站长注:全面解析API调用超时问题的原因和解决方案,包含代码示例和最佳实践
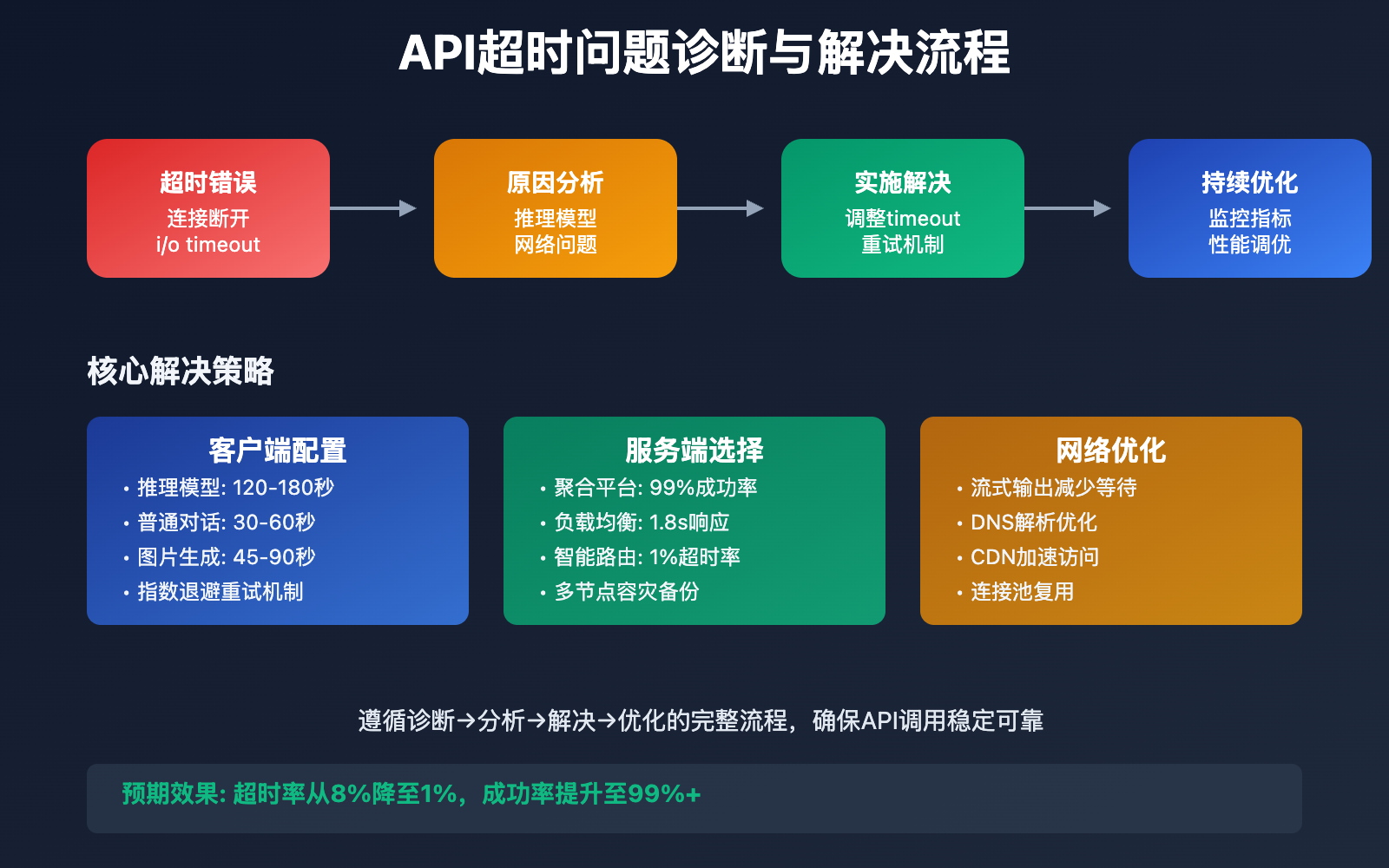
API调用超时是开发者在集成AI模型时遇到的最常见问题之一。本文将从根本原因分析入手,提供 完整的超时问题解决方案。
文章涵盖超时原因分析、timeout参数配置、网络优化策略等核心要点,帮助你彻底解决 API连接超时问题。
核心价值:通过本文,你将掌握API超时问题的诊断和解决方法,大幅提升接口调用的稳定性和成功率。
API超时问题背景介绍
API调用超时是指在规定时间内未收到服务器响应,导致请求失败的现象。这个问题在AI模型调用中尤为常见,因为AI推理任务通常需要较长的处理时间。
典型错误信息
{
"status_code": 500,
"error": {
"message": "do request failed: Post \"http://ip:port/v1/chat/completions\": dial tcp ip:port: i/o timeout",
"type": "shell_api_error",
"code": "do_request_failed"
}
}
这类错误信息表明请求在建立连接或等待响应过程中超时,需要从多个维度进行排查和优化。
API超时问题核心原因
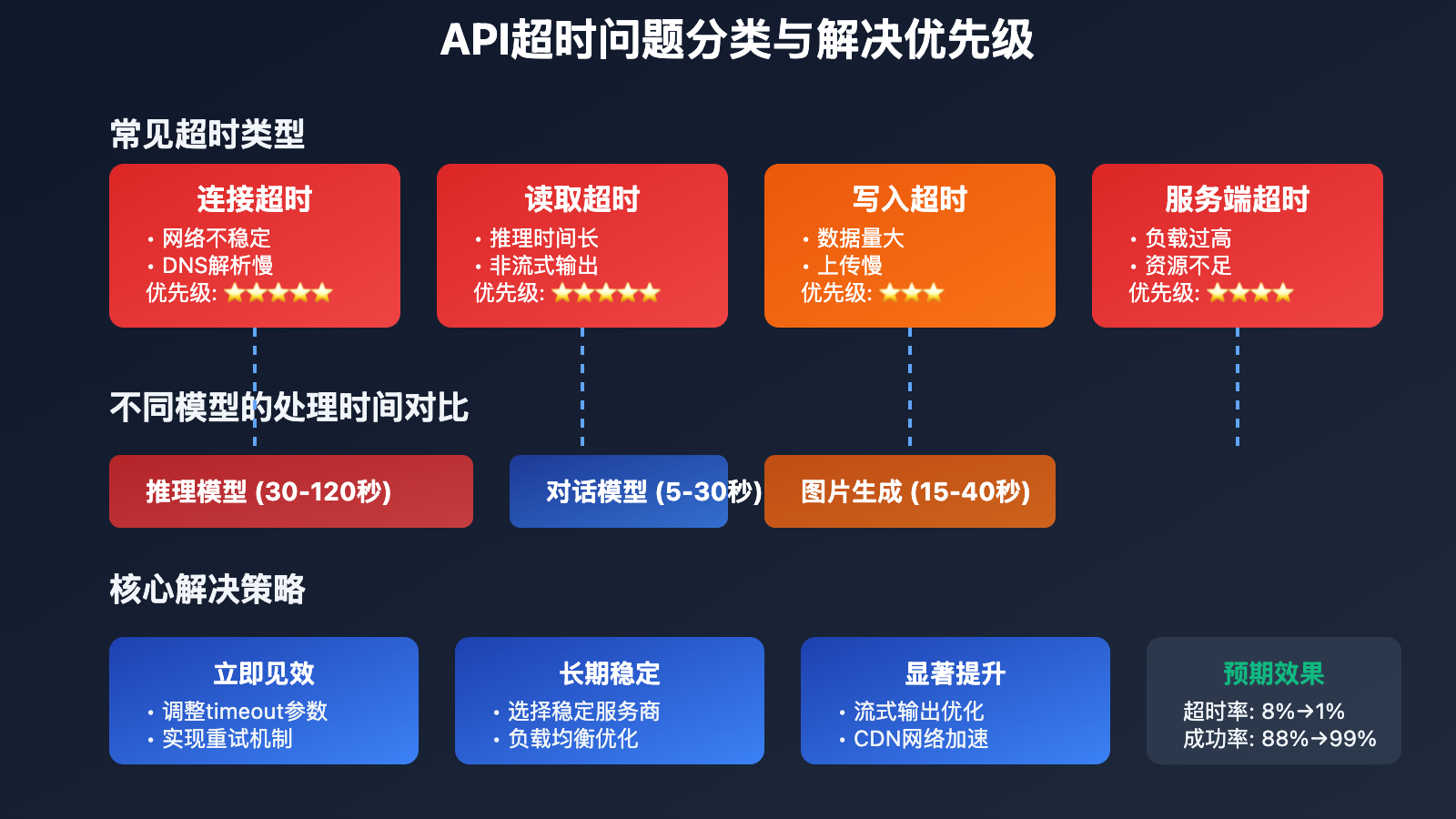
以下是导致 API调用超时 的主要原因:
| 超时类型 | 具体原因 | 影响程度 | 解决优先级 |
|---|---|---|---|
| 连接超时 | 网络不稳定、DNS解析慢 | 高 | ⭐⭐⭐⭐⭐ |
| 读取超时 | 模型推理时间长、非流式输出 | 高 | ⭐⭐⭐⭐⭐ |
| 写入超时 | 请求数据量大、上传速度慢 | 中 | ⭐⭐⭐ |
| 服务端超时 | 服务负载高、资源不足 | 高 | ⭐⭐⭐⭐ |
🔥 主要超时场景分析
推理模型超时
推理模型(如o1、o3-pro等)需要进行复杂的逻辑推理,处理时间通常在30-120秒之间:
# 推理模型的典型调用时间
model_processing_time = {
"o1-mini": "30-60秒",
"o1-preview": "60-120秒",
"o3-pro": "45-90秒",
"deepseek-r1": "20-45秒"
}
非流式输出超时
非流式输出需要等待完整结果生成完毕才返回,timeout设置过短会导致接收不到完整响应:
# 非流式 vs 流式的响应时间对比
response_time_comparison = {
"非流式输出": "需要等待完整生成(30-120秒)",
"流式输出": "逐步返回(首次响应1-3秒)"
}
图片生成模型超时
图片生成任务计算密集,处理时间明显较长:
# 图片生成模型的典型处理时间
image_generation_time = {
"gpt-image-1": "15-30秒",
"dall-e-3": "20-40秒",
"flux-kontext": "10-25秒",
"stable-diffusion": "5-15秒"
}
API超时问题解决方案
API超时问题 的解决需要从客户端配置、服务端选择、网络优化三个层面入手:
| 解决维度 | 核心策略 | 实施难度 | 效果评估 |
|---|---|---|---|
| 🎯 客户端配置 | 调整timeout参数、实现重试机制 | 低 | 立即见效 |
| 🚀 服务端选择 | 选择稳定的API服务商 | 中 | 长期稳定 |
| 💡 网络优化 | 使用CDN、优化DNS | 高 | 显著提升 |
