著者注:Qwen-Image-2.0 統合画像生成・編集モデルの5大核心的進歩を深掘り解説。7Bの軽量アーキテクチャ、ネイティブ2K解像度、1000トークンの長文プロンプトなどの技術的ハイライトに加え、API連携と実践的な活用ガイドを紹介します。
アリババの通義(Tongyi)チームは2026年2月10日、画像生成と画像編集を単一モデルに統合した重大なアップグレード版、Qwen-Image-2.0をリリースしました。驚くべきことに、パラメータ数を前世代の20Bから7Bへと大幅に削減しながらも、全体的な性能向上を実現しています。APIYIは現在、Alibaba Cloudの認定パートナーとして連携を進めており、より迅速なリリースと価格面でのメリットを提供できる見込みです。
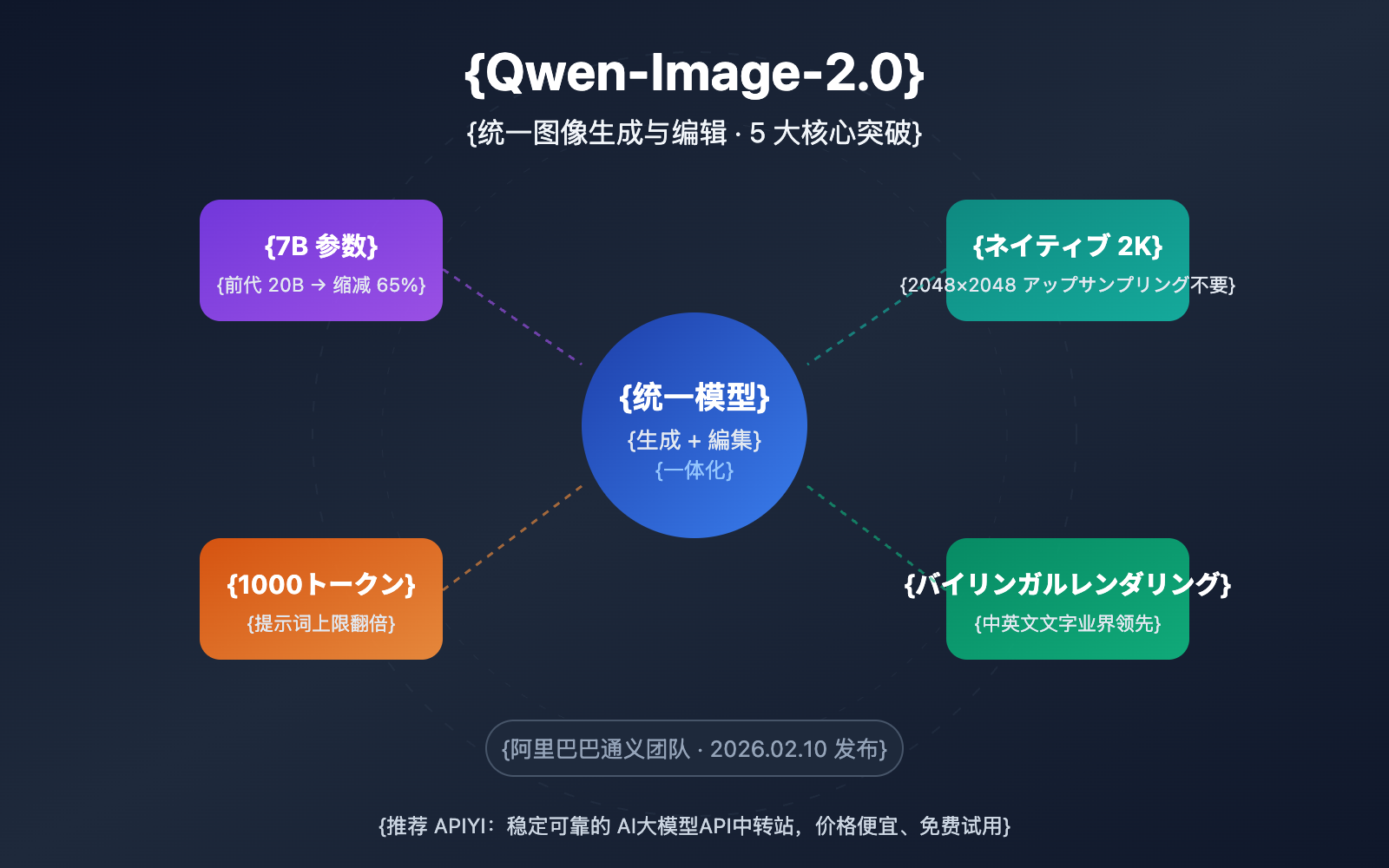
核心的価値: 本記事の深掘り解説を通じて、Qwen-Image-2.0の5大核心的進歩、競合製品との真の違い、そしてAPIを通じて迅速に導入・活用する方法を理解いただけます。
Qwen-Image-2.0 核心要点速覧
| 要点 | 説明 | 価値 |
|---|---|---|
| 生成と編集の統合 | 文生図(Text-to-Image)と画像編集を単一の7Bモデルに統合 | 2つのモデルを個別にロードする必要がなく、デプロイコストを大幅に削減 |
| パラメータ数を65%削減 | 前世代の20Bから7B(拡散デコーダー)へ精簡 | 推論速度が向上し、ビデオメモリ(VRAM)要件が顕著に低下 |
| ネイティブ2K解像度 | 最大2048×2048のネイティブ出力をサポート | アップサンプリング不要で、ディテールの鮮明度が向上 |
| 1000トークンのプロンプト | プロンプトの上限が倍増(前世代は約500トークン) | より複雑なシーン描写と精密なコントロールが可能に |
| 二言語テキストレンダリング | 中国語・英語の文字生成で業界をリード | ポスターやインフォグラフィックなど、文字を含むシーンで高い効果を発揮 |
Qwen-Image-2.0 核心技術解析
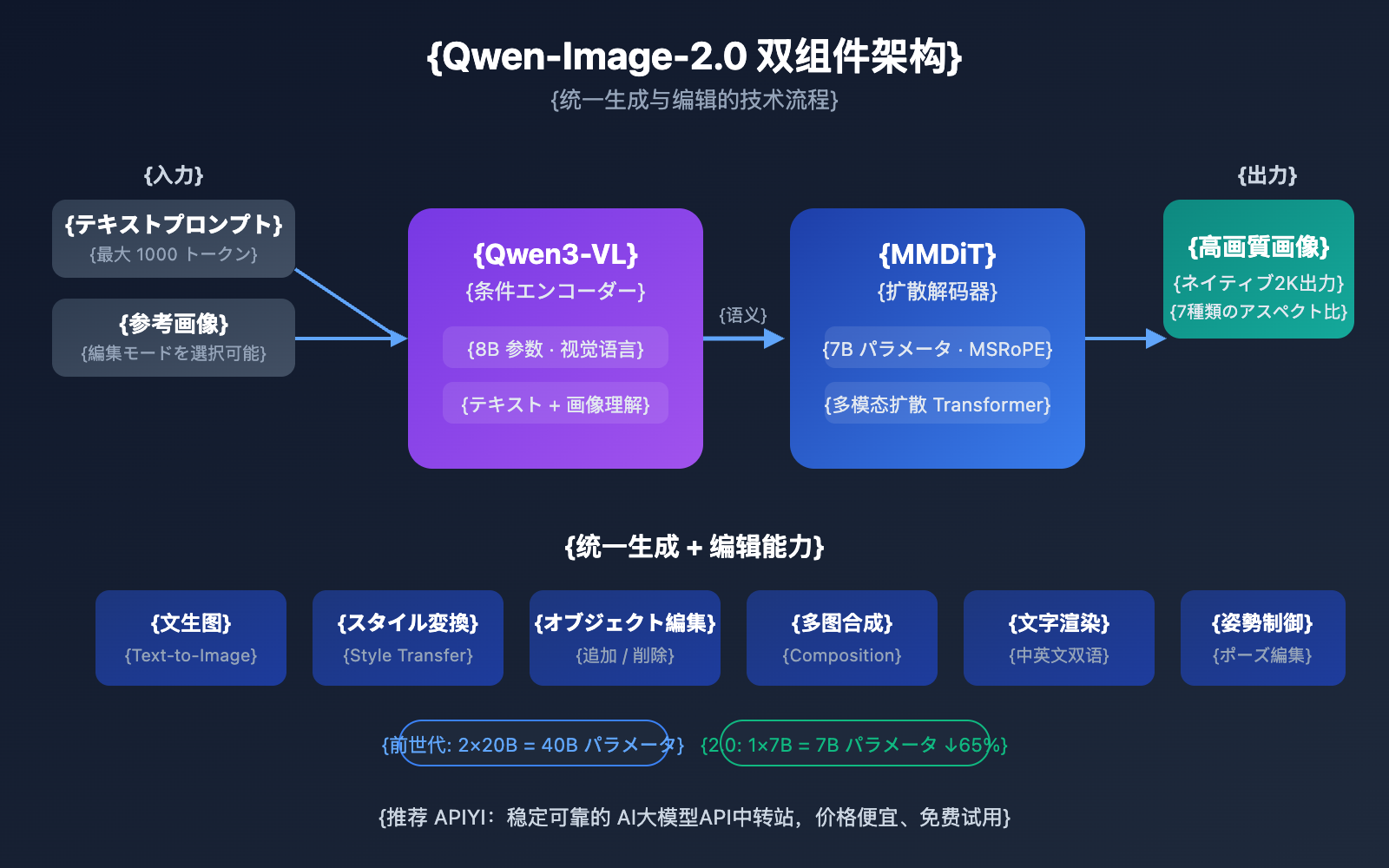
Qwen-Image-2.0は、全く新しいデュアルコンポーネントアーキテクチャを採用しています。8BパラメータのQwen3-VL(視覚言語モデル)を条件エンコーダーとして、7BパラメータのMMDiT(マルチモーダル拡散Transformer)を拡散デコーダーとして使用しています。この設計により、モデルはテキストと画像の2つのモダリティのセマンティック情報を深く理解し、拡散プロセスを通じて高品質な画像を生成することができます。
前世代のQwen-Image-2512との最大の違いは、統合トレーニング戦略にあります。文生図(T2I)と画像編集(I2I/TI2I)が単一の順伝播プロセスに統合されました。これは、以前はQwen-Image(生成)とQwen-Image-Edit(編集)という2つの独立したモデルが必要だったタスクを、1つのモデルで完結できることを意味し、デプロイのコストと複雑さが大幅に軽減されました。
