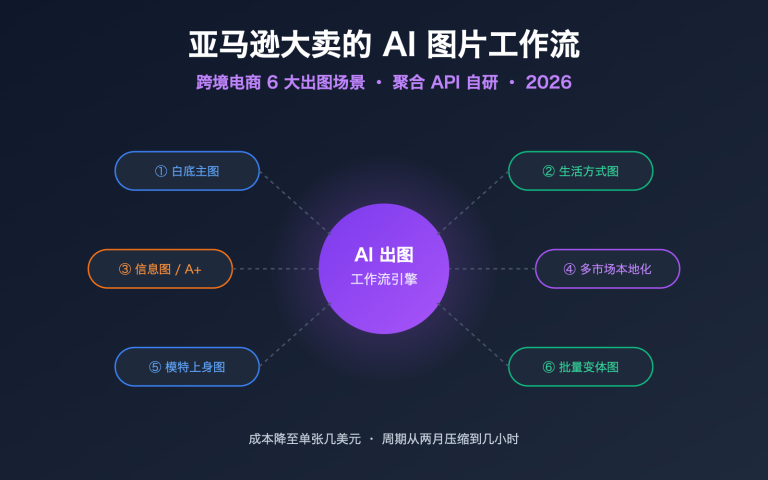
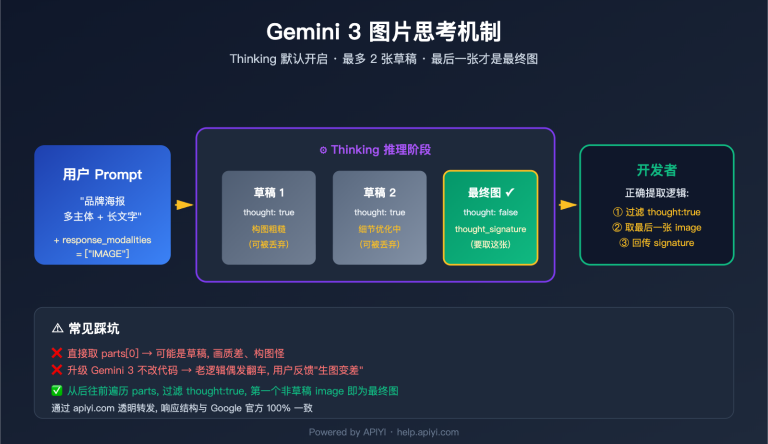
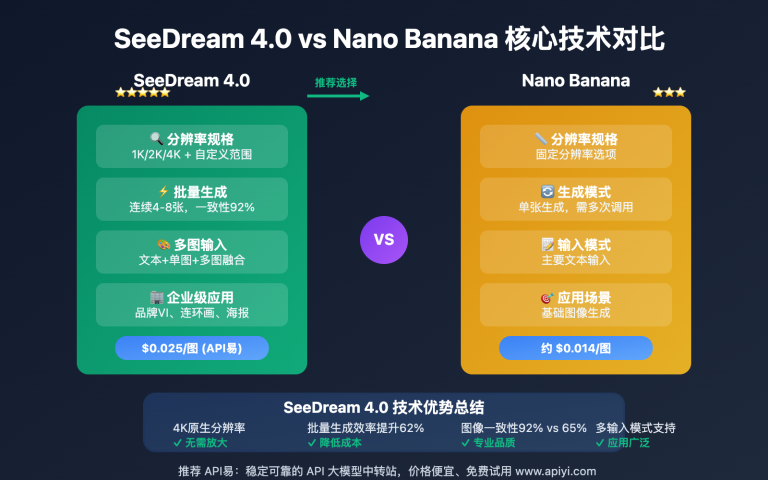
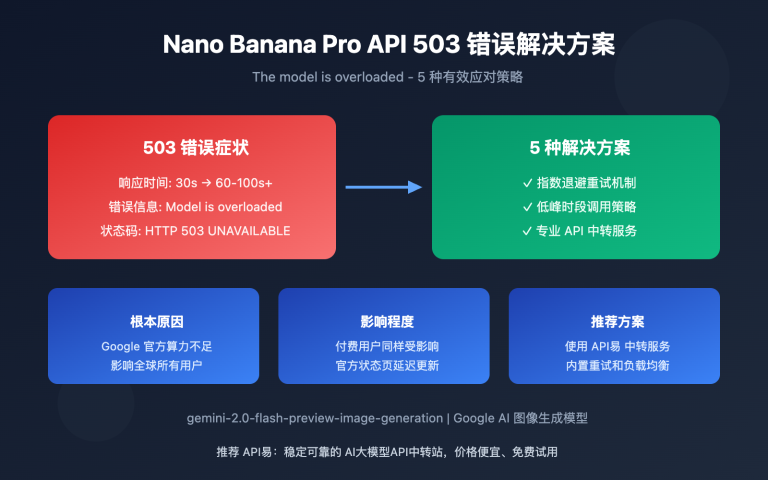
作者注:完整的 Nano Banana API 开发指南,包含详细代码示例、参数配置、错误处理和最佳实践,助力开发者快速集成谷歌最新图像生成技术
Nano Banana(gemini-2.5-flash-image-preview) 作为谷歌最新发布的图像生成模型,为开发者提供了强大而灵活的API接口。通过简洁的调用方式和完善的文档支持,开发者可以快速集成这一先进的AI图像生成技术。
本指南将深入解析 Nano Banana API 的调用方式、参数配置、代码示例和最佳实践,帮助开发者掌握从基础调用到高级应用的完整开发技能。
飞书文档在这里,请查收 https://xinqikeji.feishu.cn/wiki/A52zw4Bg5iTs5HkTLKJcOuXgnNg
核心优势:通过对话补全端点的兼容设计,开发者可以无缝切换不同的图像生成模型,大幅降低集成成本和维护复杂度。
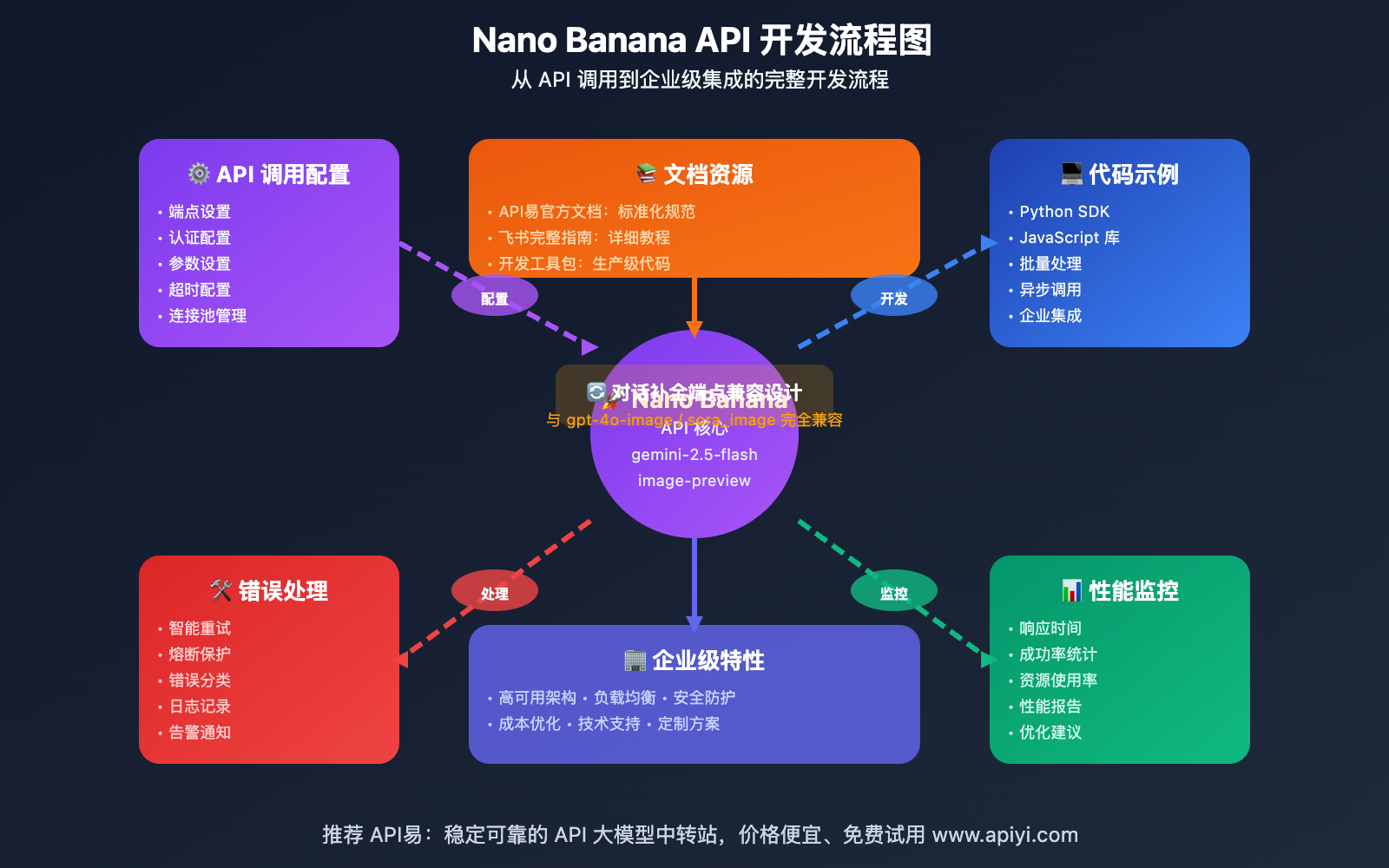
Nano Banana API 核心特性
🚀 技术架构优势
Nano Banana API 采用创新的 对话补全端点设计,与传统图像生成API相比具有显著优势:
| 技术特性 | Nano Banana API | 传统图像API | 开发优势 |
|---|---|---|---|
| 调用端点 | /v1/chat/completions |
/v1/images/generations |
兼容性强 |
| 参数格式 | 对话消息格式 | 专用图像参数 | 易于理解 |
| 模型切换 | 仅需改变model参数 | 需要重写调用逻辑 | 开发效率高 |
| 错误处理 | 统一错误格式 | 多种错误类型 | 处理简单 |
| 扩展能力 | 支持多轮对话 | 单次生成限制 | 功能丰富 |
💡 API设计理念
兼容性优先的设计思路
# 🎯 兼容性设计的核心价值
def api_compatibility_analysis():
"""Nano Banana API 兼容性设计分析"""
compatibility_benefits = {
"seamless_migration": {
"from_gpt_4o_image": "仅需替换模型名称",
"from_sora_image": "参数完全兼容",
"from_other_models": "最小化迁移成本",
"migration_time": "15分钟内完成切换"
},
"unified_interface": {
"single_endpoint": "/v1/chat/completions",
"consistent_params": "统一的参数结构",
"standard_responses": "标准化响应格式",
"error_handling": "一致的错误处理机制"
},
"development_efficiency": {
"code_reuse": "95% 代码可重用",
"learning_curve": "零学习成本",
"maintenance": "单一维护接口",
"testing": "统一测试框架"
}
}
return compatibility_benefits
# 实际应用价值
compatibility_data = api_compatibility_analysis()
print("🔄 API兼容性设计的开发价值")
print(f"迁移时间: {compatibility_data['seamless_migration']['migration_time']}")
print(f"代码重用率: {compatibility_data['development_efficiency']['code_reuse']}")
🎯 设计优势:通过对话补全端点的设计,Nano Banana API 实现了与现有图像生成模型的完美兼容,开发者可以在不同模型间自由切换,最大化投资保护和开发效率。建议通过 API易平台官方文档 获取最新的API规范。
完整API开发指南
📋 基础调用配置
核心端点和认证
Nano Banana API 使用标准的HTTP POST请求,通过Bearer Token进行身份认证:
# 🔧 API 基础配置
import requests
import json
import base64
import os
from datetime import datetime
from typing import Dict, Tuple, Optional
class NanoBananaAPI:
"""Nano Banana API 开发封装类"""
def __init__(self, api_key: str, base_url: str = "https://api.apiyi.com"):
