站长注:详解如何在Cherry Studio中为自定义API模型(如sora_image等)启用视觉功能,解决第三方渠道模型无法上传图片的问题,轻松实现多模态交互体验。
使用Cherry Studio时,你可能遇到过这样的情况:明明已经接入了支持图像识别的API模型(如sora_image、gpt-4o-image等),但在使用时发现无法上传图片附件。这是因为Cherry Studio并不能自动识别第三方渠道自定义模型的能力。本文将教你如何一键解决这个问题,让你的自定义模型秒变多模态助手。
省流版,请看下方两个图片
欢迎免费试用 API易,3 分钟跑通 API 调用 www.apiyi.com
支持sora_image、gpt-4o-image等全系列视觉模型,一键配置更方便
注册即送 1.1 美金额度起,约 300万 Tokens 额度体验。立即免费注册
加站长个人微信:8765058,发送你《大模型使用指南》等资料包,并加赠 1 美金额度。
Cherry Studio自定义模型视觉能力问题分析
为什么自定义API模型无法上传图片?
当我们在Cherry Studio中接入第三方API服务(如API易)提供的自定义模型时,经常会遇到一个困扰:即使该模型本身具备图像处理能力,Cherry Studio也不会自动显示图片上传按钮。这是因为:
- 能力识别机制限制:Cherry Studio默认只为官方已知支持视觉的模型(如官方的gpt-4o)启用图片上传功能
- 自定义模型信息不完整:第三方渠道的自定义模型(如sora_image)信息无法被Cherry Studio自动获取
- 安全考虑:为避免向不支持图像的模型发送图片导致错误,Cherry Studio采取了保守策略
这导致即使你接入了具有强大视觉能力的API模型,如API易平台提供的sora_image或gpt-4o-image,也无法充分利用其图像识别和处理功能。
常见受影响的模型类型
以下是一些常见的具备视觉能力但在Cherry Studio中默认无法上传图片的自定义API模型:
- sora_image:基于OpenAI Sora技术的高质量图像生成和识别模型
- gpt-4o-image:专注于图像生成的GPT-4o变种模型
- gpt-4o-all:综合处理文本和图像的GPT-4o版本
- gemini-1.5-flash-vision:Google的经济型视觉模型
