Lors de l'utilisation de l'API Claude pour des appels avec un long contexte, de nombreux développeurs rencontrent la même confusion : bien que la mise en cache ait été déclarée dans le champ cache_control, les valeurs cache_creation_input_tokens et cache_read_input_tokens dans la réponse restent à 0, et aucune remise sur le cache n'apparaît sur la facture. Cet article décompose systématiquement les 5 causes principales de l'échec de mise en cache des invites (prompt caching) de Claude, en se concentrant sur le "seuil minimal de jetons" et le mécanisme de "défaillance silencieuse", souvent négligés.
Valeur ajoutée : Après avoir lu cet article, vous comprendrez les seuils minimaux de mise en cache pour les différents modèles d'Anthropic, pourquoi une invite courte avec cache_control ne génère pas d'erreur tout en ne mettant rien en cache, et vous apprendrez à vérifier si le cache est bien utilisé avec seulement 4 lignes de code.
Points clés du prompt caching de Claude
Le prompt caching de Claude est un mécanisme proposé par Anthropic : il permet de stocker les invites système, les longs documents et les définitions d'outils récurrents dans un cache temporaire. Lors de la prochaine utilisation, la facturation se base sur le coût de lecture, environ 90 % moins cher que le prix d'entrée normal. Ses caractéristiques clés sont : "correspondance de préfixe + déclaration explicite + échec silencieux". Ces trois points déterminent la direction à prendre pour résoudre vos problèmes.
