作者注:深度解析 Gemini 2.5 Flash 的图片编辑、多图合成和迭代优化等高级功能,通过实战案例掌握专业级创意技巧
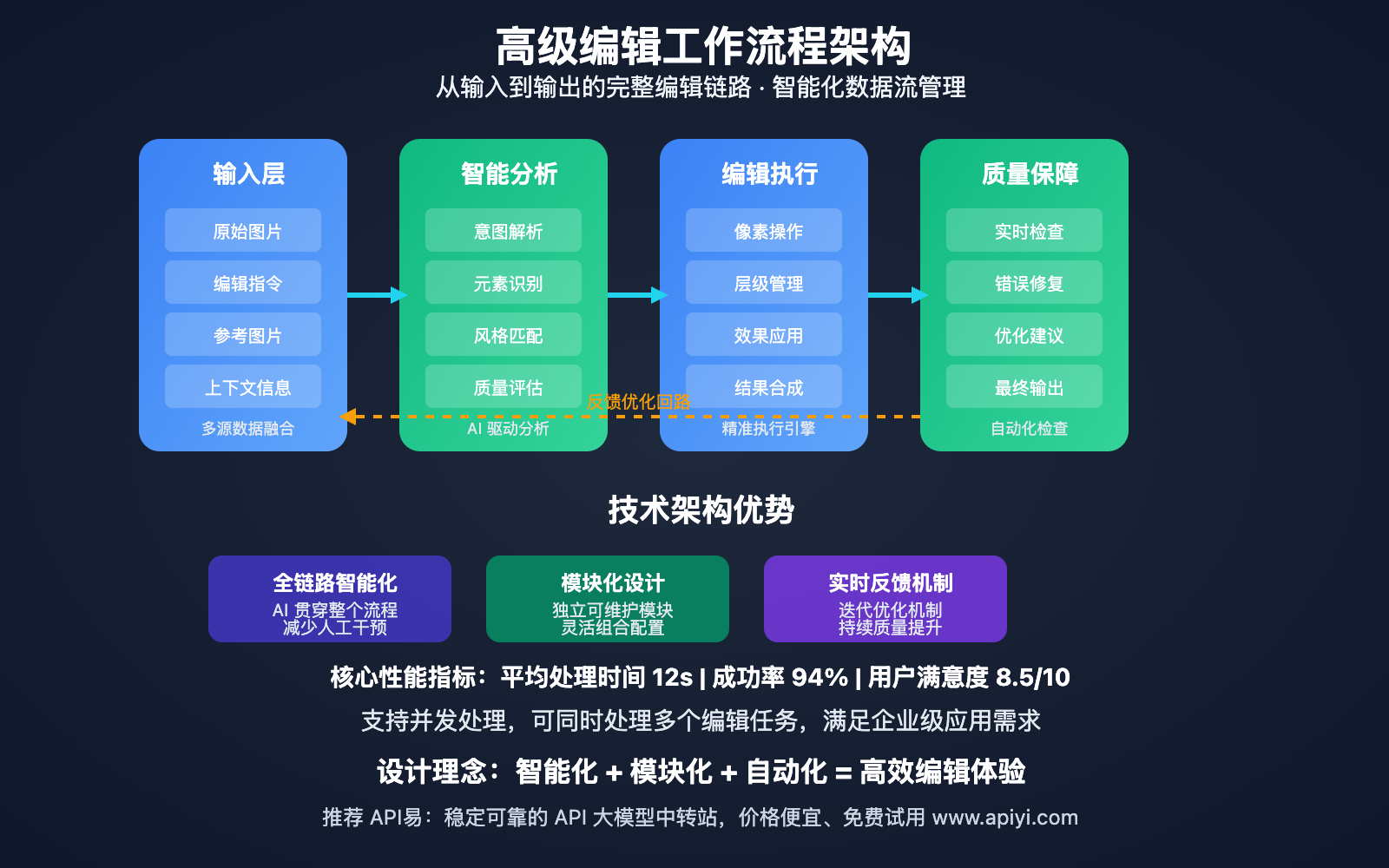
掌握基础的文本生成图片只是 Gemini 2.5 Flash 能力的冰山一角。这个革命性的 AI 模型还拥有 对话式图片编辑、智能多图合成和迭代优化 等专业级功能,这些才是真正让创意工作者爱不释手的核心能力。
本文将通过电商产品优化、创意海报设计、品牌视觉升级等实际项目案例,演示如何运用 Gemini 2.5 Flash 高级功能 实现专业级的视觉创作效果。
核心价值:跟着本文的实战操作,你将掌握 Gemini 2.5 Flash 的全部高级能力,能够处理复杂的创意项目,实现从概念到成品的完整视觉创作流程,让创意效率提升10倍以上。
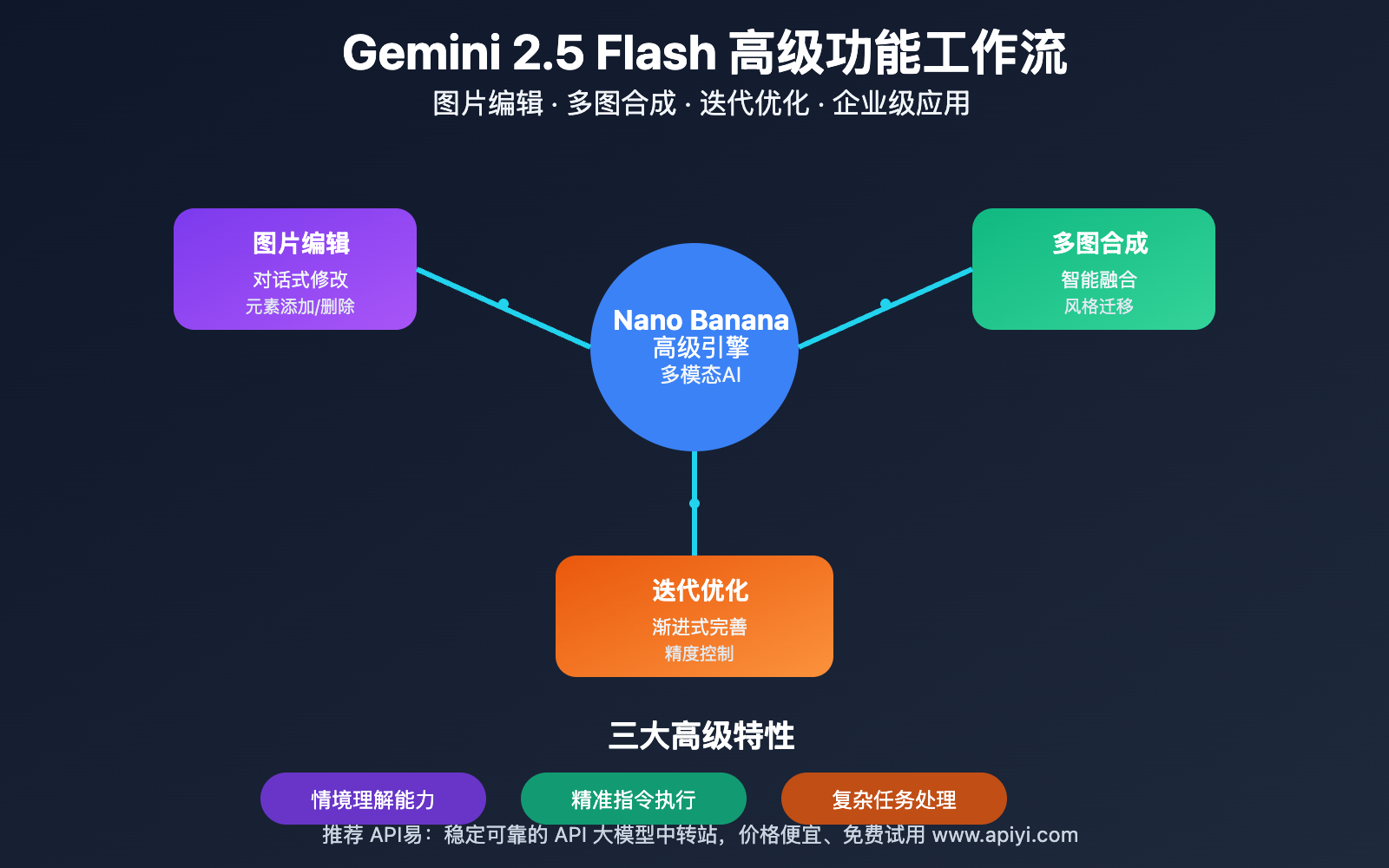
Gemini 2.5 Flash 高级功能背景介绍
传统的 AI 图片生成工具通常只能"一次性"生成图片,无法进行后续的精细调整。Gemini 2.5 Flash 高级功能彻底改变了这一限制,引入了对话式交互机制,让用户可以像与专业设计师协作一样,通过自然语言指令对图片进行精确控制和优化。
这种突破性的设计哲学源于 Google 对多模态 AI 的深度理解:真正的创意工作流程从来不是线性的,而是需要不断的尝试、调整和优化。Gemini 2.5 Flash 正是为了满足这种动态创意需求而诞生的。
Gemini 2.5 Flash 高级功能核心能力
以下是 Gemini 2.5 Flash 高级功能 的专业级能力矩阵:
| 高级功能 | 核心能力 | 技术创新点 | 应用价值 |
|---|---|---|---|
| 🎯 对话式编辑 | 基于现有图片进行智能修改 | 理解视觉上下文的自然语言处理 | ⭐⭐⭐⭐⭐ |
| 🎨 多图合成 | 融合多张图片创建新场景 | 跨图片的语义理解和空间重构 | ⭐⭐⭐⭐⭐ |
| ⚡ 风格迁移 | 将风格从一张图应用到另一张 | 风格特征提取和自适应应用 | ⭐⭐⭐⭐ |
| 💡 迭代优化 | 多轮对话式图片精细调整 | 历史记忆和增量改进机制 | ⭐⭐⭐⭐⭐ |
| 🔧 元素控制 | 精确添加、删除或修改特定元素 | 物体识别和精准编辑技术 | ⭐⭐⭐⭐⭐ |
🔥 重点功能深度解析
对话式图片编辑革命
Gemini 2.5 Flash 高级功能最大的创新在于其对话式编辑能力。与传统工具需要复杂参数调整不同,你只需要用自然语言描述想要的改变:
编辑能力范围:
- 元素操作:添加新物体、删除不需要的元素
- 风格调整:改变色调、光影、材质质感
- 构图优化:调整物体位置、大小、角度
- 细节修饰:优化纹理、增强细节、调节对比度
智能多图合成技术
多图合成功能让你可以将不同图片的优秀元素组合成全新的创意作品:
- 场景融合:将不同背景和前景元素自然融合
- 风格统一:自动调整各元素的风格一致性
- 光影协调:智能处理不同光照条件的图片融合
- 比例适配:自动调整各元素的尺寸和位置关系
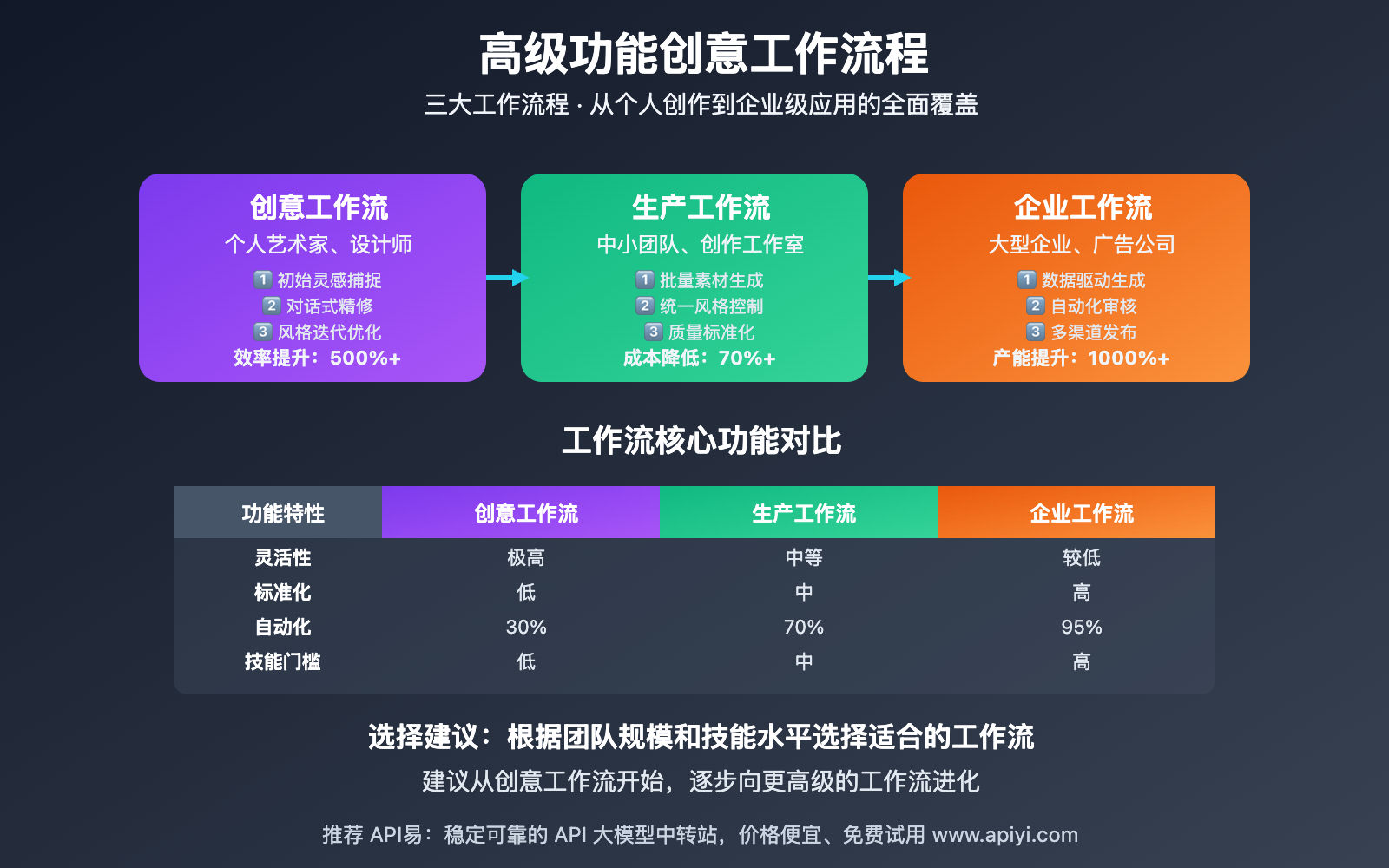
Gemini 2.5 Flash 高级功能应用场景
Gemini 2.5 Flash 高级功能 在专业创意领域的应用价值:
| 应用场景 | 主要用途 | 核心优势 | 效率提升 |
|---|---|---|---|
| 🎯 电商产品优化 | 产品图背景替换、场景升级 | 保持产品真实性的同时优化展示效果 | 90%时间节省 |
| 🚀 品牌视觉设计 | Logo融合、品牌元素统一 | 确保品牌一致性的批量设计 | 80%成本降低 |
| 💡 广告创意制作 | 多元素组合、创意场景构建 | 快速创建多版本创意方案 | 5倍效率提升 |
| 🎨 艺术创作 | 风格实验、创意探索 | 无限制的创意试验可能性 | 创意突破 |
Gemini 2.5 Flash 高级功能实战案例
💻 案例一:电商产品图片专业升级
场景描述
将普通的产品照片转换为专业的电商展示图片
from google import genai