- claude-3-haiku-vision:Anthropic的轻量级视觉模型
这些模型在API易等平台上都能正常处理图像输入,但在Cherry Studio中默认情况下无法上传图片。
解决方案:为自定义模型添加视觉能力
一键启用视觉能力的步骤
解决这个问题其实非常简单,只需几步操作即可让Cherry Studio识别你的自定义模型具备视觉能力:
- 打开Cherry Studio设置
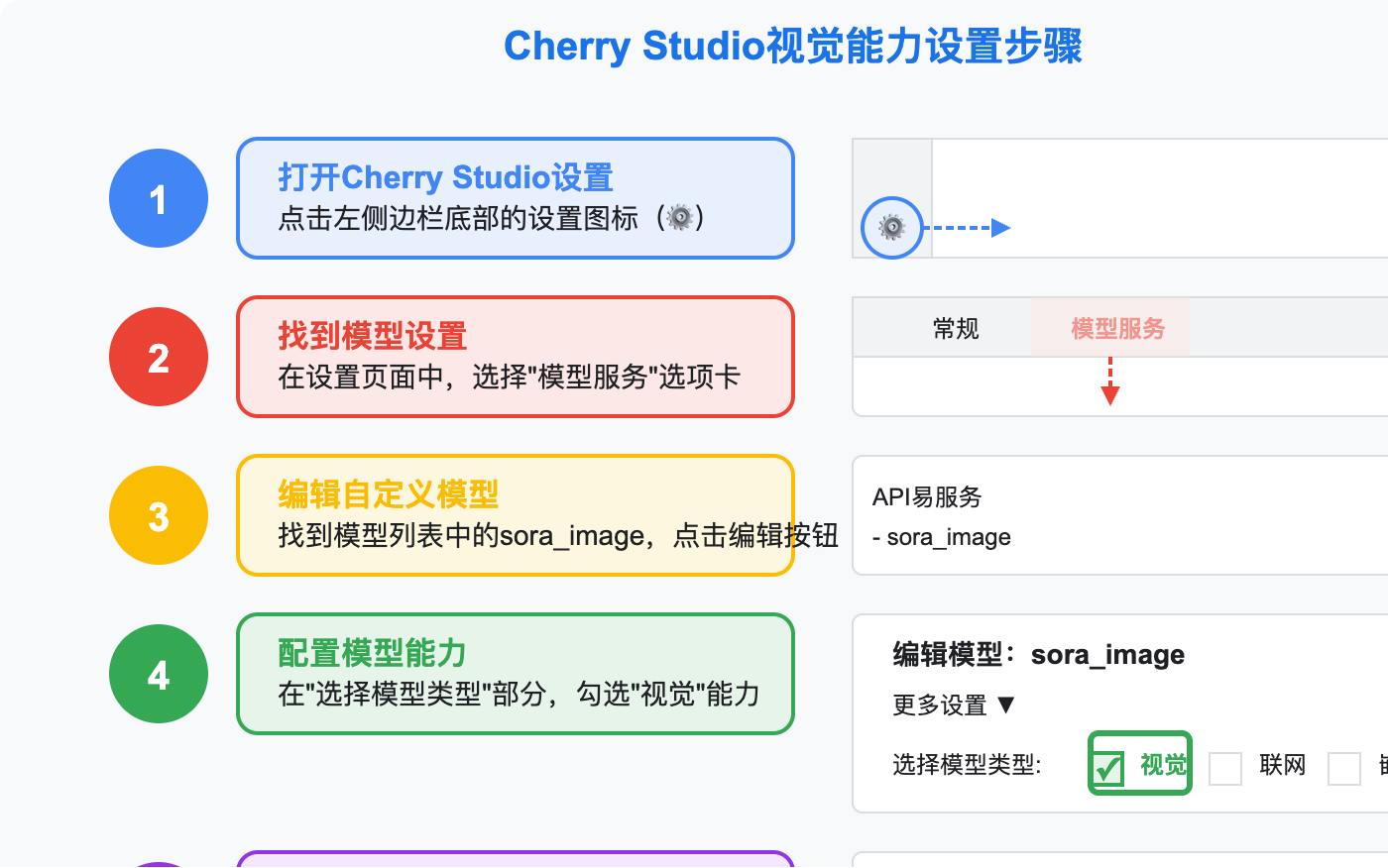
- 启动Cherry Studio
- 点击左侧边栏底部的设置图标(⚙️)
- 找到模型设置
- 在设置页面中,选择”模型服务”选项卡
- 找到你添加的第三方API服务(如”API易”)
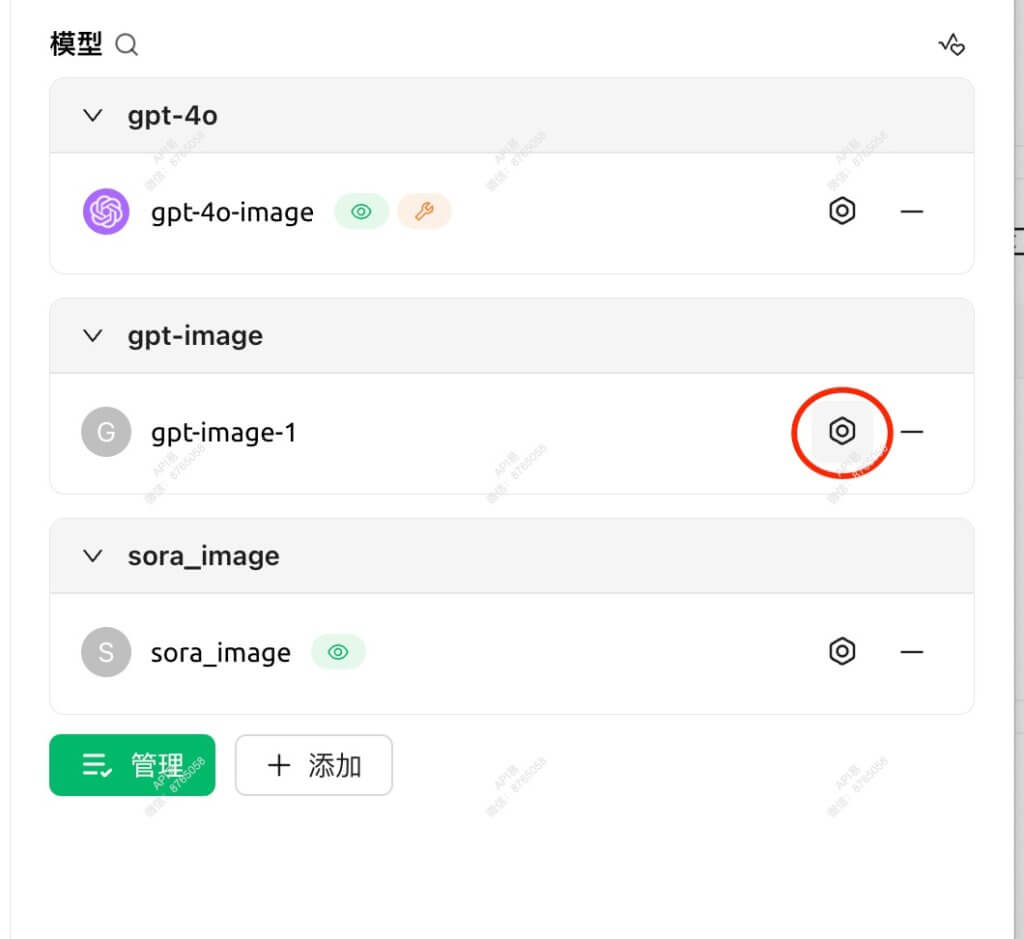
- 编辑自定义模型
- 找到列表中的目标模型(如”sora_image”)
- 点击该模型右侧的”编辑”或设置图标(如红圈标记的按钮)
- 配置模型能力
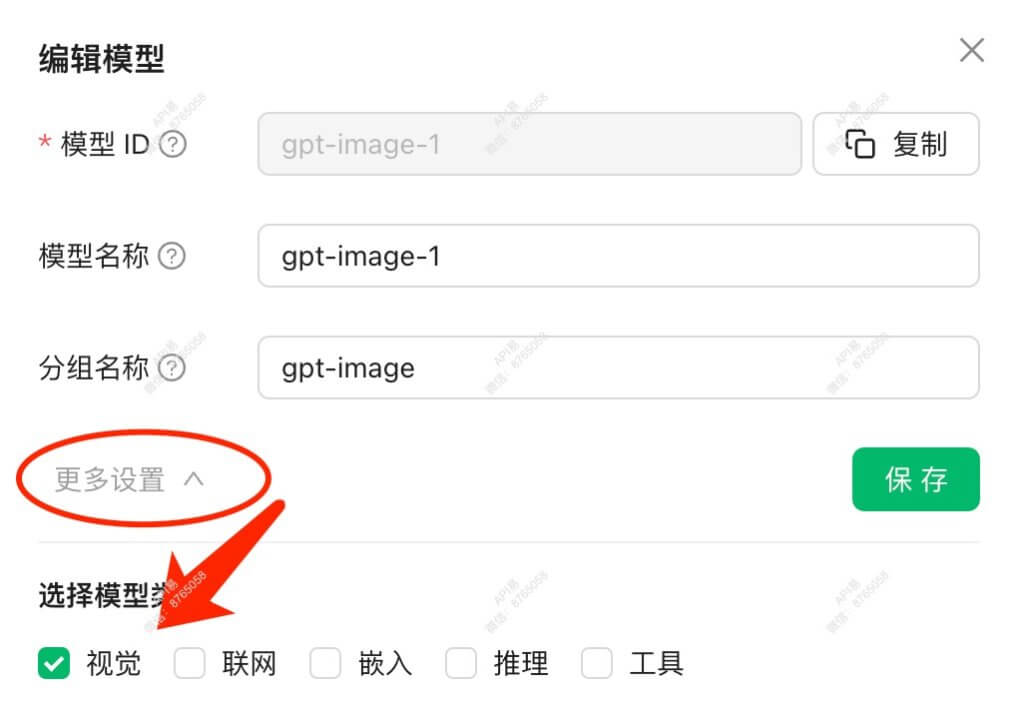
- 在模型编辑界面,找到”更多设置”或展开高级选项
- 在”选择模型类型”部分,勾选”视觉”能力
- 保存设置
- 点击”保存”按钮确认修改
- 返回聊天界面测试效果
完成这些步骤后,当你选择该模型进行对话时,Cherry Studio会自动显示图片上传按钮,允许你向模型发送图像。
视觉能力设置的位置说明
为了帮助用户更容易找到设置位置,这里提供详细说明:
- 设置入口:通常在Cherry Studio主界面左下角或右上角
- 模型服务页:在设置中寻找与”模型”、”服务”或”API”相关的选项卡
- 编辑按钮:在模型列表中,每个模型右侧通常有编辑、设置或更多选项按钮
- 视觉能力选项:在编辑界面中,寻找”模型类型”、”模型能力”或”功能设置”部分
根据Cherry Studio的版本不同,界面可能有细微差异,但基本逻辑是一致的:找到模型设置,启用视觉能力。
实际应用案例:解锁sora_image的图像识别能力
案例背景
小帅通过API易平台接入了sora_image模型到他的Cherry Studio中,希望利用其强大的图像识别和生成能力。然而,他发现虽然模型已经成功连接,但Cherry Studio不允许他上传图片。
问题解决过程
小帅按照以下步骤成功解决了问题:
- 他打开Cherry Studio,点击左下角的设置图标
- 在设置页面,他找到了”模型服务”,并找到了”API易”服务
- 在模型列表中,他找到了”sora_image”,点击了右侧的编辑按钮
- 在弹出的编辑窗口中,他找到了”更多设置”,点击展开
- 在”选择模型类型”部分,他看到了几个复选框,包括”视觉”、”联网”、”嵌入”等
- 他勾选了”视觉”选项,然后点击了”保存”按钮
- 回到聊天界面,选择sora_image模型,他发现输入框旁边出现了图片上传按钮
现在,小帅可以向sora_image模型发送图片,模型能够正确识别图像内容并提供相应回复。
效果展示
启用视觉能力前后的对比:
启用前:
- 输入框旁没有图片上传按钮
- 无法向模型发送图像
- 只能进行纯文本对话
启用后:
- 输入框旁出现图片上传按钮
- 可以轻松上传和发送图片
- 模型能够识别图像内容并做出回应
- 实现真正的多模态交互体验
其他常见模型的视觉能力配置
除了sora_image,还有许多其他自定义API模型也可以通过相同方法启用视觉能力。以下是一些常见模型的推荐配置:
gpt-4o-image与gpt-4o-all
这两个基于GPT-4o的自定义模型都具备强大的视觉处理能力:
- gpt-4o-image:专注于图像生成,建议启用”视觉”能力
- gpt-4o-all:综合处理文本和图像,建议同样启用”视觉”能力
配置后,这些模型不仅能识别图像内容,还能根据图像提供深入分析和生成相关内容。
Gemini系列视觉模型
Google的Gemini系列模型也提供了优秀的视觉能力:
- gemini-2.5-pro-03-25:专业级视觉模型
- gemini-2.5-flash:更经济的视觉选择
高级使用技巧
多模型视觉能力批量设置
如果你有多个需要启用视觉能力的模型,一个一个设置可能比较麻烦。以下是一些批量处理的技巧:
- 识别模式匹配:Cherry Studio允许对名称相似的模型应用相同设置
- 例如,可以为所有包含”vision”的模型统一启用视觉能力
- 创建模型组:将需要视觉能力的模型归入特定组
- 在Cherry Studio中创建一个新的模型组(如”视觉模型组”)
- 将所有需要视觉能力的模型添加到该组中
- 为整个组启用视觉能力设置
- 使用预设配置:创建包含视觉能力的预设配置
- 在添加新模型时应用该预设配置
- 节省重复设置的时间
视觉能力的其他相关设置
