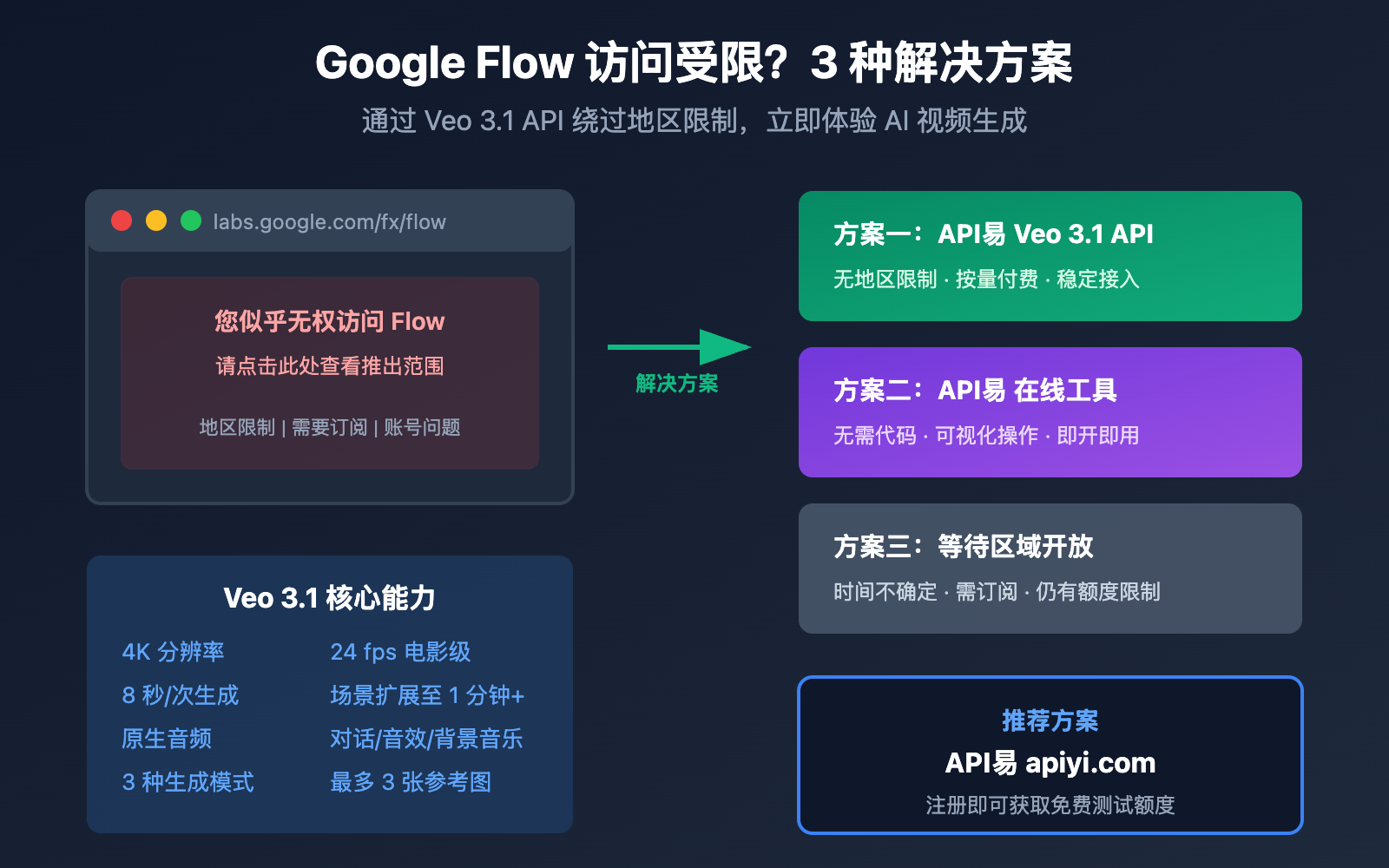
访问 Google Flow (labs.google/fx/zh/tools/flow) 时遇到「您似乎无权访问 Flow。请点击此处查看推出范围」的报错,是国内用户和部分海外用户常遇到的问题。本文将介绍 3 种有效的解决方案,包括直接通过 API 调用 Veo 3.1 生成高质量视频,帮助你绑过地区限制、快速实现 AI 视频创作。
核心价值: 读完本文,你将了解 Google Flow 访问限制的原因,掌握 Veo 3.1 API 调用方法,无需等待 Flow 开放即可立即体验顶级 AI 视频生成能力。
Google Flow 访问受限问题分析
在深入解决方案之前,我们需要先理解为什么会遇到 Google Flow 访问限制。
Google Flow 地区限制现状
Google Flow 作为 Google 最新的 AI 视频生成工具,目前并非全球开放。根据最新数据:
| 开放状态 | 时间节点 | 覆盖范围 |
|---|---|---|
| 初始发布 | 2025年5月 | 仅限美国 |
| 第一次扩展 | 2025年7月 | 70+ 国家 |
| 当前状态 | 2026年1月 | 140+ 国家 (仍不包含中国大陆) |
访问受限的常见原因
| 原因类型 | 具体说明 | 解决难度 |
|---|---|---|
| 地理位置限制 | 中国大陆等地区未开放 | ⭐⭐⭐ |
| 订阅等级不足 | 需要 Google AI Pro/Ultra 订阅 | ⭐⭐ |
| 账号资格问题 | 新账号或非 Google Workspace 账号 | ⭐⭐ |
| 企业策略限制 | 部分企业/政府禁用 AI 工具 | ⭐⭐⭐⭐ |
为什么直接使用 VPN 不是最佳方案
即使使用代理工具访问 Google Flow,仍存在以下问题:
- 需要付费订阅: Google AI Pro 每月 $19.99 起,AI Ultra 更贵
- 额度有限: 每月仅 100 credits (Workspace 用户),Pro 用户额度也有上限
- 生成速度受限: 高峰期排队时间长
- 使用体验不稳定: 网络延迟影响上传和下载
🎯 技术建议: 对于需要稳定调用 AI 视频生成能力的开发者和创作者,我们建议通过 API易 apiyi.com 平台直接调用 Veo 3.1 API。该平台提供稳定的国内访问接口,无需订阅 Google AI Pro,按量付费更灵活。
Veo 3.1 核心能力详解
在选择替代方案前,我们先了解 Google Veo 3.1 的核心能力,这是目前最先进的 AI 视频生成模型之一。
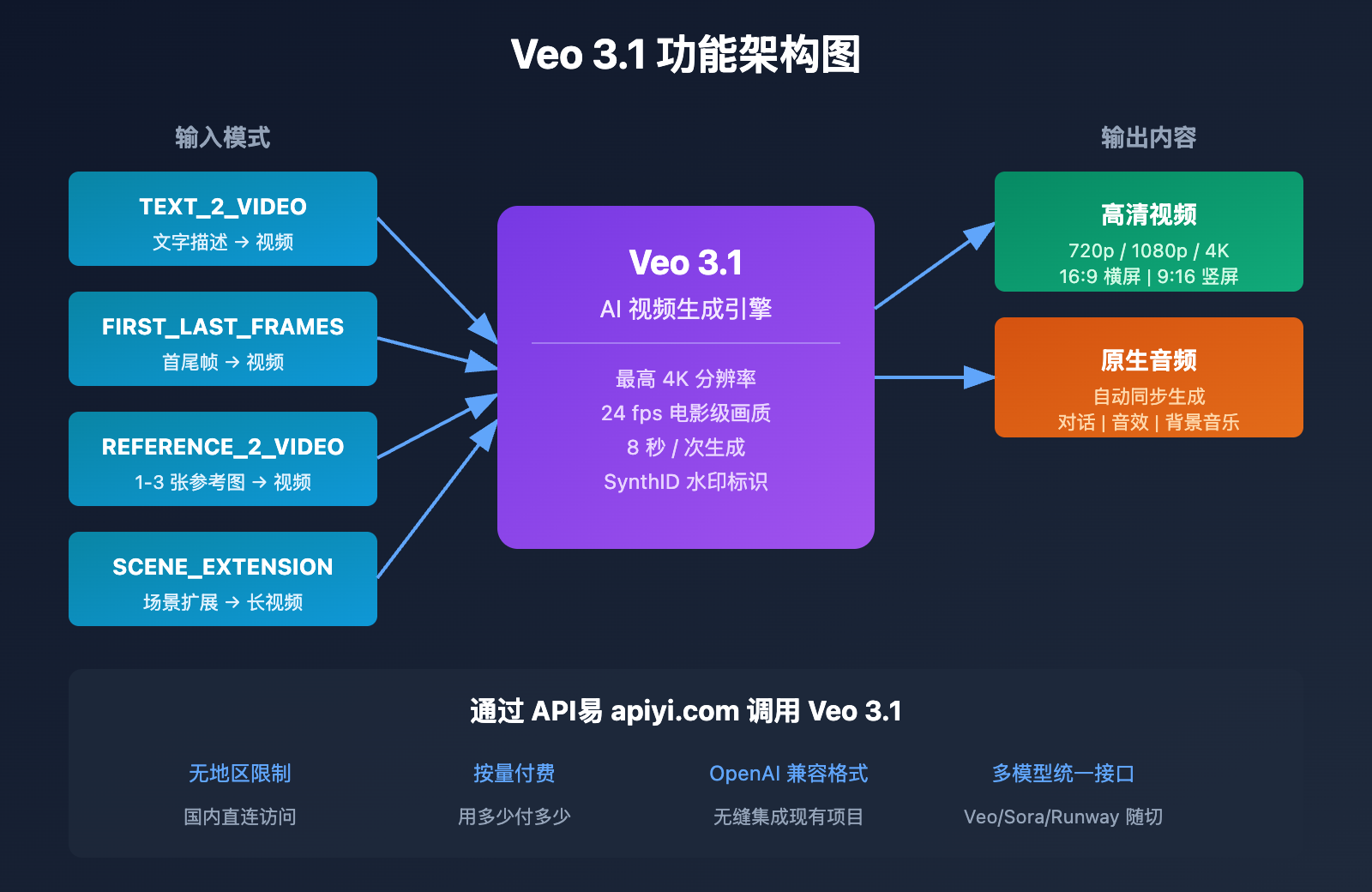
Veo 3.1 技术规格
| 技术指标 | 具体参数 | 说明 |
|---|---|---|
| 最高分辨率 | 4K | 支持 720p / 1080p / 4K |
| 帧率 | 24 fps | 电影级流畅度 |
| 视频时长 | 8 秒/次 | 可通过场景扩展连接至 1 分钟+ |
| 画面比例 | 16:9 / 9:16 | 支持横屏和竖屏 |
| 音频生成 | 原生支持 | 对话、音效、环境音全自动同步 |
