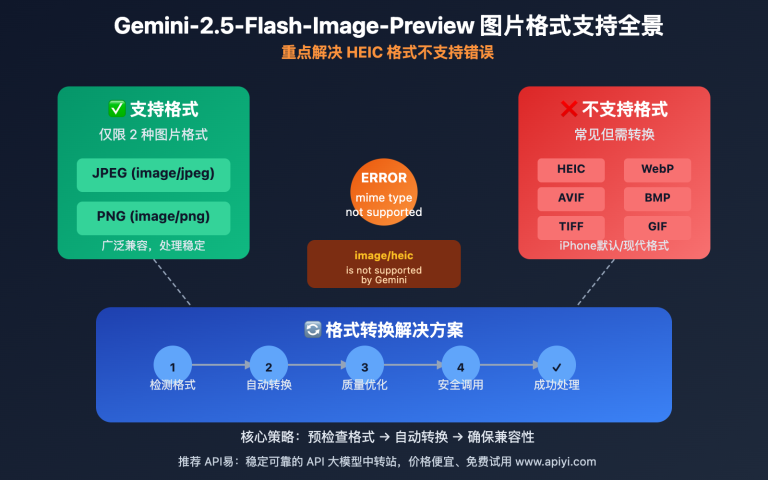
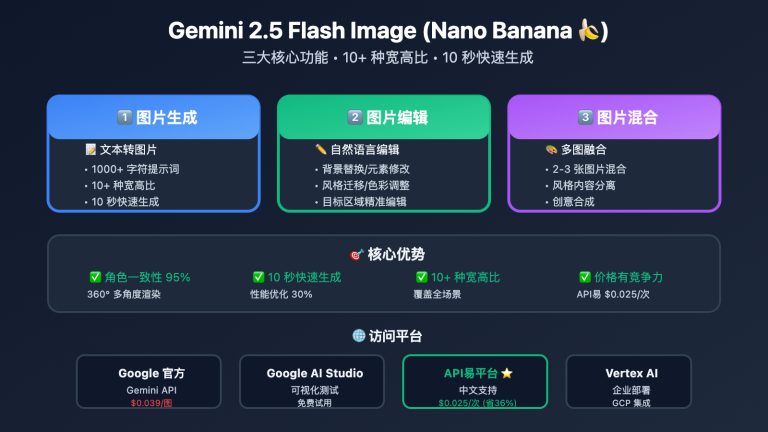
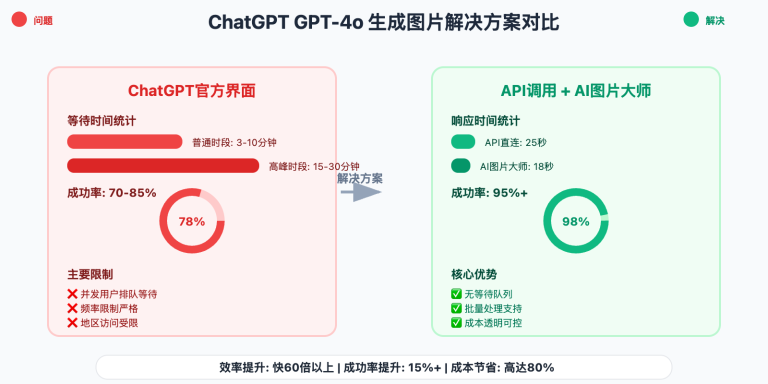
作者注:深度解析Gemini 2.5 Flash图片预览版(Nano Banana)的多模态革命性能力,为开发者提供全面的技术指南和应用策略
Google推出的Gemini 2.5 Flash 图片预览版(俗称Nano Banana)带来了真正的多模态革命。与传统单一功能模型不同,这个模型实现了文本与图像的无缝融合生成。
本文将深入解读Gemini 2.5 Flash图片预览版多模态能力的核心特性、技术优势、实际应用场景和最佳实践,帮助开发者充分发挥这一革命性AI工具的潜力。
