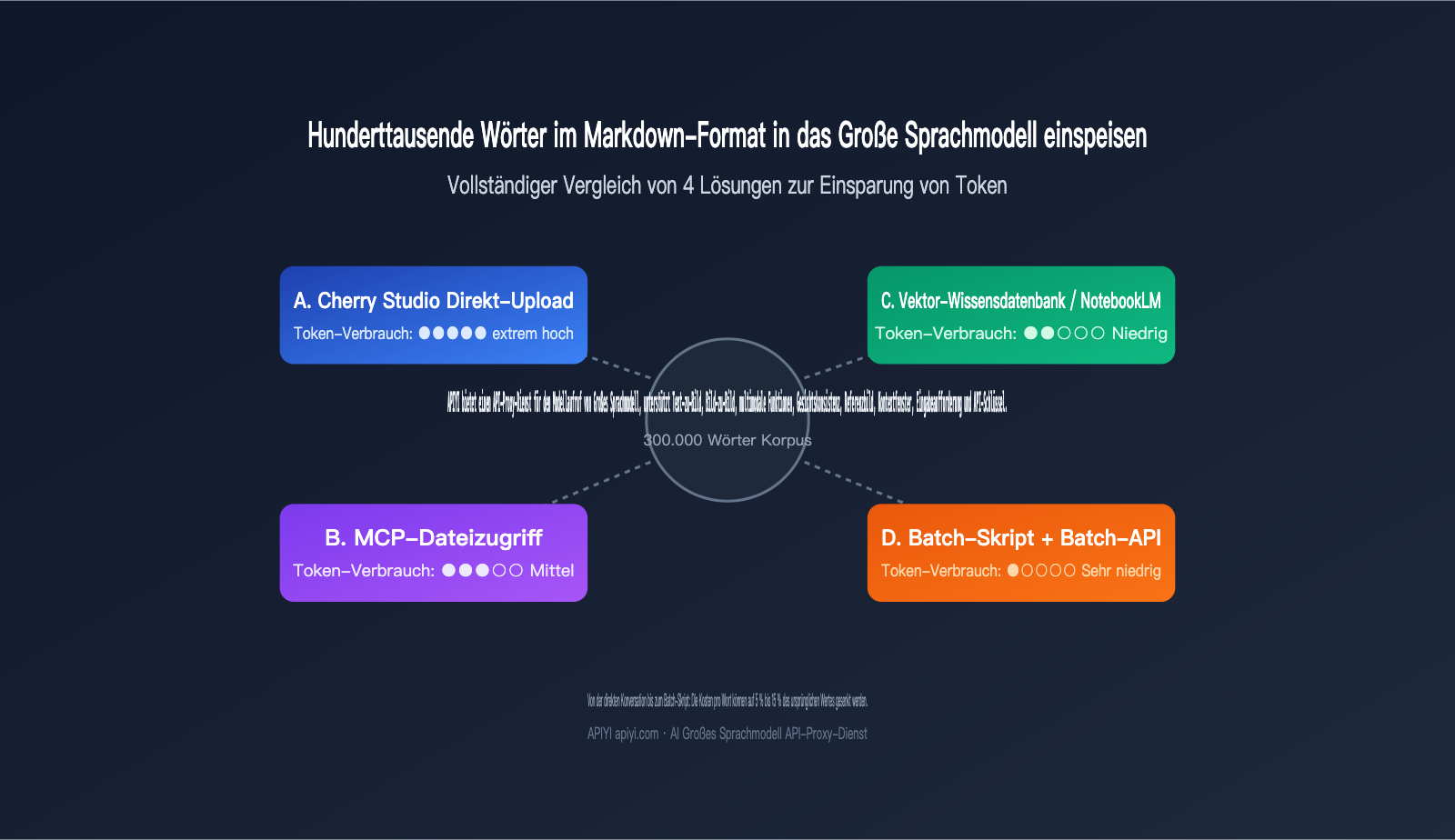
Kürzlich erreichte uns eine typische Anfrage: Ein Nutzer möchte die Texte eines versierten Autors (mehrere hunderttausend Wörter) als „Stil-Grundlage“ an ein Großes Sprachmodell „destillieren“, weiß aber nicht, wie er das Markdown-Korpus am kosteneffizientesten einspeisen soll. Die drei gängigen Ansätze sind: Dateien einzeln in Dialog-Tools wie Cherry Studio hochladen, per MCP das Modell direkt auf Dateien auf der Festplatte zugreifen lassen oder alles in eine Wissensdatenbank für RAG (Retrieval-Augmented Generation) einspeisen. Auf den ersten Blick funktionieren alle Wege, aber sobald das Korpus die 300.000-Wörter-Marke überschreitet, driften die Token-Kosten und Latenzzeiten massiv auseinander. Eine falsche Wahl kann das Budget schnell um das Zehnfache sprengen.