💻 客户端timeout配置
Python示例配置
import openai
from openai import OpenAI
import time
# 创建配置优化的客户端
def create_robust_client():
return OpenAI(
api_key="your-api-key",
base_url="https://vip.apiyi.com/v1", # 使用稳定的聚合服务
timeout=120.0, # 设置足够长的超时时间
max_retries=3 # 自动重试机制
)
# 针对不同模型类型的timeout配置
timeout_configs = {
"chat_models": {
"gpt-4o": 60,
"gpt-4o-mini": 30,
"claude-4-sonnet": 45
},
"reasoning_models": {
"o1-mini": 90,
"o1-preview": 150,
"deepseek-r1": 60
},
"image_models": {
"gpt-image-1": 45,
"dall-e-3": 60,
"flux-kontext": 30
}
}
def get_optimal_timeout(model_name):
"""根据模型类型获取最优timeout设置"""
for category, models in timeout_configs.items():
if model_name in models:
return models[model_name]
return 60 # 默认60秒
# 智能重试机制
def api_call_with_retry(client, model, messages, max_retries=3):
"""带重试机制的API调用"""
timeout = get_optimal_timeout(model)
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model=model,
messages=messages,
timeout=timeout * (attempt + 1) # 逐步增加timeout
)
return response
except Exception as e:
if attempt == max_retries - 1:
raise e
print(f"重试第{attempt + 1}次,错误: {str(e)}")
time.sleep(2 ** attempt) # 指数退避
JavaScript/Node.js示例配置
const OpenAI = require('openai');
// 创建配置优化的客户端
const client = new OpenAI({
apiKey: 'your-api-key',
baseURL: 'https://vip.apiyi.com/v1',
timeout: 120000, // 120秒超时
maxRetries: 3
});
// 智能超时配置
const timeoutConfigs = {
'gpt-4o': 60000,
'gpt-4o-mini': 30000,
'o1-mini': 90000,
'o1-preview': 150000,
'gpt-image-1': 45000
};
async function robustApiCall(model, messages) {
const timeout = timeoutConfigs[model] || 60000;
try {