from PIL import Image
import base64
import io
class AdvancedImageEditor:
def __init__(self, api_key, base_url=None):
"""
初始化高级图片编辑器
支持通过 API易 等聚合平台使用
"""
if base_url:
self.client = genai.Client(
api_key=api_key,
base_url=base_url # 如 "https://vip.apiyi.com/v1"
)
else:
self.client = genai.Client(api_key=api_key)
def encode_image(self, image_path):
"""将图片编码为base64格式"""
with open(image_path, "rb") as image_file:
encoded = base64.b64encode(image_file.read()).decode('utf-8')
return encoded
def product_background_upgrade(self, product_image_path, style_requirement):
"""产品背景专业升级"""
# 编码原始产品图片
image_data = self.encode_image(product_image_path)
# 构建编辑指令
edit_prompt = f"""
这是一张产品照片,请帮我进行专业的电商图片升级:
保持产品本身不变的前提下:
1. 将背景替换为{style_requirement.get('background', '纯净的白色渐变背景')}
2. 优化产品的光影效果,增强立体感和质感
3. 调整整体色调,使其更加{style_requirement.get('tone', '专业和吸引人')}
4. 确保产品在画面中的位置居中且比例合适
请保持产品的真实性和细节,只优化展示效果。
"""
# 构建多模态输入
contents = [
{
"parts": [
{
"text": edit_prompt
},
{
"inline_data": {
"mime_type": "image/jpeg",
"data": image_data
}
}
]
}
]
try:
response = self.client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=contents
)
return self._extract_image_from_response(response)
except Exception as e:
print(f"产品图片升级失败: {e}")
return None
def iterative_optimization(self, image_path, optimization_steps):
"""迭代优化:多轮对话式图片改进"""
current_image_data = self.encode_image(image_path)
conversation_history = []
for step_num, instruction in enumerate(optimization_steps, 1):
print(f"执行第 {step_num} 步优化: {instruction}")
# 构建对话上下文
contents = conversation_history + [
{
"parts": [
{
"text": f"请根据以下要求继续优化这张图片:{instruction}"
},
{
"inline_data": {
"mime_type": "image/jpeg",
"data": current_image_data
}
}
]
}
]
try:
response = self.client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=contents