Qwen-Image-2.0 5つの核心的ブレイクスルー詳解
ブレイクスルー1:生成と編集の統合アーキテクチャ
これは Qwen-Image-2.0 の最も象徴的なイノベーションです。前世代ではテキストからの画像生成モデルと画像編集モデルを個別に維持する必要がありましたが、2.0 バージョンではこの2つが1つに統合されました。
| 機能 | 前世代のソリューション | Qwen-Image-2.0 |
|---|---|---|
| テキストから画像生成 | Qwen-Image-2512(20B) | 統合モデル(7B) |
| 画像編集 | Qwen-Image-Edit-2511(20B) | 統合モデル(7B) |
| スタイル変換 | 編集モデルで個別対応 | 統合モデルで直接サポート |
| 複数画像の合成 | 編集モデルで個別対応 | 統合モデルで直接サポート |
| モデルの総ビデオメモリ | 20Bモデルを2つロードする必要あり | 7Bモデル1つのみでOK |
実際の使用シーンでは、まずテキストで画像を生成し、その後モデルを切り替えることなく、同じ画像に対してスタイル変換、オブジェクトの追加・削除、ポーズ調整などの編集操作を直接行うことができます。
ブレイクスルー2:7B パラメータによる性能の逆転
パラメータ数を 20B から 7B(拡散デコーダー)へと 65% 削減しながらも、画質は低下するどころか向上しています。この背景にある鍵は、Qwen3-VL エンコーダーの深い意味理解能力です。8B パラメータの視覚言語モデルが「ニーズの理解」という工程でより多くの役割を担うことで、拡散デコーダーがより効率的に「画像の生成」に集中できるようになりました。
開発者にとって、これは以下のメリットを意味します:
- 推論速度の向上: API 呼び出しは約 5〜8 秒/枚
- ビデオメモリ(VRAM)要件の低下: 24GB の VRAM で実行可能と予測(前世代は 48GB 以上が必要でした)
- デプロイコストの削減: シングルカードのコンシューマー向け GPU での動作が期待できます
ブレイクスルー3:ネイティブ 2K 高解像度
Qwen-Image-2.0 は、追加の超解像アップサンプリング・ステップを必要とせず、2048×2048 解像度の出力をネイティブにサポートしています。また、以下の 7 種類の標準アスペクト比に対応しています:
| アスペクト比 | 解像度 | 推奨シーン |
|---|---|---|
| 16:9 | 1664×928 | ビデオのサムネイル、ブログのアイキャッチ(デフォルト) |
| 1:1 | 1328×1328 | SNSのアイコン、製品のメイン画像 |
| 9:16 | 928×1664 | スマホの壁紙、ショート動画のカバー |
| 4:3 | 1472×1104 | 伝統的な横画面表示 |
| 3:4 | 1104×1472 | 伝統的な縦画面表示 |
| 3:2 | 1584×1056 | 写真スタイルの横長画像 |