Dieser Artikel analysiert vier gängige Strategien zur Optimierung von Token bei der Verarbeitung von Markdown-Korpora für Große Sprachmodelle: tatsächlicher Token-Verbrauch, Kosten pro Aufgabe, Latenz bis zum ersten Token, Kontrollierbarkeit und die optimale Wahl je nach Korpusgröße. Abschließend zeigen wir einen stufenweisen Entscheidungspfad auf – was für die erste Exploration taugt und worauf man bei der Skalierung umsteigen sollte. Wenn Sie gerade an Stil-Destillation, Wissensdatenbank-Abfragen oder der Datenbereinigung vor dem Fine-Tuning arbeiten, hilft Ihnen dieser Leitfaden bei der direkten Umsetzung.
I. Das Kernproblem bei der Token-Optimierung von Markdown-Korpora
Bevor wir die Lösungen aufschlüsseln, klären wir, wo die Kosten tatsächlich entstehen. Das Einspeisen von hunderttausenden Wörtern im Markdown-Format in ein Großes Sprachmodell ist im Wesentlichen ein Abwägen zwischen vier Kostenfaktoren: Eingabe-Token, Ausgabe-Token, Such-/Indexierungskosten und manueller Debugging-Aufwand.
Eingabe-Token werden am häufigsten unterschätzt. Wenn ein technischer Blog im HTML-Rohformat vorliegt, spart die Konvertierung in Markdown in der Regel 70 % bis 80 % der Token, da Tags, Styles und eingebettete Skripte entfernt werden. Deshalb ist der erste Schritt in jeder Pipeline zur Verarbeitung großer Korpora die Vereinheitlichung der Inhalte in Markdown oder TXT. Wenn Sie dies richtig machen, sinkt die Kostenbasis für jede nachfolgende Einspeisemethode um eine Stufe.
Ausgabe-Token scheinen zunächst irrelevant, sind aber bei „Destillations“-Aufgaben ein versteckter Engpass. Claude Sonnet und Opus haben 1 Million Token Kontext als Standardpreis etabliert (Sonnet-Eingabe $3/M, Opus-Eingabe $5/M). Theoretisch könnten Sie also hunderttausende Wörter auf einmal einspeisen, aber die maximale Ausgabe pro Antwort liegt immer noch bei nur wenigen zehntausend Token. Das bedeutet, Sie können eine vollständige Umschreibung nicht in einem einzigen Aufruf erledigen. Die Aufgabe muss in Stücke zerlegt werden, was direkt dazu führt, dass Batch-Skripte für skalierbare Szenarien oft besser geeignet sind als interaktive Dialoge.
🎯 Empfehlung vor der Auswahl: Bevor Sie sich für einen Ansatz entscheiden, sollten Sie alle Markdown-Dateien einer Bereinigung und Format-Normalisierung unterziehen. Wir empfehlen, über die Plattform APIYI (apiyi.com) zunächst kleine Stichproben zu testen, um den tatsächlichen Token-Verbrauch pro tausend Wörter zu bestätigen, bevor Sie sich für Dialog-Tools oder Batch-Skripte entscheiden, um unkontrollierbare Kosten zu vermeiden.
2. Die 4 Lösungsansätze: Kernunterschiede und Einsatzbereiche
Die vier Ansätze haben klare Leistungsgrenzen. Es ist wichtiger, diese Unterschiede zu verstehen, als sich Parameter starr einzuprägen.
2.1 Ansatz A: Direkter Upload in Dialog-Tools wie Cherry Studio
Dies ist die Methode mit der niedrigsten Einstiegshürde. Tools wie Cherry Studio, Claude Desktop oder ChatGPT erlauben es, mehrere Markdown-Dateien direkt in das Dialogfenster zu ziehen. Das Modell fügt den gesamten Inhalt zu einer langen Eingabeaufforderung zusammen und verarbeitet ihn. Der Vorteil liegt im geringen technischen Aufwand und der sofortigen Sichtbarkeit der Ergebnisse. Der Nachteil: Bei jeder neuen Sitzung muss alles erneut „gefüttert“ werden, was zu einem hohen, redundanten Token-Verbrauch führt. Zudem wird die Dateimenge pro Sitzung durch das Kontextfenster begrenzt.
