站长注:深入解析 OpenAI 的 Responses Evaluation API,了解如何评估和优化大模型性能,提升AI应用质量
随着大模型应用在各行业的广泛落地,如何确保模型输出的质量和可靠性成为了开发者面临的重要挑战。OpenAI 推出的 Responses Evaluation API 提供了一套强大的评估工具,可以帮助开发者系统化地评估模型性能,比较不同模型的表现,从而构建更高质量的 AI 应用。本文将深入解析 Responses Evaluation API 的功能和使用方法,帮助你建立科学有效的模型评估体系。
欢迎免费试用 API易,3 分钟跑通 API 调用 www.apiyi.com
支持 OpenAI 最新 Evaluation API 及全系列模型,让模型评估更简单高效
注册可送 1.1 美金额度起,约 300万 Tokens 额度体验。立即免费注册
加站长个人微信:8765058,发送你《大模型使用指南》等资料包,并加赠 1 美金额度。
Responses Evaluation API 背景介绍
随着 AI 模型的快速迭代和更新,如何确定新版本模型是否真的比旧版本更优秀,或者如何在众多可选模型中选择最适合特定任务的模型,成为了开发者面临的关键问题。传统的评估方法往往依赖人工审核,费时费力且难以大规模实施。
Responses Evaluation API 是 OpenAI 推出的专业评估工具,它允许开发者使用已有的交互日志数据,或设计特定的测试用例,来系统化评估不同模型的表现。这一工具特别适合进行模型升级前的质量验证、不同模型的性能对比,以及特定场景下的适用性测试。

Responses Evaluation API 核心功能
Responses Evaluation API 评估框架
Responses Evaluation API 提供了一个完整的评估框架,包括:
-
数据源配置:可以直接使用已有的响应日志作为评估数据源,无需额外收集数据。这对于已经有大量用户交互的应用来说,可以极大简化评估过程。
-
评估标准定义:支持自定义评估标准和评分体系,可以根据特定任务的需求设置不同的评分维度和权重。
-
模型比较:可以使用相同的输入数据评估不同模型的表现,直观比较新旧模型或不同模型之间的差异。
-
结果可视化:提供清晰的评估结果报告和可视化界面,帮助开发者快速理解模型优缺点。
Responses Evaluation API 使用场景
Responses Evaluation API 特别适合以下场景:
-
模型升级验证:在升级到新版本模型前,验证新模型是否在关键指标上有所提升。
-
多模型对比选型:在多个可选模型中,根据特定任务需求选择最合适的模型。
-
持续质量监控:设置自动化评估流程,持续监控模型输出质量,及时发现问题。
-
特定能力测试:针对特定能力(如代码解释、创意写作、逻辑推理等)进行深入评估。

Responses Evaluation API 应用场景
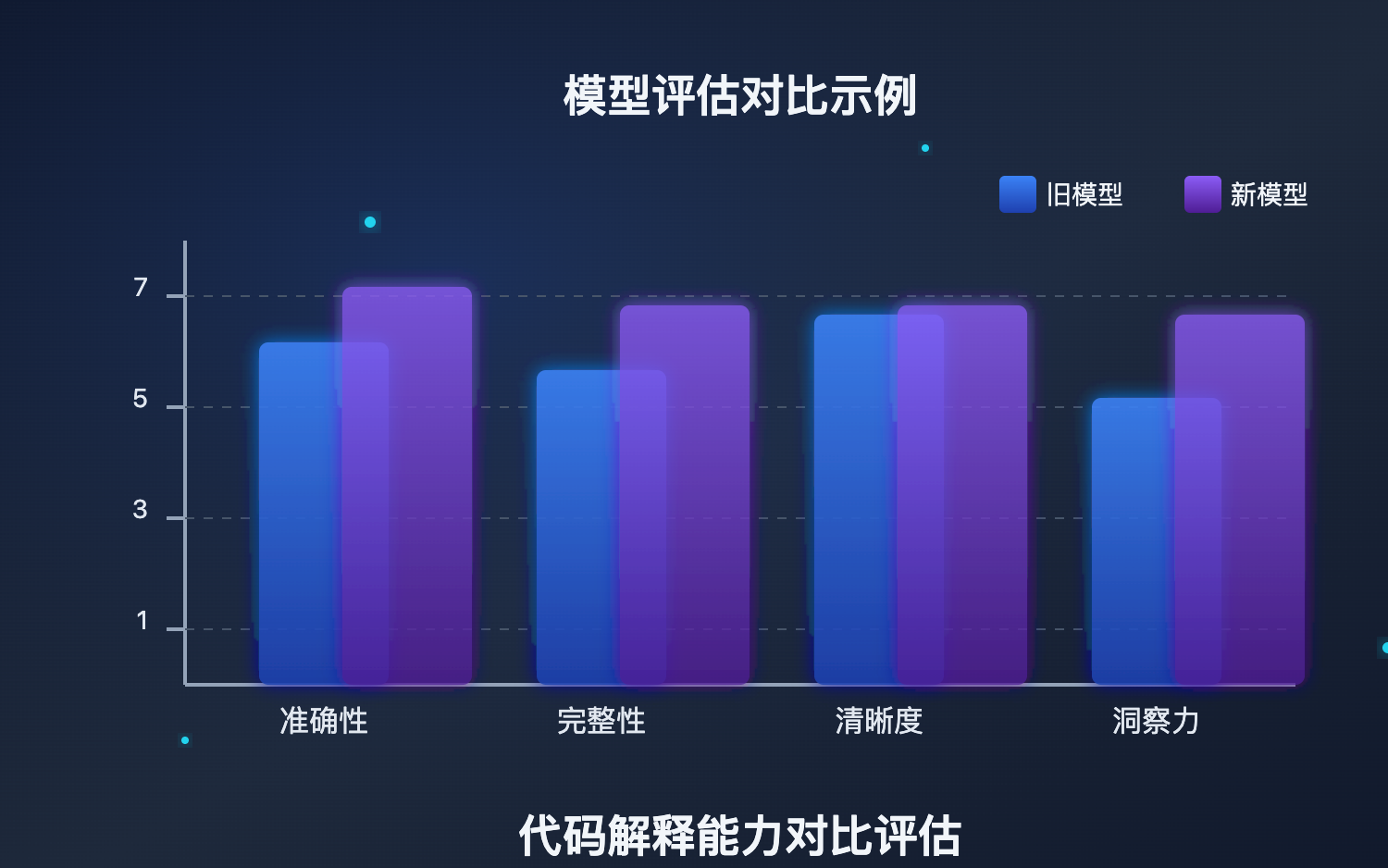
让我们通过一个具体案例来深入了解 Responses Evaluation API 的应用:假设你正在开发一个代码解释助手,需要比较 gpt-4o-mini 和最新的 gpt-4.1-mini 在解释代码方面的能力,以决定是否升级模型。
使用 Responses Evaluation API,你可以:
-
收集评估数据:使用现有模型对一系列代码片段生成解释,这些数据会存储在你的响应日志中。
-
设计评估标准:创建专门针对代码解释质量的评分标准,包括准确性、完整性、清晰度和洞察力等维度。
-
运行对比评估:使用相同的代码片段,让新模型生成解释,并与旧模型的结果进行对比评估。
-
分析评估结果:通过评估报告,了解两个模型在各个维度的优劣,做出数据驱动的决策。
这种系统化的评估方法不仅可以节省大量人工审核时间,还能提供更客观、更全面的比较结果。
