站长注:OpenAI 最新推出的强化学习微调(RFT)技术,让开发者能够通过奖励和惩罚机制训练出更符合特定需求的AI模型。本文将用通俗易懂的语言为你解析这项前沿技术。
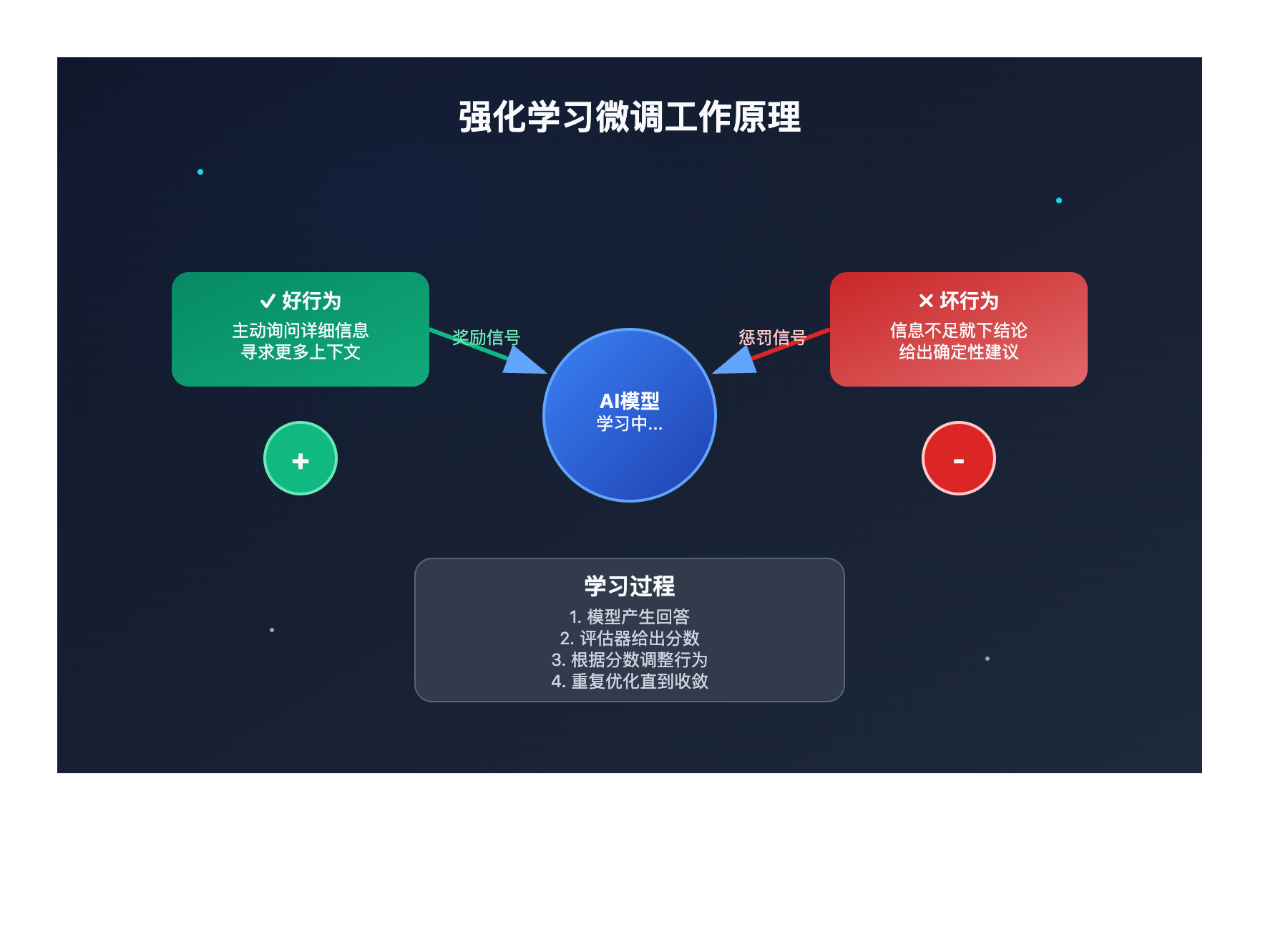
想象一下,如果你能像训练宠物一样训练AI模型——做得好就给奖励,做得不好就给惩罚,让它逐渐学会你想要的行为模式。这就是 OpenAI 强化学习微调(Reinforcement Fine-tuning, RFT) 的核心思想。
📌 快速开始体验
欢迎免费试用 API易,3 分钟跑通 API 调用 www.apiyi.com
支持 OpenAI 全系列模型,让AI开发更简单
注册可送 1.1 美金额度起,约 300万 Tokens 额度体验。立即免费注册
💬 加站长个人微信:8765058,发送你《大模型使用指南》等资料包,并加赠 1 美金额度。
OpenAI 强化学习微调 背景介绍
传统的AI模型训练就像是给学生上课——老师讲,学生听,然后考试。但现实世界的需求往往更复杂,我们需要AI不仅能回答问题,还要知道什么时候该问问题,什么时候该寻求更多信息。
OpenAI 在2025年5月推出的强化学习微调技术,正是为了解决这个问题。它基于 HealthBench 医疗问答基准测试,让模型学会在不确定的情况下主动寻求额外的上下文信息。
