2026 年 7 月 1 日,Anthropic 正式宣布 Claude Fable 5 恢复全球可用。这款 6 月 9 日发布、仅上线三天就被下架的 Mythos 级旗舰模型,在经历了近三周的"消失"之后,带着一套全新的安全分类器回到了 Claude API、Amazon Bedrock 等各大平台。对开发者来说,这不只是一条新闻,更是一次实实在在的接入机会。
不过,回归后的 claude-fable-5 和一般的 Claude 模型有几个明显不同:自适应思考(Adaptive Thinking)强制开启、请求可能被安全分类器拒绝并返回 stop_reason: "refusal"、需要为集成代码增加降级(fallback)逻辑。这些变化直接影响你的调用代码怎么写。
本文将从时间线、模型规格、API 接入、拒绝响应处理四个维度完整解读 Claude Fable 5 回归,并给出可直接运行的代码示例。如果你希望跳过 AWS 账号申请等繁琐流程,可以通过 API易 apiyi.com 提供的 AWS Claude 官方转发通道直接调用 claude-fable-5,模型名与官方完全一致。
Claude Fable 5 回归时间线:从下线到重新上线
要理解这次回归的意义,先要弄清楚 Claude Fable 5 到底经历了什么。根据 Anthropic 官方公告和多家外媒的报道,整个事件的时间线如下表所示。
| 时间 | 事件 |
|---|---|
| 2026年6月9日 | Claude Fable 5 与 Claude Mythos 5 正式发布,Fable 5 在 Claude API、Amazon Bedrock、Google Cloud、Microsoft Foundry 全面上线 |
| 2026年6月12日 | 因美国商务部出口管制指令,Fable 5 与 Mythos 5 被强制下线 |
| 2026年6月中下旬 | Anthropic 与美国政府沟通,针对性开发新一代网络安全分类器 |
| 2026年7月1日 | 出口管制限制解除,Claude Fable 5 携新安全分类器全球恢复上线 |
| 2026年7月1日-7日 | 订阅端促销期:Pro/Max/Team 及企业高级席位可免费使用至周限额的 50% |
下线的直接导火索,是 Amazon 研究团队发现了一种绕过 Fable 5 安全防护的越狱手法,可以诱导模型识别软件漏洞。美国政府认为这构成了严重的网络安全风险,商务部随即下达了出口管制指令。这也是 AI 行业首次出现旗舰模型因政府指令被全面下架的案例。
回归版本的核心变化是新增了一套针对网络安全任务的分类器。Anthropic 表示,新分类器可以在 99% 以上的情况下拦截 Amazon 报告中提到的越狱技术,并且通过了美国 AI 标准与创新中心(CAISI)的验证。代价是部分正常的编码和调试任务也可能被误伤,这正是后文要重点讲的 refusal 处理机制存在的原因。

claude-fable-5 模型规格与定价:比 Opus 更高一档
Claude Fable 5 是 Anthropic 全新 Mythos 级模型层的首发成员,定位在 Claude Opus 之上,是目前 Anthropic 能力最强的公开可用模型。它与仅限 Project Glasswing 审批客户使用的 Claude Mythos 5 共享同一底层模型,区别在于 Fable 5 内置了安全分类器,而 Mythos 5 没有。
对开发者而言,最关键的规格参数如下表。
| 规格项 | claude-fable-5 参数 |
