站长注:详解如何利用OpenAI的多模态能力构建图像理解RAG系统,通过API易平台轻松实现视觉与文本的智能检索增强应用。
多模态RAG系统是AI应用开发的前沿领域,它将图像理解与文本检索增强生成相结合,能够处理包含图片和文字的混合数据。OpenAI最近发布的官方教程展示了如何构建这样一个系统,本文将以通俗易懂的语言解析这一技术,并结合API易平台的服务,帮助开发者快速实现自己的多模态RAG应用。
欢迎免费试用 API易,3 分钟跑通 API 调用 www.apiyi.com
支持 OpenAI 多模态模型和Vector Store API,让RAG应用开发更简单
注册可送 1.1 美金额度起,约 300万 Tokens 额度体验。立即免费注册
加站长个人微信:8765058,发送你《大模型使用指南》等资料包,并加赠 1 美金额度。
OpenAI多模态RAG系统背景介绍
RAG(Retrieval-Augmented Generation,检索增强生成)是近年来大模型应用的重要技术,它通过检索外部知识来增强生成内容的准确性和相关性。而多模态RAG则将这一概念扩展到图像、文本等多种数据类型的融合处理上。
在实际应用中,数据往往不仅限于单一类型。例如,客户反馈可能同时包含文字评论和产品照片;医疗记录可能包含诊断报告和X光片;电商平台需处理商品描述和商品图片。这些场景都需要AI系统能够同时理解图像和文本,并将它们结合起来进行分析和处理。
OpenAI的多模态RAG系统利用了最新的GPT-4.1模型的视觉能力,结合Vector Store API的检索功能,实现了对图像和文本混合数据的智能理解和检索。这种技术特别适合需要处理大量多模态数据的企业和开发者。
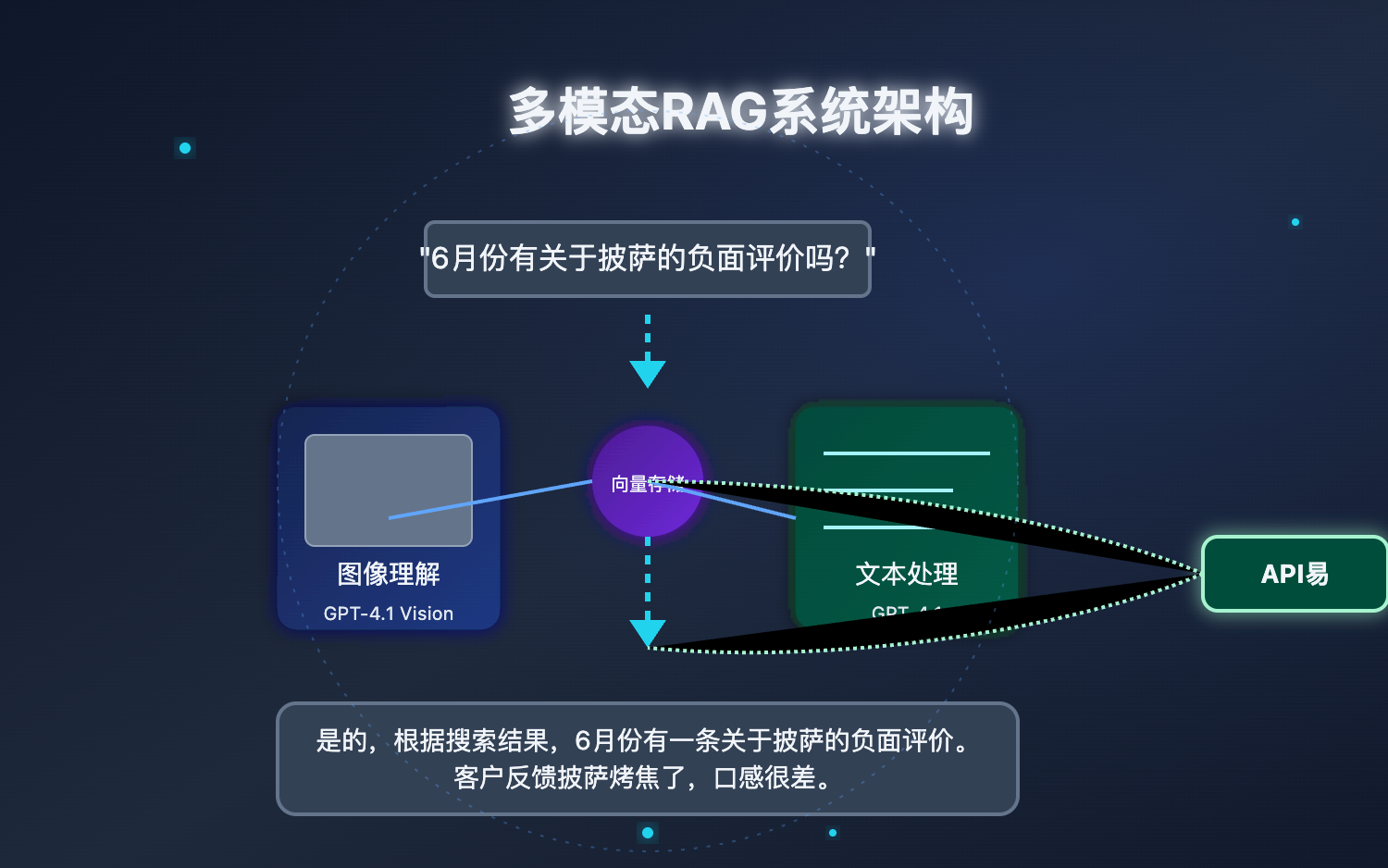
OpenAI多模态RAG系统工作原理
多模态RAG的核心组件
多模态RAG系统主要由以下几个关键组件构成:
- 图像理解模块:使用OpenAI的Vision API(GPT-4.1)对图像内容进行理解和分析
- 文本处理模块:处理各种文本输入,包括用户查询和文档文本
- 向量存储系统:存储文本和图像的语义表示(embeddings)
- 检索引擎:根据用户查询找到最相关的信息
- 生成模块:基于检索到的信息生成最终回答
这些组件共同工作,使系统能够理解和处理包含图像和文本的复杂数据。
多模态RAG的工作流程
一个典型的多模态RAG系统工作流程如下:
- 数据准备:收集并处理包含图像和文本的数据
- 图像分析:使用Vision模型分析图像内容并生成描述
- 向量化:将图像描述和文本内容转换为向量表示
- 存储索引:将向量和原始数据存入向量数据库
- 用户查询处理:将用户问题转换为向量进行检索
- 知识检索:从向量数据库中找出最相关的信息
- 生成回答:结合检索到的知识生成最终回答
这一过程使得系统能够基于对图像和文本的综合理解,为用户提供更全面、更准确的回答。

OpenAI多模态RAG系统实战应用
客户体验分析案例
OpenAI的教程展示了一个餐饮配送服务的客户体验分析案例。在这个案例中,系统需要处理的数据包括:
- 客户的文字评价
- 客户拍摄的食物照片
- 订单信息(时间、餐厅等)
系统能够回答诸如"6月份有关于披萨的负面评价吗?披萨是否烤焦了?"这样的复杂查询,通过同时分析文字评论和食物照片来提供准确答案。