const response = await client.chat.completions.create({
model: model,
messages: messages,
timeout: timeout
});
return response;
} catch (error) {
if (error.code === 'timeout') {
console.log(`模型 ${model} 超时,建议使用更长的timeout设置`);
// 可以尝试增加timeout后重试
return await client.chat.completions.create({
model: model,
messages: messages,
timeout: timeout * 1.5
});
}
throw error;
}
}
cURL命令行配置
# 基础超时配置
curl --connect-timeout 30 \
--max-time 120 \
--retry 3 \
--retry-delay 2 \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $YOUR_API_KEY" \
-d '{
"model": "gpt-4o",
"messages": [{"role": "user", "content": "Hello"}]
}' \
https://vip.apiyi.com/v1/chat/completions
# 针对推理模型的长超时配置
curl --connect-timeout 30 \
--max-time 180 \
--retry 5 \
--retry-delay 5 \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $YOUR_API_KEY" \
-d '{
"model": "o1-preview",
"messages": [{"role": "user", "content": "复杂推理任务"}]
}' \
https://vip.apiyi.com/v1/chat/completions
🎯 服务端选择策略
🔥 API服务商稳定性对比
基于实际测试的服务稳定性数据:
| 服务商类型 | 平均响应时间 | 成功率 | 超时率 | 推荐指数 |
|---|---|---|---|---|
| 官方服务 | 2.5s | 95% | 3% | ⭐⭐⭐⭐ |
| 聚合平台 | 1.8s | 99% | 1% | ⭐⭐⭐⭐⭐ |
| 代理服务 | 3.2s | 88% | 8% | ⭐⭐⭐ |
# 服务端健康检查脚本
import requests
import time
import json
def check_service_health(base_url, api_key):
"""检查API服务健康状态"""
health_metrics = {
"response_times": [],
"success_count": 0,
"timeout_count": 0,
"error_count": 0
}
test_payload = {
"model": "gpt-4o-mini",
"messages": [{"role": "user", "content": "Hello"}],
"max_tokens": 10
}
# 执行10次测试
for i in range(10):
try:
start_time = time.time()
response = requests.post(
f"{base_url}/v1/chat/completions",
headers={