Für Aufgaben mit kleinen Datenmengen von unter 50.000 Wörtern ist diese Methode am effizientesten, da man in natürlicher Sprache iterieren und die Ergebnisse direkt prüfen kann. Sobald das Korpus jedoch 200.000 Wörter überschreitet, kommt es häufig zu Kontext-Kürzungen, Verzögerungen bei der Verarbeitung langer Kontexte (der erste Token kann 20–30 Sekunden auf sich warten lassen) und unnötigen Kosten.
2.2 Ansatz B: MCP für den direkten Zugriff auf lokale Dateien
Das Model Context Protocol (MCP) ermöglicht es dem Modell, Dateien auf Ihrer Festplatte wie ein Werkzeug abzurufen. Das klingt elegant: Das Modell lädt nur bei Bedarf, statt alles auf einmal zu laden. In der Praxis wird der Token-Verbrauch von MCP jedoch oft unterschätzt – selbst wenn ein Werkzeugaufruf nur drei Felder aus einem JSON-Objekt benötigt, landet die gesamte Struktur im Kontext. Der Modus für die Schlüsselwortsuche verbraucht etwa dreimal so viele Token wie eine Vektor-Suche.
Die wahre Stärke von MCP liegt in dynamischen Datenquellen, wie Echtzeit-Logs, privaten Benutzerdaten oder Finanzdaten, die lokal bleiben müssen. Für das typische Szenario „Hunderttausende Wörter in statischen Markdown-Dateien“ ist MCP jedoch „mit Kanonen auf Spatzen schießen“ und führt dazu, dass das Kontextfenster bei mehreren Aufrufen vorzeitig erschöpft ist.
2.3 Ansatz C: Vektorisierte Wissensdatenbank / NotebookLM
Hierbei werden alle Dateien zerlegt, eingebettet (Embedding) und in einer Datenbank gespeichert, um relevante Fragmente bei Bedarf semantisch abzurufen – das ist der RAG-Ansatz. Eine gut konzipierte RAG-Pipeline ruft pro Abfrage nur 5–20 Chunks ab (insgesamt meist 2.000–10.000 Token), was im Vergleich zum vollständigen Laden 50- bis 200-mal weniger Eingabe-Token verbraucht.
NotebookLM ist eine sofort einsatzbereite RAG-Lösung von Google, die Embeddings, Suche und Quellenangaben automatisch verwaltet. Sie eignet sich hervorragend für Aufgaben wie die Analyse von Schreibstilen, Literaturübersichten oder das Befragen von Notizen. Die Einschränkung: Die Antworten basieren nur auf den Quelldateien und das Modell assoziiert nicht aktiv mit seinen Trainingsdaten; zudem sind die Anpassungsmöglichkeiten begrenzt. Wenn Sie komplexe Suchstrategien oder mehrstufige Schlussfolgerungen benötigen, ist eine selbst aufgebaute Vektor-Wissensdatenbank flexibler.
🎯 Hinweis zur Umsetzung von Ansatz C: Die Qualität der Vektor-Suche bestimmt direkt die Qualität der Ausgabe. Die Segmentierung (Chunking), das Embedding-Modell und die Top-k-Suche sollten je nach Korpus optimiert werden. Wir empfehlen, auf der Plattform APIYI (apiyi.com) zunächst einen kleinen Testlauf mit Claude oder GPT durchzuführen, um die Genauigkeit der Antworten bei verschiedenen Suchparametern zu vergleichen, bevor Sie sich für NotebookLM oder eine Eigenentwicklung entscheiden.
2.4 Ansatz D: KI-gestützte Batch-Skripte (Skalierbarkeits-Optimum)
Dies ist der Ansatz, der in der ursprünglichen Antwort am stärksten hervorgehoben wurde: Lassen Sie die KI ein Batch-Skript schreiben. Zuerst verarbeitet das Große Sprachmodell 5–10 Beispiel-Datensätze, um wiederverwendbare Muster (wie Satzvorlagen, Absatzstrukturen oder Keyword-Verteilungen) manuell oder automatisch zu identifizieren. Diese Muster werden dann in Code gegossen, der die restlichen Hunderttausenden Wörter verarbeitet, während das Große Sprachmodell nur noch an kritischen Stellen eingreift.