实现步骤详解
让我们一步步解析如何实现这样的系统:
1. 数据准备
首先,你需要准备包含图像和文本的数据集。在教程中,使用了合成数据,包括:
- 生成的食物图像
- 文字评论
- 相关元数据(日期、评分等)
这些数据可以通过OpenAI的图像生成API和文本生成API创建,也可以使用真实的业务数据。
2. 图像理解
对于每张图像,使用GPT-4.1的Vision能力进行分析,生成图像描述和情感分析:
def analyze_image_sentiment(image_path: str) -> str:
"""分析食物配送图像并返回情感分析结果"""
base64_image = encode_image(image_path)
response = client.responses.create(
model="gpt-4.1",
input=[{
"role": "user",
"content": [
{
"type": "input_text",
"text": "分析这张食物配送图像。用一行简要描述图像内容和情感(正面/负面)。"
},
{
"type": "input_image",
"image_url": f"data:image/jpeg;base64,{base64_image}",
},
],
}],
max_output_tokens=50,
temperature=0.2
)
return response.output_text.strip()
3. 向量存储构建
使用OpenAI的Vector Store API创建向量存储并上传数据:
# 创建向量存储
text_image_vector_store = client.vector_stores.create(
name="food_delivery_reviews_text_image",
metadata={"purpose": "text_image_understanding"}
)
# 上传数据到向量存储
for i, row in df.iterrows():
# 准备文件内容(包含图像分析结果)
file_content = row['full_sentiment'] # 文本+图像分析结果
# 设置文件元数据(用于过滤)
file_metadata = {
"month": row['month'],
"sentiment": row['label'],
"has_image": not pd.isna(row['image_path'])
}
# 上传文件到向量存储
file = client.files.create(
content=file_content,
purpose="vector_search",
metadata=file_metadata
)
# 将文件添加到向量存储
client.vector_stores.file_batches.create(
vector_store_id=text_image_vector_store_id,
file_ids=[file.id]
)
4. 查询和检索
使用Responses API结合file_search工具进行查询:
query = "6月份有关于披萨的负面评价吗?披萨是否烤焦了?"