启用视觉能力后,你可能还需要调整以下相关设置以获得最佳体验:
- 图像质量设置:
- 调整上传图像的默认压缩质量
- 设置最大图像尺寸限制
- 图像处理选项:
- 开启图像预处理功能
- 设置默认图像分析级别
- 视觉模型提示词:
- 为视觉模型设置特定的系统提示词
- 引导模型如何处理图像信息
常见问题解答
为什么启用视觉能力后有时仍无法上传图片?
可能的原因及解决方案:
- 模型服务暂时不可用:
- 检查API易等服务平台的状态
- 确认账户余额是否充足
- Cherry Studio版本问题:
- 确保使用最新版本的Cherry Studio
- 旧版本可能存在功能限制
- 模型能力冲突:
- 检查是否同时启用了其他可能造成冲突的能力
- 尝试只启用视觉能力进行测试
- 重启应用:
- 有时候简单重启Cherry Studio可以解决问题
- 确保设置已正确保存
模型能正确接收图片但无法识别内容怎么办?
如果模型能接收图片但响应中没有体现对图像的理解,可能是:
- 模型实际不支持视觉:
- 确认该模型确实支持图像处理功能
- 查阅API易等平台的模型说明文档
- 图像格式或大小问题:
- 尝试不同格式的图像(JPG、PNG等)
- 调整图像分辨率和文件大小
- 提示词不清晰:
- 在发送图片时添加明确的指令
- 例如:”请分析这张图片中的内容”或”描述这张图片”
- API配置问题:
- 检查API调用参数是否正确
- 确认模型名称拼写无误
总结与展望
通过本文介绍的简单设置,你可以轻松解锁Cherry Studio中自定义API模型的视觉能力,让sora_image等模型发挥真正的多模态潜力。这不仅提升了用户体验,也让这些强大模型的应用场景更加丰富。
随着AI技术的发展,越来越多的模型将具备多模态能力。了解如何正确配置这些能力,将帮助你始终站在AI应用的前沿。无论你是使用sora_image进行创意图像生成,还是利用gpt-4o-image分析复杂图表,掌握这些设置技巧都将极大提升你的AI助手使用体验。
欢迎免费试用 API易,3 分钟跑通 API 调用 www.apiyi.com
支持sora_image、gpt-4o-image等全系列视觉模型,一键配置更方便
注册即送 1.1 美金额度起,约 300万 Tokens的 deepseek-chat 额度体验。
加站长个人微信:8765058,发送你《大模型使用指南》等资料包,并加赠 1 美金额度。