Nota del autor: Comparativa neutral entre las capacidades de programación, calidad de código, ventana de contexto, precio y experiencia de desarrollador de Claude Code y GPT-5.4 para ayudarte a decidir si vale la pena el cambio.
El mismo día del lanzamiento de GPT-5.4, surgió un clamor en las redes sociales: "¡Cancela tu suscripción a Claude Code!" Los motivos parecían sólidos: 1M de contexto, liderazgo en diversas capacidades y la aparente solución a sus problemas de sonar poco natural.
Pero la realidad no es tan sencilla. Los datos de los benchmarks muestran que Claude Opus 4.6 sigue liderando con un 80,8% en el benchmark de programación SWE-Bench, frente al 77,2% de GPT-5.4. Las opiniones en la comunidad de desarrolladores están más divididas que nunca.
Valor central: Este artículo compara objetivamente Claude Code y GPT-5.4 desde 6 dimensiones para ayudarte a decidir si cambiar — o si la opción más inteligente es usar ambos.
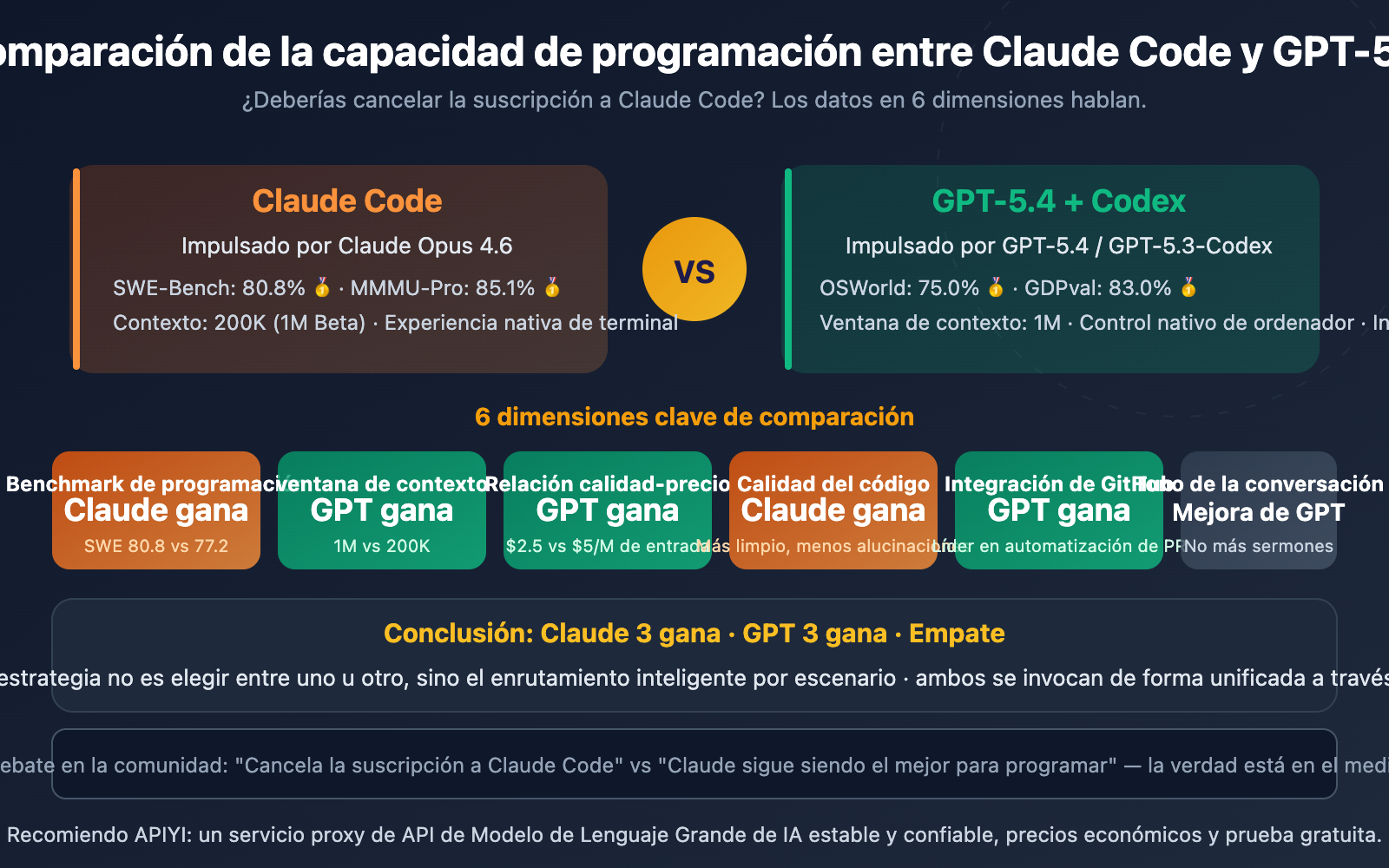
Comparativa de datos clave: Claude Code vs GPT-5.4
| Dimensión de comparación | Claude Code (Opus 4.6) | GPT-5.4 / Codex | Ganador |
|---|---|---|---|
| Programación SWE-Bench | 80,8% | 77,2% | Claude |
| Razonamiento visual MMMU-Pro | 85,1% | 81,2% | Claude |
| Trabajo de conocimiento GDPval | 78,0% | 83,0% | GPT |
| Control de computadora OSWorld | 72,7% | 75,0% | GPT |
| Matemáticas FrontierMath | 27,2% | 47,6% | GPT |
| Terminal Terminal-Bench | 65,4% | 75,1% | GPT |
| Ventana de contexto | 200K (1M Beta) | 1.000K | GPT |
| Precio de entrada API | $5,00/M | $2,50/M | GPT |
| Precio de salida API | $25,00/M | $15,00/M | GPT |
| Limpieza de código | Más limpio y estandarizado | Estándar | Claude |
| Refactorización y depuración | Líder | Estándar | Claude |
| Automatización de PR en GitHub | Promedio | Integración profunda | GPT |
El marcador es: Claude 4 victorias, GPT 8 victorias — pero no te apresures a sacar conclusiones. En escenarios de programación, el peso de SWE-Bench, la calidad del código y la capacidad de refactorización es mucho mayor que el del trabajo de conocimiento o el control de la computadora. Vamos a analizarlo punto por punto.
Análisis profundo de las capacidades de programación: Claude Code vs. GPT-5.4
Dimensión 1: Benchmarks de programación — Claude Code a la cabeza
