенов + теги задач. Простые запросы направляйте на Grok 4 Fast (стоимость в 4 раза ниже, чем у 4.3), средние рассуждения — на Grok 4.3, а критически важный кодинг и математику — на GPT-5.5. На платформе APIYI (apiyi.com) все модели используют один API-ключ, что делает инженерную доработку простой и контролируемой.
Сравнение Grok 4.3 и GPT-5.5: подключение и примеры кода
Обе модели полностью совместимы с OpenAI SDK через сервис-прокси API APIYI, поэтому затраты на миграцию практически равны нулю.
Пример унифицированного вызова Grok 4.3 и GPT-5.5
# Используем официальный OpenAI SDK для одновременного вызова обеих моделей через APIYI
from openai import OpenAI
client = OpenAI(
api_key="Ваш API-ключ APIYI",
base_url="https://vip.apiyi.com/v1"
)
# Вызов Grok 4.3
grok_resp = client.chat.completions.create(
model="grok-4.3",
messages=[{"role": "user", "content": "Опиши архитектуру Transformer в 200 словах"}]
)
# Вызов GPT-5.5
gpt_resp = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": "Опиши архитектуру Transformer в 200 словах"}],
reasoning_effort="high" # GPT-5.5 поддерживает явную настройку уровня рассуждений
)
print("Grok 4.3:", grok_resp.choices[0].message.content)
print("GPT-5.5:", gpt_resp.choices[0].message.content)
Посмотреть полный код маршрутизации с гибридной архитектурой (автоматический выбор модели по количеству токенов)
from openai import OpenAI
from typing import Literal
client = OpenAI(
api_key="Ваш API-ключ APIYI",
base_url="https://vip.apiyi.com/v1"
)
ROUTE_THRESHOLDS = {
"simple": 500, # Короткий промпт — используем Grok 4 Fast
"reasoning": 8000, # Средний промпт — используем Grok 4.3
"premium": 50000 # Длинный промпт или критические задачи — используем GPT-5.5
}
def estimate_tokens(text: str) -> int:
"""Упрощенная оценка токенов: для англ. — символы/4, для кириллицы — символы/2"""
return max(len(text) // 4, len(text) // 2)
def route_model(prompt: str, force_premium: bool = False) -> str:
"""Выбор модели в зависимости от длины промпта и сложности задачи"""
if force_premium:
return "gpt-5.5"
tokens = estimate_tokens(prompt)
if tokens < ROUTE_THRESHOLDS["simple"]:
return "grok-4-fast"
elif tokens < ROUTE_THRESHOLDS["reasoning"]:
return "grok-4.3"
else:
return "gpt-5.5"
def smart_chat(prompt: str, force_premium: bool = False) -> str:
"""Умный вызов с маршрутизацией"""
model = route_model(prompt, force_premium)
extra_params = {}
if model == "gpt-5.5":
extra_params["reasoning_effort"] = "high"
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
**extra_params
)
return f"[{model}] {response.choices[0].message.content}"
if __name__ == "__main__":
print(smart_chat("Привет"))
print(smart_chat("Помоги спроектировать конечный автомат для заказов в интернет-магазине"))
print(smart_chat("Это кодовая база на 50k токенов..." * 1000, force_premium=True))
Особенности вызова Grok 4.3 и GPT-5.5
| Особенность | Grok 4.3 | GPT-5.5 |
|---|---|---|
| Поле модели | grok-4.3 |
gpt-5.5 |
| Настройка рассуждений | Включено по умолчанию | reasoning_effort (low/medium/high/xhigh) |
| Ввод видео | video_url |
Не поддерживается, нужна транскрипция |
| Вывод документов | extra_body={"output_format": "pdf/xlsx/pptx"} |
Требуется пост-обработка на уровне приложения |
| Потоковый вывод | stream=True |
stream=True (рекомендуется для продакшена) |
| Function Calling | ✅ Полная поддержка | ✅ Полная поддержка (включая strict mode) |
| Постоянная память | ❌ Требуется RAG на уровне приложения | ✅ Поле previous_response_id |
🎯 Совет по подключению: Рекомендуем сначала запросить тестовый ключ на платформе APIYI (apiyi.com), чтобы отладить минимальный рабочий цикл, а затем принимать решение о полной миграции или гибридной маршрутизации. Платформа поддерживает оплату в юанях и модель оплаты по факту использования, что удобно для финансовой отчетности команд.