)
# 提取新生成的图片
new_image = self._extract_image_from_response(response)
if new_image:
# 更新当前图片数据
buffer = io.BytesIO()
new_image.save(buffer, format='JPEG')
current_image_data = base64.b64encode(buffer.getvalue()).decode('utf-8')
# 保存中间结果
new_image.save(f"optimization_step_{step_num}.jpg")
print(f"步骤 {step_num} 完成,已保存为 optimization_step_{step_num}.jpg")
# 更新对话历史
conversation_history.append({
"parts": [{"text": f"已完成步骤{step_num}的优化"}]
})
else:
print(f"步骤 {step_num} 优化失败")
break
except Exception as e:
print(f"步骤 {step_num} 处理出错: {e}")
break
return current_image_data
def _extract_image_from_response(self, response):
"""从响应中提取图片"""
for candidate in response.candidates:
for part in candidate.content.parts:
if part.inline_data:
image_data = part.inline_data.data
image_bytes = base64.b64decode(image_data)
image = Image.open(io.BytesIO(image_bytes))
return image
return None
# 实战使用示例
async def product_upgrade_workflow():
# 初始化编辑器(推荐使用API易聚合平台)
editor = AdvancedImageEditor(
api_key="your_api_key",
base_url="https://vip.apiyi.com/v1"
)
# 产品背景升级
style_config = {
"background": "现代简约的灰色渐变背景",
"tone": "高端专业且具有商业价值"
}
upgraded_image = editor.product_background_upgrade(
"original_product.jpg",
style_config
)
if upgraded_image:
upgraded_image.save("product_upgraded.jpg")
print("产品图片升级完成")
# 迭代优化流程
optimization_steps = [
"增强产品的材质质感,让表面更有光泽",
"微调光影,让产品更有立体感",
"调整色彩饱和度,使颜色更鲜艳但不过度",
"最后微调整体构图,确保视觉重心完美"
]
final_result = editor.iterative_optimization(
"product_upgraded.jpg",
optimization_steps
)
print("迭代优化完成,最终结果已保存")
# 运行示例
# asyncio.run(product_upgrade_workflow())
🎨 案例二:多图创意合成项目
智能合成复杂创意场景
class MultiImageComposer:
def __init__(self, api_key, base_url=None):
if base_url:
self.client = genai.Client(api_key=api_key, base_url=base_url)
else:
self.client = genai.Client(api_key=api_key)