| 参考图支持 | 最多 3 张 | 保持角色和风格一致性 |
Veo 3.1 生成模式
Veo 3.1 支持 3 种核心生成模式:
| 生成模式 | 英文名称 | 使用场景 |
|---|---|---|
| 文生视频 | TEXT_2_VIDEO | 纯文字描述生成视频 |
| 首尾帧控制 | FIRST_AND_LAST_FRAMES_2_VIDEO | 精确控制镜头起止构图 |
| 参考图生成 | REFERENCE_2_VIDEO | 基于 1-3 张图片引导生成 |
原生音频生成能力
Veo 3.1 最具突破性的能力是 原生音频生成:
- 对话生成: 使用引号指定角色台词,模型自动生成同步语音
- 音效生成: 根据画面内容自动匹配脚步声、环境音等
- 背景音乐: 智能生成与画面情绪匹配的背景音乐
这意味着你不再需要后期配音和音效剪辑,一次生成即可获得完整的视听内容。
Google Flow 访问受限的 3 种解决方案
针对不同用户需求,我们提供 3 种解决方案。
方案一: 通过 API易 调用 Veo 3.1 API (推荐)
这是最灵活、最稳定的解决方案,适合开发者和内容创作者。
核心优势
| 优势项 | 说明 |
|---|---|
| 无需订阅 | 不需要 Google AI Pro/Ultra 订阅 |
| 按量付费 | 用多少付多少,无月费 |
| 国内稳定访问 | 无需代理,直连调用 |
| 标准 API 接口 | OpenAI 兼容格式,易于集成 |
| 多模型切换 | 同一接口可切换 Veo 3.1、Veo 3、Sora 等 |
快速上手代码
import requests
import time
# API易 Veo 3.1 视频生成
def generate_video_veo31(prompt, aspect_ratio="16:9"):
"""
使用 Veo 3.1 生成视频
Args:
prompt: 视频描述文本
aspect_ratio: 画面比例,支持 "16:9" 或 "9:16"
Returns:
视频下载 URL
"""
headers = {
"Authorization": "Bearer YOUR_API_KEY", # 替换为你的 API易 密钥
"Content-Type": "application/json"
}
# 提交生成任务
response = requests.post(
"https://api.apiyi.com/v1/videos/generations", # API易 统一接口
headers=headers,
json={
"model": "veo-3.1",
"prompt": prompt,
"aspect_ratio": aspect_ratio,
"duration": 8 # 8 秒视频
}
)
task_id = response.json()["id"]
print(f"任务已提交,ID: {task_id}")
# 轮询获取结果
while True:
result = requests.get(
f"https://api.apiyi.com/v1/videos/generations/{task_id}",