En el benchmark de programación más seguido, SWE-Bench Verified (que mide la capacidad real para solucionar problemas en GitHub):
| Modelo | SWE-Bench Verified | SWE-Bench Pro |
|---|---|---|
| Claude Opus 4.6 | 80.8% 🥇 | — |
| Gemini 3.1 Pro | 80.6% | — |
| GPT-5.4 | 77.2% | 57.7% |
Claude Opus 4.6 lidera frente a GPT-5.4 con una ventaja de 3.6 puntos porcentuales. En escenarios de reparación de código de nivel de producción —como la comprensión de arquitecturas multi-archivo y el seguimiento de cadenas de dependencias complejas— Claude demuestra una comprensión superior de la estructura del código.
Sin embargo, GPT-5.4 destaca significativamente en Terminal-Bench 2.0 (tareas intensivas en operaciones de terminal) con un 75.1% frente al 65.4% de Claude. Si tu flujo de trabajo depende en gran medida de la terminal, GPT tiene la ventaja.
Dimensión 2: Calidad del código y experiencia de desarrollo — Claude Code es más limpio
El feedback de diversas comunidades de desarrolladores coincide en una misma conclusión: el código generado por Claude es más limpio, sigue mejores patrones y presenta menos alucinaciones.
Esto se traduce en:
- Tareas de refactorización: Claude se desempeña mejor en refactorizaciones complejas y depuración.
- Comprensión de arquitectura: Al analizar repositorios grandes y arquitecturas por capas, la cadena de razonamiento de Claude es más estable y sufre menos deriva de contexto.
- Velocidad de generación: La velocidad inicial de Claude Code es mayor (genera unas 1200 líneas en 5 minutos frente a las 200 líneas en 10 minutos de Codex).
La ventaja de GPT-5.4 reside en la generación de documentación y la escritura de código repetitivo (boilerplate), tareas que no requieren una comprensión profunda de la arquitectura del proyecto.
Dimensión 3: Ventana de contexto — GPT-5.4 arrasa
Esta es la mayor ventaja estructural de GPT-5.4:
| Capacidad | Claude Code | GPT-5.4 |
|---|---|---|
| Contexto estándar | 200K | 1,000K |
| Contexto Beta | 1M | — |
| Salida máxima | 32K | 128K |
Una ventana de 1M de tokens significa que puedes introducir un repositorio de código completo de nivel de producción de una sola vez. No obstante, ten en cuenta que las solicitudes que superen los 272K tokens se facturan al doble del precio de entrada y 1.5 veces el precio de salida. En la práctica, la mayoría de las tareas de programación no requieren más de 200K de contexto.