Рекомендации по выбору: Grok 4.3 против GPT-5.5
Трехшаговый метод принятия решений
Мы сократили процесс выбора до трех шагов, которые займут у вас не более 90 секунд.
Шаг 1: Каков ваш основной тип задач?
- Программирование / математика / поиск по длинному контексту → выбирайте GPT-5.5
- Видео / генерация документов / большие объемы контента / чаты в реальном времени → выбирайте Grok 4.3
Шаг 2: Какой у вас ежемесячный бюджет на токены?
- < 100 млн токенов: выбирайте «оптимальную модель для основной задачи»
- 100 млн – 1 млрд токенов: обязательно используйте гибридную архитектуру (основная — Grok 4.3, для критических задач — GPT-5.5)
- ≥ 1 млрд токенов: используйте трехуровневую систему (Grok 4 Fast / Grok 4.3 / GPT-5.5), иначе расходы выйдут из-под контроля
Шаг 3: Нужны ли вам уникальные функции экосистемы OpenAI?
- Да (постоянная память / Codex IDE / соответствие SOC2) → GPT-5.5
- Нет → Grok 4.3 вне конкуренции по соотношению цена/качество
Матрица принятия решений
| Ваш приоритет | Рекомендуемый выбор | Альтернатива |
|---|---|---|
| Максимальная выгода | Grok 4.3 | Grok 4 Fast |
| Точность кода | GPT-5.5 | GPT-5.5 Pro |
| Математические рассуждения | GPT-5.5 Pro | GPT-5.5 |
| Мультимодальная обработка видео | Grok 4.3 | (нет альтернатив) |
| Точный поиск по длинному контексту | GPT-5.5 | Grok 4.3 |
| Скорость ответа в реальном времени | Grok 4.3 | GPT-5.5 (высокий reasoning) |
| Продукты с постоянной памятью | GPT-5.5 | (Grok 4.3 требует доработки) |
| Массовые офлайн-задачи | Grok 4.3 | Batch-режим |
💡 Совет: Выбор модели зависит от ваших конкретных сценариев и требований к качеству. Мы рекомендуем подключить обе модели через платформу APIYI (apiyi.com), провести A/B-тестирование на реальных данных и только после этого принимать окончательное решение.
Часто задаваемые вопросы: Grok 4.3 против GPT-5.5
Q1: Можно ли использовать Grok 4.3 и GPT-5.5 в России?
Да, обе модели доступны через сервис-прокси API APIYI (apiyi.com). Базовый URL (base_url) един для всех: https://vip.apiyi.com/v1, а названия моделей — grok-4.3 и gpt-5.5 соответственно. Сервис развернут на нескольких серверах внутри страны, что обеспечивает стабильную задержку и избавляет от необходимости настраивать собственные прокси. Цены на Grok 4.3 полностью соответствуют официальным ценам xAI, а GPT-5.5 предоставляется по официальным тарифам OpenAI (коэффициент входных токенов 2.5, выходных — 6, что соответствует $5/$30 за миллион токенов) без каких-либо наценок.
Q2: Разница в цене 7 раз — действительно ли GPT-5.5 стоит своих денег?
Зависит от задачи. Если ваша основная работа связана с агентным программированием (Terminal-Bench, SWE-bench) или передовой математикой (FrontierMath), преимущество GPT-5.5 в точности напрямую конвертируется в экономию времени на ручную правку и более высокое качество продукта — здесь переплата оправдана. Однако для массовой генерации контента, ответов службы поддержки, анализа видео или автоматизации документов преимущество в точности GPT-5.5 может быть избыточным, и здесь «дешевизна в 7 раз» модели Grok 4.3 становится более весомым аргументом. Наш совет: используйте GPT-5.5 для критических путей, а Grok 4.3 — для вспомогательных, настроив гибридную маршрутизацию через APIYI (apiyi.com).
Q3: Обе модели поддерживают контекстное окно 1M, есть ли разница в реальной работе?
Да, и довольно существенная. В тестах MRCR v2 8-needle 512K-1M модель GPT-5.5 достигла 74.0% точности, что вдвое выше результата GPT-5.4 (36.6%). Это означает значительный прогресс в способности точно «находить иголку в стоге сена» в длинном контексте. Данные MRCR для Grok 4.3 не публиковались, но тесты сообщества показывают, что она отлично справляется с суммаризацией длинных текстов, хотя в «точном поиске» немного уступает GPT-5.5. Если ваш бизнес зависит от поиска «3 конкретных фактов среди 800k токенов», GPT-5.5 надежнее; если же нужно просто сделать краткую выжимку из длинного документа, обе модели справятся отлично.