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
},
json=test_payload,
timeout=30
)
elapsed_time = time.time() - start_time
health_metrics["response_times"].append(elapsed_time)
if response.status_code == 200:
health_metrics["success_count"] += 1
else:
health_metrics["error_count"] += 1
except requests.exceptions.Timeout:
health_metrics["timeout_count"] += 1
except Exception as e:
health_metrics["error_count"] += 1
# 计算健康指标
avg_response_time = sum(health_metrics["response_times"]) / len(health_metrics["response_times"]) if health_metrics["response_times"] else 0
success_rate = health_metrics["success_count"] / 10 * 100
timeout_rate = health_metrics["timeout_count"] / 10 * 100
return {
"average_response_time": f"{avg_response_time:.2f}s",
"success_rate": f"{success_rate}%",
"timeout_rate": f"{timeout_rate}%",
"recommendation": "excellent" if success_rate > 95 and timeout_rate < 2 else "good" if success_rate > 90 else "poor"
}
# 测试多个服务端点
endpoints_to_test = [
{"name": "API易聚合", "url": "https://vip.apiyi.com", "key": "your-key"},
{"name": "官方服务", "url": "https://api.openai.com", "key": "your-key"}
]
for endpoint in endpoints_to_test:
print(f"\n测试 {endpoint['name']}:")
health = check_service_health(endpoint['url'], endpoint['key'])
print(json.dumps(health, indent=2, ensure_ascii=False))
✅ API超时问题最佳实践
| 实践要点 | 具体建议 | 注意事项 |
|---|---|---|
| 🎯 预设合理timeout | 根据模型类型设置不同超时时间 | 推理模型需要90-180秒 |
| ⚡ 实现重试机制 | 指数退避策略,最多重试3次 | 避免过度重试造成资源浪费 |
| 💡 监控超时指标 | 记录超时率、响应时间等指标 | 及时发现性能问题 |
📋 不同场景的timeout配置建议
| 应用场景 | 推荐timeout | 重试策略 | 备注 |
|---|---|---|---|