|---|---|
| API 模型名 | claude-fable-5 |
| 上下文窗口 | 默认 1M(100 万)token |
| 单次最大输出 | 128K token |
| 输入价格 | $10 / 百万 token |
| 输出价格 | $50 / 百万 token |
| 思考模式 | 自适应思考强制开启,不支持关闭 |
| 数据保留 | 30 天,不支持零数据保留(ZDR) |
| 可用平台 | Claude API、Amazon Bedrock、Google Cloud、Microsoft Foundry |
有两点值得展开说明。第一,1M token 的上下文窗口是默认配置而非需要申请的 beta 特性,这意味着整个中型代码仓库、数百页文档可以一次性喂给模型,对长文档分析和大型代码库重构类任务是质的提升。第二,自适应思考是 claude-fable-5 唯一的思考模式,thinking: {"type": "disabled"} 会直接报错,你只能通过 effort 参数来控制思考深度和成本,这一点从 Opus 4.8 迁移过来的代码需要特别注意。
除了基础规格,claude-fable-5 回归时的功能支持面也值得关注。它在上线首日就支持了 Anthropic 近一年推出的几乎全部 Agent 基础设施,这也是它被定位为"长程 Agent 任务首选模型"的底气所在。具体支持情况如下表。
| 功能 | 状态 | 对开发者的价值 |
|---|---|---|
| effort 参数 | 正式可用 | 控制思考深度,替代已移除的 thinking 开关 |
| 记忆工具(memory tool) | 正式可用 | 跨会话持久化上下文,适合长期 Agent |
| 代码执行(code execution) | 正式可用 | 模型侧直接运行代码验证结果 |
| 程序化工具调用 | 正式可用 | 在代码中批量编排工具,减少往返 token |
| 任务预算(task budgets) | beta | 通过 header 为任务设定 token 上限 |
| 上下文编辑(context editing) | beta | 自动清理旧工具结果,压缩长会话成本 |
| 压缩(compaction)与视觉理解 | 正式可用 | 长会话自动摘要;支持图像输入 |
这份清单对架构选型的意义在于:如果你的 Agent 系统此前为了用记忆工具或代码执行而绑定在 Sonnet 上,现在 claude-fable-5 提供了同一套接口下能力更强的选项,迁移只需要改模型名和适配 refusal 处理。
促销方面需要区分清楚:7 月 1 日至 7 日的免费额度(周限额的 50%)只针对 Claude 订阅端的 Pro、Max、Team 和企业高级席位用户,参考文档: support.claude.com/en/articles/15424964。API 调用不参与促销,始终按 $10/$50 的标准费率单独计费。所以对 API 开发者来说,回归后接入的成本考量重点在于如何用 effort 参数控制输出 token,而不是赶促销窗口。
🎯 选型建议:$50/百万的输出价格意味着 claude-fable-5 适合"少量高价值调用"场景,如复杂推理、长程 Agent 任务、大规模代码审查,而不适合高频轻量任务。我们建议通过 API易 apiyi.com 平台先小流量实测,该平台支持 claude-fable-5 与 Opus、Sonnet 等模型的统一接口切换,方便你用同一套代码对比效果与成本后再做决策。
claude-fable-5 API 快速上手:3 步完成接入