| Point clé | Description | Valeur pour le diagnostic |
|---|---|---|
| Déclaration explicite | Doit insérer le bloc cache_control dans system, messages ou tools |
Oublier ou mal placer le bloc empêche la mise en cache |
| Correspondance de préfixe | La mise en cache exige une correspondance octet par octet de tout le contenu précédent | Même un espace supplémentaire invalide le cache |
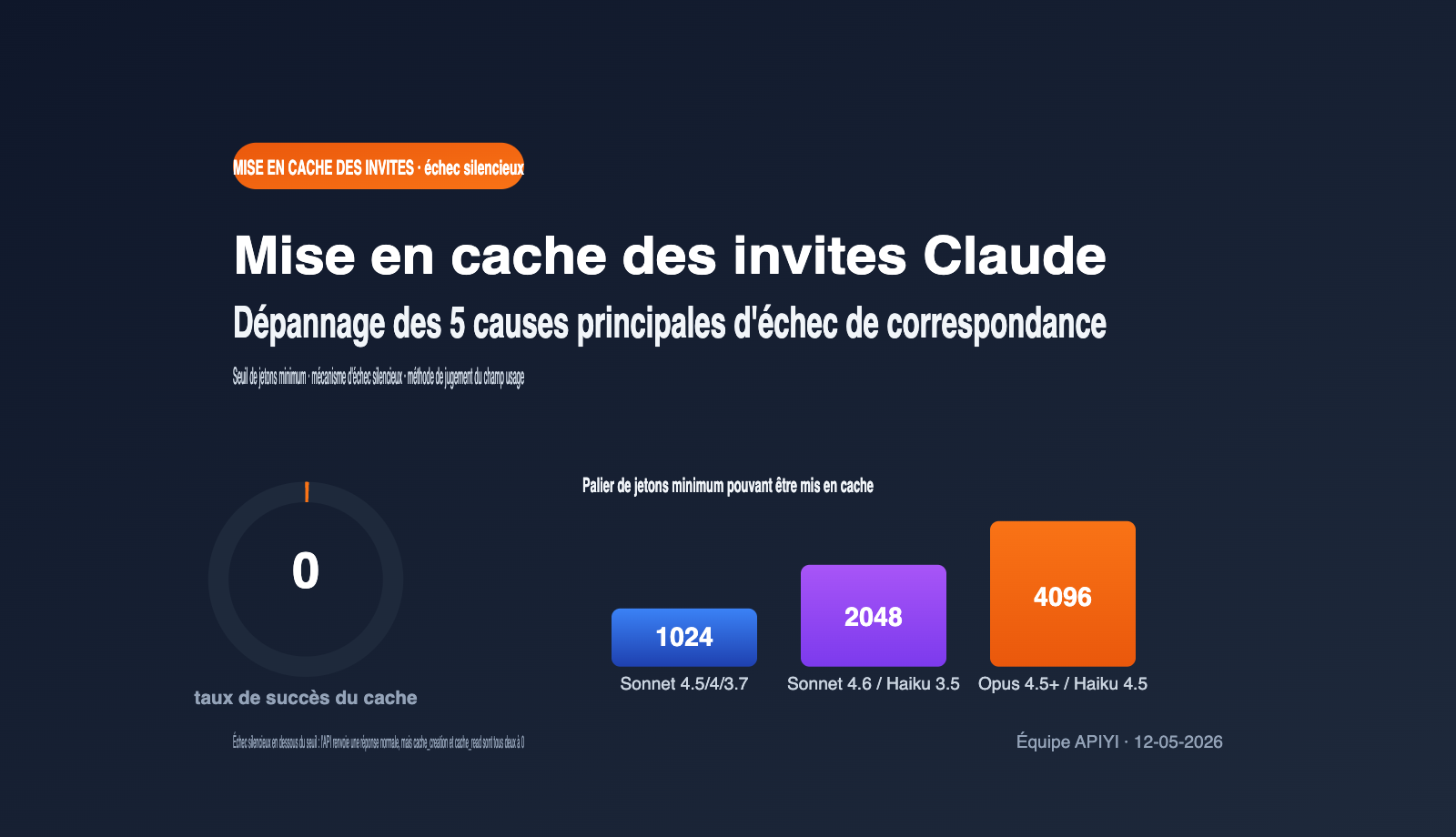
| Échec silencieux | Les requêtes ne remplissant pas les conditions renvoient une réponse normale sans erreur | Nécessite une vérification active du champ usage |
| Limite TTL | 5 minutes par défaut, 1 heure maximum | Les appels trop espacés expirent naturellement |
L'"échec silencieux" est la partie la plus piégeuse de ce mécanisme. La documentation d'Anthropic est claire : si votre requête ne remplit pas les conditions de mise en cache (par exemple, longueur insuffisante, préfixe modifié), l'API renvoie une réponse normale sans créer de cache, sans lire le cache et sans générer d'erreur. Cela signifie que vous ne verrez aucune anomalie dans votre code d'appel ; vous devez vérifier activement l'objet usage dans la réponse.
Si vous utilisez les modèles Sonnet, Opus ou Haiku de Claude via la plateforme APIYI (apiyi.com), la logique de mise en cache est identique à celle de l'interface officielle d'Anthropic. Il est conseillé d'afficher le champ usage avant toute mise en production pour confirmer que la mise en cache est bien active.
