ملاحظة المؤلف: مقارنة عميقة بين نموذجي MiniMax-M2.5 و GLM-5 المفتوحي المصدر اللذين تم إطلاقهما في فبراير 2026، مع تحليل مجالات تميز كل منهما من 6 أبعاد: البرمجة، الاستنتاج، الوكلاء، السرعة، السعر، والمعمارية.
في 11-12 فبراير 2026، أطلقت شركتان صينيتان رائدتان في مجال الذكاء الاصطناعي نماذجهما الرائدة في وقت واحد تقريبًا: GLM-5 من Zhipu (بـ 744 مليار معلمة) و MiniMax-M2.5 (بـ 230 مليار معلمة). يعتمد كلاهما على معمارية MoE (خليط الخبراء) وترخيص MIT مفتوح المصدر، لكنهما يختلفان بوضوح في توجهات القدرات.
القيمة الجوهرية: بعد قراءة هذا المقال، ستدرك بوضوح أن GLM-5 يتفوق في الاستنتاج وموثوقية المعرفة، بينما يتميز MiniMax-M2.5 في البرمجة واستدعاء أدوات الوكلاء (Agents)، مما يساعدك على اتخاذ القرار الأمثل لكل سيناريو محدد.

نظرة عامة على الاختلافات الجوهرية بين MiniMax-M2.5 و GLM-5
| بُعد المقارنة | MiniMax-M2.5 | GLM-5 | الطرف المتفوق |
|---|---|---|---|
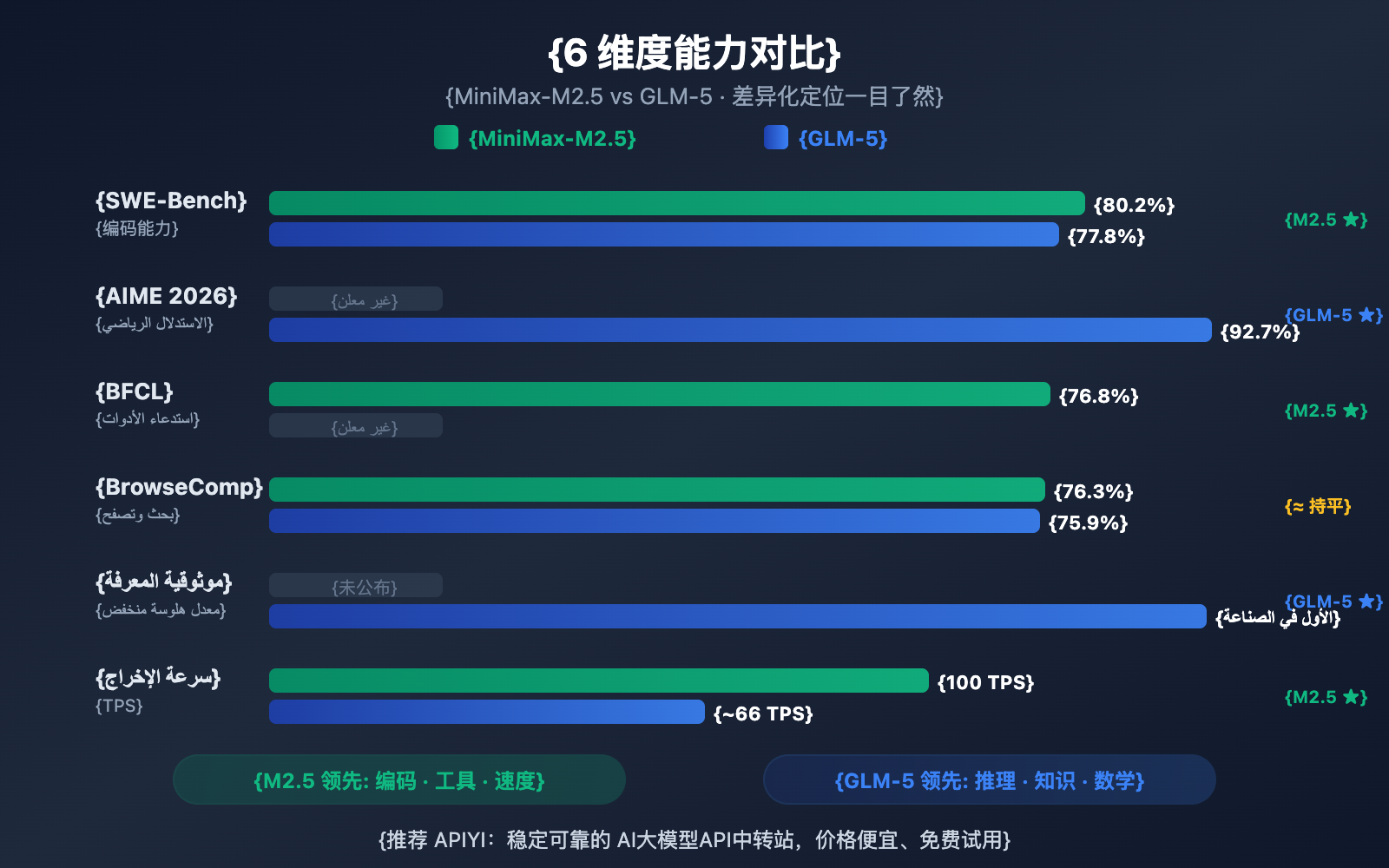
| برمجة SWE-Bench | 80.2% | 77.8% | M2.5 متفوق بـ 2.4% |
| الاستدلال الرياضي AIME | — | 92.7% | GLM-5 متميز |
| استدعاء الأدوات BFCL | 76.8% | — | M2.5 متميز |
| البحث BrowseComp | 76.3% | 75.9% | متساويان تقريباً |
| سعر المخرجات/مليون رمز | $1.20 | $3.20 | M2.5 أرخص بـ 2.7 مرة |