Responses Evaluation API 开发指南
1. 模型选择
模型服务介绍
API易,行业领先的API中转站,均为官方源头转发,价格略有优势,聚合各种优秀大模型,使用起来很方便。
企业级专业稳定的OpenAI o3/Claude 3.7/Deepseek R1/Gemini 等全模型官方同源接口的中转分发。不限速,不过期,不惧封号,按量计费,长期可靠服务;让技术助力科研、公益事业!
当前评估器模型推荐
对于 Responses Evaluation API,以下模型特别推荐作为评估器:
- 评估器模型
o3:OpenAI 最强大的推理模型,评估能力卓越,适合复杂评估任务(推荐指数:⭐⭐⭐⭐⭐)gpt-4o:平衡的推理能力,适合一般评估场景,成本更经济(推荐指数:⭐⭐⭐⭐)
- 被评估模型(可通过 API易 稳定访问的全系列模型)
- OpenAI 系列:
o3,o4-mini,gpt-4o,gpt-4o-mini等 - Claude 系列:
claude-3-7-sonnet,claude-3-5-sonnet等 - Gemini 系列:
gemini-2.5-pro,gemini-2.5-flash等 - 更多模型,详见 API易 价格页面
注意:具体价格请参考 API易价格页面
评估场景推荐
-
代码理解评估
- 评估器:
o3– 对代码理解深入,能准确评判解释质量 - 被评估模型:各编程型模型,如
o4-mini,claude-3-7-sonnet等
- 评估器:
-
创意写作评估
- 评估器:
o3或gpt-4o– 具备良好的文学鉴赏能力 - 被评估模型:创意能力强的模型,如
claude-3-7-sonnet,gpt-4o等
- 评估器:
-
知识准确性评估
- 评估器:
o3– 知识面广,判断准确 - 被评估模型:各种通用或垂直领域模型
- 评估器:
Responses Evaluation API 实践示例
以下是使用 API易 接口进行模型评估的基本示例:
# 创建评估任务
curl https://vip.apiyi.com/v1/evals \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $替换你的API易后台的Key$" \
-d '{
"name": "代码解释质量评估",
"data_source_config": {
"type": "logs"
},
"testing_criteria": [
{
"type": "score_model",
"name": "代码解释评估器",
"model": "o3",
"input": [
{
"role": "system",
"content": "您是代码解释质量评估专家。请评估模型对代码的解释质量,从准确性、完整性、清晰度和洞察力四个维度进行评分,总分为1-7分。"
},
{
"role": "user",
"content": "{{item.input}}\n\n模型回答:\n{{sample.output_text}}"
}
],
"range": [1, 7],
"pass_threshold": 5.5
}
]
}'
# 运行评估 - 老模型评估
curl https://vip.apiyi.com/v1/evals/runs \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $替换你的API易后台的Key$" \
-d '{
"name": "gpt-4o-mini评估",
"eval_id": "eval_abc123", # 替换为上一步创建的评估ID
"data_source": {
"type": "responses",
"source": {"type": "responses", "limit": 10},
}
}'