| 2:3 | 1056×1584 | 写真スタイルの縦長画像 |
ブレイクスルー4:1000 トークンの長文プロンプト
プロンプトの上限が前世代の約 500 トークンから 1000 トークンへと引き上げられました。倍増したこのスペースにより、より複雑なシーンを記述できるようになります。実際のテストでは、特に以下のシーンで大きな価値を発揮します:
- 専門的なインフォグラフィック: レイアウト位置、テキスト内容、色の組み合わせを正確に制御
- 複数主体のシーン: 複数のオブジェクトの位置関係や相互作用の詳細を同時に記述
- スタイルの融合: 期待する芸術的スタイルや質感の要求を細かく描写
ブレイクスルー5:バイリンガル・テキストレンダリングのリード
Qwen-Image-2.0 は画像内の文字生成能力において業界をリードしており、特に中国語のレンダリングに強みを持っています。楷書、痩金体、小篆など、多様な書体スタイルをサポートしています。これにより、以下のようなシーンで明らかな優位性があります:
- マーケティングポスターや宣伝画像のデザイン
- 中国語の注釈を含む技術チャート
- SNS向けの画像・テキストコンテンツ
- ブランドのビジュアル素材生成
🎯 実用的なアドバイス: Qwen-Image-2.0 は現在、API の招待テスト段階にあります。APIYI(apiyi.com)では積極的に導入を進めており、準備が整い次第、公式サイトより 20% 以上お得な価格で提供予定です。OpenAI 互換フォーマットでの統一呼び出しにも対応します。ご期待ください。
Qwen-Image-2.0 クイックスタート
シンプルな実装例
以下は、API を介して Qwen-Image-2.0 で画像を生成する基本的な方法です(DashScope API フォーマットに基づいています):
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen-image-2.0",
messages=[{
"role": "user",
"content": "サングラスをかけた柴犬が砂浜でサーフィンをしている、晴天、高画質な写真スタイル"
}]
)
print(response.choices[0].message.content)
DashScope ネイティブ API の呼び出し例を表示
from dashscope import MultiModalConversation
import os
response = MultiModalConversation.call(
api_key=os.getenv("DASHSCOPE_API_KEY"),
model="qwen-image-max",
messages=[{
"role": "user",
"content": [{
"text": "モダンでシンプルなデスク、机の上にはノートPCと観葉植物、柔らかい自然光"
}]
}],
size="1328*1328",
prompt_extend=True,
watermark=False
)