Guide rapide : Seuils minimaux de jetons pour le cache d'invites Claude
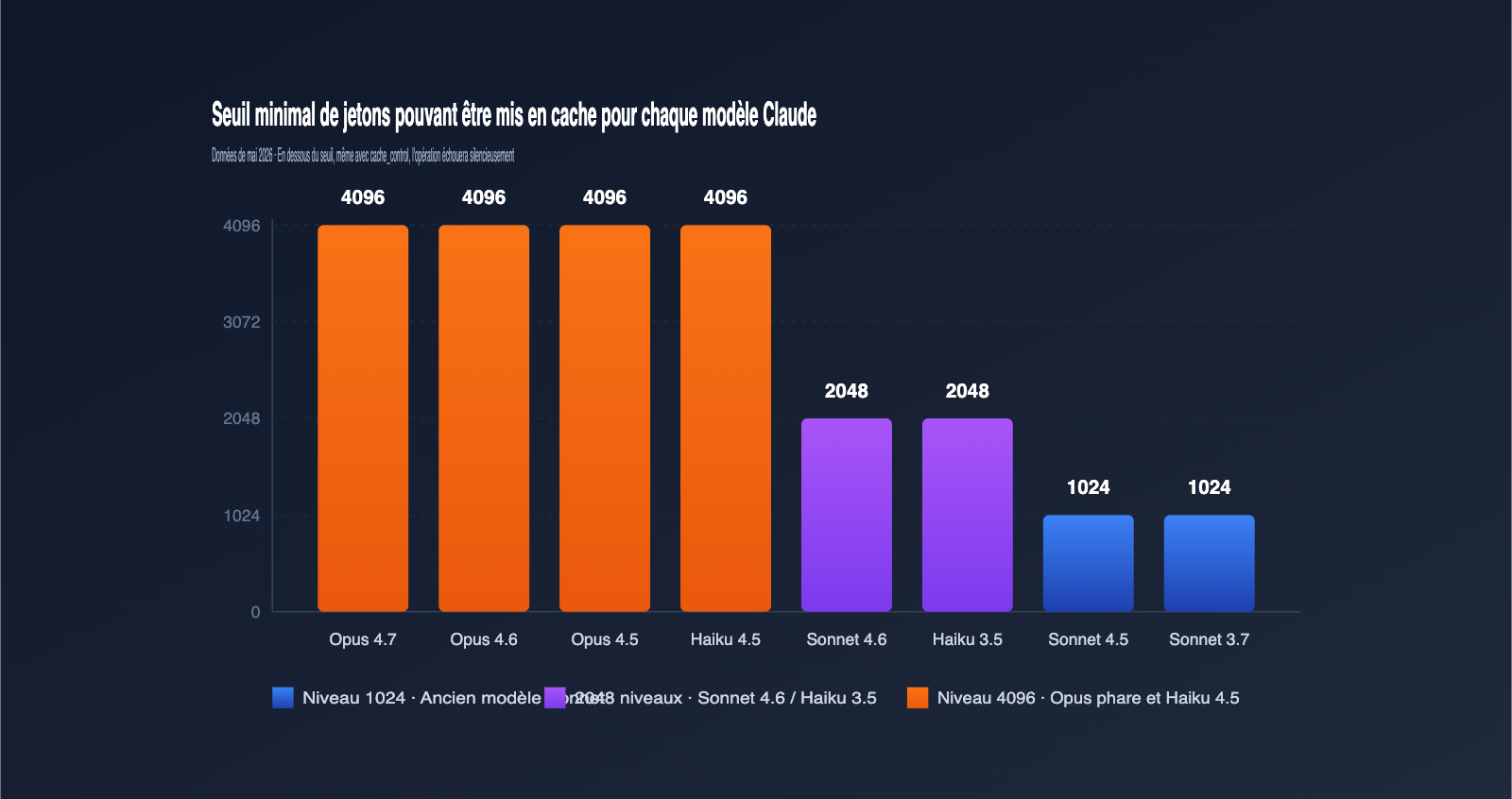
La cause la plus fréquente d'échec de mise en cache est que la longueur de votre invite n'atteint pas le seuil de « jetons minimaux pouvant être mis en cache » défini par Anthropic pour chaque modèle. En dessous de cette longueur, même si vous incluez cache_control, la requête sera traitée comme une requête standard. Les seuils varient considérablement selon les modèles. Voici les données officielles de mai 2026, que nous vous conseillons de garder sous la main.
| Modèle | Jetons minimaux pour cache | Remarques |
|---|---|---|
| Claude Opus 4.7 / 4.6 / 4.5 | 4096 | Dernier fleuron, seuil maximal |
| Claude Sonnet 4.6 | 2048 | Sonnet actuel, seuil doublé |
| Claude Sonnet 4.5 / Sonnet 4 / Sonnet 3.7 | 1024 | Série Sonnet classique |
| Claude Opus 4.1 / Opus 4 | 1024 | Ancienne génération Opus |
| Claude Haiku 4.5 | 4096 | Haiku a un seuil plus élevé que Sonnet |
| Claude Haiku 3.5 | 2048 | Modèle rapide et stable |
Beaucoup sont surpris en voyant ce tableau : pourquoi le seuil d'un « petit modèle » comme Haiku 4.5 est-il aussi élevé que celui d'Opus 4.7 ? La raison est que la nouvelle génération de Haiku utilise une fenêtre d'attention plus longue ; l'intérêt technique de la mise en cache n'est significatif que sur des préfixes plus longs, c'est pourquoi Anthropic a relevé le seuil dans sa stratégie produit.
