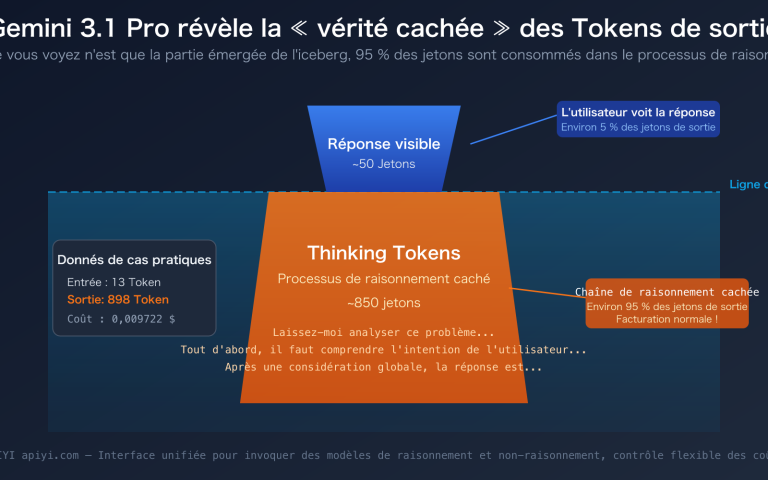
Pourquoi les tokens de sortie de Gemini 3.1 Pro sont-ils si grands ? 3 étapes pour comprendre les tokens de réflexion cachés dans les modèles de raisonnement
Note de l'auteur : Explication détaillée des raisons pour lesquelles les Tokens de sortie de Gemini 3.1 Pro Preview dépassent largement le texte visible : le mécanisme de chaîne de raisonnement Thinking Tokens, les règles de facturation, et les astuces pour économiser de l'argent en ajustant le paramètre thinking_level. « J'ai juste envoyé une phrase,…