response = client.responses.create(
model="gpt-4.1",
input=query,
tools=[{
"type": "file_search",
"vector_store_ids": [text_image_vector_store_id],
"filters": {
"type": "eq",
"key": "month",
"value": "june"
}
}]
)
print(response.output_text)
5. 性能评估
最后,可以使用OpenAI的Evaluation API评估系统性能:
# 创建评估对象
eval_obj = client.evals.create(
name="food-categorization-eval",
testing_criteria=[
{
"type": "string_check",
"name": "匹配输出和人工标签",
"input": "{{sample.output_text}}",
"reference": "{{item.ground_truth}}",
"operation": "eq"
}
]
)
# 运行评估
evaluation_data = prepare_evaluation_data(df)
run_id = create_eval_run(evaluation_data, eval_obj.id)
# 分析结果
run_output_items = client.evals.runs.output_items.list(
eval_id=eval_obj.id,
run_id=run_id
)
通过API易实现多模态RAG系统
1. 模型选择
模型服务介绍
API易,行业领先的API中转站,均为官方源头转发,价格略有优势,聚合各种优秀大模型,使用起来很方便。
企业级专业稳定的OpenAI o3/Claude 3.7/Deepseek R1/Gemini 等全模型官方同源接口的中转分发。不限速,不过期,不惧封号,按量计费,长期可靠服务;让技术助力科研、公益事业!
当前模型推荐(均为稳定供给)
在构建多模态RAG系统时,以下是我们推荐的模型选择:
-
多模态理解模型
gpt-4.1:OpenAI最新多模态模型,支持图像理解和Vector Store检索(推荐指数:⭐⭐⭐⭐⭐)gpt-4o:支持图像理解的强大模型claude-3-7-sonnet-20250219:Claude最新模型,图像理解能力出色gemini-2.5-pro-preview-05-06:谷歌最新Pro模型,多模态能力强劲
-
图像生成模型(用于合成测试数据)
gpt-image-1:OpenAI官方图像生成模型sora-image:适合生成高质量图像midjourney-turbo:快速生成多样化图像
-
向量嵌入模型
text-embedding-3-large:高质量文本嵌入模型text-embedding-3-small:经济型文本嵌入模型
场景推荐
-
客户反馈分析场景
- 首选:
gpt-4.1(图像理解与文本分析能力均强) - 备选:
claude-3-7-sonnet-20250219(细节识别能力强) - 经济型:
gpt-4o(性价比高,适合大规模处理)
- 首选:
-
产品缺陷检测场景
- 首选:
gpt-4.1(对产品缺陷识别准确) - 备选:
gemini-2.5-pro-preview-05-06(对特定产品类别有优势) - 经济型:
claude-3-5-sonnet-20241022(基本缺陷识别能力好)
- 首选:
-
内容审核场景
- 首选:
gpt-4.1(全面的内容理解能力) - 备选:
claude-3-7-sonnet-20250219(对敏感内容识别准确) - 经济型:
o4-mini(速度快,适合初步筛选)
- 首选:
注意:具体价格请参考 API易价格页面
API易接入多模态RAG系统的优势
通过API易平台接入OpenAI的多模态RAG能力,你可以获得以下优势:
-
稳定可靠的API服务
- 多节点部署,API调用稳定可靠
- 无需担心区域限制或访问不稳定问题
- 高并发支持,适合生产环境部署
-
多模型灵活切换
- 同一接口支持多种模型,便于测试比较
- 可根据不同场景选择最适合的模型
- 新模型上线快速支持,紧跟技术前沿
-
成本优化
- 合理的价格策略,性价比更高