OpenAI 强化学习微调 核心功能
以下是 OpenAI 强化学习微调 的核心功能特性:
| 功能模块 | 核心特性 | 应用价值 | 推荐指数 |
|---|---|---|---|
| 奖励机制训练 | 通过奖励/惩罚信号优化模型行为 | 让模型更符合特定业务需求 | ⭐⭐⭐⭐⭐ |
| 对话推理增强 | 提升模型在对话中的推理能力 | 改善用户交互体验 | ⭐⭐⭐⭐⭐ |
| 上下文感知 | 训练模型主动寻求额外信息 | 减少模型回答的不确定性 | ⭐⭐⭐⭐ |
🔥 重点功能详解
什么是强化学习微调?
简单来说,强化学习微调就像是给AI模型配备了一个"内在导师"。这个导师会根据模型的表现给出评分:
- 做得好:比如在医疗咨询中主动询问患者症状细节 → 获得高分奖励
- 做得不好:比如在信息不足时就给出确定性建议 → 获得低分惩罚
通过这种方式,模型逐渐学会什么样的行为是被鼓励的。
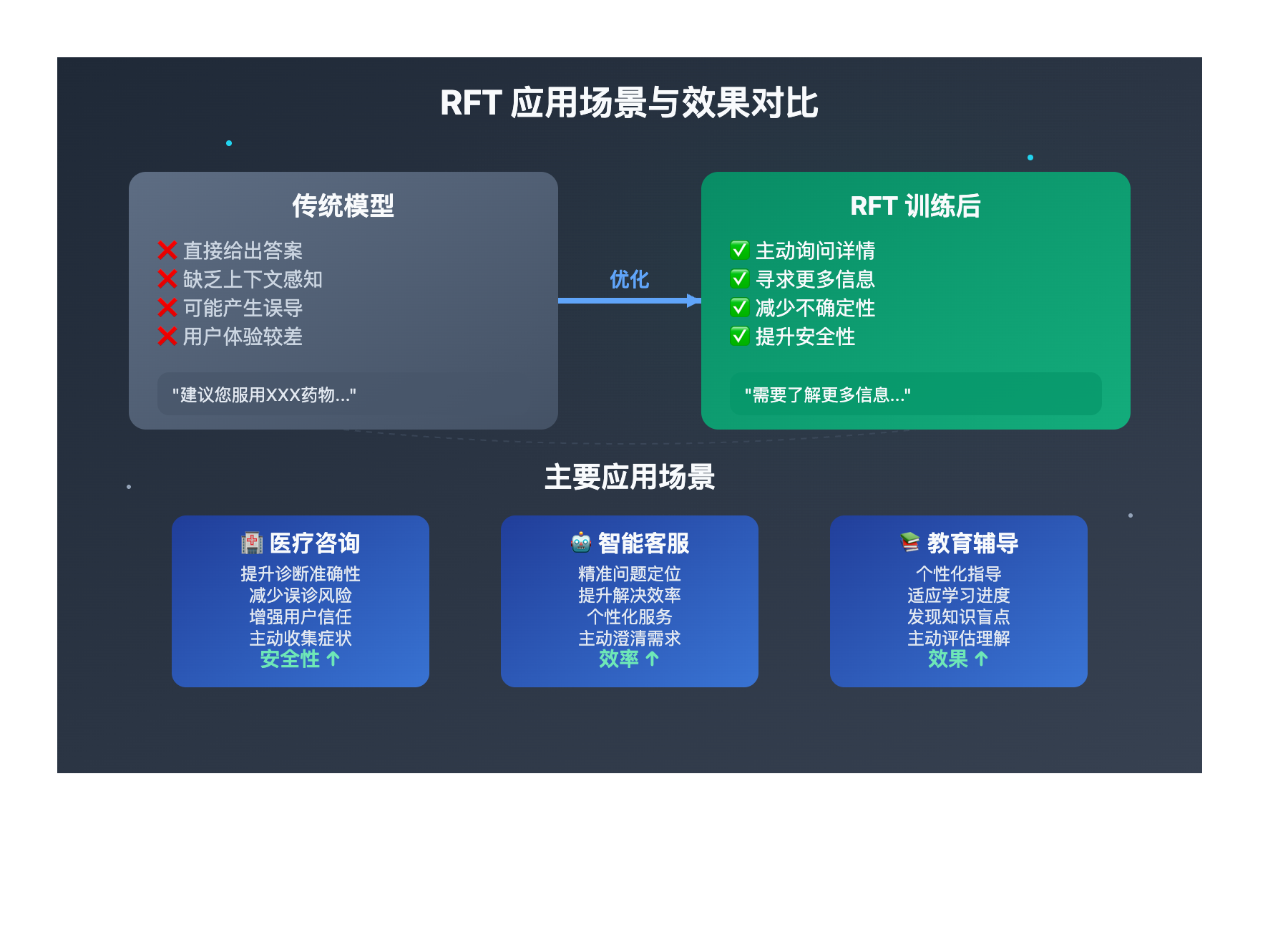
实际应用场景
根据 OpenAI 的官方教程,RFT 在医疗问答场景中表现出色。比如:
传统模型回答:
"根据您的症状,建议您服用XXX药物..."