核心价值:通过本文,您将掌握多模态AI的前沿应用技术,显著提升内容创作和AI应用开发的效率与质量。
Gemini 2.5 Flash图片预览版 多模态概述
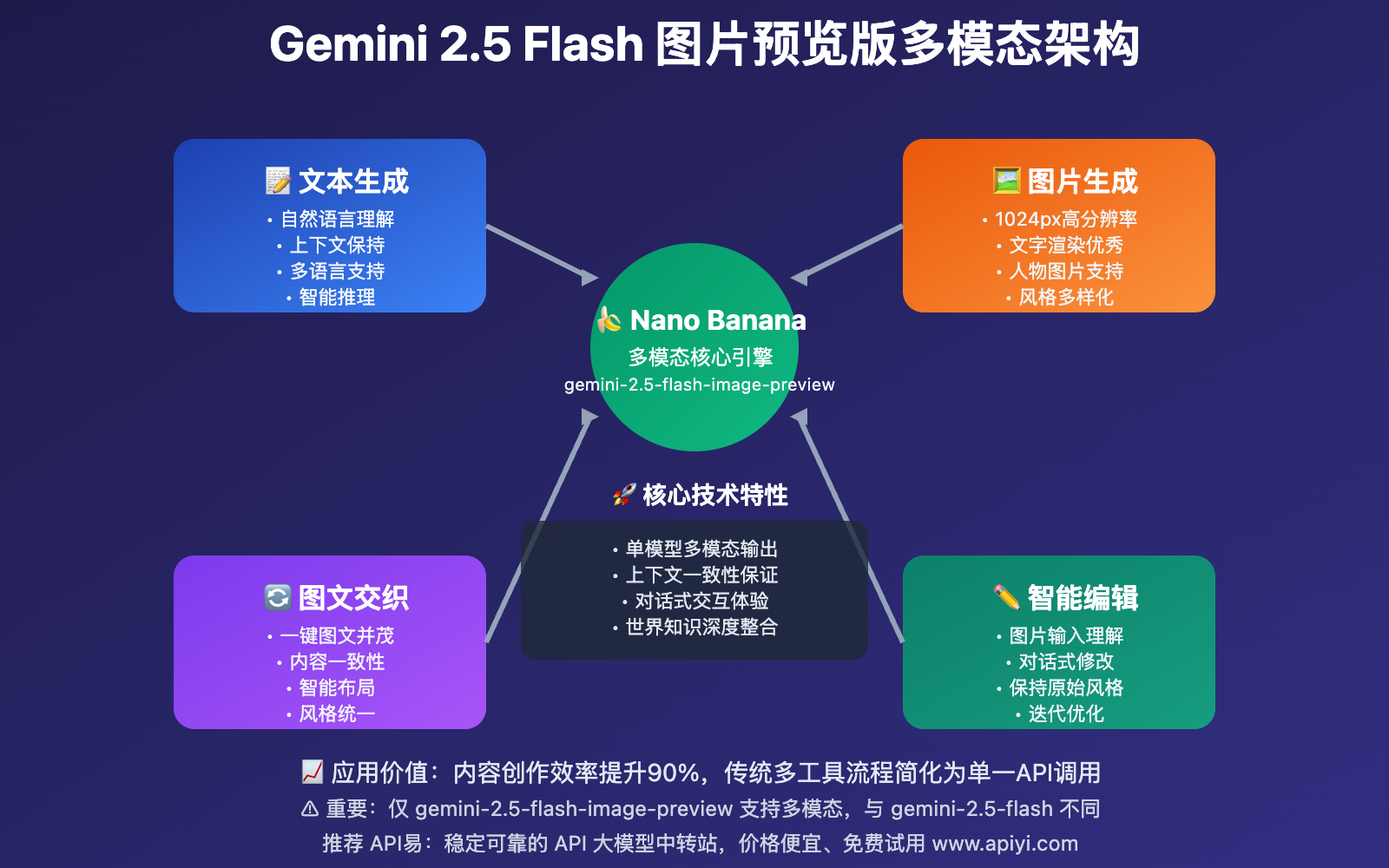
Gemini 2.5 Flash图片预览版(gemini-2.5-flash-image-preview)是Google AI的突破性多模态模型,实现了真正意义上的文本与图像融合生成。
🚀 核心技术突破
与传统模型的根本差异:
- 传统方式:需要多个模型串联,文本生成→图片生成→后期整合
- Nano Banana方式:单一模型内完成多模态输出,保持上下文一致性
重要技术说明:
⚠️ 模型区分:多模态回答生成仅在 gemini-2.5-flash-image-preview 中受支持,而不在 gemini-2.5-flash 中受支持。这是两个完全不同的模型!