Q4: GPT-5.5 не поддерживает видео, есть ли обходные пути?
Есть, но инженерная сложность заметно возрастает. Обработка видео через GPT-5.5 обычно требует трех шагов: сначала Whisper для получения субтитров (STT), затем извлечение кадров для мультимодального анализа GPT-5.5 и, наконец, логический вывод (reasoning) для интеграции данных. Эту же цепочку Grok 4.3 выполняет за один запрос. Если в вашем проекте есть задачи по обработке видео, мы рекомендуем сразу использовать Grok 4.3 через APIYI (apiyi.com) — это снизит инженерную сложность в 3–5 раз и уменьшит затраты.
Q5: Нужно ли менять код при обновлении с GPT-5.4 / GPT-5 на GPT-5.5?
Почти нет. Достаточно изменить название модели с gpt-5 или gpt-5.4 на gpt-5.5, base_url остается прежним. У GPT-5.5 по умолчанию повышен уровень reasoning, а если нужен тонкий контроль, можно добавить поле reasoning_effort (low/medium/high/xhigh). В тех же задачах GPT-5.5 расходует меньше токенов, чем GPT-5.4, поэтому реальная стоимость может остаться прежней или даже снизиться при заметном росте точности. Миграция очень выгодна.
Q6: Что выбрать: GPT-5.5 или GPT-5.5 Pro?
Выбирайте в зависимости от сложности задачи. GPT-5.5 Pro стоит в 6 раз дороже ($30/$180 против $5/$30), предлагая более высокий уровень reasoning и стабильность вывода. Рекомендация: направляйте 95% трафика на GPT-5.5, а GPT-5.5 Pro оставьте для «сверхсложных задач и критических решений» (например, сложные математические доказательства или важные PR-ревью). Так вы получите максимальную отдачу, используя GPT-5.5 Pro лишь в 5–10% случаев. Для большинства бизнес-задач GPT-5.5 более чем достаточно.
Q7: У Grok 4.3 нет постоянной памяти, повлияет ли это на продукт?
Да, но есть проверенные решения. Если ваш продукт — это «персональный ассистент» или «длительный диалог», постоянная память необходима. Grok 4.3 пока не поддерживает её нативно, поэтому нужно реализовать слой памяти на уровне приложения. Популярные варианты — Mem0 или Letta. Эти инструменты с открытым исходным кодом напрямую совместимы с протоколом OpenAI Chat Completions, а значит, работают и с Grok 4.3. Мы советуем сначала запустить базовый диалог через APIYI (apiyi.com), а затем добавить слой памяти — это самый дешевый путь итерации. Если не хотите строить свое решение, GPT-5.5 станет более простым выбором.
Q8: Одинакова ли тарификация для обеих моделей на APIYI?
Абсолютно одинакова — оплата идет за использование токенов. Для Grok 4.3 цена 1:1 соответствует официальной ($1.25 вход / $2.50 выход за миллион токенов). GPT-5.5 тарифицируется по официальным ценам OpenAI (коэффициент модели 2.5, что соответствует $5.00 за вход; коэффициент дополнения 6, что соответствует $30.00 за выход за миллион токенов). Обе модели используют один и тот же API-ключ и base_url (https://vip.apiyi.com/v1), а списания происходят с одного баланса, что упрощает управление и сверку расходов.
Q9: Как снизить расходы на вызов GPT-5.5, есть ли советы по оптимизации?
Четыре ключевых приема: (1) Включите prompt caching: фиксация системного промпта позволяет сэкономить 50–70% затрат (кешированный ввод GPT-5.5 стоит всего $0.50/1M); (2) Снизьте reasoning_effort: для простых задач используйте уровень low, это сократит потребление токенов на 60%; (3) Используйте Batch API для некритичных по времени задач — это сэкономит еще 50%; (4) Используйте потоковый вывод (streaming) с досрочной остановкой — для длинных ответов это поможет сэкономить токены в конце. При сочетании этих методов реальная стоимость GPT-5.5 может приблизиться к двойной стоимости входных токенов Grok 4.3.
Q10: Как обстоят дела с совместимостью Function Calling у обеих моделей?