Dans la pratique, l'erreur la plus courante est que les développeurs conçoivent leurs invites en se basant sur l'habitude des 1024 jetons de l'ancien Sonnet 3.7. En passant à Sonnet 4.6, cela cesse soudainement de fonctionner, et ils pensent à une erreur de code. Si vous utilisez plusieurs générations de modèles Claude via APIYI (apiyi.com), nous vous recommandons vivement d'intégrer ce tableau dans vos contrôles de paramètres et de déterminer dynamiquement le seuil en fonction du champ model.
5 causes principales d'échec du cache d'invites Claude
Une fois que vous avez compris le « seuil minimal de jetons » et les « échecs silencieux », vous pouvez diagnostiquer systématiquement les problèmes de non-correspondance. Voici les 5 causes principales, classées par fréquence.
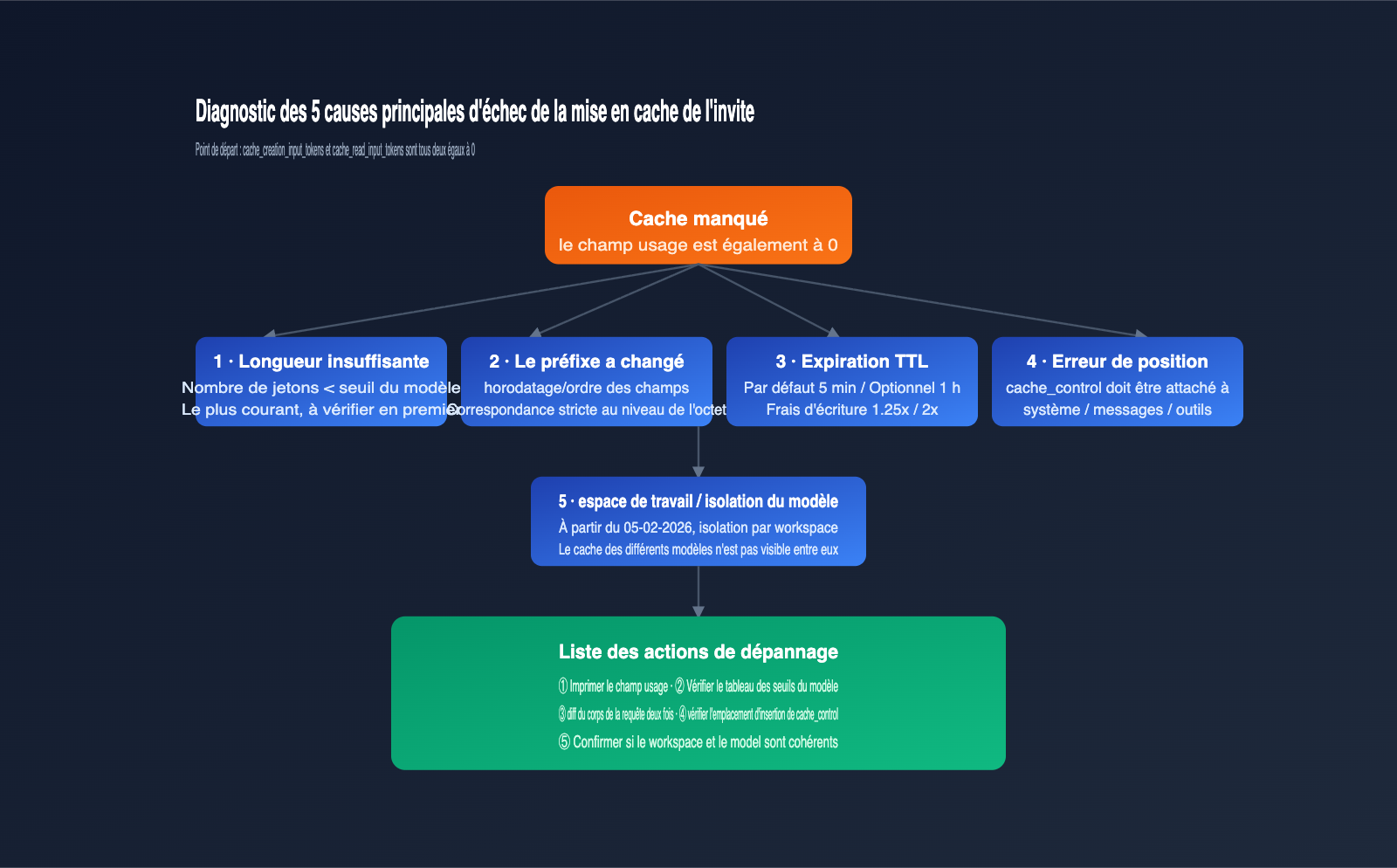
Cause 1 : Longueur de l'invite inférieure au seuil minimal
C'est le tueur numéro un. Par exemple, si vous déclarez une mise en cache sur Sonnet 4.6, mais que l'invite système réelle ne fait que 1500 jetons, le cache ne sera jamais créé. La méthode de diagnostic est simple : utilisez un tokenizer local pour estimer le nombre total de jetons (invite système + définitions d'outils + messages mis en cache), puis comparez-le au seuil du tableau ci-dessus.