Im Kern handelt es sich um „Regel-Implementierung“: Das Große Sprachmodell entdeckt Muster, der Code übernimmt die Massenverarbeitung. In Kombination mit der Batch-API von Claude/GPT (50 % Rabatt) liegen die Gesamtkosten meist nur bei 5–15 % von Ansatz A. Der Nachteil ist der initiale technische Aufwand von 1–2 Tagen, was sich für einmalige Aufgaben nicht lohnt.
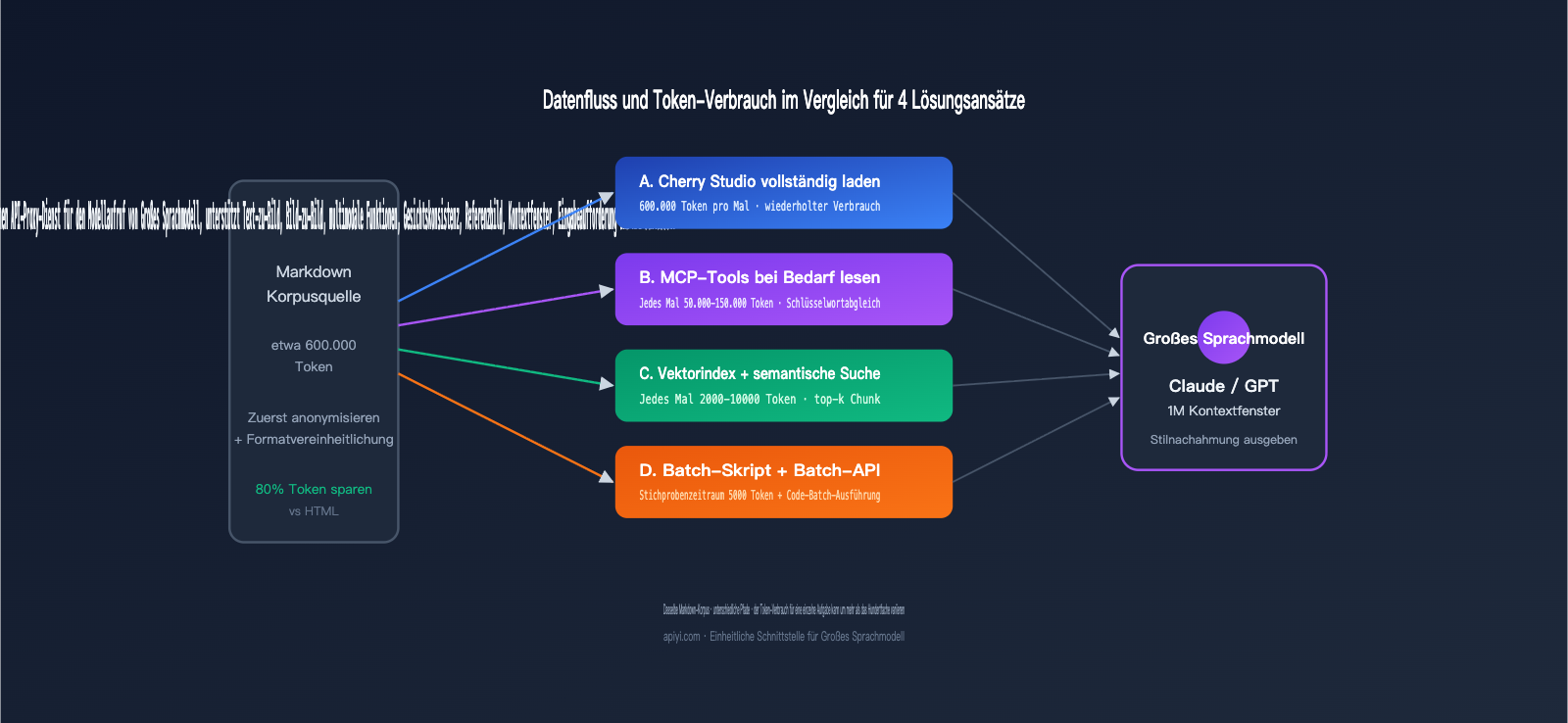
III. Kosten- und Token-Vergleich der 4 Ansätze
Um die abstrakten Unterschiede greifbar zu machen, müssen wir sie in Zahlen ausdrücken. Die folgende Tabelle basiert auf einem konkreten Szenario: Ein Nutzer möchte 300.000 Wörter an Markdown-Material (ca. 600.000 Token) verarbeiten und daraus 100 Artikel im Stil der Vorlage erstellen (je ca. 2.000 Wörter).