Обе модели полностью совместимы с протоколом OpenAI Function Calling, поэтому код можно использовать повторно. Обе поддерживают поле tools, параллельный вызов инструментов и strict mode (принудительная схема JSON). Разница в том, что у GPT-5.5 проверка схемы инструментов в strict mode строже, что снижает вероятность ложных срабатываний, а Grok 4.3 нативно поддерживает инструменты на стороне сервера (web_search / x_search / code_execution) без необходимости реализации на стороне приложения. Если ваш проект сильно зависит от Function Calling, модели можно легко переключать — рекомендуем подключить обе через APIYI (apiyi.com) для A/B тестирования.
Резюме: реальный выбор между Grok 4.3 и GPT-5.5
Суть этого сравнения не в том, «кто сильнее», а в двух разных стратегиях развития: xAI с помощью Grok 4.3 выравнивает кривую стоимости моделей с reasoning и расширяет границы мультимодальности, а OpenAI с помощью GPT-5.5 поднимает планку точности в программировании, математике и поиске по длинному контексту.
Если подвести итог одной фразой: большинству команд стоит использовать Grok 4.3 как основную модель, а GPT-5.5 — как резерв для критических путей. Цена Grok 4.3 ($1.25/$2.50), скорость 207 tps и поддержка видео покрывают 90% бизнес-сценариев. Оставшиеся 10% высокоценных задач (сложное программирование, передовая математика, точный поиск в длинном контексте) можно закрыть с помощью GPT-5.5. Общая стоимость такой связки составит 15–25% от стоимости «полного перехода на GPT-5.5» при почти нулевой потере качества на ключевых задачах.
Для российских разработчиков самый простой путь реализации такой гибридной архитектуры — сервис-прокси APIYI (apiyi.com). Обе модели используют один и тот же base_url и API-ключ, поэтому на уровне приложения достаточно просто поменять поле model. Инженерные затраты на внедрение практически нулевые. Цены на Grok 4.3 соответствуют официальным, а GPT-5.5 предоставляется без наценок. А если добавить Batch API и скидки на кешированный ввод, общие затраты можно снизить еще на 30–50%.
Напоследок совет: потратьте неделю, чтобы прогнать 100–500 образцов ваших реальных данных через обе модели на APIYI. Бенчмарки — это лишь ориентир, а соответствие вашим реальным задачам — основа для принятия решения. Обе модели уже стабильно работают, подключение не требует затрат, а данные, полученные на практике, — самый надежный аргумент.
Справочные материалы
-
Официальный анонс OpenAI: Информация о релизе GPT-5.5 и документация API
- Ссылка:
openai.com/index/introducing-gpt-5-5 - Описание: содержит информацию о ценах, бенчмарках и описании полей API.
- Ссылка:
-
Документация для разработчиков OpenAI: Спецификации модели GPT-5.5 и примеры вызовов
- Ссылка:
developers.openai.com/api/docs/models/gpt-5.5 - Описание: полные параметры API и детали тарификации.
- Ссылка:
-
Документация по моделям xAI: Полные спецификации API для Grok 4.3
- Ссылка:
docs.x.ai/developers/models - Описание: включает уникальные возможности, такие как обработка видео и генерация документов.
- Ссылка:
-
Рейтинг Artificial Analysis: Сравнительный анализ производительности различных моделей
- Ссылка:
artificialanalysis.ai/models/grok-4-3 - Описание: комплексная оценка индекса интеллекта AA, скорости и стоимости.
- Ссылка:
-
Отчет Vellum по бенчмаркам: Подробный разбор серии GPT-5 / GPT-5.5
- Ссылка:
vellum.ai/blog/gpt-5-2-benchmarks - Описание: независимое тестирование по множеству бенчмарков.
- Ссылка:
-
Сравнение моделей DocsBot: Детальное сопоставление GPT-5.5 и Grok 4.3
- Ссылка:
docsbot.ai/models/compare/gpt-5-5/grok-4-3 - Описание: сравнение цен, производительности и функциональных возможностей.
- Ссылка:
-
Документация по интеграции APIYI: Полное руководство по подключению к обеим моделям через сервис-прокси API
- Ссылка:
help.apiyi.com - Описание: включает информацию о коэффициентах, примеры SDK и проверку баланса.
- Ссылка:
Автор: Команда APIYI — специализируемся на сервисах-прокси API для больших языковых моделей, помогая разработчикам в один клик подключать Grok 4.3, GPT-5.5, Claude Opus 4.7 и другие популярные модели. Посетите APIYI на apiyi.com, чтобы получить бесплатные тестовые лимиты.