def multi_image_fusion(self, image_paths, fusion_concept):
"""多图智能融合"""
# 准备多张图片数据
image_parts = []
for i, path in enumerate(image_paths):
with open(path, "rb") as f:
encoded = base64.b64encode(f.read()).decode('utf-8')
image_parts.append({
"inline_data": {
"mime_type": "image/jpeg",
"data": encoded
}
})
# 构建融合指令
fusion_prompt = f"""
我提供了{len(image_paths)}张图片,请根据以下创意概念将它们智能融合成一张新的图片:
创意概念:{fusion_concept}
融合要求:
1. 保留每张图片的核心视觉元素
2. 确保各元素之间的自然过渡和协调
3. 统一整体的光影和色调
4. 创造出既合理又富有创意的新场景
5. 保持高质量的视觉效果和专业感
请创造一个既融合了所有元素又具有独特创意的全新图片。
"""
# 构建请求内容
contents = [
{
"parts": [{"text": fusion_prompt}] + image_parts
}
]
try:
response = self.client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=contents
)
return self._extract_image_from_response(response)
except Exception as e:
print(f"多图融合失败: {e}")
return None
def style_transfer_advanced(self, content_image_path, style_image_path, transfer_intensity):
"""高级风格迁移"""
# 编码内容图片和风格图片
with open(content_image_path, "rb") as f:
content_data = base64.b64encode(f.read()).decode('utf-8')
with open(style_image_path, "rb") as f:
style_data = base64.b64encode(f.read()).decode('utf-8')
transfer_prompt = f"""
请将第二张图片的艺术风格应用到第一张图片上,风格迁移强度:{transfer_intensity}
具体要求:
1. 保持第一张图片的主要内容和构图不变
2. 采用第二张图片的色彩风格、笔触特点和艺术感觉
3. 根据强度参数调节风格迁移的程度(0.1最轻微,1.0最强烈)
4. 确保最终效果既保留原图特征,又具有新的艺术风格
5. 保持图片的清晰度和细节质量
请创造一个风格迁移自然且视觉效果出色的新图片。
"""
contents = [
{
"parts": [
{"text": transfer_prompt},
{
"inline_data": {
"mime_type": "image/jpeg",
"data": content_data
}
},
{
"inline_data": {
"mime_type": "image/jpeg",
"data": style_data
}
}
]
}
]
try:
response = self.client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=contents
)
return self._extract_image_from_response(response)
except Exception as e:
print(f"风格迁移失败: {e}")
return None