Une situation plus insidieuse est la « superposition de plusieurs blocs cache_control ». La stratégie d'Anthropic est que « chaque point de rupture de cache doit faire en sorte que le contenu cumulé précédent atteigne le seuil du modèle », sinon le point de rupture est invalidé. Nous recommandons aux débutants de n'utiliser qu'un seul bloc cache_control jusqu'à ce qu'ils maîtrisent le mécanisme.
Cause 2 : Toute modification au niveau des octets dans le préfixe mis en cache
Le cache d'invites est une correspondance de préfixe stricte, ce qui signifie que si votre invite système, vos définitions d'outils ou votre historique de messages diffèrent d'un seul caractère, le cache est considéré comme invalide et doit être réécrit. Les « fausses modifications » courantes incluent :
- Une logique de rendu avec horodatage insérée dans l'invite système, rendant chaque requête différente.
- L'ordre des champs qui dérive lors de la sérialisation des définitions d'outils (car les dictionnaires Python ne sont pas ordonnés).
- Le traitement de rognage ou de déduplication des messages historiques, entraînant des différences subtiles dans la même conversation.
La méthode la plus directe pour diagnostiquer ce problème est de comparer le payload complet des deux requêtes. Si vous utilisez APIYI (apiyi.com) pour un proxy unifié dans votre passerelle, vous pouvez directement hacher le corps de la requête dans les journaux de la passerelle ; si les hashs diffèrent, vous avez localisé la dérive du préfixe.
Cause 3 : Le TTL a expiré
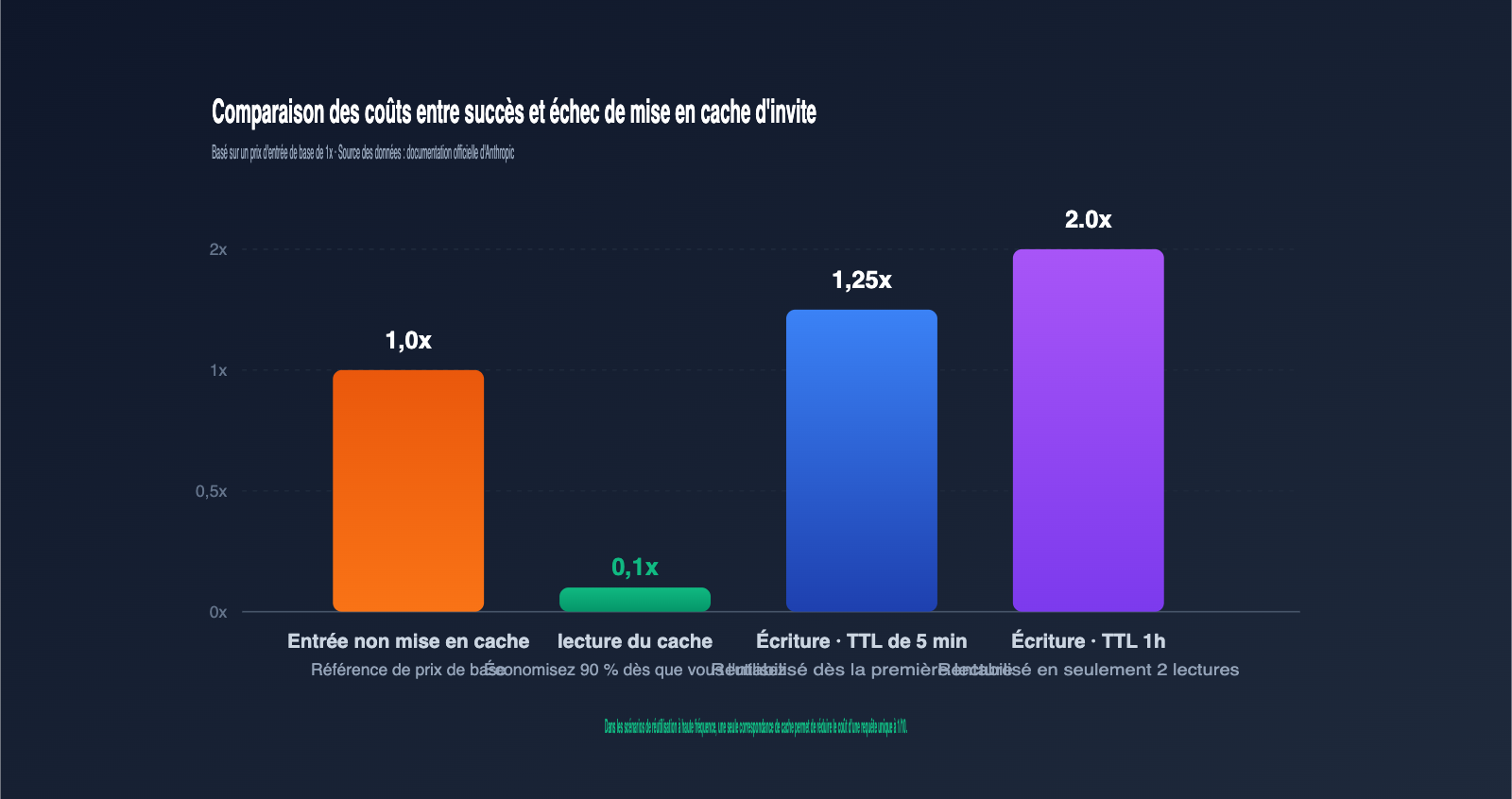