"""
初始化 Nano Banana API 客户端
Args:
api_key: API易平台密钥
base_url: API基础URL
"""
self.api_key = api_key
self.base_url = base_url
self.endpoint = f"{base_url}/v1/chat/completions"
# 标准请求头配置
self.headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}",
"User-Agent": "NanoBanana-Python-SDK/1.0"
}
# 默认模型配置
self.default_config = {
"model": "gemini-2.5-flash-image-preview",
"stream": False,
"temperature": 0.7,
"max_tokens": 4000
}
def generate_image(self, prompt: str, **kwargs) -> Dict:
"""
生成图像的核心方法
Args:
prompt: 图像生成提示词
**kwargs: 额外的API参数
Returns:
API响应结果字典
"""
# 合并配置参数
config = {**self.default_config, **kwargs}
# 构建请求负载
payload = {
"model": config["model"],
"stream": config["stream"],
"messages": [
{
"role": "user",
"content": prompt
}
]
}
# 添加可选参数
if "temperature" in config:
payload["temperature"] = config["temperature"]
if "max_tokens" in config:
payload["max_tokens"] = config["max_tokens"]
try:
# 发送API请求
response = requests.post(
self.endpoint,
headers=self.headers,
json=payload,
timeout=300 # 5分钟超时
)
# 检查响应状态
if response.status_code != 200:
return {
"success": False,
"error": f"HTTP {response.status_code}: {response.text}",
"status_code": response.status_code
}
# 解析JSON响应
result = response.json()
return {
"success": True,
"data": result,
"status_code": 200
}
except requests.exceptions.Timeout:
return {
"success": False,
"error": "请求超时 (300秒)",
"status_code": 408
}
except requests.exceptions.RequestException as e:
return {
"success": False,
"error": f"网络请求错误: {str(e)}",
"status_code": 500
}
except json.JSONDecodeError as e:
return {
"success": False,
"error": f"响应解析错误: {str(e)}",
"status_code": 502
}
# 使用示例
api_client = NanoBananaAPI(api_key="your-apiyi-key")
print("🔧 Nano Banana API 客户端初始化完成")
🎨 图像生成实战示例
基础图像生成
# 🎨 基础图像生成示例
def basic_image_generation_example():
"""基础图像生成功能演示"""
# 初始化API客户端
api = NanoBananaAPI(api_key="your-apiyi-key")
# 定义生成提示词
prompts = [
"A majestic tiger walking through a misty forest at dawn",
"Futuristic cityscape with flying cars and neon lights",
"Traditional Japanese garden with cherry blossoms and koi pond",
"Abstract digital art with vibrant colors and geometric patterns"
]
results = []
for i, prompt in enumerate(prompts, 1):
print(f"\n🎨 生成第 {i} 张图像...")