| Ansatz | Input-Token pro Durchlauf | Gesamt-Input-Token | Gesamt-Output-Token | Geschätzte Kosten (Sonnet) | Latenz (First Token) |
|---|---|---|---|---|---|
| A. Direkter Chat-Upload | 600.000 | 60 Mio. (100x) | 6 Mio. | ≈ $270 | 20-30 Sek. |
| B. MCP-Dateizugriff | 50k-150k (segmentiert) | 15 Mio. | 6 Mio. | ≈ $135 | 8-15 Sek. |
| C. Vektor-Wissensdatenbank | 5k-10k | 1 Mio. | 6 Mio. | ≈ $93 | 1-2 Sek. |
| D. Batch-Skript + Batch API | 5k (Stichprobe) + Code | 1 Mio. | 6 Mio. | ≈ $46 | Asynchron |
Wie man sieht, betragen die Kosten für Ansatz D nur etwa 17 % von Ansatz A, bei gleichzeitig stabilerer Latenz. Wenn man den 50%-Rabatt der Batch API hinzurechnet, lassen sich die Kosten für Ansatz D sogar noch einmal halbieren. Seitdem Claude 1M-Kontext-Fenster standardmäßig bepreist, wird Ansatz A zwar nicht mehr mit dem Faktor 2 belegt, aber die Verschwendung durch wiederholte Eingabe desselben Materials bleibt bestehen – ein systembedingter Nachteil dialogbasierter Workflows.
🎯 Empfehlung zur Kostenkontrolle: Die oben genannten Kosten basieren auf öffentlichen Preislisten. Die tatsächlichen Werte können je nach Design der Eingabeaufforderung, Cache-Trefferrate und Nutzung von Prompt Caching um 30-50 % schwanken. Wir empfehlen, die Nutzungsüberwachung im APIYI-Kontrollzentrum (apiyi.com) zu aktivieren und in den ersten 3 Tagen täglich einen Abgleich durchzuführen. So wird aus einem abstrakten Budget eine visualisierte Kurve, bevor Sie entscheiden, ob Sie weitere Aufgaben auf die Batch API migrieren.
Die folgende Tabelle stellt die technische Komplexität der vier Ansätze gegenüber:
| Dimension | Ansatz A: Chat-Upload | Ansatz B: MCP | Ansatz C: Vektor-DB | Ansatz D: Batch-Skript |
|---|---|---|---|---|
| Technischer Aufwand | Nahezu null | Mittel | Mittel bis hoch | Hoch (initial) |
| Einarbeitungszeit | 5 Minuten | 1-2 Stunden | 0,5 bis 1 Tag | 1-2 Tage |
| Reproduzierbarkeit | Schwach (Chat-Verlauf) | Mittel | Stark | Sehr stark |
| Geeignete Datenmenge | < 50k Wörter | 50k-300k (dynamisch) | 100k – 10 Mio. (statisch) | > 300k Wörter |
| Kontrollierbarkeit | Begrenzt durch Kontext | Begrenzt durch Tool-Calls | Begrenzt durch Retrieval | Vollständig kontrollierbar |
IV. Empfehlungen nach Datenvolumen
Die Anwendung der Ansätze auf konkrete Szenarien macht die Wahl deutlicher. Hier sind Empfehlungen für drei verschiedene Skalierungsstufen.
4.1 Kleine Datenmengen (< 50.000 Wörter): Explorationsphase
Das Hauptziel ist hier die schnelle Validierung von Ideen, nicht die Kostenoptimierung. Ansatz A (direkter Chat-Upload) ist die sinnvollste Wahl: Ziehen Sie alle Dateien in Cherry Studio oder Claude Desktop und debuggen Sie die Eingabeaufforderung direkt im Dialog mit dem Modell. Konzentrieren Sie sich in dieser Phase auf: Erfasst das Modell die Stilmerkmale des Autors? Welche Dimensionen sind quantifizierbar (Satzlänge, Wortwahl, Satzbau)? Welche sind vage (Tonfall, Rhythmus)? Bei kleinen Stichproben sind die Kosten minimal; das lässt sich für wenige Dollar testen.