Claude Fable 5 恢复上线后,官方渠道需要 Claude API 账号或 AWS Bedrock 权限(Bedrock 模型 ID 为 anthropic.claude-fable-5)。国内开发者更常见的做法是通过聚合平台接入,API易提供的正是 AWS Claude 官方转发通道,即请求经由 AWS Bedrock 官方线路转发,模型名保持 claude-fable-5 不变,兼容 OpenAI 与 Anthropic 两种调用格式。
第 1 步:获取 API Key
注册 API易 apiyi.com 账号后,在控制台创建 API Key。新用户有免费测试额度,可以先验证 claude-fable-5 的实际表现再充值。
第 2 步:发送第一个请求
以下是使用 curl 的最简调用示例,将 base_url 指向 API易 的接口地址即可:
curl https://api.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $APIYI_API_KEY" \
-d '{
"model": "claude-fable-5",
"messages": [
{"role": "user", "content": "用一段话解释什么是自适应思考"}
],
"max_tokens": 1024
}'
Python 版本同样简单,使用 OpenAI SDK 只需修改 base_url:
from openai import OpenAI
client = OpenAI(
api_key="你的APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
resp = client.chat.completions.create(
model="claude-fable-5",
messages=[{"role": "user", "content": "分析这段代码的时间复杂度"}],
max_tokens=2048
)
print(resp.choices[0].message.content)
第 3 步:用 effort 参数控制思考深度
由于自适应思考无法关闭,控制成本的正确方式是调节 effort 参数。低 effort 适合格式转换、摘要类简单任务,高 effort 留给数学推理、架构设计等硬核场景。另外要注意,claude-fable-5 永远不会返回原始思维链,thinking.display 设为 "summarized" 时返回推理摘要,默认的 "omitted" 则返回空的 thinking 字段,依赖思维链做调试的工作流需要调整预期。
多轮对话还有一个容易被忽略的细节:在同一个会话中,需要把上一轮返回的 thinking 块原样传回给模型,不要修改或删除,否则可能影响推理连贯性;跨模型切换会话(比如从 claude-fable-5 降级到 Opus 4.8 继续对话)时,则需要按官方指引处理 thinking 块的兼容问题。这类细节在自建对接时很容易踩坑,通过成熟聚合平台接入时通常已在网关层做好了兼容处理。
不同任务类型的参数建议如下表:
| 任务类型 | effort 建议 | max_tokens 建议 | 成本水平 |
|---|---|---|---|
| 摘要、格式转换 | low | 1K-2K | 低 |
| 常规代码生成 | medium | 4K-8K | 中 |
| 复杂推理、数学证明 | high | 16K+ | 高 |