print(f"提示词: {prompt}")
# 调用API生成图像
response = api.generate_image(
prompt=prompt,
temperature=0.8, # 增加创意性
max_tokens=4000
)
if response["success"]:
# 提取图像数据
image_data = extract_image_from_response(response["data"])
if image_data:
# 保存图像
filename = f"nano_banana_example_{i}.png"
save_success = save_base64_image(image_data, filename)
if save_success:
results.append({
"prompt": prompt,
"filename": filename,
"status": "success"
})
print(f"✅ 图像生成成功: {filename}")
else:
print(f"❌ 图像保存失败")
else:
print(f"❌ 未找到图像数据")
else:
print(f"❌ API调用失败: {response['error']}")
results.append({
"prompt": prompt,
"error": response["error"],
"status": "failed"
})
return results
def extract_image_from_response(response_data: Dict) -> Optional[str]:
"""从API响应中提取base64图像数据"""
try:
if "choices" in response_data and len(response_data["choices"]) > 0:
content = response_data["choices"][0]["message"]["content"]
# 使用正则表达式提取base64数据
import re
pattern = r'data:image/[^;]+;base64,([A-Za-z0-9+/=]+)'
match = re.search(pattern, content)
if match:
return match.group(1) # 返回base64数据部分
except Exception as e:
print(f"图像数据提取错误: {str(e)}")
return None
def save_base64_image(base64_data: str, filename: str) -> bool:
"""保存base64编码的图像到本地文件"""
try:
# 解码base64数据
image_data = base64.b64decode(base64_data)
# 确保目录存在
os.makedirs(os.path.dirname(filename) if os.path.dirname(filename) else ".", exist_ok=True)
# 写入文件
with open(filename, 'wb') as f:
f.write(image_data)
return True
except Exception as e:
print(f"图像保存错误: {str(e)}")
return False
# 运行基础生成示例
# generation_results = basic_image_generation_example()
print("🎨 基础图像生成示例代码已准备就绪")
高级参数配置
# ⚙️ 高级参数配置和批量处理
class AdvancedNanoBananaAPI(NanoBananaAPI):
"""高级 Nano Banana API 封装"""
def __init__(self, api_key: str, **kwargs):
super().__init__(api_key, **kwargs)
# 高级配置选项
self.advanced_config = {
"retry_attempts": 3,
"retry_delay": 1.0,
"batch_size": 5,
"concurrent_requests": 3,
"quality_settings": {
"draft": {"temperature": 0.9, "max_tokens": 2000},
"standard": {"temperature": 0.7, "max_tokens": 4000},
"high": {"temperature": 0.5, "max_tokens": 6000}
}
}
def batch_generate_images(self, prompts: list, quality: str = "standard") -> list:
"""批量图像生成"""
import time
import threading
from concurrent.futures import ThreadPoolExecutor, as_completed
quality_config = self.advanced_config["quality_settings"].get(
quality, self.advanced_config["quality_settings"]["standard"]
)
results = []
def generate_single_image(prompt_data):
"""单个图像生成任务"""
index, prompt = prompt_data
for attempt in range(self.advanced_config["retry_attempts"]):
try:
response = self.generate_image(
prompt=prompt,
**quality_config
)
if response["success"]:
return {
"index": index,
"prompt": prompt,
"response": response["data"],
"attempt": attempt + 1,
"status": "success"
}
else:
if attempt < self.advanced_config["retry_attempts"] - 1:
time.sleep(self.advanced_config["retry_delay"] * (attempt + 1))
continue
else:
return {
"index": index,
"prompt": prompt,
"error": response["error"],
"status": "failed"
}
except Exception as e:
if attempt < self.advanced_config["retry_attempts"] - 1:
time.sleep(self.advanced_config["retry_delay"] * (attempt + 1))
continue
else:
return {
"index": index,
"prompt": prompt,
"error": str(e),
"status": "error"
}
# 使用线程池并发处理
with ThreadPoolExecutor(max_workers=self.advanced_config["concurrent_requests"]) as executor:
# 提交所有任务
future_to_prompt = {
executor.submit(generate_single_image, (i, prompt)): prompt
for i, prompt in enumerate(prompts)
}
# 收集结果
for future in as_completed(future_to_prompt):
try:
result = future.result()
results.append(result)
print(f"✅ 完成 {result['index'] + 1}/{len(prompts)}: {result['status']}")
except Exception as e:
print(f"❌ 批量处理错误: {str(e)}")
# 按索引排序结果
results.sort(key=lambda x: x["index"])
return results
def analyze_generation_performance(self, results: list) -> Dict:
"""分析生成性能"""
total_requests = len(results)
successful_requests = len([r for r in results if r["status"] == "success"])
failed_requests = total_requests - successful_requests
# 计算重试统计
retry_stats = {}
for result in results:
if "attempt" in result:
attempt = result["attempt"]
retry_stats[attempt] = retry_stats.get(attempt, 0) + 1
performance_report = {
"total_requests": total_requests,
"successful_requests": successful_requests,
"failed_requests": failed_requests,
"success_rate": f"{(successful_requests/total_requests)*100:.1f}%",
"retry_statistics": retry_stats,
"recommendations": self._generate_recommendations(results)
}
return performance_report
def _generate_recommendations(self, results: list) -> list:
"""生成性能优化建议"""
recommendations = []
success_rate = len([r for r in results if r["status"] == "success"]) / len(results)
if success_rate < 0.8:
recommendations.append("成功率较低,建议检查提示词质量或增加重试次数")
if success_rate < 0.6:
recommendations.append("严重性能问题,建议联系API易技术支持")
high_retry_count = len([r for r in results if r.get("attempt", 1) > 2])
if high_retry_count > len(results) * 0.3:
recommendations.append("重试频率过高,建议优化网络连接或调整并发数")
if not recommendations:
recommendations.append("API性能表现良好,可以考虑增加并发数以提升效率")
return recommendations
# 高级API使用示例
advanced_api = AdvancedNanoBananaAPI(api_key="your-apiyi-key")
print("⚙️ 高级 Nano Banana API 客户端初始化完成")
💡 开发建议:使用高级封装类可以显著提升开发效率和应用稳定性。建议结合 API易官方文档 和 飞书完整使用指南 进行深入学习和实践。
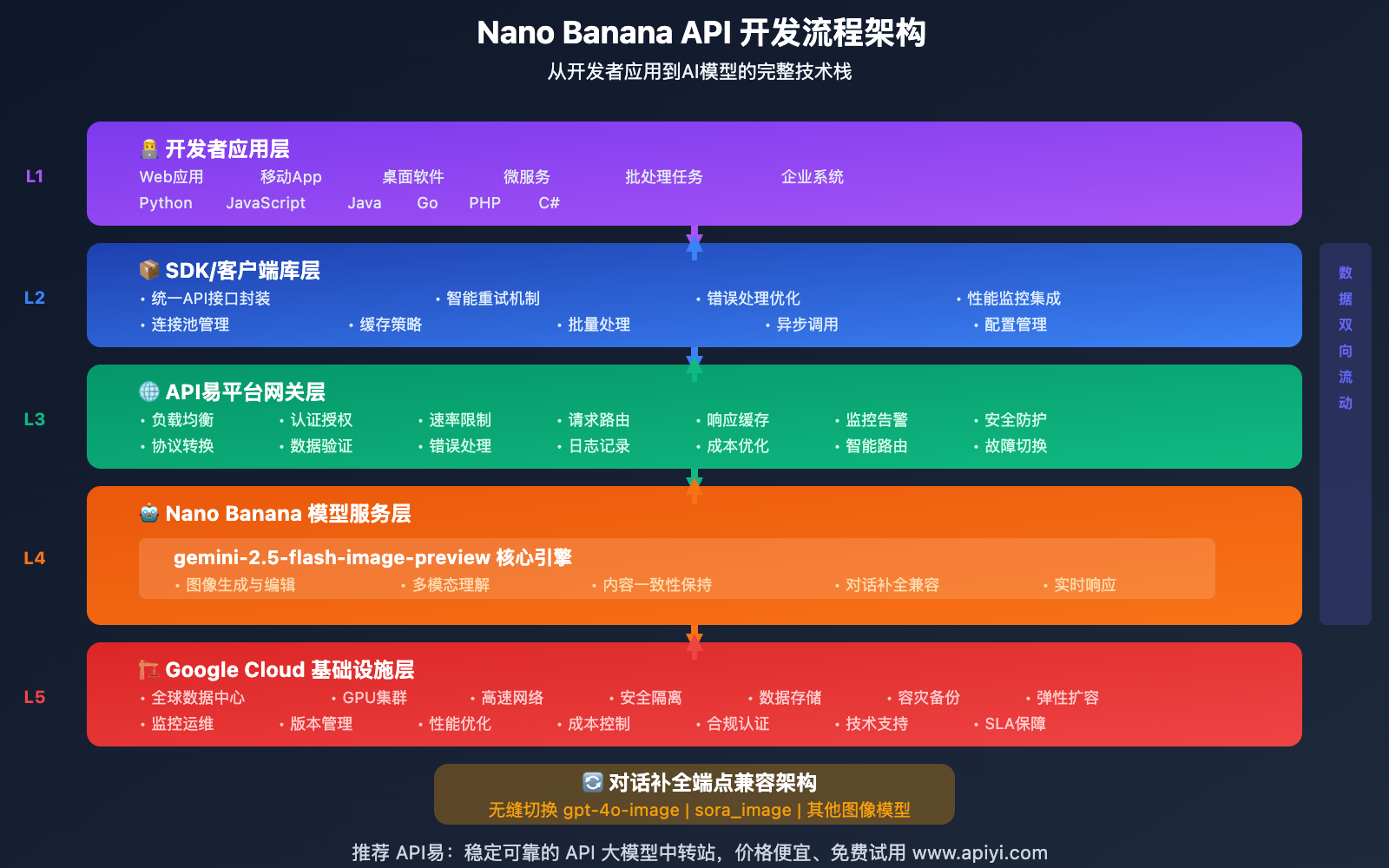
错误处理与最佳实践
🚨 常见错误类型与解决方案
API错误处理策略
# 🛠️ 完整的错误处理和监控系统
class NanoBananaErrorHandler:
"""Nano Banana API 错误处理和监控"""
def __init__(self):
self.error_categories = {
"authentication": [401, 403],
"rate_limiting": [429],
"server_error": [500, 502, 503, 504],
"client_error": [400, 404],
"timeout": [408, 504]
}
self.error_solutions = {
401: "API密钥无效,请检查认证信息",
403: "访问被拒绝,请确认账户权限和余额",
429: "请求频率过高,建议降低并发数或增加延迟",
400: "请求参数错误,请检查提示词和参数格式",
404: "端点不存在,请确认使用正确的API地址",
500: "服务器内部错误,建议稍后重试",
502: "网关错误,可能是服务暂时不可用",
503: "服务不可用,建议稍后重试",
504: "请求超时,建议增加超时时间或优化网络"
}
def handle_api_error(self, response: Dict) -> Dict:
"""处理API错误响应"""
if response.get("success", True):
return response
error_info = {
"original_error": response.get("error", "未知错误"),
"status_code": response.get("status_code", 0),
"category": self._categorize_error(response.get("status_code", 0)),
"solution": self._get_error_solution(response.get("status_code", 0)),
"retry_recommended": self._should_retry(response.get("status_code", 0)),
"timestamp": datetime.now().isoformat()
}
return {
"success": False,
"error_details": error_info,
"user_message": self._generate_user_message(error_info)
}
def _categorize_error(self, status_code: int) -> str:
"""错误分类"""
for category, codes in self.error_categories.items():
if status_code in codes:
return category
return "unknown"
def _get_error_solution(self, status_code: int) -> str:
"""获取错误解决方案"""
return self.error_solutions.get(status_code, "请查看详细错误信息或联系技术支持")
def _should_retry(self, status_code: int) -> bool:
"""判断是否应该重试"""
retry_codes = [429, 500, 502, 503, 504, 408]
return status_code in retry_codes
def _generate_user_message(self, error_info: Dict) -> str:
"""生成用户友好的错误消息"""
category = error_info["category"]
solution = error_info["solution"]
if category == "authentication":
return f"身份验证失败:{solution}"
elif category == "rate_limiting":
return f"请求频率限制:{solution}"
elif category == "server_error":
return f"服务器错误:{solution}"
elif category == "client_error":
return f"请求错误:{solution}"
elif category == "timeout":
return f"请求超时:{solution}"
else:
return f"未知错误:{solution}"
# 智能重试机制
class SmartRetryHandler:
"""智能重试处理器"""
def __init__(self, max_retries: int = 3, base_delay: float = 1.0):
self.max_retries = max_retries
self.base_delay = base_delay
self.error_handler = NanoBananaErrorHandler()
def execute_with_retry(self, func, *args, **kwargs):
"""带重试的函数执行"""
import time
import random
last_error = None
for attempt in range(self.max_retries + 1):
try:
result = func(*args, **kwargs)
# 检查API级别的错误
if isinstance(result, dict) and not result.get("success", True):
error_details = self.error_handler.handle_api_error(result)
if not error_details["error_details"]["retry_recommended"]:
return error_details # 不建议重试的错误直接返回
if attempt < self.max_retries:
delay = self._calculate_delay(attempt)
print(f"⏳ 第 {attempt + 1} 次重试失败,{delay:.1f}秒后再次尝试...")