Le TTL par défaut est de 5 minutes. Après cet intervalle, l'entrée du cache est libérée et la requête suivante déclenchera une réécriture. Le prix d'écriture avec un TTL d'une heure est deux fois supérieur au prix d'entrée de base ; évaluez si cela vaut la peine de l'activer en fonction de la fréquence d'appel.
Le signe d'expiration du TTL est : cache_creation_input_tokens devient soudainement une valeur non nulle alors que vous pensiez que la requête lirait le cache. Si vous constatez cela, réduisez l'intervalle entre les requêtes ou passez à un TTL long "ttl": "1h".
Cause 4 : Position erronée du cache_control
cache_control doit être attaché à un bloc de contenu spécifique dans les tableaux system, messages ou tools, et le type doit impérativement être ephemeral. Les erreurs courantes incluent :
- Placer
cache_controldans les paramètres de haut niveau demessages.create()au lieu d'un bloc de contenu. - Le déclarer sur un message utilisateur dans le tableau
messages, alors que le préfixe que vous souhaitez réellement mettre en cache est le système. - Écrire plusieurs
cache_controldans le même message sans atteindre le seuil de 2048 jetons.
La bonne pratique consiste à intégrer cache_control directement dans le bloc où vous souhaitez « arrêter la mise en cache » ; le cache sera verrouillé depuis le début de l'invite jusqu'à la fin de ce bloc.
Cause 5 : Le cache n'est pas partagé entre les espaces de travail ou les modèles
Depuis le 5 février 2026, Anthropic a modifié la limite d'isolation du cache d'invites au « niveau de l'espace de travail » (workspace), ce qui signifie que les caches entre différents espaces de travail sont invisibles les uns pour les autres. Si vos deux appels utilisent des clés API ou des espaces de travail différents, le cache ne sera naturellement pas réutilisé.