RFT训练后的模型回答:
"为了给您更准确的建议,我需要了解更多信息:
1. 症状出现多长时间了?
2. 是否有其他伴随症状?
3. 您目前在服用其他药物吗?"

OpenAI 强化学习微调 应用场景
OpenAI 强化学习微调 在以下场景中表现出色:
| 应用场景 | 适用对象 | 核心优势 | 预期效果 |
|---|---|---|---|
| 🎯 医疗咨询系统 | 医疗AI应用开发者 | 提升诊断准确性和安全性 | 减少误诊风险,提高用户信任度 |
| 🚀 客服机器人 | 企业客服部门 | 改善问题解决效率 | 更精准的问题定位和解决方案 |
| 💡 教育辅导 | 在线教育平台 | 个性化学习指导 | 根据学生情况调整教学策略 |
OpenAI 强化学习微调 开发指南
🎯 模型选择策略
💡 服务介绍
API易,AI行业领先的API中转站,均为官方源头转发,价格有优势,聚合各种优秀大模型,使用方便:一个令牌,无限模型。企业级专业稳定的 OpenAI o3/Claude 4/Gemini 2.5 Pro/Deepseek R1/Grok 等全模型官方同源接口的中转分发。优势很多:不限速,不过期,不惧封号,按量计费,长期可靠服务;让技术助力科研、让 AI 加速公司业务发展!
🔥 针对 强化学习微调 的推荐模型
| 模型名称 | 核心优势 | 适用场景 | 推荐指数 |
|---|---|---|---|
| gpt-4o | 平衡的推理和对话能力 | 基础RFT实验和原型开发 | ⭐⭐⭐⭐⭐ |
| claude-opus-4-20250514-thinking | 思维链推理能力强 | 复杂推理场景的RFT训练 | ⭐⭐⭐⭐ |
| deepseek-r1 | 推理能力突出,成本较低 | 大规模RFT训练项目 | ⭐⭐⭐⭐⭐ |
🎯 选择建议:基于 强化学习微调 的特点,我们推荐优先使用 gpt-4o,它在 对话推理和上下文理解 方面表现突出,是RFT训练的理想基础模型。
⚠️ 重要提醒
Fine-tuning 服务限制:目前所有API中转站(包括API易)都不支持 Fine-tuning 功能,这是 OpenAI 官方的技术限制。如需使用强化学习微调功能,您需要:
- 使用 OpenAI 官方账号和 API
- 联系站长代办官方账号服务(微信:8765058)
- 在完成微调后,可通过 API易 调用微调后的模型
🎯 强化学习微调 场景推荐表
| 使用场景 | 首选模型 | 备选模型 | 经济型选择 | 特点说明 |
|---|---|---|---|---|
| 🔥 RFT训练基础模型 | gpt-4o | claude-opus-4 | deepseek-r1 | 需要官方API进行微调训练 |
| 🖼️ 微调后模型调用 | 自定义微调模型 | gpt-4o | gpt-4o-mini | 可通过API易调用微调后的模型 |
| 🧠 效果对比测试 | claude-opus-4-thinking | deepseek-r1 | gpt-4o-mini | 对比微调前后的性能差异 |
💰 价格参考:具体价格请参考 API易价格页面
💻 实践示例
强化学习微调的基本流程
根据 OpenAI 官方教程,RFT 的实现步骤如下:
# 1. 准备训练数据
train_datapoints = [
{
"messages": conversation_history,
"completion": model_response
}
]
# 2. 创建微调任务(需要官方API)
from openai.types.fine_tuning import ReinforcementMethod, ReinforcementHyperparameters
from openai.types.graders import ScoreModelGrader
fine_tuning_job = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-4o-2024-08-06",
method=ReinforcementMethod(
type="reinforcement",
hyperparameters=ReinforcementHyperparameters(
n_epochs=3,
batch_size=8,
learning_rate_multiplier=0.1
),
grader=ScoreModelGrader(
model="gpt-4o",
prompt="评估回答质量的提示词..."