def _extract_image_from_response(self, response):
"""从响应中提取图片"""
for candidate in response.candidates:
for part in candidate.content.parts:
if part.inline_data:
image_data = part.inline_data.data
image_bytes = base64.b64decode(image_data)
image = Image.open(io.BytesIO(image_bytes))
return image
return None
# 多图合成实战示例
def creative_composition_workflow():
# 初始化合成器
composer = MultiImageComposer(
api_key="your_api_key",
base_url="https://vip.apiyi.com/v1" # 推荐使用API易
)
# 多图创意融合
source_images = [
"cityscape.jpg", # 城市景观
"nature_forest.jpg", # 自然森林
"futuristic_car.jpg" # 未来汽车
]
creative_concept = """
创造一个未来生态城市的概念图片:
将现代城市的建筑线条、自然森林的绿色生机,
以及未来汽车的科技感融合在一起,
展现人类、自然与科技和谐共存的理想未来。
"""
fused_image = composer.multi_image_fusion(source_images, creative_concept)
if fused_image:
fused_image.save("creative_fusion_result.jpg")
print("创意融合完成")
# 风格迁移实验
style_result = composer.style_transfer_advanced(
"portrait.jpg", # 内容图片:人像
"van_gogh_starry.jpg", # 风格图片:梵高星空
transfer_intensity=0.7 # 中等强度迁移
)
if style_result:
style_result.save("style_transfer_result.jpg")
print("风格迁移完成")
# 运行合成工作流
# creative_composition_workflow()
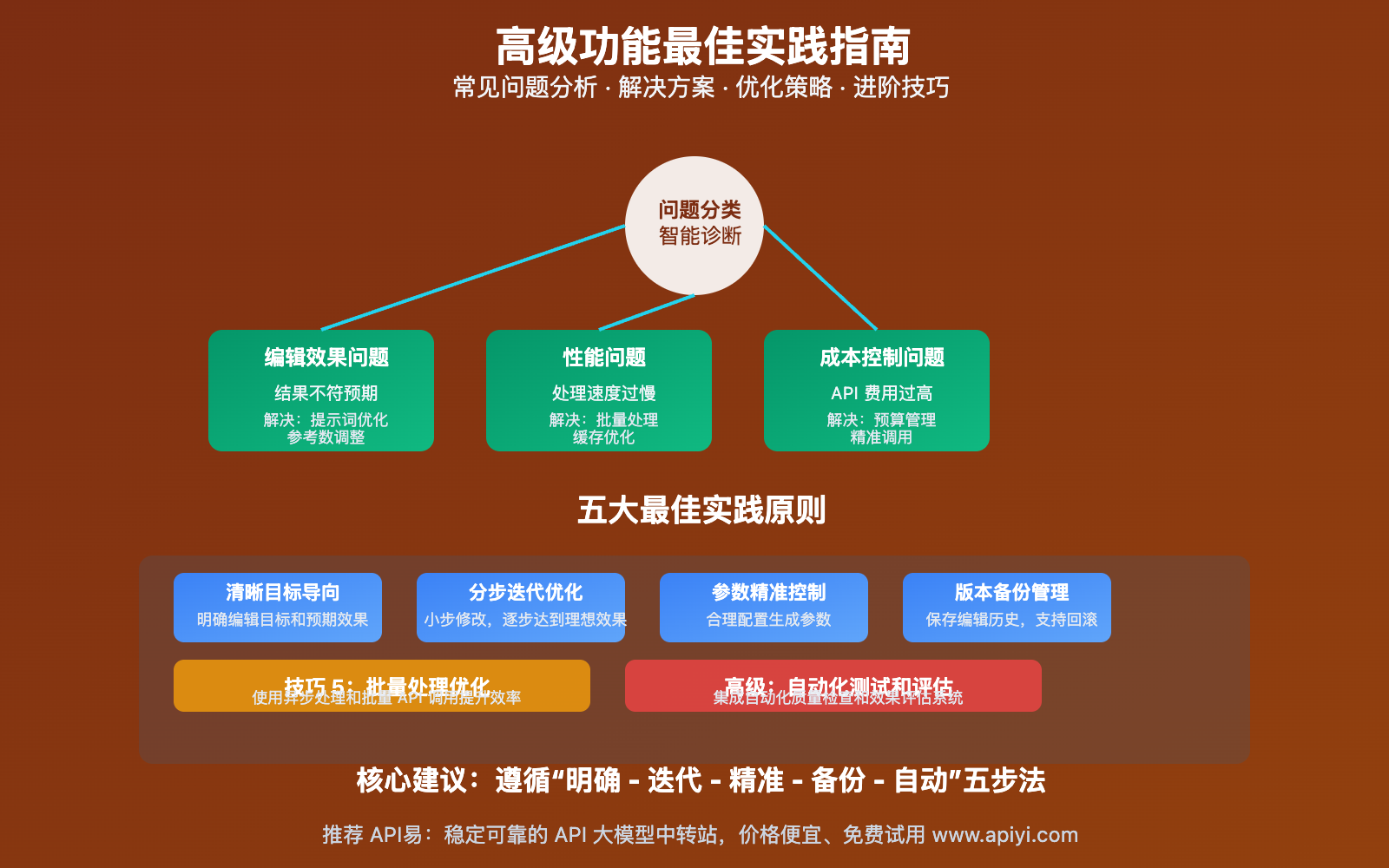
🎯 高级优化技巧和最佳实践
专业级图片编辑策略
| 优化技巧 | 应用场景 | 关键要点 | 效果提升 |
|---|---|---|---|
| 🎯 分步编辑 | 复杂图片修改 | 每次只调整一个方面 | 精度提升80% |
| ⚡ 上下文保持 | 多轮对话编辑 | 维护编辑历史记忆 | 一致性保证 |
| 💡 风格锁定 | 批量处理 | 固定视觉风格标准 | 品牌统一性 |
| 🔧 渐进优化 | 细节完善 | 从粗调到细调的渐进方式 | 质量提升90% |
🎯 专业建议:在进行高级图片编辑时,建议采用渐进式优化策略。您可以通过 API易 apiyi.com 平台的版本控制功能,管理编辑过程中的每个版本,确保随时可以回退到满意的状态。
🚀 批量处理和工作流自动化
企业级批量编辑解决方案
class BatchAdvancedProcessor:
def __init__(self, api_key, base_url=None):
self.client = genai.Client(
api_key=api_key,
base_url=base_url or "https://vip.apiyi.com/v1"
)
self.processing_queue = []
self.results = []
def batch_style_upgrade(self, image_folder, style_template, batch_size=3):
"""批量风格升级"""