image_url = response.output.choices[0].message.content[0]["image"]
print(f"画像URL: {image_url}")
# 注意: URLの有効期限は24時間です。お早めにダウンロードして保存してください。
ヒント: APIYI(apiyi.com)は Qwen-Image-2.0 への対応を進めています。対応後は OpenAI 互換フォーマットでの呼び出しが可能になり、1つの API Key で GPT Image 1.5、Gemini 3 Pro Image、FLUX.2 など複数の画像生成モデルを比較テストできるようになります。
Qwen-Image-2.0 と競合モデルの比較

| 比較項目 | Qwen-Image-2.0 | GPT Image 1.5 | Gemini 3 Pro Image | FLUX.2 Max |
|---|---|---|---|---|
| 開発元 | Alibaba | OpenAI | Black Forest Labs | |
| 統合生成・編集 | ✅ | ✅ | ✅ | ❌ |
| 最大解像度 | 2K | 2K+ | 2K | 2K |
| 中国語テキスト描画 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ |
| 推論速度 | 5-8 秒 | 10-15 秒 | 5-10 秒 | 10-20 秒 |
| オープンソース・エコシステム | 前世代は公開済み | クローズド | クローズド | 一部公開 |
| API価格(参考) | 公式の20%オフ以下(APIYI) | $0.04-0.08/枚 | トークン課金 | $0.04/枚 |
Qwen-Image-2.0 の差別化ポイント:
- 中国語環境に最強: バイリンガルテキスト描画能力が業界をリードしており、中国語のポスターやインフォグラフィックの効果は競合他社を圧倒しています。
- 最も軽量なアーキテクチャ: 7B(70億)パラメータで GPT Image 1.5 と同レベルの品質を実現し、推論コストを大幅に抑えています。
- オープンソースの可能性: 前世代の全シリーズが Apache-2.0 でオープンソース化されており、2.0 バージョンの公開も期待されています。
- 豊富なエコシステム: HuggingFace で 2,380 以上の「いいね」を獲得し、484 以上の LoRA アダプターが存在するなど、コミュニティが非常に活発です。
比較に関する注記: 上記のデータは公開されている技術文書および AI Arena ランキングに基づいています。実際の利用シーンにおける各モデルのパフォーマンスについては、APIYI (apiyi.com) プラットフォームでのテストをお勧めします。
Qwen-Image-2.0 おすすめの活用シーン
Qwen-Image-2.0 は、以下のようなシーンでの利用に最適です。
- ECサイトの商品画像: 統一されたモデルで商品画像の生成から背景の差し替えまで完結でき、ワークフローを大幅に簡略化します。EC運営やデザインチームに最適です。