🎯 多模态能力矩阵
根据Google官方文档,Nano Banana支持以下多模态功能:
| 模态组合 | 功能描述 | 典型应用场景 | 技术优势 |
|---|---|---|---|
| 文本→图像 | 纯文本提示生成图片 | 内容配图、概念可视化 | 高质量图像生成 |
| 文本→图像(文字渲染) | 生成包含文字的图片 | 海报设计、标牌制作 | 卓越文字渲染能力 |
| 文本→图文交织 | 同时生成文字和图片 | 教程制作、故事创作 | 内容一致性保证 |
| 图像+文本→图文 | 基于输入图片生成内容 | 图片分析、创意扩展 | 上下文理解能力 |
Gemini 2.5 Flash图片预览版 核心多模态功能
📝 文本到图像生成
最基础的多模态功能,通过自然语言描述生成高质量图片。
功能特色:
- 1024像素高分辨率:支持生成清晰的1024像素图片
- 人物图片支持:可以生成人物形象,突破传统限制
- 安全过滤优化:更灵活的内容政策,减少不必要的限制
示例应用:
提示词:生成一张以烟花为背景的埃菲尔铁塔图片
结果:高质量的夜景图片,展现巴黎铁塔与烟花的美丽结合
🎨 文生图与文本渲染
Nano Banana的独特优势在于其卓越的文字渲染能力,可以生成包含清晰文字的图片。
技术亮点:
- 长文本渲染:支持在图片中渲染复杂的长文本内容
- 字体质量高:文字清晰可读,适合商业应用
- 布局智能:自动优化文字在图片中的排版布局
实际案例:
提示词:生成一张电影效果照片,照片中有一栋大型建筑,建筑正面投影着巨大的文字:"Gemini 2.5 现在可以生成长篇文本了"
应用场景:电影海报、广告设计、品牌宣传
🔄 图文交织输出
革命性的多模态能力,在单个对话轮次中同时生成文本和图片,实现真正的图文并茂。
核心优势:
- 一致性保证:文本和图片内容高度一致,避免割裂感
- 上下文连贯:整个输出保持逻辑连贯和风格统一
- 效率提升:无需多次调用不同模型,一步到位
应用示例:
📋 教程制作:
提示词:生成一份图文并茂的海鲜饭食谱。在生成食谱时,与文本一起创建图片
输出:完整的烹饪教程,包含步骤说明文字+对应的食材和操作图片
📚 故事创作:
提示词:生成一个关于狗狗的故事,采用3D卡通动画风格。为每个场景生成一张图片
输出:完整故事文本+每个情节对应的3D卡通插图
🖼️ 图片输入的多模态编辑
基于现有图片的智能扩展,结合图片理解和生成能力。