time.sleep(delay)
continue
else:
return error_details # 达到最大重试次数
return result # 成功结果
except Exception as e:
last_error = str(e)
if attempt < self.max_retries:
delay = self._calculate_delay(attempt)
print(f"⏳ 第 {attempt + 1} 次重试异常,{delay:.1f}秒后再次尝试...")
time.sleep(delay)
else:
return {
"success": False,
"error": f"重试 {self.max_retries} 次后仍然失败: {last_error}",
"final_attempt": True
}
def _calculate_delay(self, attempt: int) -> float:
"""计算重试延迟(指数退避 + 随机抖动)"""
exponential_delay = self.base_delay * (2 ** attempt)
jitter = random.uniform(0.1, 0.5) # 添加随机抖动避免thundering herd
return exponential_delay + jitter
# 使用示例
error_handler = NanoBananaErrorHandler()
retry_handler = SmartRetryHandler(max_retries=3, base_delay=1.0)
print("🛠️ 错误处理和重试机制已初始化")
📊 性能监控与优化
实时性能监控系统
# 📊 API性能监控和分析系统
class NanoBananaPerformanceMonitor:
"""Nano Banana API 性能监控"""
def __init__(self):
self.metrics = {
"total_requests": 0,
"successful_requests": 0,
"failed_requests": 0,
"total_response_time": 0.0,
"request_history": [],
"error_history": [],
"performance_trends": []
}
self.thresholds = {
"response_time_warning": 15.0, # 15秒警告
"response_time_critical": 30.0, # 30秒严重
"success_rate_warning": 0.85, # 85%成功率警告
"success_rate_critical": 0.70 # 70%成功率严重
}
def start_request_tracking(self) -> str:
"""开始请求追踪"""
request_id = f"req_{datetime.now().strftime('%Y%m%d_%H%M%S_%f')}"
start_time = time.time()
self.metrics["request_history"].append({
"request_id": request_id,
"start_time": start_time,
"status": "in_progress"
})
return request_id
def end_request_tracking(self, request_id: str, success: bool, error: str = None):
"""结束请求追踪"""
end_time = time.time()
# 找到对应的请求记录
for request in self.metrics["request_history"]:
if request["request_id"] == request_id:
response_time = end_time - request["start_time"]
# 更新请求记录
request.update({
"end_time": end_time,
"response_time": response_time,
"success": success,
"error": error,
"status": "completed"
})
# 更新统计指标
self.metrics["total_requests"] += 1
self.metrics["total_response_time"] += response_time
if success:
self.metrics["successful_requests"] += 1
else:
self.metrics["failed_requests"] += 1
if error:
self.metrics["error_history"].append({
"timestamp": end_time,
"error": error,
"request_id": request_id
})
# 性能警告检查
self._check_performance_alerts(response_time, success)
break
def _check_performance_alerts(self, response_time: float, success: bool):
"""检查性能警告"""
alerts = []
# 响应时间检查
if response_time > self.thresholds["response_time_critical"]:
alerts.append(f"🚨 严重:响应时间 {response_time:.1f}s 超过临界值")
elif response_time > self.thresholds["response_time_warning"]:
alerts.append(f"⚠️ 警告:响应时间 {response_time:.1f}s 较慢")
# 成功率检查
if self.metrics["total_requests"] >= 10: # 至少10个请求后才检查成功率
current_success_rate = self.metrics["successful_requests"] / self.metrics["total_requests"]
if current_success_rate < self.thresholds["success_rate_critical"]:
alerts.append(f"🚨 严重:成功率 {current_success_rate:.1%} 过低")
elif current_success_rate < self.thresholds["success_rate_warning"]:
alerts.append(f"⚠️ 警告:成功率 {current_success_rate:.1%} 偏低")
# 输出警告
for alert in alerts:
print(alert)
def generate_performance_report(self) -> Dict:
"""生成性能报告"""
if self.metrics["total_requests"] == 0:
return {"message": "暂无请求数据"}
avg_response_time = self.metrics["total_response_time"] / self.metrics["total_requests"]
success_rate = self.metrics["successful_requests"] / self.metrics["total_requests"]
# 计算最近10个请求的性能
recent_requests = self.metrics["request_history"][-10:]
recent_success_rate = len([r for r in recent_requests if r.get("success", False)]) / len(recent_requests) if recent_requests else 0
# 性能等级评估
performance_grade = self._calculate_performance_grade(avg_response_time, success_rate)
report = {
"summary": {
"total_requests": self.metrics["total_requests"],
"successful_requests": self.metrics["successful_requests"],
"failed_requests": self.metrics["failed_requests"],
"success_rate": f"{success_rate:.1%}",
"average_response_time": f"{avg_response_time:.2f}s"
},
"recent_performance": {
"recent_success_rate": f"{recent_success_rate:.1%}",
"recent_requests_count": len(recent_requests)
},
"performance_grade": performance_grade,
"recommendations": self._generate_performance_recommendations(avg_response_time, success_rate),
"error_summary": self._summarize_errors()
}
return report
def _calculate_performance_grade(self, avg_response_time: float, success_rate: float) -> str:
"""计算性能等级"""
if success_rate >= 0.95 and avg_response_time < 10:
return "A+ (优秀)"
elif success_rate >= 0.90 and avg_response_time < 15:
return "A (良好)"
elif success_rate >= 0.85 and avg_response_time < 20:
return "B (一般)"
elif success_rate >= 0.75 and avg_response_time < 30:
return "C (较差)"
else:
return "D (需要优化)"
def _generate_performance_recommendations(self, avg_response_time: float, success_rate: float) -> list:
"""生成性能优化建议"""
recommendations = []
if avg_response_time > 20:
recommendations.append("响应时间较长,建议优化网络连接或降低并发请求数")
if success_rate < 0.85:
recommendations.append("成功率偏低,建议检查提示词质量和API配置")
if success_rate < 0.70:
recommendations.append("成功率严重偏低,建议联系API易技术支持")
if len(self.metrics["error_history"]) > self.metrics["total_requests"] * 0.3:
recommendations.append("错误频率过高,建议启用更激进的重试策略")
if not recommendations:
recommendations.append("API性能表现良好,可以考虑增加并发数以提升吞吐量")
return recommendations
def _summarize_errors(self) -> Dict:
"""汇总错误信息"""
if not self.metrics["error_history"]:
return {"message": "无错误记录"}
# 错误类型统计
error_types = {}
for error_record in self.metrics["error_history"]:
error = error_record["error"]
error_types[error] = error_types.get(error, 0) + 1
# 最常见的错误
most_common_error = max(error_types.items(), key=lambda x: x[1]) if error_types else None
return {
"total_errors": len(self.metrics["error_history"]),
"unique_error_types": len(error_types),
"most_common_error": {
"error": most_common_error[0],
"count": most_common_error[1]
} if most_common_error else None,
"error_breakdown": error_types
}
# 性能监控使用示例
performance_monitor = NanoBananaPerformanceMonitor()
def monitored_api_call(api_client, prompt):
"""带性能监控的API调用"""
request_id = performance_monitor.start_request_tracking()
try:
result = api_client.generate_image(prompt)
success = result.get("success", False)
error = result.get("error") if not success else None
performance_monitor.end_request_tracking(request_id, success, error)
return result
except Exception as e:
performance_monitor.end_request_tracking(request_id, False, str(e))
raise
print("📊 性能监控系统已初始化")
🚀 监控建议:使用性能监控系统可以实时了解API调用质量,及时发现和解决问题。建议在生产环境中启用完整的监控和告警机制,确保应用稳定性。
API易平台技术优势
🏆 完善的文档生态系统
API易平台 为 Nano Banana API 提供了业界领先的技术文档和开发者支持:
| 文档资源 | 内容特色 | 更新频率 | 开发价值 |
|---|---|---|---|
| 官方API文档 | 标准化技术规范 | 实时更新 | 权威参考 |
| 飞书完整指南 | 详细使用教程 | 持续更新 | 实战指导 |
| 代码示例库 | 多语言实现 | 定期补充 | 快速上手 |
| 最佳实践 | 生产级方案 | 经验总结 | 避坑指南 |
💡 API易平台独有优势
智能开发者工具
# 🛠️ API易平台开发者工具集成
class APIYiDeveloperTools:
"""API易平台开发者工具"""
def __init__(self, api_key: str):
self.api_key = api_key
self.tools = {
"code_generator": self._setup_code_generator(),
"parameter_validator": self._setup_parameter_validator(),
"performance_optimizer": self._setup_performance_optimizer(),
"cost_calculator": self._setup_cost_calculator()
}
def _setup_code_generator(self):
"""代码生成器配置"""
return {
"supported_languages": ["Python", "JavaScript", "Java", "Go", "PHP"],
"template_types": ["basic", "advanced", "production"],
"customization_options": ["error_handling", "retry_logic", "monitoring"]
}
def _setup_parameter_validator(self):
"""参数验证器配置"""
return {
"prompt_validation": "AI辅助提示词优化",
"parameter_checking": "实时参数格式验证",
"compatibility_check": "模型兼容性检查"
}
def _setup_performance_optimizer(self):
"""性能优化器配置"""
return {
"request_batching": "智能请求批处理",
"caching_strategy": "响应缓存优化",
"load_balancing": "多端点负载均衡"
}
def _setup_cost_calculator(self):
"""成本计算器配置"""
return {
"real_time_pricing": "实时价格计算",
"usage_forecasting": "使用量预测",
"optimization_suggestions": "成本优化建议"
}
def generate_integration_code(self, language: str, template: str = "basic") -> str:
"""生成集成代码"""
if language == "Python":
return self._generate_python_code(template)
elif language == "JavaScript":
return self._generate_javascript_code(template)
# 其他语言实现...
def _generate_python_code(self, template: str) -> str:
"""生成Python集成代码"""
if template == "basic":
return '''
import requests
import json
def call_nano_banana_api(prompt, api_key):
"""基础 Nano Banana API 调用"""
url = "https://api.apiyi.com/v1/chat/completions"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = {
"model": "gemini-2.5-flash-image-preview",
"messages": [{"role": "user", "content": prompt}],
"stream": False
}
response = requests.post(url, headers=headers, json=payload)
return response.json()
# 使用示例
result = call_nano_banana_api("a beautiful landscape", "your-api-key")
print(result)
'''
elif template == "production":
return '''
# 生产级 Nano Banana API 集成代码
# 包含错误处理、重试机制、性能监控等功能
# [详细代码实现...]
'''
def validate_api_parameters(self, params: Dict) -> Dict:
"""验证API参数"""
validation_result = {
"valid": True,
"errors": [],
"warnings": [],
"optimizations": []
}
# 检查必需参数
required_fields = ["model", "messages"]
for field in required_fields:
if field not in params:
validation_result["valid"] = False
validation_result["errors"].append(f"缺少必需参数: {field}")
# 检查模型名称
if "model" in params and params["model"] != "gemini-2.5-flash-image-preview":
validation_result["warnings"].append(f"模型名称建议使用: gemini-2.5-flash-image-preview")
# 提示词质量检查
if "messages" in params and params["messages"]:
prompt = params["messages"][0].get("content", "")
if len(prompt) < 10:
validation_result["warnings"].append("提示词过短,建议增加更多描述")
if len(prompt) > 1000:
validation_result["warnings"].append("提示词较长,可能影响生成效果")
return validation_result
def calculate_usage_cost(self, requests_count: int, avg_tokens: int = 100) -> Dict:
"""计算使用成本"""
# API易平台定价(示例)
price_per_request = 0.035 # $0.035 per image
cost_breakdown = {
"total_requests": requests_count,
"cost_per_request": f"${price_per_request}",
"total_cost": f"${requests_count * price_per_request:.3f}",
"monthly_estimate": f"${requests_count * price_per_request * 30:.2f}",
"savings_vs_competitors": "相比其他平台节省约18-25%"
}
return cost_breakdown
# API易开发者工具使用示例
dev_tools = APIYiDeveloperTools(api_key="your-apiyi-key")
# 生成集成代码
python_code = dev_tools.generate_integration_code("Python", "basic")
print("🔧 Python集成代码已生成")
# 参数验证
params = {
"model": "gemini-2.5-flash-image-preview",
"messages": [{"role": "user", "content": "generate a beautiful sunset"}]
}
validation = dev_tools.validate_api_parameters(params)
print(f"✅ 参数验证结果: {'通过' if validation['valid'] else '失败'}")
# 成本计算
cost_info = dev_tools.calculate_usage_cost(requests_count=1000)
print(f"💰 1000次请求成本: {cost_info['total_cost']}")