| سرعة المخرجات | 50-100 TPS | ~66 TPS | إصدار M2.5 Lightning أسرع |
| إجمالي المعلمات | 230B | 744B | GLM-5 أكبر |
| المعلمات النشطة | 10B | 40B | M2.5 أخف وزناً |
المزايا الأساسية لـ MiniMax-M2.5: البرمجة والوكلاء الذكيون
يُظهر MiniMax-M2.5 أداءً استثنائياً في اختبارات قياس البرمجة. فدرجة 80.2% في SWE-Bench Verified لا تجعله يتفوق على GLM-5 بنسبة 77.8% فحسب، بل تتخطى أيضاً GPT-5.2 الذي حقق 80.0%، ليأتي خلف Claude Opus 4.6 الذي حقق 80.8% بفارق ضئيل. كما سجل 51.3% في Multi-SWE-Bench الخاص بالتعاون عبر ملفات متعددة، ووصل إلى 76.8% في اختبار BFCL Multi-Turn لاستدعاء الأدوات.
تعتمد بنية M2.5 على نموذج MoE (خليط الخبراء) الذي يقوم بتنشيط 10 مليار معلمة فقط (أي 4.3% من إجمالي 230 مليار معلمة)، مما يجعله الخيار "الأخف وزناً" بين نماذج الفئة الأولى (Tier 1)، مع كفاءة استدلال عالية جداً. ويمكن أن يصل إصدار Lightning إلى 100 TPS، مما يجعله واحداً من أسرع النماذج الرائدة حالياً.
المزايا الأساسية لـ GLM-5: الاستدلال وموثوقية المعرفة
يتمتع GLM-5 بمزايا ملحوظة في مهام الاستدلال والمعرفة. فقد حقق 92.7% في الاستدلال الرياضي AIME 2026، و86.0% في الاستدلال العلمي GPQA-Diamond، كما سجل 50.4 نقطة في اختبار Humanity's Last Exam (باستخدام الأدوات)، متفوقاً على Claude Opus 4.5 الذي سجل 43.4 نقطة.