headers=headers
).json()
if result["status"] == "completed":
return result["video_url"]
elif result["status"] == "failed":
raise Exception(f"生成失败: {result.get('error')}")
time.sleep(5) # 每 5 秒查询一次
# 使用示例
video_url = generate_video_veo31(
prompt="一只金毛犬在阳光下的草地上奔跑,慢动作镜头,背景是蓝天白云,电影级画质",
aspect_ratio="16:9"
)
print(f"视频已生成: {video_url}")
查看带音频生成的完整代码
import requests
import time
import os
class Veo31VideoGenerator:
"""Veo 3.1 视频生成器 - 支持原生音频"""
def __init__(self, api_key):
self.api_key = api_key
self.base_url = "https://api.apiyi.com/v1" # API易 统一接口
self.headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
def text_to_video(self, prompt, aspect_ratio="16:9", with_audio=True):
"""
文生视频 (TEXT_2_VIDEO)
Args:
prompt: 视频描述,可包含对话 (使用引号)
aspect_ratio: "16:9" 横屏 或 "9:16" 竖屏
with_audio: 是否生成原生音频
Returns:
dict: 包含 video_url 和 status 的结果
"""
payload = {
"model": "veo-3.1",
"mode": "TEXT_2_VIDEO",
"prompt": prompt,
"aspect_ratio": aspect_ratio,
"generate_audio": with_audio,
"duration": 8
}
return self._submit_and_wait(payload)
def first_last_frame_to_video(self, prompt, first_frame_url, last_frame_url):
"""
首尾帧控制生成 (FIRST_AND_LAST_FRAMES_2_VIDEO)
Args:
prompt: 视频过渡描述
first_frame_url: 第一帧图片 URL
last_frame_url: 最后一帧图片 URL
Returns:
dict: 生成结果
"""
payload = {
"model": "veo-3.1",
"mode": "FIRST_AND_LAST_FRAMES_2_VIDEO",
"prompt": prompt,
"first_frame": first_frame_url,
"last_frame": last_frame_url,