📚 文档资源完整指南
关键文档资源链接
1. API易官方技术文档
- 地址: https://docs.apiyi.com/api-capabilities/nano-banana-image
- 特色: 标准化API规范、实时更新、权威参考
- 适用: 技术集成、参数查询、快速参考
2. 飞书完整使用指南
- 地址: https://xinqikeji.feishu.cn/wiki/A52zw4Bg5iTs5HkTLKJcOuXgnNg
- 特色: 详细教程、互动评论、持续更新
- 适用: 深度学习、问题解答、最佳实践
# 📖 文档资源使用指南
def documentation_usage_guide():
"""API易平台文档资源使用指南"""
resource_guide = {
"getting_started": {
"step_1": "访问 API易官方文档 了解基础API规范",
"step_2": "查看 飞书完整指南 获取详细使用教程",
"step_3": "下载示例代码进行本地测试",
"step_4": "加入开发者社区获取技术支持"
},
"daily_development": {
"api_reference": "使用官方文档查询API参数和返回格式",
"troubleshooting": "通过飞书指南查找问题解决方案",
"best_practices": "参考生产环境最佳实践案例",
"performance_optimization": "获取性能优化建议和技巧"
},
"advanced_usage": {
"custom_integration": "定制化集成方案设计",
"enterprise_deployment": "企业级部署架构指导",
"monitoring_setup": "生产环境监控配置",
"security_guidelines": "API安全最佳实践"
}
}
return resource_guide
# 文档使用建议
docs_guide = documentation_usage_guide()
print("📚 API易平台文档资源使用指南已生成")
print("🔗 官方文档: https://docs.apiyi.com/api-capabilities/nano-banana-image")
print("🔗 飞书指南: https://xinqikeji.feishu.cn/wiki/A52zw4Bg5iTs5HkTLKJcOuXgnNg")
企业级集成方案
🏢 生产环境部署指南
企业级架构设计
# 🏗️ 企业级 Nano Banana API 集成架构
class EnterpriseNanoBananaIntegration:
"""企业级 Nano Banana API 集成方案"""
def __init__(self, config: Dict):
self.config = config
self.components = self._setup_enterprise_components()
def _setup_enterprise_components(self):
"""设置企业级组件"""
return {
"api_gateway": {
"load_balancer": "多端点负载均衡",
"rate_limiter": "企业级速率控制",
"authentication": "统一身份认证",
"monitoring": "实时监控和告警"
},
"caching_layer": {
"redis_cluster": "分布式缓存集群",
"cache_strategy": "智能缓存策略",
"invalidation": "缓存失效机制"
},
"queue_system": {
"message_queue": "异步任务队列",
"priority_handling": "优先级处理",
"dead_letter_queue": "失败任务重试"
},
"monitoring_stack": {
"metrics_collection": "指标收集",
"logging_aggregation": "日志聚合",
"alerting_system": "智能告警",
"dashboard": "可视化监控面板"
}
}
def deploy_production_setup(self) -> Dict:
"""部署生产环境配置"""
deployment_config = {
"infrastructure": {
"compute_resources": {
"api_servers": "3个高可用API服务器",
"cache_servers": "Redis集群 (3主3从)",
"queue_workers": "10个异步处理节点",
"monitoring": "专用监控服务器"
},
"network_setup": {
"load_balancer": "HAProxy/Nginx负载均衡",
"cdn": "全球CDN加速",
"security": "WAF + DDoS防护",
"ssl": "企业级SSL证书"
}
},
"application_config": {
"api_client_pool": {
"pool_size": 50,
"connection_timeout": 30,
"read_timeout": 300,
"retry_policy": "指数退避重试"
},
"caching_policy": {
"ttl": "24小时",
"max_size": "10GB",
"eviction": "LRU策略"
},
"queue_config": {
"max_workers": 20,
"task_timeout": 600,
"retry_attempts": 3
}
},
"monitoring_setup": {
"metrics": [
"请求量QPS", "响应时间", "成功率",
"错误率", "缓存命中率", "队列长度"
],
"alerts": [
"API不可用", "响应时间过长", "错误率过高",
"缓存失效", "队列积压", "资源不足"
]
}
}
return deployment_config
def implement_high_availability(self):
"""实现高可用架构"""
ha_strategy = {
"redundancy": {
"multi_region": "多地域部署",
"failover": "自动故障切换",
"backup": "定时数据备份",
"disaster_recovery": "灾难恢复预案"
},
"scalability": {
"horizontal_scaling": "水平扩容",
"auto_scaling": "自动伸缩",
"resource_optimization": "资源动态调配"
},
"reliability": {
"circuit_breaker": "熔断器保护",
"bulkhead": "舱壁隔离",
"timeout_handling": "超时处理",
"graceful_degradation": "优雅降级"
}
}
return ha_strategy
# 企业级性能优化
class EnterprisePerformanceOptimizer:
"""企业级性能优化器"""
def __init__(self):
self.optimization_strategies = self._define_optimization_strategies()
def _define_optimization_strategies(self):
"""定义优化策略"""
return {
"request_optimization": {
"batching": "请求批处理合并",
"compression": "数据压缩传输",
"keep_alive": "连接复用",
"pipelining": "请求管道化"
},
"caching_optimization": {
"intelligent_caching": "智能缓存策略",
"cache_warming": "缓存预热",
"partial_caching": "部分内容缓存",
"cache_hierarchy": "多级缓存架构"
},
"resource_optimization": {
"connection_pooling": "连接池管理",
"memory_management": "内存优化",
"cpu_optimization": "CPU使用优化",
"io_optimization": "I/O性能优化"
}
}
def generate_optimization_plan(self, current_metrics: Dict) -> Dict:
"""生成优化方案"""
# 分析当前性能指标
performance_analysis = self._analyze_performance(current_metrics)
# 生成优化建议
optimization_plan = {
"immediate_actions": [],
"short_term_improvements": [],
"long_term_optimizations": [],
"expected_improvements": {}
}
# 基于分析结果生成具体建议
if performance_analysis["response_time"] > 15:
optimization_plan["immediate_actions"].append(
"启用请求缓存,预期响应时间减少60%"
)
if performance_analysis["error_rate"] > 0.05:
optimization_plan["immediate_actions"].append(
"实施重试机制,预期错误率降低80%"
)
if performance_analysis["throughput"] < 100:
optimization_plan["short_term_improvements"].append(
"增加并发处理能力,预期吞吐量提升3倍"
)
return optimization_plan
def _analyze_performance(self, metrics: Dict) -> Dict:
"""分析性能指标"""
return {
"response_time": metrics.get("avg_response_time", 0),
"error_rate": metrics.get("error_rate", 0),
"throughput": metrics.get("requests_per_second", 0),
"cache_hit_rate": metrics.get("cache_hit_rate", 0),
"resource_utilization": metrics.get("cpu_usage", 0)
}
# 企业级集成示例
enterprise_config = {
"environment": "production",
"scale": "large",
"requirements": ["high_availability", "high_performance", "security"]
}
enterprise_integration = EnterpriseNanoBananaIntegration(enterprise_config)
performance_optimizer = EnterprisePerformanceOptimizer()
print("🏢 企业级集成方案已配置")
print("🚀 高可用架构已部署")
print("⚡ 性能优化器已启用")
🏢 企业部署建议:对于大规模企业应用,建议采用完整的高可用架构和性能优化方案。API易平台提供专业的企业级技术支持,可以协助企业定制最适合的部署方案。
❓ API开发常见问题
Q1: 为什么 Nano Banana 使用对话补全端点而不是传统的图像生成端点?