- マーケティング素材のデザイン: ポスター、SNS投稿用画像、広告素材など、強力な中国語テキストのレンダリング機能が最大の強みとなります。マーケティングチームに最適です。
- クリエイティブデザイン: 写実、アニメ、水彩、手描きなど、多彩なアートスタイルに対応しています。1,000トークンの長文プロンプトにより、クリエイティブの方向性を精密にコントロール可能です。デザイナーやコンテンツクリエイターに最適です。
- 技術図表の生成: PPTスライド、インフォグラフィック、フローチャートなどの専門的なコンテンツを、ピクセル単位の正確なレイアウトで作成できます。テクニカルドキュメント作成チームに最適です。
🎯 ユースケースのアドバイス: 中国語を含む画像・テキストコンテンツの生成が業務で多い場合、Qwen-Image-2.0 は現在最も注目すべき選択肢です。APIYI (apiyi.com) プラットフォームを通じて実際の比較テストを行い、お客様のビジネスに最適なソリューションを見つけることをお勧めします。
Qwen-Image-2.0 バージョンの進化と料金
バージョン進化のタイムライン
Qwen-Image シリーズは、2025年8月の初版リリース以来、高頻度なアップデートを継続しています。
| バージョン | 時期 | 主なアップデート内容 |
|---|---|---|
| Qwen-Image v1 | 2025.08 | 初の 20B MMDiT モデル、Apache-2.0 ライセンスでオープンソース化 |
| Qwen-Image-Edit | 2025.08 | 専用の編集モデルを追加 |
| Qwen-Image-2512 | 2025.12 | 写実的なテクスチャとテキストレンダリングを強化 |
| Qwen-Image-2.0 | 2026.02 | アーキテクチャの統一、7B への軽量化、ネイティブ 2K 解像度 |
料金プランの参考
| チャネル | モデル | 参考価格 |
|---|---|---|
| Alibaba Cloud DashScope | qwen-image-max | 0.50元/枚 |
| Alibaba Cloud DashScope | qwen-image-plus | 0.20元/枚 |
| Replicate | Qwen Image | $0.030/枚 |
| Fal.ai | Qwen Image Edit | $0.021/枚 |
| APIYI (近日公開予定) | Qwen-Image-2.0 | 公式価格の20%OFF以下 |
💡 Qwen-Image-2.0 正式版の価格はまだ発表されていません。APIYI (apiyi.com) では現在導入準備を進めており、公式価格より20%以上お得な優待価格で提供する予定です。新規登録で無料テスト枠も進呈いたしますので、ぜひご期待ください。
よくある質問
Q1: Qwen-Image-2.0 と Qwen-Image-2512 の違いは何ですか?