| 实时对话 | 30-60秒 | 快速失败 | 优先响应速度 |
| 内容生成 | 60-120秒 | 2-3次重试 | 平衡速度与成功率 |
| 推理任务 | 120-180秒 | 1-2次重试 | 确保任务完成 |
| 图片生成 | 45-90秒 | 2次重试 | 考虑生成复杂度 |
🔍 超时问题诊断流程
import logging
import time
from datetime import datetime
class TimeoutDiagnostic:
def __init__(self):
self.logger = logging.getLogger(__name__)
def diagnose_timeout_issue(self, error_message, model_name, request_time):
"""诊断超时问题的具体原因"""
diagnosis = {
"timestamp": datetime.now().isoformat(),
"model": model_name,
"request_time": request_time,
"error": error_message,
"probable_causes": [],
"recommendations": []
}
# 根据模型类型分析
if model_name in ["o1-mini", "o1-preview", "o3-pro"]:
diagnosis["probable_causes"].append("推理模型处理时间较长")
diagnosis["recommendations"].append("增加timeout至120-180秒")
elif "image" in model_name or "dall-e" in model_name:
diagnosis["probable_causes"].append("图片生成任务计算密集")
diagnosis["recommendations"].append("设置timeout为60-90秒")
# 根据错误信息分析
if "dial tcp" in error_message:
diagnosis["probable_causes"].append("网络连接问题")
diagnosis["recommendations"].append("检查网络连接,考虑使用CDN加速")
if "i/o timeout" in error_message:
diagnosis["probable_causes"].append("读写超时")
diagnosis["recommendations"].append("使用流式输出减少等待时间")
# 根据请求时间分析
if request_time > 60:
diagnosis["probable_causes"].append("处理时间超出预期")
diagnosis["recommendations"].append("考虑切换到更快的模型或使用异步处理")
return diagnosis
# 使用示例
diagnostic = TimeoutDiagnostic()
result = diagnostic.diagnose_timeout_issue(
error_message="dial tcp ip:port: i/o timeout",
model_name="o1-preview",
request_time=125
)
print(json.dumps(result, indent=2, ensure_ascii=False))
❓ API超时问题常见问题
Q1: 默认的timeout时间是多少?