🎯 Sugerencia práctica: La ventana de contexto es la ventaja competitiva de GPT-5.4, pero solo brilla realmente al manejar bases de código masivas. En proyectos medianos o pequeños, los 200K de contexto de Claude, sumados a su mejor capacidad de comprensión arquitectónica, suelen ser la mejor opción. Ambos modelos pueden invocarse de forma unificada a través de APIYI (apiyi.com).
Comparativa de precios y ecosistema: Claude Code vs. GPT-5.4

Dimensión 4: Precio — GPT-5.4 ofrece mejor relación calidad-precio
En cuanto a los precios de la API, GPT-5.4 es considerablemente más económico que Claude Opus 4.6:
- Entrada: $2.50 vs $5.00/M (50% más barato)
- Salida: $15.00 vs $25.00/M (40% más barato)
- Entrada en caché: $0.25 vs $0.50/M (50% más barato)
A nivel de suscripción, la comunidad de desarrolladores reporta que Claude tiene límites de uso mucho más estrictos. El plan Codex de $20/mes ofrece una cuota más generosa que el plan Claude Pro de $17/mes. Muchos usuarios señalan que con Codex Pro es raro alcanzar el límite, mientras que los usuarios de Claude suelen encontrarse con restricciones incluso en planes de mayor precio.
Dimensión 5: Integración con GitHub — GPT Codex lidera claramente
Este es un factor que a menudo se pasa por alto, pero que impacta enormemente en el flujo de trabajo.
Según el feedback de los usuarios, las revisiones de PR de Claude Code suelen ser "comentarios extensos que pasan por alto bugs evidentes", mientras que Codex es capaz de ofrecer una "detección de bugs realmente difíciles de encontrar", incluyendo comentarios en línea y flujos de trabajo de reparación accionables. Además, la GitHub App de Codex mantiene una consistencia total entre la CLI y la interfaz web.
Dimensión 6: Tono conversacional — El problema del estilo robótico de GPT-5.x se ha mitigado
Este es un punto recurrente en redes sociales. La serie GPT-5 ha evolucionado notablemente en su forma de interactuar:
- GPT-5.0: Criticado por ser un "robot frío".
- GPT-5.1: Se le añadió más calidez y capacidad de diálogo.
- GPT-5.3 Instant: Enfocado en ser "menos vergonzoso" (less cringe), reduciendo las alucinaciones en un 26.8%.
- GPT-5.4: Hereda las mejoras de tono de la versión 5.3, potenciando a la vez sus capacidades profesionales.
No obstante, siendo objetivos, Claude sigue siendo considerado superior en cuanto a la naturalidad del diálogo y la legibilidad de sus explicaciones de código. GPT-5.4 ha mejorado, pero aún existe una brecha.
🎯 Optimización de costos: Independientemente del modelo que elijas, el acceso unificado a través de APIYI (apiyi.com) te permite disfrutar de una facturación más flexible. Los precios de GPT-5.4 están sincronizados con la web oficial ($2.50/$15.00), y al recargar desde 100 USD obtienes un 10% de bonificación adicional.