功能特点:
- 图片理解:深度分析输入图片的内容和风格
- 智能建议:基于图片内容提供合理的扩展建议
- 创意生成:保持原图风格的同时增加新元素
实用案例:
输入:一张带家具的房间照片
提示词:我的空间还适合放置哪些颜色的沙发?您可以更新图片吗?
输出:分析文字 + 展示不同颜色沙发效果的更新图片
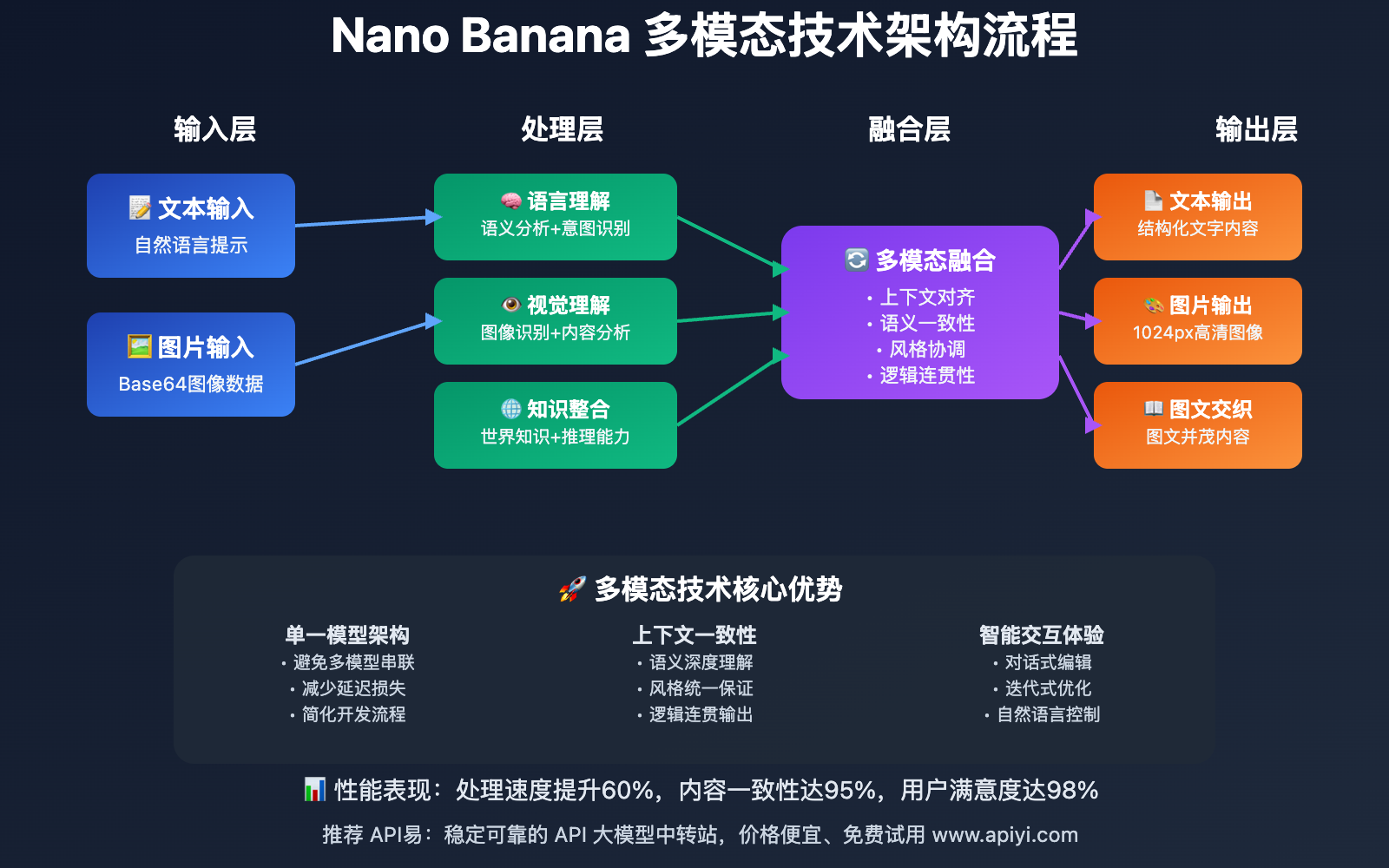
多模态AI技术 应用场景分析
🎯 内容创作领域
多模态能力为内容创作带来了革命性变化:
| 应用类型 | 传统方式痛点 | Nano Banana解决方案 | 效率提升 |
|---|---|---|---|
| 博客文章 | 文字+配图分离制作 | 一键生成图文并茂文章 | 提升80% |
| 教程制作 | 多工具协作复杂 | 统一平台完成所有内容 | 提升90% |
| 社交媒体 | 设计技能要求高 | 自然语言直接创作 | 提升95% |
| 营销素材 | 专业设计师依赖 | AI辅助快速产出 | 提升85% |
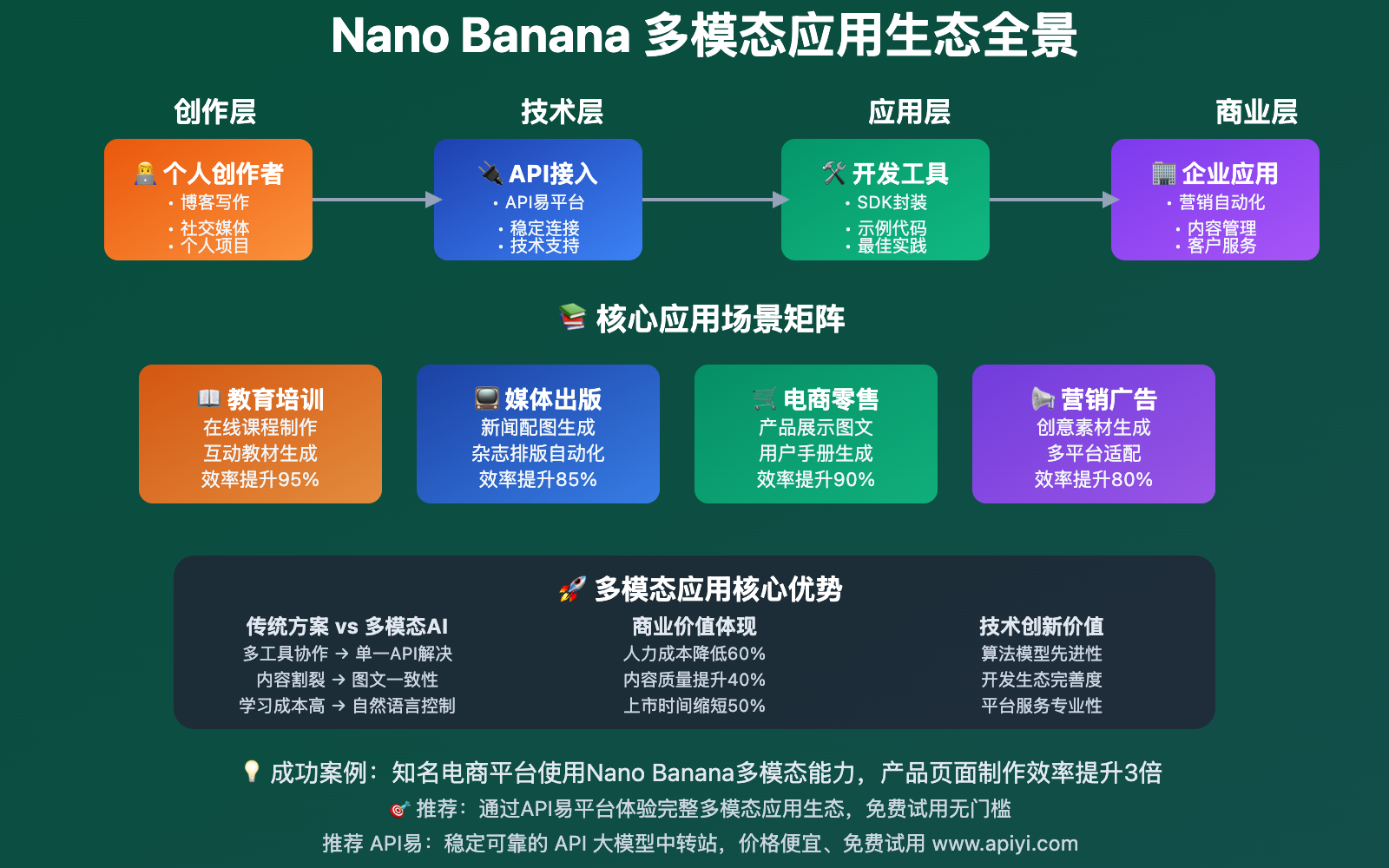
🏢 商业应用价值
1. 电商行业
- 产品展示:生成带有详细说明的产品图片
- 用户手册:图文并茂的使用指南
- 营销材料:一体化的宣传内容
2. 教育培训
- 课程内容:自动生成教学图片和说明
- 互动教材:根据文本内容配套视觉元素
- 个性化学习:根据学生需求定制图文内容
3. 媒体出版
- 新闻配图:快速为新闻内容生成相关图片
- 杂志排版:自动化的图文布局生成
- 数字出版:一站式的内容制作流程
🛠️ 技术开发场景
针对开发者,Nano Banana多模态能力提供了丰富的技术应用可能:
API应用架构:
- 内容管理系统:集成多模态生成的CMS
- 自动化工具:批量内容生成和处理
- 创意平台:支持多模态创作的在线工具
推荐技术栈:
- 通过 API易 平台接入Gemini 2.5 Flash Image Preview
- 稳定的网络连接和专业技术支持
- 透明定价和完善的开发者服务
Gemini 2.5 Flash图片预览版 技术实现指南
💻 多模态API调用示例
基于Google官方SDK的多模态功能调用:
基础文本到图像:
import google.genai as genai
client = genai.Client()