| 长程 Agent 任务、大型重构 | high | 32K-128K | 很高 |
💡 实践提示:如果你的业务同时有轻量任务和重度任务,不必全部走 claude-fable-5。通过 API易 apiyi.com 的统一接口,可以按任务难度把请求路由到 claude-fable-5、Opus 4.8 或 Sonnet,同一套鉴权和代码结构,整体成本通常能降低一半以上。
Claude Fable 5 拒绝响应(refusal)处理:回归后最大的集成变化
这是 claude-fable-5 回归后与所有旧版 Claude 模型最大的不同,也是官方文档反复强调的集成要点。由于新安全分类器的存在,模型可能拒绝某些请求,尤其是涉及漏洞分析、渗透测试的网络安全类任务,少数正常的编码调试请求也可能被误判。
关键在于:拒绝不是错误。当分类器拦截请求时,Messages API 返回的是 HTTP 200 成功响应,stop_reason 字段值为 "refusal",响应中还会标明是哪个分类器做出的拦截。如果你的代码只检查 HTTP 状态码,会把拒绝响应当成正常输出处理,这是集成时最容易踩的坑。
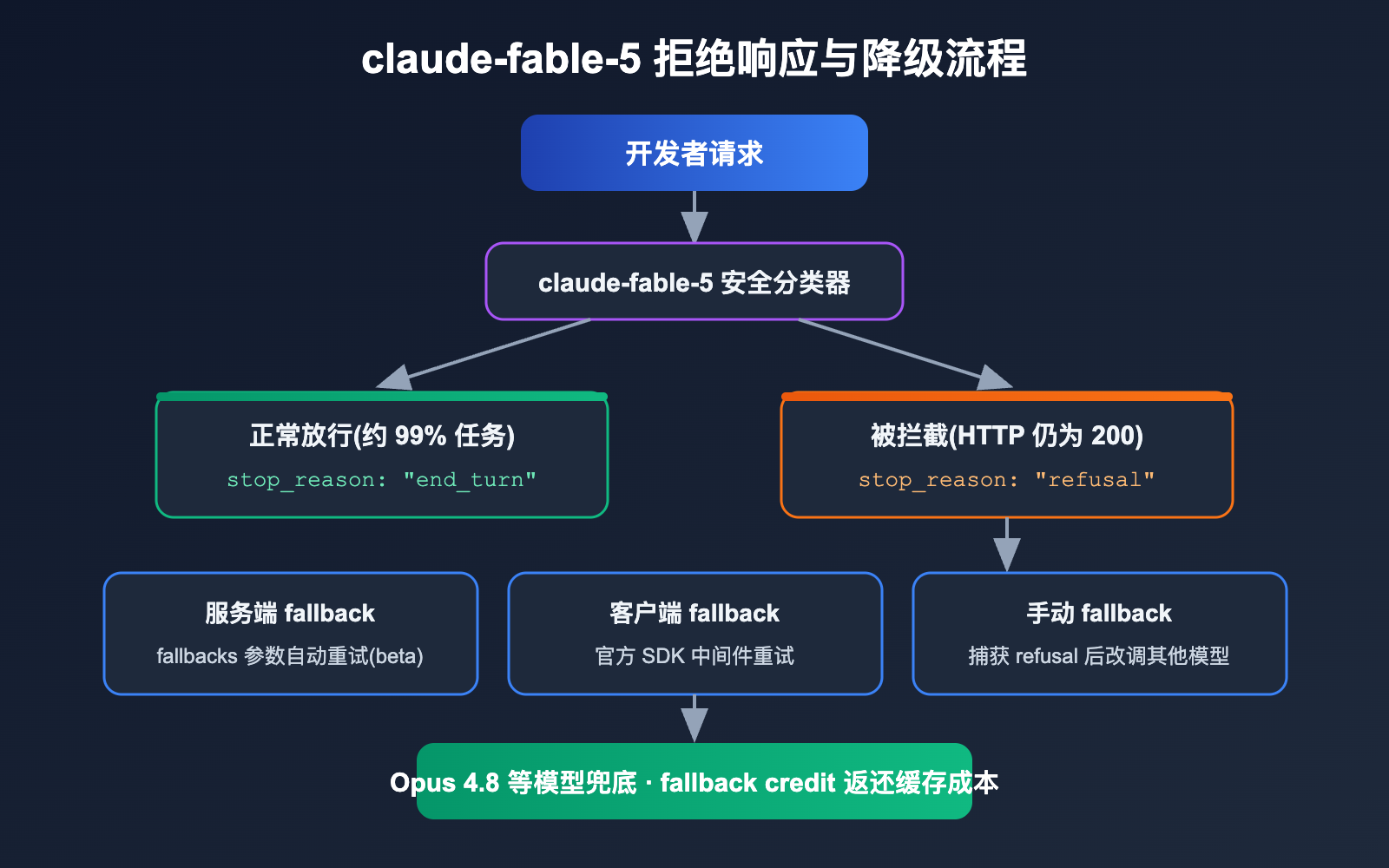
好消息是,被 Fable 5 拒绝的请求通常可以由其他 Claude 模型正常完成,官方为此提供了三种降级方案:
| 降级方案 | 实现方式 | 适用场景 |
|---|---|---|
| 服务端 fallback | 请求中传入 fallbacks 参数,API 自动重试(beta) |
希望零代码改动,接受 beta 状态 |
| 客户端 fallback | 官方 SDK 中间件(Python/TS/Go/Java/C#)自动重试 | 需要跨平台一致行为 |
| 手动 fallback | 自行捕获 stop_reason: "refusal" 后改调其他模型 |
需要完全控制重试逻辑 |
计费规则也做了相应设计:在产生任何输出之前被拒绝的请求不计费;通过 fallback 重试到其他模型时,fallback credit 机制会返还切换产生的提示词缓存成本,避免同一份上下文付两次钱。
除了实现降级本身,我们还建议在网关或应用层记录每次请求的 stop_reason,并对 refusal 占比做监控告警。一方面,refusal 率突然升高往往意味着 Anthropic 调整了分类器策略,需要及时评估业务影响;另一方面,长期数据能帮你识别哪类 prompt 容易触发误伤,通过改写提示词(例如避免"扫描漏洞""绕过限制"等敏感表述)可以显著降低被拦截的概率。
手动降级的核心逻辑大约十行代码:
resp = call_model("claude-fable-5", messages)
if resp.stop_reason == "refusal":
# 被安全分类器拦截,降级到 Opus 4.8 重试
resp = call_model("claude-opus-4-8", messages)
🎯 架构建议:生产环境接入 claude-fable-5 时,务必把 refusal 处理纳入上线检查清单。我们推荐在 API易 apiyi.com 平台上同时开通 claude-fable-5 和 claude-opus-4-8 两个模型,因为两者共用同一个 base_url 和 API Key,上面这段降级代码不需要任何额外的鉴权配置就能直接运行。
Claude Fable 5 常见问题 FAQ
Q1:Claude Fable 5 和 Claude Mythos 5 有什么区别?我该用哪个?