Claude Code vs GPT-5.4: Sugerencias de selección por escenario
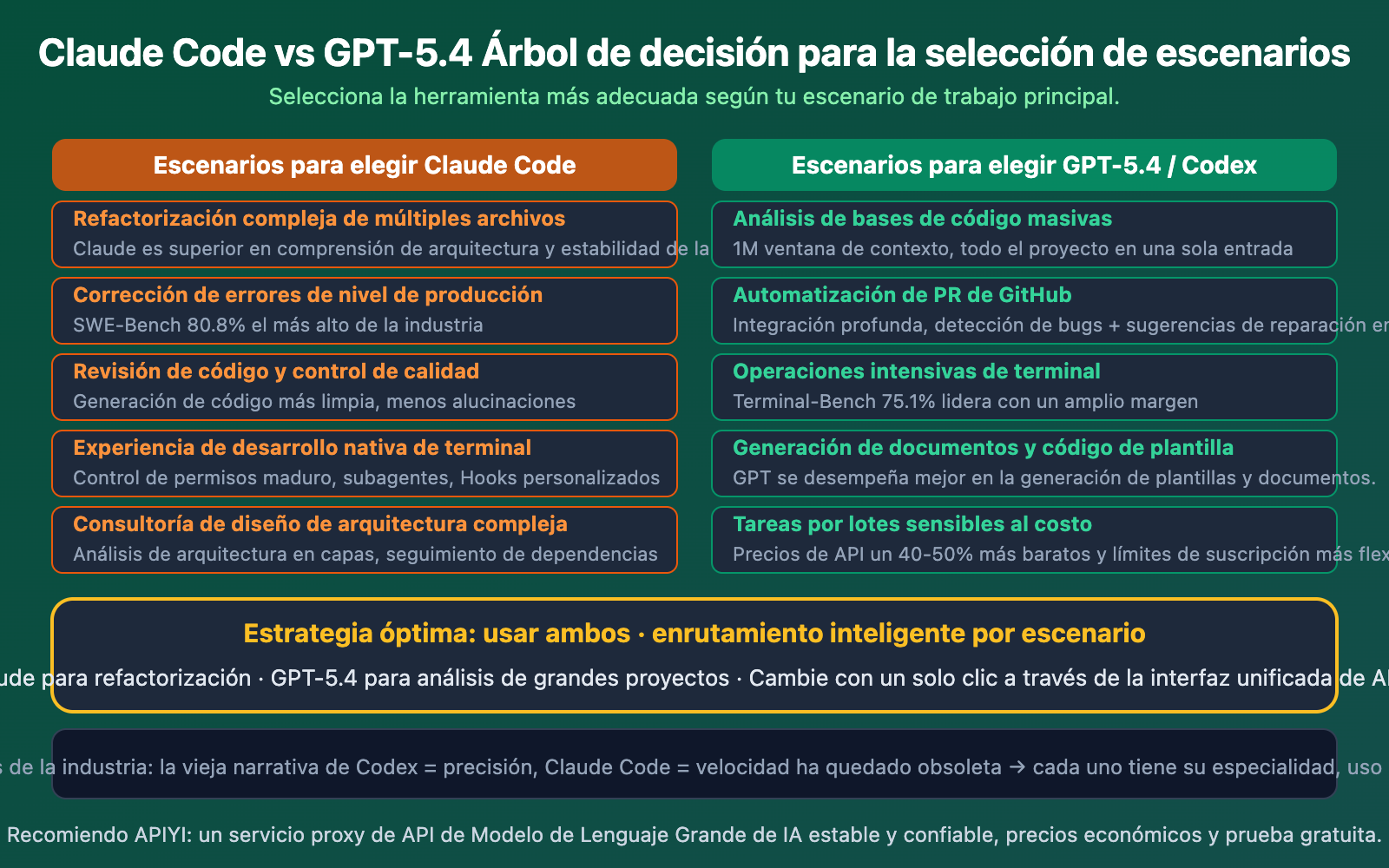
Ejemplo de invocación de API para Claude Code vs GPT-5.4
import openai
client = openai.OpenAI(
api_key="TU_CLAVE_API",
base_url="https://vip.apiyi.com/v1"
)
# Refactorización compleja → Usar Claude Opus 4.6 (mayor calidad de código)
refactor_result = client.chat.completions.create(
model="claude-opus-4-6",
messages=[{"role": "user", "content": "Reestructura la arquitectura de inyección de dependencias de este módulo"}]
)
# Análisis de base de código masiva → Usar GPT-5.4 (ventana de contexto de 1M)
analysis_result = client.chat.completions.create(
model="gpt-5.4",
messages=[{"role": "user", "content": "Analiza las vulnerabilidades de seguridad de todo el proyecto"}]
)
Sugerencia: Al registrarte en APIYI (apiyi.com), puedes invocar tanto a Claude como a GPT-5.4 con una sola cuenta. Los precios de GPT-5.4 están sincronizados con el sitio oficial, y obtienes un 10% de bonificación en recargas desde $100 USD. Cambiar de modelo según el escenario es tan fácil como modificar un parámetro.
Preguntas Frecuentes
P1: ¿Debería cancelar mi suscripción a Claude Code?
Depende de tu escenario de trabajo principal. Si tu necesidad principal es la refactorización de código complejo y la corrección de errores de nivel de producción, Claude sigue siendo la opción más sólida (liderando con un 80.8% en SWE-Bench). Si necesitas una ventana de contexto ultra larga, integración con GitHub y menores costos, GPT-5.4 / Codex tiene más ventajas. La mejor estrategia no es elegir uno, sino invocar ambos según el escenario a través de una API.