4.2 Mittlere Datenmengen (50.000 – 300.000 Wörter): Analysephase
In diesem Bereich steigen die Kosten für die wiederholte Eingabe bei Ansatz A schnell an. Die Best Practice ist hier der Wechsel zu Ansatz C (Vektor-Wissensdatenbank) oder NotebookLM. Sobald die Stichproben in einer Vektordatenbank gespeichert sind, können sie per semantischer Suche bei Bedarf abgerufen werden. Für Inhaltsanalysen, Stilzusammenfassungen oder explorative Fragen ist NotebookLM fast ohne technischen Aufwand nutzbar. Für komplexere mehrstufige Schlussfolgerungen empfiehlt sich ein eigenes RAG-System auf Basis von Claude oder GPT.
🎯 Tipp für mittlere Skalierung: NotebookLM eignet sich hervorragend für reines Lesen und Analysieren, unterstützt jedoch keine benutzerdefinierten Suchstrategien oder komplexe Workflows. Wir empfehlen, auf der APIYI-Plattform (apiyi.com) Claude Sonnet oder Opus mit 1M-Kontext für RAG zu nutzen. So profitieren Sie von Standardpreisen und können Chunk-Größen sowie Suchgewichtungen flexibel steuern – ideal für langfristig genutzte Wissensdatenbanken.
4.3 Große Datenmengen (> 300.000 Wörter): Produktionsphase
Bei Volumina von mehreren hunderttausend bis Millionen Wörtern ist Ansatz D (Batch-Skript) fast die einzige nachhaltige Lösung. Teilen Sie den Workflow in drei Teile: „Mustererkennung → Batch-Verarbeitung per Code → KI nur für kritische Knoten“. In Kombination mit der Batch API für asynchrone Ausführung lassen sich die Kosten pro Wort auf 5-15 % des ursprünglichen Wertes senken. In dieser Phase benötigen Sie keine „klügere“ Eingabeaufforderung, sondern eine robustere technische Pipeline.

V. Entscheidungshilfe zur phasenweisen Token-Optimierung
Die obige Analyse lässt sich in einer praktischen Übersichtstabelle zusammenfassen, die Sie direkt als Leitfaden verwenden können:
| Auslöser | Empfohlene Lösung | Wichtige Maßnahme |
|---|---|---|
| Korpus < 50.000 Wörter / Einmalige Erkundung | Lösung A: Direkter Dialog | Datei hochladen, Eingabeaufforderung anpassen, effektive Eingabeaufforderungen protokollieren |
| 50.000–300.000 Wörter / Statische Daten / Analyse | Lösung C: Vektor-Wissensdatenbank | NotebookLM oder eigenes RAG nutzen, Fokus auf Chunking und Top-K |
| > 300.000 Wörter / Wiederkehrende Aufgaben | Lösung D: Batch-Skript + Batch API | KI beim Schreiben des Skripts helfen lassen, Muster in der Stichprobenphase manuell validieren |
| Dynamische Daten / Lokale Verarbeitung | Lösung B: MCP | Aufrufe von Werkzeugen begrenzen, bei Stichwortsuche vorsichtig sein |
In der Praxis ist die Kombination „Lösung A für den Start, Lösung C für die Mitte, Lösung D für den Abschluss“ am effektivsten. Das liegt daran, dass das Aufgabenverständnis ein schrittweiser Prozess ist: Kleine Stichproben helfen Ihnen, das Ziel und die Bewertungskriterien zu definieren; mittlere Stichproben validieren die Suchqualität und Generalisierung; in der großflächigen Phase werden ausgereifte Abläufe in Code gegossen.
Ein häufiger Fehler ist es, die Zwischenschritte zu überspringen und direkt mit Batch-Skripten zu starten – Sie werden feststellen, dass das Skript zwar perfekt geschrieben ist, die Ergebnisse aber nicht den Erwartungen entsprechen, da die ursprüngliche Eingabeaufforderung nicht ausreichend optimiert wurde. Umgekehrt verschwendet ein zu langes Verweilen in der Dialogphase unnötig Token; Rechnungen über Hunderte Dollar können dann nur wenige effektive Ergebnisse liefern.