أبرز قدرات GLM-5 هي موثوقية المعرفة، حيث حقق مستوى رائد في الصناعة في تقييم الهلوسة AA-Omniscience، بتحسن قدره 35 نقطة عن الجيل السابق. بالنسبة للسيناريوهات التي تتطلب مخرجات حقائق عالية الدقة، مثل كتابة الوثائق التقنية، والمساعدة في البحوث الأكاديمية، وبناء قواعد المعرفة، فإن GLM-5 هو الخيار الأكثر موثوقية. بالإضافة إلى ذلك، فإن حجم معلمات GLM-5 البالغ 744 ملياراً وبيانات التدريب التي تصل إلى 28.5 تريليون رمز (Token) تمنحه مخزوناً معرفياً أعمق.
مقارنة تفصيلية لمهارات البرمجة بين MiniMax-M2.5 و GLM-5
تُعد القدرة على البرمجة أحد أهم المعايير التي يركز عليها المطورون عند اختيار نموذج لغة كبير. وهناك فجوة واضحة بين هذين النموذجين في هذا الجانب.
| معيار البرمجة | MiniMax-M2.5 | GLM-5 | Claude Opus 4.6 (مرجع) |
|---|---|---|---|
| SWE-Bench Verified | 80.2% | 77.8% | 80.8% |
| Multi-SWE-Bench | 51.3% | — | 50.3% |
| SWE-Bench Multilingual | — | 73.3% | 77.5% |
| Terminal-Bench 2.0 | — | 56.2% | 65.4% |
| BFCL Multi-Turn | 76.8% | — | 63.3% |
يتفوق MiniMax-M2.5 على GLM-5 في معيار SWE-Bench Verified بفارق 2.4 نقطة مئوية (80.2% مقابل 77.8%). تُعتبر هذه الفجوة كبيرة في معايير البرمجة؛ حيث تضع قدرات M2.5 البرمجية في مستوى Opus 4.6، بينما يقترب GLM-5 من مستوى Gemini 3 Pro.
يمتلك GLM-5 بيانات حول البرمجة متعددة اللغات (SWE-Bench Multilingual بنسبة 73.3%) والبرمجة في بيئة الطرفية (Terminal-Bench بنسبة 56.2%)، مما يظهر قدرات برمجية من زوايا مختلفة. ومع ذلك، في المعيار الأساسي SWE-Bench Verified، تظل أفضلية M2.5 واضحة.
يتميز M2.5 أيضاً بكفاءة البرمجة، حيث يستغرق إكمال مهمة واحدة في SWE-Bench حوالي 22.8 دقيقة فقط، وهو تحسن بنسبة 37% عن الجيل السابق M2.1. يعود الفضل في ذلك إلى أسلوب البرمجة الفريد "Spec-writing" – الذي يقوم أولاً بتفكيك الهيكل المعماري ثم التنفيذ بكفاءة، مما يقلل من حلقات التجربة والخطأ غير المجدية.
🎯 نصيحة لسيناريوهات البرمجة: إذا كان احتياجك الأساسي هو البرمجة بمساعدة الذكاء الاصطناعي (إصلاح الأخطاء، مراجعة الكود، تنفيذ الميزات)، فإن MiniMax-M2.5 هو الخيار الأفضل. يمكنك الوصول إلى كلا النموذجين لإجراء اختبارات مقارنة عملية عبر APIYI (apiyi.com).
مقارنة تفصيلية لقدرات الاستنتاج بين MiniMax-M2.5 و GLM-5
تكمن القوة الأساسية لنموذج GLM-5 في قدرات الاستنتاج، خاصة في مجالات الرياضيات والعلوم.