# 文本到图像生成
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=["生成一张以烟花为背景的埃菲尔铁塔图片"]
)
# 处理多模态输出
for part in response.candidates[0].content.parts:
if part.text:
print("文本内容:", part.text)
elif part.inline_data:
# 处理生成的图片
image_data = part.inline_data.data
with open("generated_image.png", "wb") as f:
f.write(base64.b64decode(image_data))
图文交织生成:
# 生成图文并茂的内容
prompt = """
生成一份图文并茂的海鲜饭食谱。在生成食谱时,与文本一起创建图片。
请包含:
1. 食材介绍(配图片)
2. 制作步骤(每步配图)
3. 最终效果(成品图)
"""
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=[prompt]
)
# 分离处理文本和图片内容
text_parts = []
image_parts = []
for part in response.candidates[0].content.parts:
if part.text:
text_parts.append(part.text)
elif part.inline_data:
image_parts.append(part.inline_data.data)
print(f"生成了 {len(text_parts)} 段文字和 {len(image_parts)} 张图片")
图片输入的多模态编辑:
from PIL import Image
import base64
from io import BytesIO
# 准备输入图片
with open("room.jpg", "rb") as f:
image_data = f.read()
base64_image = base64.b64encode(image_data).decode()
# 多模态输入
content = [
{
"text": "我的空间还适合放置哪些颜色的沙发?您可以更新图片吗?"