"duration": 8
}
return self._submit_and_wait(payload)
def reference_to_video(self, prompt, reference_images):
"""
参考图生成 (REFERENCE_2_VIDEO)
Args:
prompt: 视频描述
reference_images: 参考图 URL 列表 (1-3 张)
Returns:
dict: 生成结果
"""
if len(reference_images) > 3:
raise ValueError("最多支持 3 张参考图")
payload = {
"model": "veo-3.1",
"mode": "REFERENCE_2_VIDEO",
"prompt": prompt,
"reference_images": reference_images,
"duration": 8
}
return self._submit_and_wait(payload)
def extend_video(self, previous_video_url, extension_prompt):
"""
场景扩展 - 基于上一个视频的最后一帧继续生成
Args:
previous_video_url: 上一个视频的 URL
extension_prompt: 扩展场景描述
Returns:
dict: 新视频结果
"""
payload = {
"model": "veo-3.1",
"mode": "SCENE_EXTENSION",
"previous_video": previous_video_url,
"prompt": extension_prompt,
"duration": 8
}
return self._submit_and_wait(payload)
def _submit_and_wait(self, payload, max_wait=300):
"""提交任务并等待完成"""
# 提交任务
response = requests.post(
f"{self.base_url}/videos/generations",
headers=self.headers,
json=payload
)
if response.status_code != 200:
raise Exception(f"提交失败: {response.text}")
task_id = response.json()["id"]
print(f"✅ 任务提交成功,ID: {task_id}")
# 轮询等待
start_time = time.time()
while time.time() - start_time < max_wait:
result = requests.get(
f"{self.base_url}/videos/generations/{task_id}",
headers=self.headers
).json()
status = result.get("status")
if status == "completed":
print(f"🎬 视频生成完成!")