| معيار الاستنتاج | MiniMax-M2.5 | GLM-5 | التوضيح |
|---|---|---|---|
| AIME 2026 | — | 92.7% | استنتاج رياضي بمستوى الأولمبياد |
| GPQA-Diamond | — | 86.0% | استنتاج علمي بمستوى الدكتوراه |
| Humanity's Last Exam (w/tools) | — | 50.4 | يتجاوز 43.4 لنموذج Opus 4.5 |
| HMMT Nov. 2025 | — | 96.9% | قريب من 97.1% لنموذج GPT-5.2 |
| τ²-Bench | — | 89.7% | استنتاج في مجال الاتصالات |
| AA-Omniscience موثوقية المعرفة | — | رائد في الصناعة | أقل معدل هلوسة |
اعتمد GLM-5 طريقة تدريب جديدة تسمى SLIME (بنية تحتية للتعلم المعزز غير المتزامن)، مما أدى إلى تحسين كبير في كفاءة ما بعد التدريب. وقد مكن هذا GLM-5 من تحقيق قفزة نوعية في مهام الاستنتاج:
- درجة 92.7% في AIME 2026، وهي قريبة من درجة Claude Opus 4.5 البالغة 93.3%، وتتجاوز بكثير مستويات عصر GLM-4.5.
- 86.0% في GPQA-Diamond، وهي قدرة استنتاج علمي بمستوى الدكتوراه، تقترب من 87.0% لنموذج Opus 4.5.
- 50.4 نقطة في Humanity's Last Exam (مع الأدوات)، متفوقاً على 43.4 نقطة لـ Opus 4.5 و 45.5 نقطة لـ GPT-5.2.
الميزة الأكثر تفرداً في GLM-5 هي موثوقية المعرفة. في تقييم الهلوسة AA-Omniscience، تحسن GLM-5 بمقدار 35 نقطة عن الجيل السابق، ليصل إلى مستوى رائد في الصناعة. وهذا يعني أن GLM-5 يميل أقل إلى "اختلاق" المحتوى عند الإجابة على الأسئلة الواقعية، وهو أمر ذو قيمة هائلة للسيناريوهات التي تتطلب مخرجات معلومات عالية الدقة.
البيانات المتعلقة باستنتاج MiniMax-M2.5 أقل علانية، حيث يتركز تدريبه الأساسي على التعلم المعزز في سيناريوهات البرمجة والوكلاء الذكيين. يركز إطار عمل Forge RL الخاص بـ M2.5 على تفكيك المهام وتحسين استدعاء الأدوات في أكثر من 200 ألف بيئة حقيقية، بدلاً من قدرات الاستنتاج البحتة.
توضيح المقارنة: إذا كان احتياجك الأساسي هو الاستنتاج الرياضي، التحليل العلمي، أو كنت بحاجة إلى إجابات معرفية عالية الموثوقية، فإن GLM-5 يتفوق هنا. نقترح اختبار الفرق في الأداء بين الاثنين في مهام الاستنتاج الخاصة بك عبر منصة APIYI (apiyi.com).
مقارنة قدرات الوكلاء والبحث بين MiniMax-M2.5 و GLM-5

| معيار الوكيل | MiniMax-M2.5 | GLM-5 | الطرف المتفوق |
|---|---|---|---|
| BFCL متعدد الجولات | 76.8% | — | تفوق M2.5 في استدعاء الأدوات |
| BrowseComp (مع السياق) | 76.3% | 75.9% | متساويان تقريباً |
| MCP Atlas | — | 67.8% | تنسيق GLM-5 للأدوات المتعددة |
| Vending Bench 2 | — | $4,432 | تخطيط GLM-5 طويل المدى |
| τ²-Bench | — | 89.7% | استنتاج GLM-5 في المجالات المتخصصة |
يُظهر النموذجان تمايزاً واضحاً في قدرات الوكلاء (Agents):
MiniMax-M2.5 يبرع في "الوكلاء التنفيذيين": حيث يقدم أداءً ممتازاً في السيناريوهات التي تتطلب استدعاءً متكرراً للأدوات، وتكراراً سريعاً، وتنفيذاً عالي الكفاءة. وتعني نسبة 76.8% في معيار BFCL أن M2.5 قادر على استخدام الأدوات بدقة، مثل استدعاء الدوال، وعمليات الملفات، والتفاعل مع واجهات برمجة التطبيقات (APIs)، مع تقليل جولات استدعاء الأدوات بنسبة 20% مقارنة بالجيل السابق. وداخلياً في شركة MiniMax، يتم توليد 80% من الأكواد البرمجية الجديدة بواسطة M2.5، كما ينجز 30% من المهام اليومية.