最大の違いは、2.0 バージョンが生成と編集を1つの 7B パラメータモデルに統合している点です。一方、前世代の 2512 は純粋な画像生成(Text-to-Image)のための 20B モデルであり、画像編集には別途 Qwen-Image-Edit を読み込む必要がありました。また、2.0 バージョンはネイティブで 2K 解像度と 1000 トークンの長いプロンプトに対応しており、画質やテキストレンダリングの面でも大幅に向上しています。
Q2: Qwen-Image-2.0 は現在 API で利用できますか?
現在は API の招待制テスト段階にあり、chat.qwen.ai で無料のオンライン体験が可能です。APIYI(apiyi.com)でも現在導入を進めており、リリース後は公式サイトの 2 割引き以下の価格で提供される予定です。OpenAI 互換形式での呼び出しに対応し、1 つの API キーで複数の画像生成モデルを比較できるようになります。
Q3: Qwen-Image-2.0 はローカル環境でのデプロイに適していますか?
Qwen-Image-2.0 の重み(ウェイト)は現在まだオープンソース化されていません。しかし、前世代の全シリーズが Apache-2.0 でオープンソース化された実績があるため、コミュニティでは 2.0 バージョンもオープンソース化されることが広く期待されています。7B というパラメータ量は、コンシューマー向け GPU(ビデオメモリ 24GB)での動作が期待できるサイズです。オープンソース化を待つ間は、まず APIYI(apiyi.com)を通じて API 形式で効果を素早く検証することをお勧めします。
まとめ
Qwen-Image-2.0 の核心となるポイント:
- 統合アーキテクチャが最大のハイライト: 1 つの 7B モデルで生成と編集を完結。前世代は 2 つの 20B モデルが必要でした。
- 軽量化しつつ品質は維持: パラメータ数を 65% 削減しながらも、画質と機能範囲は全面的に向上しています。
- 中国語シーンにおいて不可欠: 二言語テキストレンダリング、マルチフォント対応など、中国語の画像・テキストコンテンツ生成における第一選択肢です。
- API 連携もまもなく開放: 現在招待制テスト中で、正式版のリリースが期待されます。
Qwen-Image-2.0 は、中国産 AI 画像生成モデルにおける重要なブレイクスルーを象徴しています。高品質な中国語の画像・テキストコンテンツを必要とするチームにとって、今最も注目すべきモデルの一つです。
最新の導入状況やお得な価格(公式サイトの 2 割引き以下)については、APIYI(apiyi.com)で確認することをお勧めします。プラットフォームでは無料枠やマルチモデル統一インターフェースを提供しており、迅速な比較検証が可能です。
📚 参考文献・リソース
-
Qwen 公式ブログ: Qwen-Image-2.0 リリースのお知らせ
- リンク:
qwen.ai/blog?id=qwen-image-2.0 - 説明: 公式による技術解説と機能紹介
- リンク:
-
GitHub リポジトリ: Qwen-Image プロジェクトページ
- リンク:
github.com/QwenLM/Qwen-Image - 説明: オープンソースコード、技術ドキュメント、使用ガイド
- リンク:
-
AI Arena リーダーボード: 画像生成および画像編集ランキング
- リンク:
arena.ai/leaderboard/text-to-image - 説明: 第三方機関による独立した評価ランキング、データはリアルタイムで更新
- リンク:
-
Alibaba Cloud API ドキュメント: DashScope 画像生成 API
- リンク:
help.aliyun.com/zh/model-studio/qwen-image-api - 説明: 公式 API 連携ドキュメントおよびパラメータ説明
- リンク:
著者: 技術チーム
技術交流: コメント欄でのディスカッションを歓迎します。詳細な資料は APIYI apiyi.com 技術コミュニティをご覧ください。