return {
"status": "success",
"video_url": result["video_url"],
"duration": result.get("duration", 8),
"resolution": result.get("resolution", "1080p")
}
elif status == "failed":
raise Exception(f"生成失败: {result.get('error')}")
else:
progress = result.get("progress", 0)
print(f"⏳ 生成中... {progress}%")
time.sleep(5)
raise TimeoutError("生成超时,请稍后查询结果")
# ========== 使用示例 ==========
if __name__ == "__main__":
# 初始化生成器
generator = Veo31VideoGenerator(api_key="YOUR_API_KEY")
# 示例 1: 文生视频 (带对话音频)
result = generator.text_to_video(
prompt='''
一位年轻女性站在咖啡店柜台前,微笑着说:"我要一杯拿铁"。
咖啡师点头回应:"好的,稍等"。
背景是温馨的咖啡店氛围,轻柔的爵士乐。
''',
aspect_ratio="16:9",
with_audio=True
)
print(f"视频地址: {result['video_url']}")
# 示例 2: 首尾帧控制 (精确构图)
result = generator.first_last_frame_to_video(
prompt="镜头从特写逐渐拉远,展示整个城市天际线",
first_frame_url="https://example.com/closeup.jpg",
last_frame_url="https://example.com/skyline.jpg"
)
# 示例 3: 生成长视频 (多次扩展)
clips = []
# 生成第一个片段
clip1 = generator.text_to_video("日出时分,海面波光粼粼,一艘帆船缓缓驶来")
clips.append(clip1["video_url"])
# 扩展后续片段
clip2 = generator.extend_video(clip1["video_url"], "帆船靠近港口,渔民开始忙碌")
clips.append(clip2["video_url"])
clip3 = generator.extend_video(clip2["video_url"], "渔民们满载而归,脸上洋溢着笑容")
clips.append(clip3["video_url"])
print(f"已生成 3 个连续片段: {clips}")
🚀 快速开始: 推荐使用 API易 apiyi.com 平台快速体验 Veo 3.1。该平台提供开箱即用的 API 接口,无需复杂配置,注册即可获取测试额度。
方案二: 通过 API易 视频生成工具使用
如果你不擅长编程,API易 还提供在线可视化工具,无需代码即可生成视频。
使用步骤
- 访问 apiyi.com 并注册账号
- 进入「AI 工具」-「视频生成」
- 选择 Veo 3.1 模型
- 输入视频描述 (支持中文)
- 选择画面比例和分辨率
- 点击生成,等待结果
工具功能对比
| 功能 | Google Flow | API易 在线工具 |
|---|---|---|
| 访问限制 | 需要特定地区 + 订阅 | 无地区限制 |
| 语言支持 | 仅英文最优 | 中英文均可 |
| 生成速度 | 受排队影响 | 较快 |
| 结果下载 | 2 天后过期 | 永久保存 |
| 付费方式 | 月度订阅 | 按次/按量 |
| API 接口 | 有 | 有 |
方案三: 等待 Google Flow 区域扩展
如果你不着急使用,也可以选择等待 Google 继续扩展 Flow 的可用区域。
根据 Google 的扩展历史:
- 2025年5月: 美国首发
- 2025年7月: 扩展至 70+ 国家
- 2025年7月底: 扩展至 140+ 国家
预计趋势: Google 可能在未来几个月内继续扩展覆盖范围,但中国大陆何时开放仍不确定。
Veo 3.1 API 调用实战指南
本节详细介绍各种使用场景的 API 调用方法。

场景一: 短视频内容创作
适合抖音、小红书等短视频平台的竖屏内容。
# 竖屏短视频生成
result = generator.text_to_video(
prompt="""
一位美食博主在厨房制作蛋糕,
特写镜头展示奶油裱花过程,
最后展示成品蛋糕,背景是轻快的音乐
""",
aspect_ratio="9:16", # 竖屏比例
with_audio=True
)
场景二: 电商产品展示
360度产品展示视频,适合电商详情页。
# 产品展示视频
result = generator.text_to_video(