GLM-5 يبرع في "الوكلاء صانعي القرار": حيث يتمتع بميزة أكبر في السيناريوهات التي تتطلب استنتاجاً عميقاً، وتخطيطاً طويل المدى، واتخاذ قرارات معقدة. تُظهر نسبة 67.8% في معيار MCP Atlas قدرته على تنسيق الأدوات على نطاق واسع، بينما تعكس أرباح المحاكاة البالغة 4,432 دولاراً في Vending Bench 2 قدرته على التخطيط للأعمال لفترات زمنية طويلة، وتُظهر نسبة 89.7% في τ²-Bench استنتاجاً عميقاً في مجالات محددة.
كلا النموذجين متساويان تقريباً في قدرات البحث وتصفح الويب — بنسبة 76.3% مقابل 75.9% في معيار BrowseComp، مما يجعلهما رائدين في هذا المجال.
🎯 نصيحة لسيناريوهات الوكلاء: اختر M2.5 لاستدعاء الأدوات عالي التردد والبرمجة التلقائية؛ واختر GLM-5 لاتخاذ القرارات المعقدة والتخطيط طويل المدى. تدعم منصة APIYI (apiyi.com) كلا النموذجين في وقت واحد، مما يتيح لك التبديل بينهما بمرونة حسب السيناريو.
مقارنة الهندسة والتكلفة بين MiniMax-M2.5 و GLM-5
| الهندسة والتكلفة | MiniMax-M2.5 | GLM-5 |
|---|---|---|
| إجمالي عدد المعلمات | 230B | 744B |
| عدد المعلمات النشطة | 10B | 40B |
| نسبة التنشيط | 4.3% | 5.4% |
| بيانات التدريب | — | 28.5 تريليون توكن (Token) |
| نافذة السياق | 205K | 200K |
| الحد الأقصى للمخرجات | — | 131K |
| سعر الإدخال | $0.15 لكل مليون (الإصدار القياسي) | $1.00 لكل مليون |
| سعر الإخراج | $1.20 لكل مليون (الإصدار القياسي) | $3.20 لكل مليون |
| سرعة الإخراج | 50-100 TPS | ~66 TPS |
| شرائح التدريب | — | هواوي أسيند 910 (Huawei Ascend 910) |
| إطار عمل التدريب | Forge RL | SLIME Asynchronous RL |
| آلية الانتباه | — | DeepSeek Sparse Attention |
| رخصة المصدر المفتوح | MIT | MIT |
تحليل مزايا هندسة MiniMax-M2.5
تكمن الميزة الجوهرية لهندسة M2.5 في "الخفة الفائقة"؛ فمن خلال تنشيط 10 مليار معلمة فقط، استطاع تحقيق قدرات برمجية تقترب من نموذج Opus 4.6. وهذا يؤدي إلى:
- تكلفة استدلال منخفضة للغاية: سعر الإخراج هو 1.20 دولار لكل مليون توكن، وهو ما يمثل 37% فقط من تكلفة GLM-5.
- سرعة استدلال فائقة: يصل إصدار Lightning إلى 100 توكن في الثانية (TPS)، وهو أسرع بنسبة 52% من GLM-5 الذي تبلغ سرعته حوالي 66 TPS.
- عتبة نشر أقل: بفضل وجود 10 مليار معلمة نشطة فقط، هناك إمكانية لنشر النموذج حتى على وحدات معالجة الرسوميات (GPUs) المخصصة للمستهلكين.
تحليل مزايا هندسة GLM-5
تمنح المعلمات الإجمالية البالغة 744 مليار والمعلمات النشطة البالغة 40 مليار نموذج GLM-5 سعة معرفية أكبر وعمقاً أقوى في الاستدلال:
- مخزون معرفي أكبر: تم تدريبه على 28.5 تريليون توكن، وهو ما يتجاوز الأجيال السابقة بمراحل.