)
)
)
通过 API易 调用微调后的模型
# 🚀 调用微调后的模型
curl https://vip.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $替换你的API易后台的Key$" \
-d '{
"model": "ft:gpt-4o:your-org:your-model-name",
"stream": true,
"messages": [
{"role": "system", "content": "你是一个经过强化学习训练的医疗咨询助手。"},
{"role": "user", "content": "我最近总是感到疲劳,这是什么原因?"}
]
}'
✅ 强化学习微调 最佳实践
| 实践要点 | 具体建议 | 注意事项 |
|---|---|---|
| 🎯 数据质量 | 确保训练数据包含高质量的对话示例 | 避免有偏见或不准确的训练样本 |
| ⚡ 评分标准 | 设计清晰的奖励/惩罚机制 | 评分标准要与业务目标一致 |
| 💡 迭代优化 | 小批量测试,逐步优化模型表现 | 避免过度拟合特定场景 |
❓ 强化学习微调 常见问题
Q1: 为什么API中转站不支持Fine-tuning?
这是技术架构限制。Fine-tuning 需要直接访问 OpenAI 的训练基础设施,而API中转站只能提供推理服务。如需微调服务,建议:
- 使用官方API进行训练
- 训练完成后通过API易调用微调模型
- 联系站长获取官方账号代办服务
Q2: 强化学习微调的成本如何?
RFT的成本主要包括:
- 训练数据准备成本
- OpenAI官方微调费用(按训练tokens计算)
- 后续模型调用费用(可通过API易优化成本)
Q3: 微调后的模型效果如何评估?
可以通过以下方式评估:
- A/B测试对比微调前后的模型表现
- 使用标准化评估指标(如HealthBench)
- 收集真实用户反馈进行定性分析
🏆 为什么选择「API易」AI大模型API聚合平台
| 核心优势 | 具体说明 | 竞争对比 |
|---|---|---|
| 🛡️ 微调模型支持 | • 支持调用用户自定义的微调模型 • 提供稳定的推理服务 • 解决官方API访问限制问题 |
相比官方平台更稳定 |
| 🎨 丰富的基础模型 | • 提供多种适合RFT的基础模型 • 支持效果对比测试 • 灵活的模型切换 |
一个令牌,无限模型 |
| ⚡ 高性能推理 | • 微调模型调用不限速 • 多节点部署保障稳定性 • 7×24 技术支持 |
性能优于同类平台 |
| 🔧 开发者友好 | • OpenAI 兼容接口 • 完善的微调模型集成文档 • 简单快速接入 |
开发者友好 |
| 💰 成本优势 | • 微调模型调用价格透明 • 按量计费,无隐藏费用 • 提供免费测试额度 |
价格更有竞争力 |
💡 应用示例
以强化学习微调为例,完整的开发流程是:
- 通过 OpenAI 官方API完成RFT训练
- 获得微调后的模型ID(如:ft:gpt-4o:org:model-name)
- 在API易平台配置并调用微调模型
- 享受不限速、高稳定性的推理服务
- 根据实际效果进行模型迭代优化
🎯 总结
OpenAI 的强化学习微调技术为AI模型训练带来了革命性的改进,让模型能够通过奖励机制学会更符合特定需求的行为模式。虽然微调训练需要使用官方API,但训练完成后可以通过API易平台获得更稳定、更经济的推理服务。
重点回顾:RFT让AI模型学会主动思考和提问,显著提升了对话质量和用户体验
📞 立即开始体验
欢迎免费试用 API易,3 分钟跑通 API 调用 www.apiyi.com
支持微调模型调用,让强化学习训练成果发挥最大价值
💬 加站长个人微信:8765058,发送你《大模型使用指南》等资料包,并加赠 1 美金额度。

📝 本文作者:API易团队
🔔 关注更新:欢迎关注我们的更新,持续分享 AI 开发经验和最新动态。