- 按量计费,无需大额预付
- 免费测试额度,降低尝试成本
-
简化的开发体验
- 与OpenAI API完全兼容,无需修改代码
- 完善的文档和示例,加速开发
- 技术支持响应迅速,解决问题更高效
实战示例:通过API易实现图像理解RAG
下面是通过API易实现图像理解RAG系统的简化代码示例:
图像理解部分
import base64
import requests
# 设置API易密钥和基础URL
APIYI_API_KEY = "你的API易API密钥"
APIYI_API_BASE = "https://vip.apiyi.com/v1"
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def analyze_image_with_apiyi(image_path):
base64_image = encode_image(image_path)
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {APIYI_API_KEY}"
}
payload = {
"model": "gpt-4.1",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "分析这张图片,描述内容并给出情感(积极/消极)。"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
]
}
response = requests.post(
f"{APIYI_API_BASE}/chat/completions",
headers=headers,
json=payload
)
return response.json()['choices'][0]['message']['content']
向量存储和检索部分
# 创建向量存储
def create_vector_store():
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {APIYI_API_KEY}"
}
payload = {
"name": "customer_feedback_store",
"metadata": {
"purpose": "multimodal_rag"
}
}
response = requests.post(
f"{APIYI_API_BASE}/vector_stores",
headers=headers,
json=payload
)
return response.json()['id']
# 上传文件到向量存储
def upload_to_vector_store(vector_store_id, content, metadata):
# 第一步:创建文件
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {APIYI_API_KEY}"
}
file_payload = {
"purpose": "vector_search",
"content": content,
"metadata": metadata
}
file_response = requests.post(
f"{APIYI_API_BASE}/files",
headers=headers,
json=file_payload
)
file_id = file_response.json()['id']
# 第二步:将文件添加到向量存储
batch_payload = {
"file_ids": [file_id]
}
batch_response = requests.post(
f"{APIYI_API_BASE}/vector_stores/{vector_store_id}/file_batches",
headers=headers,
json=batch_payload
)
return batch_response.json()
# 执行查询
def query_vector_store(vector_store_id, query, filters=None):
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {APIYI_API_KEY}"
}
tools = [{