- قدرة استدلال أعمق: تدعم المعلمات النشطة الـ 40 مليار سلاسل استدلال أكثر تعقيداً.
- استقلالية قوة الحوسبة: تم التدريب بالكامل باستخدام شرائح هواوي أسيند (Huawei Ascend)، مما يحقق استقلالية في موارد الحوسبة.
- آلية DeepSeek Sparse Attention: تتيح معالجة فعالة للسياقات الطويلة التي تصل إلى 200 ألف توكن.
نصيحة: بالنسبة للسيناريوهات الحساسة للتكلفة والتي تتطلب استدعاءات متكررة، فإن ميزة السعر في M2.5 واضحة جداً (سعر الإخراج 37% فقط من GLM-5). ننصحك بإجراء اختبارات فعلية لكلا النموذجين عبر منصة APIYI (apiyi.com) لتقييم نسبة الأداء مقابل السعر في مهامك الخاصة.
الوصول السريع إلى واجهة برمجة التطبيقات (API) لـ MiniMax-M2.5 و GLM-5
يمكنك استخدام منصة APIYI لتوحيد الواجهة واستدعاء كلا النموذجين في نفس الوقت، مما يسهل المقارنة السريعة:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# اختبار مهام البرمجة - M2.5 يتفوق هنا
code_task = "قم بتنفيذ طابور متزامن بدون أقفال (lock-free concurrent queue) باستخدام لغة Rust"
m25_result = client.chat.completions.create(
model="MiniMax-M2.5",
messages=[{"role": "user", "content": code_task}]
)
# اختبار مهام الاستدلال - GLM-5 يتفوق هنا
reason_task = "أثبت أن كل عدد زوجي أكبر من 2 يمكن تمثيله كمجموع عددين أوليين (فكرة التحقق من حدسية غولدباخ)"
glm5_result = client.chat.completions.create(
model="glm-5",
messages=[{"role": "user", "content": reason_task}]
)
نصيحة: احصل على رصيد اختبار مجاني عبر APIYI (apiyi.com)، وقم باختبار النموذجين بناءً على سيناريوهاتك المحددة. جرب M2.5 لمهام البرمجة، و GLM-5 لمهام الاستدلال، لتجد الحل الأمثل لك.
الأسئلة الشائعة
س1: بماذا يتميز كل من MiniMax-M2.5 وGLM-5؟
يتفوق MiniMax-M2.5 في البرمجة واستدعاء أدوات الوكيل الذكي (Agent Tools) – حيث حقق 80.2% في اختبار SWE-Bench مقترباً من Opus 4.6، وحصل على 76.8% في اختبار BFCL ليتصدر الصناعة. أما GLM-5 فيتميز في الاستنتاج وموثوقية المعرفة – حيث حقق 92.7% في AIME، و86.0% في GPQA، مع أدنى معدل هلوسة في الصناعة. باختصار: اختر M2.5 لكتابة الأكواد، واختر GLM-5 لمهام الاستنتاج.
س2: ما هو فرق السعر بين النموذجين؟
يبلغ سعر مخرجات MiniMax-M2.5 (الإصدار القياسي) 1.20 دولار لكل مليون توكن، بينما يبلغ سعر مخرجات GLM-5 حوالي 3.20 دولار لكل مليون توكن، مما يجعل M2.5 أرخص بنحو 2.7 مرة. إذا اخترت إصدار M2.5 Lightning فائق السرعة (2.40 دولار/مليون توكن)، فسيكون السعر قريباً من GLM-5 ولكن بسرعة أكبر. يمكنك الاستمتاع بخصومات عند الشحن من خلال الوصول عبر منصة APIYI (apiyi.com).
س3: كيف يمكنني مقارنة الأداء الفعلي للنموذجين بسرعة؟
نوصي بالوصول الموحد عبر منصة APIYI (apiyi.com):
- قم بتسجيل حساب للحصول على مفتاح API ورصيد مجاني.
- جهّز نوعين من مهام الاختبار: مهام برمجية ومهام استنتاجية.