La logique est la même au niveau du modèle. Si vous mettez en cache une invite sur Sonnet 4.6, elle ne sera jamais utilisée lors d'un appel ultérieur sur Sonnet 4.5. Lors de la planification multi-modèles, il est préférable de maintenir un script de préchauffage du cache par dimension de modèle, ou d'utiliser une plateforme d'agrégation comme APIYI (apiyi.com) pour réutiliser directement le même espace de travail en amont, évitant ainsi la fragmentation du cache.
Vérification de la mise en cache des invites Claude et logique de décision
La première étape pour diagnostiquer un problème de non-mise en cache est toujours d'« afficher le champ usage ». Anthropic inclut un objet usage dans chaque réponse messages.create. Il contient 4 champs clés qui constituent la seule source fiable pour déterminer l'état du cache.
Code de vérification minimaliste
import anthropic
client = anthropic.Anthropic(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com"
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system=[{
"type": "text",
"text": LONG_SYSTEM_PROMPT, # Doit être ≥ 2048 jetons
"cache_control": {"type": "ephemeral"}
}],
messages=[{"role": "user", "content": "votre question"}]
)
u = response.usage
print(f"Écriture cache : {u.cache_creation_input_tokens}")
print(f"Lecture cache : {u.cache_read_input_tokens}")
print(f"Entrée non mise en cache : {u.input_tokens}")
Utilisez ce code comme modèle de diagnostic. Dès que vous soupçonnez que la mise en cache ne fonctionne pas, exécutez-le pour identifier immédiatement la source du problème grâce aux champs retournés.
Voir la version encapsulée complète
import anthropic
import logging
MIN_TOKENS = {
"claude-opus-4-7": 4096,
"claude-opus-4-6": 4096,
"claude-opus-4-5": 4096,
"claude-sonnet-4-6": 2048,
"claude-sonnet-4-5": 1024,
"claude-haiku-4-5": 4096,
"claude-haiku-3-5": 2048,
}
def call_with_cache_check(model: str, system_text: str, user_msg: str):
client = anthropic.Anthropic(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com"
)
response = client.messages.create(
model=model,
max_tokens=1024,
system=[{
"type": "text",
"text": system_text,
"cache_control": {"type": "ephemeral"}
}],
messages=[{"role": "user", "content": user_msg}]
)
u = response.usage
if u.cache_creation_input_tokens == 0 and u.cache_read_input_tokens == 0:
logging.warning(
f"Cache inactif, probablement en dessous du seuil de {MIN_TOKENS.get(model)} jetons"
)
return response
Tableau de décision de l'état du cache
cache_creation_input_tokens |
cache_read_input_tokens |
Conclusion |
|---|---|---|
| > 0 | = 0 | Première écriture dans le cache (normal) |
| = 0 | > 0 | Cache atteint (idéal) |
| > 0 | > 0 | Cache partiel, ajout de nouvelles données |
| = 0 | = 0 | Non mis en cache, vérifiez les 5 causes principales |
La dernière ligne indique un problème. Si vous voyez cela, passez directement à la première cause et vérifiez les 5 points un par un. Si votre équipe exige une grande stabilité, vous pouvez intégrer cette logique de vérification sous forme de middleware dans votre chaîne d'invocation via APIYI (apiyi.com) pour recevoir une alerte immédiate en cas de problème.
4 astuces pratiques pour atteindre le seuil minimal de jetons
Une fois confirmé que le problème vient d'une « longueur insuffisante », l'étape suivante consiste à atteindre le seuil requis pour le préfixe de cache. Voici 4 astuces classées par recommandation ; les 3 premières n'ont pratiquement aucun effet secondaire.
| Astuce | Scénario | Jetons ajoutés | Remarques |
|---|---|---|---|
| Base de connaissances complète | Invite système trop courte | +2000 à 4000 | Doit être réellement utile |
| Hébergement centralisé des outils | Applications multi-outils | +500 à 2000 | Le champ tools est aussi cachable |
| Exemples few-shot courants | Tâches spécifiques | +1000 à 3000 | Les exemples doivent être généralisables |
| Remplissage de texte inutile | Urgence | Variable | Déconseillé, impacte la qualité |
La première option, la « base de connaissances complète », est la plus robuste. Si votre application possède déjà une base de connaissances interne (FAQ, guides de style, SOP), insérez-la en haut du bloc system avec cache_control. La seconde, les « définitions d'outils », est souvent oubliée ; le champ tools d'Anthropic supporte également la mise en cache. La troisième, les « exemples few-shot », est idéale pour les tâches complexes. Enfin, le « remplissage de texte » est une solution de dernier recours : si rien ne fonctionne, envisagez de passer à un modèle avec un seuil plus bas (comme Sonnet 4.5) via la plateforme APIYI (apiyi.com).