# 运行评估 - 新模型评估
curl https://vip.apiyi.com/v1/evals/runs \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $替换你的API易后台的Key$" \
-d '{
"name": "gpt-4.1-mini评估",
"eval_id": "eval_abc123", # 替换为上一步创建的评估ID
"data_source": {
"type": "responses",
"source": {"type": "responses", "limit": 10},
"input_messages": {
"type": "item_reference",
"item_reference": "item.input"
},
"model": "gpt-4.1-mini"
}
}'
Responses Evaluation API 最佳实践
-
设计全面的评分标准:评估效果很大程度上取决于评分标准的质量。建议包含多个维度,并为每个维度提供清晰的评分指南。
-
选择代表性的测试样本:确保测试样本覆盖各种实际使用场景,特别是关键或高风险场景。
-
使用自动化流程:将评估整合到CI/CD流程中,实现模型升级前的自动质量验证。
-
结合多种评估方法:除了模型评估外,还可结合人工审核和用户反馈,获得更全面的质量视图。
Responses Evaluation API 常见问题
问题1:Responses Evaluation API 与传统的人工评估相比有什么优势?
Responses Evaluation API 可以大规模自动化进行评估,显著节省时间和成本。它使用强大的模型作为评估器,能够提供更一致、更客观的评分标准,并且可以持续运行以监控模型质量。
问题2:如何确保评估结果的可靠性?
设计清晰、具体的评分标准是关键。此外,可以使用多个评估标准从不同角度评估模型,并在条件允许的情况下结合少量人工评估来验证自动评估的准确性。
问题3:评估数据需要多少样本才有意义?
这取决于具体任务的复杂性和变异性。一般建议至少使用30-50个不同的测试样本,对于更复杂的任务可能需要更多。重要的是确保样本具有代表性,涵盖各种使用场景。
为什么选择「API易」进行模型评估
-
全面的模型支持
- API易 提供对 OpenAI、Claude、Gemini 等多家顶级模型的访问
- 可以在同一平台上评估和比较不同厂商的模型
- 灵活切换评估器和被评估模型
-
稳定的 API 访问
- 无需担心区域限制或配额问题
- 高可用性保障,确保评估流程不会中断
- 不限速调用,加快评估过程
-
成本优化
- 合理的价格策略,降低评估成本
- 按量计费,无需为未使用的资源付费
- 免费额度可用于小规模试验性评估
-
专业技术支持
- 提供模型评估最佳实践建议
- 解决评估过程中遇到的技术问题
- 协助设计适合特定需求的评估标准
总结
Responses Evaluation API 为 AI 开发者提供了一个强大、灵活的工具,可以系统化地评估和比较不同模型的性能。通过使用这一工具,你可以:
- 基于客观数据选择最适合特定任务的模型
- 在升级模型前验证新版本的性能提升
- 持续监控模型输出质量,及时发现和解决问题
- 建立可量化的 AI 质量管理体系
作为行业领先的 API 聚合平台,API易 提供了对 Responses Evaluation API 和各大模型的稳定访问,让你能够轻松进行全面、深入的模型评估,为构建高质量 AI 应用奠定坚实基础。
欢迎免费试用 API易,3 分钟跑通 API 调用 www.apiyi.com
支持模型评估和多种顶级大模型,助力构建高质量 AI 应用
加站长个人微信:8765058,发送你《大模型使用指南》等资料包,并加赠 1 美金额度。

本文作者:API易团队
欢迎关注我们的更新,持续分享 AI 开发经验和最新动态。