"type": "file_search",
"vector_store_ids": [vector_store_id]
}]
if filters:
tools[0]["filters"] = filters
payload = {
"model": "gpt-4.1",
"messages": [
{"role": "user", "content": query}
],
"tools": tools
}
response = requests.post(
f"{APIYI_API_BASE}/chat/completions",
headers=headers,
json=payload
)
return response.json()['choices'][0]['message']['content']
应用场景扩展
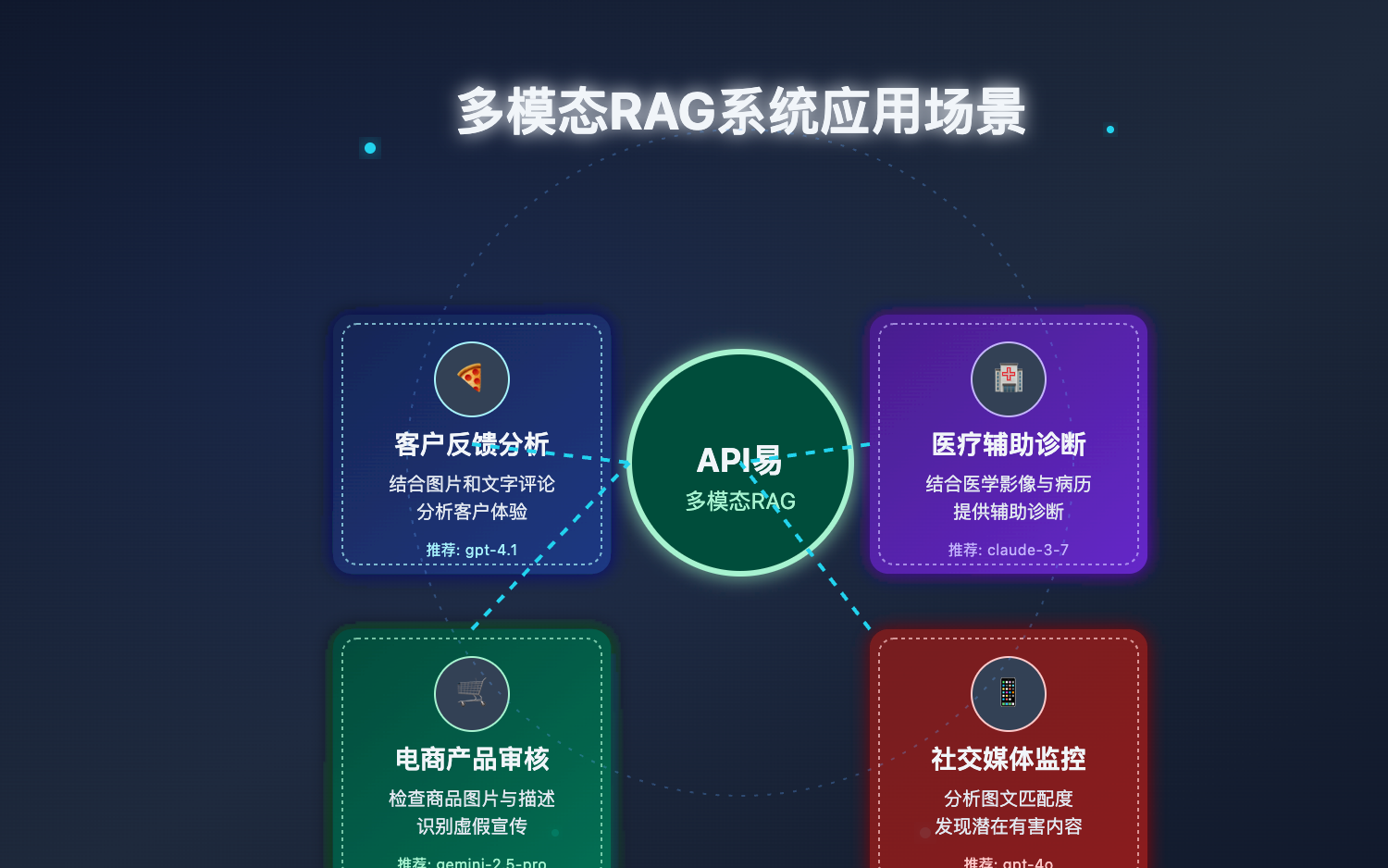
除了教程中的餐饮配送评价分析,多模态RAG系统还可以应用在多种场景:
- 电商产品审核:分析商品图片和描述是否一致,发现虚假宣传
- 医疗辅助诊断:结合医学影像和病历记录进行辅助诊断
- 社交媒体监控:识别图文不一致的内容或潜在有害信息
- 智能客服:理解客户上传的产品照片并提供相应帮助
- 教育内容分析:评估教材中图片和文字的教学效果
这些场景都可以通过API易平台轻松实现,既保持了OpenAI原生API的全部功能,又获得了更高的稳定性和成本效益。
多模态RAG系统常见问题
如何处理大量图像数据?
处理大量图像数据时,建议:
- 采用批处理方式分析图像
- 使用图像压缩减小文件大小
- 考虑使用更经济的模型进行初步筛选
- 设置合理的重试和错误处理机制
如何提高图像理解准确性?
提高图像理解准确性的方法:
- 使用高质量、清晰的图像
- 设计更具体的分析提示词
- 针对特定领域进行提示词工程
- 结合多种模型的结果进行交叉验证
向量存储如何设计更高效?
高效向量存储设计建议:
- 合理设置元数据,便于精确过滤
- 定期更新和优化向量数据
- 根据应用需求选择适当的嵌入模型
- 为频繁查询的内容建立缓存机制
成本如何控制?
控制成本的策略:
- 使用API易平台获得更优惠的价格
- 根据任务复杂度选择合适的模型
- 优化提示词减少token消耗
- 实施缓存机制避免重复处理
- 设置合理的使用配额和监控
为什么选择「API易」实现多模态RAG系统
对于想要构建多模态RAG系统的开发者和企业,API易平台提供了以下独特优势:
-
全面的技术支持
- 支持OpenAI全系列多模态模型
- 支持Vector Store API完整功能
- 提供技术咨询和最佳实践指导
-
稳定的服务保障
- 多节点全球部署,确保API调用稳定性
- 99.9%服务可用性保证
- 专业的技术团队24/7监控服务状态
-
更优的经济效益
- 相比直接使用OpenAI API更具成本优势
- 灵活的计费模式,适应不同规模的应用
- 新用户免费体验额度,降低尝试门槛
-
无缝的开发体验
- 与OpenAI API完全兼容,无需修改现有代码
- 详细的开发文档和示例代码
- 快速响应的技术支持
提示:构建多模态RAG系统时,通过API易平台可以:
- 更稳定地访问OpenAI的多模态能力和Vector Store功能
- 灵活切换不同模型,找到最适合特定应用场景的选择
- 降低开发和运营成本,提高投资回报率
- 获得专业技术支持,加速应用开发和部署
总结
多模态RAG系统代表了AI应用的未来发展方向,它能够同时理解和处理图像和文本数据,为各行各业带来全新的可能性。OpenAI提供的图像理解RAG教程展示了这一技术的强大潜力,而通过API易平台,你可以更轻松、更经济地将这一技术应用到实际业务中。
无论是分析客户反馈、辅助医疗诊断,还是内容审核,多模态RAG系统都能显著提升信息处理的准确性和全面性。随着大模型技术的不断进步,这一领域还将涌现更多创新应用。
现在就通过API易平台,开始探索多模态RAG系统的无限可能吧!
欢迎免费试用 API易,3 分钟跑通 API 调用 www.apiyi.com
支持OpenAI多模态模型和Vector Store API,让智能应用开发更简单高效
加站长个人微信:8765058,发送你《大模型使用指南》等资料包,并加赠 1 美金额度。

本文作者:API易团队
欢迎关注我们的更新,持续分享 AI 开发经验和最新动态。