Questions fréquentes
Q1 : J’ai ajouté `cache_control` mais la mise en cache ne fonctionne pas, est-ce un bug de l’API ?
Il ne s'agit probablement pas d'un bug, mais plutôt d'un mécanisme d'échec silencieux. La première étape consiste à vérifier le seuil minimal de jetons (tokens) correspondant au champ model. Ensuite, affichez l'objet usage. Dans 99 % des cas, le problème est dû à une longueur insuffisante ou à une modification du préfixe.
Q2 : Est-ce que `cache_creation_input_tokens` coûte cher ?
Le coût d'écriture avec un TTL de 5 minutes est 1,25 fois le prix d'entrée de base, et 2 fois pour un TTL d'une heure. Le prix de lecture est de 0,1 fois le prix de base. En règle générale, un cache de 5 minutes est rentabilisé dès la première lecture, et un cache d'une heure dès la deuxième. Plus vous réutilisez le cache, plus les économies sont importantes.
Q3 : L’ancienne documentation indiquait un minimum de 1024 pour Sonnet, pourquoi est-ce passé à 2048 dans la nouvelle version ?
Il s'agit d'un nouveau seuil apparu avec Sonnet 4.6. Les versions 4.5 et antérieures restent à 1024. Il est conseillé de maintenir une table de correspondance « modèle → seuil » dans votre code et de l'ajuster dynamiquement selon le modèle appelé. Lors de l'invocation du modèle via APIYI (apiyi.com), le nommage du champ model est strictement identique à celui d'Anthropic, ce qui vous permet de réutiliser la même logique de mappage.
Q4 : Comment utiliser plusieurs blocs `cache_control` en toute sécurité ?
Chaque cache_control exige que le préfixe cumulé atteigne le seuil requis, sinon le point d'arrêt devient inopérant. Pour les débutants, nous recommandons de ne placer qu'un seul point d'arrêt et de mettre en cache l'intégralité du bloc system. Si vous devez absolument procéder par couches, placez la « base de connaissances peu changeante » au premier niveau et les « définitions d'outils occasionnelles » au second.
Q5 : Puis-je utiliser une plateforme de service proxy API locale pour tester le prompt caching ?
Oui. Les interfaces de la série Claude proposées par les plateformes d'agrégation comme APIYI (apiyi.com) sont entièrement compatibles avec l'API officielle d'Anthropic, y compris pour les champs cache_control, ttl et usage. Les développeurs peuvent effectuer le débogage et la mise à l'échelle sur la plateforme, tout en conservant la même logique de mise en cache et les mêmes règles de facturation.
Conclusion
Le prompt caching de Claude semble simple à mettre en œuvre avec l'ajout d'un champ cache_control, mais à l'usage, on se heurte souvent aux problèmes combinés d'échec silencieux, de seuils de jetons minimaux et de correspondance stricte des préfixes. Cet article propose une liste de contrôle en 5 points et un tableau de diagnostic pour aider les développeurs à identifier 90 % des problèmes de non-correspondance en moins de 5 minutes.
Nos recommandations : intégrez la validation dans un middleware par défaut, définissez les seuils des modèles sous forme de constantes dans votre code et créez des scripts dédiés pour le préchauffage du cache. Si votre activité nécessite de basculer fréquemment entre plusieurs modèles, utilisez la plateforme APIYI (apiyi.com) pour centraliser vos appels Claude. Vous pourrez ainsi réutiliser la même stratégie de cache et la même logique de monitoring, évitant ainsi la fragmentation du cache et les coûts cachés liés à l'incohérence des seuils entre les différents environnements.
Auteur : Équipe technique APIYI
Contact : Obtenez un support complet pour le débogage de la série Claude et du prompt caching via APIYI (apiyi.com)
Date de mise à jour : 12/05/2026