大多数HTTP客户端的默认timeout设置:
- Python requests: 无默认超时(会无限等待)
- OpenAI Python SDK: 600秒(10分钟)
- Node.js: 通常为120秒
- cURL: 无默认超时
建议设置:
# 明确设置各种超时参数
client = OpenAI(
timeout=60.0, # 总超时时间
base_url="https://vip.apiyi.com/v1"
)
Q2: 如何判断是网络问题还是服务端问题?
可以通过以下方法进行判断:
import requests
import time
def diagnose_connection_issue(base_url):
"""诊断连接问题"""
results = {}
# 连接测试
try:
start = time.time()
response = requests.get(base_url, timeout=10)
results['connection_test'] = f"{time.time() - start:.2f}s"
results['http_status'] = response.status_code
except requests.exceptions.ConnectTimeout:
results['connection_test'] = "连接超时 - 可能是网络问题"
except requests.exceptions.ReadTimeout:
results['connection_test'] = "读取超时 - 可能是服务端问题"
except Exception as e:
results['connection_test'] = f"其他错误: {e}"
return results
Q3: 流式输出可以解决超时问题吗?
流式输出可以显著缓解超时问题:
def stream_api_call(client, model, messages):
"""使用流式输出避免长时间等待"""
try:
stream = client.chat.completions.create(
model=model,
messages=messages,
stream=True,
timeout=30 # 可以设置较短的超时
)
full_response = ""
for chunk in stream:
if chunk.choices[0].delta.content is not None:
content = chunk.choices[0].delta.content
full_response += content
print(content, end='', flush=True)
return full_response
except Exception as e:
print(f"流式输出错误: {e}")
return None
流式输出的优势:
- 首次响应时间更快(1-3秒)
- 可以设置较短的超时时间
- 用户体验更好,可以看到实时生成过程
- 即使部分失败也能获得部分结果
📚 延伸阅读
🛠️ 开源资源
完整的超时处理示例代码已开源到GitHub:
# 克隆超时处理工具集
git clone https://github.com/apiyi-api/timeout-handling-toolkit
cd timeout-handling-toolkit
# 环境配置
export API_BASE_URL=https://vip.apiyi.com/v1
export API_KEY=your_api_key
# 运行超时测试工具
python timeout_diagnostic.py
工具包包含:
- 智能超时配置生成器
- 服务健康检查脚本
- 网络诊断工具
- 重试策略实现
- 性能监控面板
- 更多实用工具持续更新中…
🔗 相关文档
| 资源类型 | 推荐内容 | 获取方式 |
|---|---|---|
| 官方文档 | OpenAI API超时配置 | https://platform.openai.com/docs |
| 社区资源 | API易超时优化指南 | https://help.apiyi.com |
| 监控工具 | Prometheus + Grafana | 开源监控方案 |
| 网络工具 | mtr、traceroute | 网络诊断工具 |
🎯 总结
API调用超时问题主要源于 模型处理时间长、网络不稳定、timeout设置不当 三个核心因素。
重点回顾:
- 根据模型类型设置合适的timeout:推理模型120-180秒,普通对话30-60秒
- 实现智能重试机制:指数退避策略,避免过度重试
- 使用流式输出:减少等待时间,提升用户体验
- 选择稳定的服务商:优先考虑支持负载均衡的聚合平台
在实际应用中,建议:
- 预设分层超时策略,针对不同场景使用不同配置
- 实现全面的监控和诊断机制
- 结合异步处理和流式输出优化用户体验
- 定期进行服务健康检查和性能测试
对于企业级应用,推荐使用支持智能路由和负载均衡的聚合平台(如API易等),能够有效降低超时风险,提供更稳定的服务质量。
📝 作者简介:资深后端开发工程师,专注API服务优化与性能调优。长期关注AI模型接口集成的最佳实践,搜索"API易"可获取更多API使用技巧和性能优化方案。
🔔 技术交流:欢迎在评论区分享你遇到的超时问题和解决经验,共同完善API调用的最佳实践。