P2: ¿Es la capacidad de programación de GPT-5.4 realmente superior en todos los aspectos?
No. GPT-5.4 lidera en dimensiones como GDPval (trabajo de conocimiento), OSWorld (control de computadora) y FrontierMath (matemáticas), pero en el benchmark de programación más importante, SWE-Bench, Claude Opus 4.6 mantiene el liderazgo con un 80.8% frente al 77.2% de GPT-5.4. En cuanto a calidad de código, capacidad de refactorización y comprensión de arquitectura, la comunidad de desarrolladores sigue prefiriendo a Claude. Puedes comparar ambos mediante la API unificada de APIYI (apiyi.com).
P3: ¿Cómo puedo usar Claude y GPT-5.4 al mismo tiempo?
Regístrate en APIYI (apiyi.com) para obtener una cuenta:
- Obtén una clave API unificada.
- Configura el
base_urlcomohttps://vip.apiyi.com/v1. - Usa
model="claude-opus-4-6"para tareas de refactorización. - Usa
model="gpt-5.4"para análisis de grandes proyectos. - Usa
model="gpt-5.3-chat-latest"para tareas cotidianas (más económico).
Con recargas desde $100 USD recibes un 10% extra, y una sola cuenta cubre todos los modelos principales.
Resumen
Conclusiones clave de Claude Code vs GPT-5.4:
- Claude sigue liderando en los benchmarks de programación: Con un 80.8% en SWE-Bench frente al 77.2% de GPT-5.4, la calidad de su código es más limpia y su capacidad de refactorización y depuración es superior. Por eso, decir que hay que "cancelar la suscripción a Claude Code" es demasiado radical.
- GPT-5.4 arrasa en contexto y relación calidad-precio: Ofrece una ventana de contexto de 1M de tokens (5 veces más que Claude), el precio de su API es entre un 40% y 50% más económico y cuenta con una integración más profunda con GitHub. Es ideal para proyectos grandes y escenarios donde el costo es un factor crítico.
- La mejor estrategia es usar ambos: Utiliza Claude para refactorizaciones y corrección de errores (bugs), GPT-5.4 para el análisis de bases de código masivas y operaciones de terminal, y GPT-5.3 Instant para tareas cotidianas para ahorrar dinero.
No te dejes llevar por los titulares tipo "clickbait" que piden abandonar Claude Code. Los desarrolladores inteligentes eligen la herramienta más adecuada para cada situación, en lugar de ser fieles a una sola marca.
Te recomendamos acceder de forma unificada a Claude y GPT-5.4 a través de APIYI (apiyi.com). Con una sola clave API podrás realizar la invocación del modelo que necesites. Además, obtén un 10% de bonificación en recargas a partir de 100 USD.
📚 Referencias
-
Comparativa profunda entre Claude Code y Codex: Una comparativa detallada desde la perspectiva del desarrollador del equipo de Builder.io.
- Enlace:
builder.io/blog/codex-vs-claude-code - Descripción: Incluye comparativas prácticas de precios, calidad de código e integración con GitHub.
- Enlace:
-
Análisis de competencia: GPT-5.4 apunta a Claude: Cómo se posiciona GPT-5.4 para competir con Claude.
- Enlace:
trendingtopics.eu/gpt-5-4-targets-anthropics-claude-with-premium-pricing-and-coding-muscle/ - Descripción: Análisis profundo del posicionamiento premium de GPT-5.4 Pro y su ambición en el ámbito de la programación.
- Enlace:
-
Comparativa multidimensional: GPT-5.4 vs Opus 4.6 vs Gemini 3.1 Pro: Datos de 12 pruebas de rendimiento (benchmarks).
- Enlace:
digitalapplied.com/blog/gpt-5-4-vs-opus-4-6-vs-gemini-3-1-pro-best-frontier-model - Descripción: La comparativa más completa de los tres grandes, incluyendo análisis de competitividad y sugerencias de selección.
- Enlace:
-
Benchmark para desarrolladores: Claude Sonnet 4.6 vs GPT-5: Pruebas en escenarios reales de desarrollo por SitePoint.
- Enlace:
sitepoint.com/claude-sonnet-4-6-vs-gpt-5-the-2026-developer-benchmark/ - Descripción: Datos comparativos en tareas específicas como refactorización, depuración y generación de documentación.
- Enlace:
Autor: Equipo técnico de APIYI
Intercambio técnico: Te invitamos a debatir en la sección de comentarios. Para más información, visita nuestro centro de documentación en docs.apiyi.com.