prompt="""
一款高端机械手表在黑色背景下缓慢旋转,
光线从侧面打来,突出金属质感和表盘细节,
环绕拍摄,专业产品广告风格
""",
aspect_ratio="16:9",
with_audio=False # 产品展示通常不需要音频
)
场景三: 广告创意测试
快速生成多版本广告创意进行 A/B 测试。
# 批量生成广告创意
prompts = [
"年轻情侣在咖啡厅约会,品尝新款饮品,温馨浪漫氛围",
"商务人士在办公室,一杯咖啡提神醒脑,专业高效形象",
"大学生在图书馆学习,咖啡陪伴熬夜复习,青春活力场景"
]
for i, prompt in enumerate(prompts):
result = generator.text_to_video(prompt, aspect_ratio="16:9")
print(f"创意版本 {i+1}: {result['video_url']}")
场景四: 长视频制作
通过场景扩展功能,生成 1 分钟以上的连贯视频。
# 生成品牌故事长视频
scenes = [
"清晨,一家小咖啡馆刚刚开门,店主在准备第一杯咖啡",
"顾客陆续到来,店内渐渐热闹起来,充满咖啡香气",
"午后阳光透过窗户,一位老顾客在角落安静阅读",
"傍晚,店主微笑着送走最后一位客人,关上店门",
]
video_clips = []
previous_clip = None
for scene in scenes:
if previous_clip is None:
result = generator.text_to_video(scene)
else:
result = generator.extend_video(previous_clip, scene)
video_clips.append(result["video_url"])
previous_clip = result["video_url"]
print(f"已生成 {len(video_clips)} 个连续片段,共约 {len(video_clips) * 8} 秒")
Veo 3.1 与其他 AI 视频模型对比
选择 AI 视频生成模型时,了解各模型的特点很重要。
| 对比维度 | Veo 3.1 | Sora | Runway Gen-3 | Pika 2.0 |
|---|---|---|---|---|
| 最高分辨率 | 4K | 1080p | 4K | 1080p |
| 单次时长 | 8秒 | 60秒 | 10秒 | 5秒 |
| 原生音频 | ✅ 支持 | ✅ 支持 | ❌ 不支持 | ❌ 不支持 |
| 首尾帧控制 | ✅ 支持 | ✅ 支持 | ✅ 支持 | ✅ 支持 |
| 参考图数量 | 最多 3 张 | 最多 1 张 | 最多 1 张 | 最多 1 张 |
| 场景扩展 | ✅ 支持 | ✅ 支持 | ❌ 不支持 | ❌ 不支持 |
| 中文提示词 | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ |
| API易 支持 | ✅ | ✅ | ✅ | ✅ |
💡 选择建议: 选择哪个模型主要取决于您的具体应用场景。如需原生音频和 4K 画质,Veo 3.1 是目前最佳选择;如需超长视频,Sora 单次可生成 60 秒。我们建议通过 API易 apiyi.com 平台进行实际测试对比,该平台支持以上所有模型的统一接口调用。
各模型适用场景
| 使用场景 | 推荐模型 | 原因 |
|---|---|---|
| 短视频内容创作 | Veo 3.1 | 原生音频 + 高画质 |
| 长视频/短剧制作 | Sora | 单次 60 秒最长 |
| 产品展示广告 | Veo 3.1 / Runway | 4K 高画质 |
| 快速创意测试 | Pika 2.0 | 生成速度快 |
| 角色一致性视频 | Veo 3.1 | 支持 3 张参考图 |
常见问题
Q1: API易 的 Veo 3.1 API 和 Google 官方 API 有什么区别?
API易 平台通过官方渠道接入 Veo 3.1 能力,技术上与 Google 官方 API 完全一致。主要区别在于:
- 访问便捷性: 无需科学上网,国内直连访问
- 付费方式: 按量付费,无需订阅 Google AI Pro
- 接口格式: 提供 OpenAI 兼容格式,便于集成
- 额度灵活: 不受 Google 每月 credits 限制
通过 API易 apiyi.com 可以获取免费测试额度,快速验证效果。
Q2: Veo 3.1 生成的视频会有水印吗?
所有通过 Veo 3.1 生成的视频都会包含 SynthID 隐形水印,这是 Google 用于标识 AI 生成内容的技术。这个水印:
- 肉眼不可见
- 不影响视频画质
- 可被专门检测工具识别
- 符合 AI 内容标注规范
这是 Google 的安全措施,通过任何渠道调用 Veo 3.1 都会包含此水印。
Q3: 如何提高 Veo 3.1 生成视频的质量?