两者是同一个底层模型,能力和定价完全一致。区别在于 Fable 5 内置安全分类器、公开可用,Mythos 5 无分类器、仅向 Project Glasswing 审批客户开放。对绝大多数开发者来说,claude-fable-5 是唯一可选项,也完全够用。
Q2:7 月 1 日-7 日的促销对 API 调用有效吗?
无效。促销仅覆盖 Claude 订阅端(Pro/Max/Team/企业高级席位),额度为周限额的 50%。API 调用始终按 $10/$50 每百万 token 标准计费,通过 API易 apiyi.com 接入的 claude-fable-5 按实际用量计费,无月费门槛,适合先小规模验证。
Q3:回归版的 claude-fable-5 会不会经常拒绝正常请求?
Anthropic 表示约 99% 的常规任务不受影响,但涉及漏洞挖掘、安全审计的请求被拦截的概率显著提高,普通编码调试偶尔也会误伤。生产环境务必实现 fallback 逻辑,把被拒请求自动路由到 Opus 4.8 等模型兜底。
Q4:模型会因为政策原因再次下线吗?
无法完全排除,但这次回归经过了 CAISI 验证、出口管制正式解除,短期内再次下线的风险较低。从架构上防范的方法就是不要硬编码单一模型:通过聚合平台的统一接口接入,一旦某个模型不可用,改一行模型名即可切换到 Opus 4.8 等备选模型,业务不中断。
Q5:通过 AWS 官转调用 claude-fable-5,和直连 Anthropic API 有什么区别?
模型本体完全一致,权重、能力、安全分类器行为都相同。区别主要在接入体验:直连 Anthropic 需要海外支付方式和网络环境,Bedrock 直连则需要 AWS 账号和模型开通审批(Bedrock 侧模型 ID 为 anthropic.claude-fable-5)。API易 apiyi.com 的 AWS 官方转发通道把这两步都省掉了,模型名沿用 claude-fable-5,人民币计费,同时保留了 Bedrock 官方线路的稳定性,对国内团队是更省事的选择。
Q6:1M 上下文实际用起来要注意什么?
超长上下文会显著推高输入费用(1M token 一次就是 $10),建议配合提示词缓存使用,重复的长文档前缀可以大幅降低成本。同时注意 claude-fable-5 数据保留期为 30 天且不支持零数据保留,对数据合规敏感的业务需要提前评估。
总结:Claude Fable 5 回归后的正确接入姿势
Claude Fable 5 的回归让开发者重新拿到了 Mythos 级模型的入场券:1M 上下文、128K 输出、超越 Opus 的推理能力,模型名 claude-fable-5 保持不变。但回归版不是简单的"原样恢复",自适应思考强制开启、安全分类器可能返回 stop_reason: "refusal"、需要配套 fallback 降级逻辑,这三点是所有集成代码必须适配的新现实。
接入路径上,订阅用户可以趁 7 月 7 日前的促销期在 Claude 客户端免费体验;API 开发者则建议通过 API易 apiyi.com 的 AWS Claude 官方转发通道接入,统一接口同时覆盖 claude-fable-5 与 Opus、Sonnet 等降级备选模型,把本文的三步接入和 refusal 处理跑通后,就可以放心把这款最强 Claude 模型用到生产业务里了。
作者:APIYI Team,专注 AI 大模型 API 接入与工程实践。更多模型评测与接入教程,访问 API易 apiyi.com 查看。