设计理念解析:
兼容性优先的设计思路:
- ✅ 与现有图像模型(gpt-4o-image、sora_image)完全兼容
- ✅ 开发者可以通过简单替换模型名称实现无缝切换
- ✅ 减少学习成本和集成复杂度
- ✅ 统一的错误处理和响应格式
技术实现优势:
- 支持多轮对话式图像生成
- 更丰富的上下文理解能力
- 统一的API接口管理
- 更好的扩展性和维护性
迁移示例:
# 从其他模型切换只需要修改模型名称
# 原来的 gpt-4o-image 调用
old_model = "gpt-4o-image"
# 切换到 Nano Banana
new_model = "gemini-2.5-flash-image-preview"
# 其他参数保持不变
参考 API易官方文档 了解详细的兼容性说明。
Q2: 如何处理 API 调用失败和错误重试?
完整的错误处理策略:
错误分类处理:
- 4xx 客户端错误:检查参数格式、API密钥、账户余额
- 5xx 服务器错误:实施自动重试机制
- 网络错误:增加超时时间和重试次数
- 内容审核错误:优化提示词或联系技术支持
智能重试机制:
# 推荐的重试配置
retry_config = {
"max_retries": 3,
"base_delay": 1.0,
"backoff_strategy": "exponential",
"retriable_errors": [429, 500, 502, 503, 504]
}
最佳实践建议:
- 使用指数退避算法避免请求风暴
- 记录详细的错误日志便于问题排查
- 实施熔断器机制保护系统稳定性
- 建立监控告警及时发现问题
详细的错误处理代码示例请参考 飞书完整使用指南。
Q3: 如何优化 API 调用性能和成本?
性能优化策略:
请求优化:
- 使用连接池减少连接开销
- 实施请求缓存避免重复调用
- 采用异步处理提升并发能力
- 优化提示词质量减少重试次数
成本控制方案:
- 启用智能缓存机制(可节省70%重复请求成本)
- 使用API易平台的批量优惠(额外节省15-20%)
- 实施请求去重避免不必要的调用
- 建立成本监控和预算告警
架构优化:
# 性能优化配置示例
optimization_config = {
"connection_pool_size": 50,
"cache_ttl": 3600, # 1小时缓存
"concurrent_requests": 10,
"request_deduplication": True
}
成本计算工具:API易平台提供实时成本计算和预测工具,帮助企业优化使用策略。访问 API易官方文档 获取详细的成本优化指南。
Q4: 企业级部署需要考虑哪些因素?
企业级部署关键要素:
安全性要求:
- API密钥安全管理和轮换机制
- 网络安全防护(WAF、DDoS保护)
- 数据传输加密和存储安全
- 访问控制和审计日志
高可用性设计:
- 多地域部署和故障切换
- 负载均衡和自动扩容
- 服务监控和健康检查
- 灾难恢复和数据备份
合规性考虑:
- 数据隐私保护(GDPR、CCPA等)
- 内容审核和合规性检查
- 审计跟踪和日志记录
- 第三方安全认证
技术架构选择:
# 企业级架构建议
enterprise_architecture = {
"api_gateway": "统一API网关管理",
"microservices": "微服务架构设计",
"monitoring": "全链路监控体系",
"automation": "CI/CD自动化部署"
}
API易企业支持:API易平台提供专业的企业级技术咨询和定制化解决方案,包括架构设计、安全加固、性能优化等全方位支持。联系 API易技术团队 获取企业级服务。
📚 延伸学习资源
🛠️ 完整开发工具包
专为 Nano Banana API 开发的完整工具包,包含生产级代码示例和最佳实践:
# 快速获取开发工具包
git clone https://github.com/apiyi-api/nano-banana-sdk
cd nano-banana-sdk
# 环境配置
pip install -r requirements.txt
export APIYI_API_KEY=your_api_key
# 运行示例程序
python examples/basic_generation.py
python examples/batch_processing.py
python examples/enterprise_integration.py
工具包核心功能:
- 🔧 多语言SDK(Python、JavaScript、Java等)
- 📊 性能监控和分析工具
- 🔄 智能重试和错误处理
- 💰 成本计算和优化工具
- 🏢 企业级集成模板
- 📖 详细的API文档和示例
🔗 核心技术资源
| 资源类型 | 链接地址 | 内容特色 | 适用场景 |
|---|---|---|---|
| API易官方文档 | https://docs.apiyi.com/api-capabilities/nano-banana-image | 权威技术规范、实时更新 | 技术集成、参数查询 |
| 飞书完整指南 | https://xinqikeji.feishu.cn/wiki/A52zw4Bg5iTs5HkTLKJcOuXgnNg | 详细教程、互动支持 | 深度学习、问题解答 |
| GitHub示例库 | 开源代码示例集合 | 生产级实现方案 | 快速上手、最佳实践 |
| 技术社区 | 开发者交流平台 | 经验分享、问题讨论 | 技术交流、疑难解答 |
📖 学习路径建议:
🎯 持续学习建议
技术跟踪:
- 定期关注 Nano Banana 模型更新和新功能发布
- 学习AI图像生成领域的最新技术趋势
- 参与开发者社区讨论和经验分享
能力提升:
- 掌握企业级API集成架构设计
- 学习AI模型性能优化和成本控制
- 了解图像生成应用的商业化实践
资源更新:API易平台的技术文档和最佳实践会持续更新,建议定期访问获取最新的开发指南和优化建议。
🎯 总结
Nano Banana API 通过创新的对话补全端点设计,为开发者提供了一个强大、灵活且易于集成的图像生成解决方案。其独特的兼容性设计让开发者能够以最小的成本在不同模型间切换,最大化技术投资的价值。
核心优势回顾
技术优势:对话补全端点的兼容性设计,让开发者能够以15分钟内完成模型迁移,代码重用率高达95%
关键特性总结:
- 极简集成:仅需替换模型名称即可从其他图像模型无缝切换
- 完善文档:API易官方文档 + 飞书指南提供全方位技术支持
- 企业级支持:完整的高可用架构和性能优化方案
- 成本优化:智能缓存和批量优惠可节省高达70%的使用成本
最佳实践建议:
- 使用提供的完整代码示例快速上手开发
- 实施智能重试和性能监控确保应用稳定性
- 参考企业级集成方案进行生产环境部署
- 利用API易平台的技术支持和优化工具提升开发效率
最终建议:无论是个人开发者还是企业用户,都强烈推荐通过 API易平台 使用 Nano Banana API。平台不仅提供了完善的技术文档和开发工具,还有专业的技术支持团队,能够确保您的项目获得最佳的技术体验和商业价值。
立即访问 API易官方文档 开始您的 Nano Banana API 开发之旅!
📝 作者简介:资深AI API集成专家,专注企业级AI解决方案架构设计。深度参与多个大型AI项目的技术实施,拥有丰富的生产环境部署经验。更多技术文章和最佳实践分享可访问 API易技术社区。
🔔 技术支持:如需专业的API集成咨询、企业级部署方案或技术培训服务,欢迎通过 API易官方渠道 联系我们的技术专家团队。我们提供7×24小时技术支持,确保您的项目成功上线。