- قم باستدعاء كل من MiniMax-M2.5 وGLM-5 لنفس المهمة.
- قارن جودة المخرجات، سرعة الاستجابة، واستهلاك التوكنز.
- بفضل الواجهة المتوافقة مع OpenAI، يمكنك التبديل بين النماذج فقط عبر تغيير بارامتر
model.
الخلاصة
الاستنتاجات الجوهرية لمقارنة MiniMax-M2.5 مقابل GLM-5:
- M2.5 هو الخيار الأول للبرمجة: حقق 80.2% في SWE-Bench مقابل 77.8% لـ GLM-5، متفوقاً بنسبة 2.4%، كما يتصدر الصناعة في استدعاء أدوات BFCL بنسبة 76.8%.
- GLM-5 هو الخيار الأول للاستنتاج: حقق 92.7% في AIME، و86.0% في GPQA، و50.4 نقطة في اختبار Humanity's Last Exam متجاوزاً Opus 4.5.
- تفوق GLM-5 في موثوقية المعرفة: حصل على المركز الأول في تقييم الهلوسة AA-Omniscience، مما يجعل مخرجاته الواقعية أكثر جدارة بالثقة.
- M2.5 يتفوق في القيمة مقابل السعر: سعر مخرجاته يمثل 37% فقط من سعر GLM-5، مع سرعة أكبر في إصدار Lightning.
كلا النموذجين مفتوح المصدر بترخيص MIT ويعتمدان بنية MoE، لكن توجهاتهما مختلفة تماماً: M2.5 هو "ملك البرمجة والوكلاء التنفيذيين"، بينما GLM-5 هو "رائد الاستنتاج وموثوقية المعرفة". ننصح بالتبديل المرن بينهما عبر منصة APIYI (apiyi.com) حسب احتياجاتك الفعلية، والمشاركة في عروض الشحن للحصول على أفضل الأسعار.
📚 المراجع
-
الإعلان الرسمي عن MiniMax M2.5: قدرات البرمجة الجوهرية لـ M2.5 وتفاصيل تدريب Forge RL
- الرابط:
minimax.io/news/minimax-m25 - الوصف: بيانات المعايير المرجعية الكاملة مثل SWE-Bench 80.2% وBFCL 76.8% وغيرها.
- الرابط:
-
الإصدار الرسمي لـ GLM-5: بنية MoE بسعة 744B لنموذج Zhipu GLM-5 وتقنية التدريب SLIME
- الرابط:
docs.z.ai/guides/llm/glm-5 - الوصف: يتضمن بيانات معايير الاستدلال مثل AIME 92.7% وGPQA 86.0% وغيرها.
- الرابط:
-
تقييم مستقل من Artificial Analysis: اختبارات المعايير المرجعية الموحدة والتصنيفات لكلا النموذجين
- الرابط:
artificialanalysis.ai/models/glm-5 - الوصف: بيانات مستقلة تشمل مؤشر الذكاء (Intelligence Index)، واختبارات السرعة الفعلية، ومقارنة الأسعار.
- الرابط:
-
تحليل عميق من BuildFastWithAI: اختبارات معايير شاملة لـ GLM-5 ومقارنة مع المنافسين
- الرابط:
buildfastwithai.com/blogs/glm-5-released-open-source-model-2026 - الوصف: جدول مقارنة مفصل مع Opus 4.5 وGPT-5.2.
- الرابط:
-
MiniMax على HuggingFace: أوزان نموذج M2.5 مفتوح المصدر
- الرابط:
huggingface.co/MiniMaxAI - الوصف: ترخيص MIT، يدعم النشر باستخدام vLLM/SGLang.
- الرابط:
المؤلف: فريق APIYI
التواصل التقني: نرحب بمشاركة نتائج اختبارات مقارنة النماذج الخاصة بك في قسم التعليقات. لمزيد من دروس دمج واجهات برمجة التطبيقات (API) لنماذج الذكاء الاصطناعي، يمكنك زيارة مجتمع APIYI التقني على apiyi.com.