🎯 Signale für den Phasenwechsel: Wenn Sie feststellen, dass Sie bei mehr als 5 aufeinanderfolgenden Dialogen ähnliche Eingabeaufforderungen für vergleichbare Dateien verwenden, ist es Zeit für eine Vektor-Wissensdatenbank. Wenn Sie bei jeder Aufgabe die gleiche Suchlogik wiederholen müssen, ist es Zeit für ein Skript. Wir empfehlen, auf der Plattform APIYI (apiyi.com) das Caching für Eingabeaufforderungen und die Verbrauchsstatistik zu aktivieren, damit der Wechsel auf Daten basiert und nicht auf Vermutungen.
VI. Minimales lauffähiges Beispiel für ein Batch-Skript
Um Lösung D zu konkretisieren, finden Sie hier ein minimalistisches Grundgerüst für ein Batch-Skript, das den Kernprozess „Stichprobenerkennung → Regelverfestigung → Batch-Ausführung“ demonstriert:
import os, json
from anthropic import Anthropic
# Nutzung des API-Proxy-Dienstes von APIYI
client = Anthropic(base_url="https://vip.apiyi.com")
def extract_style_features(markdown_text: str) -> dict:
"""Extrahiert quantifizierbare Stilmerkmale aus einem einzelnen Artikel mittels Großem Sprachmodell."""
resp = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1500,
messages=[{"role": "user", "content": f"""
Bitte extrahieren Sie die Schreibstilmerkmale aus dem folgenden Markdown-Artikel und geben Sie diese als JSON aus:
- avg_sentence_length: Durchschnittliche Satzlänge
- paragraph_structure: Muster der Absatzstruktur
- key_phrases: Die 10 häufigsten Phrasen
- tone: Tonfall-Label (z. B. sachlich/umgangssprachlich/pointiert)
Artikelinhalt:
{markdown_text}
"""}],
)
return json.loads(resp.content[0].text)
# Stichprobenphase: 10 Artikel zur Mustererkennung nutzen
samples = [open(f, encoding="utf-8").read() for f in os.listdir("samples")[:10]]
features = [extract_style_features(s) for s in samples]
# Regelverfestigung: Häufige Merkmale in eine Konfigurationsdatei schreiben, die später direkt vom Code angewendet wird
with open("style_profile.json", "w", encoding="utf-8") as f:
json.dump(features, f, ensure_ascii=False, indent=2)
Nach Abschluss der Stichprobenphase kann die eigentliche Batch-Überarbeitung vollständig durch den Code erfolgen, der die Regeln aus style_profile.json anwendet. Das Große Sprachmodell greift nur noch beim „finalen Feinschliff“ ein, wodurch der Token-Verbrauch von Hunderttausenden auf wenige Tausend gesenkt werden kann.
🎯 Empfehlung zur API-Anbindung: Der obige
base_url-Parameter verweist auf den API-Proxy-Dienst von APIYI (apiyi.com). Sie können das offizielle Anthropic-SDK direkt weiterverwenden, ohne den Code ändern zu müssen. Wir empfehlen, Logik für Wiederholungsversuche (Retry) und Kostenverfolgung (Cost Tracking) in das Skript zu integrieren. Bei langen Aufgaben stoppt das Skript so automatisch, falls das Budget überschritten wird – dies ist die häufigste Fehlerquelle bei Batch-Verarbeitungen.
VII. Häufig gestellte Fragen (FAQ)
Q1: Claude Sonnet und Opus verfügen bereits über ein Kontextfenster von 1 Million Token. Kann ich nicht einfach alles auf einmal hineinladen?
Technisch gesehen ist das möglich, bringt jedoch zwei versteckte Kostenfaktoren mit sich. Erstens verzögert sich die Zeit bis zum ersten Token (Time to First Token) auf 20–30 Sekunden, was die Benutzererfahrung erheblich verschlechtert. Zweitens müssen dieselben Daten bei jeder Sitzung erneut eingegeben werden, was die Kosten im Vergleich zu RAG nach wenigen Durchläufen um das 50- bis 200-fache in die Höhe treibt. Ein 1M-Kontextfenster eignet sich für einmalige, globale Schlussfolgerungen (z. B. „Widersprüche über Dokumente hinweg finden“), ist jedoch nicht für den wiederholten Zugriff auf denselben Korpus geeignet. Wir empfehlen, auf APIYI (apiyi.com) Sonnet 1M für globale Analyseaufgaben und Haiku für die stapelweise Verarbeitung von Teilaufgaben zu nutzen – diese Kombination bietet das beste Preis-Leistungs-Verhältnis.