优化提示词是关键,建议包含以下要素:
| 要素 | 示例 | 作用 |
|---|---|---|
| 主体描述 | 一只金毛犬 | 明确画面主角 |
| 动作状态 | 在草地上奔跑 | 定义动态 |
| 镜头语言 | 慢动作、特写、环绕拍摄 | 控制拍摄风格 |
| 光线氛围 | 阳光、黄昏、工作室灯光 | 设定氛围 |
| 画面风格 | 电影级、纪录片风格、动画风格 | 整体风格 |
| 音频提示 | 轻快的音乐、"对话内容" | 控制声音 |
Q4: 生成的视频保存多久?
- Google 官方: 生成后 2 天内需下载,否则会被删除
- API易 平台: 视频永久保存在你的账户中,可随时下载
Q5: 能否用于商业用途?
根据 Google 服务条款,使用 Veo 3.1 生成的内容可用于商业用途,但需要:
- 确保提示词和参考图不侵犯他人知识产权
- 不生成违规内容 (暴力、色情等)
- 遵守当地法律法规
API易 平台同样遵循这些规范。
Prompt 编写技巧
掌握 Veo 3.1 的 Prompt 编写技巧,可以显著提升生成质量。
结构化提示词模板
[主体] + [动作] + [环境] + [镜头] + [风格] + [音频]
示例:
一位身穿红裙的年轻女性 (主体)
在巴黎街头漫步 (动作)
背景是埃菲尔铁塔和咖啡馆 (环境)
跟拍镜头,保持中景 (镜头)
法国新浪潮电影风格,胶片质感 (风格)
轻柔的手风琴音乐,偶尔传来街头的喧嚣声 (音频)
音频生成技巧
| 音频类型 | 提示词写法 | 示例 |
|---|---|---|
| 对话 | 使用引号包裹 | 她说:"今天天气真好" |
| 音效 | 明确描述声音来源 | 脚步声回荡在走廊 |
| 环境音 | 描述环境特征 | 繁忙的咖啡馆,杯碟碰撞声 |
| 背景音乐 | 描述音乐类型和情绪 | 轻快的爵士乐,愉悦氛围 |
常见问题与解决
| 问题 | 可能原因 | 解决方案 |
|---|---|---|
| 画面抖动 | 未指定镜头稳定 | 添加"稳定镜头"、"三脚架拍摄" |
| 人物变形 | 描述不够具体 | 详细描述外貌特征,使用参考图 |
| 风格不符 | 风格关键词模糊 | 使用具体的电影/导演风格参考 |
| 音频不同步 | 动作与对话冲突 | 简化场景,减少同时发生的事件 |
总结
Google Flow 访问受限是许多用户面临的实际问题,但这并不意味着无法体验 Veo 3.1 的强大能力。
三种方案对比
| 方案 | 适合人群 | 优势 | 劣势 |
|---|---|---|---|
| API易 API 调用 | 开发者、技术团队 | 灵活、可集成、无地区限制 | 需要编程能力 |
| API易 在线工具 | 内容创作者 | 无代码、易上手 | 功能相对固定 |
| 等待 Flow 开放 | 不着急的用户 | 官方体验 | 时间不确定 |
核心建议
- 立即需要: 选择 API易 平台,5 分钟即可开始生成
- 重视性价比: API易 按量付费,比订阅更灵活
- 需要长期集成: API易 API 提供稳定的生产环境接口
- 多模型需求: API易 支持 Veo 3.1、Sora、Runway 等统一调用
推荐通过 API易 apiyi.com 快速验证 Veo 3.1 效果,该平台提供免费测试额度,注册即可体验。
参考资料
-
Google Labs Flow 帮助中心: 官方使用指南
- 链接:
support.google.com/labs/answer/16353333
- 链接:
-
Veo 3.1 开发者文档: Gemini API 视频生成指南
- 链接:
ai.google.dev/gemini-api/docs/video
- 链接:
-
Google DeepMind Veo 介绍: 模型技术背景
- 链接:
deepmind.google/models/veo
- 链接:
-
Vertex AI Veo 3.1 文档: 企业级 API 文档
- 链接:
docs.cloud.google.com/vertex-ai/generative-ai/docs/models/veo/3-1-generate
- 链接:

本文由 API易技术团队撰写,如有疑问欢迎访问 apiyi.com 获取技术支持。