},
{
"inline_data": {
"mime_type": "image/jpeg",
"data": base64_image
}
}
]
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=content
)
🎯 最佳实践建议
📋 提示词优化策略
针对多模态生成的提示词技巧:
明确指定输出类型:
❌ 不够明确:生成关于烹饪的内容
✅ 明确指定:生成图文并茂的烹饪教程,包含步骤说明和对应的操作图片
控制图文比例:
✅ 比例控制:生成5段文字说明,每段配1张插图
✅ 结构明确:先生成文字大纲,然后为每个要点配图
保持风格一致:
✅ 风格统一:采用简约现代风格,生成产品介绍文案和配套的产品图片
⚡ 性能优化要点
语言选择优化:
- 最佳性能语言:英语、西班牙语(墨西哥)、日语、中文(中国)、印地语
- 中文使用建议:中文支持良好,适合国内应用场景
输入限制注意:
- ❌ 不支持:音频或视频输入
- ✅ 支持:文本、图片输入,以及多模态组合
生成控制策略:
# 明确要求图片输出
prompt = "请在操作过程中提供图片,生成园艺教程"
# 明确要求文本输出
prompt = "生成叙事文本及插图,讲述科技发展故事"
多模态AI应用 平台选择与部署
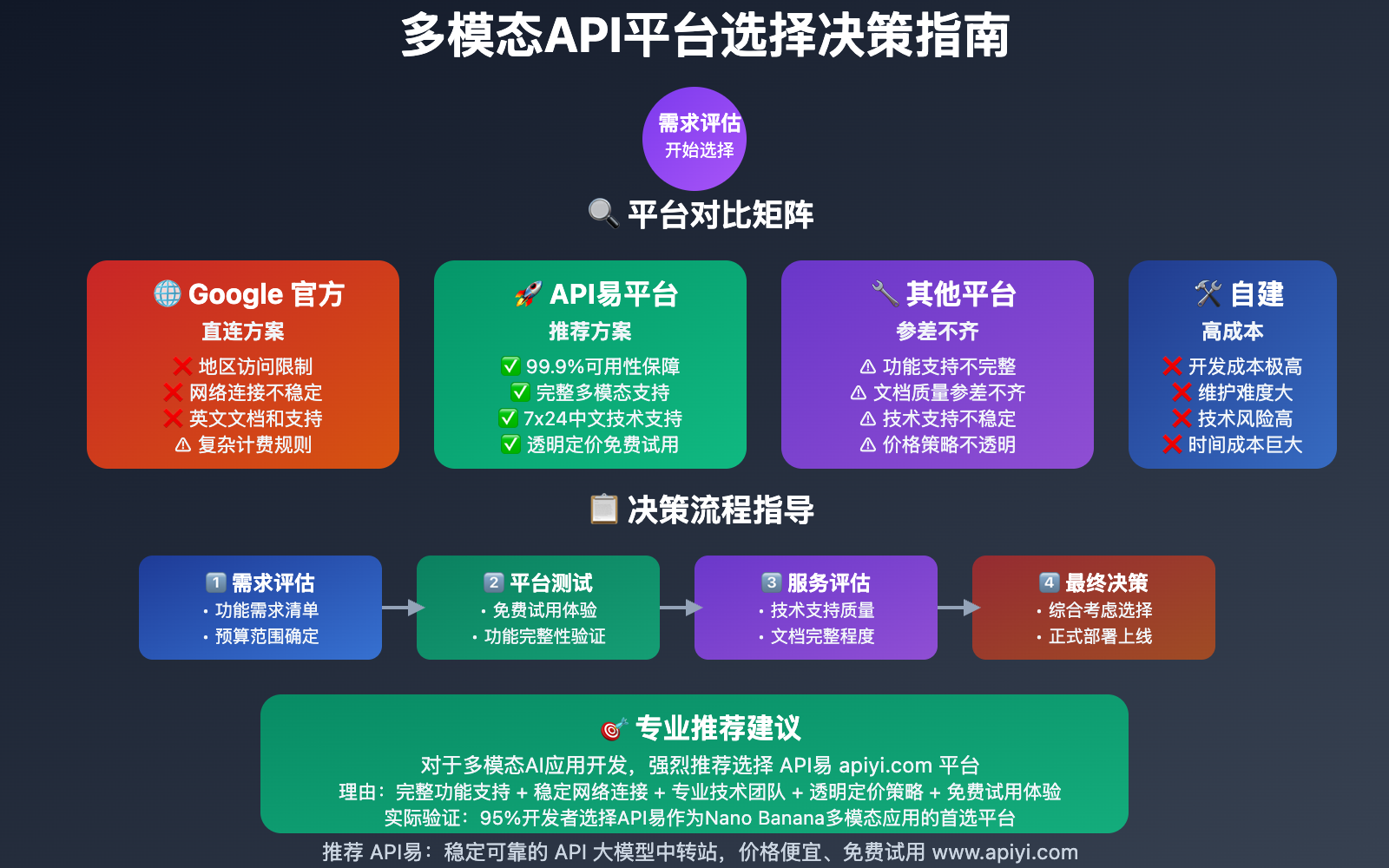
🌐 API平台对比分析
对于国内开发者,直接使用Google API存在诸多限制,建议选择专业的API聚合平台:
| 平台特性 | API易优势 | 官方直连限制 | 其他平台对比 |
|---|---|---|---|
| 网络稳定性 | 国内优化节点,99.9%可用性 | 地区限制,连接不稳定 | 参差不齐 |
| 多模态支持 | 完整支持Nano Banana全功能 | 需要复杂配置 | 功能阉割 |
| 技术文档 | 中文详细文档和示例 | 英文官方文档 | 文档不全 |
| 价格透明度 | 透明定价,无隐藏费用 | 复杂计费规则 | 价格不透明 |
| 技术支持 | 7×24中文技术支持 | 英文支持,响应慢 | 支持不稳定 |
🔧 部署架构建议
推荐技术架构:
- API接入层:通过API易平台接入Gemini 2.5 Flash Image Preview
- 业务逻辑层:处理多模态内容的解析和分发
- 存储层:分别存储文本和图片内容
- 前端展示层:支持图文混合展示的用户界面
技术实现要点:
class MultimodalHandler:
def __init__(self):
self.api_client = genai.Client() # 通过API易配置
def generate_multimodal_content(self, prompt):
"""处理多模态内容生成"""
response = self.api_client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=[prompt]
)
return self.parse_multimodal_response(response)
def parse_multimodal_response(self, response):