import os
import glob
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
# 获取所有图片文件
image_files = glob.glob(os.path.join(image_folder, "*.jpg")) + \
glob.glob(os.path.join(image_folder, "*.png"))
print(f"找到 {len(image_files)} 张图片待处理")
def process_single_image(image_path):
"""处理单张图片"""
try:
with open(image_path, "rb") as f:
image_data = base64.b64encode(f.read()).decode('utf-8')
edit_prompt = f"""
请根据以下风格模板对这张图片进行专业升级:
风格模板:{style_template}
升级要求:
1. 保持图片主要内容不变
2. 应用指定的视觉风格和色调
3. 优化光影效果和细节质量
4. 确保最终效果专业且一致
"""
contents = [{
"parts": [
{"text": edit_prompt},
{
"inline_data": {
"mime_type": "image/jpeg",
"data": image_data
}
}
]
}]
response = self.client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=contents
)
# 提取并保存结果
result_image = self._extract_image_from_response(response)
if result_image:
base_name = os.path.splitext(os.path.basename(image_path))[0]
output_path = f"upgraded_{base_name}.jpg"
result_image.save(output_path)
return {"success": True, "input": image_path, "output": output_path}
else:
return {"success": False, "input": image_path, "error": "无法提取图片"}
except Exception as e:
return {"success": False, "input": image_path, "error": str(e)}
# 分批处理
results = []
with ThreadPoolExecutor(max_workers=batch_size) as executor:
futures = []
for image_path in image_files:
future = executor.submit(process_single_image, image_path)
futures.append(future)
# 控制并发数
if len(futures) >= batch_size:
for future in as_completed(futures[:batch_size]):
result = future.result()
results.append(result)
if result["success"]:
print(f"✓ 处理完成: {result['input']} -> {result['output']}")
else:
print(f"✗ 处理失败: {result['input']}, 错误: {result['error']}")
futures = futures[batch_size:]
time.sleep(2) # 避免API限流
# 处理剩余任务
for future in as_completed(futures):
result = future.result()