Q2: Wie entscheide ich mich zwischen NotebookLM und dem Aufbau einer eigenen Vektordatenbank?
Wenn Sie als Einzelperson oder in einem kleinen Team statische Korpora analysieren, Stiluntersuchungen durchführen oder Abfragen tätigen möchten, ist NotebookLM am schnellsten einsatzbereit – einfach Dateien per Drag-and-Drop hochladen und loslegen. Wenn Sie jedoch Chunking-Strategien anpassen, das Gewicht der Suche steuern, Geschäftssysteme anbinden oder Modelle anderer Anbieter für die Generierung nutzen möchten, ist eine selbst gehostete Vektordatenbank wesentlich flexibler.
Q3: Ist MCP wirklich nutzlos?
Ganz und gar nicht. Die Stärken von MCP liegen in Szenarien, in denen sich Daten häufig ändern oder das System den lokalen Bereich nicht verlassen darf, wie etwa beim Auslesen von Echtzeit-Logs, dem Abfragen privater Datenbanken oder dem Aufruf interner APIs. Für statische Markdown-Korpora ist RAG jedoch in fast allen Dimensionen überlegen – das ist die eigentliche Schlussfolgerung.
Q4: Spart die Batch API wirklich 50 %? Ist die Antwortzeit langsam?
Die Batch API arbeitet asynchron und liefert Ergebnisse in der Regel innerhalb von 24 Stunden; der Preis beträgt 50 % der Standard-API. Dies ist ideal für Aufgaben, die keine Echtzeit erfordern, wie etwa „Destillation eines Schreibstils zur Generierung von 100 Nachahmungsartikeln“. In Kombination mit der Standardpreisgestaltung für 1M-Kontext können die Gesamtkosten auf 30–40 % des ursprünglichen Preises gesenkt werden. Wir empfehlen, den Prozess zunächst über die synchrone API auf der Plattform APIYI (apiyi.com) zu testen und dann für die Massenproduktion auf den Batch-Modus umzustellen.
Q5: Was ist mit Bildern, Tabellen und Code-Blöcken im Korpus?
Markdown bewahrt diese Strukturen bereits sehr gut, aber Vorsicht: Große Code-Blöcke verbrauchen viele Token. Wenn es nur um die Analyse des Sprachstils geht, können Sie den Code vorab per Skript entfernen. Bei komplexen Tabellen empfiehlt es sich, diese in CSV umzuwandeln und separat zu speichern, während Sie dem Großen Sprachmodell nur eine Zusammenfassung übergeben. Dies kann weitere 30 % der Token einsparen.
VIII. Fazit
Kommen wir zurück zur ursprünglichen Frage: Wie füttert man ein Großes Sprachmodell mit hunderttausenden Wörtern in Markdown? Die Antwort ist kein „Entweder-oder“, sondern eine phasenweise Kombination. In der Explorationsphase mit kleinen Stichproben ist die direkte Übertragung im Chat am schnellsten. In der Forschungsphase mittleren Umfangs sind Vektor-Wissensdatenbanken oder NotebookLM am stabilsten. In der Phase der skalierten Produktion sollten Sie unbedingt auf Batch-Skripte in Verbindung mit der Batch API setzen. Verschieben Sie die Rolle des Großen Sprachmodells vom „Ausführenden“ hin zum „Mustererkenner“ – der Code ist das eigentliche Werkzeug für die Bewältigung großer Datenmengen.
Sobald Sie diesen Pfad verstanden haben, wandelt sich das Thema „Token-Einsparung bei Markdown-Korpora für Große Sprachmodelle“ von der Frage „Welches Tool soll ich wählen?“ zu „Welche Kombination nutze ich in welcher Phase?“. Wenn Sie sich in einer bestimmten Phase unsicher sind, ob ein Wechsel sinnvoll ist, führen Sie auf der Plattform APIYI (apiyi.com) einen kleinen Testlauf durch. Vergleichen Sie die Kosten pro tausend Wörter, die Suchgenauigkeit und die Latenz des ersten Tokens – die Entscheidung wird dann deutlich klarer. Wir hoffen, dass dieser Vergleich Ihnen einige Umwege erspart und Sie Ihr Budget dort einsetzen, wo es echten Mehrwert schafft.
— APIYI Team (api.apiyi.com)