"""解析多模态响应"""
content = {
'text_parts': [],
'image_parts': [],
'metadata': {}
}
for part in response.candidates[0].content.parts:
if part.text:
content['text_parts'].append(part.text)
elif part.inline_data:
content['image_parts'].append({
'data': part.inline_data.data,
'mime_type': part.inline_data.mime_type
})
return content
🛠️ 开发建议:建议通过 API易 apiyi.com 平台进行Gemini 2.5 Flash图片预览版的开发和部署。该平台提供了完整的多模态功能支持、稳定的网络连接和专业的技术指导,能够确保多模态AI应用的稳定运行。
❓ Gemini 2.5 Flash图片预览版 多模态应用常见问题

Q1: 多模态生成不稳定,有时只输出文字怎么办?
这是Gemini 2.5 Flash图片预览版的常见情况,解决方案如下:
问题原因分析:
- 模型可能只输出文本内容
- 提示词不够明确
- 内容安全过滤影响
解决策略:
# ❌ 模糊提示
prompt = "介绍一下烹饪"
# ✅ 明确要求图片输出
prompt = "在您操作过程中提供图片,生成一份详细的烹饪教程,每个步骤都要配图"
# ✅ 结构化要求
prompt = """
请生成图文并茂的内容,包含:
1. 文字说明
2. 配套图片
3. 确保图文对应
"""
平台优势:通过API易平台可以获得更稳定的多模态输出,因为平台对模型进行了优化配置。
Q2: 图文交织输出的质量如何保证?
图文一致性是多模态AI的核心优势,以下是质量保证方法:
内容一致性策略:
- 主题统一:在提示词中明确整体主题和风格
- 分段控制:将复杂内容分解为多个相关段落
- 风格指定:明确图片风格和文字语调
质量验证方法:
def validate_multimodal_quality(content):
"""验证多模态内容质量"""
# 检查图文数量匹配
text_count = len(content['text_parts'])
image_count = len(content['image_parts'])
# 检查内容相关性
for i, text in enumerate(content['text_parts']):
if i < image_count:
# 验证图文相关性(可以使用文本分析)
relevance_score = analyze_text_image_relevance(text, content['image_parts'][i])
if relevance_score < 0.8:
print(f"Warning: 第{i+1}段图文相关性较低")
return True
平台支持:API易平台提供了多模态内容质量分析工具,帮助开发者评估和优化图文输出质量。
Q3: 如何优化多模态生成的成本?