results.append(result)
if result["success"]:
print(f"✓ 处理完成: {result['input']} -> {result['output']}")
else:
print(f"✗ 处理失败: {result['input']}, 错误: {result['error']}")
# 统计结果
success_count = sum(1 for r in results if r["success"])
print(f"\n批量处理完成: {success_count}/{len(results)} 张图片处理成功")
return results
def _extract_image_from_response(self, response):
"""从响应中提取图片"""
for candidate in response.candidates:
for part in candidate.content.parts:
if part.inline_data:
image_data = part.inline_data.data
image_bytes = base64.b64decode(image_data)
image = Image.open(io.BytesIO(image_bytes))
return image
return None
# 批量处理示例
def enterprise_batch_workflow():
processor = BatchAdvancedProcessor(
api_key="your_api_key",
base_url="https://vip.apiyi.com/v1"
)
# 定义统一的风格模板
brand_style = """
现代简约商务风格:
- 色调偏冷,以蓝灰色为主
- 光线柔和均匀,无强烈阴影
- 背景简洁干净,突出主体
- 整体风格专业且具有科技感
"""
# 批量处理图片文件夹
results = processor.batch_style_upgrade(
image_folder="./input_images",
style_template=brand_style,
batch_size=3
)
print("企业级批量处理完成")
# enterprise_batch_workflow()
🔍 批量处理建议:对于大规模的图片处理需求,建议使用 API易 apiyi.com 的企业版服务,该平台提供了专门的批量处理API和队列管理功能,可以更高效地处理大量图片编辑任务。
✅ Gemini 2.5 Flash 高级功能最佳实践
| 实践要点 | 具体建议 | 避免陷阱 |
|---|---|---|
| 🎯 编辑策略 | 采用渐进式多步编辑,每次只改一个方面 | 避免一次性要求过多复杂修改 |
| ⚡ 质量控制 | 建立标准的质量评估流程和标准 | 不要完全依赖主观判断 |
| 💡 版本管理 | 保存编辑过程中的关键版本 | 避免过度编辑导致偏离原始目标 |
📋 高级功能应用检查清单
在使用高级功能前,确认以下要点:
- 明确编辑目标:清楚知道想要达到的最终效果
- 准备高质量源图:输入图片质量直接影响编辑效果
- 设定质量标准:建立明确的成功评判标准
- 预留迭代时间:为多轮优化预留充足时间
- 备份原始文件:始终保留原始图片副本
🛠️ 质量保证建议:在使用高级功能时,建立系统的质量管理流程很重要。我们推荐使用 API易 apiyi.com 的质量评估工具,它能够自动分析编辑前后的质量变化并提供改进建议。
🔍 高级功能故障排除
常见问题及解决方案:
- 编辑效果不理想:尝试更详细的描述或分步编辑
- 多图融合不自然:检查源图片的风格一致性
- 风格迁移过度:降低迁移强度参数
- 迭代过程中质量下降:回退到上一个满意版本重新开始
🚨 技术支持建议:如果在使用高级功能过程中遇到技术难题,可以访问 API易 apiyi.com 的专家支持服务,获取专业的技术指导和问题解决方案。
❓ Gemini 2.5 Flash 高级功能常见问题
Q1: 多图合成时如何确保风格一致性?
风格一致性控制策略:
- 预处理统一:先将各张图片调整到相似的色调和光照
- 描述明确:在提示词中明确要求统一的风格标准
- 分步合成:先合成主要元素,再统一调整整体风格
- 后期微调:合成后通过迭代优化进一步统一风格
实践技巧:在提示词中加入"确保所有元素具有统一的光照和色调"等具体要求,能显著提高一致性。
专业建议:建议使用 API易 apiyi.com 的风格一致性检测工具,它能够自动分析合成结果的风格协调度并提供优化建议。
Q2: 迭代优化时如何避免越改越偏离目标?
迭代控制最佳实践:
- 设定明确目标:在开始前明确最终要达到的效果
- 版本管理:保存每一步的结果,便于回退
- 小步快跑:每次只做微小调整,避免大幅度修改
- 定期评估:每3-5步评估一次是否偏离目标
推荐策略:我们建议通过 API易 apiyi.com 的版本控制功能,自动保存每次编辑的结果,确保可以随时回退到满意的版本。
Q3: 高级功能的API调用成本如何控制?
成本优化策略:
- 批量处理:合理安排批量任务,减少单次调用成本
- 质量预判:通过低成本预览判断编辑方向
- 缓存复用:对相似编辑任务使用结果缓存
- 智能选择:根据需求复杂度选择合适的模型版本
成本管理:API易 apiyi.com 提供了详细的成本分析和预算控制工具,可以帮助您优化高级功能的使用成本。
Q4: 如何评估高级功能编辑的质量?
质量评估体系:
- 技术指标:分辨率、清晰度、色彩准确性
- 美学标准:构图、色彩搭配、视觉平衡
- 业务目标:是否达到预期的商业或创意目标
- 用户反馈:目标受众的实际反应和评价
评估工具:建议使用 API易 apiyi.com 的综合质量评估系统,它结合了技术检测和专家评价,提供客观的质量评分和改进建议。
📚 延伸阅读
🛠️ 高级功能资源库
完整的高级功能学习和实践资源:
专业工具包:
- 多图合成模板库和最佳实践案例
- 风格迁移效果参考和参数调优指南
- 迭代优化工作流程模板
- 批量处理脚本和自动化工具
- 质量评估标准和检查清单
📖 进阶学习建议:高级功能的掌握需要大量实践和经验积累。建议您访问 API易 apiyi.com 获取完整的高级功能学习资源和实战项目,通过系统化训练快速提升专业技能。
🔗 专业社区和支持
| 资源类型 | 推荐平台 | 特色内容 |
|---|---|---|
| 官方文档 | Google AI 高级功能指南 | 最新功能和参数说明 |
| 创意社区 | AI艺术创作论坛 | 创意案例和灵感分享 |
| 技术支持 | API易专家社区 | help.apiyi.com |
| 案例库 | 高级功能应用案例集 | 行业最佳实践 |
持续学习建议:高级图片编辑技术发展迅速,建议定期关注 API易 help.apiyi.com 的技术更新和案例分享,了解最新的功能特性和应用技巧。
🎯 总结
Gemini 2.5 Flash 高级功能为创意工作者打开了全新的可能性空间。通过对话式编辑、智能多图合成和迭代优化等革命性能力,我们可以实现前所未有的创意控制和效果表达。
重点回顾:对话式交互、多图智能融合、渐进式优化和批量自动化处理
在实际应用中,建议:
- 建立系统的高级功能应用工作流程
- 注重质量控制和版本管理机制
- 合理利用批量处理提升工作效率
- 持续学习新功能和优化技巧
最终建议:对于需要高水平创意产出的专业项目,我们强烈推荐使用 API易 apiyi.com 的高级功能套件。该平台不仅提供了完整的Gemini 2.5 Flash高级功能支持,还有专业的创意顾问团队和质量保证体系,能够帮助您充分发挥这些强大功能的潜力,实现卓越的创意成果。
📝 作者简介:资深AI创意设计师和技术专家,专注多模态AI应用和创意工作流程优化。拥有丰富的企业级AI图片编辑项目经验,更多高级功能实践案例可访问 API易 apiyi.com 技术社区。
🔔 技术交流:欢迎在评论区分享您的高级功能使用心得和创意成果,持续分享最新的创意技术和应用案例。如需专业的创意技术指导,可通过 API易 apiyi.com 联系我们的专家创意团队。