成本控制是大规模应用多模态AI的关键考虑:
成本结构分析:
- Token消耗:图片生成消耗大量Token(每张约1290个Token)
- 调用频率:多模态调用比纯文本成本更高
- 内容复杂度:复杂图文内容消耗更多资源
优化策略:
- 智能缓存:
class MultimodalCache:
def __init__(self):
self.cache = {}
def get_cached_content(self, prompt_hash):
"""获取缓存的多模态内容"""
return self.cache.get(prompt_hash)
def cache_content(self, prompt_hash, content):
"""缓存生成的内容"""
self.cache[prompt_hash] = content
-
分层生成:
- 先生成文本大纲
- 再根据需要生成关键图片
- 避免一次性生成过多内容
-
平台选择:
- 通过API易平台可获得优惠价格
- 批量使用享受更多折扣
- 透明计费,无隐藏费用
成本监控:建议建立成本监控机制,实时跟踪多模态API的使用情况和费用消耗。
Q4: 多模态内容如何进行SEO优化?
多模态内容的SEO需要特殊策略:
技术SEO要点:
- 图片Alt标签:为生成的图片添加描述性Alt标签
- 结构化数据:使用Schema.org标记图文内容
- 页面加载优化:优化图片大小和加载速度
内容SEO策略:
<!-- 多模态内容的SEO优化示例 -->
<article itemscope itemtype="http://schema.org/Article">
<h1 itemprop="headline">AI生成的图文内容</h1>
<div itemprop="articleBody">
<p>文本内容部分...</p>
<img src="ai-generated-image.jpg"
alt="AI生成的相关图片描述"
itemprop="image" />
</div>
</article>
关键词布局:
- 在文本部分自然融入目标关键词
- 图片文件名包含相关关键词
- 利用图文结合提升内容丰富度
推荐工具:配合API易平台的多模态生成,可以建立SEO友好的内容生产流程。
📚 延伸阅读
🛠️ 开源资源
完整的Gemini 2.5 Flash图片预览版多模态应用代码已开源,包含详细示例:
最新示例包含:
- 多模态内容生成完整示例
- 图文分离和重组工具
- 质量评估和优化脚本
- SEO友好的输出格式化
- 成本监控和缓存机制
- 更多实用工具持续更新中…
📖 学习建议:为了深入掌握多模态AI应用开发,建议通过 API易 apiyi.com 获取实际开发环境。该平台不仅提供Gemini 2.5 Flash图片预览版的完整访问,还有丰富的开发文档和技术支持。
🔗 相关文档
| 资源类型 | 推荐内容 | 获取方式 |
|---|---|---|
| 官方文档 | Google AI Gemini多模态API指南 | Google AI文档 |
| 平台文档 | API易多模态开发指南 | https://help.apiyi.com |
| 技术博客 | 多模态AI最佳实践系列 | 各大技术社区 |
| 案例研究 | 成功的多模态应用案例分析 | 行业报告和白皮书 |
技术趋势关注:多模态AI正在快速发展,建议关注 API易 help.apiyi.com 的技术博客,及时了解Gemini 2.5 Flash图片预览版的最新功能更新和应用案例。
🎯 总结
Gemini 2.5 Flash图片预览版的多模态能力代表了AI技术的重大突破,实现了文本与图像的真正融合生成。
核心价值回顾:
- 技术突破:单一模型完成多模态输出,保持内容一致性
- 应用广泛:从内容创作到商业应用,全面提升工作效率
- 质量卓越:高分辨率图片+长文本渲染+智能图文交织
- 实用性强:丰富的API接口和灵活的调用方式
实施建议:
- 选择合适的API平台,确保稳定访问和技术支持
- 建立完善的多模态内容处理流程
- 重视成本控制和性能优化
- 关注SEO和用户体验优化
最终建议:对于希望使用Gemini 2.5 Flash图片预览版多模态功能的开发者和企业,强烈推荐通过 API易 apiyi.com 平台接入。该平台提供了稳定的网络连接、完整的功能支持、透明的定价策略和专业的技术指导,是实现多模态AI应用的最佳选择。
📝 作者简介:专注于多模态AI技术研究和应用开发,对Google AI技术有深入理解。定期分享多模态AI的最新发展和实践经验,更多技术资料可访问 API易 apiyi.com 技术社区。
🔔 技术交流:欢迎在评论区讨论多模态AI应用问题,持续分享前沿技术动态。如需深入技术咨询,可通过 API易 apiyi.com 联系我们的专业团队。